
Erstellen Sie ein benutzerdefiniertes Tiktok -Influencer -Scouting -Tool, mit dem Sie die Ersteller nach Land, Follower -Anzahl und mehr filtern, während Sie Follow -up -Abfragen unterstützen, indem Sie den Scraperapi Langchain -Agenten für die Datenextraktion, die LLM von QWEN3 für kontextbezogene Erkenntnisse und Streamlit für kostenlose App -Hosting verwenden.

Influencer -Marketing inirdiert sich schnell traditionelle Anzeigen, insbesondere bei jüngeren Zielgruppen, die die Authentizität und Relativität schätzen. Mikro-Influencer mit ihren engmaschigen und hoch engagierten Gemeinden inspirieren weitaus mehr Vertrauen und Loyalität als ein generisches Banner, das es je gab.
Die Anhängerzählungen und Engagement -Metriken allein werden jedoch den Erfolg garantieren. Was die Nadel wirklich bewegt, arbeitet mit Schöpfer zusammen, deren einzigartige Stimme, Werte und Vision Ihre Marke widerspiegeln, die eher echte Aktionen als leere Klicks auslösen.
Wir bauen eine Lösung auf, die dank seines hochpassbaren Ansatzes die Lead -Generierung und ein gezielter Marketing erhöhen und Ihnen helfen kann, den richtigen Influencer zu finden, um Ihre Marke wirklich zu steigern.
Sie werden lernen, wie Sie ein Tiktok-Influencer-Scouting-Tool erstellen, das den Langchain-SCRAPRAPI-Agenten zum Abkratzen von Rohdaten und zum Auffinden von Nischenschöpfer durch natürliche Anfragen verwendet.
Wir werden QWEN3 als unser großes Sprachmodell verwenden, um das kontextbezogene Verständnis des Tools zu vertiefen und die fertige App kostenlos in der Cloud bereitzustellen und zu hosten.
Fangen wir an.
AI -Agenten in Langchain verstehen
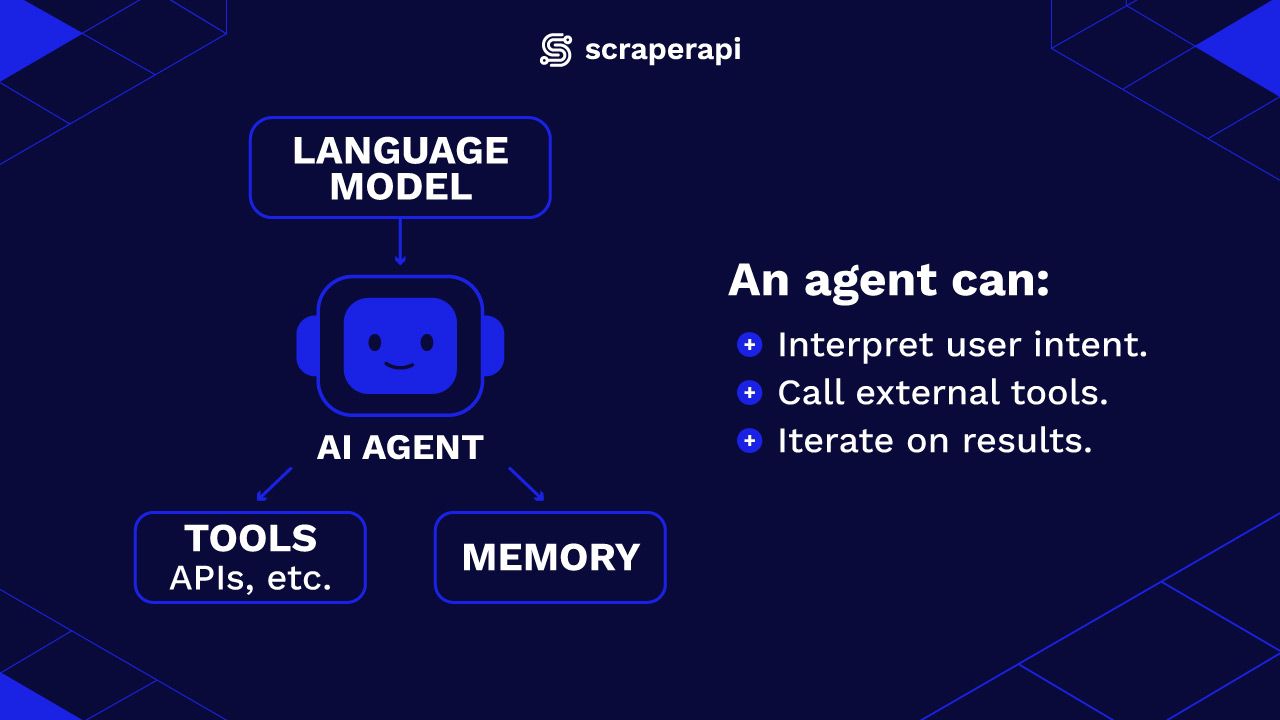
Grundsätzlich ist ein AI -Agent ein Programm, das ein großes Sprachmodell (LLM) mit Tools und Speicher kombiniert, um Aufgaben autonom auszuführen. Anstatt auf einmalige Eingabeaufforderungen zu reagieren, kann ein Agent:
- Interpretieren und führen Sie die Benutzerabsichte aus, indem Sie hochrangige Abfragen in umsetzbare Schritte unterteilen.
