
Die Preisgestaltung ist der Kern jedes Unternehmens, jeder Marke und jedes Produkts. Eine gute Preisstrategie kann Sie an die Spitze des Marktes bringen, während ein schlechtes Modell Ihr Untergang sein kann. Wenn Sie also Ihre Erfolgschancen erhöhen möchten, ist Price Scraping möglicherweise das wichtigste Instrument in Ihrem Arsenal.
Durch das Sammeln von Preisdaten erhalten Sie Einblicke in die Marktdynamik und können datengesteuerte Entscheidungen zur Verbesserung der Wettbewerbsfähigkeit treffen. alles aus Daten, die im Internet öffentlich verfügbar sind.
Durch die Nutzung von Price Scraping können Sie:
- Informieren Sie sich über Ihre Preisstrategie, um wettbewerbsfähig zu bleiben
- Passen Sie die Preise automatisch an die Marktbedingungen, Nachfrageschwankungen und die Preise der Wettbewerber an (dynamische Preisgestaltung).
- Erkennen Sie Markttrends und passen Sie sich an plötzliche Veränderungen an
- Identifizieren Sie Preismöglichkeiten
- Behalten Sie Ihre Konkurrenten im Auge
Und vieles mehr. Um Ihnen den Einstieg zu erleichtern, stellen wir Ihnen einige der besten Tools vor, mit denen Sie Preisinformationen in großem Umfang sammeln können, sowie zwei effektive Methoden, um dies selbst zu tun.
Die 3 besten Tools zum Preis-Scraping
Für die Überwachung von Preisdaten stehen zahlreiche Tools und Dienste zur Verfügung. Anstatt Ihnen also hundert verschiedene Lösungen anzubieten, die größtenteils das Gleiche tun, haben wir drei Lösungen aufgelistet. Wenn Sie sich nicht sicher sind, welchen Weg Sie einschlagen sollen, denken Sie über Ihr Budget, Ihre Datenanforderungen und Ihr Fachwissen (Ihres oder das Ihres Teams) nach, und Sie werden schnell die beste Lösung für Sie finden.
Ressource: So wählen Sie ein Datenerfassungstool aus
1. Python
Python ist eine anspruchsvolle, vielseitige und leicht lesbare Programmiersprache. Es ist für seine Einfachheit und umfangreichen Bibliotheken bekannt.
Da es Open-Source ist, kann Python für jede Art von Anwendung (geschäftlich oder privat) kostenlos verwendet werden und hat die Türen für eine umfangreiche Community geöffnet, die immer bereit ist, zu helfen.
Dank Bibliotheken wie Requests, Beautiful Soup und Pandas ist das Auslesen öffentlich verfügbarer Preisinformationen und die Manipulation dieser Informationen bei ausreichendem Wissen ein sehr einfacher Prozess. Was Python jedoch (zumindest für diese Aufgabe) von anderen Sprachen unterscheidet, ist, dass es zu einem Standard in der Datenbranche geworden ist. Es besteht kein Mangel an kostenlosen Bildungsinhalten, Bibliotheken und Tools zum Sammeln und Analysieren von Daten in großem Maßstab.
Ressource: Web-Scraping-Anleitung mit Python und Beautiful Soup
Alternative
Wenn Sie sich nicht für Python interessieren, ist JavaScript (in einer Node.js-Umgebung) eine weitere großartige Programmiersprache zum Erstellen von Datensammlern.
Dank Tools wie Axios und Cheerio können Sie hochentwickelte Web-Scraper für Websites erstellen, die eine Benutzerinteraktion erfordern (z. B. Single-Page-Anwendungen).
Ressource: So führen Sie Web Scrape mit JavaScript und Node.js durch
2. Datenpipeline
DataPipeline ist die Low-Code-Lösung von ScraperAPI zum Erstellen von Datensammlern und zum Planen von Scraping-Jobs mit einer visuellen Schnittstelle.
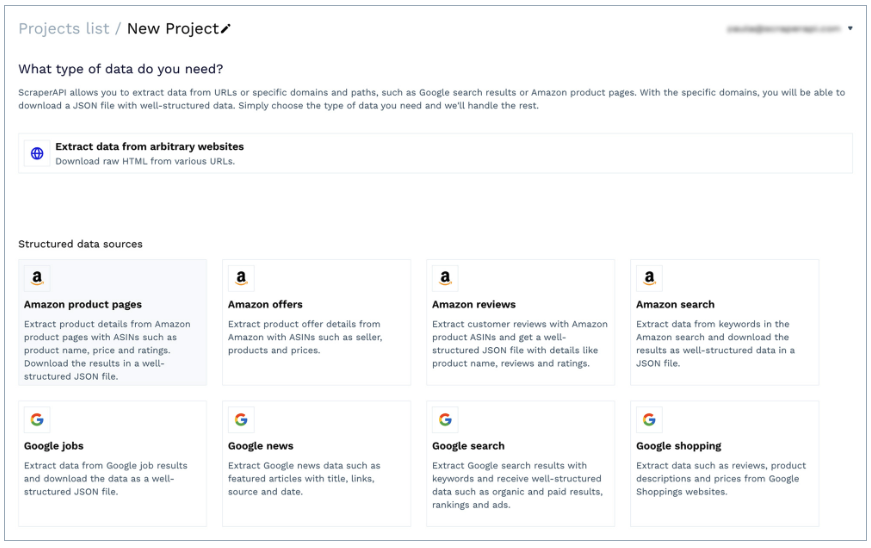
Dank seiner einfachen Benutzeroberfläche kann es von technisch nicht versierten Fachleuten verwendet werden, um Daten von jeder URL zu sammeln, ohne eine einzige Codezeile schreiben zu müssen. Darüber hinaus bietet es spezifische Vorlagen für Domains wie Amazon (Produktseiten, Suche, Angebote usw.) und Google Shopping. Es ermöglicht Ihnen, Produktinformationen – einschließlich der Preise – als strukturierte JSON-Daten abzurufen.
