Nicht alle gescrapten Webdaten sind sauber und können direkt verwendet werden. Wenn Ihr Parser nicht richtig konfiguriert ist, kann Ihr Web Scraper große Mengen unnötiger, „schmutziger“ Daten zurückgeben. Um einen robusten Parser zu erstellen, müssen Sie die richtigen CSS-Selektoren verwenden und konfigurieren.
Da es verschiedene Arten von CSS-Selektoren gibt, kann die Auswahl des richtigen CSS-Selektors eine Herausforderung sein. Dieser CSS-Selektor-Spickzettel soll Ihnen bei der Auswahl der geeigneten CSS-Selektoren für Ihre Datenextraktionsanforderungen helfen. Darüber hinaus haben wir Beispiele für die Erstellung von HTML-Parsern mit verschiedenen CSS-Selektoren in Programmiersprachen wie Scrapy und Node.JS beigefügt, um ein praktisches Verständnis ihrer Implementierung zu vermitteln.
CSS-Selektoren-Spickzettel für Web Scraping
Hinweis: Wenn Sie mit Cascading Style Sheets (CSS) nicht vertraut sind, empfehlen wir Ihnen, am Ende dieses Blogs die Grundlagen von CSS und seine Verwendung für Web Scraping zu lesen.
Obwohl es viele CSS-Selektoren gibt, müssen wir sie für Web Scraping nicht wirklich alle kennen (es sei denn, Sie sind auch daran interessiert, Front-End-Entwicklung zu erlernen. Das ist derzeit nicht unser Ziel).
Daher listet unser Spickzettel für CSS-Selektoren nur diejenigen auf, die uns beim Aufbau eines effizienten Web-Scraper helfen können. Einen ausführlicheren Spickzettel für CSS-Selektoren finden Sie auf der CSS-Selektor-Referenzseite von W3Schools.
| Wähler | Beispiel | Anwendungsfall-Szenario |
| * | * | Dieser Selektor wählt alle Elemente innerhalb einer Seite aus. Es ist nicht viel anders als eine Seite. Es nützt nicht viel, ist aber trotzdem gut zu wissen |
| .Klasse | .Kartentitel | Der einfachste CSS-Selektor zielt auf das Klassenattribut ab. Wenn es nur von Ihrem Zielelement verwendet wird, reicht es möglicherweise aus. |
| .class1.class2 | .card-heading.card-title | Es gibt Elemente mit einer Klasse wie class=“card-heading card-title“. Wenn wir ein Leerzeichen sehen, liegt das daran, dass das Element mehrere Klassen verwendet. Es gibt jedoch keine feste Methode zur Auswahl des Elements. Versuchen Sie, das Leerzeichen beizubehalten. Wenn das nicht funktioniert, ersetzen Sie das Leerzeichen durch einen Punkt. |
| #Ausweis | #Kartenbeschreibung | Was passiert, wenn die Klasse in zu vielen Elementen verwendet wird oder das Element keine Klasse hat? Die Auswahl des Ausweises kann das nächstbeste sein. Das einzige Problem besteht darin, dass IDs pro Element eindeutig sind. Es ist also nicht erforderlich, mehrere Elemente gleichzeitig zu schneiden und abzukratzen. |
| Element | h4 | Um ein Element auszuwählen, müssen wir unserem Parser lediglich den HTML-Tag-Namen hinzufügen. |
| element.class | h4.kartentitel | Dies ist die häufigste Form, die wir in unseren Projekten verwenden werden. |
| parentElement > childElement | div > h4 | Wir können unserem Scraper anweisen, ein Element in ein anderes zu extrahieren. In diesem Beispiel soll das h4-Element gefunden werden, dessen übergeordnetes Element ein div ist. |
| parentElement.class > childElement | div.card-body > h4 | Wir können die vorherige Logik kombinieren, um ein übergeordnetes Element anzugeben und ein bestimmtes untergeordnetes CSS-Element zu extrahieren. Dies ist sehr nützlich, wenn die gewünschten Daten keine Klasse oder ID haben, sondern sich in einem übergeordneten Element mit einer eindeutigen Klasse/ID befinden. |
| (Attribut) | (href) | Eine weitere großartige Möglichkeit, ein Element anzusprechen, für das keine klare Klasse zur Auswahl steht. Ihr Scraper extrahiert alle Elemente, die das spezifische Attribut enthalten. In diesem Fall wird es alles dauern Tags, die am häufigsten ein href-Attribut enthalten. |
| (Attribut=Wert) | (Ziel=_blank) | Wir können unseren Scraper anweisen, nur die Elemente mit einem bestimmten Wert innerhalb seines Attributs zu extrahieren. |
| Element(Attribut=Wert) | a(rel=next) | Dies ist der Selektor, den wir verwendet haben, um unserem Scrapy-Skript eine Crawling-Funktion hinzuzufügen: next_page = Response.css('a(rel=next)').attrib('href') Die Zielwebsite verwendete für ihre gesamte Paginierung dieselbe Klasse Links, also mussten wir eine andere Lösung finden. |
| (Attribut~=Wert) | (Titel~=Bewertung) | Dieser Selektor wählt alle Elemente aus, die das Wort „Bewertung“ in seinem Titelattribut enthalten. |
Für die meisten Projekte werden diese Selektoren mehr als ausreichen, um die gesuchten Daten zu extrahieren.
