
Node Unblocker ist eine Node.js-Bibliothek, mit der Sie Proxyserver erstellen können, um Inhaltsblöcke zu umgehen. Die Bibliothek wurde ursprünglich als Tool zur Umgehung der Zensur entwickelt, hat sich jedoch inzwischen zu einem allgemeineren Proxyserver entwickelt. Dies macht es zu einer großartigen Wahl für eine Vielzahl von Aufgaben, beispielsweise für den Zugriff auf Inhalte aus anderen Regionen oder den Schutz der Privatsphäre.
In diesem Artikel behandeln wir die Grundlagen von Node Unblocker, einschließlich seiner Funktionen, Verwendung und Einschränkungen. Wir werden uns auch ein Beispiel für die Erstellung einer einfachen Anwendung mit dieser Bibliothek ansehen.
Was ist Node Unblocker?
Wie bereits erwähnt, ist Node Unblocker eine Node.js-Bibliothek, die für das Traffic-Proxying erstellt wurde. Allerdings wurde seine Funktionalität im Laufe der Zeit erweitert. Heute lässt sich damit ein vollwertiger Proxy-Server einrichten. Dieser Server kann Datenverkehr übertragen, empfangen und sogar ändern.
Mit anderen Worten: Node Unblocker-Server bieten einen vollständigen Mechanismus zum Weiterleiten von Anfragen an Remote-Ressourcen. Es unterstützt auch Middleware-Funktionalität. Diese Bibliothek kann nicht nur HTTP-Anfragen eines Clients annehmen und an die angeforderten Ressourcen weiterleiten, sondern auch Änderungen am Inhalt entfernter Webseiten vornehmen.
Gründe für die Verwendung des Node Unblocker Proxy-Netzwerks
