
PHP ist eine weit verbreitete Backend-Sprache. Von vielen gehasst und für viele Anwendungen wie WordPress verwendet. Wenn man über Web Scraping nachdenkt, kommt einem jedoch nicht als Erstes PHP in den Sinn.
Da Tools wie Scrapy für Python oder Cheerio für Node.js das Web-Scraping vereinfachen, ist es schwer vorstellbar, warum man PHP zum Scrapen von Daten verwenden sollte. Bis Sie all die verschiedenen Möglichkeiten kennengelernt haben, die Sie damit haben.
Da es eine aktive Community hat und es schon so lange gibt, verfügt PHP über viele Tools, die Web Scraping nicht nur einfacher, sondern auch leistungsfähiger machen.
Wenn Sie PHP bereits beherrschen oder daran interessiert sind, eine Backend-Sprache mit der Möglichkeit zu erlernen, Webdaten schnell und effizient zu extrahieren, dann ist dieses Tutorial genau das Richtige für Sie.
Heute werden wir einige der Tools erkunden, die Ihnen zur Verfügung stehen, und ein reales Codebeispiel erstellen, um Ihren ersten Web-Scraper mit PHP zu erstellen.
Auswahl einer PHP-Web-Scraping-Bibliothek
Es gibt viele Möglichkeiten, Web Scraping in PHP durchzuführen. Am effizientesten ist es jedoch, eine Bibliothek zu verwenden, die alle Tools integriert hat, die Sie zum Herunterladen und Analysieren von URLs benötigen.
Andernfalls müssten wir mehr Zeit aufwenden und komplexeren Code schreiben, um einfache Aufgaben wie das Senden einer HTTP-Anfrage zu erledigen.
Wenn wir Web Scraping in seine Kernaufgaben aufteilen würden, sähe es so aus:
- Zuerst würden wir eine HTTP-Anfrage an einen Server senden, um den Quellcode der Seite zu erhalten.
- Dann müssten wir das DOM analysieren, um die Informationen zu identifizieren und zu filtern und die benötigten Daten zu extrahieren.
- Schließlich möchten wir die Daten formatieren, um sie verständlicher zu machen – etwa in eine CSV- oder JSON-Datei.
Nur für die HTTP-Anfrage könnten wir verschiedene Methoden verwenden, wie zum Beispiel:
- fsockopen() – wird zwar nicht für HTTP-Anfragen verwendet, ist aber durchaus möglich. Natürlich würde es eine Menge unnötigen Code erfordern, den wir eigentlich nicht schreiben wollen.
- cURL – ein Client für URLs, mit dem Sie problemlos HTTP-Anfragen ausführen können, der jedoch nicht sehr hilfreich ist, um in der HTML-Datei zu navigieren und die gesuchten Daten zu extrahieren.
- Verwendung eines HTTP-Clients wie Guzzle oder Goutte – was auch das Parsen des HTML-DOM-Baums einfacher machen würde als die vorherigen Optionen.
Wie Sie sehen, handelt es sich bei den letzten beiden um ein gebrauchsfertiges Tool für Web Scraping mit PHP.
Warum Goutte für PHP Web Scraping verwenden?
Sie wissen bereits, dass wir für dieses Beispiel Goutte verwenden werden – Spoiler zum Titel –, aber wissen Sie warum?
Guzzle ist definitiv eine großartige Option für Web Scraping. Es vereinfacht die Erstellung der HTTP-Anfrage und bietet die Möglichkeit, die heruntergeladene Datei zu analysieren, um Daten zu extrahieren.
Das Problem besteht darin, dass wir dazu die heruntergeladene HTML-Datei in ein DOM-Dokument umwandeln und dann XPath-Ausdrücke verwenden müssten, um durch das Dokument zu navigieren und die Knoten auszuwählen, die wir erhalten möchten.
Diese fügen zusätzliche Schritte hinzu, die wir stattdessen problemlos mit Goutte bewältigen können.
Goutte ist ein HTTP-Client, der für Web-Scraping entwickelt wurde von Fabian PotencierSchöpfer des Symfony-Frameworks.
Diese Bibliothek kombiniert vier Symfony-Komponenten, die Web Scraping sehr einfach und elegant machen:
- Das BrowserKit – das das Verhalten eines Browsers simuliert.
