
Kundenbewertungen sind mehr als nur Feedback. Sie sind eine reiche, oft ungenutzte Quelle von Business Intelligence. Wenn Sie genau aufmerksam machen und analysieren, was Ihre Kunden über ihre Erfahrungen mit Ihren Produkten sagen, können wir echte Schmerzpunkte aufdecken, Trends in Beschwerden erkennen und sogar Bereiche für Möglichkeiten entdecken, die ansonsten unsichtbar sind.
Das Abkratzen dynamischer, hochgefreundeter Websites wie Walmart kann eine herausfordernde Aufgabe sein. Selbst wenn Sie die richtigen JavaScript -Tags mit den gewünschten Daten finden, kann es verwirrend sein und eine unmögliche Aufgabe erscheint. Zum Glück bietet Scraperapi für uns einen speziellen Endpunkt speziell für das Kratzen von Walmart -Bewertungen.
In diesem Artikel wird Sie durch das Erstellen eines einzigartigen Tools geführt, das Walmart -Kundenfeedback analysiert. Durch die Verwendung des strukturierten Walmart -Bewertungen von Scraperapi werden wir den asynchronen Endpunkt für mehrere Produkte abkratzen und Vader verwenden, um den emotionalen Ton jeder Bewertung zu bestimmen.
Darüber hinaus werden wir Gemini verwenden, um diese Rohdaten in einen klaren, umsetzbaren Bericht zu verwandeln, der Empfehlungen enthält, die alle in einer kostenlosen, mit Cloud veranstalteten Webschnittstelle mit Streamlit erstellt werden.
Vader für die Stimmungsanalyse verstehen
Die Stimmungsanalyse ist eine Methode zur Identifizierung der in einem Textstück ausgedrückten Emotionen. Da Vader (Valence Award Dictionary- und Sentiments Dens -Dens) das Instrument zur Stimmungsanalyse ist, die wir in diesem Projekt verwenden, ist es am besten zu verstehen, wie es funktioniert und ihre Vorteile, bevor Sie tiefer tauchen.
Vader verwendet ein vordefiniertes Wörterbuch (Lexikon), bei dem jedem Wort eine Stimmungsbewertung zugeteilt wird. Diese Ergebnisse spiegeln wider, wie positiv, negativ oder neutral ein Begriff ist. In diesem Projekt weist Vader jeder von uns analysierenden Übersicht zwei wichtige Metriken zu: Polarität und Subjektivität.
Die Polarität stellt die allgemeine Stimmung einer Überprüfung dar, die von negativ bis positiv reicht. Eine Punktzahl näher an +1 zeigt eine positivere Bewertung an, während eine Punktzahl näher an -1 bedeutet eine negativere Bewertung. Eine Punktzahl in der Nähe 0 bedeutet eine neutrale Bewertung. Vader berechnet jede Punktzahl, indem die Stimmungsintensität einzelner Wörter in der Überprüfung bewertet wird, wobei das integrierte Wörterbuch verweist.
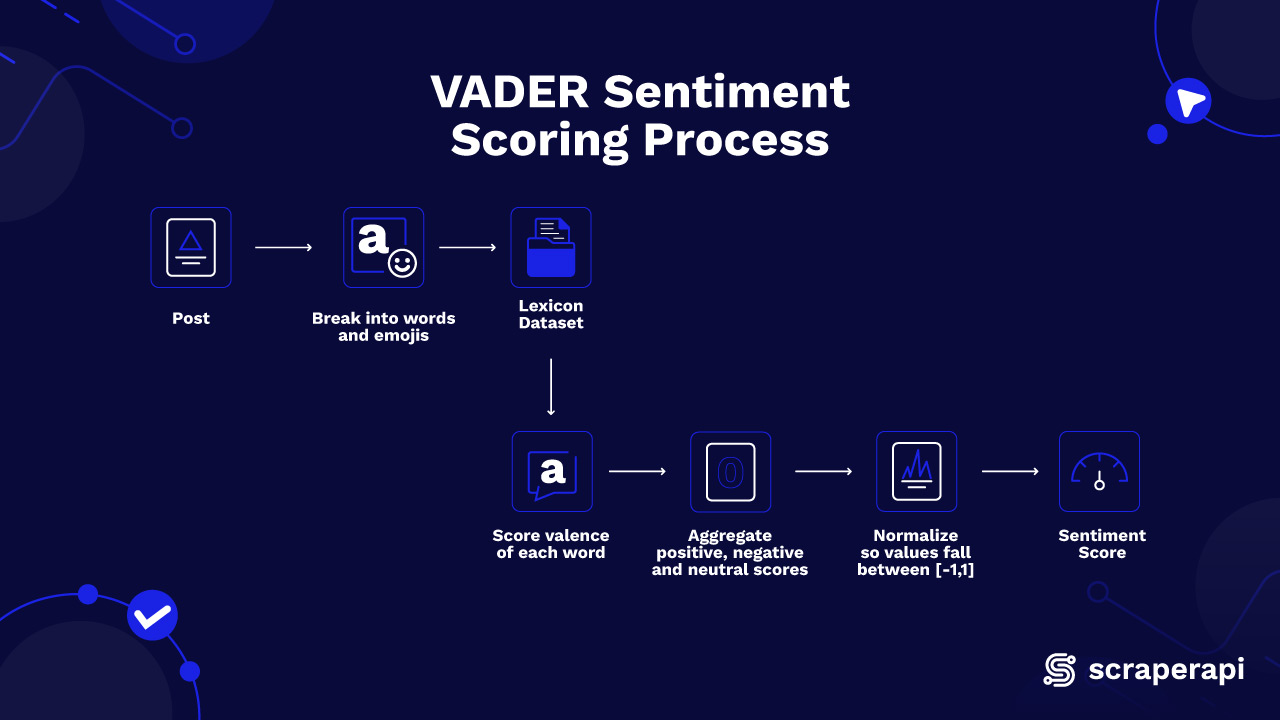
Hier finden Sie weitere Informationen zu Vader, die wichtige Vorteile und Funktionen enthalten:
1. Griff informelle Sprache gut
Vader ist hervorragend darin, die Art von Gelegenheitssprache zu analysieren, die Menschen in sozialen Medien verwenden. Es kann Slang, unregelmäßig kapitalisierte Wörter und sogar emotionale Hinweise durch Interpunktion, wie z. B. mehrere Ausrufespunkte und Emojis, leicht verstehen und interpretieren. Bei den meisten Tools für die Analyse der Stimmung ist es schwierig, dies zu erreichen und Vader für unsere Aufgabe besonders gut geeignet zu machen.
2. Bietet eine kontextbewusste Stimmungsanpassung
Anstatt Wörter isoliert zu behandeln, verwendet Vader intelligente Regeln, um den Kontext zu interpretieren. Wenn ein Satz Wörter wie „nicht“ enthält, umdreht er die Bedeutung, so dass „gut“ positiv ist, „nicht gut“ negativ wird.
Es merkt auch, ob bestimmte Wörter in allen Kappen sind oder ob es viele Ausrufezeichen gibt, was normalerweise bedeutet, dass die Emotion stärker ist. Und es gibt Vorrang für Wörter wie „sehr“ oder „leicht“, insbesondere wenn sie vor einem Adjektiv erscheinen, um genau herauszufinden, wie stark die Emotionen sind.
3. gibt eine Gesamtstimmungsbewertung
Vader beendet alle seine Analysen in einer einzelnen Zahl, die als Verbindungsbewertung bezeichnet wird, die von -1 bis +1 reicht. Diese Punktzahl sagt Ihnen auf einen Blick, ob sich die Gesamtüberprüfung positiv (näher an +1), negativ (näher an -1) oder neutral (ca. 0) anfühlt. Es ist wie ein zusammenfassender Stimmungsindikator, der das gesamte Wort Scores und Kontext-Optimierungen zu einem leicht verständlichen Wert kombiniert.
Die Walmart -API von Scraperapi (Async Endpoint)
Das Web -Scraping ist aus mehreren Gründen schwierig. Moderne Websites sind mit dynamischen JavaScript -Frameworks erstellt, was bedeutet, dass die meisten Inhalte in der statischen HTML nicht verfügbar sind. In der Praxis müssten Sie JavaScript verstehen und sich mit Tools für Webentwicklung in der Entwicklung von Webentwicklungs -Tools kennenlernen, um die von Ihnen benötigten Daten zu lokalisieren und zu extrahieren.
