
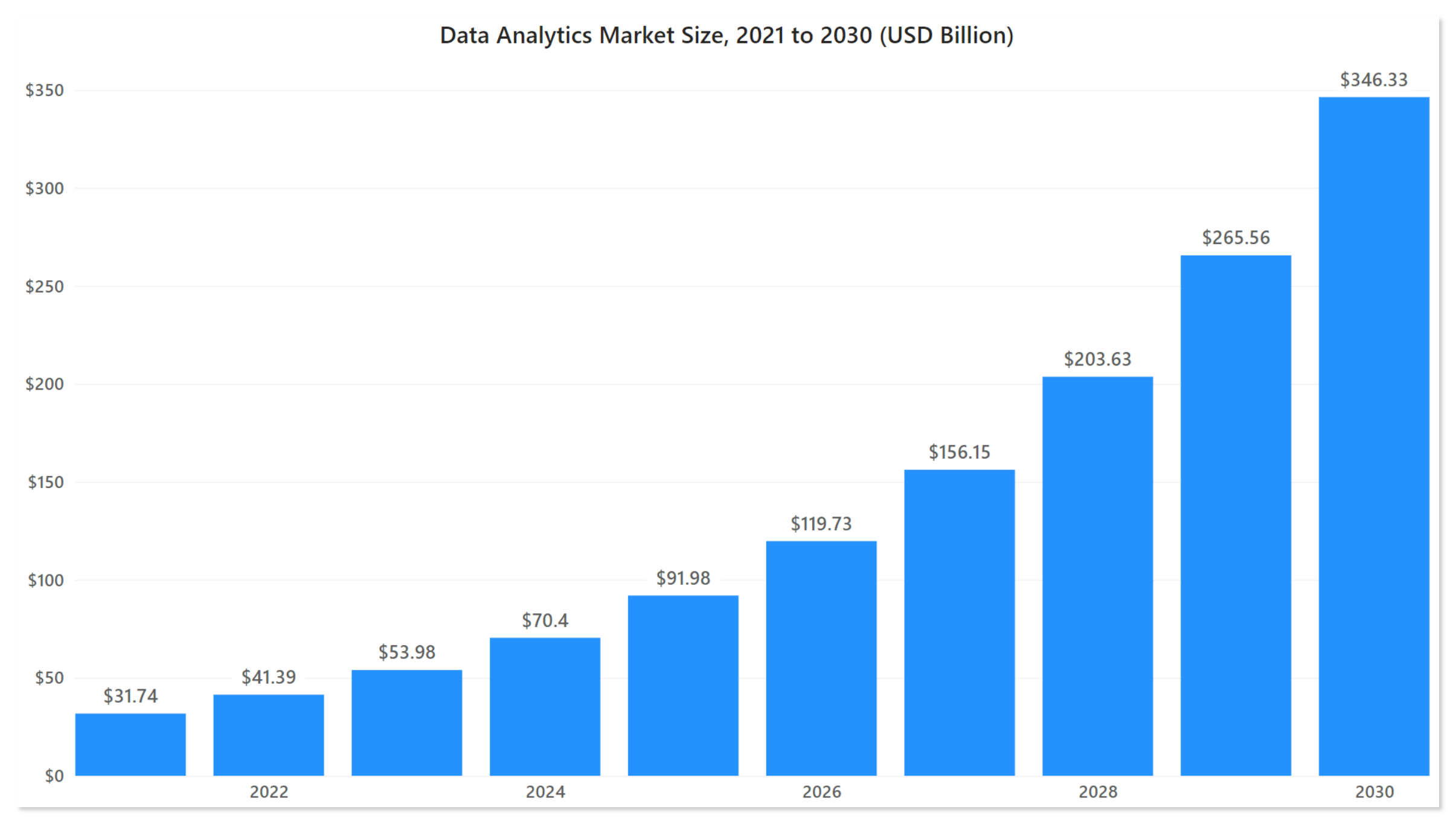
Web Scraping ist eine Technik zum Extrahieren von Daten aus Websites und anderen Quellen. In den letzten Jahren hat es vor allem in der Geschäftswelt eine weite Verbreitung gefunden. Wenn man genauer darüber nachdenkt, sind Daten derzeit das größte Kapital eines jeden Unternehmens. Der Datenanalysemarkt wird voraussichtlich mit einer jährlichen Wachstumsrate von 30,41 % wachsen, von 41,39 Milliarden US-Dollar im Jahr 2022 auf 346,33 Milliarden US-Dollar im Jahr 2030.
