
Das Auslesen von Daten aus dem Internet ist ein leistungsstarkes Tool für Menschen, die schnell Online-Informationen sammeln müssen. Mit den richtigen Tools und etwas Know-how ist es einfach, große Datenmengen aus Websites zu extrahieren, um sie in anderen Anwendungen oder Projekten zu verwenden.
Google Sheets ist eines dieser leistungsstarken Tools, mit denen Benutzer problemlos Daten aus Websites extrahieren können, ohne über Programmierkenntnisse zu verfügen. Es eignet sich hervorragend für Anfänger, da Sie keinen Code schreiben müssen, um Daten in Excel (XSLX- oder CSV-Format) zu erhalten – Sie benötigen lediglich einige Grundkenntnisse über Tabellenkalkulationen und Formeln.
Hauptformeln für das Web-Scraping in Google Sheets
Web Scraping mit Google Sheets hat viele Vorteile gegenüber herkömmlichen Methoden, z. B. dass kein großes technisches Fachwissen oder teure Softwarepakete erforderlich sind; mit nur wenigen Klicks schnell aktuelle Informationen abrufen können; Zugriff auf leistungsstarke Funktionen der Abfragesprache, die es einfacher als je zuvor machen; und was am wichtigsten ist: All dies in einer Umgebung tun zu können, die jedem vertraut ist.
Google Sheets bietet verschiedene Möglichkeiten, Daten von Websites zu extrahieren. Die einfachste Methode besteht darin, eine von vier Formeln zu verwenden:
- IMPORTFEED – Abrufen von RSS-Feed-Daten;
- IMPORTHTML – Scraping-Listen und -Tabellen;
- IMPORTDATA – Alle strukturierten Daten importieren;
- IMPORTXML – Verwendung einer XPath-Abfrage zum Abrufen beliebiger Daten von einer Webseite.
Für diejenigen mit Programmierkenntnissen gibt es eine andere Möglichkeit, Daten in Google Sheets zu extrahieren – benutzerdefinierte Skripte, die in GS geschrieben sind, das der Programmiersprache JavaScript ähnelt. Diese Methode bietet mehr Flexibilität, als sich einfach auf die vorhandenen Formeln zu verlassen, da sie es Benutzern ermöglicht, ihren eigenen Code an bestimmte Anforderungen anzupassen.
Scrapen Sie WooCommerce-Produkte mit Google Spreadsheet
WooCommerce ist eine Open-Source-E-Commerce-Plattform, die es Benutzern ermöglicht, Online-Shops mit WordPress zu erstellen. Es ist eine der beliebtesten (mit über 5 Millionen aktiven Installationen) und vielseitigsten verfügbaren Lösungen und bietet eine breite Palette an Funktionen wie anpassbare Produktseiten, mehrere Zahlungsmethoden, Tools zur Bestandsverwaltung und mehr. WooCommerce bietet außerdem leistungsstarke Marketingfunktionen wie Gutscheine, Rabatte und automatisierte Verkaufs-E-Mails. Deshalb haben wir beim Schreiben unseres Scrapers WooCommerce als Beispiel gewählt.
Gute Nachrichten für diejenigen, die Websites mit WooCommerce scrapen möchten – alle Websites, die dieses Plugin verwenden, haben die gleiche Produktstruktur, dieselben Tags und denselben Scraping-Prozess. Das bedeutet, dass Sie, sobald Sie herausgefunden haben, wie Sie eine WooCommerce-Site scrapen, problemlos Daten von fast jedem anderen Shop auf dieser Plattform extrahieren können.
Analysieren der Seite mit Woocommerce
Bevor Sie damit beginnen können, Daten von einer Website zu extrahieren und in Google Sheets zu verarbeiten, müssen Sie sich die Webseite, die Sie durchsuchen möchten, genau ansehen und entscheiden, welche Daten Sie sammeln möchten.
Schauen wir uns einen zufälligen Shop an, der auf der WooCommerce-Plattform basiert. Um den HTML-Code für die Seite anzuzeigen, können Sie Ihre Chrome-Entwicklertools verwenden. Drücken Sie dazu F12 oder klicken Sie mit der rechten Maustaste auf eine leere Stelle auf der Seite und wählen Sie „Inspizieren“ aus dem Menü.
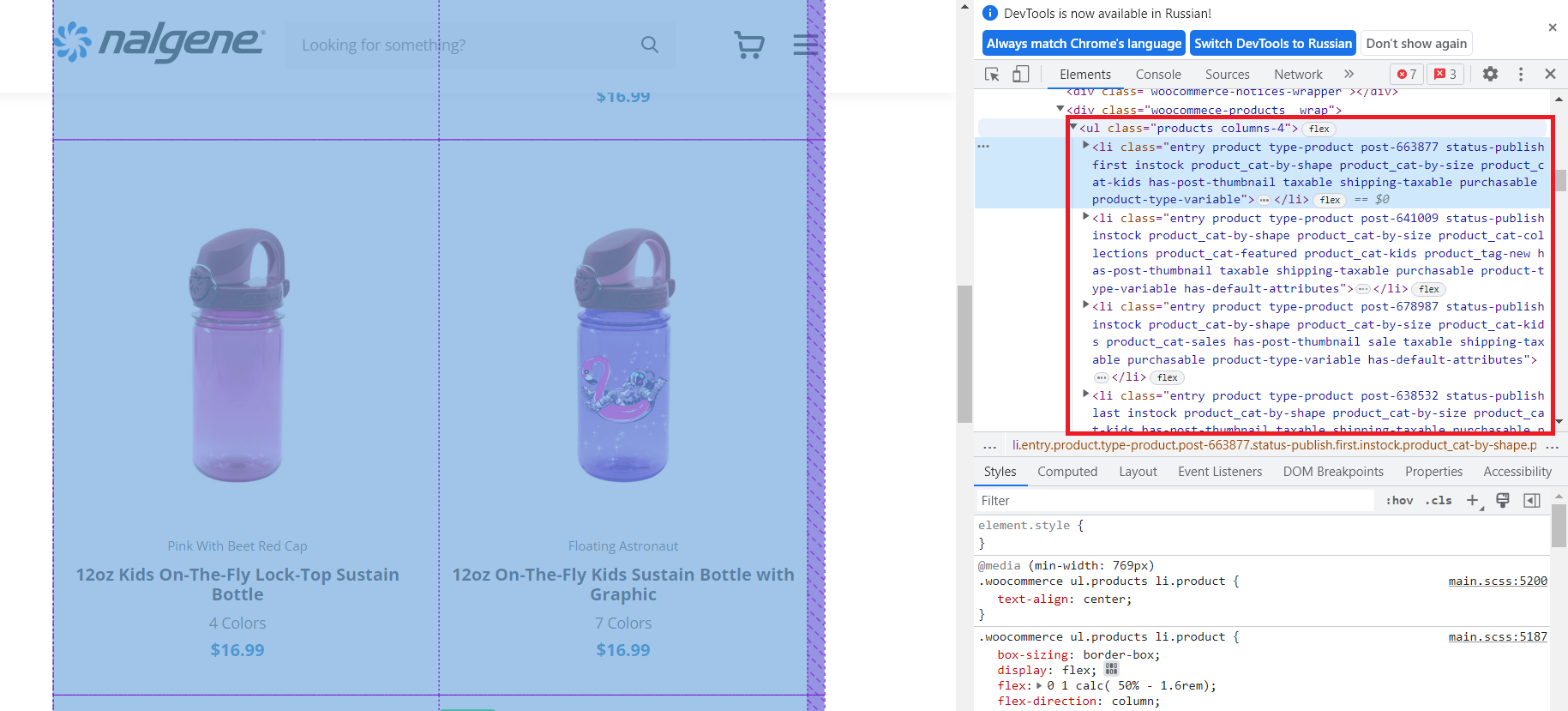
Wie wir sehen können, befinden sich alle Produkte im
- -Tag mit der Klasse „products“. Somit befinden sich alle Produkte in strukturierter Form innerhalb dieses Tags. Wir werden dies verwenden, um die Namen, Links und Preise zu erhalten.