- Der DomCrawler – diese Komponente ermöglicht es uns, mit Ausdrücken wie im DOM-Dokument zu navigieren
$crawler = $crawler->filter('body > h2');und viele andere Methoden. - Der CssSelector – diese Komponente macht die Auswahl von Elementen sehr einfach, indem sie es uns ermöglicht, mithilfe von CSS-Selektoren ein Element auszuwählen und es dann für uns in den entsprechenden XPath-Ausdruck umzuwandeln. Zum Beispiel dieser Ausschnitt
$crawler->filter('.fire');findet alle Elemente mitclass="fire". - Der Symfony HTTP Client – dies ist die neueste Komponente und erfreut sich seit ihrer Einführung im Jahr 2019 großer Beliebtheit.
Aus diesen Gründen verwenden wir für den Rest dieses Tutorials Goutte.
Notiz: Wir werden in Zukunft ein Guzzle-Tutorial veröffentlichen, also bleiben Sie auf dem Laufenden über unseren Blog und soziale Medien.
Erstellen eines Web Scrapers mit PHP und Goutte
Bevor wir tatsächlich mit dem Schreiben unseres Codes beginnen können, ist es wichtig, die Struktur der Site zu verstehen, die wir durchsuchen möchten.
Für dieses Tutorial durchsuchen wir die T-Shirt-Seite für Frauen von NewChic, um Folgendes zu extrahieren:
- Name des T-Shirts
- Link zum Stück
- Preis
Ein solcher Scraper kann für E-Commerce-Unternehmen verwendet werden, die eine Wettbewerbsanalyse durchführen möchten.
Beginnen wir mit der Inspektion der Seite.
1. Überprüfen Sie die Seite mit den Browser-Entwicklungstools
Klicken Sie auf unserer Zielwebsite mit der rechten Maustaste auf die Seite und klicken Sie auf „Inspizieren“. Alternativ können Sie auch Strg + Umschalt + C drücken.
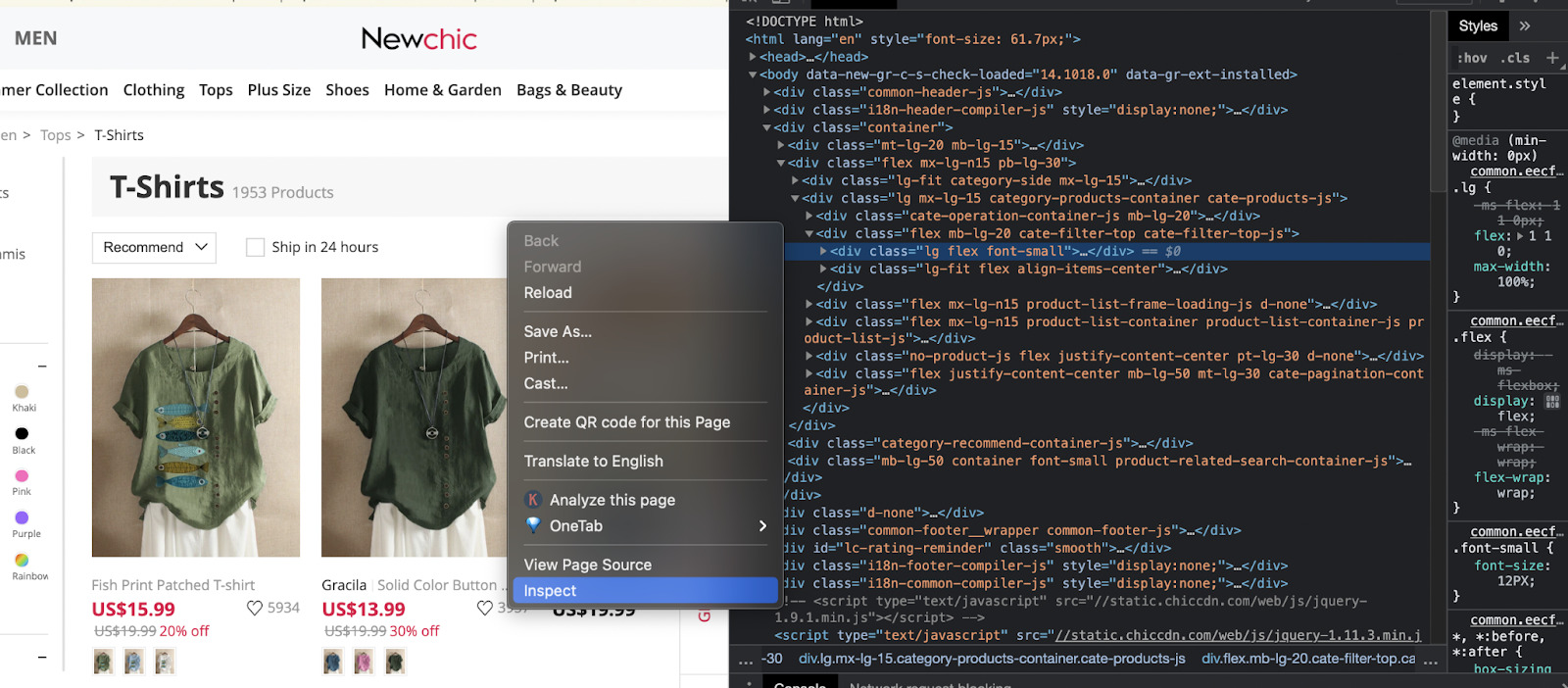
Das Inspektortool wird in Ihrem Browser geöffnet.
