
Web Scraping ermöglicht nicht nur das Lesen verschiedener Daten von Webseiten, sondern hilft auch, diese für die weitere Analyse zu organisieren. Die Ausgabedaten können im benutzerfreundlichsten Format gespeichert werden, sei es eine Tabelle (z. B. in einer CSV-Datei) oder eine API.
Gleichzeitig extrahiert Web Scraping in Python nicht nur Daten aus CSS-Selektoren. Dies ist eine zuverlässige und einfache Möglichkeit, schnell an große Datenmengen zu gelangen.
Grundlagen zum Webseiten-Scraping
Um Daten zu analysieren, muss man wissen, in welcher Form sie gespeichert sind, und die Grundprinzipien ihrer Übertragung verstehen. Die Übertragung der Informationen im Browser erfolgt über HTTP (Hyper Text Transfer Protocol), das eine Client-Server-Kommunikation nutzt. Das bedeutet, dass es einen Client (jemanden, der Daten anfordert) und einen Server (jemanden, der Daten bereitstellt) gibt.
Beispielsweise kann der Server eine HTML-Seite übertragen. HTML ist eine Hypertext-Markup-Sprache einer Webseite, die dem Browser hilft zu verstehen, was auf der geladenen Site angezeigt werden soll.
Der Client kann ein Browser, Parser oder etwas anderes sein, das Informationen anfordern kann. Der Server ist eine Ressource, auf die der Client zugreift, um Informationen zu erhalten (z. B. der Nginx- oder Apache-Webserver).
Es sieht aus wie das:
- Der Client öffnet die Verbindung.
- Der Client fordert Daten an.
- Der Server gibt die angeforderten Daten zurück.
- Der Server schließt die Verbindung.
Die Anfrage könnte so aussehen:
:authority: scrape-it.cloud
:method: GET
:path: /blog/
:scheme: https
accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
accept-encoding: gzip, deflate, br
accept-language: en-US,en;q=0.9,en;q=0.8;q=0.7
cookie: PHPSESSID=lj21547rbeor092lf7q1tbv2kj; _gcl_au=1.1.46260893.1654510660; _ga=GA1.1.87541067.1654500661; _clck=16uoci|1|f25|0; _ga_QSH330BHPP=GS1.1.1654773897.3.1.1654695637.58; _clsk=ac0mn0|1654695838342|7|1|h.clarity.ms/collect
dnt: 1
referer: https://scrape-it.cloud/