- Der Link zur Produktseite.
- Ein Bild des Produkts.
- Name des Produkts.
- Produktvariationen.
- Der Preis.
Schauen wir uns eines der Produkte genauer an:
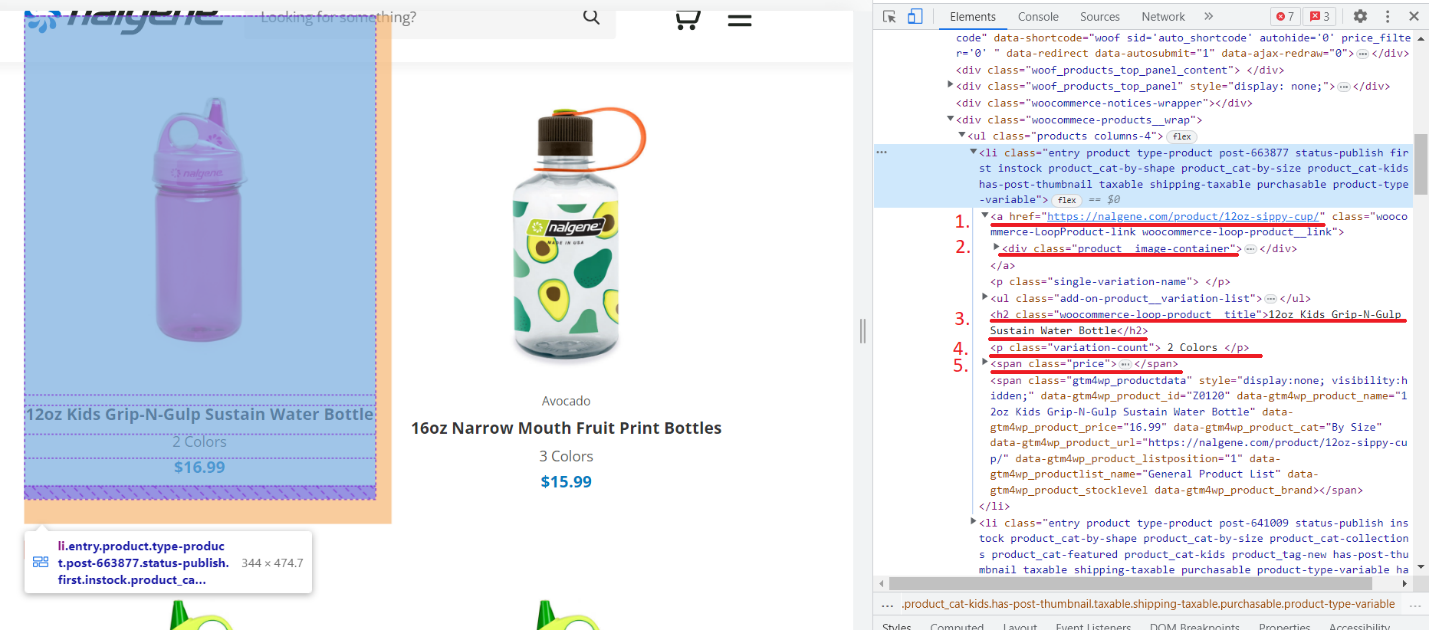
Wir haben die Tags nummeriert, die die Daten enthalten, die wir extrahieren möchten:
Gehen wir nun zur Produktseite und sehen, welche Informationen wir dazu erhalten können.

Hier können wir eine Beschreibung des Produkts, seiner Funktionen und Bewertungen erhalten. Nachdem wir nun alle benötigten Informationen haben, beginnen wir mit dem Hinzufügen von Daten zu Google Sheets.
So verwenden Sie IMPORTXML für Web Scraping in Google Sheets
Um Daten aus dem Beispielspeicher zu extrahieren, verwenden wir die Funktion IMPORTXML(), die es uns ermöglicht, mithilfe von XPath-Abfragen Daten aus einer Webseite zu extrahieren. XPath ist eine Abfragesprache, die zum Navigieren in XML-Dokumenten verwendet wird. Es erfordert einige Grundkenntnisse der HTML- oder XML-Struktur und -Syntax sowie Vertrautheit mit XPath-Ausdrücken. Um Ihnen den Scraping-Prozess zu erleichtern, halten Sie Ausschau nach unserem Tutorial, das Sie durch die Grundlagen des Schreibens eines effektiven XPath-Ausdrucks führt.
Obwohl die Verwendung der IMPORTXML()-Formel einige Programmierkenntnisse erfordert, ist sie nicht allzu schwierig. Wir benötigen einen Link zur Produktseite und den XPath der Artikel, die wir scrapen müssen. Im Allgemeinen sieht die Formel so aus:
=IMPORTXML(URL, XPath)Durchsuchen der Store-Kategorieseite mit Google Sheets
Nehmen wir den Link zur Produktseite einer der Rubriken. Es gibt zwei Möglichkeiten, XPath zu erhalten:
- Verfassen Sie es selbst.
- Aus dem Browser kopieren.