Was wir im HTML-Code sehen, den unser Browser zum Anzeigen der Seite verwendet. Jede Zeile enthält Informationen zu einem Element auf der Seite.
Was uns wirklich wichtig ist, sind die Tags, Klassen und IDs für jedes Element, da dies die Details sind, die wir verwenden, damit unser Scraper die benötigten Informationen findet.
Beginnen wir also mit dem Titel des Tuchs. Klicken Sie dazu mit der rechten Maustaste auf das Element und prüfen Sie es.

Wir können sehen, dass der Name des T-Shirts dazwischen eingewickelt ist Tags im Inneren Tags.
Allerdings ist es sicherlich nicht der einzige Link auf der Seite. Wenn wir nur das Tag des Elements verwenden, würden wir alle Links von der Seite abrufen, einschließlich Navigationslinks, Fußzeilenlinks und alles andere.
Hier kommen Klassen ins Spiel.
Für den Namen des T-Shirts gilt: Tag hat die Klasse „lg text-ellipsis d-block text-hover-underline text-secondary-hover font-small-12 text-grey product-item-name-js„. Daher möchten wir sicherstellen, dass alle anderen Elemente dieselbe Klasse verwenden.

Nach einigen weiteren Überprüfungen verwenden sie alle dieselbe Klasse, was für uns perfekt ist, da wir sie dann zur Auswahl unserer Titel und des Links verwenden können.
Notiz: Wir werden untersuchen, wie man das href-Attribut eines extrahiert später markieren.
Als nächstes machen wir für jedes Element dasselbe:
- Für den Preis:
span class="product-item-final-price-js price product-price-js font-middle font-bold text-black-light-1„
- Für den Link: Wir verwenden dasselbe wie für den Titel, aber anstatt den Text abzurufen, ziehen wir den href-Wert.
2. Installieren Sie PHP und alle notwendigen Abhängigkeiten
Bevor wir eine Datei herunterladen, prüfen wir zunächst, ob bereits eine PHP-Version installiert ist. Geben Sie in Ihr Terminal ein php -v.

Dies ist die Benachrichtigung, die wir erhalten, weil wir ein M1-Macbook verwenden. Wichtig ist, dass wir Version 7.3.24 von PHP haben.
Wenn Sie es nicht installiert haben, befolgen Sie diese Schritte, um PHP auf Ihrem Mac zu installieren:
- Gehen Sie zu https://brew.sh/ und installieren Sie Homebrew. Es handelt sich um einen fehlenden Paketmanager für macOS
- Nachdem Homebrew installiert ist, können Sie PHP mit dem folgenden Befehl installieren: brew install php – Vor dem Start des Downloads werden Sie nach dem Passwort Ihres Rechners gefragt.
Sie können auch diesem einfachen Video zur Installation von PHP 8 in macOS Big Sur folgen.
Notiz: Hier ist eine Ressource, die erklärt, wie man PHP unter Windows installiert.
Composer global installieren
Jetzt, da PHP auf unserem Rechner ist, wir werden herunterladen Komponist (ein PHP-Paketmanager, den wir zum Herunterladen von Goutte verwenden werden), indem Sie der Dokumentation folgen.
- Öffnen Sie Ihr Terminal auf Ihrem Desktop (CD-Desktop) und schreiben Sie
php -r "copy('https://getcomposer.org/installer', 'composer-setup.php');". Eine Datei mit dem Namen „composer-setup.php“ befindet sich jetzt auf Ihrem Desktop.
- Als nächstes kopieren Sie den folgenden Befehl und fügen ihn ein:

php -r "if (hash_file('sha384', 'composer-setup.php') === '756890a4488ce9024fc62c56153228907f1545c228516cbf63f885e036d37e9a59d27d63f46af1d4d07ee0f76181c7d3') { echo 'Installer verified'; } else { echo 'Installer corrupt'; unlink('composer-setup.php'); } echo PHP_EOL;"
Dadurch wird überprüft, ob die Setup-Datei korrekt heruntergeladen wurde.