Aber trotz seiner weit verbreiteten Verwendung herrscht immer noch große Verwirrung über seine Legalität – ist Web Scraping schließlich legal oder illegal?
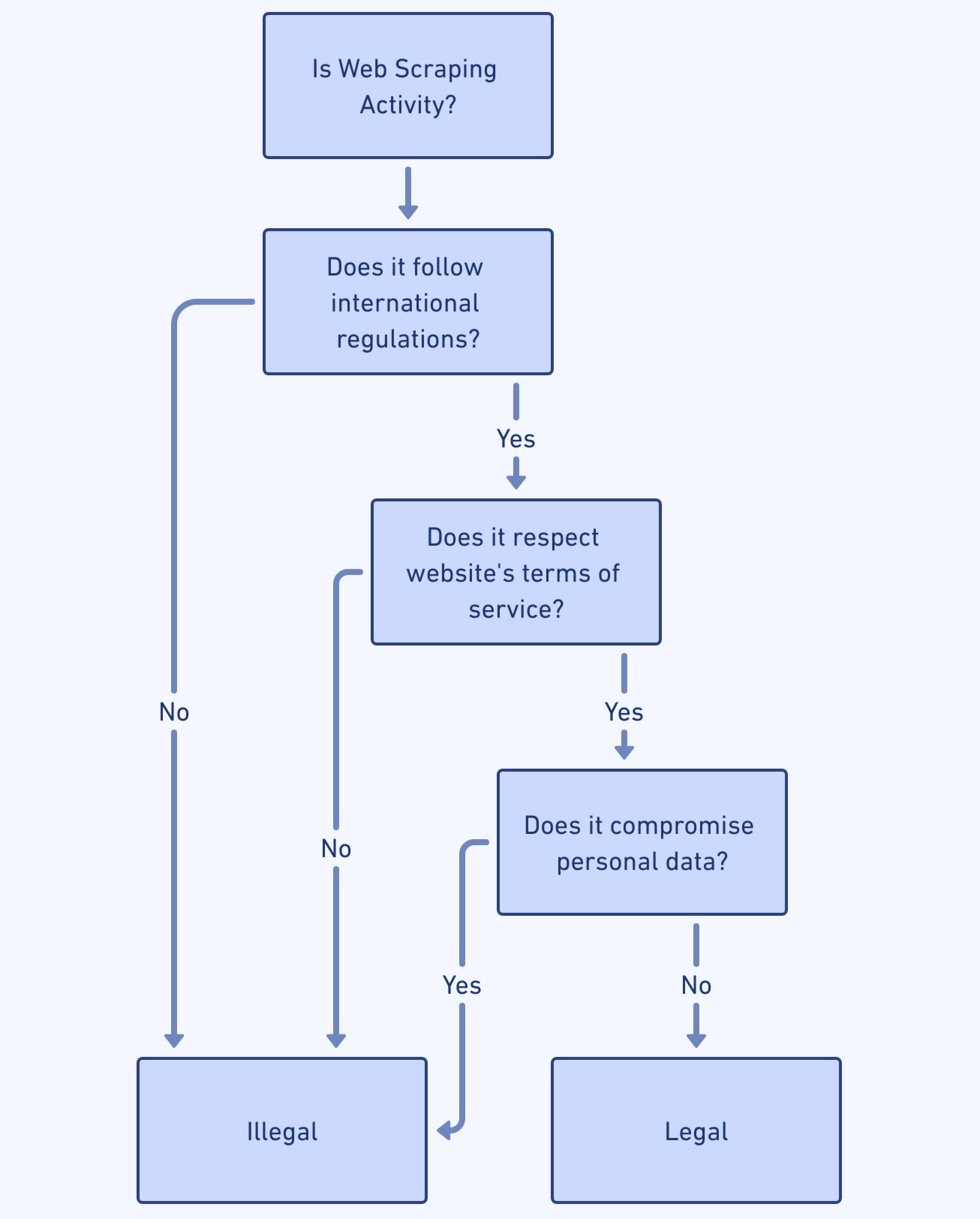
Entgegen der landläufigen Meinung ist Web Scraping selbst völlig legal und nicht grundsätzlich illegal. Dies bedeutet jedoch nicht, dass jede Art von Web Scraping legal ist; Wie bei allen menschlichen Aktivitäten müssen bestimmte Richtlinien eingehalten werden, um legal zu bleiben. Web-Scraper müssen die Bestimmungen zum Schutz personenbezogener Daten und des geistigen Eigentums sowie die Nutzungsbedingungen der Websites, auf die sie zugreifen, kennen.