Lassen Sie uns zunächst aus dem Browser kopieren und dann sehen, wie ein selbst kompilierter XPath aussehen würde.
Gehen Sie im Browser zur Kategorieseite und öffnen Sie DevTools. Wählen Sie die Artikelauswahlfunktion und klicken Sie auf den Artikelnamen.
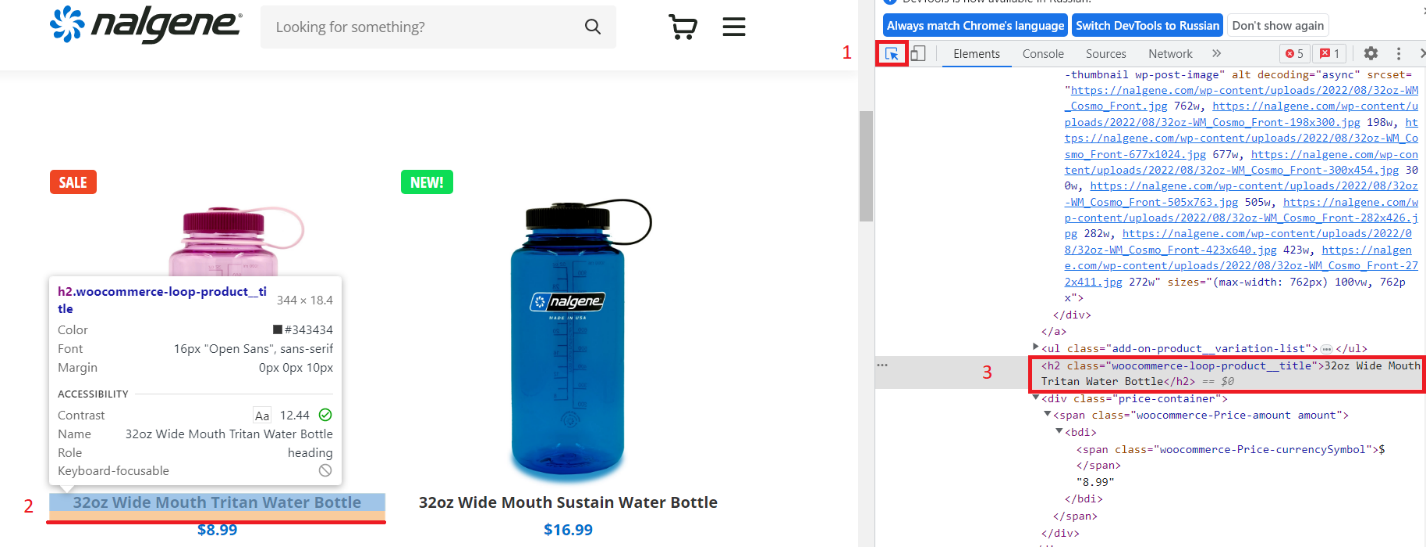
Klicken Sie dann mit der rechten Maustaste auf das Tag mit dem Namen des Produkts und wählen Sie „Kopieren“ – „XPath kopieren“.
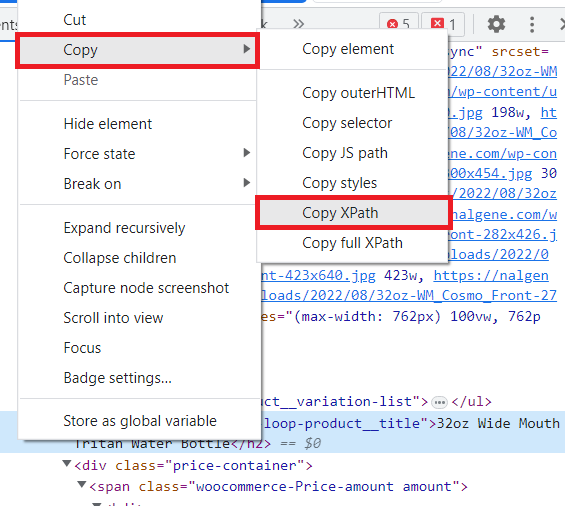
Der resultierende XPath sieht folgendermaßen aus:
/html/body/div(1)/div(2)/div/main/article/div/div(3)/div/div/div/div(1)/h2Gehen wir zu Google Sheets und versuchen, die Titel mithilfe des kopierten XPath abzurufen. Fügen Sie in Zelle A1 einen Link zur Produktseite ein und geben Sie in Zelle B1 die Formel ein:
=IMPORTXML(A1,"/html/body/div(1)/div(2)/div/main/article/div/div(3)/div/div/div/div(1)/h2")Infolgedessen erhalten wir nur einen Titel. Um dies zu beheben, ändern wir den XPath:
=IMPORTXML(A1,"/html/body/div(1)/div(2)/div/main/article/div/div(3)/div/div/div/div/h2")Jetzt haben wir alle Artikel. Dieser XPath ist jedoch lang und schwer zu verstehen. Lassen Sie uns also selbst einen geeigneten XPath erstellen.
Schauen wir uns den Tag mit dem Titel einmal genauer an:
<h2 class="woocommerce-loop-product__title">32oz Wide Mouth Tritan Water Bottle</h2>Wie wir sehen können, handelt es sich hierbei um einen h2-Tag mit der Klasse „woocommerce-loop-product__title“. In XPath sieht es so aus:
//h2(@class="woocommerce-loop-product__title")Ersetzen Sie den Inhalt der Zelle durch eine neue Formel:
=IMPORTXML(A1,"//h2(@class="woocommerce-loop-product__title")")Als Ergebnis erhalten wir die gleiche Liste wie zuvor, aber XPath sieht jetzt klarer aus und noch besser: Es eignet sich nicht nur für die Verwendung auf dieser Website, sondern auch auf anderen Websites, die WooCommerce verwenden.
Scrapen der Kategorielinks mit Google Sheets
Es ist jedoch schwierig und zeitaufwändig, alle Kategorieseiten manuell zu umgehen und deren Links abzurufen. Hier haben wir einen Link zu einer Kategorie verwendet, die wir selbst gefunden haben. Aber lassen Sie uns alle Kategorielinks automatisch mit der Formel IMPORTLXML() erfassen.
Lassen Sie uns zunächst alle Links auf der Seite abrufen:
=IMPORTXML("https://nalgene.com/#","//li/a/@href")Einige Links sind jedoch doppelt vorhanden und können störend sein. Daher verwenden wir die Formel QUNIQUE(), um nur eindeutige Werte zu belassen.