Das Beste ist, dass es über einen integrierten Zeitplaner verfügt. Sie können damit bestimmte Intervalle für Scraping-Jobs festlegen und so mit nur wenigen Klicks Produkte und URLs regelmäßig überwachen.
Alternative
Wenn Sie über Programmiererfahrung verfügen, können Sie die strukturierten Datenendpunkte von ScraperAPI verwenden, um Produktseiten in JSON umzuwandeln. Beim Senden einer get()-Anfrage über einen dieser Endpunkte umgeht ScraperAPI alle Anti-Scraping-Mechanismen, übernimmt alle relevanten Elemente von der Produktseite oder dem Suchergebnis und gibt alles in strukturierten Schlüsselpaaren (JSON) zurück.
Sie haben weiterhin die Flexibilität, eine komplette Lösung von Grund auf zu erstellen, jedoch mit einfacher zu manipulierenden Datenformaten.
3. Gedankenruhe
Mindrest ist eine komplette handelsübliche Preisüberwachungs- und Preisoptimierungssoftware. Es ist so konzipiert, dass es von Anfang an funktioniert, ohne dass Sie viel dazu beitragen müssen.
Der Kompromiss bei der Verwendung dieser Art von Software besteht natürlich in der Anpassung und dem Preis.
Da Preisüberwachungssoftware möglichst viele Unternehmen bedienen muss, um profitabel zu sein, bedeutet dies auch, dass die Software so konzipiert ist, dass sie möglichst viele Anwendungsfälle abdeckt, und dass die Änderung von Teilen der Software an Ihre Arbeitsabläufe eine größere Herausforderung darstellen kann.
Dennoch kann dies die perfekte Wahl für Unternehmen sein (die über das Budget verfügen, um sich den Service leisten zu können), die keine internen Lösungen entwickeln möchten oder nicht über genügend Personal verfügen, um das Projekt abzuwickeln (z. B. Datenanalysten, um die gesammelten Daten zu verarbeiten). Daten).
Alternative
Eine ähnliche, aber günstigere Lösung ist Prisync. Die Software kann mehrere Plattformen (wie Shopify-Shops) überwachen und basierend auf den gefundenen Daten eine dynamische Preisgestaltung implementieren, was sie zu einer großartigen, maßgeschneiderten Lösung für mittelständische Unternehmen macht.
Preisdaten mit DataPipeline sammeln (Low-Code-Methode)
Lassen Sie uns zunächst die Low-Code-Methode untersuchen, die recht einfach ist.
Erstellen Sie zunächst ein kostenloses ScraperAPI-Konto, navigieren Sie zu Ihrem Dashboard und klicken Sie auf „Neues DataPipeline-Projekt erstellen“.
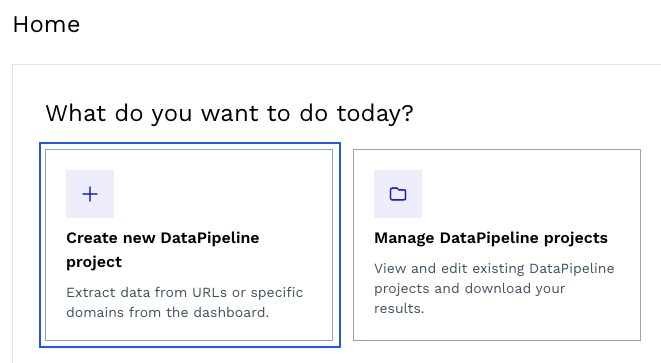
Wir können eine der vorgefertigten Vorlagen auswählen oder ein Projekt erstellen, um Daten von beliebigen URLs zu sammeln. Für dieses Projekt verwenden wir die Vorlage „Amazon-Produktseiten“.
