
S.
for job in jobs:
job_title = job.find('h3', class_='base-search-card__title').text.strip()
job_company = job.find('h4', class_='base-search-card__subtitle').text.strip()
job_location = job.find('span', class_='job-search-card__location').text.strip()
job_link = job.find('a', class_='base-card__full-link')('href')
Catatan: Jika Anda merasa kami bergerak terlalu cepat, kami sarankan membaca tutorial web scraping Python kami untuk pemula. Proses ini akan dibahas lebih detail.
Daftar Isi
9. Impor pekerjaan LinkedIn ke dalam file CSV
Di luar fungsi utama, kita membuka file baru, membuat penulis baru, dan memerintahkannya untuk membuat baris judul menggunakan metode .writerow():
file = open('linkedin-jobs.csv', 'a')
writer = csv.writer(file)
writer.writerow(('Title', 'Company', 'Location', 'Apply'))
Jika Anda membuka file yang ingin terus ditambahkan baris baru, Anda harus membukanya mode lampiran, maka mengapa a sebagai argumen kedua di open() Fungsi.
Untuk membuat baris baru dengan data yang diekstrak oleh parser, tambahkan cuplikan kode ini ke akhir perulangan for:
writer.writerow((
job_title.encode('utf-8'),
job_company.encode('utf-8'),
job_location.encode('utf-8'),
job_link.encode('utf-8')
))
Di akhir setiap iterasi melalui daftar pekerjaan, scraper kami memasukkan semua data ke dalam baris baru.
Catatan: Penting untuk memastikan bahwa urutan penambahan data baru sesuai dengan urutan judul.
Untuk menyelesaikan langkah ini, kami menambahkan satu else Pernyataan untuk menutup file segera setelah loop terputus.
else:
file.close()
print('File closed')
10. Melewati Deteksi Anti-Bot LinkedIn dengan ScraperAPI
Langkah terakhir kami bersifat opsional, namun dapat menghemat jam kerja Anda dalam jangka panjang. Lagi pula, kami tidak tertarik hanya membuang satu atau dua halaman saja.
Untuk menskalakan proyek Anda, Anda perlu melakukan hal berikut:
- Menangani rotasi IP
- Kelola kumpulan proxy
- Tangani CAPTCHA
- Kirim header yang benar
dan lebih banyak lagi untuk menghindari banned atau bahkan banned seumur hidup.
ScraperAPI dapat mengatasi tantangan ini dan tantangan lainnya hanya dengan beberapa perubahan pada URL dasar yang saat ini kami gunakan.
Pertama, buat akun ScraperAPI gratis baru untuk mendapatkan akses ke kunci API kami.
Dari sana, yang perlu Anda lakukan hanyalah menambahkan string ini ke awal URL:
http://api.scraperapi.com?api_key={YOUR_API_KEY}&url=
Ini menghasilkan pemanggilan fungsi berikut:
linkedin_scraper('http://api.scraperapi.com?api_key=51e43be283e4db2a5afb62660xxxxxxx&url=https://www.linkedin.com/jobs-guest/jobs/api/seeMoreJobPostings/search?keywords=Product%20Management&location=San%20Francisco%20Bay%20Area&geoId=90000084&trk=public_jobs_jobs-search-bar_search-submit&position=1&pageNum=0&start=', 0)
Dengan cara ini, permintaan HTTP diproses oleh server ScraperAPI. Ini merotasi IP setelah setiap permintaan (atau sesuai kebutuhan) dan memilih header yang benar berdasarkan analisis statistik dan pembelajaran mesin selama bertahun-tahun.
Selain itu, ScraperAPI memiliki proxy ultra-premium yang dipilih secara khusus untuk menangani situs yang sangat sulit seperti LinkedIn. Untuk menggunakannya, aktifkan ultra_premium=true Parameter dalam permintaan.
Scraper Web LinkedIn: Kode Lengkap
Selamat, Anda baru saja membuat scraper LinkedIn pertama Anda!
Jika Anda mengikuti, basis kode Anda akan terlihat seperti ini:
import csv
import requests
from bs4 import BeautifulSoup
file = open('linkedin-jobs.csv', 'a')
writer = csv.writer(file)
writer.writerow(('Title', 'Company', 'Location', 'Apply'))
def linkedin_scraper(webpage, page_number):
next_page = webpage + str(page_number)
print(str(next_page))
response = requests.get(str(next_page))
soup = BeautifulSoup(response.content,'html.parser')
jobs = soup.find_all('div', class_='base-card relative w-full hover:no-underline focus:no-underline base-card--link base-search-card base-search-card--link job-search-card')
for job in jobs:
job_title = job.find('h3', class_='base-search-card__title').text.strip()
job_company = job.find('h4', class_='base-search-card__subtitle').text.strip()
job_location = job.find('span', class_='job-search-card__location').text.strip()
job_link = job.find('a', class_='base-card__full-link')('href')
writer.writerow((
job_title.encode('utf-8'),
job_company.encode('utf-8'),
job_location.encode('utf-8'),
job_link.encode('utf-8')
))
print('Data updated')
if page_number
Kami telah menambahkan beberapa print() Pernyataan sebagai umpan balik visual.