=UNIQUE(IMPORTXML("https://nalgene.com/#","//li/a/@href"))Verwenden Sie nun die Funktion REGEMATCH() in FILTER(), um nur die Links zu belassen, die „product-category“ enthalten:
=FILTER(UNIQUE(IMPORTXML("https://nalgene.com/#","//li/a/@href")),REGEXMATCH(UNIQUE(IMPORTXML("https://nalgene.com/#","//li/a/@href")),"product-category"))Auf diese Weise erhalten wir Links zu allen Kategorien:
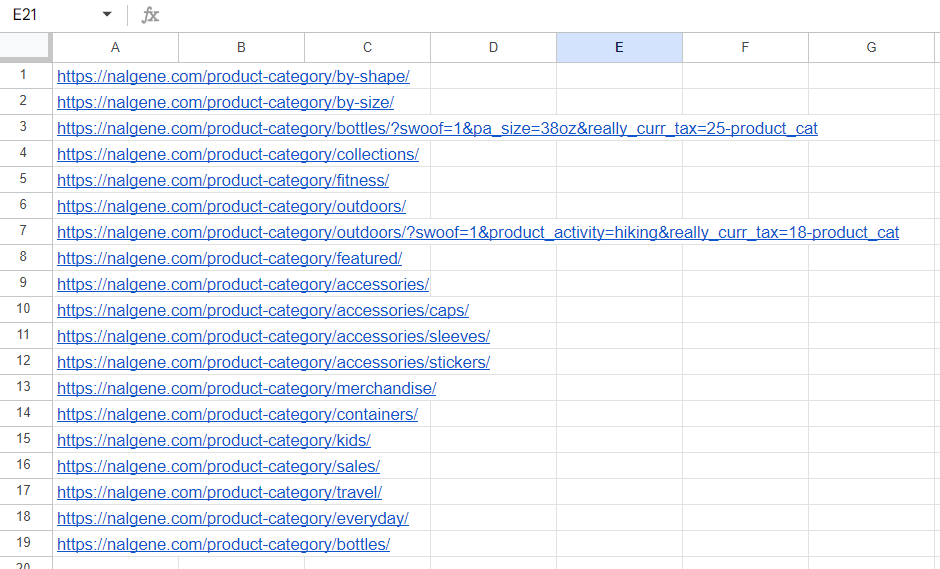
Leider unterstützt die Funktion IMPORTXML() keine Arrays. Daher können wir keine Spalte mit Links angeben und Daten für alle Produkte abrufen. Daher müssen wir die Links immer noch manuell ersetzen, aber jetzt haben wir Links zu allen Kategorien.
Produktdaten aus dem WooCommerce-Shop entfernen
Sammeln wir weiterhin Daten zu Produkten auf der Kategorieseite. Manchmal kommt es vor, dass wir nicht den Text eines Tags, sondern das Attribut dieses Tags benötigen. Geben Sie dazu am Ende Ihres XPath ein Attribut an und rufen Sie dessen Inhalt mithilfe eines „@“-Symbols ab. Lassen Sie uns beispielsweise Links zu Artikeln erhalten. Schauen Sie sich zunächst das Item-Link-Tag an:
<div class="add-on-product">
<a href="https://nalgene.com/product/32oz-wide-mouth-bottle-tritan/">
…
</a>
</div>Schreiben Sie den entsprechenden XPath:
//div(@class="add-on-product")/a/@hrefWie Sie sehen, ist alles ganz einfach. Schreiben wir den XPath für die letzten beiden Elemente auf:
- Preis: //div(@class=“price-container“)
- Bild: //div(@class=“add-on-product__image-container“)/img/@src
Tragen wir alle Formeln in die Tabelle ein (nur XPath wird geändert) und sehen wir uns das Ergebnis an:
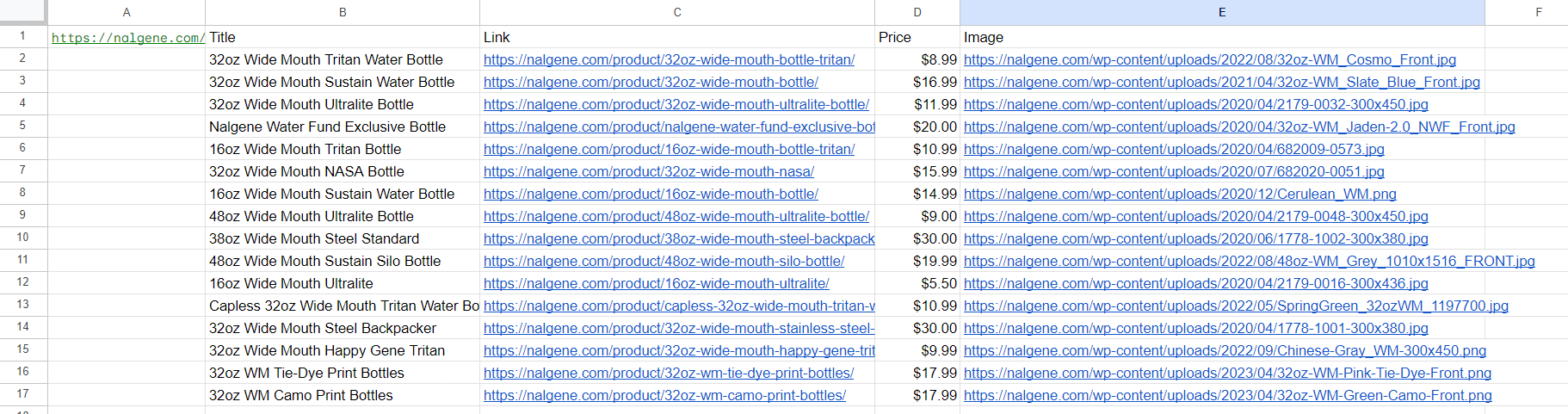
Fügen wir nun eine Beschreibung der Produkte hinzu. Wir haben in Spalte C bereits Links zu Produktseiten, also nutzen wir diese. Geben Sie in Spalte F die Formel ein, um die Beschreibung zu erhalten:
=IMPORTXML(C4,"//div(@class="product-description__wrap")")Als Ergebnis erhalten wir eine vollständige Tabelle mit Daten zu Produkten und deren Beschreibungen. Wenn wir es dabei belassen, wird die Beschreibung in mehrere Spalten unterteilt, so wie sie auf der Website in Absätze unterteilt sind. Um sie zusammenzusetzen, verwenden wir die Funktion CONCATENATE():
=concatenate(IMPORTXML((C2),"//div(@class="product-description__wrap")"))Das Ergebnis ist eine Tabelle mit Beschreibungen:
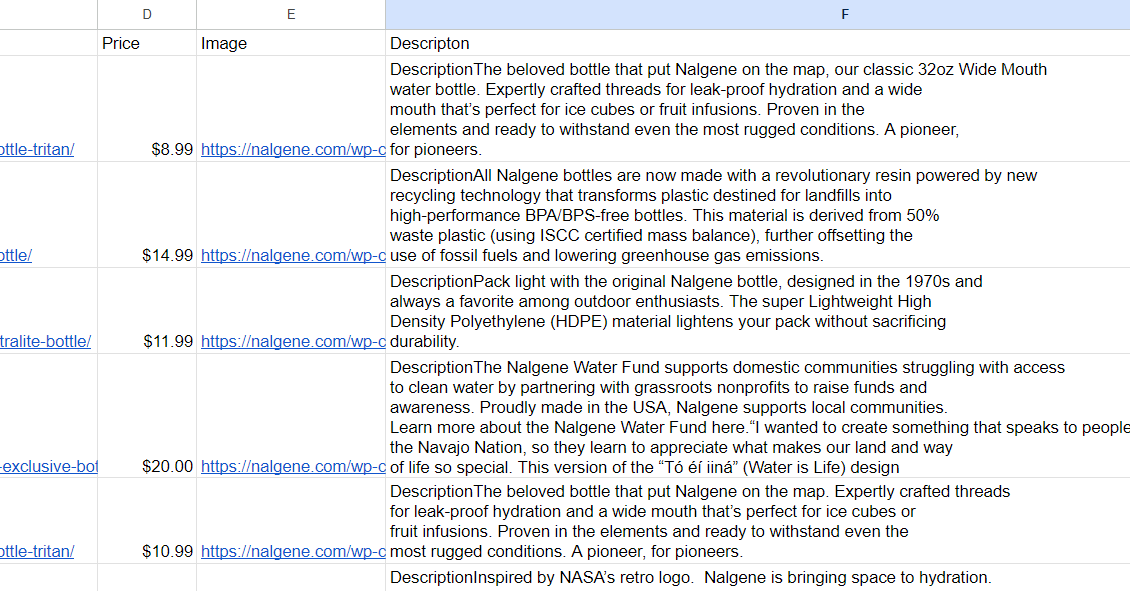
Leider hat die Funktion CONCATENATE() einen großen Nachteil: Sie verbindet Teile ohne Trennzeichen und ist daher nicht sehr praktisch. Da die Daten als Array und nicht als String zurückgegeben werden, können wir die Funktion TEXTJOIN() nicht verwenden, die uns die Angabe von Trennzeichen ermöglicht.
Vor- und Nachteile von IMPORTXML() für Web Scraping mit Google Sheets