Bitte beachten Sie: Obwohl wir bestrebt sind, genaue und aufschlussreiche Informationen bereitzustellen, erheben wir keinen Anspruch auf rechtliches Fachwissen. Für eine differenzierte Rechtsberatung, die auf Ihr spezifisches Projekt zugeschnitten ist, ist es immer ratsam, einen qualifizierten Anwalt in Ihrem Zuständigkeitsbereich zu konsultieren.
Ist Web Scraping legal?
Kurz gesagt, ja. Web Scraping gilt als legale Aktivität, solange dadurch die Sicherheit vertraulicher Informationen oder die Glaubwürdigkeit und das geistige Eigentum derjenigen, deren Daten erfasst werden, nicht gefährdet werden. Vorausgesetzt, dass öffentlich zugängliche Daten, die durch Web Scraping gewonnen werden, nur positiven Zwecken dienen, können sie als rechtlich zulässig angesehen werden.
Es ist wichtig zu verstehen, dass Web Scraping im Wesentlichen lediglich ein automatisiertes Tool ist, das dazu dient, manuelle Datenextraktionsprozesse zu reproduzieren. Das Tool an sich hat keine rechtliche Konnotation. Die rechtlichen Implikationen ergeben sich vielmehr aus der Anwendung und Nutzung.
Erkundung der Gesetze zum Scraping öffentlich zugänglicher personenbezogener Daten
In verschiedenen Regionen gelten unterschiedliche Regeln und Vorschriften für Web Scraping, insbesondere wenn es um personenbezogene Daten geht. Schauen wir uns die Besonderheiten dieser Gesetze nach Regionen an:
Europäische Union – Die DSGVO
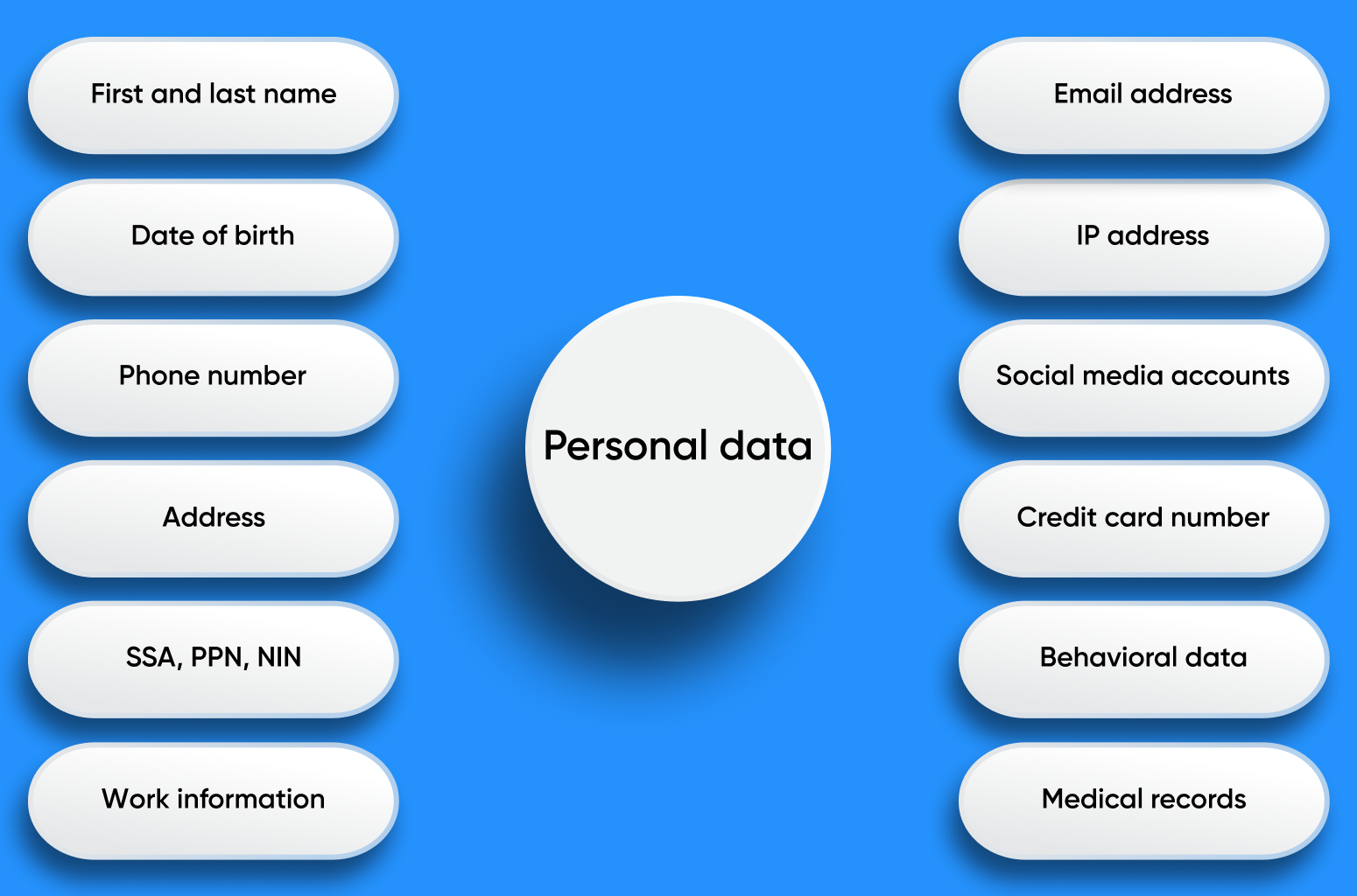
Die Datenschutz-Grundverordnung (DSGVO) ist eine Grundverordnung der Europäischen Union, die die Nutzung und den Schutz personenbezogener Daten regelt. Die DSGVO definiert personenbezogene Daten als „alle Informationen, die sich auf eine identifizierte oder identifizierbare natürliche Person beziehen“. Diese weit gefasste Definition legt nahe, dass selbst Informationsfragmente, wenn sie zusammengesetzt werden, zur Identifizierung einer bestimmten Person führen und somit als personenbezogene Daten eingestuft werden könnten.
Das US-Datenschutzgesetz und andere Vorschriften
