
TL;DR: Google Jobs Python Scraper
Für alle, die es eilig haben, gibt es hier eine schnelle Möglichkeit, Google Jobs für mehrere Abfragen mit Python und ScraperAPI zu scrapen:
import requests
queries = ('video editor', 'python developer')
for query in queries:
payload = {
'api_key': 'YOUR_API_KEY',
'query': query,
'country_code': 'us',
'output_format': 'csv'
}
response = requests.get('https://api.scraperapi.com/structured/google/jobs', params=payload)
if response.status_code == 200:
filename = f'{query.replace(" ", "_")}_jobs_data.csv'
with open(filename, 'w', newline='', encoding='utf-8') as file:
file.write(response.text)
print(f"Data for {query} saved to {filename}")
else:
print(f"Error {response.status_code} for query {query}: {response.text}")
Dieser Scraper durchläuft eine Liste von Jobabfragen, sendet Anfragen über den Google Jobs-Endpunkt von ScraperAPI und speichert die Ergebnisse als CSV-Dateien.
Möchten Sie erfahren, wie es gebaut wurde? Lesen Sie weiter!
Die Herausforderungen beim Scraping von Google-Jobs
Google Jobs (oder Google for Jobs) ist eine der weltweit bedeutendsten Quellen für Stellenangebote. Es sammelt Stellenangebote von Millionen von Websites an einem Ort, sodass Arbeitssuchende in den Google-Suchergebnissen die richtige Gelegenheit finden können.
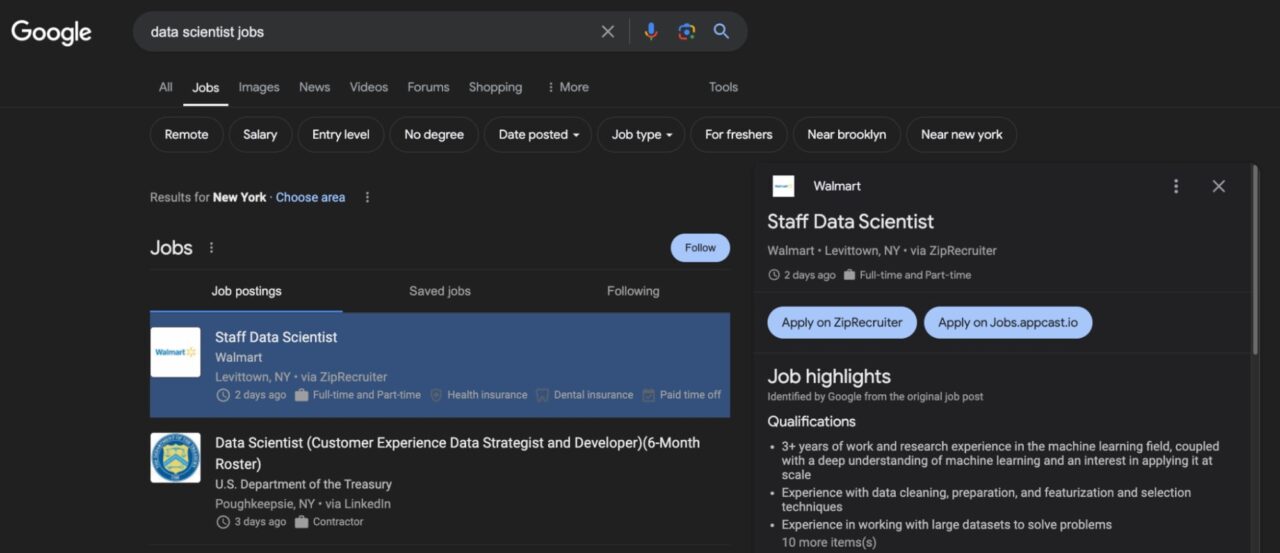
Da diese Ergebnisse öffentlich verfügbar sind, können wir die Stellenangebote bei Google legal und unter Einhaltung ethischer Praktiken durchsuchen, um eine Überlastung des Dienstes zu vermeiden.
Es gibt jedoch einige Herausforderungen, die diese Aufgabe erschweren:
- Anti-Scraping-Mechanismen von Google: Als Teil der Google-Dienste verfügt Google Jobs über fortschrittliche Bot-Erkennungssysteme, die schnell erkennen können, wenn ein Mensch eine Anfrage stellt. Dazu können beispielsweise CAPTCHA-Herausforderungen und Ratenbegrenzungen gehören.
