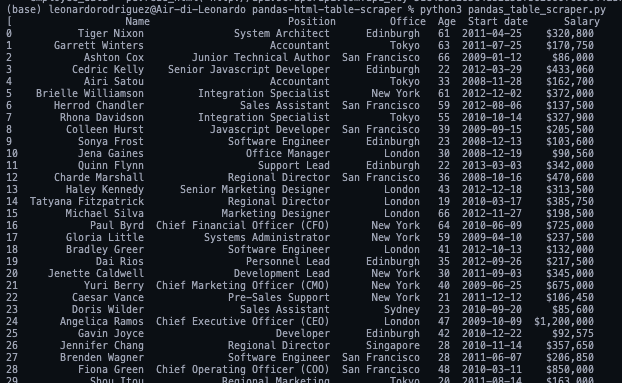
Versuchen wir zunächst, den Namen des ersten Mitarbeiters in der Konsole unseres Browsers mithilfe der Methode .querySelectorAll() auszuwählen. Ein wirklich nützliches Merkmal dieser Methode besteht darin, dass wir immer tiefer in die Hierarchie vordringen können, indem wir das Größer-als-Symbol (>) implementieren, um das übergeordnete Element (links) und das untergeordnete Element, das wir greifen möchten (rechts), zu definieren.
document.querySelectorAll('table.stripe > tbody > tr > td')(0)
Das könnte nicht besser funktionieren. Wie Sie sehen, schnappen wir uns erst einmal alle
Von dort aus können wir unseren Code wie folgt schreiben:
for row in rows:
name = row.find_all('td')(0).text
print(name)
Vereinfacht ausgedrückt nehmen wir jede Zeile einzeln und suchen alle darin enthaltenen Zellen. Sobald wir die Liste haben, greifen wir nur auf die erste im Index (Position 0) und schließen mit der .text-Methode ab Greifen Sie auf den Text des Elements zu und ignorieren Sie die HTML-Daten, die wir nicht benötigen.
Da ist sie, eine Liste mit allen Namen der Mitarbeiter! Im Übrigen folgen wir einfach der gleichen Logik:
position = row.find_all('td')(1).text
office = row.find_all('td')(2).text
age = row.find_all('td')(3).text
start_date = row.find_all('td')(4).text
salary = row.find_all('td')(5).text
Allerdings ist es nicht besonders hilfreich, all diese Daten auf unserer Konsole ausgedruckt zu haben. Speichern wir diese Daten stattdessen in einem neuen, nützlicheren Format.
5. Speichern tabellarischer Daten in einer JSON-Datei
Obwohl wir problemlos eine CSV-Datei erstellen und unsere Daten dorthin senden könnten, wäre das nicht das am besten zu handhabende Format, wenn wir mit den gescrapten Daten etwas Neues erstellen könnten.
Dennoch ist hier ein Projekt, das wir vor ein paar Monaten durchgeführt haben und das erklärt, wie man eine CSV-Datei zum Speichern von Scraped-Daten erstellt.
Die gute Nachricht ist, dass Python über ein eigenes JSON-Modul für die Arbeit mit JSON-Objekten verfügt, sodass wir nichts installieren müssen, sondern es einfach importieren müssen.
Aber bevor wir mit der Erstellung unserer JSON-Datei fortfahren können, müssen wir all diese gescrapten Daten in eine Liste umwandeln. Dazu erstellen wir ein leeres Array außerhalb unserer Schleife.
Und dann hängen Sie die Daten daran an, wobei jede Schleife ein neues Objekt an das Array anhängt.
employee_list.append({
'Name': name,
'Position': position,
'Office': office,
'Age': age,
'Start date': start_date,
'salary': salary
})
Wenn wir print(employee_list)hier ist das Ergebnis:
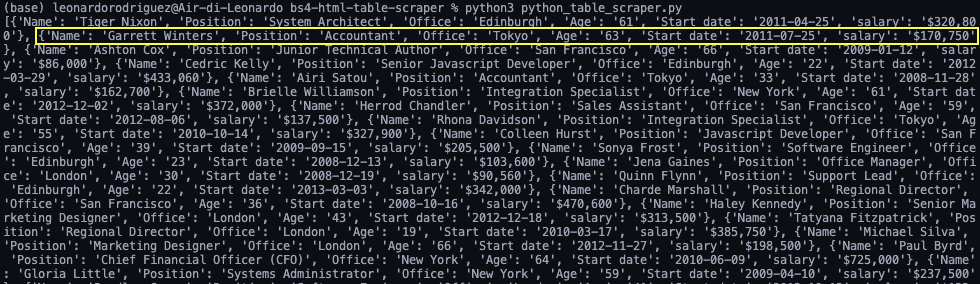
Immer noch etwas chaotisch, aber wir haben eine Reihe von Objekten, die bereit sind, in JSON umgewandelt zu werden.