In den Vereinigten Staaten gibt es kein einziges, übergreifendes Bundesgesetz zum Schutz der Privatsphäre. Stattdessen gibt es mehrere bundesstaatliche und branchenspezifische Gesetze, die sich mit verschiedenen Aspekten personenbezogener Daten, Web Scraping und Computerbetrug befassen.
-
California Consumer Privacy Act (CCPA): Dieses Gesetz regelt, wie Unternehmen weltweit mit den personenbezogenen Daten von Einwohnern Kaliforniens umgehen. Als personenbezogene Daten gelten Angaben, die eine Einzelperson oder einen Haushalt identifizieren, sich auf sie beziehen oder vernünftigerweise mit ihr in Verbindung gebracht werden können. Während das Gesetz ein breites Spektrum an Daten umfasst, schließt es öffentlich zugängliche Informationen wie Regierungsunterlagen aus. Mit der Einführung des California Privacy Rights Act (CPRA) wurden die Definitionen und Schutzmaßnahmen des CCPA verfeinert. Beispielsweise genießen Daten, die zuvor von einer Einzelperson veröffentlicht wurden, nicht mehr denselben Schutz, was bedeutet, dass Unternehmen personenbezogene Daten löschen können, allerdings nur innerhalb Kaliforniens.
-
Andere US-Bundesgesetze: Neben dem CCPA gibt es weitere wichtige Vorschriften wie den Health Insurance Portability and Accountability Act (HIPAA), der sich auf das Gesundheitswesen konzentriert, und den Gramm-Leach-Bliley Act von 1999 (GLBA), der sich auf Finanzen konzentriert.
Bei Web-Scraping-Aktivitäten, insbesondere wenn es um das Sammeln von Daten geht, ist die Annahme weit verbreitet, dass nur private personenbezogene Daten geschützt seien. Auch beim Auslesen öffentlicher Daten ist es wichtig, sich der regionalen Gesetzesnuancen bewusst zu sein. Das Ignorieren dieser Feinheiten kann zur Nichteinhaltung führen und möglicherweise rechtliche Konsequenzen nach sich ziehen.
So kratzen Sie Daten legal

Um Daten legal zu extrahieren, müssen Sie mehr tun, als nur das Gesetz zu befolgen. Es gibt verschiedene Arten von Vereinbarungen und Richtlinien, die Sie auch beim Online-Sammeln von Informationen befolgen sollten.