- JavaScript-Rendering: Wenn Sie die Website genauer untersuchen, werden Sie feststellen, dass die Daten, die Sie auf Ihrem Bildschirm sehen, nicht im HTML der Website enthalten sind. Stattdessen werden sie dynamisch über JavaScript eingefügt. Dies fügt eine weitere Komplexitätsebene hinzu und zwingt uns, einen Weg zu finden, die Seite zu rendern, bevor wir auf Daten zugreifen können.
- Endloses Scrollen: Im Zusammenhang mit den vorherigen Herausforderungen werden neue Google Jobs-Einträge nur dann auf die Seite geladen, wenn nach unten gescrollt wird. Mit anderen Worten: Wir müssen auch mit der Seite interagieren, wenn wir eine signifikante Menge an Daten sammeln möchten.
- Geospezifische Daten: Obwohl es an sich keine Herausforderung darstellt, zeigt Google Jobs je nach IP-Standort unterschiedliche Ergebnisse an. Wenn Sie beispielsweise Daten aus den USA abrufen möchten, aber wie ich in Italien ansässig sind, müssen Sie einen Weg finden, Ihren IP-Standort zu ändern (Geotargeting).
Um diese Herausforderungen – und alle anderen Hindernisse auf unserem Weg – zu überwinden, verwende ich ScraperAPI, um:
- Greifen Sie auf einen Pool von über 40 Millionen Proxys in über 50 Ländern zu
- Meine Proxys automatisch rotieren lassen, um eine hohe Erfolgsrate sicherzustellen
- Wandeln Sie Google Jobs-HTML-Rohdaten in strukturierte JSON-Daten um
Scraping von Google-Jobs mit Python und ScraperAPI
ScraperAPI bietet einen einfach zu verwendenden Google Jobs-Endpunkt zum Sammeln von Stellenangeboten für jede gewünschte Abfrage, ohne dass wir eine komplexe Infrastruktur aufbauen oder einen Headless-Browser verwenden müssen.
Indem wir unsere Anfragen über den Endpunkt senden, übernimmt ScraperAPI das JS-Rendering, die CAPTCHA-Verarbeitung und die Proxy-Rotation für uns und gibt Auftragsdaten im JSON-Format zurück, wodurch wir Entwicklungsstunden, Datenanalyse und -bereinigung sparen.
Lassen Sie uns für dieses Beispielprojekt Daten für die Abfrage „Video-Editor“ sammeln.
Google Jobs Layoutübersicht
Wenn Sie zu Google navigieren und nach Jobs für Videoeditorgelangen Sie auf eine Seite ähnlich dieser:
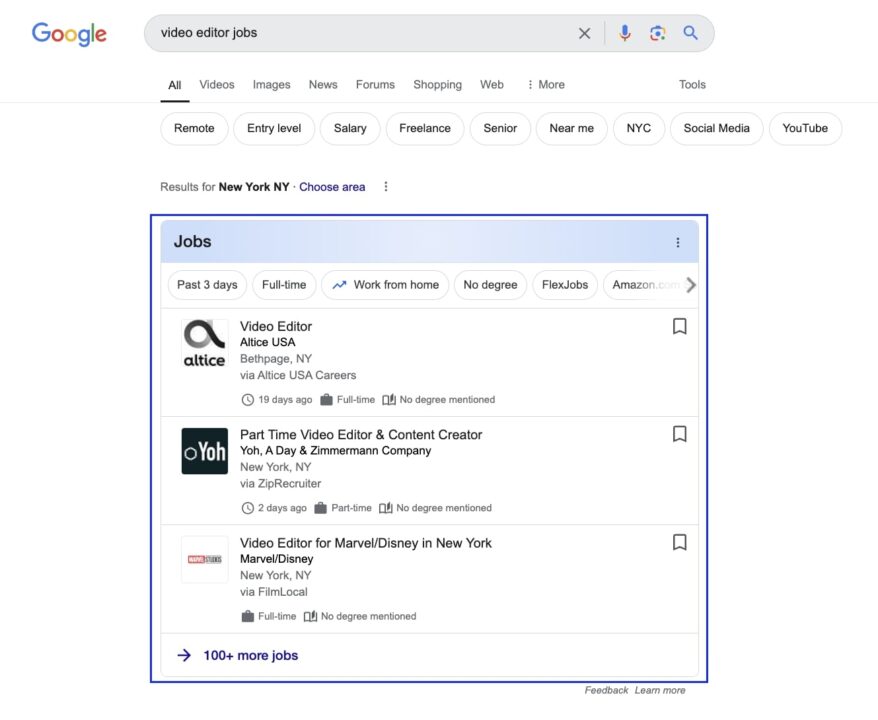
Wenn Sie auf das Feld klicken, gelangen Sie zur Hauptoberfläche von Google Jobs. Auf der linken Seite sind alle Stellenangebote aufgeführt, auf der rechten Seite werden weitere Details angezeigt.