- Nachdem wir die Datei überprüft haben, führen wir das Skript mit php Composer-Setup.php aus. Dieser Befehl lädt den eigentlichen Composer herunter und installiert ihn.

- Wenn wir an dieser Stelle aufhören, können wir den Composer nur noch vom Desktop aus aufrufen, was wir nicht wollen. Um es auf unseren Pfad zu verschieben, verwenden wir den Befehl
mv composer.phar /usr/local/bin/composer.


Hoppla! Wir hatten ein kleines Problem mit unserem Kommando. Aber keine Sorge, wir müssen nur sudo in unserem Befehl verwenden, dann sieht es so aus:
sudo mv composer.phar /usr/local/bin/composer
Es fragt nach unserem Passwort und verschiebt die Datei dann in das angegebene Verzeichnis.
- Um den Vorgang abzuschließen, rufen wir Composer auf, um zu überprüfen, ob es ordnungsgemäß funktioniert, indem wir „composer“ in das Terminal eingeben. Es sollte die ausführbare Datei aufrufen und die folgende Meldung anzeigen.


Wenn es nicht funktioniert, gehen Sie zu Ihrem Finder und klicken Sie shift+command+Gund geben Sie die ein usr/local/bin/ path in das Popup.
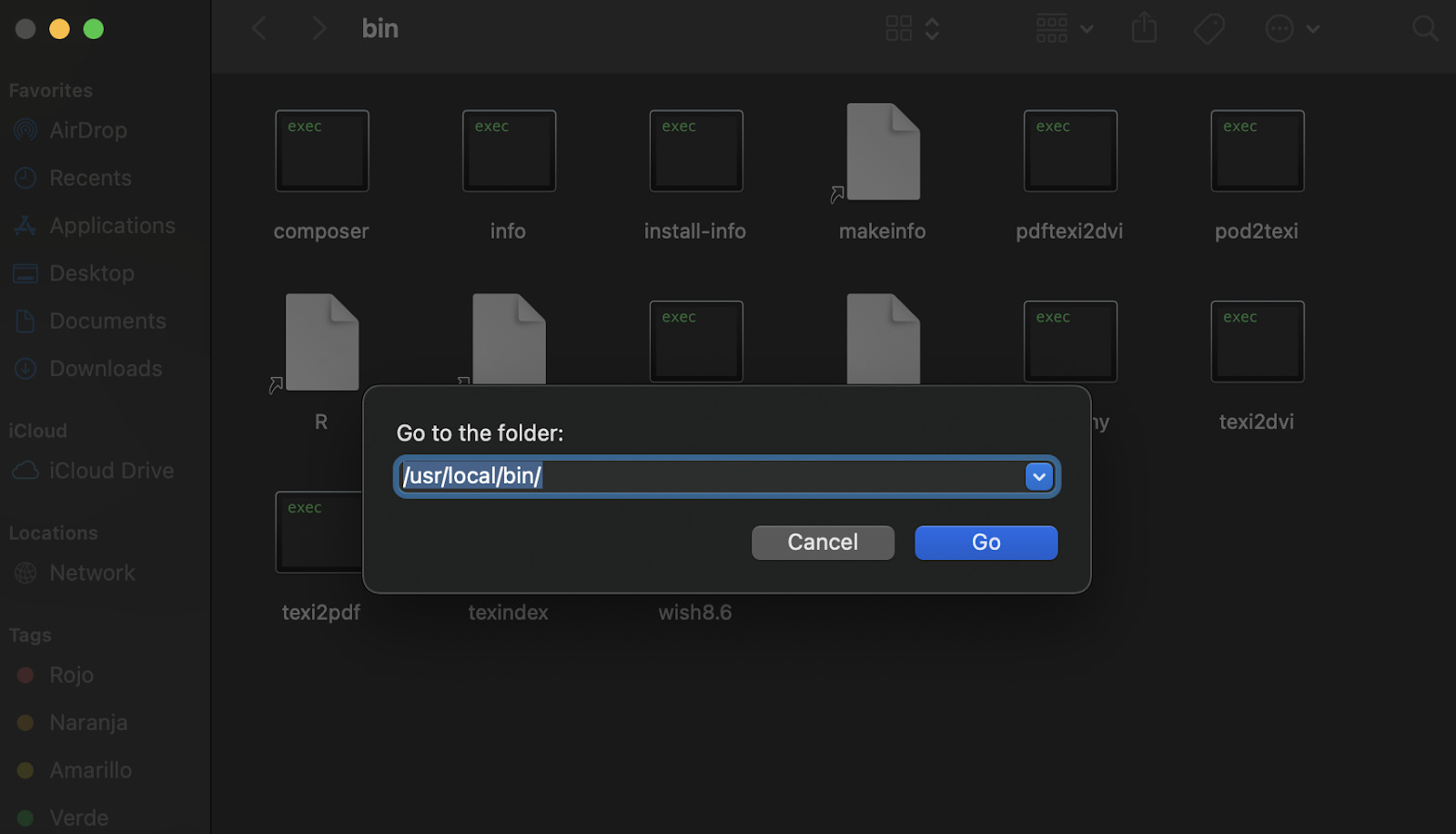
Mir ist aufgefallen, dass unsere Datei „composer.phar“ jetzt „composer“ heißt und eine ausführbare Datei ist. Wenn Sie feststellen, dass es sich immer noch um eine .phar-Datei handelt, ändern Sie einfach den Namen und Sie können den Composer-Befehl verwenden.