Nutzungsbedingungen
Eine Nutzungsbedingungen (TOU) ist eine vertragliche Vereinbarung zwischen einem Dienstanbieter und dem Benutzer, die darlegt, wie sie sich an die Nutzung der Website oder des Dienstes halten müssen. Für Websites ist es wichtig, die Verpflichtungen zwischen Benutzern und ihren Aktionen, Konten, Produkten und Technologien zu klären, da dies zum Schutz aller auf der Website gespeicherten persönlichen Daten beiträgt.
Vereinbarungen können auch Browsewrap und Clickwrap sein.
Browsewrap-Vereinbarungen werden erstellt, wenn Sie eine Website besuchen. Manchmal erscheinen sie unauffällig am unteren Bildschirmrand oder in einem Dropdown-Menü. In diesen Fällen sind sie in der Regel nicht rechtsverbindlich.
Clickwrap-Vereinbarungen erfordern, dass der Benutzer ein Kontrollkästchen aktiviert oder auf eine Schaltfläche klickt. Unter der Schaltfläche oder dem Kontrollkästchen finden Sie eine schriftliche Zustimmung zu den Allgemeinen Geschäftsbedingungen der Website. Sobald Sie zustimmen, werden die Allgemeinen Geschäftsbedingungen rechtsverbindlich.
Robots.txt-Datei
Heute ist robots.txt ein wichtiges Werkzeug für Website-Besitzer und -Entwickler und dient als Kommunikationsbrücke zwischen Menschen und hochentwickelten Computerprogrammen wie Webcrawlern oder Suchmaschinen-Bots. Robots.txt weist Webcrawler an, wie sie mit Websites interagieren sollen, und ermöglicht ihnen so tiefe Einblicke in die Struktur von Inhalten, etwa die Hierarchie von Webseiten und Dateiformattypen.
Die Regeln in Robots.txt müssen sorgfältig befolgt und auf legitimes Web Scraping überprüft werden. Wenn die Nutzungsbedingungen oder die Robots.txt-Datei das Scraping von Inhalten jedoch ausdrücklich verhindern, sollten Sie vor der Datenerfassung die Erlaubnis des Website-Eigentümers einholen.
Datenschutzrichtlinie
Diese Datenschutzrichtlinie ist das Dokument, das die Regeln für die Erfassung und Verarbeitung der persönlichen Daten der Benutzer auf der Website festlegt. Am besten lesen Sie die Datenschutzrichtlinie, bevor Sie die Website nutzen oder sich registrieren. Dort wird erläutert, welche Daten die Website erfasst, warum sie diese erfasst und wie sie verwendet werden.
Datennutzungsvereinbarung
Eine Datennutzungsvereinbarung (Data Use Agreement, DUA) ist ein Dokument, das in der Datenschutzrichtlinie erforderlich ist. Es wird zur Übertragung von Daten verwendet, die von gemeinnützigen, staatlichen oder privaten Organisationen entwickelt wurden, wenn die Daten nicht öffentlich verfügbar sind oder Nutzungsbeschränkungen unterliegen.
Ethik des Web Scraping
Manche Dinge können ethisch oder unethisch getan werden. Und Web Scraping ist eines dieser Dinge. Die Ethik der automatischen Datenerfassung zeigt sich unterschiedlich, je nachdem, in welcher Phase des Scraping-Prozesses Sie sich befinden.
Ohne die Etablierung ethischer Standards für Web Scraping kann es schwierig sein, zwischen böswilligen Web Scrapern, die plagiieren oder Profit schlagen wollen, und solchen, die Daten nutzen, ohne gegen das Gesetz zu verstoßen, Innovationen einzuführen und den Markt zu analysieren, zu unterscheiden.
Aus ethischer Sicht ist es nichts Falsches daran, Scraping für geschäftliche Zwecke einzusetzen, wenn man bedenkt, dass es für Web Scraping bereits viele Einsatzmöglichkeiten und professionelle Anbieter auf dem Markt gibt. Es gibt jedoch Regeln, die Sie befolgen müssen, wenn Sie Daten auf ethische Weise sammeln möchten.
Tatsächlich stellen Web Scraper eine wichtige Lösung für Benutzer dar, die Daten von Websites und Diensten benötigen, für die keine API verfügbar ist.
Best Practices für Web Scraping
Web Scraping ist ein unglaublich nützliches Tool zur Datenerfassung und -analyse, es muss jedoch verantwortungsvoll durchgeführt werden. Es ist wichtig, sich daran zu erinnern, dass das Web eine gemeinsame Ressource ist und es im Interesse aller liegt, sie respektvoll zu nutzen. Die folgenden Best Practices tragen dazu bei, sicherzustellen, dass Ihre Web-Scraping-Aktivitäten ethisch einwandfrei und gesetzeskonform sind.