IMPORTXML() ist ein leistungsstarkes Tool zum schnellen und einfachen Sammeln großer Informationsmengen in Google Sheets. Es hilft, Daten von Websites direkt in eine Tabelle zu kopieren. Es ist jedoch wichtig, die Vor- und Nachteile abzuwägen, bevor Sie entscheiden, ob dies die richtige Option für Sie ist.
| Vorteile | Nachteile |
|---|---|
| Einfach zu verwenden, ohne dass Programmierkenntnisse erforderlich sind | Begrenzte Anzahl von Abfragen (1000 Abfragen pro Stunde) |
| Kann Daten schnell in eine Tabellenkalkulation importieren | Begrenzte Fähigkeit, dynamische Websites zu navigieren |
| Funktioniert mit den meisten Websites | Kann beim Scrapen großer Datenmengen langsam sein |
| Kostenlose Nutzung | Scrapen Sie nur eine URL in einer Formel |
Die IMPORTXML-Formel eignet sich perfekt für Web-Scraping-Projekte, bei denen Sie spezifische Informationen benötigen, um Trends zu analysieren oder andere Aufgaben zu bearbeiten. Daher ist es die beste Wahl für diejenigen, die nicht gut im Programmieren sind. Wenn Sie jedoch mit der Programmierung vertraut sind und komplexere Aufgaben ausführen müssen, ist es an der Zeit, über Google App Scripts nachzudenken.
Web Scraping mit Google Sheets Apps Script
Google Sheets verfügt über ein leistungsstarkes Tool zum Erstellen von Skripten – App Scripts. Mit diesem Tool können Sie viele Aufgaben, die sonst Stunden dauern würden, schnell und einfach automatisieren. Und wenn Sie auf komplexere Daten zugreifen möchten, als in der Tabellenkalkulationsschnittstelle verfügbar sind, können Sie Web Scraping-APIs verwenden.
Google App Scripts verwendet JavaScript als Programmiersprache. Mit diesem Tool haben Benutzer Zugriff auf Funktionen wie das Erstellen benutzerdefinierter Menüs oder Schaltflächen; Zugriff auf Dienste Dritter; Bearbeiten von in Drive gespeicherten Dokumenten; Senden Sie E-Mails direkt von Ihren Tabellen aus oder greifen Sie sogar auf externe Ressourcen zu.
Um den Bereich „App-Skripte“ zu öffnen, gehen Sie zu „Erweiterungen – App-Skripte“.

Als Beispiel verwenden wir die Web-Scraping-API Scrape-It.Cloud. Nach der Anmeldung erhalten Sie 1.000 Gratis-Credits, die Ihnen den Einstieg erleichtern.
Erstellen wir zunächst ein einfaches Skript, das den gesamten Code der Seite abruft. Nachdem wir App Script gestartet haben, gelangen wir zum Skriptfenster.
Wir können die Funktion anders benennen, um sie bequemer zu machen, oder wir können den gleichen Namen belassen. Dies wirkt sich darauf aus, wie wir auf dem Blatt auf unser Skript verweisen. Der Funktionsname ist der Name der Formel.
Wenn Sie nicht lernen möchten, wie Sie Ihr eigenes Skript erstellen, sondern das fertige Ergebnis verwenden möchten, fahren Sie mit dem endgültigen Code und einer Erklärung seiner Funktionsweise fort.