Beim Abkratzen einer Website muss das Tool, das Sie zuerst verwenden, mehrere Anti-Scraping-Verteidigungen umgehen, die viele Websites heutzutage anwenden. Sobald es durchläuft, kommt es sofort in Kontakt mit einem Codeberg in Kontakt. Das folgende Bild zeigt ein echtes Beispiel für den Code hinter der Website von Walmart (klicken Sie mit der rechten Maustaste und wählen Sie aus und wählen Sie „Überprüfen”Um das gleiche Bild unten auf einer Walmart -Website zu sehen):):
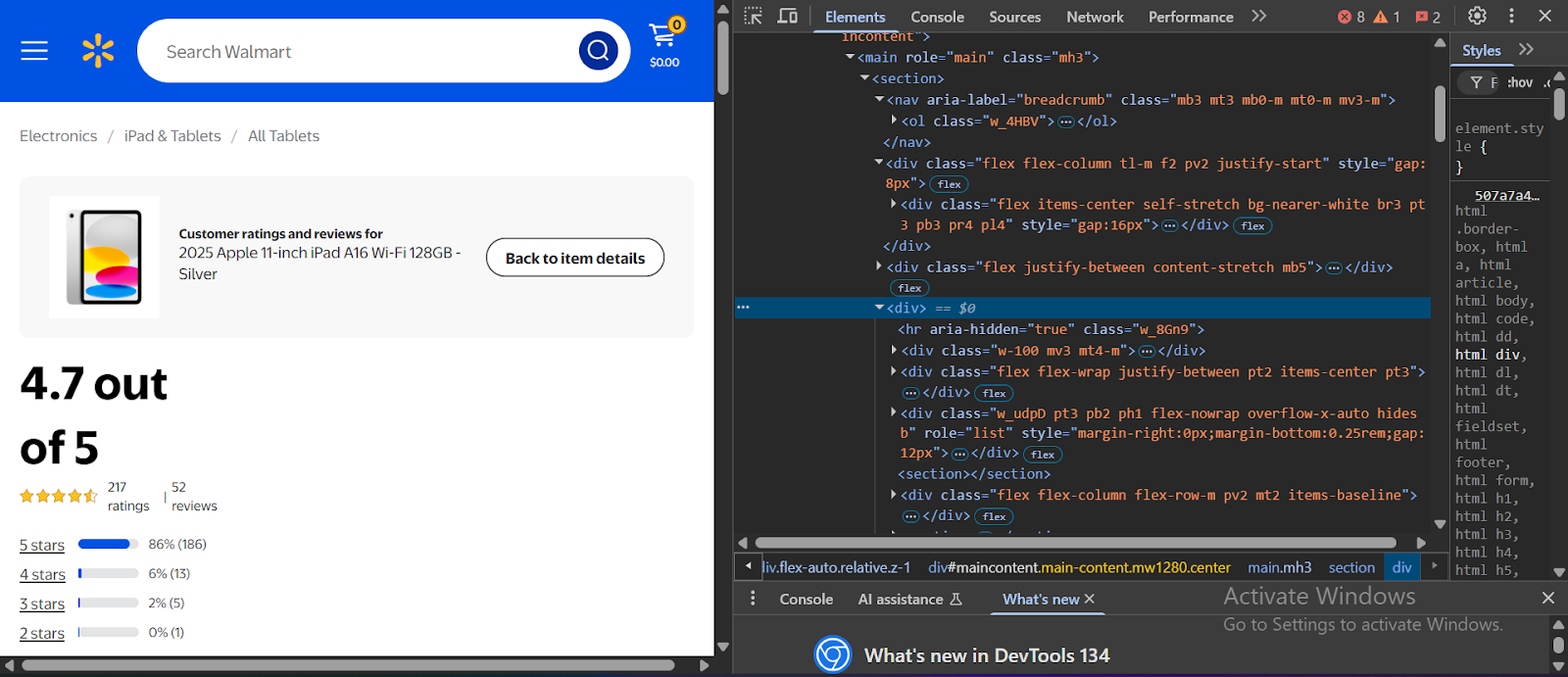
Der Code im Abschnitt Elements einer Webseite ist häufig unter mehreren HTML -Ebenen vergraben, sodass es schwierig ist, genau zu finden, woher die Daten stammen. Um dies zu navigieren, benötigen Sie normalerweise ein gutes Verständnis von HTML, CSS und JavaScript.
Aber was ist, wenn Sie kein Front-End-Entwickler sind? Wenn Sie Datenanalyst, Wissenschaftler oder Ingenieur sind, ist Ihre Hauptsprache wahrscheinlich nicht JavaScript.
In den meisten Fällen müssen Sie die Entwickler -Tools Ihres Browsers verwenden, um die Seite zu inspizieren und die spezifischen Elemente wie Bewertungen, Bewertungen oder Daten zu finden, die die Daten enthalten, die Sie kratzen möchten.