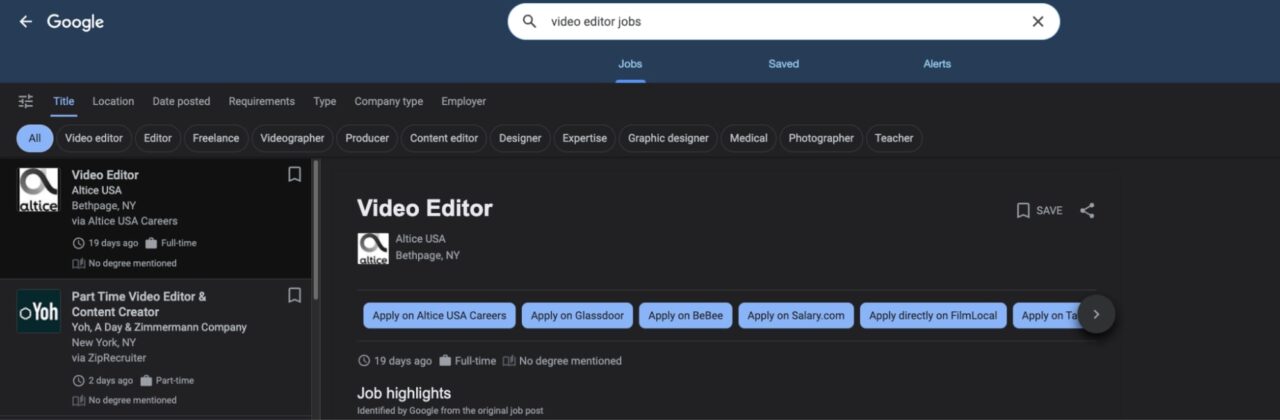
Von hier aus können wir auf der linken Karte auf einige grundlegende Informationen zugreifen, wie etwa auf die Berufsbezeichnung, das Unternehmen, das die Stelle anbietet, den Arbeitsort und zusätzliche Einzelheiten, etwa wie lange das Stellenangebot veröffentlicht war und das Gehalt.
Natürlich können wir aus der Stellenanzeige selbst noch mehr Daten gewinnen, das relevanteste Element ist jedoch die Stellenbeschreibung auf der rechten Seite, die uns den gesamten Kontext zum Stellenangebot liefert, den wir benötigen.
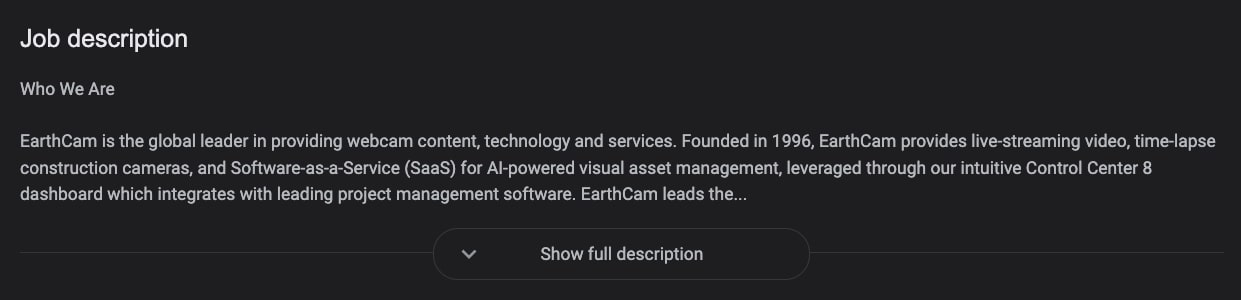
Sie müssen auch bedenken, dass alle diese Informationen dynamisch über JavaScript in die Seite eingefügt werden. Ein normales Skript kann die Seite also nicht so sehen wie wir. Und selbst nach dem Rendern müssen wir noch bestimmte Aktionen ausführen, um das vollständige Bild zu erhalten.