Setelah mengeksekusi kode, skrip membuat file CSV dengan data yang diekstraksi:

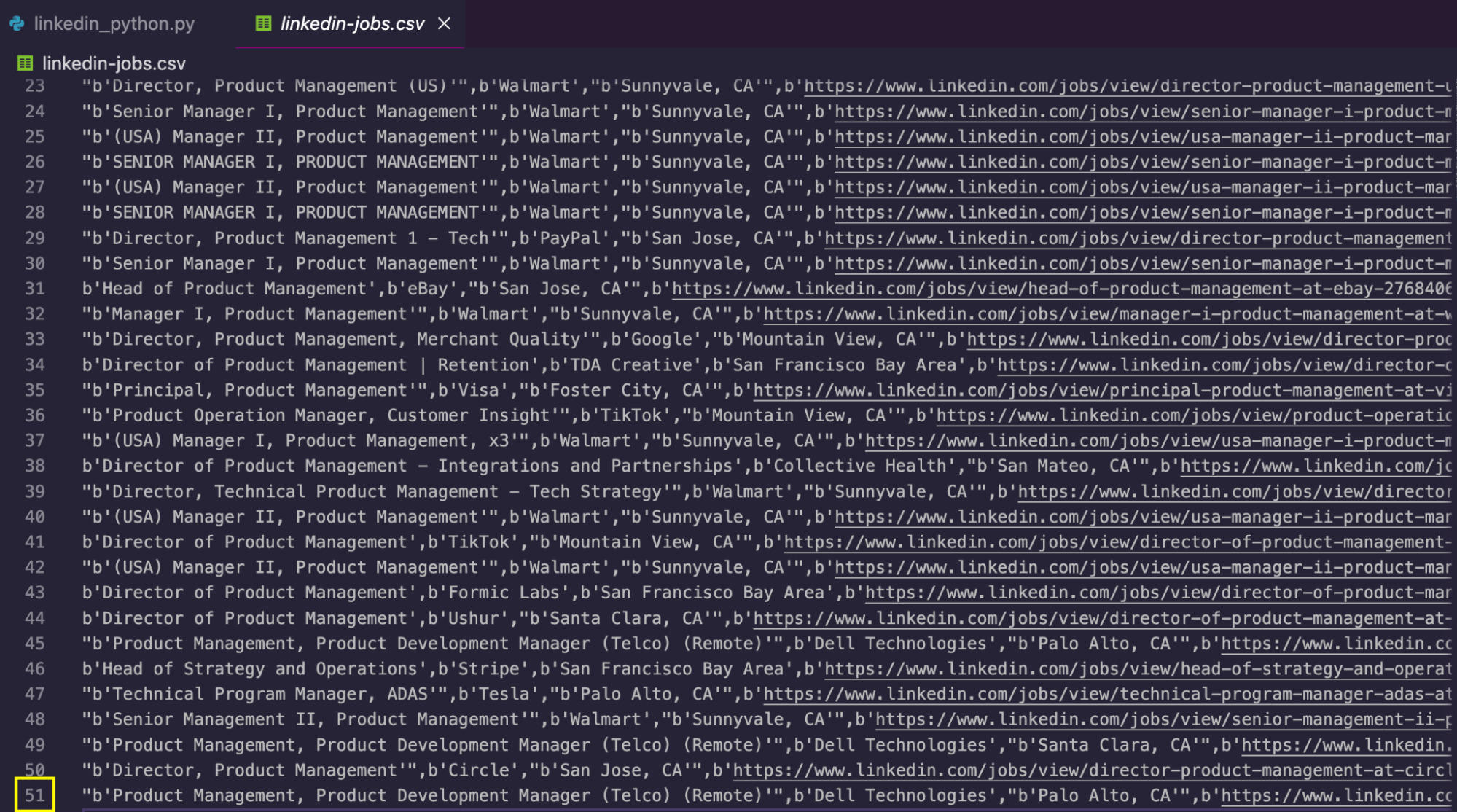
Untuk mendapatkan lebih banyak data, Anda dapat meningkatkan batasnya if Kondisi untuk mengikis lebih banyak halaman, obati keywords Parameter untuk mengulangi dan/atau mengubah berbagai kueri location Parameter untuk mendapatkan jabatan yang sama di berbagai kota dan negara.
Mengikis profil LinkedIn berdasarkan jabatan dengan Selenium
catatan: Sebelum melanjutkan, ingatlah bahwa mengambil data di balik dinding login dapat menimbulkan konsekuensi hukum dan mungkin melanggar persyaratan layanan LinkedIn. Kami sangat menyarankan untuk tidak menggunakan teknik ini tanpa izin. Untuk tutorial ini kita akan menggunakan akun burner dan server proxy untuk meminimalkan risiko pemblokiran.
Meskipun metode kami sebelumnya efektif dalam menyaring lowongan pekerjaan, metode ini tidak memberikan informasi profil terperinci yang kami perlukan untuk penelitian kandidat. Untuk mengakses data ini, kita perlu mencari profil individual.
Mari kita lihat cara membuat web scraper menggunakan Selenium untuk mengumpulkan data dari profil LinkedIn berdasarkan jabatan tertentu driver Chrome tidak terdeteksi. Bagian ini mengasumsikan bahwa Anda sudah memiliki pemahaman dasar tentang cara kerja Selenium.