Tools wie Selen und Puppeteer können dazu beitragen, das Benutzerverhalten zu simulieren, aber sie fügen Komplexitätsschichten hinzu. Wenn wir diese Walmart -Site kratzen wollten, müssen wir hier normalerweise ein idealer Prozess machen, um diese Daten zu lokalisieren und zu extrahieren:
- Zunächst müssen Sie den übergeordneten Container im HTML -Code der Website finden, der die Div -Klasse enthält, in der Sie die Bewertungsdaten finden:
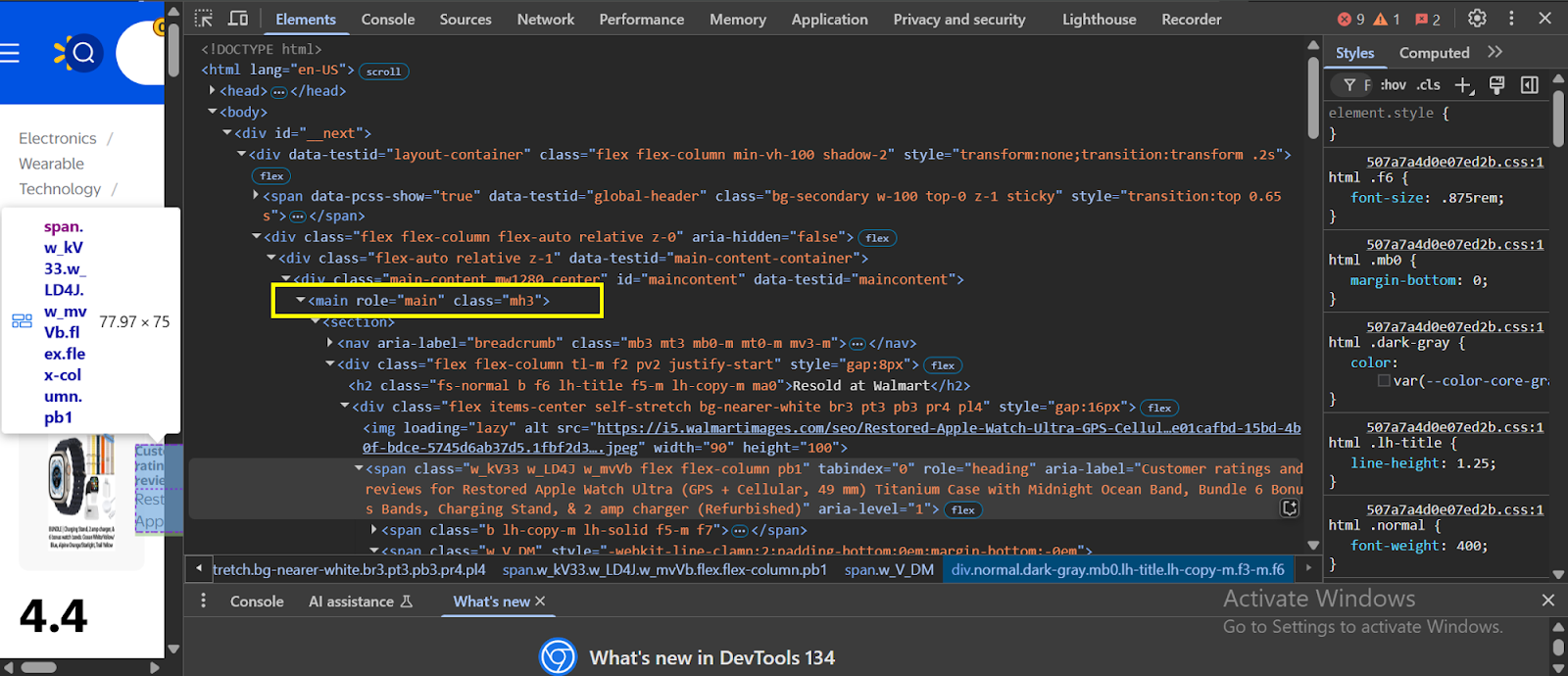
- Innerhalb der Div -Klasse suchen “
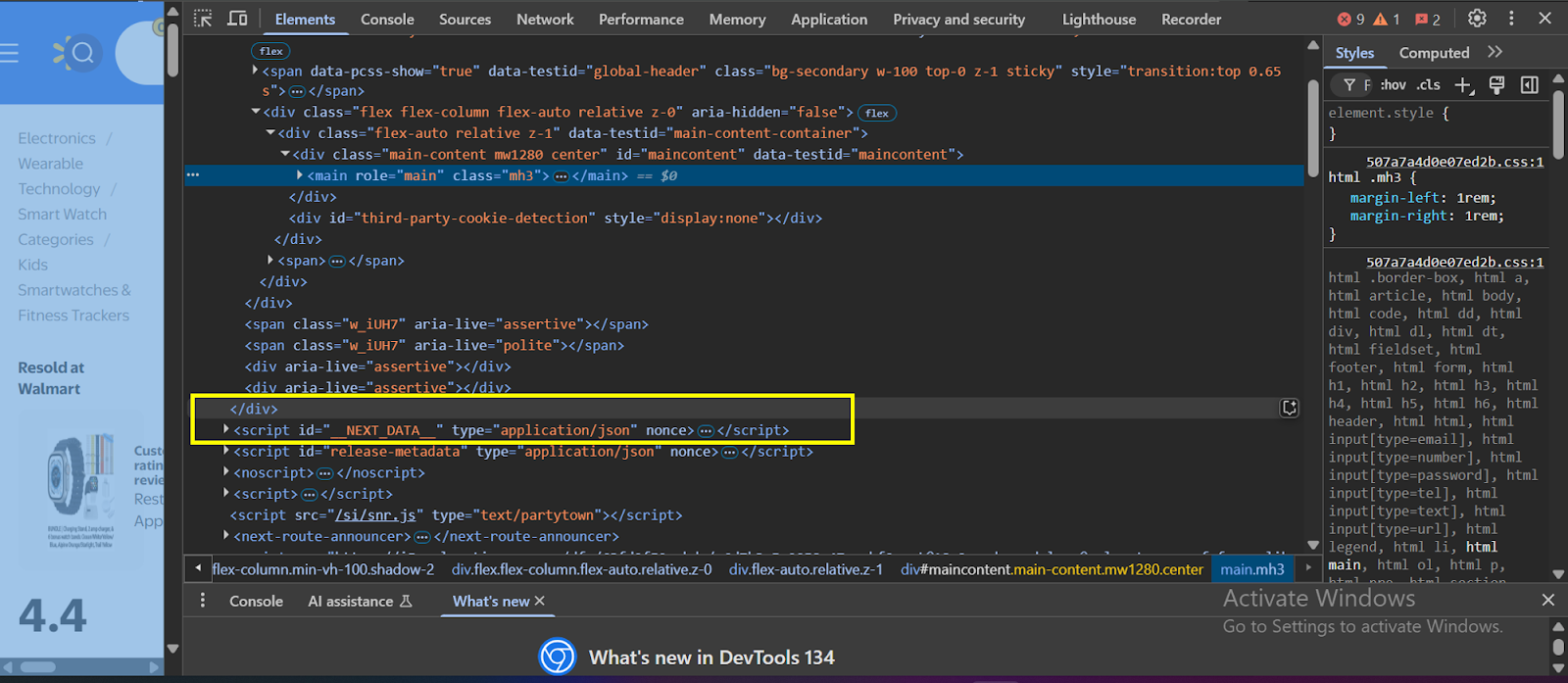
- Innerhalb dieser Klasse finden Sie die Überprüfungsdaten:
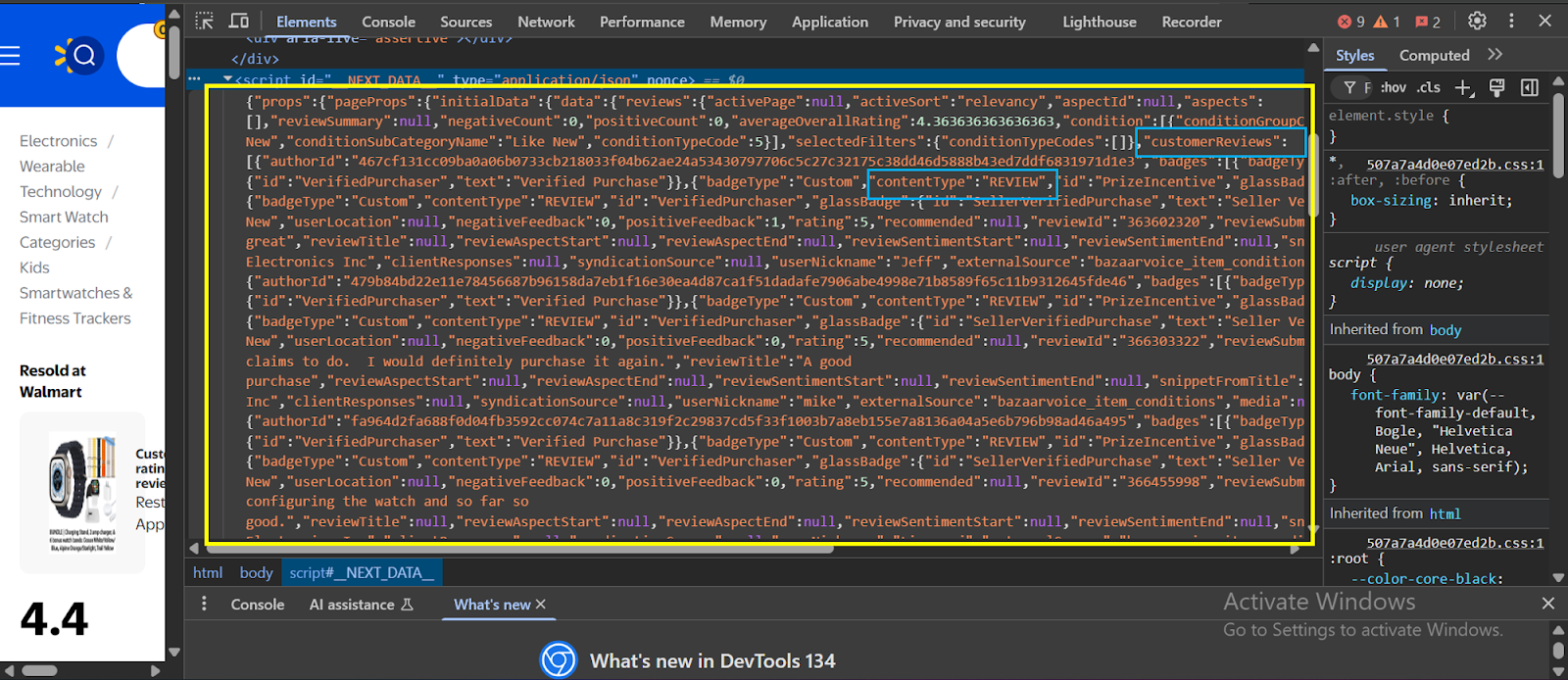
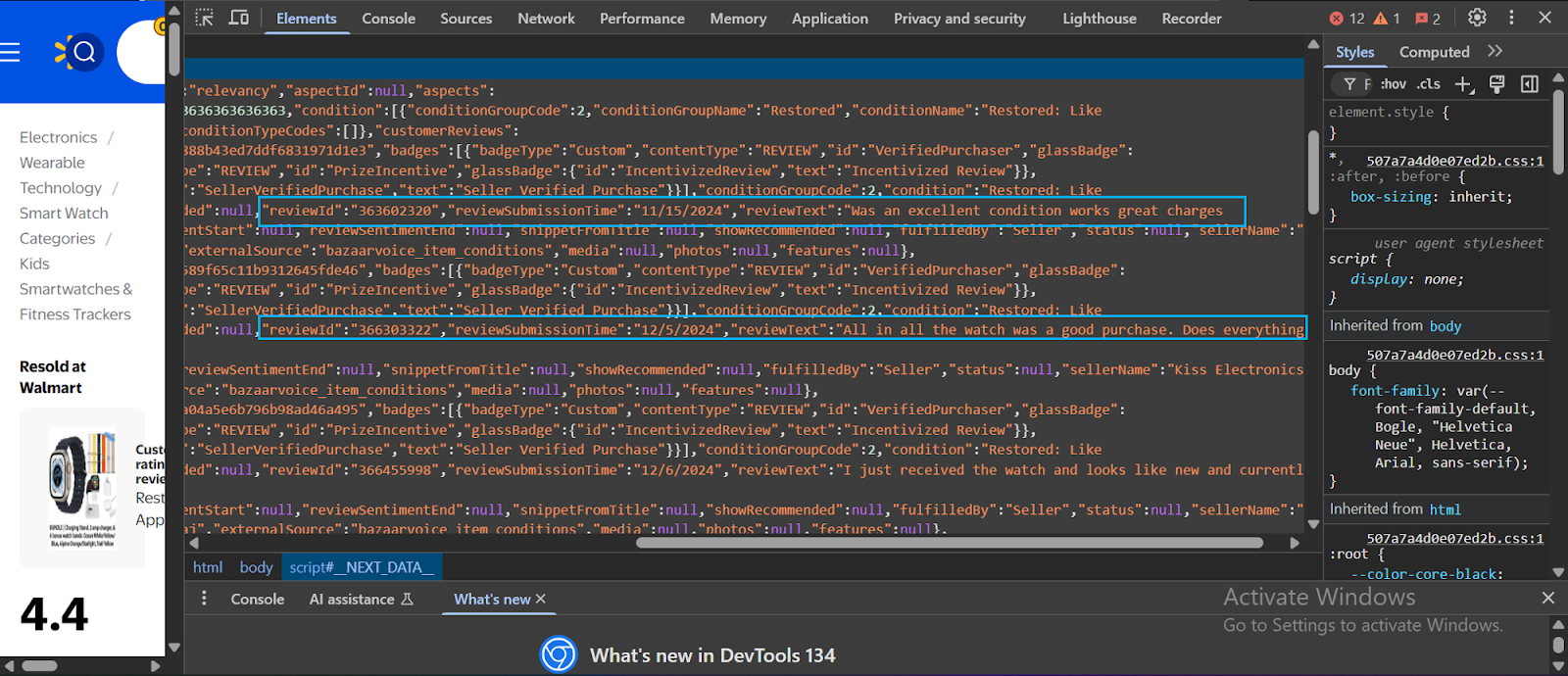
Moderne Websites verwenden häufig dynamisches Rendering, was bedeutet, dass die Daten asynchron über JavaScript laden. Infolgedessen können Sie mit einer einfachen HTML -Anfrage nicht darauf zugreifen - die wichtigen Informationen sind hinter Skripten versteckt, die nach dem Laden der Seite ausgeführt werden.