Um eine Abfrage auszuführen, müssen wir ihre Parameter festlegen. Den API-Schlüssel finden Sie in Ihrem Konto im Dashboard-Bereich. Legen wir zunächst die Header fest:
var headers = {'contentType':'application/json','x-api-key': 'YOUR-API-KEY};Als Nächstes geben wir den Hauptteil der Anfrage an. Da wir den Code der gesamten Seite benötigen, geben wir lediglich den Link zu der Site an, von der wir Daten sammeln müssen:
var data ={'url': 'https://nalgene.com/water-bottles/wide-mouth/'};Zum Schluss sammeln wir die Abfrage, führen sie aus und zeigen das Ergebnis an:
var options = {
'method': 'post',
'headers': headers,
'payload': data
};
var response = UrlFetchApp.fetch('https://api.scrape-it.cloud/scrape', options).getContentText();
Logger.log(response);Als Ergebnis erhalten wir Folgendes:
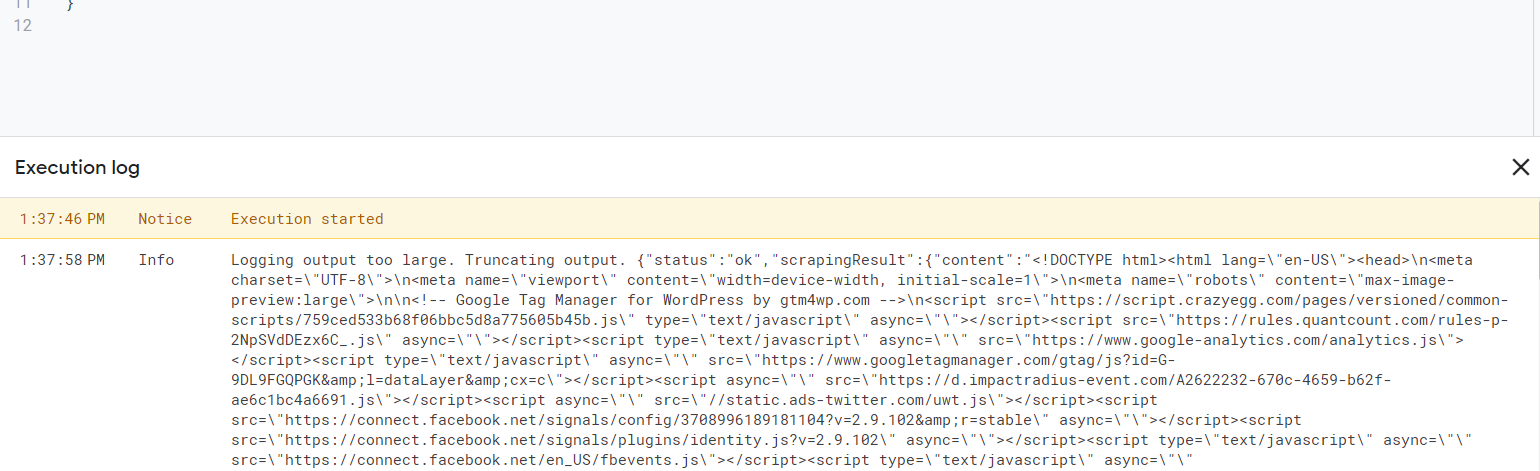
Sie können die Datenextraktionseinstellungen in Ihrem Konto im Abschnitt Web Scraping API konfigurieren. Dort können Sie die Abfrage auch visuell über spezielle Funktionen konfigurieren.
Beispielsweise können wir die Funktion „Ausführungsregeln“ verwenden, um nur die Produktnamen und Preise zu extrahieren:
"extract_rules": {
"title": "h2.woocommerce-loop-product__title",
"price": "div.price-container"
},Das Hinzufügen neuer Regeln wird im Format „Name“: „CSS-Selektor“ angegeben. Es ist nicht sehr praktisch, diese Parameter fest in das Skript zu schreiben. Um die Formel dynamisch zu gestalten, wäre es praktisch, diese Parameter auf dem Blatt zu übergeben. Fügen wir diese Daten also zur Eingabe hinzu. Eingabeparameter werden in Klammern neben dem Funktionsnamen angegeben.
function myFunction(...rules) {…}Das bedeutet, dass wir mehrere Parameter erhalten, die in die Regelvariable eingegeben werden müssen. Der Einfachheit halber benennen wir die Funktion um und fügen der Eingabe einen weiteren Parameter hinzu – einen Link zu der Seite, von der die Daten erfasst werden.
function scrape_it(url, ...rules) {…}Lassen Sie uns nun die Variablen deklarieren und die Header für die zukünftige Tabelle aus den Extraktionsregeln auswählen, die wir erhalten haben:
var extract_rules = {};
var headers = true;
// Check if the last argument is a boolean
if (typeof rules(rules.length - 1) === "boolean") {
headers = rules.pop();
}Schreiben wir die Regeln in der benötigten Form in die Variable extract_rules:
for (var i = 0; i < rules.length; i++) {
var rule = rules(i).split(":");
extract_rules(rule(0)) = rule(1).trim();
}Lassen Sie uns den Hauptteil der Abfrage ändern, indem wir Variablen anstelle von Werten einfügen und sie dann ausführen.
var data = JSON.stringify({
"extract_rules": extract_rules,
"wait": 0,
"screenshot": false,
"block_resources": true,
"url": url
});
var options = {
"method": "post",
"headers": {
"x-api-key": "YOUR-API-KEY",
"Content-Type": "application/json"
},
"payload": data
};
var response = UrlFetchApp.fetch("https://api.scrape-it.cloud/scrape", options);
Diese Abfrage gibt Daten als JSON mit Attributen zurück, die die erforderlichen Daten enthalten und deren Name mit dem Namen identisch ist, den wir in den Extraktionsregeln festgelegt haben. Um diese Daten zu erhalten, analysieren wir die JSON-Antwort:
var json = JSON.parse(response.getContentText());Legen wir die Attributvariable fest, die das Ergebnis der Extraktionsregeln enthält:
var result = json("scrapingResult")("extractedData");Ermitteln Sie alle Schlüssel und die Länge des größten Arrays, um dessen Dimensionalität zu ermitteln:
// Get the keys from extract_rules
var keys = Object.keys(extract_rules);
// Get the maximum length of any array in extractedData
var maxLength = 0;
for (var i = 0; i < keys.length; i++) {
var length = Array.isArray(result(keys(i))) ? result(keys(i)).length : 1;
if (length > maxLength) {
maxLength = length;
}
}
Erstellen Sie eine variable Ausgabe, in die wir die erste Datenzeile einfügen, die die Spaltennamen der zukünftigen Tabelle sein wird. Überprüfen Sie dazu die Überschriften und Schlüssel, damit wir nur die Spalten eingeben können, für die die Daten gefunden wurden.
// Create an empty output array with the first row being the keys (if headers is true)
var output = headers ? (keys) : ();Lassen Sie uns alle Elemente aus den Extraktionsregeln durchgehen und sie Zeile für Zeile zur Ausgabevariablen hinzufügen.