Namun, metode ini dapat bermanfaat untuk membangun database kandidat, terutama jika Anda ingin melakukan pencarian di beberapa lokasi. Untuk setiap kandidat kami mengumpulkan informasi berikut:
- Nama kandidat
- URL profil LinkedIn
- Judul pekerjaan
- Lokasi
- Peran saat ini jika tersedia
Menyiapkan lingkungan
Untuk mengikis profil LinkedIn, kami menggunakan pustaka Python berikut:
- selenium: Mengotomatiskan interaksi browser.
- Kawat selenium: Memperluas kemampuan Selenium.
- Driver Chrome tidak dikenal: Membantu melewati deteksi anti-bot.
- Sup yang indah: Mem-parsing konten HTML.
- Lxml: Pengurai XML dan HTML yang kuat
- CSV: Menangani operasi file CSV.
Lanjutkan untuk menginstal perpustakaan yang diperlukan menggunakan pip:
pip install selenium selenium-wire undetected-chromedriver beautifulsoup4 lxml webdriver-manager setuptools
Impor perpustakaan
Selanjutnya, impor perpustakaan yang diperlukan dan atur Selenium WebDriver dengan opsi yang sesuai.
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from time import sleep
import undetected_chromedriver as uc
from bs4 import BeautifulSoup
import csv
Konfigurasikan pengaturan proksi
Kami kemudian mengatur konfigurasi proxy kami. Menggunakan proxy membantu mendistribusikan permintaan dan mengurangi risiko pemblokiran berbasis IP:
proxy_host="your_proxy_host"
proxy_port="your_proxy_port"
proxy_username="your_username"
proxy_password = 'your_password'
proxy_url = f'http://{proxy_username}:{proxy_password}@{proxy_host}:{proxy_port}'
catatan: Pengganti"host_proxy_Anda", "port_proksi_Anda ", "nama pengguna_Anda", Dan "kata sandi_Anda” dengan kredensial proxy Anda yang sebenarnya.
Konfigurasi proxy kemudian diatur menggunakan opsi Selenium Wire:
seleniumwire_options = {
'proxy': {
'http': proxy_url,
'https': proxy_url,
},
'verify_ssl': False,
}
Navigasi ke LinkedIn
Untuk contoh ini kami mencari “Pengembang web junior” di Amerika Serikat dan India.
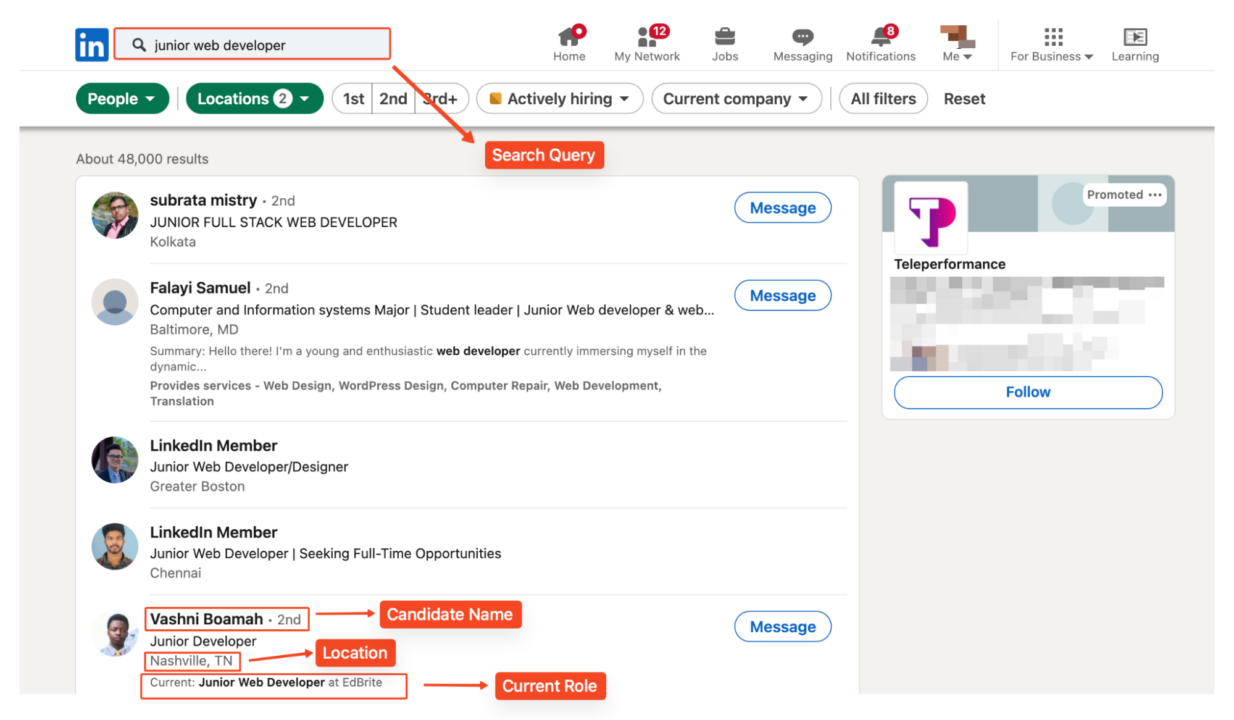
URL berisi parameter lokasi untuk penelusuran bertarget:
linkedin_url="https://www.linkedin.com/search/results/people/?geoUrn=%5B%22103644278%22%2C%22102713980%22%5D&keywords=junior%20web%20developer&origin=FACETED_SEARCH"
Gunakan “driver.get()” metode untuk menavigasi ke halaman arahan LinkedIn.