Notiz: Als Test haben wir die Länge ausgedruckt employee_list und es wurde 57 zurückgegeben, was der korrekten Anzahl von Zeilen entspricht, die wir gescrapt haben (Zeilen sind jetzt Objekte innerhalb des Arrays).
Für den Import einer Liste in JSON sind lediglich zwei Codezeilen erforderlich:
with open('json_data', 'w') as json_file:
json.dump(employee_list, json_file, indent=2)
- Zuerst öffnen wir eine neue Datei und geben den gewünschten Namen für die Datei ein
(json_data)und 'w', da wir Daten darauf schreiben möchten. - Als nächstes verwenden wir die
.dump()Funktion, um die Daten aus dem Array zu sichern(employee_list)Undindent=2Jedes Objekt hat also seine eigene Zeile, anstatt dass sich alles in einer unlesbaren Zeile befindet.
6. Ausführen des Skripts und des vollständigen Codes
Wenn Sie mitverfolgt haben, Ihre Codebasis sollte so aussehen:
#dependencies
import requests
from bs4 import BeautifulSoup
import json
url = 'http://api.scraperapi.com?api_key=51e43be283e4db2a5afbxxxxxxxxxxx&url=https://datatables.net/examples/styling/stripe.html'
#empty array
employee_list = ()
#requesting and parsing the HTML file
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
#selecting the table
table = soup.find('table', class_ = 'stripe')
#storing all rows into one variable
for employee_data in table.find_all('tbody'):
rows = employee_data.find_all('tr')
#looping through the HTML table to scrape the data
for row in rows:
name = row.find_all('td')(0).text
position = row.find_all('td')(1).text
office = row.find_all('td')(2).text
age = row.find_all('td')(3).text
start_date = row.find_all('td')(4).text
salary = row.find_all('td')(5).text
#sending scraped data to the empty array
employee_list.append({
'Name': name,
'Position': position,
'Office': office,
'Age': age,
'Start date': start_date,
'salary': salary
})
#importing the array to a JSON file
with open('employee_data', 'w') as json_file:
json.dump(employee_list, json_file, indent=2)
Notiz: Wir haben einige Kommentare für den Kontext hinzugefügt.
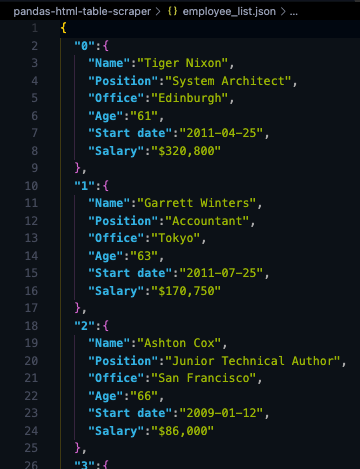
Und hier ist ein Blick auf die ersten drei Objekte aus der JSON-Datei:
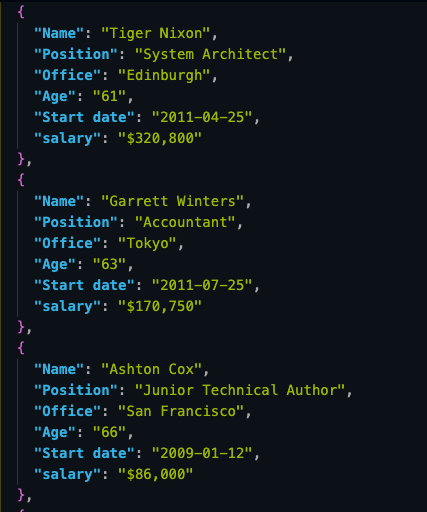
Durch das Speichern der Scraped-Daten im JSON-Format können wir die Informationen für neue Anwendungen oder wiederverwenden
Scrapen Sie HTML-Tabellen mit komplexen Headern.
Das Scrapen von Daten aus HTML-Tabellen ist ziemlich einfach, aber was passiert, wenn Sie auf eine Tabelle mit komplexeren Strukturen, wie z. B. verschachtelten Tabellen, stoßen? rowspansoder colspans? In diesen Fällen müssen Sie möglicherweise eine ausgefeiltere Parsing-Logik implementieren.