Notiz: Nachdem dies erledigt ist, können Sie das Installationsprogramm mit dem folgenden Befehl löschen php -r "unlink('composer-setup.php');".
Installation von Guzzle und Goutte
Der Grund, warum wir Guzzle installieren, ist, dass Goutte es benötigt, um ordnungsgemäß zu funktionieren.
Laufen composer require guzzlehttp/guzzle in Ihrem Terminal, um Guzzle zu installieren und composer require fabpot/goutte Goutte installieren bzw. installieren.
Es dauert ein paar Sekunden und dann können wir mit dem Schreiben unseres Scrapers beginnen.
3. Entfernen Sie alle Titel von der Seite
Wir werden Visual Studio Code verwenden, aber Sie können mit Ihrem bevorzugten Texteditor weitermachen.
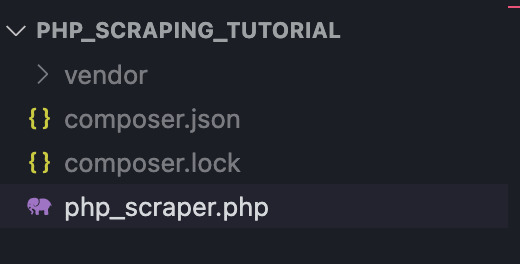
Erstellen wir einen Ordner mit dem Namen „php_scraper_tutorial“ und rufen ihn in Visual Studio auf. Öffnen Sie dann ein neues Terminal und installieren Sie Goutte darin composer require fabpot/goutte.
Es werden ein neuer Ordner namens „vendor“ und zwei Dateien („composer.json“ und „composer.lock“) hinzugefügt. Wenn diese fertig sind, erstellen Sie eine neue Datei mit dem Namen „php_scraper.php“. Ihr Ordner sollte etwa so aussehen:
require 'vendor/autoload.php';
use Goutte\Client;
$client = new Client();
Das automatische Laden von PHP lädt jede Bibliothek, die wir benötigen, automatisch, was uns viel Zeit und Kopfschmerzen erspart. Dann öffnen wir einen neuen Goutte-Client, über den wir die Anfrage senden.
Dazu erstellen wir eine neue Instanz mit dem Namen „$crawler“ und geben an, dass sie die Anfrage an die Seite von Newchic sendet und dabei die Methode angibt – in unserem Fall GET – vor der URL.
$crawler = $client->request('GET', 'https://www.newchic.com/women-t-shirts-c-3666/?mg_id=1&from=nav&country=223&NA=1')
Aber wir wollen doch nicht nur den HTML-Code, oder?
Nachdem wir die Antwort erhalten haben, möchten wir die zuvor identifizierte CSS-Klasse verwenden, um nur die Namen der einzelnen T-Shirts zu extrahieren. Das ist der Zeitpunkt filter() kommt, um den Tag zu retten.
$crawler->filter('.lg text-ellipsis d-block text-hover-underline text-s;econdary-hover font-small-12 text-grey product-item-name-js')->each(function($node){
var_dump($node->text());
});
Unser Skript wird alles filtern Elemente, die der von uns angegebenen Klasse entsprechen, und durchlaufen jeden der Knoten (da wir beim Extrahieren aller Elemente mehr als einen haben).
Nach der Ausführung des Skripts erhalten wir jedoch tatsächlich einen schwerwiegenden Fehler und es wird nichts zurückgegeben.