sec-ch-ua: " Not A;Brand";v="99", "Chromium";v="102", "Google Chrome";v="102"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "Windows"
sec-fetch-dest: document
sec-fetch-mode: navigate
sec-fetch-site: same-origin
sec-fetch-user: ?1
upgrade-insecure-requests: 1
user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36Um die Anfrage anzuzeigen, die beim Aufrufen der Webseite generiert wird, gehen Sie zu DevTools (klicken Sie entweder mit der rechten Maustaste auf die Seite und wählen Sie „Inspizieren“ aus oder drücken Sie F12). Gehen Sie in DevTools zur Registerkarte „Netzwerk“, aktualisieren Sie die Seite und wählen Sie ihre Adresse aus der Liste aus. Anschließend wird eine vom Browser generierte Anfrage geöffnet.
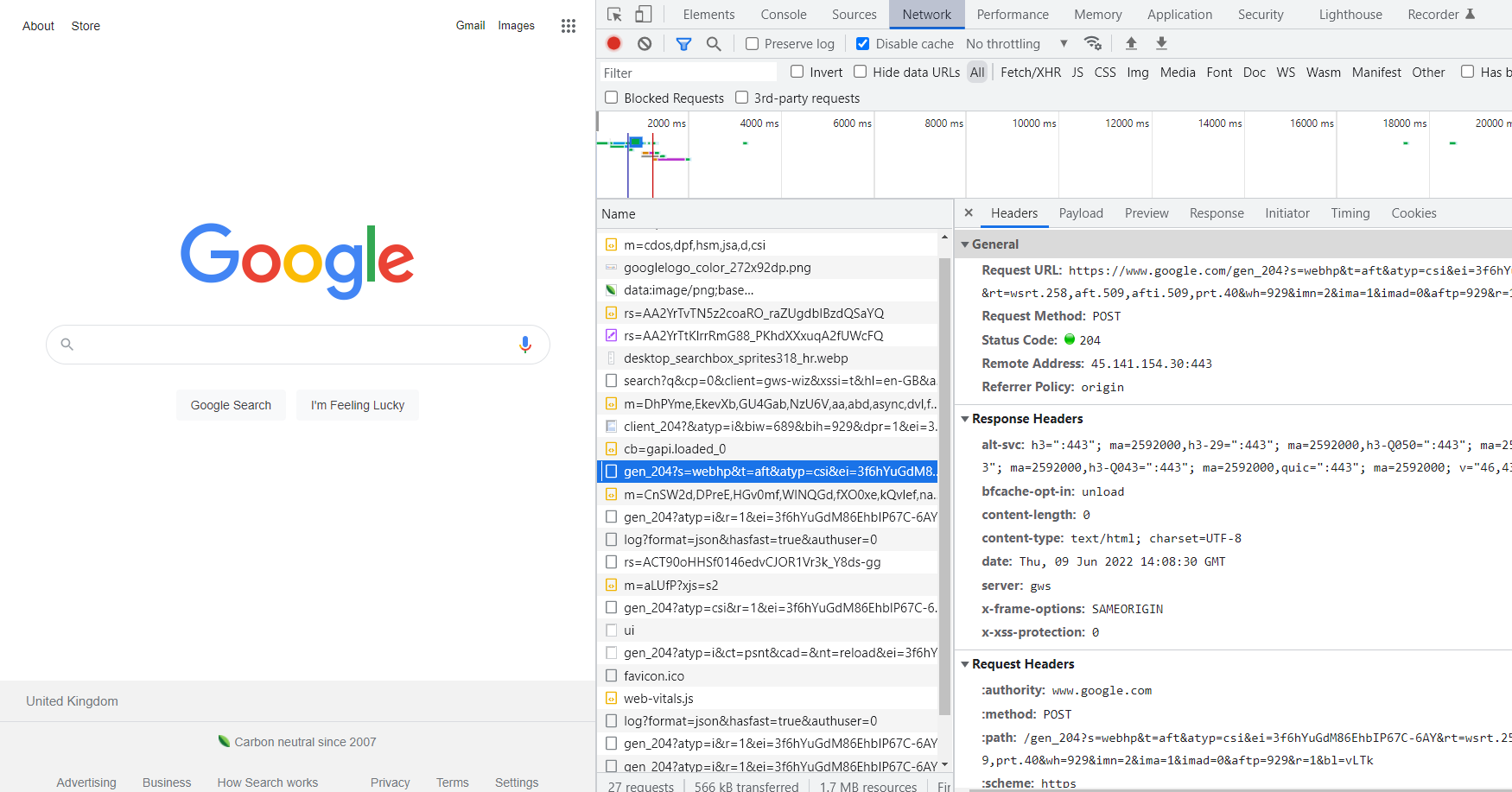
Die Daten, die in den Abschnitten „Cookies“ und „Referrer“ (jedoch im Browser-Referer) gespeichert werden, sind für den Parser wichtig. Cookies – zur Bestätigung der Authentifizierung, des Referrers – für den Fall, dass die Website den Zugriff auf Informationen abhängig davon einschränkt, von welcher Seite der Benutzer kam.
Accept und User-Agent werden ebenfalls nützlich sein. Accept zeigt den Inhaltstyp der Serverantwort an (Text/Plain, Text/HTML, Bild/JPEG usw.) und User-Agent speichert Informationen über den Client.
Instrumental zum Schaben
Mit der wachsenden Beliebtheit von Web Scraping wächst auch die Anzahl der Bibliotheken und Frameworks für Scraping. Die beliebtesten, vollständigsten, am besten dokumentierten und am häufigsten verwendeten sind jedoch nur einige: Beautiful Soup, Requests, Scrapy, lxml, Selenium, URLlib und Pyppeteer.
Um die am besten geeigneten zu finden und ihre Vor- und Nachteile herauszufinden, lohnt es sich, sie genauer zu betrachten.
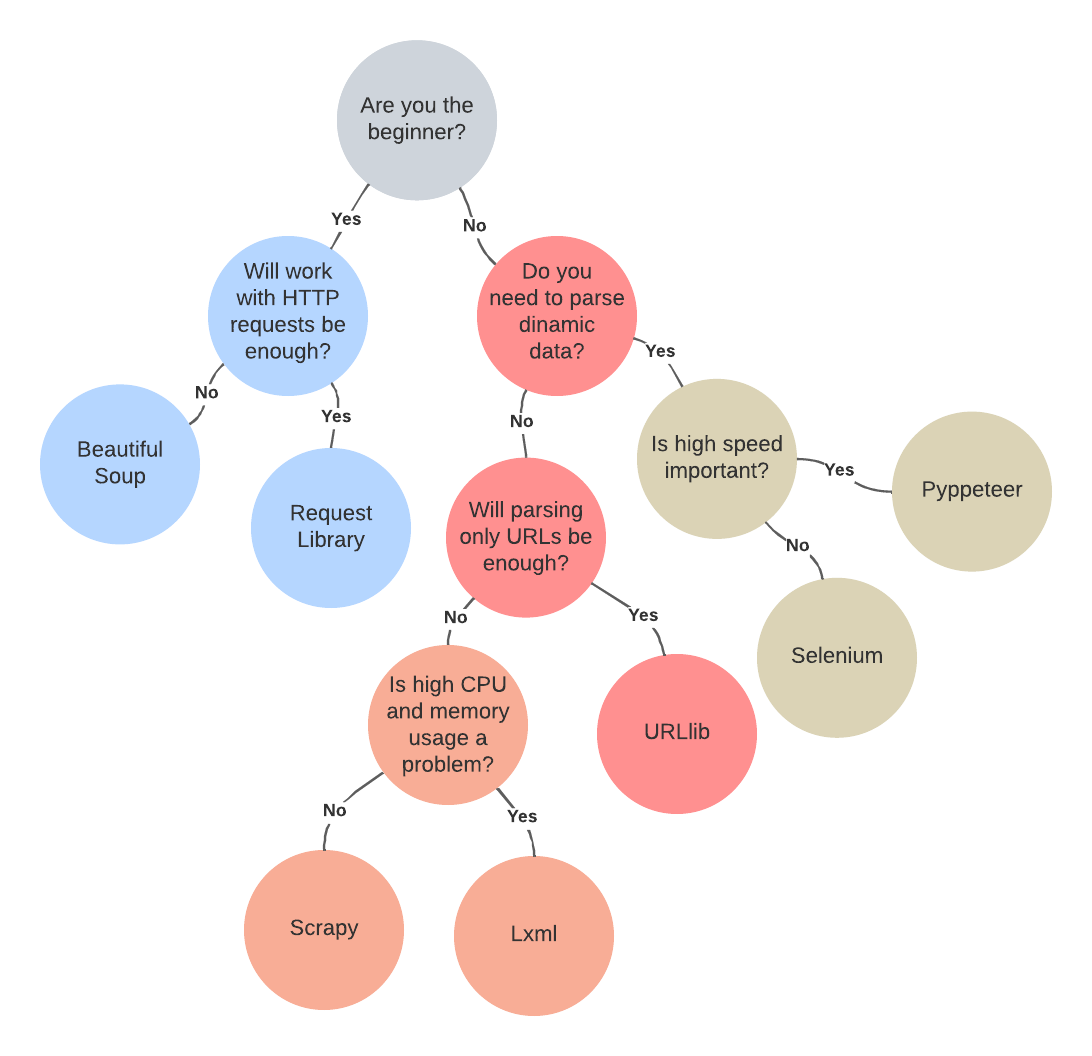
Requests ist die grundlegende Scraping-Bibliothek, auf die jeder auf die eine oder andere Weise stößt.
Was ist die Anforderungsbibliothek?