Bevor wir beginnen, sehen Sie sich unten an, wie die Zieltabelle aussieht:
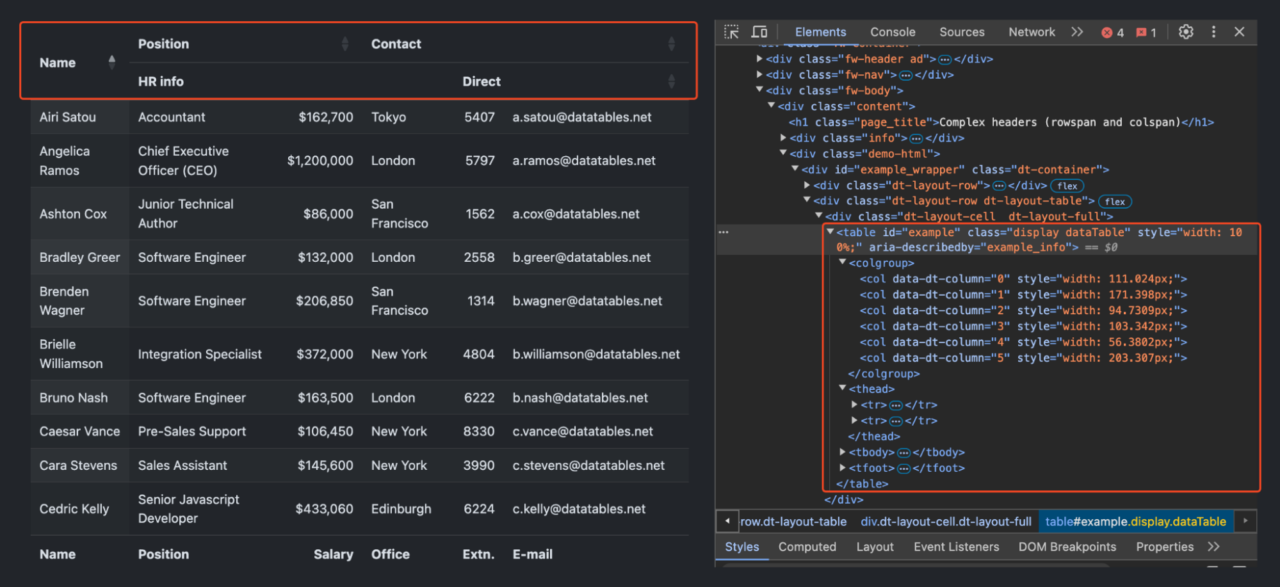
Wie Sie sehen, hat diese Tabelle eine zweistufige Kopfstruktur:
-
Die erste Zeile enthält umfassendere Kategorien: „Name„, „Position„, Und „Kontakt„.
- In der zweiten Zeile werden diese Kategorien weiter aufgeschlüsselt.
Lasst uns den Tisch abkratzen!
Einrichten der Scraping-Umgebung
Zuerst müssen wir die benötigten Bibliotheken importieren. ScraperAPI hilft uns bei der Handhabung aller Anti-Scraping-Maßnahmen, die auf der Website möglicherweise vorhanden sind, einschließlich der Verwaltung von Headern und rotierenden IPs, falls erforderlich:
import requests
from bs4 import BeautifulSoup
import pandas as pd
api_key = 'YOUR_API_KEY'
url = 'https://datatables.net/examples/basic_init/complex_header.html'
Erstellen der Scraping-Funktion
Fahren wir mit der Erstellung einer Funktion fort scrape_complex_table Das übernimmt den gesamten Schabevorgang. Diese Funktion verwendet unsere URL als Eingabe und gibt einen Pandas-DataFrame zurück, der die strukturierten Tabellendaten enthält:
def scrape_complex_table(url):
# Send a request to the webpage
payload = {'api_key': api_key, 'url': url}
response = requests.get('https://api.scraperapi.com', params=payload)
soup = BeautifulSoup(response.text, 'html.parser')
Diese Funktion verwendet requests.get um eine GET-Anfrage an ScraperAPI zu senden, die wiederum die Zielwebseite abruft. Anschließend analysieren wir den HTML-Inhalt mit BeautifulSoup.
Auffinden der Zieltabelle
Wir lokalisieren die Tabelle im analysierten HTML mithilfe von it id Attribut.
# Find the target table
table = soup.find('table', id='example')
Diese Zeile findet den ersten
| , and stores the data in the rows Liste.