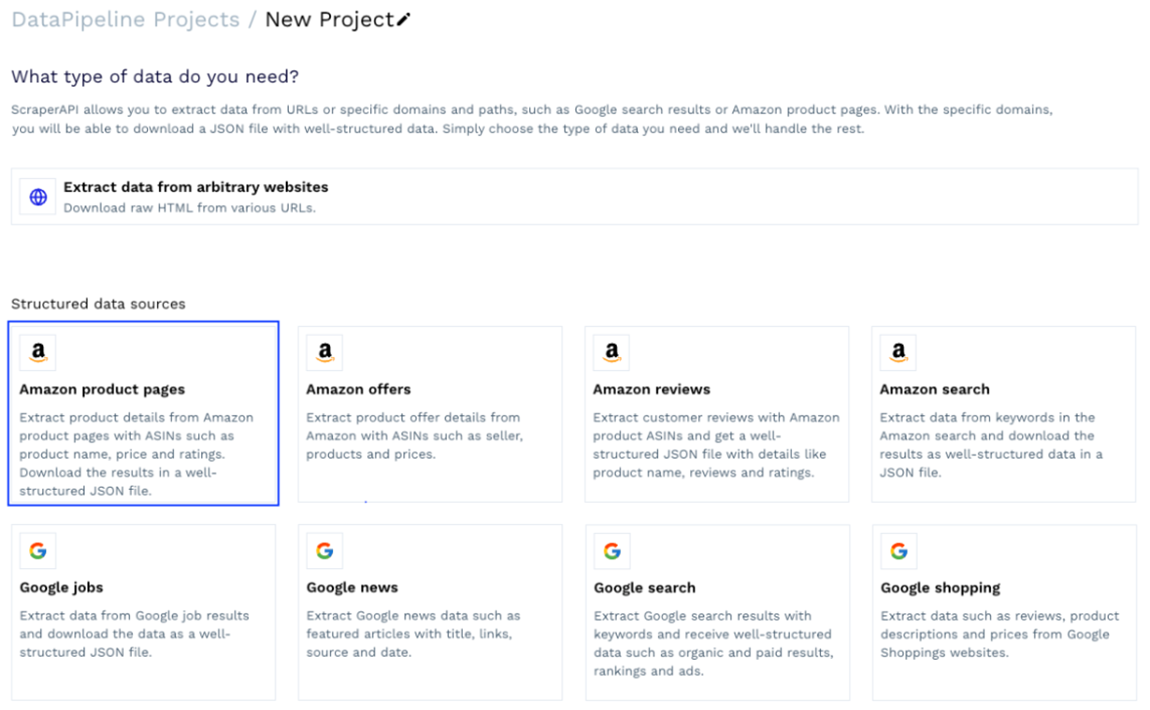
In dieser Vorlage werden Sie nach ein paar Details zum Scraping-Auftrag gefragt, aber das wichtigste Element ist die Produkt-ASIN – eine eindeutige Nummer, die Amazon jedem auf der Plattform gelisteten Produkt zuweist und die Sie normalerweise in der Produkt-URL leicht finden können /db/.
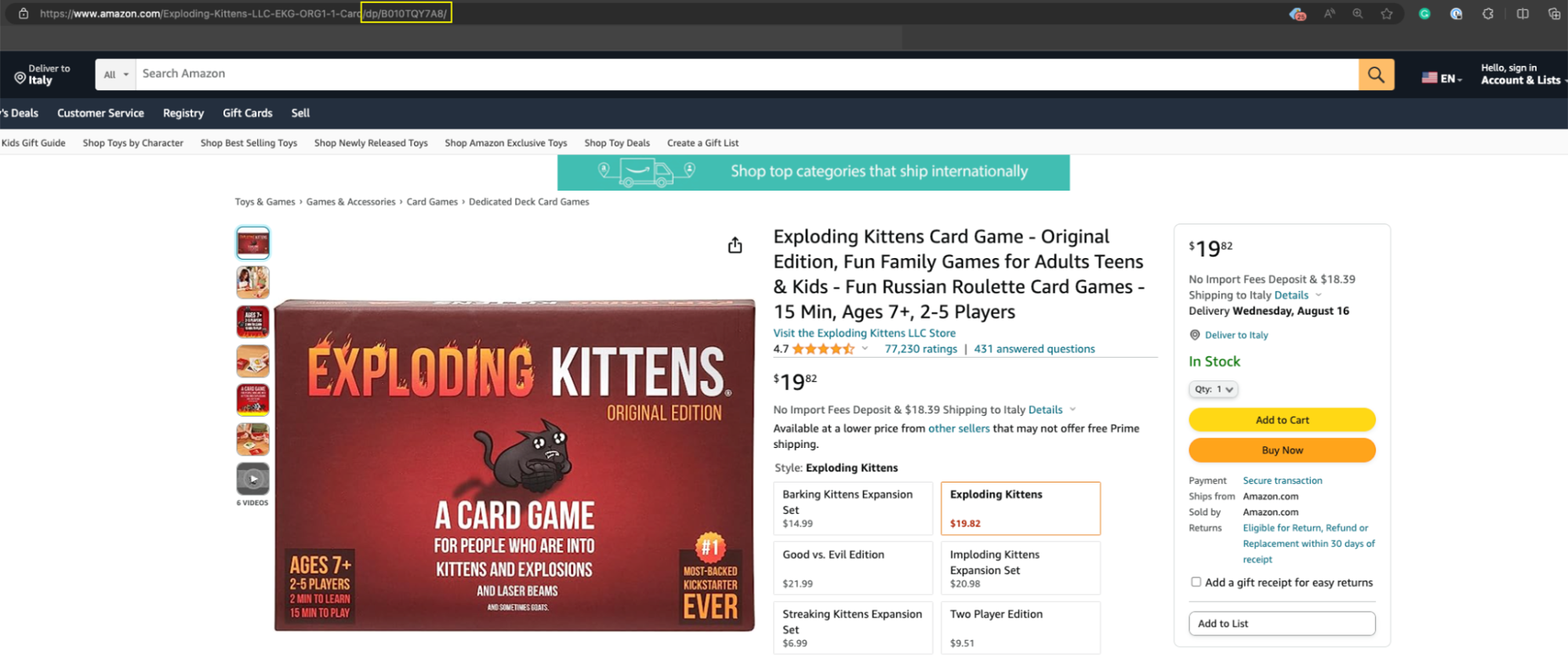
Kopieren Sie die Produkt-ASIN und fügen Sie sie in das Textfeld des Tools ein.