Der Einsatz von Node Unblocker kann durch verschiedene Faktoren motiviert werden, abhängig von den spezifischen Bedürfnissen des Benutzers oder Entwicklers. Es kann beispielsweise verwendet werden, um den Datenverkehr weiterzuleiten oder den Inhalt übertragener Daten zu ändern. Dies macht es zu einem wertvollen Werkzeug für eine Vielzahl von Zwecken, einschließlich Seitenoptimierung, Skripteinfügung und Inhaltsänderung.
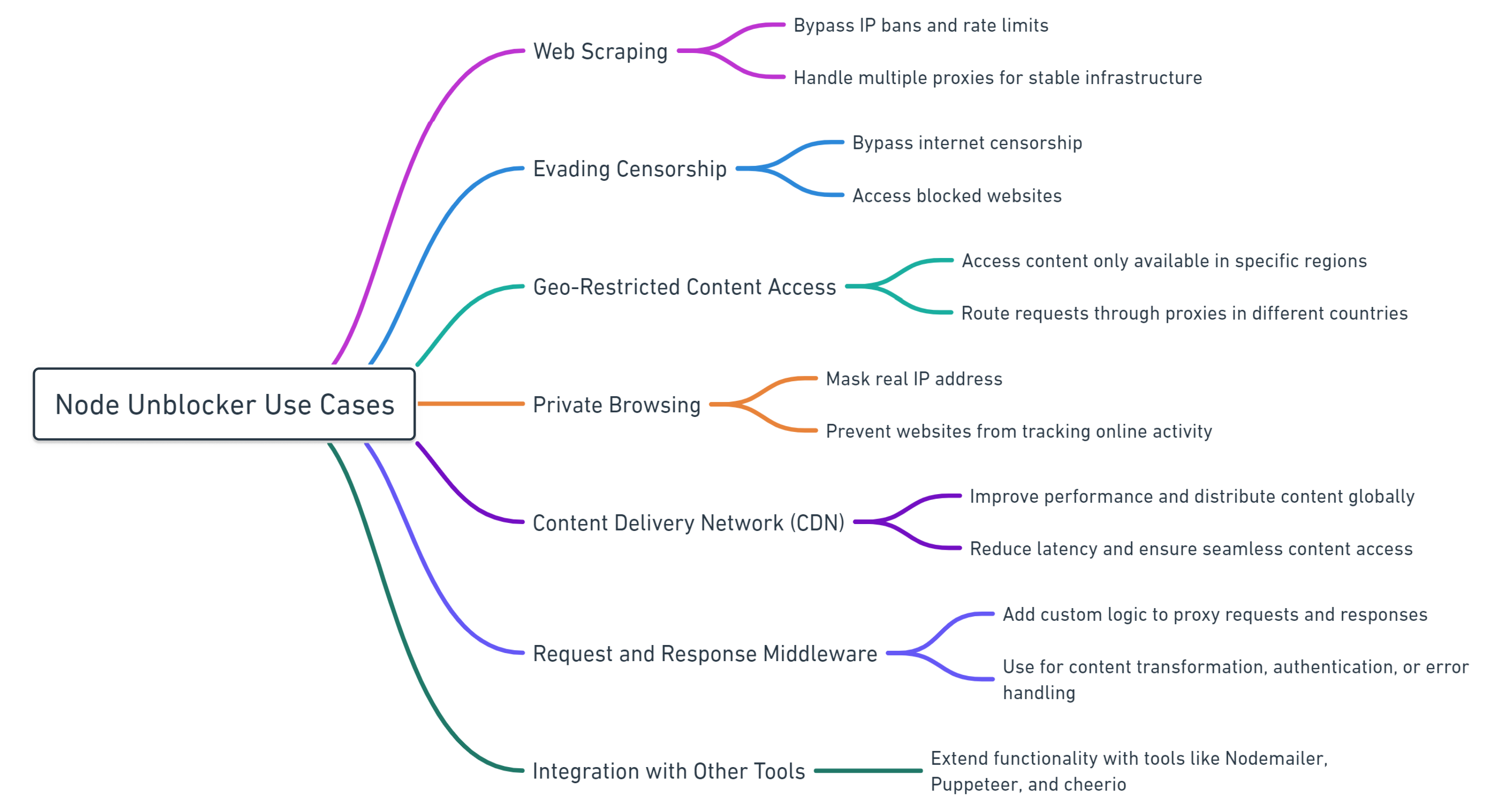
Verbesserung der Sicherheit im öffentlichen WLAN
Node Unblocker ist ein Tool, mit dem die Anonymität der Benutzer erhöht und der Zugriff auf blockierte Websites erleichtert werden kann. Es funktioniert, indem der Datenverkehr über einen Proxyserver geleitet wird, der die tatsächliche IP-Adresse des Benutzers verbirgt und es ihm ermöglicht, Netzwerkbeschränkungen zu umgehen.
An öffentlichen Orten kann Node Unblocker besonders nützlich sein, um die Privatsphäre zu schützen und auf Informationen zuzugreifen, die ansonsten blockiert wären. Es ist jedoch wichtig, sich der möglichen Auswirkungen auf die Netzwerkleistung bewusst zu sein. Die Verwendung eines Web-Proxy-Servers kann die Netzwerklast erhöhen, was zu langsameren Geschwindigkeiten und schlechterer Qualität für alle Benutzer im Netzwerk führen kann.
Zugriff auf Inhalte von jedem Ort aus
Ein weiterer Grund, Ihren Proxyserver mithilfe der Node Unblocker-Bibliothek zu erstellen, besteht darin, auf Informationen und Ressourcen zuzugreifen, die in Ihrer Region nicht verfügbar sind. Mit dieser Bibliothek können Sie eine einfache Anwendung erstellen und diese auf einem Remote-Server ausführen, für den diese Einschränkungen nicht gelten. So können Sie problemlos auf alle notwendigen Informationen zugreifen.