# Initialize the undetected Chrome driver with proxy settings
driver = uc.Chrome(options=options, seleniumwire_options=seleniumwire_options)
# Go to the LinkedIn page
driver.get(linkedin_url)
Kami mengonfigurasi opsi Chrome untuk meminimalkan deteksi:
options = Options()
options.add_argument("--disable-blink-features=AutomationControlled")
options.add_argument("--headless=new")
Masuk ke LinkedIn
Untuk mengakses data profil, kita perlu login ke LinkedIn. Kami sangat menyarankan penggunaan akun tiruan untuk menghindari risiko pada profil pribadi Anda. Kami menemukan kolom input email dan kata sandi berdasarkan ID HTML-nya dan kemudian menggunakannya kirim_kunci() Metode untuk memasukkan informasi login Anda.
# Wait for the username and password fields to load and enter credentials
username_field = WebDriverWait(driver, 20).until(EC.presence_of_element_located((By.ID, 'username')))
username_field.send_keys('Linkedin_username')
password_field = driver.find_element(By.ID, 'password')
password_field.send_keys(‘Linkedin_password’)
login_button = driver.find_element(By.CSS_SELECTOR, '.login__form_action_container button')
login_button.click()
print("Sign In Successful...\n")
# Allow some time to bypass CAPTCHA if needed
sleep(10)
Catatan: Pengganti "Linkedin_nama pengguna" Dan "LinkedIn_Kata Sandi” dengan kredensial LinkedIn Anda yang sebenarnya.
Mengikis data profil dengan Selenium
Setelah masuk, kami membuat file CSV untuk menyimpan data tergores kami:
with open('linkedin_profiles.csv', 'w', newline="", encoding='utf-8') as csvfile:
fieldnames = ('Name', 'Profile Link', 'Job Title', 'Location', 'Current Role')
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
Scraper menelusuri lima (5) halaman hasil pencarian pertama dan mengekstrak informasi penting dari setiap profil.
Kita dapat mengikis lebih banyak halaman hanya dengan menyesuaikan jumlah halaman yang akan dikikis:
for page_number in range(1, 6):
page_url = linkedin_url + f"&page={page_number}"
driver.get(page_url)
print(f"Scraping page {page_number}...\n")
Untuk setiap profil, kami mencari dan menganalisis data pengguna menggunakan BeautifulSoup. Mari kita uraikan setiap elemen yang kita ekstrak dari profil LinkedIn:
Temukan wadah profil
Pertama kita perlu menemukan semua penampung profil di halaman. Kami akan menggunakan BeautifulSoup find_all() Metode untuk mendapatkan semua container ini:
profiles = soup.find_all('li', class_='reusable-search__result-container')
Ekstraksi nama
Untuk mengekstrak nama pengguna, terletak di a Tandai dengan atribut aria-hidden='true'. Kami menggunakan metode pencarian untuk menemukan tag ini di setiap profil. Beberapa profil mungkin disembunyikan atau dibatasi, jadi kami memberikan alternatif untuk “LinkedIn Member":
name_tag = profile.find('span', {'aria-hidden': 'true'})
name = name_tag.get_text(strip=True) if name_tag else "LinkedIn Member"
Selanjutnya, kami mengekstrak URL ke profil LinkedIn pengguna:
profile_link_tag = profile.find('a', class_='app-aware-link', href=True)
profile_link = profile_link_tag('href') if profile_link_tag else "N/A"
Judul pekerjaan
Judul pekerjaan pengguna terletak di a div Elemen dengan 'entity-result__primary-subtitle' Kelas:
job_title_tag = profile.find('div', class_='entity-result__primary-subtitle')
job_title = job_title_tag.get_text(strip=True) if job_title_tag else "N/A"
Jika jabatan pekerjaan tidak tersedia, kami menetapkannya “T/A”. job_title Variabel.
Informasi lokasi
Data lokasi disimpan di a div dengan 'entity-result__secondary-subtitle' Kelas:
location_tag = profile.find('div', class_='entity-result__secondary-subtitle')
location = location_tag.get_text(strip=True) if location_tag else "N/A"
Peran saat ini
Untuk mengekstrak peran atau posisi saat ini, kami mencarinya hari bersama kelas entity-result__summary. Kami memeriksa apakah teks dimulai dengan ""Current:” dan ekstrak informasi yang relevan:
current_role = "N/A"
summary_p = profile.find('p', class_='entity-result__summary')
if summary_p:
summary_text = summary_p.get_text(strip=True)
if summary_text.startswith("Current:"):
current_role = summary_text.replace("Current:", "").strip()
Menulis data yang diekstrak ke file CSV
Setelah mengekstraksi semua informasi yang diperlukan, kami menulis data ke file CSV kami menggunakan writer.writerow() Prosedur:
writer.writerow({
'Name': name,
'Profile Link': profile_link,
'Job Title': job_title,
'Location': location,
'Current Role': current_role
})
Kami juga mencetak pesan konfirmasi untuk menunjukkan bahwa profil telah disimpan:
print(f"Saved profile: {name}")
Menutup peramban
Setelah mengikis, tutup browser untuk mengosongkan sumber daya sistem.