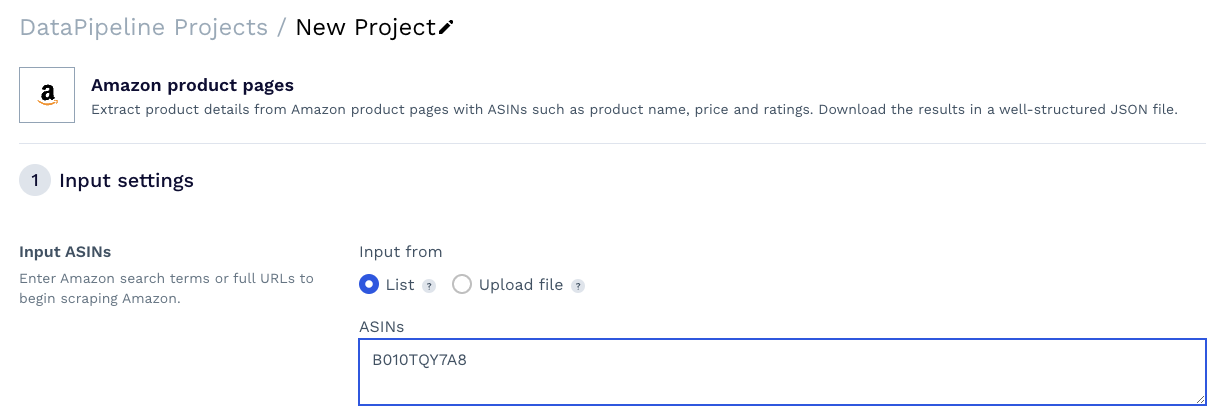
Ressource: Sammeln Sie Produkt-ASINs in großem Maßstab
Klicken Sie anschließend auf das Dropdown-Menü und suchen Sie nach den USA. Sie können die TLD leer lassen.

Der Ländercode definiert den Standort, von dem aus DataPipeline die Anfragen senden soll. Die TLD teilt ihm mit, an welche Amazon-Domain es gesendet werden soll. Wenn keine TLD definiert ist, wie in unserem Fall, wird standardmäßig die US-TLD verwendet, also amazon.com.
Notiz: Dies ist praktisch, wenn Sie lokalisierte Daten sammeln.
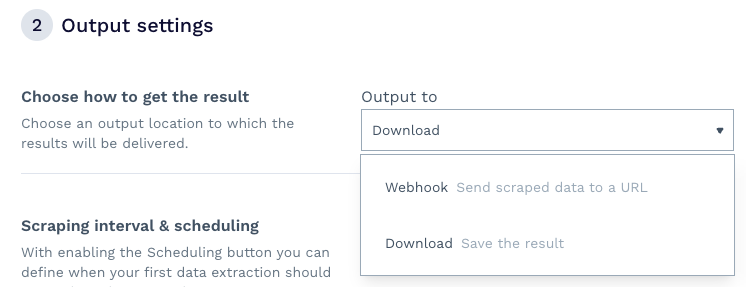
Im zweiten Schritt des Setups geschieht die Magie. Zunächst können Sie entscheiden, wie Sie Ihre Daten erhalten möchten – wir haben uns für den Download der Datei entschieden, Sie können aber auch einen Webhook einrichten, um die Informationen direkt in eine Anwendung, ein Data Warehouse usw. zu empfangen.
Zweitens können Sie durch die Aktivierung der Planung einen Tag, eine Uhrzeit und ein Intervall festlegen, in dem der Scraping-Job automatisch erneut ausgeführt wird, und so die Produktseiten Ihrer Konkurrenten effektiv überwachen.
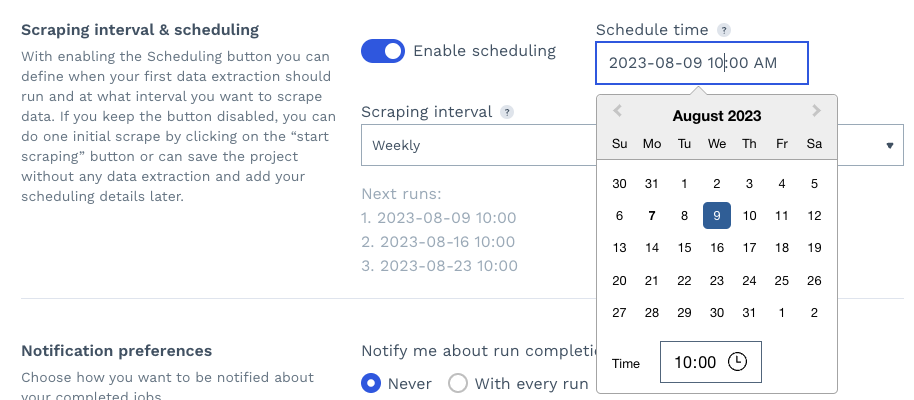
Schließlich können Sie Ihre Benachrichtigungseinstellungen festlegen und auf „Scraping starten“ klicken, um Ihr Projekt auszuführen.

Sobald der Auftrag abgeschlossen ist, können Sie zum Projekt zurückkehren und die Datei mit den zum Parsen bereiten Daten herunterladen.