Hinweis: Wenn Sie mehr über CSS-Selektoren im Allgemeinen erfahren möchten, bietet Mozilla eine großartige Seite an, auf der erklärt wird, wie CSS-Selektoren für die Webentwicklung funktionieren. Vor diesem Hintergrund ist es an der Zeit, zu etwas Praktischerem überzugehen.
So erstellen Sie einen HTML-Parser mit CSS-Selektoren (Codebeispiele)
Jeder Web Scraper, egal wie er aufgebaut ist, benötigt einen Parser. Mit dieser Methode filtert unser Skript die Daten aus dem HTML-Code und extrahiert nur die Informationsbits, die wir benötigen. Da jede Programmiersprache dies anders handhabt, finden Sie hier vier HTML-Parser, die mit CSS für verschiedene Bibliotheken erstellt wurden:
Erstellen eines HTML-Parsers mit Scrapy-CSS-Selektoren
Scrapy ist ein Open-Source-Framework, das Web-Scraping mit Python einfach und skalierbar macht. Für dieses Projekt suchten wir nach der Website eines Weinlieferanten (https://www.wine-selection.com/), um den Namen, den Prinzen und den Link aller Weine zu sammeln.
def parse(self, response):
for wines in response.css('div.txt-wrap'):
yield {
'name': wines.css('a::text').get(),
'price': wines.css('strong.price::text').get().replace('$ ',''),
'link': wines.css('a').attrib('href'),
}
Bei dieser Analysemethode sind zwei Dinge zu beachten:
Notiz: Wir verwenden die Antwort der ersten Anfrage. Ohne eine Antwort auf die Analyse macht es keinen Sinn, diese Methode zu definieren.
Das vollständige Scrapy-Tutorial können Sie hier lesen
Erstellen eines HTML-Parsers mit Rvest-CSS-Selektoren
Rvest ist für R, was Scrapy für Python ist. Dies (Rvest) ist eine hocheffiziente und einfallsreiche Bibliothek für Web Scraping, die für R entwickelt wurde und sich dadurch auszeichnet, wie einfach es ist, Daten zu bearbeiten und schöne Visualisierungen zu erstellen.
Für dieses Projekt wollten wir ein Repository mit Filmen von IMDb erstellen und den Filmtitel, das Jahr, die Bewertung und die Zusammenfassung abrufen.
titles = page > html_nodes(".lister-item-header a") > html_text()
movie_url = page > html_nodes(".lister-item-header a") > html_attr("href") > paste("https://www.imdb.com", ., sep)
year = page > html_nodes(".text-muted.unbold") > html_text()
rating = page > html_nodes(".ratings-imdb-rating strong") > html_text()
synopsis = page > html_nodes(".ratings-bar+ .text-muted") > html_text()
In Rvest müssen wir nicht wirklich eine Methode definieren, um den heruntergeladenen HTML-Code zu analysieren. Wir mussten lediglich eine Anfrage senden und die Antwort in der Seitenvariablen speichern.
Dann können wir > verwenden, um durch das DOM zu navigieren und die gesuchten Daten zu extrahieren.
