
TL;DR: Verwenden von Newspaper3k
Installieren Sie zunächst das Newspaper3k-Paket:
Hier sind einige Codefragmente, die bei der Verwendung des Pakets nützlich sind:
- Laden Sie das HTML der Seite zum Parsen herunter
- Analysieren Sie die HTML-Antwort, um bestimmte Datenpunkte zu extrahieren
- Alle Autoren einer Artikelseite extrahieren
- Extrahieren Sie das Veröffentlichungsdatum des Artikels
- Extrahieren Sie den Text des Artikels aus dem HTML
- Extrahieren Sie das Titelbild des Artikels
- Laden Sie jedes Video zum Artikel herunter
Verwenden Sie die Verarbeitung natürlicher Sprache (NLP), um den Artikel zu analysieren, bevor Sie zusätzliche Daten extrahieren. So erhalten Sie Schlüsselwörter und eine Zusammenfassung des Artikels
- Extrahieren Sie relevante Suchbegriffe aus dem Artikel
- Erstellen Sie eine prägnante Zusammenfassung eines Artikels
Möchten Sie lernen, wie Sie all dies in einem echten Projekt nutzen können?
Weiter lesen!
Was ist Newspaper3k?
Newspaper3k ist ein leistungsstarkes Tool für Web Scraping. Es handelt sich um eine Python-Bibliothek, die Inhalte von Webseiten ausliest, die wie Online-Artikel strukturiert sind. Es verfügt auch über andere Funktionen, mit denen Entwickler HTML-Inhalte analysieren können, um Daten wie Autor, Titel, Haupttext, Veröffentlichungsdatum und manchmal Bilder oder Videoinhalte zu extrahieren, die mit dem Artikel verknüpft sind.
So scrapen Sie Nachrichtenartikel mit Newspaper3k
Um einen Nachrichtenartikel mit dem Newspaper3k-Paket zu scrapen, erstellen Sie zunächst einen Projektordner und darin eine Datei mit dem Namen index.py. Führen Sie dann die folgenden Schritte aus.
Schritt 1: Installieren Sie das Newspaper3k-Paket
Installieren Sie das Newspaper3k-Paket, indem Sie den folgenden Befehl ausführen:
Schritt 2: Laden Sie den Artikel herunter und analysieren Sie ihn
Importieren Sie das Paket und holen Sie sich die URL von der News-Seite, die Sie scrapen möchten. Zuerst laden wir den Artikel herunter, indem wir den download() Methode auf den Artikel. Dann analysieren wir den Artikel, indem wir die Methode aufrufen
parse()Wie nachfolgend dargestellt.
from newspaper import Article
url = 'https://edition.cnn.com/2023/06/10/sport/manchester-city-wins-champions-league-for-first-time-beating-inter-milan-1-0-in-tense-istanbul-final/index.html'
article = Article(url)
article.download()
article.parse()
Schritt 3: Extrahieren der gewünschten Daten
Die im vorherigen Schritt aufgerufene Parse-Methode extrahiert die Daten aus der HTML-Seite. Zu diesen Daten gehören:
- Titel – extrahiert den Artikeltitel
- Autoren – extrahiert den Autor oder die Autorenliste des Artikels und gibt das Ergebnis in einem Array zurück.
- Datum der Veröffentlichung – extrahiert das Datum und die Uhrzeit der Veröffentlichung des Artikels
- Text – extrahiert den Textinhalt des Artikels
- html – gibt das vollständige HTML der Seite zurück
- oberes Bild – gibt das vorgestellte Bild des Artikels zurück (falls vorhanden)
- Bilder – gibt ein Objekt zurück, das die URL aller Bilder im Artikel enthält
- Videos – extrahiert alle Videos im Artikel (falls vorhanden)
# Extract and print the desired data
print("**Headline:**", article.title)
print("**Authors:**", article.authors)
print("**Publication Date:**", article.publish_date)
print("**Main Text:**", article.text)
Führen Sie das Skript aus, indem Sie den folgenden Befehl ausführen.
Das Ergebnis sollte dem Bild unten ähneln.