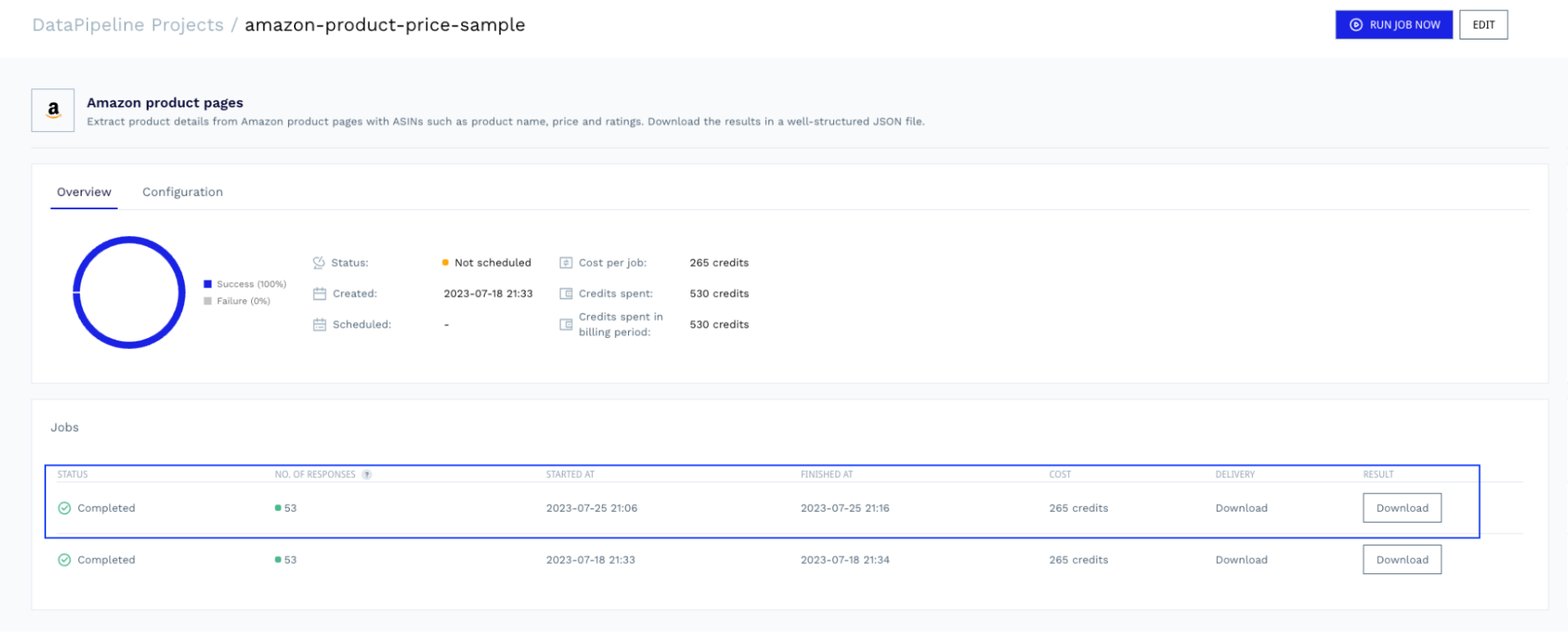
Sehen Sie sich die vollständige Amazon-Produktbeispielantwort an, die DataPipeline zurückgibt.
Scraping von Preisdaten mit Python (technische Methode)
Der Einfachheit halber erfassen wir Preisdaten von books.toscrape.com. Genauer gesagt erfassen wir den Namen, den Preis, den UPC und die Verfügbarkeit des ersten auf der Seite aufgeführten Buchs.
Einrichten Ihres Projekts
Lassen Sie uns ein neues Verzeichnis für unser Projekt erstellen, eine Python-Datei erstellen und oben unsere Abhängigkeiten importieren.
import requests
from bs4 import BeautifulSoup
import pandas as pd
Erstellen Sie als Nächstes ein kostenloses ScraperAPI-Konto, falls Sie dies noch nicht getan haben, kopieren Sie Ihren API-Schlüssel aus dem Dashboard und fügen Sie die folgende Nutzlastvariable zu Ihrer Datei hinzu.
payload = {
'api_key': 'YOUR_API_KEY',
'url': 'https://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html',
'country_code': 'us'
}
In einem echten Projekt – insbesondere bei komplexen Websites – werden Websites Ihre Skripte schnell erkennen und ihnen den Zugriff auf das Web blockieren, was auch dazu führen kann, dass Ihre IP auf unbestimmte Zeit auf die schwarze Liste gesetzt wird.
Um Risiken zu vermeiden und den technisch anspruchsvollsten Aspekt des Web-Scrapings (wie rotierende Proxys, Handhabung von CAPTCHAs und Geotargeting) zu automatisieren, verwenden wir den Standardendpunkt von ScraperAPI.
Beachten Sie außerdem, dass wir die URL hinzufügen, die wir scannen möchten (https://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html) und den Standort der Proxys, die ScraperAPI verwenden soll (in den USA ansässige Proxys).
Jetzt können wir unsere Anfrage senden.
Senden Ihrer Anfrage
Um eine Anfrage über ScraperAPI zu senden, erstellen wir eine get() Anfrage an die https://api.scraperapi.com Endpunkt, mit der Nutzlast als Parameter.
response = requests.get('https://api.scraperapi.com', params=payload)
ScraperAPI nutzt maschinelles Lernen und jahrelange statistische Analysen, um die richtige IP- und Header-Kombination auszuwählen, um den Anti-Scraping-Mechanismus der Website zu umgehen. Sobald es auf den Inhalt zugreift, gibt es den rohen HTML-Code zurück und speichert ihn in Antwort.