# Close the browser
driver.quit()
Lihat data yang dikumpulkan
Setelah menjalankan skrip, Anda akan mendapatkan file CSV dengan nama linkedin_profiles.csv berisi data yang tergores:
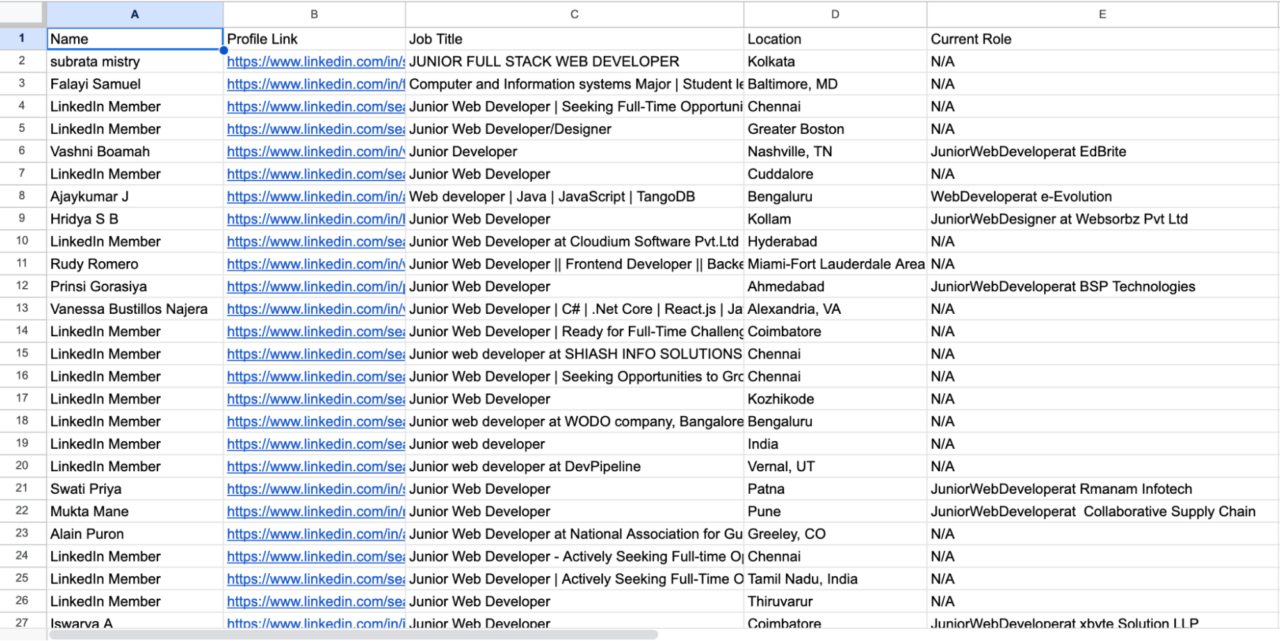
Kode lengkap: menggores profil dengan Selenium
Kode lengkap ini mengintegrasikan semua teknik yang kami gunakan di bagian ini.
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from time import sleep
import undetected_chromedriver as uc
from bs4 import BeautifulSoup
import csv
proxy_host="your_proxy_host"
proxy_port="your_proxy_port"
proxy_username="your_linkedin_email"
proxy_password = 'your_password'
# Construct the proxy URL
proxy_url = f'http://{proxy_username}:{proxy_password}@{proxy_host}:{proxy_port}'
# LinkedIn URL and credentials
linkedin_url="https://www.linkedin.com/search/results/people/?geoUrn=%5B%22103644278%22%2C%22102713980%22%5D&keywords=junior%20web%20developer&origin=FACETED_SEARCH"
username = "Your_linkedin_username"
password = "Your_linkedin_password"
# Setting Chrome options and proxy configuration for undetected_chromedriver
options = Options()
options.add_argument("--disable-blink-features=AutomationControlled")
options.add_argument("--headless=new")
seleniumwire_options = {
'proxy': {
'http': proxy_url,
'https': proxy_url,
},
'verify_ssl': False,
}
# Initialize the undetected Chrome driver with proxy settings
driver = uc.Chrome(options=options, seleniumwire_options=seleniumwire_options)
# Go to the LinkedIn page
driver.get(linkedin_url)
# Wait for the username and password fields to load and enter credentials
username_field = WebDriverWait(driver, 20).until(EC.presence_of_element_located((By.ID, 'username')))
username_field.send_keys(username)
password_field = driver.find_element(By.ID, 'password')
password_field.send_keys(password)
login_button = driver.find_element(By.CSS_SELECTOR, '.login__form_action_container button')
login_button.click()
print("Sign In Successful...\n")
sleep(10)
# Open a CSV file to write the data
with open('linkedin_profiles.csv', 'w', newline="", encoding='utf-8') as csvfile:
fieldnames = ('Name', 'Profile Link', 'Job Title', 'Location', 'Current Role')
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader() # Write the header row
# Loop through the first 5 pages
for page_number in range(1, 6):
page_url = linkedin_url + f"&page={page_number}"
driver.get(page_url)
print(f"Scraping page {page_number}...\n")
# Wait for the search results to load
sleep(5)
# Locate and parse the profile details
try:
page_source = driver.page_source
soup = BeautifulSoup(page_source, 'lxml')
profiles = soup.find_all('li', class_='reusable-search__result-container')
for profile in profiles:
# name
name_tag = profile.find('span', {'aria-hidden': 'true'})
name = name_tag.get_text(strip=True) if name_tag else "LinkedIn Member"
# profile link
profile_link_tag = profile.find('a', class_='app-aware-link', href=True)
profile_link = profile_link_tag('href') if profile_link_tag else "N/A"
# job title
job_title_tag = profile.find('div', class_='entity-result__primary-subtitle')
job_title = job_title_tag.get_text(strip=True) if job_title_tag else "N/A"
# location
location_tag = profile.find('div', class_='entity-result__secondary-subtitle')
location = location_tag.get_text(strip=True) if location_tag else "N/A"
# current (if any)
current_role = "N/A"
summary_p = profile.find('p', class_='entity-result__summary')
if summary_p:
summary_text = summary_p.get_text(strip=True)
if summary_text.startswith("Current:"):
current_role = summary_text.replace("Current:", "").strip()
# Write the extracted data to the CSV file
writer.writerow({
'Name': name,
'Profile Link': profile_link,
'Job Title': job_title,
'Location': location,
'Current Role': current_role
})
print(f"Saved profile: {name}")
except Exception as e:
print(f"An error occurred on page {page_number}: {e}")
# Close the browser
driver.quit()
Cara Mengekstrak Data Perusahaan dari LinkedIn
Untuk mengekstrak data perusahaan LinkedIn, kami dapat mengembangkan teknik scaping profil pengguna dan menyesuaikan kode kami dengan perusahaan LinkedIn. Agar aman, kami menelusuri perusahaan teknologi AS dengan 11-50 karyawan untuk mengumpulkan informasi seperti nama mereka, profil LinkedIn, jumlah pengikut, situs web, industri, dan kantor pusat.