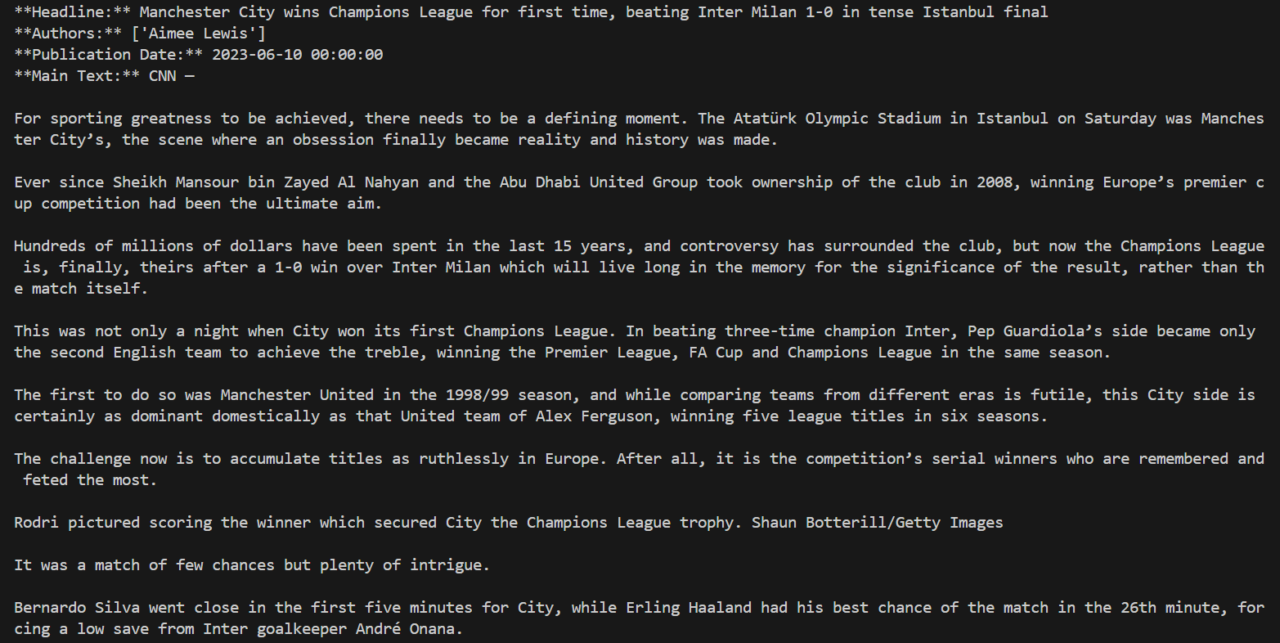
Schritt 4: Sprache des Artikels festlegen
Das Newspaper3k-Paket verfügt außerdem über eine eingebettete Funktion zur nahtlosen Spracherkennung und -extraktion. Dies ermöglicht es dem Entwickler, eine Sprache für die Datenextraktion anzugeben. Wenn keine Sprache angegeben ist, erkennt Newspaper3k automatisch eine Sprache und verwendet diese standardmäßig.
Sehen wir uns an, wie die Sprache beim Scraping von Daten angegeben wird:
url = 'https://www.bbc.com/zhongwen/simp/chinese_news/2012/12/121210_hongkong_politics'
article = Article(url, language='zh') #Chinese
Zum Zeitpunkt des Schreibens unterstützt Newspaper3k die folgenden Sprachen:
Your available languages are:
input code full name
ar Arabic
be Belarusian
bg Bulgarian
da Danish
de German
el Greek
en English
es Spanish
et Estonian
fa Persian
fi Finnish
fr French
he Hebrew
hi Hindi
hr Croatian
hu Hungarian
id Indonesian
it Italian
ja Japanese
ko Korean
mk Macedonian
nb Norwegian (Bokmål)
nl Dutch
no Norwegian
pl Polish
pt Portuguese
ro Romanian
ru Russian
sl Slovenian
sr Serbian
sv Swedish
sw Swahili
tr Turkish
uk Ukrainian
vi Vietnamese
zh Chinese
Fügen Sie mit ScraperAPI eine Proxy-Rotation in Newspaper3k hinzu
Viele Zeitungen und Artikel-Websites verwenden Anti-Bot-Technologien, was es dem Paket erschwert, Websites in großem Umfang zu durchsuchen. Die Optimierung von Headern und die Verwendung von Proxys zum Extrahieren von HTML-Rohdaten von den Websites ist in diesen Situationen normalerweise unvermeidlich.
Ein großer Nachteil von Newspaper3k ist jedoch, dass die Download-Funktion keine integrierte Unterstützung für Proxys bietet. Daher sollte zur Implementierung ein HTTP-Client wie Python Request verwendet werden und das HTML anschließend mithilfe der Newspaper3k-Bibliothek analysiert werden.
Für dieses Beispiel verwenden wir die Scraping-API von ScraperAPI als Proxy-Lösung, um den HTML-Inhalt zu extrahieren und zur Analyse an Newspaper3k weiterzugeben.