Hier hilft die Walmart -Rezensionen von Scraperapis API (asynchrischer Endpunkt). Es wurde entwickelt, um diese Herausforderungen zu bewältigen, indem Walmarts Anti-Scraping-Abwehr umgehen und vollständig gerenderte Seitendaten direkt an Sie liefern.
Noch besser ist, dass mit dem asynchronen Endpoint Sie sich speziell für Kundenbewertungen ansprechen können. Während die API im Hintergrund läuft, kann Ihre App wie gewohnt weiter ausgeführt werden. Sobald die Daten fertig sind, erhalten Sie ein Status -Update.
Mehr über Scraperapis asynchrone Funktion
Die Async-Funktion von Scraperapi überwindet die Herausforderungen des großflächigen Web-Scrapings, insbesondere auf Websites mit strengen Anti-Scraping-Maßnahmen. Anstatt auf sofortige Antworten zu warten, die zu Zeitüberschreitungen und niedrigen Erfolgsraten führen können, reichen Sie eine oder mehrere Schablonen -Jobs ein und holen die Ergebnisse später ab, während Sie andere Funktionen in Ihrer App verwenden.
Wie es funktioniert /jobs Endpunkt für einzelne URLs oder die /batchjobs Endpunkt für mehrere URLs. Der Service weist sofort eine eindeutige Job -ID und Status -URL zu. Anschließend befragen Sie diese Status -URL, um den Fortschritt zu überwachen, bis Sie den abgekratzten Inhalt im Bereich "Body" von JSON erhalten.
Dieser asynchrone Prozess bietet Scraperapi mehr Zeit, um komplexe Websites zu navigieren, Zeitüberschreitungen zu verwalten, HTTP -Header anzupassen und Inhalte zu rendern, die für JavaScript stark sind. Sie richten auch Webhook -Callbacks ein, sodass der Service automatisch Daten liefert, sobald Ihr Job abgeschlossen ist.
Der Async -Ansatz von Scraperapi erledigt das starke Heben, sodass Sie sich auf andere Aspekte Ihrer Anwendung konzentrieren können, anstatt darauf zu warten, dass Daten vollständig kratzen. Infolgedessen erhalten Sie saubere, strukturierte Daten, die für die weitere Verarbeitung bereit sind.
Erste Schritte mit Schakerapi
- Gehen Sie zunächst auf die Website von Scraperapi.
- Sie können sich entweder anmelden, wenn Sie bereits ein Konto haben oder auf “klicken“Versuch beginnenUm einen zu erstellen:
- Nachdem Sie Ihr Konto erstellt haben, sehen Sie ein Dashboard, die Ihnen eine zur Verfügung stellen API -SchlüsselAnwesend Zugriff auf 5000 API -Credits (7-Tage-begrenzte Testzeit) und Informationen über das Abkratzen.
- Um auf weitere Credits und erweiterte Funktionen zuzugreifen, klicken Sie nach unten und klicken Sie auf "Upgrade auf größeren Plan."
- Scraperapi bietet Dokumentation für verschiedene Programmiersprachen und Frameworks, die mit seinen Endpunkten verbunden sind, einschließlich PHP, Java, Node.js und mehr. Sie finden diese Ressourcen, wenn Sie auf der Dashboard -Seite nach unten scrollen und auswählen “Alle Dokumente anzeigen”:
- Suchen Sie die Suchleiste in der oberen rechten Ecke:
- Suchen nach "Walmart Reviews Endpoint“Und klicken Sie auf die "Async strukturierte Datenerfassung Methode" Popup:
- Sie werden in die detaillierte und klare Dokumentation von Scraperapi zur Verwendung der asynchronen strukturierten Datenerfassungsmethode gerichtet.

- Scrollen Sie auf der Dokumentationsseite nach unten, bis Sie den Abschnitt "Walmart -Endpunkt" finden. Klicken Sie dann auf "Walmart Reviews API (Async)"
- Sie werden in die Dokumentation von Walmart Reviews API (ASYNC) führen, in der Sie klare Anweisungen und praktische Beispiele für die Verwendung dieser Funktion in Ihrer Anwendung finden.
Erstellen des Walmart Reviews Analysis Tools
Schritt 1: Einrichten des Projekts
Erstellen Sie einen neuen Projektordner in einer virtuellen Umgebung und installieren Sie die erforderlichen Abhängigkeiten.
1. Erstellen Sie den Projektordner:
mkdir walmart_rev_project
cd walmart_rev_project
2. Richten Sie eine virtuelle Umgebung ein:
Aktivieren Sie die Umgebung:
3. Installieren Sie Abhängigkeiten:
pip install streamlit requests google-generativeai
Sozug auf Vader:
pip install nltk
python -c "import nltk; nltk.download('vader_lexicon')"
Die wichtigsten Abhängigkeiten und ihre Funktionen sind:
- stromlit: Erstellen einer interaktiven Web -Benutzeroberfläche für das Tool.
- Anfragen: Stellt HTTP -Anfragen an externe Dienste (wie Scraperapi) an, um Daten zu senden und zu empfangen.
- Google-Generativai: Schnittstellen mit Googles Gemini großes Sprachmodell (LLM), um Berichte aus den von uns kratzenden Daten zu generieren.
- NLTK: Dies ist eine Bibliothek, die Tools für natürliche Sprachverarbeitung bietet, einschließlich der Stimmungsanalyse über Vader und Text -Tokenisierung für die Verarbeitung von Kundenbewertungen.
- JSON (Standardbibliothek): Griff JSON Codierung und Dekodierung für API -Antworten.
- Concurrent.Futures (Standardbibliothek): Ermöglicht die Anwendung, Aufgaben gleichzeitig mithilfe von Thread-basierter Parallelität auszuführen.
- DateTime (Standardbibliothek): Verwaltet Datums- und Uhrzeitfunktionen, wie z. B. Zeitstempelberichte und Arbeitseinführungen.
4. Definieren Sie die Projektstruktur:
walmart_rev_project/
│── walmart_scraperapi.py
Schritt 2: Aktivieren Sie die Gemini LLM von Google
Wir werden benutzen Gemini 1.5 Blitz als großes Sprachmodell (LLM) für dieses Tutorial. Um die gleichen Ergebnisse zu erzielen, folgen Sie mit und verwenden Sie dasselbe Modell. So können Sie es einrichten:
- Gehen Sie zur Google Developer API -Website.
- Erstellen Sie ein Google -Konto, wenn Sie noch keines haben.
- Klicken Sie auf “Holen Sie sich einen Gemini -API -Schlüssel “:

- Sie werden in Google AI Studio, ausgewählt, umgeleitet.Erstellen Sie einen API -Schlüssel”Kopieren Sie Ihren API -Schlüssel und speichern Sie sie als Umgebungsvariable:
Schritt 3: Initialisieren von Bibliotheken, Vader und API -Schlüssel
Erstellen wir nun die Codebasis und erstellen Sie eine geeignete Aufforderung, die LLM in ihrer Aufgabe zu leiten.
1. Importieren von Bibliotheken und Einrichten von Vader
Erstens importiert das Tool die erforderlichen Bibliotheken aus installierten Abhängigkeiten und konfiguriert sowohl Gemini als auch NLTKs Sentiment Analyzer.
import streamlit as st
import requests
import google.generativeai as genai
import nltk
from nltk.sentiment.vader import SentimentIntensityAnalyzer
import json
import concurrent.futures
import datetime
# Download VADER lexicon if not already present
nltk.download('vader_lexicon')
# Initialize VADER sentiment analyzer
analyzer = SentimentIntensityAnalyzer()
Der obige Code erreicht Folgendes:
Importe:
streamlit: Erstellt die Benutzeroberfläche der Web -App.requests: Ermöglicht HTTP -Anfragen, mit externen Diensten wie Scraperapi zu interagieren.google.generativeai as genai: Integriert Googles Gemini LLM für Sprachgenerierungsfunktionen (später im Skript verwendet).nltk: Bietet Tools für die Arbeit mit Daten mit menschlicher Sprache, insbesondere für die Stimmungsanalyse.nltk.sentiment.vader.SentimentIntensityAnalyzer: Eine bestimmte NLTK -Klasse, mit der das Textgefühl analysiert wird.json: Ermöglicht die Handhabung von Daten im JSON -Format, die für Web -Service -Antworten üblich sind.concurrent.futures: Ermöglicht die gleichzeitigen Ausführung von Aufgaben und potenziell die Leistung.datetime: Bietet Funktionen für die Arbeit mit Daten und Uhrzeiten, wahrscheinlich für die Berichterstattung.