Um jedoch Elemente aus dem auszuwählen Antwortwir müssen das analysieren Antwortund hier kommt BeautifulSoup ins Spiel.
soup = BeautifulSoup(response.content, 'html.parser')
Dadurch wird ein Parse-Baum generiert, durch den wir nun mithilfe von CSS-Selektoren navigieren können.
Erstellen Sie Ihren Parser
Da wir diese Daten exportieren möchten, erstellen wir ein leeres Array, in dem wir die extrahierten Elemente formatieren.
Bevor wir den Code schreiben, müssen wir verstehen, wo sich die Daten innerhalb der HTML-Struktur befinden. Navigieren Sie zur Seite und öffnen Sie DevTools, um den HTML-Code der Seite anzuzeigen.
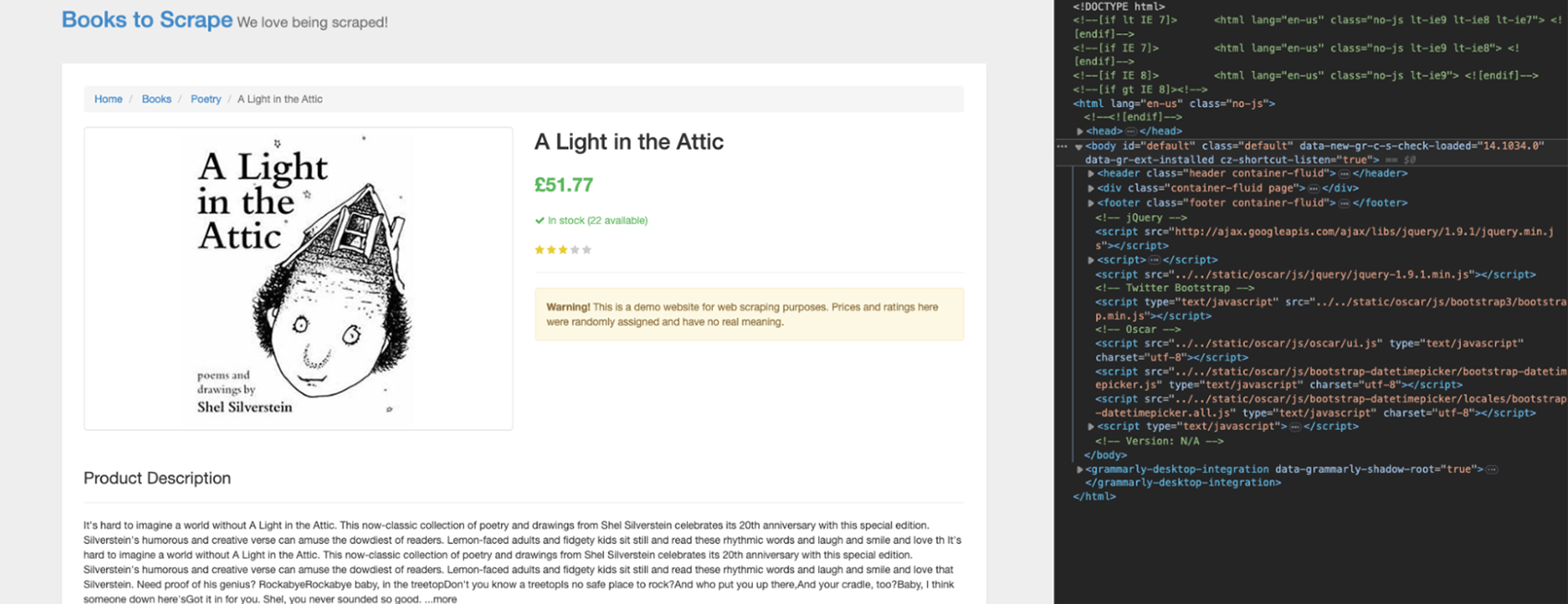
Klicken Sie oben mit dem Inspektor-Tool auf den Namen des Buchs.