Dies kommt beim Web Scraping (und übrigens in jeder Entwicklungsumgebung) sehr häufig vor und das Wichtigste ist, sich nicht entmutigen zu lassen.
Nach vielen Versuchen haben wir die Chrome-Erweiterung SelectorGadget verwendet, um den richtigen CSS-Selektor zu erhalten.
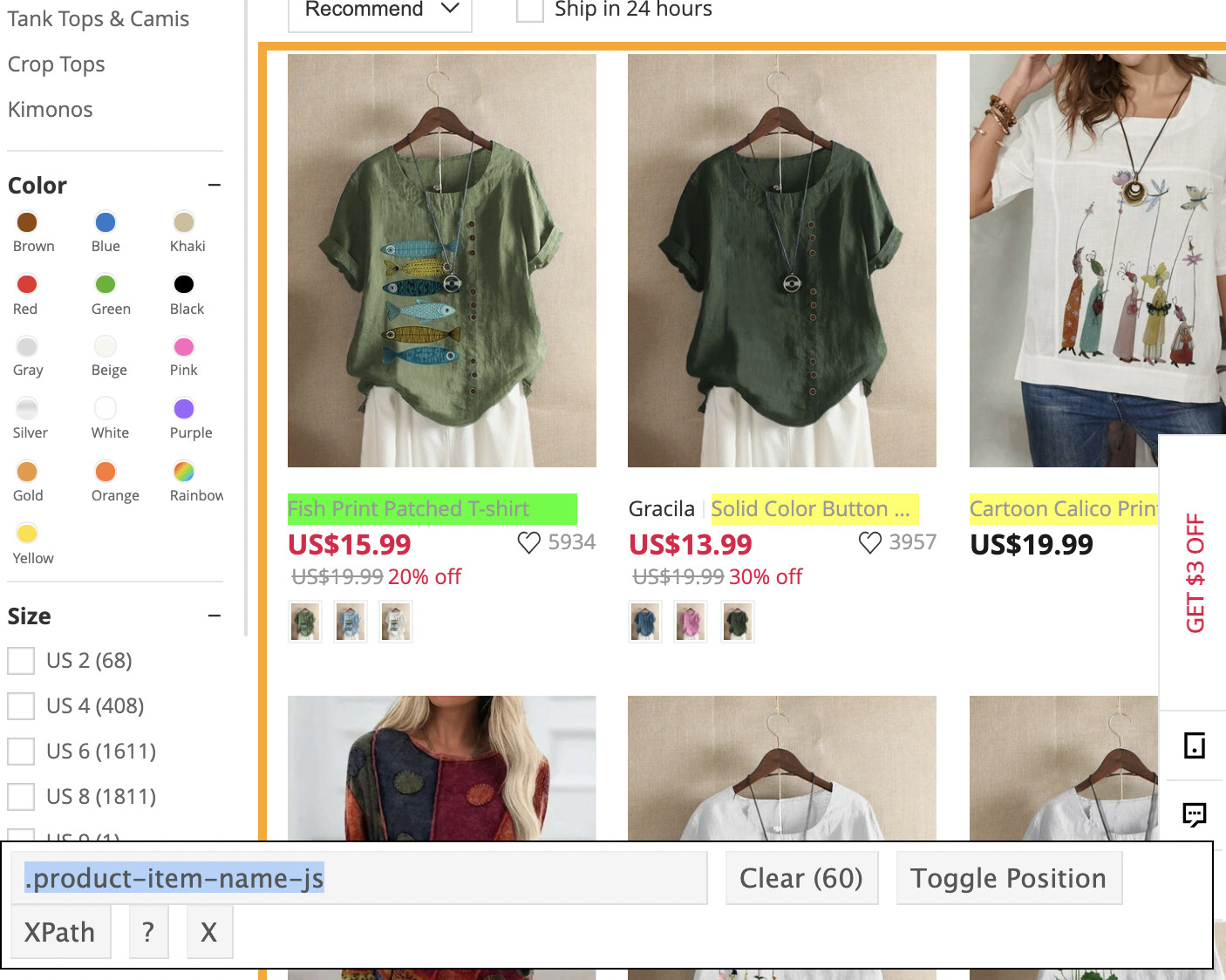
Anscheinend bestand das Problem darin, dass unser Skript die Klasse, nach der es suchen sollte, nicht finden konnte. Es stürzte also mitten in der Operation ab.
Nach dem Aktualisieren des Codes:
$crawler->filter('.product-item-name-js')->each(function($node){
var_dump($node->text());
});
Wir konnten den Code ausführen und die 60 Produktnamen auf der Seite abrufen:

Warte… Spanisch? Was ist gerade passiert?