Vader Setup:
nltk.download('vader_lexicon'): Download das Vader -Lexikon, eine Liste von Wörtern und deren Stimmungsbewertung, wenn es noch nicht vorhanden ist.analyzer = SentimentIntensityAnalyzer(): Erstellt eine Instanz des Vader Sentiment Analyzer, bereit für die Verwendung.
2. Einrichten der API -Schlüssel und Konfigurieren von Gemini:
Weiter unten werden die für Google Gemini und Scraperapi benötigten API -Schlüssel eingerichtet und die Gemini -API konfiguriert.
# Replace with your actual API keys
GOOGLE_API_KEY = "Axxxxxx" # Replace with your Gemini API key
SCRAPERAPI_KEY = "9xxxxxx" # Replace with your ScraperAPI key
# Configure Gemini API
genai.configure(api_key=GOOGLE_API_KEY)
Hier ist, was der obige Code erreicht:
- API -Schlüssel einrichten: Es definiert Variablen, um die API -Schlüssel für Gemini und Scraperapi zu halten, die sind
GOOGLE_API_KEYUndSCRAPERAPI_KEY. Denken Sie daran, die Platzhalterwerte durch Ihre tatsächlichen API -Schlüssel zu ersetzen, damit die Anwendung diese Dienste nutzen kann. - Konfigurieren von Gemini:
genai.configure(api_key=GOOGLE_API_KEY)Konfiguriert die Google Generative AI -Bibliothek(genai)Verwenden Sie den bereitgestellten API -Schlüssel, sodass die Anwendung das Gemini -Sprachmodell authentifiziert und interagiert.
Schritt 4: Erstellen Sie die Funktion zur Stimmungsanalyse
Die Funktion unten, analyze_sentimentNimmt Text als Eingabe und initialisiert Vader, um seine Polarität und Subjektivität zu bestimmen.
def analyze_sentiment(text):
scores = analyzer.polarity_scores(text)
polarity = scores('compound')
subjectivity = 1 - scores('neu')
return polarity, subjectivity
Nachfolgend finden Sie eine weitere Aufschlüsselung dessen, was der obige Code tut:
- Funktionsdefinition: Es definiert eine Funktion namens
analyze_sentimentdas akzeptiert ein einziges Argument,textdie die Eingabezeichenfolge enthalten, die wir benötigen, um eine Stimmungsanalyse durchzuführen. - Sentiment -Scoring:
scores = analyzer.polarity_scores(text)ruft diepolarity_scores()Methode des initialisierten VadersanalyzerObjekt auf der Eingabetext. Diese Aktion gibt ein Wörterbuch zurück, das verschiedene Stimmungswerte enthält, einschließlich positiver, negativer, neutraler und zusammengesetzter Score. - Polarität extrahieren:
polarity = scores('compound')extrahiert diecompoundPunktzahl aus demscoresWörterbuch und weist es dem zupolarityVariable. Denken Sie daran, dass wir darüber diskutierten, dass der Zusammengesetzte Score eine normalisierte, gewichtete Verbundbewertung ist, die die allgemeine Stimmung des Textes zusammenfasst. - Subjektivität berechnen:
subjectivity = 1 - scores('neu')Berechnet das Maß für die Subjektivität, während Vader a liefertneuPunktzahl, der den Anteil der neutralen Wörter im Text darstellt. Durch Subtrahieren von 1 schätzt die Funktion den Grad, in dem der Text Meinungen oder subjektive Inhalte ausdrückt. Ein höherer Wert zeigt eine höhere Subjektivität an. - Rückgabeergebnisse:
return polarity, subjectivityGibt zwei Werte zurück: die berechnetenpolarity(zusammengesetzte Stimmungsbewertung) und abgeleitetsubjectivityPunktzahl.
Schritt 5: Erstellen Sie die Funktion zur Erstellung der Berichtsgenerierung
Hier die Funktion, generate_gemini_reportnimmt die "Modell" Instanz und eine Texteingabeaufforderung als Eingabe und generieren dann Inhalte basierend auf dieser Eingabeaufforderung.
def generate_gemini_report(model, prompt):
try:
response = model.generate_content(prompt)
return response.text
except Exception as e:
return f"Error generating report: {e}"
Hier ist, was wir aus dem obigen Code verstehen können:
- Funktionsfunktion: Es definiert die Funktion
generate_gemini_reportDas akzeptiert zwei Argumente, die sindmodel(eine Instanz von Gemini zuvor konfiguriert) undprompt(Eine Zeichenfolge, die die Anweisungen oder Fragen enthält, auf die Gemini antworten kann). - Inhaltsgenerierung:
response = model.generate_content(prompt)ruft diegenerate_content()Methode der bereitgestelltenmodelObjekt, übergebenpromptals Argument. Senden Sie die Eingabeaufforderung an das Gemini -Modell, um eine Textantwort zu generieren. - Rückgabe der Antwort:
return response.textstellt sicher, dass die Erzeugung der Inhaltsgenerierung den generierten Text aus dem extrahiertresponseObjekt und gibt es zurück. - Fehlerbehandlung:
except Exception as e: behandelt potenzielle Fehler, die während des Inhaltsgenerierungsprozesses auftreten können (z. B. Netzwerkprobleme, API -Fehler). Währendreturn f"Error generating report: {e}"Gibt eine Fehlermeldung zurück, die eine Beschreibung der Ausnahme enthält. Dieser Abschnitt dient hauptsächlich zu Debugging -Zwecken.
Schritt 6: Erstellen der asynchrischen Schaberfunktion
Nutzen wir fetch_async_reviews als Funktion zur Interaktion mit dem Walmart Review Endpoint (ASYNC) von Scraperapi und eine Anfrage für Produktbewertungen einreichen.
def fetch_async_reviews(api_key, product_id, tld, sort, page):
url = "https://async.scraperapi.com/structured/walmart/review"
headers = {"Content-Type": "application/json"}
data = {
"apiKey": api_key,
"productId": product_id,
"tld": tld,
"page": str(page),
"sort": sort,
}
st.info(f"Submitting job for Product ID '{product_id}' on page {page} with payload: {data}")
response = requests.post(url, json=data, headers=headers)
try:
response.raise_for_status()
return response.json()
except requests.exceptions.HTTPError as err:
st.error(f"HTTP error during async request: {err}")
st.error(f"Response content: {response.text}")
raise
except json.JSONDecodeError as e:
st.error(f"Error decoding async response: {e}")
raise
except Exception as e:
st.error(f"Unexpected error during async request: {e}")
raise
Der Code erreicht Folgendes:
1. Definieren der Funktion:
Erstens definiert es fetch_async_reviewswas die folgenden Argumente akzeptiert:
api_key: Ihr Schaker -API -Schlüssel zur Authentifizierung.product_id: Die eindeutige Kennung des Walmart -Produkts, dessen Bewertungen abgerufen werden sollen.tld: Die Domain der obersten Ebene für Walmart (zB "com", "ca").sort: Die Kriterien, nach denen die Bewertungen sortiert werden sollten (z. B. „Relevanz“, „hilfreich“).page: Die spezifische Seitennummer der zu abgerufenen Bewertungen.
2. Anfrage Details:
url = "https://async.scraperapi.com/structured/walmart/review": Definiert den spezifischen Scraperapi -Endpunkt für das Abholen strukturierter Walmart -Bewertungen asynchron.headers = {"Content-Type": "application/json"}: Legt die HTTP -Headers fest, um anzuzeigen, dass die Anforderungskörper im JSON -Format sein wird.data = {...}: Erstellt ein Python -Wörterbuch, das die Parameter enthält, die in der Anfrage als JSON gesendet werden sollen:
3.. Senden Sie den asynchronen Job:
st.info(...)verwendet StreamlitinfoFunktion zur Anzeige einer Nachricht in der Web -App, die angibt, dass ein Scraping -Job mit den angegebenen Details eingereicht wird. Währendresponse = requests.post(url, json=data, headers=headers)Sendet eine HTTP -Postanforderung an den Schaker -Endpunkt mit den angegebenen URL, JSON -Daten und Headern.
4. Umgang mit der Antwort:
try...exceptBlock: Dieser Block behandelt potenzielle Fehler während der API -Anforderung und der Antwortverarbeitung.response.raise_for_status(): Überprüft, ob die HTTP -Anforderung erfolgreich war (Statuscode 2xx). Wenn nicht, erhöht es eineHTTPErrorAusnahme.return response.json(): Wenn die Anfrage erfolgreich ist, analysiert sie die JSON -Antwort von Scraperapi und gibt sie zurück. Diese Antwort enthält typischerweise Informationen über den eingereichten Job, z. B. die ID und die Status -URL.except requests.exceptions.HTTPError as err:: Fängt HTTP-bezogene Fehler (z. B. 4xx- oder 5xx-Statuscodes aus Scraperapi) an, zeigt eine Fehlermeldung in der Streamlit-App mit dem HTTP-Fehler und dem Antwortinhalt an und rägt die Ausnahme erneut.except json.JSONDecodeError as e:: Fängt Fehler auf, die auftreten, wenn die Antwort von Scraperapi kein gültiges JSON ist, eine Fehlermeldung zeigt und die Ausnahme wiederholt.except Exception as e:: Erfasst andere unerwartete Fehler während des Vorgangs, zeigt eine Fehlermeldung an und rägt die Ausnahme wieder.