Verbergen von Daten vor ISPs
Schließlich möchten Sie möglicherweise die von Ihrem Internetdienstanbieter (ISP) auferlegten Beschränkungen umgehen. Dies kann nützlich sein, wenn Sie Ihre Online-Aktivitäten vor Ihrem ISP verbergen oder auf Websites zugreifen möchten, die Ihr Provider blockiert. Die Verwendung von Node Unblocker trägt dazu bei, die sichere Übertragung von Daten zwischen Ihnen und der Zielressource sicherzustellen, indem die tatsächliche IP-Adresse des Clients verborgen wird und es schwierig wird, seine Aktivitäten zu verfolgen und zu überwachen.
Wie bei der Umgehung regionaler Beschränkungen hilft Ihnen Ihr Proxyserver dabei, Daten abzurufen, die der Anbieter blockiert hat. In diesem Fall fungiert der Proxyserver als Vermittler. Das heißt, Sie fordern Daten vom Proxyserver an, auf die der Anbieter den Zugriff nicht beschränkt, und der Proxyserver wiederum fordert die benötigten Informationen von der Zielressource an und sendet dann seine Antwort an Sie zurück.
Trotz der potenziellen Vorteile ist anzumerken, dass die Verwendung von Proxyservern zur Verschlüsselung von Daten mit einigen Nachteilen verbunden sein kann. Dies kann sich beispielsweise durch zusätzliche Verschlüsselungs- und Proxying-Stufen auf die Geschwindigkeit der Datenübertragung auswirken.
Darüber hinaus hängt die Sicherheit der übertragenen Daten von der korrekten Konfiguration des Proxyservers und der Verwendung zuverlässiger Verschlüsselungsverfahren ab. Durch eine falsche Konfiguration können Daten anfällig für Angriffe werden.
Node Unblocker für Web Scraping: Schritt-für-Schritt-Anleitung
Zuerst erstellen wir eine Basisanwendung und starten einen Server auf Port 3000. Anschließend besprechen wir, wie Sie die Unblocker-Bibliothek zum Erstellen von Middleware verwenden. Wir behandeln auch die Bereitstellung und die nächsten Schritte. Sie können auch die offizielle Dokumentation der Unblocker-Bibliothek auf GitHub besuchen, um verschiedene Beispiele zu sehen.
Voraussetzungen
Vorausgesetzt, dass Sie bereits über grundlegende NodeJS-Kenntnisse verfügen, gehen wir nicht auf die Installation und Vorbereitung der Umgebung ein. Wenn Sie ein Anfänger sind, können Sie unseren anderen Artikel lesen, in dem Sie nicht nur Anweisungen zur Installation und Vorbereitung der Umgebung finden, sondern auch grundlegende Kenntnisse im Umgang mit beliebten Bibliotheken wie Axios und Cheerio.
Fahren wir nun mit der Erstellung unserer Basisanwendung mithilfe der Node-Unblocker-Bibliotheken fort. Lassen Sie uns zunächst alle npm-Pakete installieren, die später verwendet werden.
npm install express unblocker Erstellen Sie dann eine index.js-Datei, in die wir den gesamten nachfolgenden Code schreiben. Um die Datei auszuführen, verwenden Sie den folgenden Befehl:
node index.jsKommen wir nun zur Datei index.js.
Erstellen der Basisanwendung
Importieren wir zunächst die Bibliotheken, die wir zuvor installiert haben:
import express from 'express';
import Unblocker from 'unblocker';Anschließend erstellen wir eine Instanz des Express-Servers, der die Grundlage unserer Webanwendung bildet. Dadurch können wir Routen und Middleware konfigurieren und Anfragen verarbeiten.
const app = express();Jetzt können wir eine Unblocker-Instanz erstellen und das Präfix für die Verwendung von Node-Unblocker-Proxys festlegen:
const unblocker = new Unblocker({
prefix: '/proxy/'
});Es ist wichtig, Unblocker als einen der ersten app.use()-Aufrufe zu platzieren:
app.use(unblocker);Jetzt können wir konfigurieren, wie mit verschiedenen Anfragen umgegangen wird. Lassen Sie uns beispielsweise Anfragen an den Stammpfad (/) unserer Anwendung bearbeiten, der sich unter der URL http://localhost:3000/ befindet. Wenn ein Benutzer diesen Pfad anfordert, senden wir die Nachricht „Willkommen auf der Hauptseite!“
app.get("https://scrape-it.cloud/", (req, res) => {
res.send('Welcome to the main page!');
});Um die Einrichtung abzuschließen, müssen wir den Server so konfigurieren, dass er auf Port 3000 läuft.