// Loop over each item in the extractedData arrays and push them to the output array
for (var i = 0; i < maxLength; i++) {
var row = ();
for (var j = 0; j < keys.length; j++) {
var value = "";
if (Array.isArray(result(keys(j))) && result(keys(j))(i)) {
value = result(keys(j))(i);
} else if (typeof result(keys(j)) === "string") {
value = result(keys(j));
}
row.push(value.trim());
}
output.push(row);
}
Zum Schluss bringen wir das Ergebnis noch einmal aufs Blatt:
return output;Jetzt können Sie das resultierende Skript speichern und es unter Angabe der erforderlichen Parameter direkt aus dem Blatt aufrufen.
Endgültiger Code für Web Scraping mit Google App Script
Bevor wir uns mit den ersten Schritten mit dem vorgefertigten App-Skript befassen, schauen wir uns an, was für diejenigen zu tun ist, die den Abschnitt zum Erstellen eines Skripts übersprungen haben, es aber verwenden möchten.
Gehen Sie zu Google Sheets und erstellen Sie eine neue Tabelle.
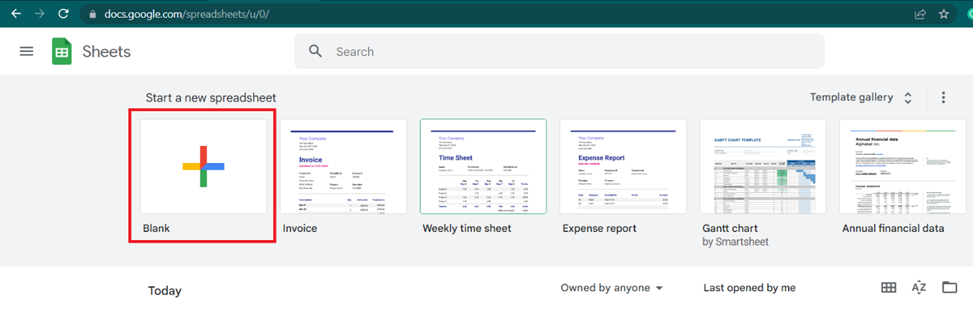
Gehen Sie zu Erweiterungen und öffnen Sie App Scripts. Wählen Sie im angezeigten Fenster den gesamten Text aus und ersetzen Sie ihn durch unseren Skriptcode:

Skriptcode:
function scrape_it(url, ...rules) {
var extract_rules = {};
var headers = true;
// Check if the last argument is a boolean
if (typeof rules(rules.length - 1) === "boolean") {
headers = rules.pop();
}
for (var i = 0; i < rules.length; i++) {
var rule = rules(i).split(":");
extract_rules(rule(0)) = rule(1).trim();
}
var data = JSON.stringify({
"extract_rules": extract_rules,
"wait": 0,
"screenshot": false,
"block_resources": true,
"url": url
});
var options = {
"method": "post",
"headers": {
"x-api-key": "YOUR-API-KEY",
"Content-Type": "application/json"
},
"payload": data
};
var response = UrlFetchApp.fetch("https://api.scrape-it.cloud/scrape", options);
var json = JSON.parse(response.getContentText());
var result = json("scrapingResult")("extractedData");
// Get the keys from extract_rules
var keys = Object.keys(extract_rules);
// Get the maximum length of any array in extractedData
var maxLength = 0;
for (var i = 0; i < keys.length; i++) {
var length = Array.isArray(result(keys(i))) ? result(keys(i)).length : 1;
if (length > maxLength) {
maxLength = length;
}
}
// Create an empty output array with the first row being the keys (if headers is true)
var output = headers ? (keys) : ();
// Loop over each item in the extractedData arrays and push them to the output array
for (var i = 0; i < maxLength; i++) {
var row = ();
for (var j = 0; j < keys.length; j++) {
var value = "";
if (Array.isArray(result(keys(j))) && result(keys(j))(i)) {
value = result(keys(j))(i);
} else if (typeof result(keys(j)) === "string") {
value = result(keys(j));
}
row.push(value.trim());
}
output.push(row);
}
return output;
}
Geben Sie anstelle von „IHR-API-SCHLÜSSEL“ Ihren API-Schlüssel ein, den Sie in Ihrem Konto im Dashboard-Bereich bei Scrape-It.Cloud finden, und speichern Sie ihn.
Schauen wir uns nun das Ergebnis der Arbeit an. Kehren wir zum Blatt zurück, fügen den Link zur Seite in Zelle A1 ein und geben in der nächsten Zelle die Formel an. Im Allgemeinen sieht die Formel so aus:
=scrape_it(URL, element1, (element2), (false))Wo:
- Die URL ist ein Link zur Seite, die gescrapt werden soll.
- Elemente (Sie können mehr als eines angeben). Elemente werden im Format „Titel: CSS_Selector @attribute“ angegeben. Geben Sie anstelle von Titel den Namen des Elements an, geben Sie dann über einen Doppelpunkt den CSS-Selektor des Elements an und geben Sie ggf. über ein Leerzeichen und @ das Attribut an, dessen Wert erforderlich ist. Wenn nur Elementtext benötigt wird, wird kein Attribut angegeben. Zum Beispiel:
- „Titel: h2“ – um den Produktnamen zu erhalten.
- „link: a @href“ – um den Produktlink zu erhalten.
- (FALSCH). Dies ist ein optionaler Parameter, der standardmäßig verwendet wird WAHR. Es gibt an, ob die Überschriften der Spalten gespeichert werden sollen oder nicht. Wenn Sie nichts angeben, wird der Header in der ersten Zelle angegeben und aus dem Elements-Parameter übernommen. Wenn Sie angeben FALSCHSpaltenüberschriften werden nicht angegeben und gespeichert.