Ein paar Dinge, die Sie bei diesem Parser beachten sollten:
- Wir verwenden html_text() am Ende der Zeichenfolge, um unserem Skript mitzuteilen, dass es nur den Text innerhalb des Knotens erfassen soll.
- Da die URL innerhalb des href-Attributs fragmentiert war (The Suicide Squad), haben wir eine paste()-Funktion hinzugefügt, damit die endgültige URL tatsächlich anklickbar ist.
Diese Übung hat wirklich Spaß gemacht und wir mussten eine Schleife bauen, damit sich unser Schaber durch die Paginierung bewegen konnte.
Das vollständige Tutorial zum Rvest-Schaber können Sie hier lesen
Erstellen eines HTML-Parsers mit C#-ScrapySharp-CSS-Selektoren
Wie bei jeder anderen Programmiersprache könnten wir auch C# allein zum Erstellen unseres Scrapers verwenden. Allerdings würde es uns einfach mehr Zeit kosten, ein minderwertiges Skript zu erstellen – viele Codezeilen, um einfache Aufgaben zu erledigen.
Stattdessen können wir ScrapySharp verwenden, eine Bibliothek, die speziell für Web Scraping in C# entwickelt wurde.
Obwohl wir ein relativ kleines Projekt durchgeführt haben, können Sie dieselbe Logik anwenden, um einen größeren, komplexeren Parser in Ihr Projekt einzubauen.
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load("https://blog.hubspot.com/topic-learning-path/customer-retention");
var Headers = doc.DocumentNode.CssSelect("h3.blog-card__content-title > a")
Beachten Sie, dass wir dieses Mal element.class > element verwenden, um unseren CSS-Selektor zu erstellen.
Wir haben es so gemacht, weil es dort keinen Unterricht gab Tag, der den Titel der Artikel im Hubspot-Blog enthält.
Das vollständige C#-Web-Scraping-Tutorial können Sie hier lesen
Erstellen eines HTML-Parsers mit Node.JS Cheerio CSS-Selektoren
Node.JS ist eine Laufzeitumgebung, die es uns ermöglicht, JavaScript im Backend zu verwenden.
Dank seiner Vielseitigkeit können wir mit Node.JS viele Dinge tun. Beispielsweise könnten wir eine Bibliothek namens Puppeteer verwenden, um einen Web-Scraper zu schreiben, der mit Websites interagiert, um auf Daten hinter Triggern und Ereignissen zuzugreifen.
Für statische Seiten besteht die beste Lösung jedoch darin, Cheerio zum Parsen des heruntergeladenen HTML-Codes zu verwenden.
Auch dies ist nur ein einfaches Beispiel, aber Sie können dieselbe Syntax verwenden, um weitere Elemente zu extrahieren, solange Sie die richtigen CSS-Selektoren kennen (hier ist der Spickzettel für CSS-Selektoren oben hilfreich).
Für dieses Beispiel haben wir die Anfrage mit Axios (versprechungsbasierter HTTP-Client für Node.js) gesendet und dann Cheerio verwendet, um das Preiselement innerhalb des DOM auszuwählen.
axios(url)
.then(response => {
const html = response.data;
const $ = cheerio.load(html)
const salePrice = $('.sale-price').text()
console.log(salePrice);
})
Das vollständige Node.js-Web-Scraper-Tutorial können Sie hier lesen
Web Scraping mit CSS-Selektoren
Wenn Sie gerade erst mit dem Web-Scraping begonnen haben, erfahren Sie jetzt mehr über CSS, seine Rolle beim Web-Scraping und wie wir es zum Parsen von HTML verwenden können.
Neben HTML und JavaScript ist CSS einer der Bausteine jeder Website und Webanwendung. Es verwendet Selektoren, um HTML-Elemente basierend auf Klassen, IDs, Attributen und Pseudoklassen auszuwählen und dann Stile darauf anzuwenden, um dem Browser mitzuteilen, wie das Element auf visueller Ebene angezeigt werden soll.
Mithilfe derselben Logik können wir CSS-Selektoren verwenden, um unserem Scraper mitzuteilen, wo sich die Daten befinden, die er sammeln soll.