Schritt 7: Jobstatus überprüfen
Die folgende Funktion nimmt die Status -URL (bereitgestellt von Scraperapi nach dem Einreichen eines asynchronen Jobs) und holt den aktuellen Status dieses Jobs ab.
def check_job_status(status_url):
try:
response = requests.get(status_url)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
st.error(f"Error checking job status: {e}")
raise
except json.JSONDecodeError as e:
st.error(f"Error decoding job status response: {e}")
raise
Hier finden Sie weitere Informationen darüber, wie der Code funktioniert:
- Funktionsdefinition: Es definiert die
check_job_statusFunktion, die ein einzelnes Argument akzeptiert,status_urlDas ist die von Scraperapi bereitgestellte URL, mit der der Status eines zuvor eingereichten asynchronen Schablonenauftrags abfragt wird. - Beantragungsstatus anfordern:
response = requests.get(status_url)sendet eine HTTP ERHALTEN Anfrage an die bereitgestelltestatus_urlUm den aktuellen Status des Scraping -Jobs abzurufen.
Schritt 8: Abrufen der abgekratzten Daten aus dem Jobergebnis
Eine andere Funktion, get_job_resultNimmt die Daten an, die den Status des asynchronen Jobs darstellen, und extrahiert den tatsächlichen Inhalt, wenn der Jobstatus erfolgreich ist.
def get_job_result(job_data):
if job_data and job_data.get("status") == "finished":
response_data = job_data.get("response")
if response_data and isinstance(response_data, dict) and "body" in response_data:
try:
return json.loads(response_data("body"))
except json.JSONDecodeError as e:
st.error(f"Error decoding 'body' JSON: {e}")
return None
else:
st.error("Could not find 'body' in the job result response.")
return None
return None
Unten finden Sie eine Zusammenfassung dessen, was der obige Code erreicht:
- Definiert die Funktion: Erstens definiert es
get_job_resultwas ein einzelnes Argument akzeptiert,job_dataein Wörterbuch mit Informationen über den Status und das Ergebnis des asynchronen Jobs. - Überprüfung des Auftrags Abschluss:
if job_data and job_data.get("status") == "finished":Zuerst überprüft, objob_dataist nicht "Keiner" und schaut dann explizit für die "Status" Schlüssel darin. Wenn der Wert zugeordnet ist "Status" Ist "fertig"Es fährt fort, die Ergebnisse zu extrahieren. - Zugriff auf Antwortdaten:
response_data = job_data.get("response"): Ruft den Wert der ab "Antwort" Schlüssel aus demjob_data. Das "Antwort" Enthält Details zur HTTP -Antwort von Walmarts Website. - Überprüfung der Reaktionskörper:
if response_data and isinstance(response_data, dict) and "body" in response_data:Überprüft, obresponse_dataexistiert, ist ein Wörterbuch und enthält einen Schlüssel mit dem Namen "Körper". Der "Körper" Key enthält den tatsächlichen HTML -Inhalt der abgekratzten Webseite als Zeichenfolge. - Körper extrahieren und dekodieren: Der
try...except json.JSONDecodeError as e:Blockiert den Inhalt des "Körper" als JSON. - Umgang mit fehlendem Körper:
else: st.error("Could not find 'body' in the job result response.") return None: Dieser Codeblock überprüft, ob die "Körper" Der Schlüssel ist nicht innerhalb der gefundenresponse_dataZeigt dann eine Fehlermeldung in der Streamlit -App an und kehrt zurückNone.
Schritt 9: Bewertungsbewertungen
Hier, die process_reviews_for_display Die Funktion nimmt die Produkt -ID- und RAW -Überprüfungsdaten (aus Scraperapi) als Eingabe an und verarbeitet dann jede Überprüfung, um relevante Informationen wie Text, Stimmung und potenzielle Schmerzpunkte zu extrahieren.
def process_reviews_for_display(product_id, results):
review_data_list = ()
for review in results.get("reviews", ()):
if "text" in review:
review_text = review("text")
polarity, subjectivity = analyze_sentiment(review_text)
sentences = nltk.sent_tokenize(review_text)
pain_points = (s.strip() for s in sentences if analyzer.polarity_scores(s)('compound') 5)
review_data_list.append({
"text": review_text,
"pain_points": pain_points,
"sentiment": {
"polarity": polarity,
"subjectivity": subjectivity
}
})
return review_data_list
Der obige Code erreicht Folgendes:
1. Funktionsdefinition:
Es definiert die process_reviews_for_display Funktion, die zwei Argumente akzeptiert:
product_id: Die ID des Produkts, zu dem die Bewertungen gehören.results: Ein Wörterbuch, das die von Scraperapi abgerufenen Rohüberprüfungsdaten enthält
2. Initialisieren von Überprüfungsdatenliste:
review_data_list = () Erstellt eine leere Liste, um die verarbeiteten Informationen für jede Bewertung zu speichern.
3.. Iterieren durch Bewertungen:
for review in results.get("reviews", ()): Iteriert die Liste der Bewertungen, auf die mit dem zugegriffen wird .get("reviews", ()) Methode auf der results Wörterbuch. Daher sicher mit Fällen, in denen die sicher behandelt werden "Bewertungen" Der Schlüssel könnte fehlen.
4. Verarbeitung jeder Bewertung:
if "text" in review:: Es überprüft, ob der StromreviewDictionary enthält einen Textschlüssel, der den tatsächlichen Überprüfungstext aufbewahrt.review_text = review("text"):Wenn der Schlüssel „Text“ vorliegt, wird der Wert (der Überprüftext) dem zugewiesen, der dem zugewiesen istreview_textVariable.polarity, subjectivity = analyze_sentiment(review_text): Deranalyze_sentimentFunktion (früher definiert) wird auf die aufgerufenreview_textUm seine Stimmungspolarität und Subjektivitätswerte zu erhalten.sentences = nltk.sent_tokenize(review_text): Der Überprüfungstext wird mit NLTKs in einzelne Sätze aufgeteiltsent_tokenizeFunktion.pain_points = (s.strip() for s in sentences if analyzer.polarity_scores(s)('compound') 5): Diese Zeile identifiziert potenzielle „Schmerzpunkte“ innerhalb der Überprüfung. Es iteriert jeden Satz und berechnet seinen zusammengesetzten Stimmungswert mit Vader. Wenn die Punktzahl unter -0,05 liegt (was auf eine negative Stimmung hinweist) und der Satz länger als 5 Zeichen ist, gilt er als potenzieller Schmerzpunkt (nach Entfernen von Leading/Trailing Whitespace).review_data_list.append({...}): Ein Wörterbuch, das die extrahierten und analysierten Informationen für die aktuelle Überprüfung enthältreview_data_list.
5. Returning verarbeitete Überprüfungsdaten:
Die Funktion gibt die zurück review_data_listdie nun eine strukturierte Darstellung jeder verarbeiteten Überprüfung enthält, einschließlich des Textes, der identifizierten Schmerzpunkte und der Ergebnisse der Stimmungsanalyse.
Schritt 10: Erstellen einer Eingabeaufforderungsfunktion, um die Berichte zu generieren
Jetzt müssen wir eine Funktion schreiben und aufrufen, die eine Liste von Produkt -IDs und verarbeiteten Überprüfungsdaten als Eingabe aufnimmt, und dann eine Textaufforderung erstellt, um an Gemini für die Erstellung eines Berichts zu senden.
def generate_report_prompt(product_ids, processed_reviews):
# The function up here generates a combined prompt for all products
prompt = f"Here are the customer reviews and their associated pain points for product IDs: {', '.join(product_ids)}:nn"
for review_info in processed_reviews:
prompt += f"Review: {review_info('text')}n"
if review_info('pain_points'):
prompt += f"Pain Points: {', '.join(review_info('pain_points'))}n"
else:
prompt += "Pain Points: Nonen"
prompt += f"Sentiment: Polarity={review_info('sentiment')('polarity'):.2f}, Subjectivity={review_info('sentiment')('subjectivity'):.2f}nn"
prompt += "Based on these reviews, identify the key pain points for each product. Explain what sentiment polarity and subjectivity mean in the context of these reviews. Provide an overall sentiment summary for each product."
return prompt
So funktioniert der Code im Detail:
1. Initialisieren der Eingabeaufforderung:
Nach der Definition der FunktionAnwesend prompt = f"Here are the customer reviews and their associated pain points for product IDs: {', '.join(product_ids)}:nn" Erstellen Sie die Eingabeaufforderung an, indem Sie einen Header aufnehmen, der die Produkt -IDs auflistet, für die der Bericht generiert wird.