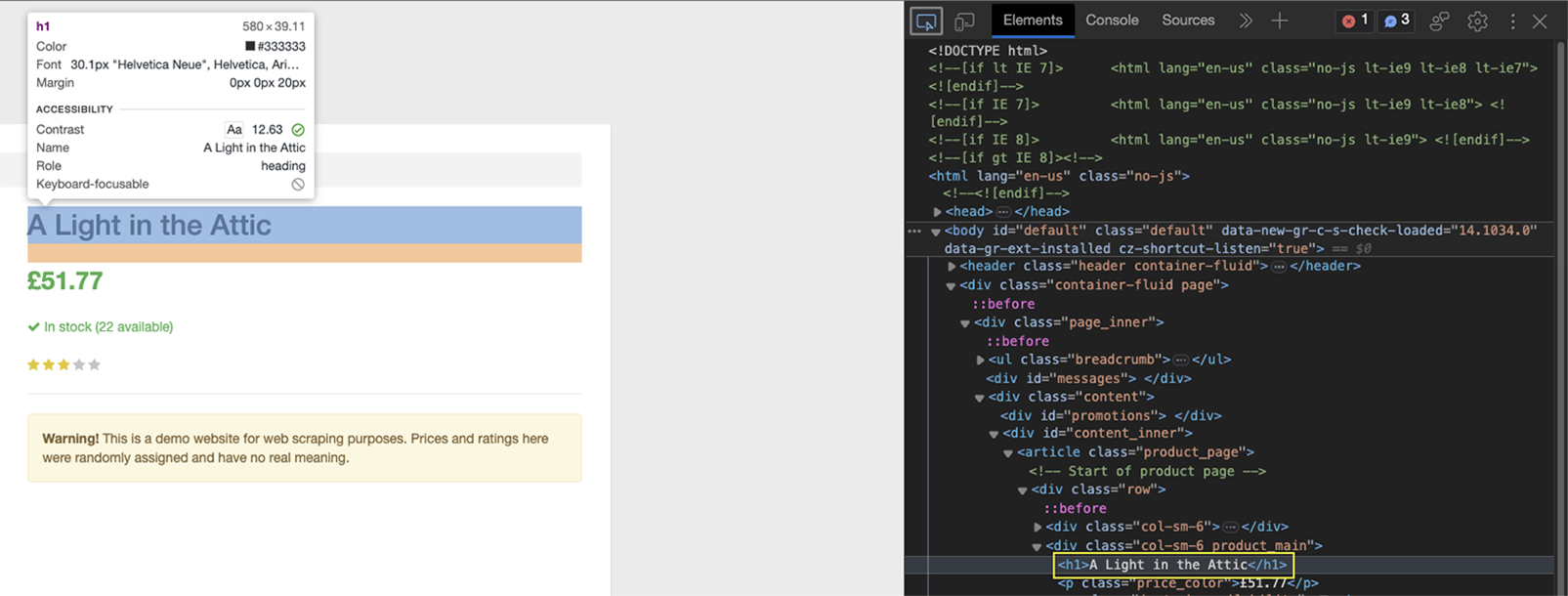
Wie Sie sehen können, ist das Element zwischen h1-Tags eingeschlossen und das einzige h1-Element auf der Seite.
Bevor wir den Namen des Buchs extrahieren, erstellen wir die Logik zum Anhängen der Daten an das leere Array (book_data.append()), und darin formatieren wir die Informationen.
book_data.append({
'Name': soup.find('h1').text,
})
Weil der Analysebaum in gespeichert ist Suppewir können jetzt das verwenden .find() Methode darauf, um auf die zu zielen h1 Element und bitten Sie es dann, das zurückzugeben Text innerhalb dieses Elements.
Machen Sie das Gleiche für den Preis.

In diesem Fall liegt der Preis zwischen eingewickelt p Tags, aber es gibt viele auf der Seite. Was können wir also tun?
Wenn man genauer hinschaut, wird dies konkret p Tag hat eine price_color Klasse, auf die wir mit dem richtigen CSS-Selektor abzielen können:
book_data.append({
'Name': soup.find('h1').text,
'Price': soup.find('p', class_='price_color').text,
})
Die nächsten beiden Elemente befinden sich jedoch innerhalb einer Tabelle, was eine andere Strategie erfordert.
Produktdaten aus Tabellen extrahieren
Tabellen sind (manchmal) etwas schwieriger zu durchsuchen als andere Elemente, da sie aus Tags ohne bestimmte Zielattribute wie Klassen oder IDs bestehen. Stattdessen können wir die Position jedes Elements innerhalb der Tabelle verwenden, um auf die Daten abzuzielen.

Im Bild oben können Sie sehen, dass sich der Hauptinhalt der Tabelle im befindet tbody Tag – dies ist bei den meisten Tabellen der Fall – und jede Zeile wird durch a dargestellt tr Etikett.
Dann, im Inneren tr Tag sind zwei Tags, die den Namen des Details enthalten (th) und der Wert (td).
Mit dieser Struktur sollten wir in der Lage sein, beispielsweise den UPC gezielt anzusprechen, indem wir alle finden tr Tags auf der Seite, wählt das erste in der Liste aus und gibt dann den Text von dem jeweiligen zurück td.