Wir können uns den Prozess so vorstellen:
- Zuerst veranlassen wir unser Skript, eine Anfrage an den Server zu senden. Als Antwort sendet ihm der Server den HTML-Quellcode.
- Anschließend erstellen wir mithilfe von CSS einen Parser, um den HTML-Code zu filtern und nur die Elemente auszuwählen, die wir benötigen.
Das Erstellen eines Parsers mit CSS kann sehr leistungsstark sein, da wir eine einzige Codezeile verwenden können, um einen bestimmten Satz von Elementen abzurufen.
Beispielsweise können wir gezielt eine Produktliste erstellen, Produktnamen, Beschreibungen und Preise extrahieren und eine Tabelle mit all diesen Daten zur weiteren Analyse füllen.
Bevor wir das tun können, müssen wir jedoch die Struktur unserer Zielwebsite verstehen, um das richtige Ziel zu finden.
So überprüfen Sie eine Seite, um den richtigen CSS-Selektor auszuwählen
Es gibt mehrere Möglichkeiten, die richtige Eigenschaft zu finden, auf die wir beim Erstellen eines Parsers mit CSS abzielen müssen.
Am häufigsten wird die Website mit dem Entwicklertool des Browsers überprüft.
Gehen wir zum Blog von ScraperAPI, klicken Sie mit der rechten Maustaste und klicken Sie auf „Inspizieren“.
Es öffnet sich das „Inspektor-Tool“, sodass wir die HTML-Struktur der Seite sehen können.
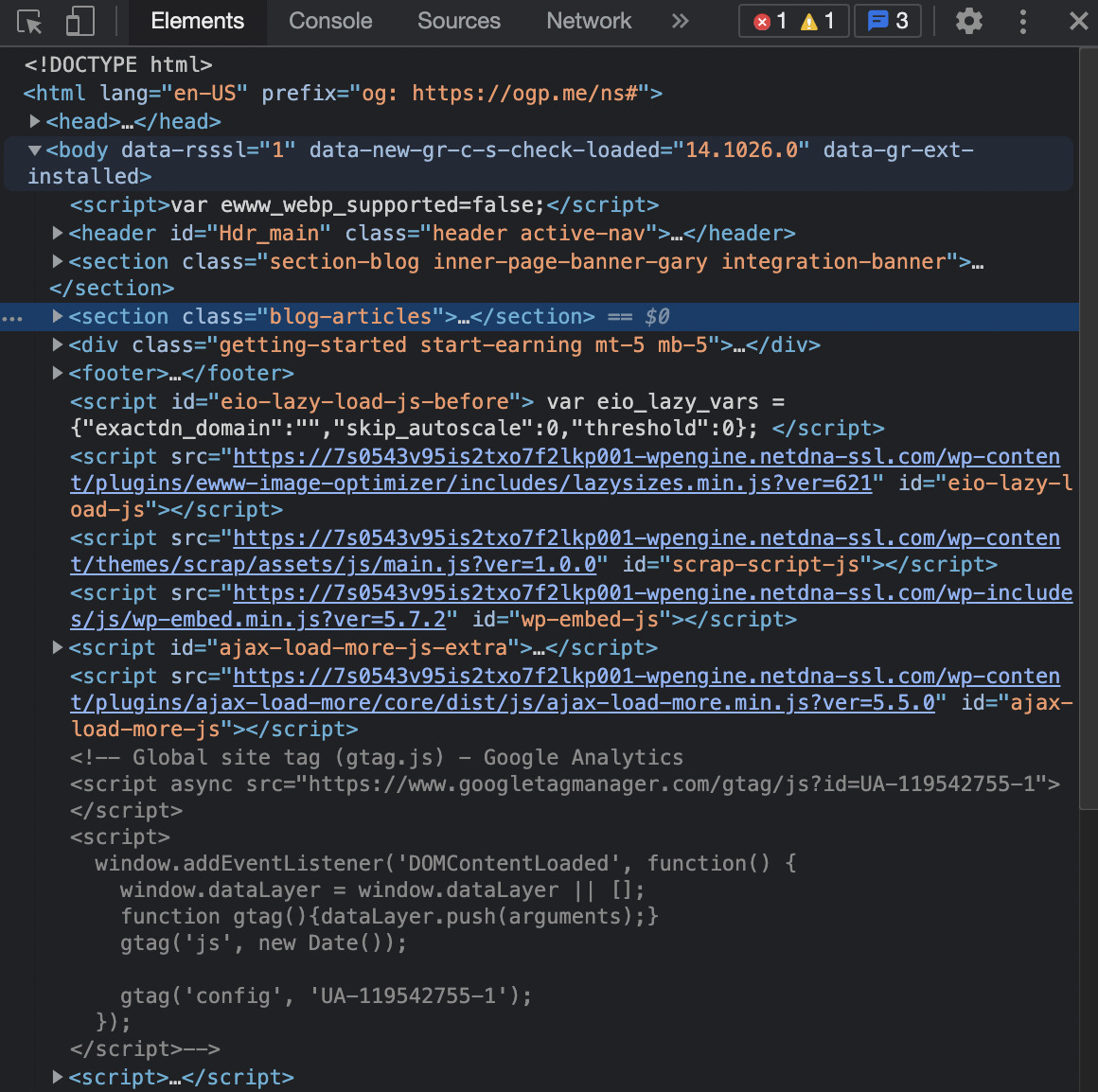
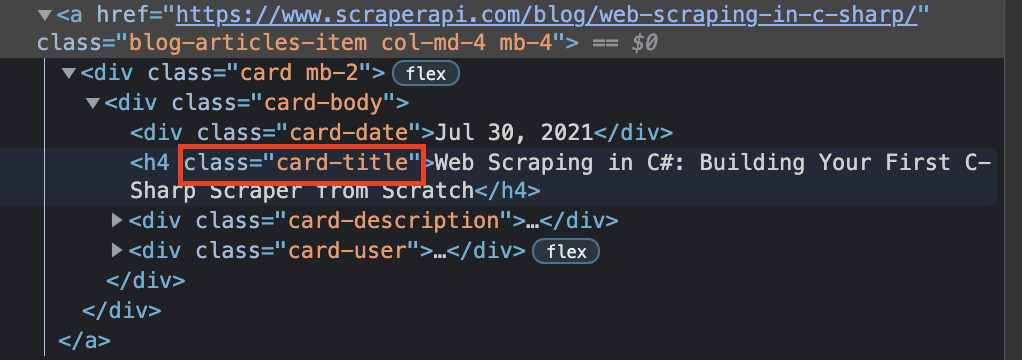
Für diese Seite möchten wir den Titel jedes Artikels abrufen, also müssen wir sehen, wie der Titel im HTML bereitgestellt wird.
Wir können dies tun, indem wir das „Inspektor-Tool“ verwenden und auf den Titel klicken.
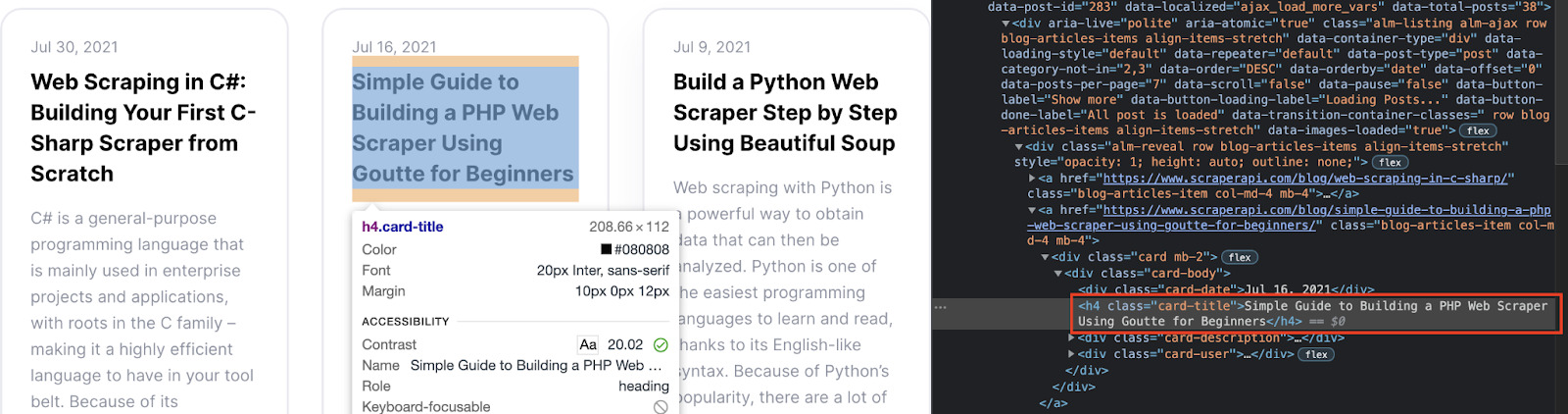
Okay, wir können sehen, dass unser Titel in a steht
Tags. Mit diesen Informationen könnten wir unseren Scraper anweisen, alle zu finden
Tags und fügen Sie sie unserer Tabelle hinzu.