Auf der Website von Newchic werden je nach Standort unterschiedliche Inhalte angezeigt (wie bei Amazon). Da die IP-Adresse, von der aus wir die Anfrage senden, aus einem lateinamerikanischen Land stammt, antwortet die Website mit der spanischen Version der Seite.
Um dies zu umgehen, müssen wir unsere IP-Adresse ändern.
4. Integrieren Sie die Scraper-API mit PHP für Geotargeting
Scraper API ist eine Lösung, die Proxys von Drittanbietern, KI und jahrelange statistische Daten kombiniert, um zu verhindern, dass unsere Scraper durch CAPTCHAs, Verbote und andere Anti-Scraping-Techniken blockiert werden.
Darüber hinaus können wir über die API JavaScript ausführen (wofür wir einen Headless-Browser verwenden müssten) und auf geospezifische Daten zugreifen.
Erstellen wir zunächst ein kostenloses Scraper-API-Konto, um Zugriff auf 5000 kostenlose API-Credits (pro Monat) und unseren API-Schlüssel zu erhalten.
Sobald wir uns in unserem Dashboard befinden, verwenden wir das cURL-Beispiel, um die URL zu erstellen, die wir für unser Skript verwenden.

$crawler = $client->request('GET', 'http://api.scraperapi.com?api_key=51e43be283e4db2a5afb6266xxxxxxxx&url=https://www.newchic.com/women-t-shirts-c-3666/?mg_id=1&from=nav&country=223&NA=1&country_code=us');
Der country_code Der Parameter weist die Scraper-API an, die Anfrage von einem US-Proxy zu senden.
Wenn wir jetzt unser Skript ausführen, sehen wir, dass der zurückgegebene Inhalt jetzt auf Englisch ist und den US-Benutzern in ihren Browsern angezeigt wird.

Eine vollständige Liste der verfügbaren Ländercodes und mehr finden Sie in unserer ausführlichen Dokumentation.
Notiz: Wenn Sie Zugriffsdaten von einer Website erhalten möchten, die die Ausführung von JavaScript erfordert, legen Sie sie einfach fest render=trueund denken Sie daran, dass jeder Parameter durch ein & getrennt ist.
5. Entfernen Sie mehrere Elemente von einer Webseite
In diesem Abschnitt mischen wir die Dinge ein wenig. Wir möchten für jedes der Elemente, die wir erfassen möchten, eine andere Variable erstellen.
Ändern wir zunächst den ersten Filter, damit unser PHP-Scraper nach dem Element sucht, das den Namen, den Preis und den Link umschließt.
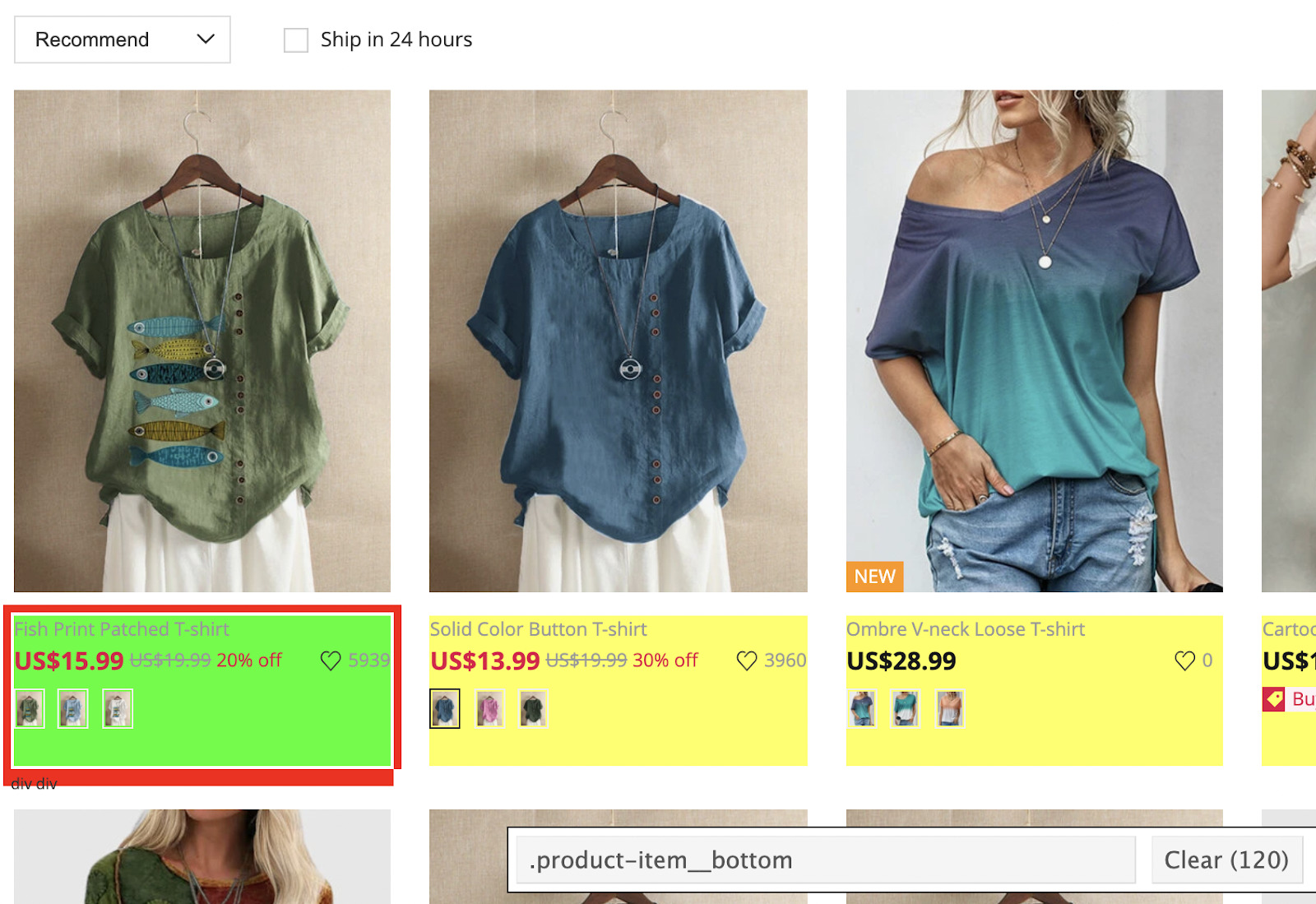