Kami akan menggunakan perpustakaan dan pengaturan yang sama seperti sebelumnya. Pertama, navigasikan ke halaman hasil pencarian perusahaan:
linkedin_url="https://www.linkedin.com/search/results/companies/?companyHqGeo=%5B%22103644278%22%5D&companySize=%5B%22C%22%5D&industryCompanyVertical=%5B%221594%22%5D&origin=FACETED_SEARCH&sid=G4U"
Namun, fokus kami hanya mengumpulkan data khusus perusahaan yang tercantum di bawah ini:
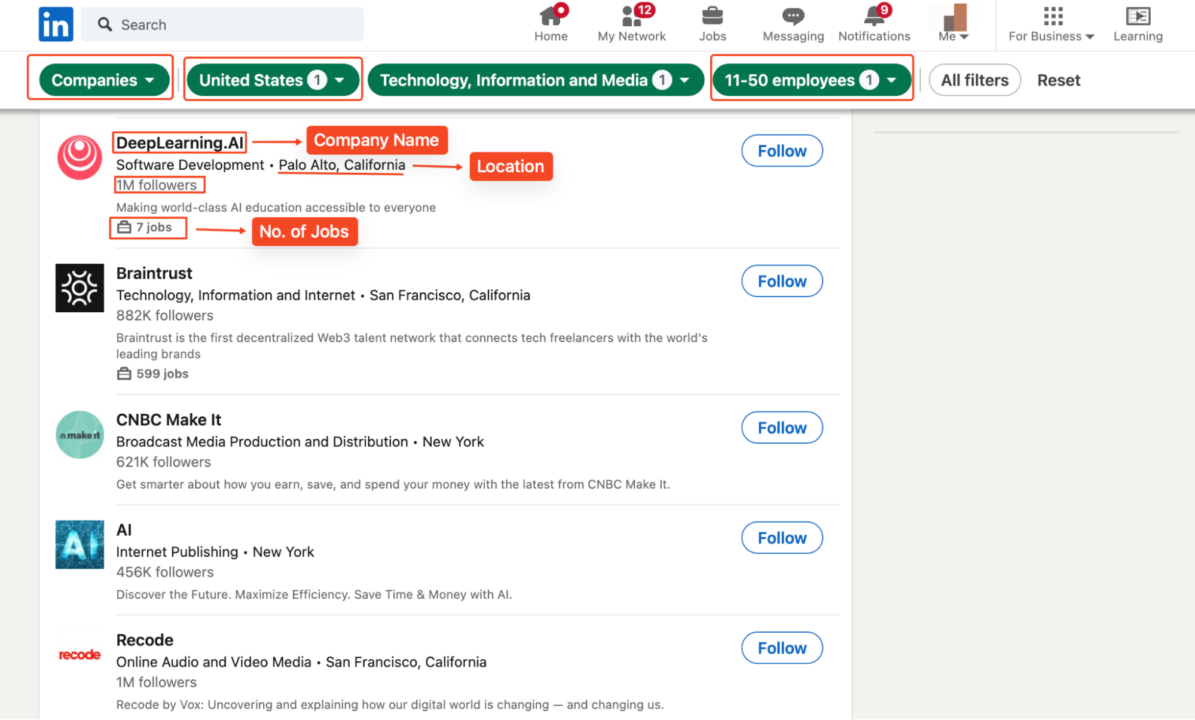
Jelajahi halaman dan ekstrak data perusahaan
Setelah mendaftar, kami menelusuri lima halaman pertama hasil pencarian untuk mengumpulkan data dari beberapa perusahaan. Kami membuat URL untuk setiap halaman dengan menambahkan nomor halaman dan menavigasi ke sana. Kami kemudian menunggu beberapa detik hingga halaman dimuat.