Die Requests-Bibliothek wurde erstellt, um das Senden von HTTP-Anfragen zu vereinfachen. Da es sich um eine einfache Bibliothek handelt, ist keine große Übung erforderlich, um damit zu arbeiten. Es unterstützt die gesamte Restful API mit all ihren Methoden (PUT, GET, DELETE und POST).
Bei Verwendung der Requests-Bibliothek muss man nicht selbst eine Abfragezeichenfolge für URLs eingeben. Darüber hinaus hat die Request-Bibliothek im Laufe der Jahre eine große Menge nützlicher und gut geschriebener Dokumentation erworben.
In der Regel handelt es sich um eine bereits integrierte Python-Bibliothek. Sollte es jedoch aus irgendeinem Grund nicht vorhanden sein, kann man es selbst installieren. Gehen Sie dazu zum Terminal und geben Sie die Zeile ein:
pip install requestsSobald die Bibliothek installiert ist, kann sie in Projekten verwendet werden:
import requestsUm eine Seite mit der Methode „requests.get“ abzurufen:
import requests
page = requests.get("example.com")
pageWozu dient die Requests-Bibliothek?
Die Requests-Bibliothek unterstützt Datei-Uploads, Verbindungszeitüberschreitungen, Cookies und Sitzungen, Authentifizierung, SSL-Browserüberprüfung und alle Methoden der Interaktion mit der REST-API (PUT, GET, DELETE, POST).
Es hat jedoch einen Nachteil: Es besteht keine Möglichkeit, dynamische Daten zu analysieren, da Requests nicht mit JavaScript-Code interagiert.
Daher ist es eine gute Idee, es in allen Fällen zu verwenden, in denen keine dynamischen Daten analysiert werden müssen.
Beginnen Sie mit einer schönen Suppe
Heute ist die Beautiful Soup-Bibliothek oder einfach BS4 die beliebteste aller zum Scraping verwendeten Python-Bibliotheken.
Was ist die Beautiful Soup-Bibliothek?
Die Beautiful Soup-Bibliothek wurde zum Parsen von HTML erstellt. Aufgrund der Tatsache, dass viele Dinge automatisch erledigt werden (z. B. die Verarbeitung von ungültigem HTML), ist es für Anfänger geeignet.
Die Ausgabe hat ein Baumformat, das das Auffinden von Elementen und das Extrahieren der benötigten Informationen erleichtert. BS4 ermittelt auch die Kodierung automatisch, wodurch auch HTML-Seiten mit Sonderzeichen verarbeitet werden können.