Erstellen des DataFrameWir erstellen einen Pandas DataFrame unter Verwendung der kombinierten Header und extrahierten Daten. Dieser DataFrame organisiert unsere Daten in einem strukturierten Format mit entsprechenden Spaltennamen.
Ausführen des Scrapers und Speichern von Daten Wir nennen das
Dadurch werden die oberen Zeilen des DataFrame gedruckt und die gesamten Daten in einer Datei mit dem Namen gespeichert Alles zusammenfügenSo sollte der vollständige Code nach der Kombination aller Schritte aussehen:
Notiz: Stellen Sie sicher, dass Sie ersetzt haben Scraping von paginierten HTML-Tabellen mit PythonBeim Umgang mit großen Datensätzen werden Tabellen häufig auf mehrere Seiten aufgeteilt, um die Ladezeiten und das Benutzererlebnis zu verbessern. Traditionell würde dies die Einrichtung eines Headless-Browsers mit Tools wie Selenium erfordern. Mit dem Render-Befehlssatz von ScraperAPI können wir jedoch die gleichen Ergebnisse effizienter erzielen. Notiz: Sehen Sie sich dieses ausführliche Tutorial zum Web Scraping mit Selenium an, um mehr zu erfahren. Grundlegendes zum Umgang mit PaginierungenIn unserem etablierten Beispiel ist die Tabelle mit „>“ und „ 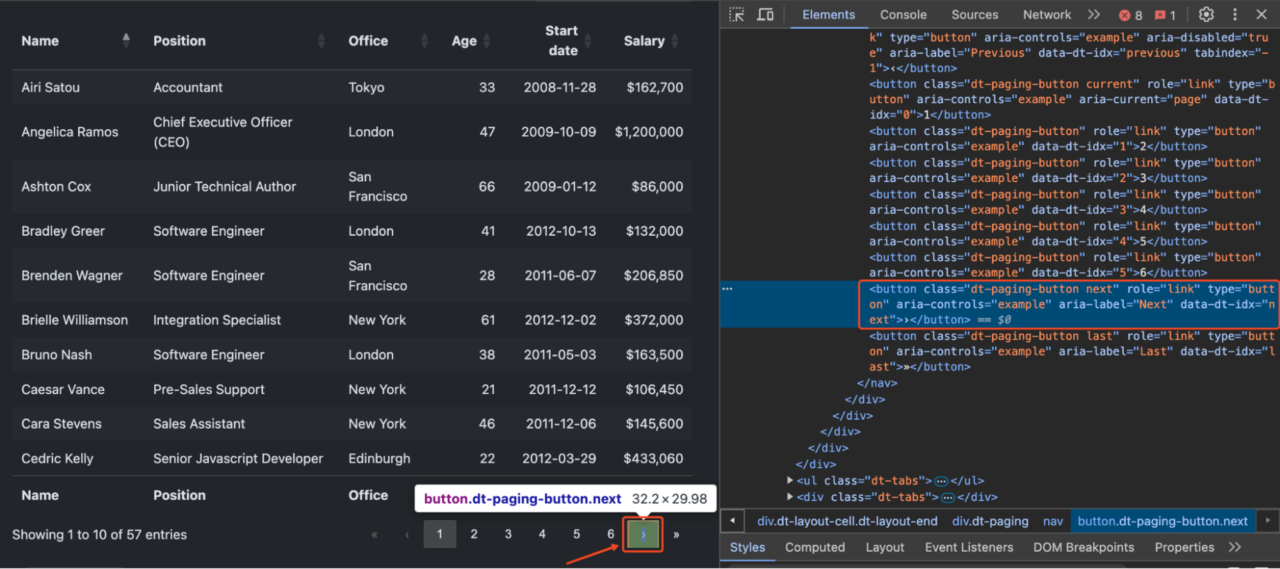 Um alle Daten zu extrahieren, müssen wir Folgendes tun:
Verwendung des Render-Anweisungssatzes von ScraperAPIAnstatt einen Browser manuell zu steuern, können wir über deren API Anweisungen an den Headless-Browser von ScraperAPI senden. Mit dem Render-Anweisungssatz von ScraperAPI können Sie über einen API-Aufruf Anweisungen an einen Headless-Browser senden und ihn anleiten, welche Aktionen beim Rendern der Seite ausgeführt werden sollen. Diese Anweisungen werden als JSON-Objekt in den API-Anfrageheadern gesendet. Lassen Sie uns kurz demonstrieren, wie Sie eine paginierte Tabelle mit dem Render-Befehlssatz von ScraperAPI scrapen: Konfigurieren von ScraperAPI und Renderanweisungen Zuerst richten wir unseren ScraperAPI-Schlüssel und die Ziel-URL ein, die wir scrapen möchten. Denken Sie daran, es auszutauschen
Jetzt definieren wir den Satz von Renderanweisungen.