const PORT = process.env.PORT || 3000;
app.listen(PORT, () => {
console.log(`Server started on port ${PORT}`);
});Lassen Sie es uns ausführen und testen:
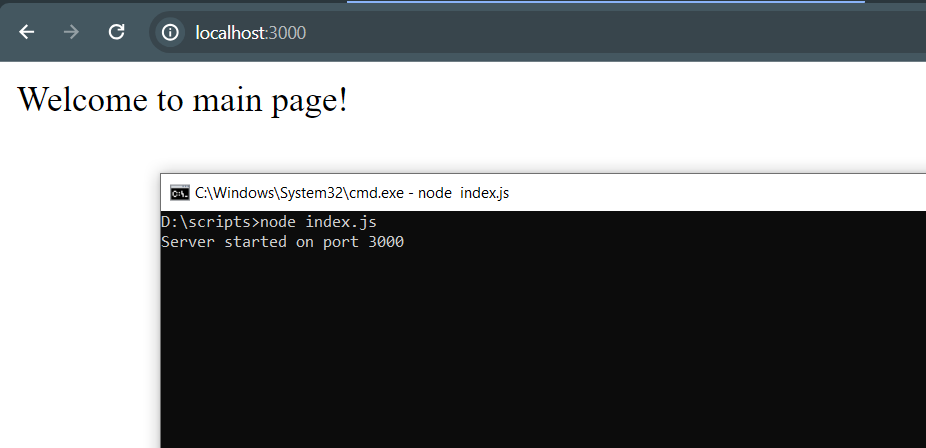
Um Proxying zu verwenden, können Sie das Präfix /proxy/ verwenden. Zum Beispiel, http://localhost:3000/proxy/http://example.com/ leitet Anfragen über den Proxyserver unter http://localhost:3000/ an http://example.com/ weiter.
Verwendung von Middlewares
Mit Node Unblocker können Sie benutzerdefinierte Middleware erstellen und verwenden, um Anfragen und Antworten zu verarbeiten. Sie können beispielsweise Middleware zum Validieren von Anfragen, zum Ändern von Antwortinhalten, zum Umgang mit Cookies, zum Korrigieren von URLs und für andere Aufgaben hinzufügen.
Betrachten wir die Erstellung und Verwendung benutzerdefinierter Middleware zur Validierung von Anforderungen. Beispielsweise prüfen wir, ob es sich bei der Anfrage-URL um eine Google-Website handelt. Wenn nicht, sendet die Middleware dem Client eine Antwort mit dem Statuscode 403 (Verboten) und einer Fehlermeldung.
Erstellen Sie dazu vor dem Erstellen einer Instanz von Unblocker deren Konfigurationsparameter. Erstellen Sie eine Funktion namens „validateRequest“, die die Validierung der Anforderungs-URL durchführt:
function validateRequest(data) {
if (!data.url.match(/^https?:\/\/google.com\//)) {
data.clientResponse.status(403).send('Access denied.');
}
}Fügen Sie dann die Middleware zur Unblocker-Konfiguration hinzu:
const config = {
requestMiddleware: (
validateRequest
)
};Verwenden Sie abschließend die erstellte Konfiguration, wenn Sie eine Instanz von Unblocker erstellen:
const unblocker = new Unblocker(config);Nach dem gleichen Prinzip können Sie weitere Middleware erstellen, beispielsweise zum Umleiten von Anfragen:
function redirect(data) {
data.clientResponse.redirect('https://www.example.com');
}Oder zum Ändern von Anforderungsheadern:
function modifyHeaders(data) {
data.clientRequest.headers('X-Custom-Header') = 'Custom Value';
}Diese Beispiele kratzen nur an der Oberfläche der Fähigkeiten von Middleware. Sie können komplexere Middleware erstellen, die je nach Bedarf Ihrer Anwendung verschiedene Manipulationen mit Anforderungen und Antworten durchführt. Es ist wichtig zu bedenken, dass Middleware in der Reihenfolge ausgeführt wird, in der sie hinzugefügt wird, sodass die Reihenfolge des Hinzufügens von Middleware das Ergebnis der Anforderungsverarbeitung beeinflussen kann.