Wir erstellen für jedes Element neue Variablen und verwenden die Funktion filter(), um das Element innerhalb des $node zu finden.
crawler->filter('.product-item__bottom')->each(function($node){
$name = $node->filter('.product-item-name-js')->text();
$price = $node->filter('.product-price-js')->text();
Für den Preis und den Namen möchten wir den Text übernehmen, aber das ist beim Link nicht der Fall. Um den Wert innerhalb des href-Attributs abzurufen, verwenden wir die Methode attr('href'). Um sicherzustellen, dass die richtige Zeile gefunden wird, haben wir das Tag a in den CSS-Selektor eingefügt.
$link = $node->filter('a.product-item-name-js')->attr('href');
Nach der Aktualisierung unserer Datei sollte diese so aussehen:
include 'vendor/autoload.php';
use Goutte\Client;
$client = new Client();
$crawler = $client->request('GET', 'http://api.scraperapi.com?api_key=51e43be283e4db2a5afb62660fc6ee44&url=https://www.newchic.com/women-t-shirts-c-3666/?mg_id=1&from=nav&country=223&NA=1&country_code=us');
$crawler->filter('.product-item__bottom')->each(function($node){
$name = $node->filter('.product-item-name-js')->text();
$price = $node->filter('.product-price-js')->text();
$link = $node->filter('a.product-item-name-js')->attr('href');
});
Zusammenfassung
Glückwunsch! Sie haben gerade Ihren ersten PHP-Web-Scraper mit Goutte erstellt. Natürlich gibt es noch viel zu lernen.
Wir beenden dieses Tutorial an dieser Stelle vorerst, da es sich um eine Einführung in das Web-Scraping mit PHP handelt.
In zukünftigen Tutorials werden wir unsere Scraper-Funktionen erweitern, sodass er Links folgen kann, um mehrere Seiten aus einem Skript zu scrapen und unsere gescrapten Daten in eine CSV-Datei umzuwandeln, die wir für weitere Analysen verwenden können.
Wenn Sie mehr über Web Scraping erfahren möchten, werfen Sie einen Blick auf unsere Tipps für große Scraping-Projekte.
Weitere Informationen zur Verwendung der Scraper-API finden Sie im Scraper-API-Spickzettel und auf der Seite mit Best Practices für Scraping. Sie werden die größten Herausforderungen verstehen, mit denen jeder Web Scraper konfrontiert ist, und erfahren, wie Sie diese mit einem einfachen API-Aufruf lösen können.
Viel Spaß beim Schaben!