for page_number in range(1, 6):
page_url = linkedin_url + f"&page={page_number}"
driver.get(page_url)
print(f"Scraping page {page_number}...\n")
sleep(5) # Adjust sleep time if necessary
Mengurai sumber halaman
Kami mengurai sumber halaman menggunakan BeautifulSoup untuk mengambil semua daftar perusahaan di halaman saat ini:
page_source = driver.page_source
soup = BeautifulSoup(page_source, 'lxml')
company_listings = soup.find_all('li', class_='reusable-search__result-container')
Ekstrak nama perusahaan
Kami mengekstrak nama perusahaan dari hari bersama kelas entity-result__title-text. Jika tag nama tidak ditemukan, kami default ke “N/A”.
name_tag = company_li.find('span', class_='entity-result__title-text')
company_name = name_tag.get_text(strip=True) if name_tag else "N/A"
Ekstrak URL profil perusahaan
Tautan ke profil perusahaan terletak di dalam a hari bersama kelas app-aware-link. Kami mengekstraknya href Atribut untuk mendapatkan URL:
profile_link_tag = company_li.find('a', class_='app-aware-link', href=True)
company_profile_url = profile_link_tag('href') if profile_link_tag else "N/A"
Mengekstraksi industri, lokasi dan jumlah pengikut
Industri dan lokasi berada dalam radius a
entity-result__primary-subtitle. Biasanya dipisahkan dengan tanda “•”:
primary_subtitle_tag = company_li.find('div', class_='entity-result__primary-subtitle')
primary_subtitle = primary_subtitle_tag.get_text(strip=True) if primary_subtitle_tag else "N/A"
if '•' in primary_subtitle:
industry, location = (text.strip() for text in primary_subtitle.split('•', 1))
else:
industry, location = primary_subtitle, "N/A"
Kemudian kita cari jumlah pengikut a
entity-result__secondary-subtitle:
secondary_subtitle_tag = company_li.find('div', class_='entity-result__secondary-subtitle')
num_followers = secondary_subtitle_tag.get_text(strip=True) if secondary_subtitle_tag else "N/A"
Ekstrak jumlah pekerjaan
Kami kemudian mencari jumlah pekerjaan di perusahaan tersebut
reusable-search-simple-insight__text-container:
num_jobs = "N/A"
insight_tags = company_li.find_all('div', class_='reusable-search-simple-insight__text-container')
for insight_tag in insight_tags:
insight_text = insight_tag.get_text(strip=True)
if 'jobs' in insight_text:
num_jobs = insight_text
break
Tulis data ke file CSV
Setelah mengekstraksi semua informasi yang diperlukan, kami menulis data ke file CSV kami. Ini akan menambahkan baris baru ke file CSV untuk setiap perusahaan:
writer.writerow({
'Company Name': company_name,
'Profile URL': company_profile_url,
'Industry': industry,
'Location': location,
'Number of Followers': num_followers,
'Number of Jobs': num_jobs
})
print(f"Saved company: {company_name}")
Menutup peramban
Setelah pengikisan selesai, kami menutup browser dan mencetak pesan konfirmasi. Ini membebaskan sumber daya sistem dan menandakan akhir skrip:
driver.quit()
print("Scraping complete.")
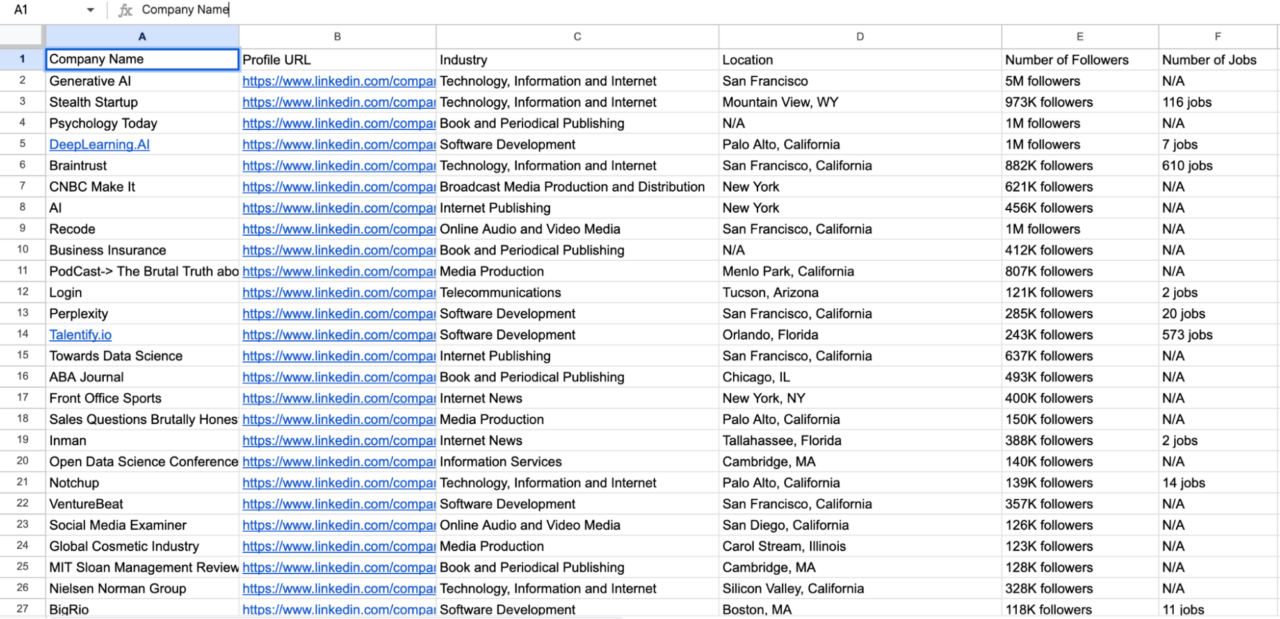
Lengkapi kode dan lihat data yang dikumpulkan
Ini adalah kode lengkap yang kami gunakan untuk menghapus data perusahaan dari LinkedIn.