2. Iterieren durch verarbeitete Bewertungen:
for review_info in processed_reviews:: Iteriert jede verarbeitete Überprüfung in derprocessed_reviewsListe.prompt += f"Review: {review_info('text')}n": Fügt den ursprünglichen Überprüfungstext der Eingabeaufforderung hinzu.if review_info('pain_points'):: Überprüft, ob für die aktuelle Überprüfung Schmerzpunkte identifiziert wurden.prompt += f"Sentiment: Polarity={review_info('sentiment')('polarity'):.2f}, Subjectivity={review_info('sentiment')('subjectivity'):.2f}nn": Fügt die Sentiment -Polaritäts- und Subjektivitätswerte für die aktuelle Überprüfung der Eingabeaufforderung hinzu, die an zwei Dezimalstellen formatiert ist.
3.. Hinzufügen von Anweisungen für Gemini:
prompt += "Based on these reviews, identify the key pain points for each product. Explain what sentiment polarity and subjectivity mean in the context of these reviews. Provide an overall sentiment summary for each product."Damit ein Benutzer die Ergebnisse von Vader besser verstehen kann, werden wir Anweisungen in die Eingabeaufforderung einbeziehen und dem Gemini mitgeteilt, welche Art von Informationen und Analysen im generierten Bericht zu erwarten sind.
4. zurückgeben die Eingabeaufforderung:
return prompt Gibt die komplette zurück prompt String, der jetzt zum Senden an Gemini bereit ist.
Schritt 11. Erstellen der Hauptanwendungsfunktion
Das main Funktion orchestriert die gesamte streamlit -Anwendung, bearbeitet die Benutzereingabe, asynchronbewertete Bewertungen, Überprüfung des Jobstatus, das Verarbeiten von Bewertungen, das Generieren von Berichten mit Gemini und das Anzeigen der Ergebnisse.
def main():
st.title("ScraperAPI Walmart Customer Reviews Analysis Tool")
st.markdown("Enter Walmart product review details below:")
# accept multiple product IDs and page numbers as comma-separated lists
product_ids_input = st.text_input("Walmart Product IDs (comma separated)", "")
tld = st.selectbox("Top Level Domain (TLD)", ("com", "ca"), index=0)
sort_options = ("relevancy", "helpful", "submission-desc", "submission-asc", "rating-desc", "rating-asc")
sort = st.selectbox("Sort By", sort_options, index=0)
pages_input = st.text_input("Page Numbers (comma separated for each product, e.g., 1,2 for first product)", "1")
# Initialize session state variables if not already set
if 'gemini_report' not in st.session_state:
st.session_state.gemini_report = None
if 'model' not in st.session_state:
st.session_state.model = genai.GenerativeModel('gemini-1.5-flash')
if 'review_data_prompt' not in st.session_state:
st.session_state.review_data_prompt = None
if 'jobs' not in st.session_state:
st.session_state.jobs = () # this will store dicts with product_id, page, job_id, status_url
if 'async_results' not in st.session_state:
st.session_state.async_results = {} # keyed by (product_id, page)
if 'processed_reviews' not in st.session_state:
st.session_state.processed_reviews = {} # Keyed by product_id
if 'reports' not in st.session_state:
st.session_state.reports = {} # kkeyed by report name
st.sidebar.header("Previous Reports")
if st.session_state.reports:
selected_report_name = st.sidebar.selectbox("Select a Report", list(st.session_state.reports.keys()))
st.sidebar.markdown("---")
st.subheader("View Previous Report")
st.markdown(st.session_state.reports(selected_report_name))
else:
st.sidebar.info("No reports generated yet.")
st.sidebar.markdown("---")
if st.button("Fetch Reviews (Async)"):
if product_ids_input.strip():
product_ids = (pid.strip() for pid in product_ids_input.split(",") if pid.strip())
pages_list = (p.strip() for p in pages_input.split(","))
st.session_state.jobs = () # Reset jobs list for new submission
st.session_state.async_results = {} # Reset results
st.session_state.processed_reviews = {} # Reset processed reviews
if len(pages_list) == 1:
# Apply the same page number to all products
pages_per_product = (int(pages_list(0))) * len(product_ids)
elif len(pages_list) == len(product_ids):
# Use the provided page numbers for each product
pages_per_product = (int(p) for p in pages_list if p.isdigit())
if len(pages_per_product) != len(product_ids):
st.error("Number of page numbers must match the number of product IDs or be a single value.")
return
else:
st.error("Number of page numbers must match the number of product IDs or be a single value.")
return
for i, pid in enumerate(product_ids):
page = pages_per_product(i)
try:
async_response = fetch_async_reviews(SCRAPERAPI_KEY, pid, tld, sort, page)
job_id = async_response.get("id")
status_url = async_response.get("statusUrl")
st.session_state.jobs.append({
"product_id": pid,
"page": page,
"job_id": job_id,
"status_url": status_url
})
st.info(f"Submitted job for Product {pid} Page {page}: Job ID {job_id}")
except Exception as e:
st.error(f"Error submitting async request for Product {pid} Page {page}: {e}")
st.session_state.gemini_report = None # Reset report on new fetch
else:
st.warning("Please enter at least one Walmart Product ID.")
st.markdown("---")
st.subheader("Async Job Status")
if st.session_state.jobs:
if st.button("Check Job Status"):
jobs = st.session_state.jobs
results_dict = {} # Key: (product_id, page), Value: job result (JSON)
with concurrent.futures.ThreadPoolExecutor() as executor:
future_to_job = {executor.submit(check_job_status, job("status_url")): job for job in jobs}
for future in concurrent.futures.as_completed(future_to_job):
job = future_to_job(future)
try:
status_data = future.result()
st.write(f"Job for Product {job('product_id')} Page {job('page')} status: {status_data.get('status')}")
if status_data.get('status') == 'finished':
job_result = get_job_result(status_data)
if job_result and isinstance(job_result, dict) and "reviews" in job_result:
results_dict((job("product_id"), job("page"))) = job_result
st.success(f"Job for Product {job('product_id')} Page {job('page')} finished.")
else:
st.error(f"Unexpected async results structure for Product {job('product_id')} Page {job('page')}.")
elif status_data.get('status') == 'failed':
st.error(f"Job for Product {job('product_id')} Page {job('page')} failed: {status_data.get('error')}")
except Exception as e:
st.error(f"Error checking job for Product {job('product_id')} Page {job('page')}: {e}")
st.session_state.async_results = results_dict
# Process all finished jobs and aggregate reviews per product
processed_reviews_per_product = {}
for (pid, p), job_result in results_dict.items():
processed_reviews = process_reviews_for_display(pid, job_result)
if pid not in processed_reviews_per_product:
processed_reviews_per_product(pid) = ()
processed_reviews_per_product(pid).extend(processed_reviews)
st.session_state.processed_reviews = processed_reviews_per_product
if st.session_state.processed_reviews and st.session_state.gemini_report is None:
prompt = generate_report_prompt(list(st.session_state.processed_reviews.keys()),
(review for reviews in st.session_state.processed_reviews.values() for review in reviews))
st.session_state.review_data_prompt = prompt
with st.spinner("Generating combined report with Gemini..."):
report = generate_gemini_report(st.session_state.model, prompt)
st.session_state.gemini_report = report
report_name = f"Combined Report for Products {', '.join(st.session_state.processed_reviews.keys())} - {datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')}"
st.session_state.reports(report_name) = report
else:
st.info("No async job submitted yet.")
# Display the processed review data per product
if st.session_state.processed_reviews:
st.markdown("---")
st.subheader("Processed Review Data:")
for pid, reviews in st.session_state.processed_reviews.items():
st.markdown(f"**Product ID: {pid}**")
for i, review in enumerate(reviews):
st.markdown(f"- **Review {i+1}:**")
st.markdown(f" - **Text:** {review('text')}")
if review('pain_points'):
st.markdown(f" - **Pain Points:** {', '.join(review('pain_points'))}")
else:
st.markdown(" - **Pain Points:** None")
st.markdown(f" - **Sentiment:** Polarity={review('sentiment')('polarity'):.2f}, Subjectivity={review('sentiment')('subjectivity'):.2f}")
st.markdown("---")
if st.session_state.gemini_report:
st.markdown("---")
st.subheader("Generated Walmart Customer Reviews Analysis Report")
st.markdown(st.session_state.gemini_report)
st.markdown("### Ask Additional Questions")
user_query = st.text_input("Enter your question here", key="user_query")
if st.button("Submit Question"):
if st.session_state.review_data_prompt is not None:
question_prompt = (
"You are an expert in customer review analysis and product evaluation. "
"Based on the following review data, provide a detailed, critically evaluated answer to the question below.nn"
"Review Data:n" + st.session_state.review_data_prompt + "nn"
"Question: " + user_query
)
with st.spinner("Generating answer from Gemini..."):
answer = generate_gemini_report(st.session_state.model, question_prompt)
st.markdown("### Answer to Your Question")
st.markdown(answer)
else:
st.markdown("Please generate a report first.")
if __name__ == "__main__":
main()
Der obige Code definiert die main Funktion, die den Fluss und die Benutzerinteraktionen der Stromanwendung steuert. Hier ist eine detaillierte Aufschlüsselung des Code:
1. Legt die Benutzeroberfläche ein:
st.title(...) and st.markdown(...): Zeigen Sie den Titel und den Einführungstext der Anwendung an.st.text_input(...), st.selectbox(...): Erstellen Sie Eingabefelder, damit Benutzer ihre Walmart-Produkt-IDs eingeben können, wählen Sie die Domäne auf der obersten Ebene, wählen Sie die Sortiermethode für Überprüfungen und geben Sie Seitennummern ein.