Bereitstellung auf Heroku und nächste Schritte
Heroku ist eine Cloud-Plattform, die Hosting- und Bereitstellungsdienste für Webanwendungen bereitstellt. Es wird häufig zum Entwickeln, Testen und Bereitstellen von Anwendungen verwendet, ohne dass die physische Infrastruktur verwaltet werden muss.
Heroku skaliert Anwendungen automatisch basierend auf der Auslastung, sodass Sie sich ändernde Verkehrsmengen effizient bewältigen können. Ein wesentlicher Vorteil besteht darin, dass Heroku eine Vielzahl von Programmiersprachen unterstützt, darunter Node.js (JavaScript), Python, Ruby, Java, Go, Clojure und PHP.
Heroku bot zuvor eine kostenlose Stufe für kleine Projekte an, sodass Entwickler ihre Anwendungen in der Anfangsphase kostenlos starten konnten. Allerdings bietet Heroku derzeit nur kostenpflichtige Pläne an. Der einfachste Plan kostet 5 US-Dollar für 1.000 Stunden pro Monat. Heroku-Ressourcen werden in Sekundenschnelle abgerechnet, sodass Sie nur für die Ressourcen bezahlen, die Sie nutzen.
Um Ihre Heroku-App bereitzustellen, benötigen Sie die Heroku-CLI, die Sie von der offiziellen Website herunterladen können. Die Website bietet außerdem Dokumentation und Anweisungen zur Verwendung der CLI. Sobald Sie sich bei Heroku angemeldet und Ihre App konfiguriert haben, können Sie Ihre Anwendung hinzufügen. Anschließend stellt Ihnen Heroku eine zufällige Subdomain zur Verfügung, über die Sie auf Ihre Anwendung zugreifen können.
Möglicherweise müssen Sie Ihren Unblocker auch für die Zusammenarbeit mit der Heroku-Umgebung konfigurieren, indem Sie beispielsweise Umgebungsvariablen zum Festlegen des Ports und anderer Konfigurationsparameter verwenden, die möglicherweise von Ihrer lokalen Entwicklungsumgebung abweichen.
Zukünftig können Sie die Überwachung Ihres Unblockers auch mithilfe von Heroku-Tools oder anderen Überwachungstools konfigurieren. Auf diese Weise können Sie die Leistung verfolgen, Probleme identifizieren und Maßnahmen zu deren Lösung ergreifen.
Einschränkungen von Node Unblocker
Trotz der großen Anzahl von Funktionen, die von der Node Unblocker-Bibliothek unterstützt werden, weist sie eine Reihe von Nachteilen und Einschränkungen auf, die bei der Verwendung berücksichtigt werden sollten. Der Hauptnachteil ist die Unfähigkeit, postMessage-Anfragen zu verwenden, die fehlende Möglichkeit, einen Proxy-Pool zu konfigurieren, und Probleme bei der Unterstützung überlasteter Websites.
Wenn Sie hingegen Node Unblocker verwenden, um Einschränkungen beim Scraping zu umgehen, können Sie andere, geeignetere Lösungen verwenden. Beispielsweise können Web-Scraping-APIs verwendet werden, um Daten völlig sicher von absolut jeder Ressource zu scrapen. Im Falle ihrer Verwendung übernimmt der API-Anbieter alle Probleme des Scrapings, einschließlich der Verwendung von Proxys, der Umgehung von CAPTCHAs und Blöcken, JS-Rendering und mehr.