Diese Tags werden nur für Titel verwendet, das würde also für diese Seite ausreichen.
Auf den meisten Websites finden wir jedoch
Zu
Tags werden für viele verschiedene Elemente verwendet, was dazu führen würde, dass unser Scraper viel Rauschen zurückgibt.
Ein weiteres Szenario, in dem ein Tag nicht ausgeschnitten wird, ist der Versuch, bestimmte URLs abzurufen.
URLs befinden sich – fast – immer innerhalb eines Element innerhalb seines href-Attributs. Aus diesem Grund bitten wir unser Skript einfach, alles zu extrahieren Tags werden Navigationslinks, Fußzeilenlinks und jede andere Art von Link auf der Seite angezeigt.
Nicht sehr nützlich, oder?
Dann kommen CSS-Selektoren ins Spiel.
Bei näherer Betrachtung können wir zwei Dinge feststellen:
- Das Wichtigste
wo wir finden können, dass der Titel die Klasse „Card-Body“ hat
- Während der Titel selbst ein ist
mit der Klasse 'card-title'

Mit diesen neuen Informationen können wir eine Methode erstellen, um den heruntergeladenen HTML-Code zu analysieren und nur die Elemente zu extrahieren, die unserem Filter entsprechen.
Wenn wir diese Methode mit Scrapy schreiben würden, würde sie so aussehen:
def parse(self, response): for articles in response.css('div.card-body'): yield { 'title': articles.css('h4.card-title::text').get(), }Natürlich wäre jede Programmiersprache ein wenig anders. In Scrappy verwenden wir „:text“, um anzugeben, dass wir nur den Text innerhalb der Tags und nicht das gesamte Element haben möchten.
Die Logik hinter dem CSS-Selektor bleibt jedoch relativ gleich.
Bedenken Sie, dass unsere Zielseite eine wirklich einfache Struktur hat. Andere Websites können viel komplexer sein, daher ist es wichtig, einen CSS-Spickzettel zur Hand zu haben, der uns hilft, herauszufinden, wie wir unseren Parser am besten programmieren.
Die richtigen CSS-Selektoren erstellen robuste HTML-Parser
Wie Sie sehen, können Sie, wenn Sie die Syntax zum Erstellen von CSS-Selektoren verstehen, fast jedes Element aus einer Website extrahieren – einschließlich dynamischer Seiten.
Es geht darum, die richtige Logik für die Zielgruppe zu finden und die Grundlagen der Programmiersprache zu verstehen, mit der Sie Ihren Web Scraper erstellen möchten.
Bisher sind unsere beiden bevorzugten Sprachen Python mit Scrapy und R mit Rvest. Ihre Syntax ist leicht zu verstehen und mit nur wenigen Codezeilen können Sie große Datenmengen extrahieren.
Darüber hinaus ist es mit Python und R viel einfacher, Ihr Skript an die Paginierung anzupassen als mit C# oder Node.js.
Wenn Sie jedoch bereits viel Erfahrung mit Letzterem haben, ist es kein Problem, sich dafür zu entscheiden. Solange Sie die richtigen Daten erhalten und schneller programmieren können, liegt der Rest bei Ihnen.
Wenn Sie einen umfassenderen CSS-Spickzettel wünschen, schauen Sie sich diesen von W3Schools an. Möchten Sie mehr über Web Scraping erfahren? Schauen Sie sich diese Web-Scraping-Ressourcen im ScraperAPI-Blog an:
Bis zum nächsten Mal, viel Spaß beim Schaben!
- Während der Titel selbst ein ist