2. Verwalten des Anwendungszustands:
- Es initialisiert mehrere
st.session_stateVariablen. Der Sitzungsstatus ermöglicht es der Anwendung, Informationen über Benutzerinteraktionen hinweg zu erinnern, z. B. generierte Berichte, abgerufene Jobs und verarbeitete Bewertungen. Auf diese Weise verhindern wir, dass Daten bei jeder Wiederholung zurückgesetzt werden.
3.. Vorherige Berichte anzeigen:
- Weiter unten überprüft es, ob bereits Berichte generiert wurden (gespeichert in
st.session_state.reports). In diesem Fall wird eine Seitenleiste mit einer Dropdown -Liste angezeigt, um diese vorherigen Berichte auszuwählen und anzeigen.
4. Abrufen von Bewertungen: Abruf: Wenn der Benutzer auf die Schaltfläche „Bewertungen (ASync) abrufen“ klickt:
- Es analysiert die eingegebenen Produkt -IDs und Seitenzahlen.
- Es setzt die zurück
jobs, async_resultsUndprocessed_reviewsSitzungsstatusvariablen für eine neue Anfrage. - Es iteriert die bereitgestellten Produkt -IDs und Seiten, wobei es das aufruft
fetch_async_reviewsFunktionieren Sie, um einen Schablonenjob für jeden zu erhalten. - Es speichert Informationen zu jedem eingereichten Job (Produkt -ID, Seite, Job -ID, Status -URL) in der
st.session_state.jobsListe. - Es zeigt Nachrichten an den Benutzer an, der die Einreichung jedes Jobs angibt.
5. Asynchronen Jobstatus überprüfen:
HierAnwesend Wenn der Benutzer auf das klickt "Jobstatus überprüfen" Taste:
- Es iteriert die in gespeicherten Jobs in
st.session_state.jobs. - Es verwendet a
concurrent.futures.ThreadPoolExecutorgleichzeitig das nennencheck_job_statusFunktion für die Status -URL jedes Jobs, Verbesserung der Effizienz. - Für jeden Job wird der aktuelle Status angezeigt.
- Wenn ein Job abgeschlossen ist, ruft er an
get_job_resultUm die abgekratzten Daten abzurufen. - Wenn die Daten erfolgreich abgerufen werden, speichert sie sie in der
st.session_state.async_resultsWörterbuch. - Es ruft dann an
process_reviews_for_displaySo analysieren und Schmerzpunkte aus den abgerufenen Überprüfungen extrahieren und die verarbeiteten Daten in speichernst.session_state.processed_reviewsorganisiert nach Produkt -ID.
6. Erzeugen des Gemini -Berichts:
Nachdem die Jobs überprüft wurden und Bewertungen bearbeitet wurden, wenn bearbeitete Bewertungen vorliegen und noch nicht ein Bericht erstellt wurde:
- Es ruft
generate_report_promptErstellen einer Eingabeaufforderung für das Gemini -Modell basierend auf den verarbeiteten Überprüfungen. - Es verwendet
st.spinnerSo zeigen Sie eine Ladenachricht beim Aufrufen angenerate_gemini_reportUm den Bericht von Gemini zu erhalten. - Es speichert den generierten Bericht in
st.session_state.gemini_reportund speichert es als benannten Bericht inst.session_state.reports.
7. Ergebnisse anzeigen:
- Es zeigt die verarbeiteten Überprüfungsdaten (Text, Schmerzpunkte, Stimmung) für jedes Produkt an.
- Wenn ein Gemini -Bericht erstellt wurde, wird der Bericht angezeigt.
- Es bietet dem Benutzer ein Eingabefeld, um zusätzliche Fragen zu den Bewertungen zu stellen, die dann für eine Antwort an Gemini gesendet werden.
8. Ausführen der Anwendung:
if __name__ == "__main__": main(): Dieses Standard -Python -Konstrukt stellt sicher, dass diemain()Die Funktion wird ausgeführt, wenn das Skript direkt ausgeführt wird.
Im Wesentlichen verbindet die Hauptfunktion alle anderen Funktionen im Skript zusammen, um eine funktionale Webanwendung zu erstellen, mit der ein Benutzer Walmart -Kundenbewertungen mithilfe von Scraperapi und Gemini abrufen, verarbeiten und analysieren können. Es verwaltet die Benutzeroberfläche, übernimmt Benutzerinteraktionen, orchestriert die Daten zum Abrufen und Verarbeiten von Pipelines und zeigt die Ergebnisse in einem geeigneten, benutzerfreundlichen Format an.
Hier ist ein Ausschnitt davon, wie die Benutzeroberfläche des Werkzeugs aussieht:

Bereitstellung der Walmart Reviews -Analyse -App mit streamlit
Hier erfahren Sie, wie Sie unsere Walmart -Analyse -App bereitstellen Auf streamlit für kostenloses Cloud -Hosting in nur wenigen Schritten:
Schritt 1: Richten Sie ein Github -Repository ein
Nach Strom müssen Ihr Projekt veranstaltet werden Github.
1. Erstellen Sie ein neues Repository auf GitHub
Erstellen Sie ein neues Repository auf GitHub und setzen Sie es als öffentlich.
2. Drücken Sie Ihren Code zu GitHub
Wenn Sie Git noch nicht eingerichtet und Ihr Repository verknüpft haben, verwenden Sie die folgenden Befehle in Ihrem Terminal:
git init
git add .
git commit -m "Initial commit"
git branch -M main
git remote add origin https://github.com/YOUR_USERNAME/walmart_reviews_tool.git
git push -u origin main
Schritt 2: Speichern Sie Ihr Gemini -Token als Umgebungsvariable
Bevor Sie Ihre App bereitstellen, müssen Sie Ihr Gemini -Token in Ihrem System als Umgebungsvariable sicher speichern, um sie vor Missbrauch durch andere zu schützen.
1. Stellen Sie Ihr Token als Umgebungsvariable (lokal) ein:
export GOOGLE_API_TOKEN="your_token"
set GOOGLE_API_TOKEN="your_token"
- Verwenden Os.Environ Um das Token in Ihrem Skript abzurufen:
import os
GOOGLE_API_TOKEN = os.environ.get("GOOGLE_API_TOKEN")
if GOOGLE_API_TOKEN is None:
print("Error: Google API token not found in environment variables.")
# Handle errors
else:
# Use GOOGLE_API_TOKEN in your Google Developer API calls
print("Google API token loaded successfully")
- Starten Sie Ihren Code -Editor neu.
Schritt 3: Erstellen Sie eine Anforderungen.txt -Datei
Streamlit muss wissen, welche Abhängigkeiten Ihre App benötigt.
1. Erstellen Sie in Ihrem Projektordner eine Datei namens Anforderungen.txt.
2. Fügen Sie die folgenden Abhängigkeiten hinzu:
streamlit
requests
google-generativeai
nltk
3. Speichern Sie die Datei und verpflichten Sie sie bei GitHub:
git add requirements.txt
git commit -m "Added dependencies"
git push origin main
4. Tun Sie dasselbe für die App.py -Datei, die Ihren gesamten Code enthält:
git add app.py
git commit -m "Added app script"
git push origin main
Schritt 4: Bereitstellen in der streamlitischen Cloud
1.. Gehen Sie zu Stromlit Community Cloud.
2. Klicken Sie auf "Anmelden mit Github" und die Stromversorgung autorisieren.
3. Klicken Sie "App erstellen."
4.. Wählen Sie “Stellen Sie eine öffentliche App von Github Repo bereit. “
5. in der Repository -Einstellungeneingeben:
- Repository:
YOUR_USERNAME/Walmart-Reviews-application - Zweig:
main - Hauptdateipfad:
app.py(oder was auch immer Ihr streamlites Skript benannt ist)
6. Klicken Sie klicken "Einsetzen" und warten Sie, bis die App die App erstellt.
Schritt 5: Holen Sie sich Ihre Stromlit -App -URL
Nach dem Einsatz wird Streamlit a generieren öffentliche URL (z.B, https://your-app-name.streamlit.app). Sie können diesen Link jetzt freigeben, damit andere auf Ihr Tool zugreifen können!
Abschluss
In diesem Tutorial haben wir ein leistungsstarkes Tool erstellt, das die Walmart -Rezensionen von Scraperapis asynchronen Endpunkt mit Vader für die Stimmungsanalyse und Gemini für die Erstellung aufschlussreicher Berichte kombiniert - alle, die über ein sauberes und interaktives optimiges Interface präsentiert werden.
Diese Anwendung ist ein Game-Changer für die Marktforschung, da sie die Trends der Kundenstimmung identifizieren, potenzielle Schmerzpunkte frühzeitig hervorheben und die Wettbewerbsanalyse unterstützen kann, indem sie untersuchen, wie Käufer auf ähnliche Produkte reagieren.
Bereit, Ihre eigenen zu bauen? Verwenden Sie noch heute Schakerapi und verwandeln Sie Raw Walmart -Kundenbewertungen in wertvolle geschäftliche Erkenntnisse!