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from time import sleep
import undetected_chromedriver as uc
from bs4 import BeautifulSoup
import csv
# Proxy credentials and LinkedIn credentials
proxy_host="your_proxy_host"
proxy_port="your_proxy_port"
proxy_username="your_proxy_username"
proxy_password = 'your_proxy_password'
proxy_url = f'http://{proxy_username}:{proxy_password}@{proxy_host}:{proxy_port}'
linkedin_url="https://www.linkedin.com/search/results/companies/?companyHqGeo=%5B%22103644278%22%5D&industryCompanyVertical=%5B%221594%22%5D&origin=FACETED_SEARCH&sid=G4U"
username = "your_linkedin_email"
password = "your_password"
# Set Chrome options
options = Options()
options.add_argument("--disable-blink-features=AutomationControlled")
options.add_argument("--headless=new")
# Initialize the undetected Chrome driver with proxy settings
driver = uc.Chrome(options=options, seleniumwire_options={
'proxy': {'http': proxy_url, 'https': proxy_url},
'verify_ssl': False
})
# Log into LinkedIn
driver.get(linkedin_url)
username_field = WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.ID, 'username'))
)
username_field.send_keys(username)
driver.find_element(By.ID, 'password').send_keys(password)
driver.find_element(By.CSS_SELECTOR, "button(type="submit")").click()
print("Sign In Successful...\n")
sleep(10) # Wait for the login process to complete
# Open a CSV file to write the company data
with open('linkedin_companies.csv', 'w', newline="", encoding='utf-8') as csvfile:
fieldnames = ('Company Name', 'Profile URL', 'Industry', 'Location', 'Number of Followers', 'Number of Jobs')
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
# Loop through the first 5 pages
for page_number in range(1, 6):
page_url = linkedin_url + f"&page={page_number}"
driver.get(page_url)
print(f"Scraping page {page_number}...\n")
sleep(5)
# Parse page source and extract company data
try:
page_source = driver.page_source
soup = BeautifulSoup(page_source, 'lxml')
company_listings = soup.find_all('li', class_='reusable-search__result-container')
for company_li in company_listings:
# company name
name_tag = company_li.find('span', class_='entity-result__title-text')
company_name = name_tag.get_text(strip=True) if name_tag else "N/A"
# company profile link
profile_link_tag = company_li.find('a', class_='app-aware-link', href=True)
company_profile_url = profile_link_tag('href') if profile_link_tag else "N/A"
# industry and location
primary_subtitle_tag = company_li.find('div', class_='entity-result__primary-subtitle')
primary_subtitle = primary_subtitle_tag.get_text(strip=True) if primary_subtitle_tag else "N/A"
if '•' in primary_subtitle:
industry, location = (text.strip() for text in primary_subtitle.split('•', 1))
else:
industry, location = primary_subtitle, "N/A"
# number of followers
secondary_subtitle_tag = company_li.find('div', class_='entity-result__secondary-subtitle')
num_followers = secondary_subtitle_tag.get_text(strip=True) if secondary_subtitle_tag else "N/A"
# number of jobs (if any)
num_jobs = "N/A"
insight_tags = company_li.find_all('div', class_='reusable-search-simple-insight__text-container')
for insight_tag in insight_tags:
insight_text = insight_tag.get_text(strip=True)
if 'jobs' in insight_text:
num_jobs = insight_text
break
# Write company data to the CSV file
writer.writerow({
'Company Name': company_name,
'Profile URL': company_profile_url,
'Industry': industry,
'Location': location,
'Number of Followers': num_followers,
'Number of Jobs': num_jobs
})
print(f"Saved company: {company_name}")
except Exception as e:
print(f"An error occurred on page {page_number}: {e}")
# Close the browser
driver.quit()
print("Scraping complete.")
Menjalankan kode ini akan menghasilkan file CSV bernama linkedin_companies.csv berisi data perusahaan yang diambil.
Dapatkan data LinkedIn yang Anda inginkan dengan ScraperAPI
Membuat scraper LinkedIn bisa menjadi hal yang menakutkan, terutama bila ada risiko pemblokiran. Namun, jika Anda mengikuti panduan web scraping LinkedIn ini, kami menjamin Anda akan dapat mengekstrak dan mengekspor data LinkedIn secara massal tanpa kesulitan.
Ingat: jika proyek lebih dari beberapa halaman, Anda dapat menggunakan integrasi ScraperAPI untuk menghindari hambatan dan melindungi kekayaan intelektual Anda dari sistem anti-scraping.
Tidak tahu harus mulai dari mana? Hubungi tim penjualan kami dan biarkan pakar kami membuat rencana sempurna untuk kasus penggunaan Anda!
Sampai jumpa lagi, selamat menggores!