Ein gutes Beispiel ist die Stellenbeschreibung oben. Um die gesamte Stellenbeschreibung zu erhalten, müssten wir auf das Vollständige Beschreibung anzeigen Taste.
Durch die Verwendung des Google Jobs-Endpunkts von ScraperAPI können wir jedoch Folgendes abrufen:
- URL der Stellenausschreibung
- Name der Firma
- Berufsbezeichnung
- Beschreibung
Und zusätzliche Details, ohne dass Seiteninteraktionen durchgeführt werden müssen – also kein Headless-Browser oder komplexer Workaround.
Das Wichtigste ist, dass Sie Ihre Parser nicht warten müssen, da das ScraperAPI-Entwicklerteam dafür sorgt, dass Ihre Scraper weiterlaufen, indem es Änderungen an der Google Jobs-Site überwacht und sich schnell an neue Layouts und Herausforderungen anpasst.
Projektanforderungen
Bevor wir mit dem Schreiben unseres Skripts beginnen, stellen Sie sicher, dass Python und die Requests-Bibliothek auf Ihrem Computer installiert sind.
Um Requests zu installieren, verwenden Sie den folgenden Befehl:
Sie müssen außerdem ein kostenloses ScraperAPI-Konto erstellen, um Zugriff auf Ihren API-Schlüssel zu erhalten, auf den Sie über Ihr Dashboard zugreifen können.
Das war’s, jetzt können wir loslegen!
Schritt 1: Einrichten Ihres Google Jobs Scraping-Projekts
Erstellen Sie zunächst ein neues Verzeichnis für Ihr Projekt und eine neue Python-Datei darin. Ich nenne es google-jobs-scraper.py.
Importieren Sie oben in der Datei requests Und json. Letzteres verwenden wir, um unsere Daten zu exportieren.
import requests
import json
Der Google Jobs-Endpunkt funktioniert, indem er Ihren API-Schlüssel, die Abfrage, für die Sie Daten benötigen, und das Land, aus dem Ihre Anfragen kommen sollen, weitergibt. Wir geben alle diese Informationen in einem payload.
payload = {
'api_key': 'YOUR_API_KEY',
'query': 'video editor',
'country_code': 'us'
}
Notiz: Fügen Sie Ihren echten API-Schlüssel zu der api_key Parameter, bevor Sie Ihr Skript ausführen.
Ich habe unsere Proxys auch auf die USA eingestellt, um Stellenangebote aus den USA zu erhalten. Andernfalls könnte ScraperAPI Proxys aus verschiedenen Ländern verwenden, was die Genauigkeit unserer Daten beeinträchtigen würde. Wenn der Standort für Sie nicht wichtig ist, ignorieren Sie diesen Vorschlag.
Um die Geolokalisierung noch besser zu kontrollieren, können Sie auch eine bestimmte Google-TLD mit dem tld Parameter wie folgt:
payload = {
'api_key': 'YOUR_API_KEY',
'query': 'video editor',
'country_code': 'us',
'tld': '.com'
}
Dies ist besonders nützlich, wenn Sie sehen möchten, wie sich die Suchergebnisse bei verschiedenen Kombinationen ändern, z. B. bei Verwendung von britischen Proxys, aber Ausrichtung auf Googles .com TLD.
Wenn nicht festgelegt, zielt ScraperAPI standardmäßig auf die TLD .com.
Schritt 2: Senden Sie eine get()-Anfrage an den Google Jobs-Endpunkt
Jetzt, da die payload ist fertig, senden Sie eine get() Anfrage an den Endpunkt, wobei die payload als params.
response = requests.get('https://api.scraperapi.com/structured/google/jobs', params=payload)
ScraperAPI verwendet Ihre Abfrage, um die Suche nach Google Jobs durchzuführen, die Seite zu rendern und alle relevanten Datenpunkte im JSON-Format zurückzugeben.