OAuth-Probleme und Unfähigkeit, PostMessage-Anfragen zu verarbeiten
Node Unblocker unterstützt keine PostMessage-Anfragen. Dies ist wichtig für Websites, die Technologien wie OAuth, Google und Facebook verwenden, die möglicherweise auf postMessage-basierten Interaktionsmechanismen basieren.
OAuth ist ein Protokoll zur Autorisierung des Zugriffs auf Webressourcen Dritter. Wie bereits erwähnt, unterstützt Node Unblocker keine OAuth-Anmeldeformulare. Daher kann es bei der Arbeit mit Ressourcen, die eine OAuth-Authentifizierung erfordern, zu Problemen führen.
Fähigkeit, an komplexen Standorten zu arbeiten
Während Node Unblocker für einfache Websites gut funktioniert, kann es bei der Verwendung mit komplexeren Webressourcen zu Einschränkungen kommen. Beispielsweise werden Websites, die fortschrittliche Technologien wie JavaScript-Frameworks, AJAX-Anfragen und dynamische Inhaltserstellung verwenden, möglicherweise nicht vollständig unterstützt.
Wie auf der offiziellen GitHub-Seite des Node Unblocker-Projekts angegeben, funktionieren beliebte, aber komplexe Websites wie Discord, Twitter oder YouTube möglicherweise nicht richtig. Sie bieten jedoch auch ein Beispiel, das YouTube-Videoseiten erkennt und durch eine benutzerdefinierte Seite ersetzt, die lediglich das Video bereitstellt.
Cloudflare-Erkennung
Cloudflare ist ein beliebter Web-Sicherheits- und Leistungssteigerungsdienst. Einige Websites verwenden Cloudflare, um automatisierte Anfragen oder Proxyserver zu erkennen und zu blockieren. Node Unblocker hat möglicherweise Schwierigkeiten, durch Cloudflare geschützte Websites zu umgehen, da es nicht explizit darauf ausgelegt ist, solche Sicherheitsmechanismen zu umgehen.
Möglichkeit, einen Proxy-Pool zu konfigurieren
Node Unblocker soll in erster Linie die Internet-Zensur umgehen und dabei helfen, einen Proxy-Server zu erstellen. Daher wird die Verwendung von Proxy-Pools oder Proxy-Rotation nicht unterstützt.
Die Proxy-Rotation kann eine komplexe Aufgabe sein, insbesondere wenn Sie eine Vielzahl von Proxy-Servern unterstützen und Netzwerkprobleme lösen müssen. Wenn Ihr Hauptziel das Web-Scraping ist, empfehlen wir die Verwendung der Web-Scraping-API. Es bewältigt die Herausforderungen der Proxy-Rotation und der Umgehung von Blöcken, sodass Sie sich auf das Parsen und Analysieren von Daten konzentrieren können.
Fazit und Erkenntnisse
In diesem Artikel haben wir einen umfassenden Überblick über Node Unblocker gegeben, eine Node.js-Bibliothek zur Umgehung der Inhaltsblockierung, zum Zugriff auf beliebige Websites und zur Verbesserung der Scraping-Effizienz. Wir haben die Grundlagen der Bibliothek behandelt, einschließlich ihrer Installation, Verwendung und Einschränkungen.
Darüber hinaus haben wir ein praktisches Beispiel für die Erstellung einer Basisanwendung besprochen, wie diese konfiguriert und ausgeführt wird und wie zusätzliche Konfigurationen hinzugefügt werden, um benutzerdefinierte Middleware zu erstellen. Wir haben mehrere Beispiele für solche Konfigurationen und Codes bereitgestellt, die Sie ändern und für Ihre Zwecke verwenden können.
Abschließend haben wir besprochen, wo und wie Sie Ihr Projekt für den cloudbasierten Betrieb bereitstellen können und welche Herausforderungen bei der Entwicklung Ihres eigenen Node Unblockers auftreten können.