Der Nachteil von BS4 ist die geringe Flexibilität und Skalierbarkeit sowie die Langsamkeit. Der eingebaute Parser kann jedoch problemlos durch einen schnelleren ersetzt werden.
Um BS4 zu installieren, geben Sie einfach die Zeile im Terminal ein
pip install beautifulsoup4Danach kann es zum Schaben verwendet werden. Um beispielsweise alle Titel zu scrapen, reicht ein wenig Code aus:
from bs4 import BeautifulSoup
soup = BeautifulSoup(contents, 'html.parser')
soup.find_all('title')Beachten Sie, dass für eine ordnungsgemäße Funktion die Request-Bibliothek im Projekt enthalten sein muss.
Um gut formatierten Seitencode auszugeben, kann man Folgendes verwenden:
print(soup.prettify())Nehmen wir an, man muss alle Produkttitel sammeln, die auf der Seite gespeichert sind.
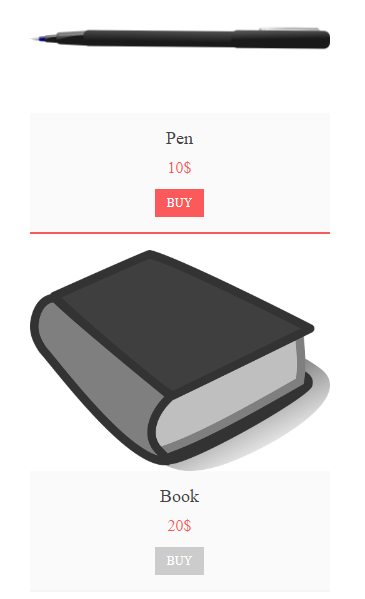
Gleichzeitig gab print(soup.prettify()) den folgenden Code zurück:
<!DOCTYPE html>
<html>
<head>
<title>A sample shop</title>
</head>
<body>
<div class="product-item">
<img src="https://scrape-it.cloud/blog/example.com\item1.jpg">
<div class="product-list">
<h3>Pen</h3>
<span class="price">10$</span>
<a href="example.com\item1.html" class="button">Buy</a>
</div>
</div>
<div class="product-item">
<img src="example.com\item2.jpg">
<div class="product-list">
<h3>Book</h3>
<span class="price">20$</span>
<a href="example.com\item2.html" class="button">Buy</a>
</div>
</div>
</body>
</html>Als nächstes ermitteln Sie den Typ aller Seitenelemente:
(type(item) for item in list(soup.children))BS4 wird etwa Folgendes zurückgeben:
(bs4.element.Doctype, bs4.element.NavigableString, bs4.element.Tag)Die ersten beiden enthalten Informationen über die Seite selbst und nur die letzte enthält Informationen über ihre Elemente. Um Informationen zu Produktnamen zu erhalten, wählen Sie alle Daten im Zusammenhang mit bs4.element.Tag aus:
html = list(soup.children)(2)
# items count from 0Um die Ordnungszahl eines Elements zu überprüfen:
list(html.children)Kehrt zurück:
('n', <head> <title>A sample shop</title> </head>, 'n', <body> <div>…</div> </body>, 'n')So erhalten Sie alle
-Elemente, die in Folge an vierter Stelle stehen:body = list(html.children)(4)Die nächsten Elemente werden auf die gleiche Weise überprüft:
divit = list(body.children)(1)
divli = list(divit.children)(2)
h3 = list(divli.children)(0)Um die Produktnamen zu extrahieren, muss man Folgendes tun:
h3.get_text() Allerdings ermöglicht Beautiful Soup die Automatisierung der meisten Prozesse und der gesamte oben genannte Code kann durch prägnanteren ersetzt werden:
soup = BeautifulSoup(page.content, 'html.parser')
soup.find_all('h3')(0).get_text()Wozu dient die Beautiful Soup-Bibliothek?
Beautiful Soup ist die beste Wahl für diejenigen, die gerade erst mit Schabern beginnen, da es den Großteil der Arbeit automatisch erledigt. Diese Bibliothek eignet sich auch für diejenigen, die Daten von nicht strukturierten Websites extrahieren müssen.
Allerdings eignet sich Beautiful Soup schlecht für große Web-Scraping-Projekte.
Sammeln Sie alle Daten mit Scrapy
Scrapy ist eines der besten Frameworks für Scraping mit Python.
Was ist das Scrapy-Framework?
Scrapy ist ein Open-Source-Framework, das es ermöglicht, eine HTML-Seite zu laden und in der gewünschten Form (z. B. einer CSV-Datei) zu speichern. Da Anfragen parallel ausgeführt und verarbeitet werden, ist die Ausführungsgeschwindigkeit hoch. Es ist die am besten geeignete Option zur Lösung komplexer Architekturdatenerfassungs- und -verarbeitungsaufgaben.