Testen wir dies in der Konsole des Browsers:
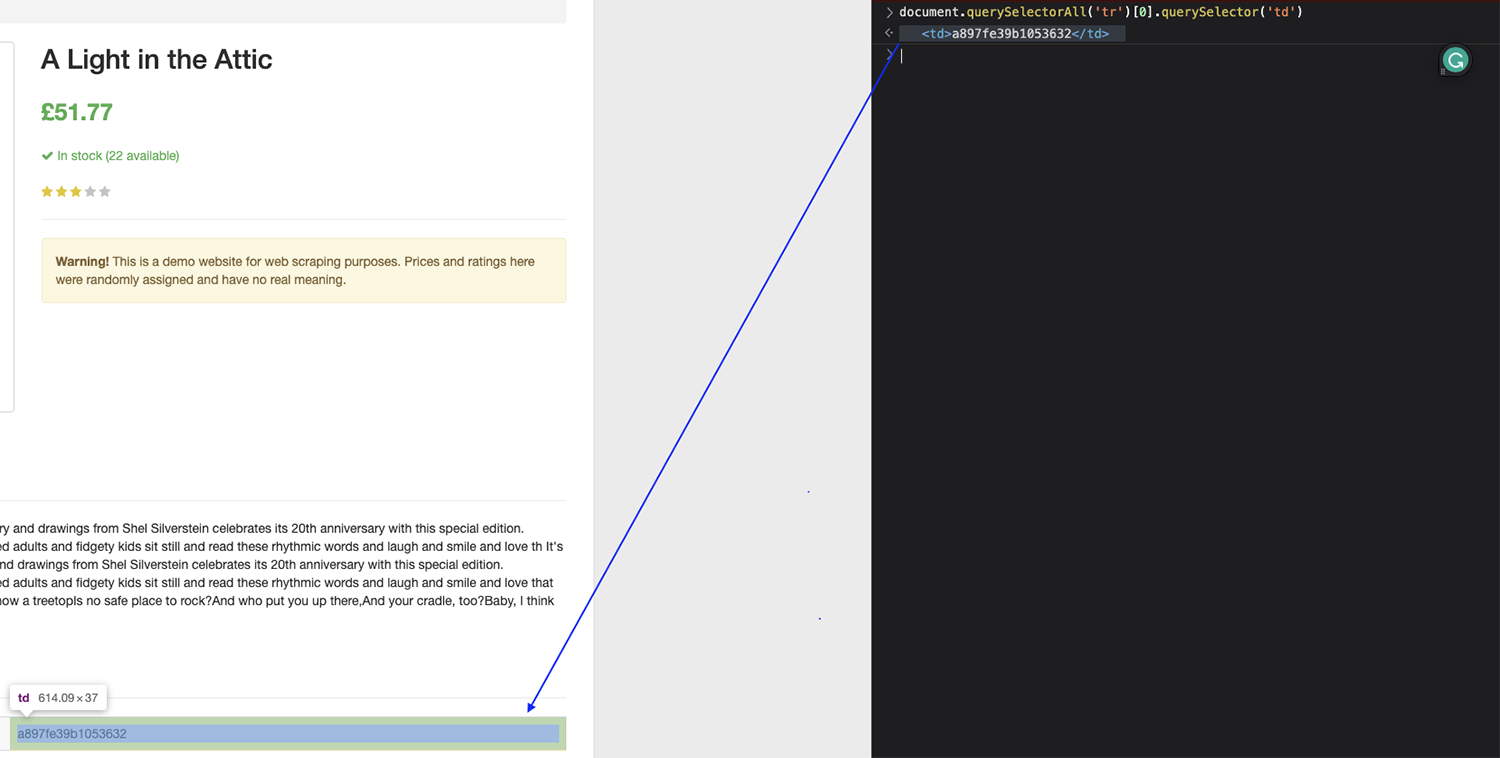
Notiz: Denken Sie daran, dass der Index bei Null (0) beginnt zu zählen. Wenn Sie also das erste Element erfassen möchten, müssen Sie auf das Element Null zielen.
Es hat perfekt funktioniert!
Jetzt können wir dieselbe Logik in unserem Code verwenden, um den UPC zu extrahieren.
book_data.append({
'Name': soup.find('h1').text,
'Price': soup.find('p', class_='price_color').text,
'UPC': soup.find_all('tr')(0).find('td').text,
})
Für die Verfügbarkeit ändern Sie einfach die Zahl auf 5, um die sechste Zeile in der Tabelle anzuvisieren, und jetzt haben wir unseren Parser fertiggestellt.
book_data.append({
'Name': soup.find('h1').text,
'Price': soup.find('p', class_='price_color').text,
'UPC': soup.find_all('tr')(0).find('td').text,
'Availability': soup.find_all('tr')(5).find('td').text,
})
Exportieren der extrahierten Daten in eine CSV-Datei
Dieser Teil ist super einfach, da Sie die harte Arbeit bereits erledigt haben. Durch das Anhängen der Daten an book_data haben wir ein Wörterbuch erstellt, das wir mit Pandas wie folgt exportieren können:
df = pd.DataFrame(book_data)
df.to_csv('product_data.csv', index=False)
Dabei werden die oben festgelegten Namen (Name, Preis, UPC und Verfügbarkeit) als Kopfzeilen verwendet und dann der Wert hinzugefügt.

Zusammenfassung
Herzlichen Glückwunsch, Sie haben gerade Ihren ersten Preis-Tracker erstellt!
Natürlich können Sie dieses Skript skalieren, um die Daten aller 1.000 Bücher in „Books to Scrape“ zu sammeln, wenn Sie möchten, oder eine Liste von Amazon-ASINs erstellen und DataPipeline verwenden, um Preisdaten von bis zu 10.000 Produkten pro Projekt zu sammeln.
Sobald Sie die gewünschten Daten gesammelt haben, können Sie diese analysieren, um aussagekräftige Schlussfolgerungen zu ziehen, die Ihnen dabei helfen können, Ihre Produktpreise festzulegen, den Gesamtmarkt zu verstehen und interessante Preismöglichkeiten zu finden.
Die Erstellung historischer Preisdaten ist der beste Weg, um hochwertige Preismöglichkeiten zu finden (z. B. Jahreszeiten, in denen die Konkurrenz teurer ist), Marktveränderungen zu erkennen, damit Sie sich schnell anpassen können, Umsatzrückgänge aufgrund niedrigerer Preistrends zu erkennen und vieles mehr.
Kombinieren Sie diese Daten mit Produktdetails und Produktbewertungen, um den größtmöglichen Nutzen für Ihre Bemühungen zu erzielen.
Hier sind zwei Ressourcen, die Ihnen den Einstieg erleichtern können:
Zögern Sie nicht, das heutige Skript zu verwenden, um andere Projekte anzustoßen, oder nutzen Sie DataPipeline für eine effizientere Planung von Scraping-Jobs.
Bis zum nächsten Mal, viel Spaß beim Schaben!