Der Stellen Sie die Anfrage an ScraperAPI Nachdem wir die Renderanweisungen definiert haben, müssen wir sie konvertieren
Anschließend bereiten wir die Header und Nutzdaten für die GET-Anfrage an ScraperAPI vor:
In den Überschriften:
Die Nutzlast umfasst lediglich die Verarbeitung der TabellendatenSobald wir die Antwort haben, können wir die Tabellendaten mit BeautifulSoup verarbeiten:
Vorteile der Verwendung von RenderanweisungenDie Verwendung der Render-Anweisungen von ScraperAPI bietet mehrere Vorteile gegenüber der herkömmlichen Browser-Automatisierung:
Umgang mit Fehlern beim Scraping von HTML-TabellenHTML-Tabellen auf echten Websites haben oft komplexe Layouts, was es für Anfänger schwierig macht, sie zu bewältigen. Diese Tabellen können gemischte Datentypen, verschachtelte Elemente, verbundene Zellen und andere komplizierte Strukturen enthalten, die das Parsen der Tabelle beim Scraping erschweren. Lassen Sie uns einige häufig auftretende Probleme und ihre Lösungen untersuchen, um Ihr Table Scraping effizienter und zuverlässiger zu gestalten: 1. Umgang mit leeren Zellen und fehlenden DatenLeere Zellen oder fehlende Daten können dazu führen, dass Ihr Scraping-Skript fehlschlägt oder unvollständige Ergebnisse liefert. So gehen Sie elegant damit um:
2. JavaScript-injizierte TabellenEinige Tabellen werden mithilfe von JavaScript dynamisch generiert. Das bedeutet, dass die Daten nicht in der ersten HTML-Antwort vorhanden sind, sondern nach der Darstellung durch einen Browser in die Seite eingefügt werden. Herkömmliche Scraping-Methoden können diesen Inhalt möglicherweise nicht abrufen, da sie kein JavaScript ausführen. Mit dem Render-Befehlssatz von ScraperAPI können Sie Benutzerinteraktionen simulieren und JavaScript in einer Headless-Browserumgebung ausführen. Dadurch können Sie dynamisch geladene Tabellen durchsuchen, ohne auf komplexe Tools wie Selenium zurückgreifen zu müssen.
Notiz: Weitere Informationen zum Scraping von Javascript-Tabellen finden Sie in unserem ausführlichen Leitfaden. 3. Fehlerhafte HTML-TabellenEinige Tabellen haben möglicherweise eine ungültige HTML-Struktur oder fehlende schließende Tags. Ein besserer Parser für diesen Fall wäre html5lib. So gehen Sie damit um:
4. Verwendung von Pandas anstelle von MechanicalSoup oder BeautifulSoup Die Verwendung von Pandas zum Scrapen von HTML-Tabellen spart viel Zeit und macht den Code zuverlässiger, da Sie die gesamte Tabelle auswählen und nicht einzelne Elemente, die sich im Laufe der Zeit ändern können. Der Scraping von HTML-Tabellen mit PandasBevor Sie die Seite verlassen, möchten wir einen zweiten Ansatz zum Scrapen von HTML-Tabellen untersuchen. In wenigen Codezeilen können wir alle Tabellendaten aus einem HTML-Dokument extrahieren und sie mithilfe von Pandas in einem Datenrahmen speichern. Erstellen Sie einen neuen Ordner im Projektverzeichnis (wir haben ihn pandas-html-table-scraper genannt) und erstellen Sie einen neuen Dateinamen mit dem Namen pandas_table_scraper.py. Öffnen wir ein neues Terminal und navigieren wir zu dem Ordner, den wir gerade erstellt haben (cd pandas-html-table-scraper) und installieren von dort aus pandas: Und wir importieren es oben in die Datei. Pandas verfügt über eine Funktion namens read_html(), die im Grunde die Ziel-URL für uns auswertet und alle HTML-Tabellen als Liste von DataFrame-Objekten zurückgibt. Damit dies funktioniert, muss die HTML-Tabelle jedoch zumindest einigermaßen ordentlich strukturiert sein, da die Funktion nach Elementen wie sucht |