Um Scrapy zu installieren, geben Sie einfach Folgendes in das Terminal ein:
pip install scrapyUm mit Scrapy zu beginnen:
scrapy shell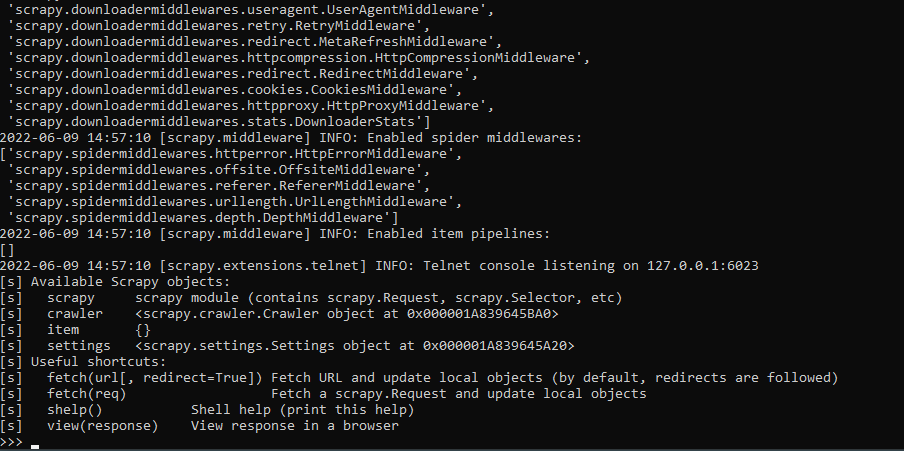
Um den HTML-Inhalt einer Website abzurufen, kann man die Fetch-Funktion verwenden. Lass es uns versuchen:
Um nun sicherzustellen, dass Scrapy die Seite speichert und im Browser anzeigt, verwenden Sie Folgendes:
view(response)
print(response.text)Um mit Scrapy spezifischere Informationen zu erhalten, muss man den CSS-Selektor verwenden.
Wozu dient das Scrapy-Framework?
Scrapy ist sehr ressourcenabhängig. Möglicherweise ist ein separater Server erforderlich, um eine ausreichende Leistung aufrechtzuerhalten.
Darüber hinaus ist dieses Framework nicht für Anfänger geeignet. Anfänger können von allem abgeschreckt werden, von Installationsproblemen auf manchen Systemen bis hin zum Überfluss an einfachen Problemen.
Doch trotz aller Nachteile ist Scrapy immer noch eines der besten Frameworks für große Projekte. Es kann für die Anforderungsverwaltung, die Beibehaltung von Benutzersitzungen, die Verfolgung von Weiterleitungen und die Verarbeitung von Ausgabepipelines verwendet werden.
Lxml-Bibliothek
Lxml ist eine der schnellen, leistungsstarken und dennoch einfachen Parsing-Bibliotheken.
Was ist die Lxml-Bibliothek?
Lxml ist eine Parsing-Bibliothek. Es kann mit HTML- und XML-Dateien arbeiten. Wie Scrapy eignet sich Lxml ideal zum Extrahieren von Daten aus großen Datensätzen. Im Gegensatz zu Beautiful Soup kann es jedoch schlecht gestaltetes HTML nicht analysieren.
Um die Lxml-Bibliothek zu installieren, gehen Sie zum Terminal und schreiben Sie:
pip install lxmlKehren wir zum Beispiel mit Pen and Book zurück. Zunächst müssen Bibliotheken in das Projekt eingebunden werden:
from lxml import html
import requestsRufen Sie dann die Webseite mit den Daten ab:
page = requests.get('http://example.com/item1.html')
tree = html.fromstring(page.content)Die Informationen bestehen aus zwei Elementen – der Titel ist in
und der Preis ist in :
<h3>Pen</h3>
<span class="price">10$</span>
Holen Sie sich die Daten:
titles = tree.xpath('//h3/text()')
prices = tree.xpath('//span(@class="price")/text()')
Zur Anzeige auf dem Bildschirm:
print('Titles: ', titles)
print('Prices: ', prices)
Folgendes wird angezeigt:
Titles: ('Pen', 'Book')
Prices: ('10$','20$')
Wozu dient die Lxml-Bibliothek?
In Fällen, in denen es auf die Leistung ankommt, ist Lxml eine großartige Option. Es ist auch nützlich, wenn große Datenmengen verarbeitet werden müssen.
Allerdings erfreut sich die Bibliothek trotz der Funktionalität und Geschwindigkeit aufgrund der unzureichenden Dokumentation bei Einsteigern keiner großen Beliebtheit, was sie recht schwierig macht.
Selen zum Schaben
Einige Websites werden mit JavaScript geschrieben, einer Sprache, die es Entwicklern ermöglicht, Felder und Menüs dynamisch auszufüllen. Während die meisten Python-Bibliotheken Daten nur von statischen Webseiten abrufen können, ermöglicht Selenium die Verarbeitung dynamischer Daten.