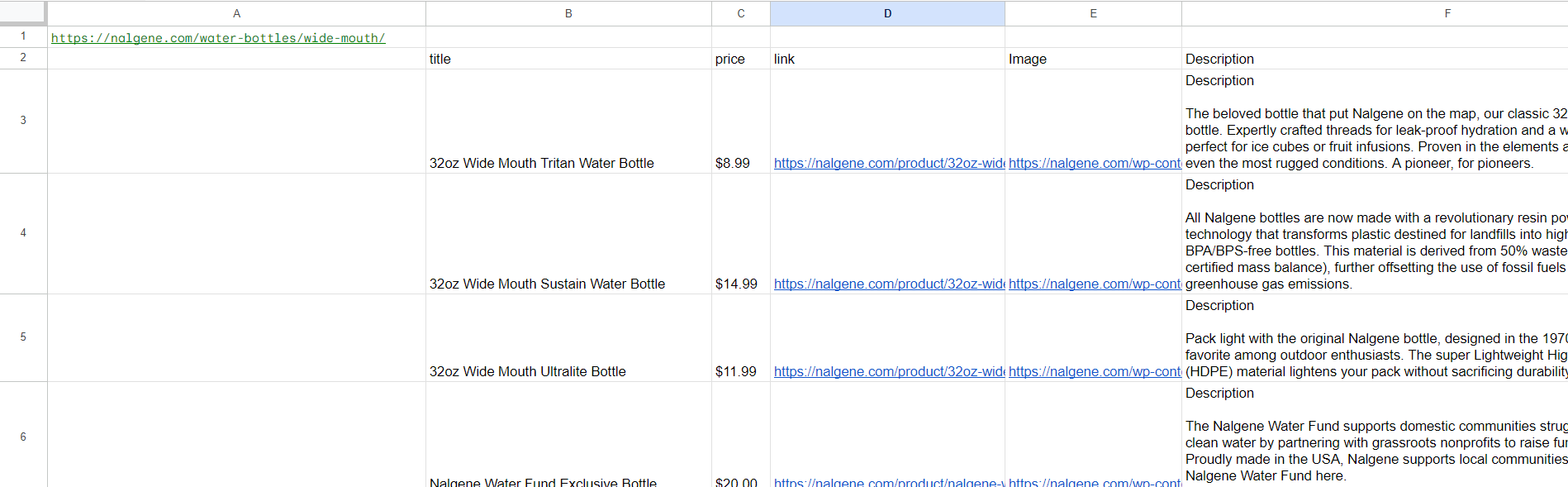
Lassen Sie uns nun mit all den Fähigkeiten, die wir gelernt haben, eine Tabelle erstellen, die mit der identisch ist, die wir mit IMPORTXML erhalten haben, aber unter Verwendung der scrape_it-Formel:
=scrape_it(A1,"title: h2.woocommerce-loop-product__title", "price: div.price-container","link:div.add-on-product>a @href", "Image:div.add-on-product__image-container>img @src")Als Ergebnis haben wir die folgende Tabelle erhalten:
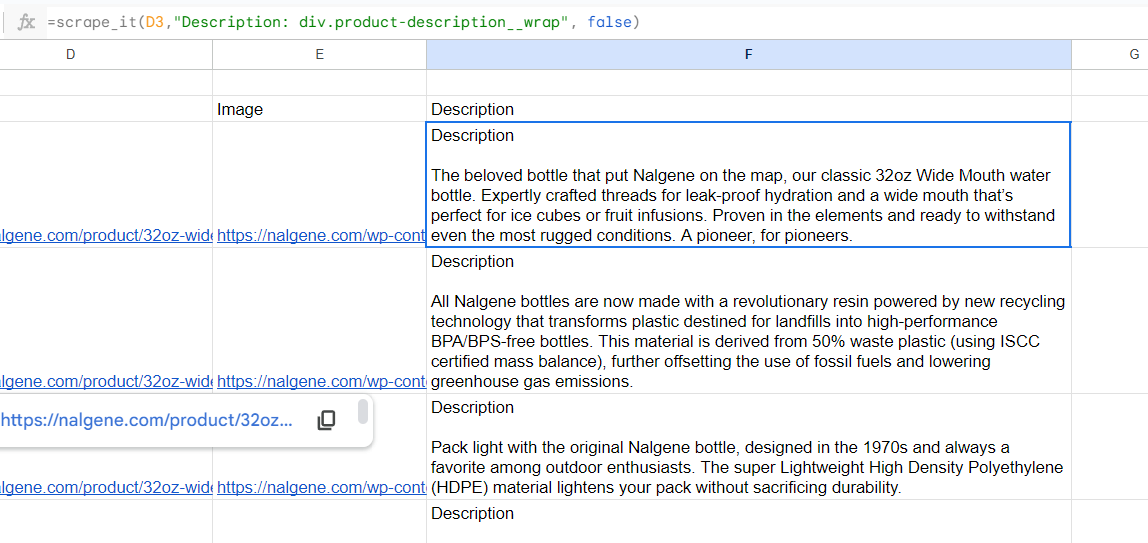
Allerdings müssen wir die Beschreibung von jeder einzelnen Produktseite abrufen, sodass wir keine Überschriften angeben müssen. In diesem Fall müssen wir den dritten zusätzlichen Parameter angeben FALSCH, am Ende der Formel:
Scraping mit Google Sheets und App Scripts kann ein leistungsstarkes Tool zur Datenerfassung und -analyse sein. Mit Hilfe der Skriptsprache von Google können Sie problemlos auf externe Websites zugreifen, um Informationen abzurufen, die Web-Scraping-API für Automatisierungsprozesse verwenden oder sogar Ergebnisse auf die für Ihren Zweck geeignete Weise manipulieren.
Es ist praktisch, wenn IMPORTXML nicht verwendet werden kann. Beispielsweise können Sie IMPORTXML nicht für Websites mit dynamischem Rendering verwenden. Allerdings kann die Verwendung von Google App Scripts zusammen mit der Web Scraping API dieses Problem lösen. Das betrachtete Skript eignet sich zum Scrapen jeder Site, unabhängig davon, auf welcher Plattform sie basiert, ob sie über dynamisches Rendering verfügt oder nicht.
Fazit und Erkenntnisse
Das Web-Scraping von Daten mit Google Sheets ist eine großartige Möglichkeit, schnell Daten von Websites zu sammeln und zu organisieren. Es ist ein benutzerfreundliches Tool, das von jedem verwendet werden kann, auch von denen, die keine Programmierkenntnisse oder -erfahrung haben. Mit den richtigen Schritten können Sie in nur wenigen Minuten leistungsstarke Web-Scraper erstellen. Von da an liegt es an Ihnen, wie Sie Ihre neu gesammelten Informationen nutzen möchten – sei es für die Marktforschung oder die Erstellung eigener benutzerdefinierter Berichte.
Mit Scraping-Tools wie Google Sheets hat jeder Zugriff auf wertvolle Website-Daten, ohne dass zusätzliche Ressourcen oder teure Softwareprogramme erforderlich sind. Darüber hinaus machen die integrierten Funktionen das Bereinigen unordentlicher Datensätze einfach und schnell – das spart Zeit bei manuellen Aufgaben, sodass Sie sich auf das Wesentliche konzentrieren können: die Nutzung der aus Ihren gekratzten Daten gewonnenen Erkenntnisse.