Schritt 3: Alle Stellenangebote in eine JSON-Datei exportieren
Da der Endpunkt eine JSON-Antwort zurückgibt, können wir die Daten in einem all_jobs Variable und exportieren Sie sie dann in eine Datei mit dem dump() Methode von json.
all_jobs = response.json()
with open('google-jobs', 'w') as f:
json.dump(all_jobs, f)
Das erhalten Sie:
{
"url": "https://www.google.com/search?ibp=htl;jobs&q=video+editor&gl=US&hl=en&uule=w+CAIQICIgSHViZXIgSGVpZ2h0cyxPaGlvLFVuaXRlZCBTdGF0ZXM=",
"scraper_name": "google-jobs",
"jobs_results": (
{
"title": "Freelance Video Editor for Long Form Video",
"company_name": "Upwork",
"location": "Anywhere",
"link": "https://www.google.com/search?ibp=htl;jobs&q=video+editor(TRUNCATED)",
"via": "Upwork",
"description": "We are looking for a talented freelance video editor to work on a long form style video. (TRUNCATED)",
"extensions": (
"Posted 16 hours ago",
"Work from home",
"Employment Type Contractor and Temp work",
"Qualification No degree mentioned"
)
}, //TRUNCATED
Notiz: Sehen Sie, wie eine vollständige Antwort auf Google Jobs aussieht.
Schritt 3.2: Google-Stellenangebote als CSV exportieren
Der Google Jobs-Endpunkt kümmert sich auch um die Umwandlung der Scraped-Daten in tabellarische Daten, wodurch das Exportieren von Stellenangeboten in eine CSV-Datei ganz einfach wird.
Lassen Sie uns zunächst die output Parameter auf csv in unserem payload:
payload = {
'api_key': credentials.api_key,
'query': 'video editor',
'country_code': 'us',
'tld': '.com',
'output_format': 'csv'
}
Notiz: Wenn das output_format nicht festgelegt ist, wird für den Endpunkt standardmäßig das JSON-Format verwendet.
Anschließend können wir die CSV-Datei mit dem Text aus der Antwort erstellen:
response = requests.get('https://api.scraperapi.com/structured/google/jobs', params=payload)
if response.status_code == 200:
filename = 'jobs_data.csv'
# Save the response content to a CSV file
with open(filename, 'w', newline='', encoding='utf-8') as file:
file.write(response.text)
print(f"Data saved to {filename}")
else:
print(f"Error {response.status_code}: {response.text}")
So sieht Ihre Datei aus:
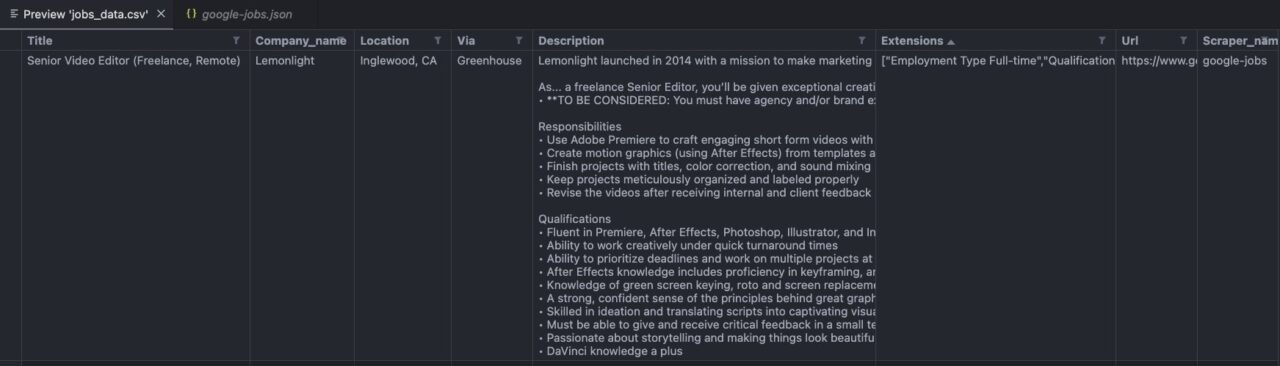
Notiz: Das Bild oben stammt aus meiner VScode-Editor-Vorschau.