Was ist die Selenium-Bibliothek?
Selenium ist eine Python-Bibliothek, die auch als Web-Treiber bekannt ist und es ermöglicht, das Verhalten des Benutzers auf der Seite zu simulieren, indem ein echter Browser gestartet wird. Webdriver ist das erste vom W3C entwickelte Browser-Automatisierungsprotokoll, das sich zwischen dem Client und dem Browser befindet und Client-Befehle in Webbrowser-Aktionen übersetzt.
Dadurch kann man die Daten auf der Seite vollständig verarbeiten. Trotzdem ist Selenium ein einsteigerfreundliches Werkzeug. Gehen Sie zur Installation zum Terminal und schreiben Sie:
pip install selenium
Dann aktivieren ChromeDriver für Chrome-Browser oder Geckodriver für Mozilla Firefox. Jetzt ist Selen einsatzbereit.
Um die URL der Seite zu erhalten, führen Sie das Skript aus:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.example.com/items")
Dieses Skript startet den Browser und ruft die URL ab. Es ist jedoch wünschenswert, den Parsing-Prozess für den Benutzer verborgen zu halten. Für diese Zwecke wird der sogenannte Headless-Modus verwendet, der dem Browser die grafische Hülle entzieht und ihn im Hintergrund arbeiten lässt.
In Selenium kann es durch aktiviert werden Optionen Schlüsselwortargument. Der endgültige Beispielcode lautet also:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.headless = True # hide GUI
options.add_argument("--window-size=1920,1080")
# set window size to native GUI size
options.add_argument("start-maximized")
# ensure window is full-screen
driver = webdriver.Chrome(options=options)
driver.get("https://www.example.com/items")
Um dynamische Daten zu analysieren, sollte man den Browser starten und ihn anweisen, zu example.com zu wechseln. Warten Sie dann, bis die Seite geladen ist und ihren Inhalt erhält.
Um HTML-Tags (z. B. Titel) mithilfe von Selektoren zu analysieren, kann Folgendes verwendet werden:
titles = driver.get_elements_by_css_selector('h3')
for title in tiles:
print(title.text)
Denken Sie daran, dass der Parser so lange funktioniert, bis ein Befehl zum Schließen verwendet wird:
driver.quit()
Wozu dient die Selenium-Bibliothek?
Der Hauptnachteil besteht darin, dass das Tool sehr langsam ist und viel Speicher und CPU-Zeit verbraucht. Es ist jedoch das beste Tool zum Parsen von Daten von mit JavaScript generierten Seiten.
Parsen Sie URLs mit URLlib in Komponenten
Vor dem Scraping von Daten ist es notwendig, Links zu analysieren, die für das weitere Scraping verwendet werden. Und Urllib ist eines der besten Tools für die Arbeit mit URLs. Lesen Sie auch darüber Verwendung von cULR in Python hier.
Was ist die URLlib-Bibliothek?
URLlib ist ein Paket mit mehreren Modulen. Bietet grundlegende Funktionen zum Parsen von Webseiten wie Authentifizierung, Weiterleitungen, Cookies usw. Geeignet zum Parsen einer begrenzten Anzahl von Seiten mit anschließender einfacher Datenverarbeitung.
Es handelt sich um eine integrierte Python-Bibliothek. Wenn sie jedoch nicht installiert ist, schreiben Sie einfach in das Terminal:
pip install urllib
Es unterstützt die folgenden URL-Schemata: Datei, FTP, Gopher, HDL, http, https, IMAP, Mailto, MMS, News, NNTP, Prospero, Rsync, RTSP, RTSPU, SFTP, Shttp, SIP, Sips, Snews, SVN, SVN +ssh, telnet, wais, ws, wss.
Eine Anfrage zum Abrufen von Daten mithilfe von URLlib sieht im Allgemeinen wie folgt aus:
urllib.request.urlopen(url, data=None, (timeout, )*, cafile=None, capath=None, cadefault=False, context=None)
Wo:
- URL: Seitenadresse;
- Daten: für GET ist leer; für POST die Art der Bytes;
- Timeout: Timeout in Sekunden;
- cafile: CA-Zertifikat erforderlich, wenn ein HTTPS-Link abgerufen wird;
- capath: Pfad zum CA-Zertifikat;
- context: ist vom Typ ssl.SSLContext und wird zum Angeben von SSL-Einstellungen verwendet.
Wozu dient die URLlib-Bibliothek?
URLlib bietet eine bessere Kontrolle über Anfragen in der Requests-Bibliothek, ist aber auch komplizierter.
Und trotz aller Vor- und Nachteile ist URLLib die beste Bibliothek zum Sammeln von Links.
Alternative Lösung: Pyppeteer
Puppeteer ist ein von Google entwickeltes Tool auf Basis von Node.js. Und Pyppeteer ist so etwas wie Puppeteer für Python.
Was ist Pyppeteer?