Überlasten Sie die Zielwebsite nicht
Beim Scrapen von Daten von einer Website ist es wichtig, schrittweise vorzugehen. Durch die Begrenzung der Anzahl gleichzeitiger Anfragen wird sichergestellt, dass der Scraping-Prozess das Benutzererlebnis menschlicher Besucher nicht beeinträchtigt. Darüber hinaus stellt die sorgfältige Beobachtung von Verzögerungen zwischen Anfragen sicher, dass eine gecrackte Site für alle Parteien offen und zugänglich bleibt. Wenn aggressives Scraping durchgeführt wird, kann es zu Funktionsproblemen kommen, die sowohl das Benutzererlebnis beeinträchtigen als auch möglicherweise DoS-Angriffe (Denial of Service) auslösen, die zum Absturz der Website führen und deren Inhalte für andere unzugänglich machen. Wenn Sie es langsam angehen und auf die Zeiten mit der geringsten Aktivität auf der Website achten, können Sie solche negativen Auswirkungen proaktiv verhindern.
Respektieren Sie Urheberrechte
Sämtliche im Internet erfassten Daten gehören nicht Ihnen. Stellen Sie beim Scrapen der Website sicher, dass Sie keine urheberrechtlich geschützten Daten sammeln. Weitere Informationen zu Urheberrechtsfragen finden Sie am besten in den Allgemeinen Geschäftsbedingungen der Website und in der Datenschutzrichtlinie.
Scrapen Sie nur die Daten, die Sie benötigen
Sammeln Sie nur die Informationen, die Sie wirklich benötigen und für Ihre Arbeit verwenden werden. Dadurch wird das Risiko einer Überlastung der geschabten Site mit unerwünschtem Verkehr minimiert. Außerdem erhalten Sie nur die Daten, die Sie nutzen, und speichern keine nutzlosen Inhalte in Datenbanken.
Höflich sein
Vor dem Scrapen lohnt es sich, höflich zu sein und zu fragen, ob Sie diese Daten sammeln dürfen.
Sie können den Web Scraper anhand der legitimen Agentenzeichenfolge des Benutzers identifizieren. Auf diese Weise erscheint ein User-Agent, der die Websitebesitzer über Ihre Aktivität, ihren Zweck und ihre Organisation informiert. So zeigen Sie Respekt gegenüber dem Websitebesitzer.
Verwenden Sie spezielle Web-Scraping-Tools
Wenn Sie viele Daten sammeln, kann es nahezu unmöglich sein, die Standards jeder Site einzeln zu überprüfen. Es lohnt sich, ein spezielles Tool wie die Web-Scraping-API zu verwenden, um Ärger zu vermeiden. Sie können sich auch an unsere Spezialisten wenden, die sich um die korrekte Informationsextraktion kümmern und einen Daten-Scraper speziell für Ihre Zwecke entwickeln.
Abschluss
Wir hoffen, dass Sie nach der Lektüre dieses Artikels einen kleinen Einblick in die Legalität des Scrapings erhalten haben. Web Scraping ist beispielsweise legal, wenn Sie Daten von Websites für die öffentliche Nutzung oder wissenschaftliche Forschung sammeln.
Web Scraping ist illegal, wenn Sie vertrauliche Informationen aus Profitgründen abgreifen, indem Sie beispielsweise ohne Erlaubnis persönliche Informationen sammeln und diese an Dritte verkaufen. Es ist ebenfalls unethisch, gelöschte Inhalte als Ihre eigenen auszugeben.
Ein wichtiger zu berücksichtigender Aspekt ist das Scrapen personenbezogener Daten. Auch wenn die Daten öffentlich zugänglich sind, kann das Auslesen personenbezogener Daten ohne ausdrückliche Zustimmung oder für böswillige Zwecke zu rechtlichen Komplikationen und ethischen Dilemmata führen. Es ist von entscheidender Bedeutung, solche Aktivitäten mit Vorsicht und Respekt für die Privatsphäre des Einzelnen anzugehen.
Web Scraping hat eine große Zukunft als wertvolles und ethisches Werkzeug zum Sammeln von Informationen und sogar zum Generieren neuer Informationen online. Indem Sie die Nutzungsbedingungen anderer Websites respektieren, die Gesetze befolgen und beim Scraping einen ethischen Ansatz verfolgen, werden Sie keine Probleme mit Websitebesitzern haben.