Notiz: Um die ScraperAPI Proxy Endpoint-Methode zu verwenden, müssen Sie ein kostenloses ScraperAPI-Konto erstellen, um in Ihrem Dashboard auf Ihren API-Schlüssel zuzugreifen – Ihre kostenlose Testversion umfasst 5.000 API-Credits, mit denen Sie in den meisten Fällen bis zu 5.000 Seiten kostenlos scrapen können.
import requests
from urllib.parse import urlencode
from newspaper import Article
url = 'https://edition.cnn.com/2023/06/10/sport/manchester-city-wins-champions-league-for-first-time-beating-inter-milan-1-0-in-tense-istanbul-final/index.html'
article = Article(url)
## Download HTML using ScraperAPI Proxy
payload = {'api_key': ‘API-KEY', 'url': url}
response = requests.get('https://api.scraperapi.com', params=urlencode(payload))
## Insert HTML into the Newspaper3k article object and parse the article
article.download(input_html=response.text)
article.parse()
print("Headline: ", article.title)
print("Authors: ", article.authors)
print("Publication Date: ", article.publish_date)
Mit dieser Kombination können Sie Ihre Scraper auf Millionen von Seiten skalieren, ohne sich um CAPTCHAs, Ratenbegrenzungen und andere potenzielle Herausforderungen kümmern zu müssen.
So verwenden Sie die NLP-Methoden von Newspaper3k
Newspaper3k bietet auch eine Natural Language Processing (NLP)-Funktion. Dies ermöglicht es Entwicklern, den Inhalt zu analysieren, bevor er extrahiert wird. Die
nlp() Mit dieser Methode können Sie die Zusammenfassung und die Schlüsselwörter im Artikel abrufen.
Die NLP-Methode ist genauso aufwändig wie die Parse-Methode. Daher ist es wichtig, sie nur bei Bedarf zu verwenden. Nachfolgend finden Sie eine Demo zur Implementierung der NLP-Methode.
from newspaper import Article
url = 'https://edition.cnn.com/2023/06/10/sport/manchester-city-wins-champions-league-for-first-time-beating-inter-milan-1-0-in-tense-istanbul-final/index.html'
article = Article(url)
article.download()
article.parse()
article.nlp()
# Extract and print the desired data
print("**Text Summary:**", article.summary)
print("**Keywords: **", article.keywords)
Das Ergebnis sollte dem Bild unten ähneln.

Tipps zur Fehlerbehebung für die Newspaper3k NLP-Methode
Dieser Fehler kann auftreten, wenn die Methode nlp() zum ersten Mal implementiert wird.

Dieser Fehler kann behoben werden, indem Sie den folgenden Code oben im Skript hinzufügen:
import nltk
nltk.download('punkt')
Führen Sie das Skript anschließend erneut aus. Dieses Skript lädt das Punkt-Paket herunter, das für die Ausführung der NLP-Funktion erforderlich ist. Die beiden Codezeilen können anschließend gelöscht werden, ohne dass dies die Ausführung des Skripts beeinträchtigt.
Verwenden der Multithreading-Artikel-Download-Funktion von Newspaper3k
Mit dieser Funktion können Entwickler Nachrichten aus mehreren Nachrichtenquellen gleichzeitig extrahieren. Das gleichzeitige Spammen einer einzelnen Nachrichtenquelle mit mehreren Threads oder mehreren asynchronen E/A-Anfragen führt zu einer Ratenbegrenzung. Daher stellt Newspaper3k 1-2 Threads für jede bereitgestellte Nachrichtenquelle bereit.
Um die Multithreading-Funktion für die Artikel-Download-Funktion zu implementieren, verwenden Sie den folgenden Code:
import newspaper
from newspaper import news_pool
ted = newspaper.build('https://ted.com')
cnbc = newspaper.build('https://cnbc.com')
fox_news = newspaper.build('https://foxnews.com/')
papers = (ted, cnbc, fox_news)
news_pool.set(papers, threads_per_source=2) # (3*2) = 6 threads total
news_pool.join()
# At this point, you can safely assume that download() has been
# called on every single article for all three sources.
print(cnbc.size())
Der join() Die Methode ruft die Download-Funktion für jeden Artikel aus jeder Quelle auf. Daher gibt jede Quelle ein Array zurück und auf die Daten in jedem Array kann wie unten gezeigt zugegriffen werden.
for article in cnbc.articles:
print(article.title)
Lerne weiter
In diesem Artikel haben wir Folgendes gelernt:
- Verwenden Sie das Newspaper3k-Paket zum Scraping von Zeitungs- und Artikel-Websites
-
Integrieren Sie Newspaper3k mit ScraperAPI, um Ihre Infrastruktur in Sekunden zu skalieren
-
Verwenden Sie die Methode nlp(), um relevante Suchbegriffe zu extrahieren und eine Zusammenfassung für jeden Artikel zu erstellen
Das Paket bietet einige weitere Funktionen, darunter die hot Und
popular_url Methoden für das Zeitungspaket. Diese Methoden geben die Trendbegriffe bzw. die beliebtesten Nachrichtenquellen zurück. Weitere Informationen zu diesem Paket finden Sie in der offiziellen Dokumentation.
Wenn Sie mehr über Scraping mit Python erfahren möchten, sehen Sie sich einige dieser Ressourcen an:
Bis zum nächsten Mal, viel Spaß beim Scrapen!