Pyppeteer ist ein Python-Wrapper für die JavaScript (Node) Puppeteer-Bibliothek. Es funktioniert ähnlich wie Selenium und unterstützt sowohl den Headless- als auch den Non-Headless-Modus. Allerdings ist die Pyppeteer-Unterstützung auf den Chromium-Browser beschränkt.
Pyppeteer verwendet den asynchronen Mechanismus von Python und erfordert daher zur Ausführung Python 3.5 oder höher. Zum Installieren schreiben Sie einfach:
pip3 install pyppeteer
Versuchen Sie dann, dies im Interpreter auszuführen:
import pyppeteer
Wenn Pyppeteer erfolgreich installiert wurde, liegt kein Fehler vor. Das einfachste Beispiel für die Verwendung von Pyppeteer ist also:
import asyncio
import pyppeteer
async def main():
browser = await pyppeteer.launch()
page = await browser.newPage()
await page.goto('https://example.com/')
await page.screenshot({'path': 'items/item1/item1.png'})
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
Wozu dient der Pyppeteer?
Pyppetter verfügt bereits über einen integrierten Chromium-Browser. Außerdem verbraucht es weniger CPU-Zeit und RAM als Selenium. Es funktioniert jedoch nicht mit anderen Browsern und verfügt nicht über eine vollständige Dokumentation, da es sich um eine nicht offizielle Puppeteer-Shell eines japanischen Entwicklers handelt.
Pyppeteer ist also die beste Wahl, wenn es aufgrund des Ressourcenverbrauchs nicht möglich ist, Selenium zu verwenden, man aber gleichzeitig einen leistungsstarken Scraper schreiben muss.
Zusammenfassung
Was ist also die beste Bibliothek? Leider gibt es auf diese Frage keine eindeutige Antwort. Die Wahl der Bibliothek hängt von den Zielen, dem Umfang und den Ressourcenkapazitäten jeder Person ab.
Für einen Anfänger reichen beispielsweise Requests Library und Beautiful Soup aus, um einfache Probleme zu lösen. Wer etwas Komplexeres ausprobieren möchte und sein Projekt groß genug ist, kann Pyppeteer oder Selenium wählen.
Es gibt also eine Tabelle, die einem bei der Entscheidungsfindung und Auswahl der am besten geeigneten Bibliothek oder des am besten geeigneten Frameworks helfen kann.
Charakteristisch
Anfragen
Wunderschöne Suppe
Scrapy
lxml
Selen
URLlib
Pyppeteer
Zweck
Vereinfachen Sie das Erstellen von HTTP-Anfragen
Parsing
Schaben
Parsing
Vereinfachen Sie das Erstellen von HTTP-Anfragen
Parsen von URLs
Parsing
Anfängerfreundlich
Ja
Ja
NEIN
NEIN
Ja
NEIN
NEIN
Geschwindigkeit
Schnell
Schnell
Langsam
Sehr schnell
Langsam
Schnell
Schnell
Dokumentation
Exzellent
Exzellent
Gut
Gut
Gut
Vielleicht besser
Vielleicht besser
JavaScript-Unterstützung
NEIN
NEIN
NEIN
NEIN
Ja
NEIN
Ja
CPU- und Speichernutzung
Niedrig
Niedrig
Hoch
Niedrig
Hoch
Niedrig
Hoch
Nützlich für Projekte
Groß und klein
Klein
Groß und klein
Groß und klein
Groß und klein
Groß und klein
Groß und klein
Tricks und Tipps für besseres Schaben
Beim Parsen von Daten gibt es immer einige gemeinsame Aufgaben, mit denen jeder konfrontiert ist. Sie sind recht häufig, ebenso wie die Lösungen dafür. Ihr Einsatz spart Zeit und vereinfacht Aufgaben.
Interne Links erhalten
Die BeautifulSoup-Bibliothek kann verwendet werden, um relevante Inhalte abzurufen. Extrahieren Sie beispielsweise interne Links von einer Seite. Um die Aufgabe zu vereinfachen, gehen wir davon aus, dass interne Links Links sind, die mit einem Schrägstrich beginnen.
internalLinks = (
a.get('href') for a in soup.find_all('a')
if a.get('href') and a.get('href').startswith("https://scrape-it.cloud/"))
print(internalLinks)
Sobald man Links hat, kann man die Duplikate entfernen und sie ebenfalls entfernen
Erhalten von Links zu sozialen Netzwerken und E-Mail
Eine weitere typische Aufgabe ist das Sammeln von E-Mail-Adressen und Links zu sozialen Netzwerken. Dazu ist es notwendig, alle Links durchzugehen und zu prüfen, ob Mailto (über das man die E-Mail abrufen kann) und Domänen sozialer Netzwerke vorhanden sind. Solche URLs müssen zur Liste hinzugefügt und angezeigt werden.
links = (a.get('href') for a in soup.find_all('a'))
to_extract = ("facebook.com", "twitter.com", "mailto:")
social_links = ()
for link in links:
for social in to_extract:
if link and social in link:
social_links.append(link)
print(social_links)
Automatisches Schaben des Tisches
In der Regel sind Tabellen gut formatiert und strukturiert, sodass sie leicht durchsucht werden können. Die Zeilen der Tabellen befinden sich im tr Tag, und die Spalten befinden sich im td oder th. Im Allgemeinen sieht eine HTML-Tabelle so aus:
<table>
<tr>
<td>1 row 1 column</td>
<td>1 row 2 column</td>
</tr>
<tr>
<td>2 row 1 column</td>
<td>2 row 2 column</td>
</tr>
</table>
Um Daten aus der Tabelle zu sammeln, ist es notwendig, alle Zeilen zu überprüfen, die Spalten in jeder von ihnen zu überprüfen und den Inhalt auf dem Bildschirm anzuzeigen:
table = soup.find("table", class_="sortable")
output = ()
for row in table.findAll("tr"):
new_row = ()
for cell in row.findAll(("td", "th")):
collapsible.extract()
new_row.append(cell.get_text().strip())
output.append(new_row)
print(output)
Informationen aus Metadaten gewinnen
Nicht alle Daten sind im Code gespeichert, einige können über Schema.org gefunden werden. Und diese Metadaten können folgendermaßen abgerufen werden:
metaDescription = soup.find("meta", {'name': 'description'})
print(metaDescription('content'))
Dadurch werden die Daten aus der Meta-Beschreibung analysiert.
Versteckte Produktinformationen abrufen
Um versteckte Informationen zu erhalten, müssen Sie sie über ein Element im HTML-Code finden und sie wie jedes andere Element analysieren. So analysieren Sie beispielsweise im Tag versteckte Informationen zur Produktmarke:
brand = soup.find('meta', itemprop="brand")
print(brand('content'))
Fazit und Erkenntnisse
Es gibt viele Tools zum Parsen von Daten in Python, von Bibliotheken bis hin zu Frameworks, die das Speichern von Daten in Tabellen, APIs oder auf andere Weise ermöglichen.
Allerdings entscheidet jeder selbst, welches Werkzeug für ihn besser geeignet ist. Für Einfachheit und Komfort muss man mit eingeschränkter Funktionalität oder Geschwindigkeit bezahlen, für mehr Geschwindigkeit und Funktionalität mit Ressourcenintensität.
Wenn man jedoch für jedes einzelne Projekt ein Werkzeug auswählt, kann man das beste Ergebnis erzielen.
Lesen Sie auch über Google Maps Scraper
<h3>Pen</h3>
<span class="price">10$</span>titles = tree.xpath('//h3/text()')
prices = tree.xpath('//span(@class="price")/text()')print('Titles: ', titles)
print('Prices: ', prices)Titles: ('Pen', 'Book')
Prices: ('10$','20$')pip install seleniumfrom selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.example.com/items")from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.headless = True # hide GUI
options.add_argument("--window-size=1920,1080")
# set window size to native GUI size
options.add_argument("start-maximized")
# ensure window is full-screen
driver = webdriver.Chrome(options=options)
driver.get("https://www.example.com/items")titles = driver.get_elements_by_css_selector('h3')
for title in tiles:
print(title.text)driver.quit() pip install urlliburllib.request.urlopen(url, data=None, (timeout, )*, cafile=None, capath=None, cadefault=False, context=None)pip3 install pyppeteerimport pyppeteerimport asyncio
import pyppeteer
async def main():
browser = await pyppeteer.launch()
page = await browser.newPage()
await page.goto('https://example.com/')
await page.screenshot({'path': 'items/item1/item1.png'})
await browser.close()
asyncio.get_event_loop().run_until_complete(main()) internalLinks = (
a.get('href') for a in soup.find_all('a')
if a.get('href') and a.get('href').startswith("https://scrape-it.cloud/"))
print(internalLinks) links = (a.get('href') for a in soup.find_all('a'))
to_extract = ("facebook.com", "twitter.com", "mailto:")
social_links = ()
for link in links:
for social in to_extract:
if link and social in link:
social_links.append(link)
print(social_links)tr Tag, und die Spalten befinden sich im td oder th. Im Allgemeinen sieht eine HTML-Tabelle so aus:<table>
<tr>
<td>1 row 1 column</td>
<td>1 row 2 column</td>
</tr>
<tr>
<td>2 row 1 column</td>
<td>2 row 2 column</td>
</tr>
</table>table = soup.find("table", class_="sortable")
output = ()
for row in table.findAll("tr"):
new_row = ()
for cell in row.findAll(("td", "th")):
collapsible.extract()
new_row.append(cell.get_text().strip())
output.append(new_row)
print(output)metaDescription = soup.find("meta", {'name': 'description'})
print(metaDescription('content'))brand = soup.find('meta', itemprop="brand")
print(brand('content'))Lesen Sie auch über Google Maps Scraper