- Rufen Sie externe Tools wie APIs, Web -Scrapers, Datenbanken usw. an, um Informationen zu sammeln oder zu verarbeiten.
- Setzen Sie die Ergebnisse weiter und iterieren Sie, bis es den Anforderungen des Benutzers erfüllt.
Was Agenten von Standard -LLM -Anwendungen unterscheidet, ist die Fähigkeit, fundierte Entscheidungen darüber zu treffen, welche Maßnahmen als nächstes auf der Grundlage von Zwischenergebnissen ergreifen sollen. Agenten reagieren nicht nur – sie sind aktive Teilnehmer an der Lösung einer Aufgabe.
Anstatt beispielsweise zu antworten: „Wie ist das Wetter in Paris?“, Kann ein Langchain-Agent auf eine komplexe, mehrteilige Abfrage reagieren:
„Planen Sie einen Wochenendausflug in Paris. Ich brauche Wettervorhersagen, Hotelpreise unter 200 US -Dollar pro Nacht und Vorschläge für Indoor -Aktivitäten, wenn es regnet.“
Der Agent löst dies nieder, verwendet Tools wie das Google-Suchwerkzeug für Scraperapi und einen allgemeinen Web-Schaber, um jede Informationen wie Wetterdaten, Hotellisten und lokale Attraktionen zu sammeln und dann alles zu einer vollständigen Antwort zu kombinieren.
Langchain bietet einen flexiblen Rahmen, um diese Komponenten zusammenzustellen. Sie definieren eine Reihe von Funktionen, APIs oder Scrapern, wickeln sie mit einfachen Adaptern ein und verdrahten sie dann in einen Agenten, der das LLM verwendet, um zu entscheiden, wann und wie Sie jede Ressource aufrufen.
Wie funktioniert autonomes Kratzen mit der Langchain -S -Craperapi -Integration?
Die Integration von Langchain-Craperapi ist ein Python-Paket, mit dem AI-Agenten das Web mit dem Schaferapi kratzen können. Das Paket enthält drei verschiedene Komponenten, die jeweils einem offiziellen Schaferapi -Endpunkt entsprechen:
- Scraperapitool: Ermöglicht dem AI -Agenten, jede Website zu kratzen und Daten abzurufen
- Scraperapigooglesearchtool: Ermöglicht dem Agenten speziell, die Google -Suchergebnisse und -Rankings zu erzählen.
- Scraperapiamazonsearchtool: Scrape Amazon Suchergebnisse und Rankings ausschließlich.
Alles, was Sie tun müssen, um dieses Paket in Python zu verwenden, ist, es mit PIP zu installieren und dann die Komponenten zu importieren:
pip install -U langchain-scraperapi
from langchain_scraperapi.tools import (
ScraperAPITool,
ScraperAPIGoogleSearchTool,
ScraperAPIAmazonSearchTool
)
Wenn Sie es noch nicht haben, erstellen Sie ein Scraperapi -Konto und erhalten Sie Ihre API -Taste. Stellen Sie es als Umgebungsvariable fest. Rennen Sie in Ihrem Terminal:
export SCRAPERAPI_API_KEY="your API key"
Sobald die Tools installiert sind, können Sie eine Instanz von ihnen erstellen und Parameter wie die URL zum Kratzen, das gewünschte Ausgangsformat und alle zusätzlichen Optionen bereitstellen, die Sie benötigen. Hier ist ein Beispiel:
from langchain_scraperapi.tools import ScraperAPITool
tool = ScraperAPITool()
print(tool.invoke(input={"url": "walmart.com", "output_format": "markdown"}))
Der obige Code initialisiert eine der Komponenten des Pakets, ScraperAPIToolschreibt es als Variable zu und verwendet dann die invoke Methode zum Kratzen von „Walmart.com“ und Anfragen der Ausgabe in Markdown -Format. Der abgekratzte Inhalt wird dann gedruckt.
Das Tolle an Agenten ist, dass Sie sie in der natürlichen Sprache anweisen können, komplexe Aufgaben zu erledigen. Zum Beispiel können wir dem Scraperapi-LangChain-Agenten eine Abfrage zum Durchsuchen und Rückgabergebnis und sogar Bildern von Teddybären an Amazon geben, und genau das wird dies tun. Unten finden Sie ein Beispiel des Code:
from langchain_scraperapi.tools import ScraperAPIAmazonSearchTool
tool = ScraperAPIAmazonSearchTool()
print(tool.invoke(input={"query": "show me pink teddy bears for sale on Amazon"}))
Die Verwendung des regulären Scraperapi -Amazon -Endpunkts gibt ebenfalls die gleichen Ergebnisse zurück, aber Sie müssen eine tatsächliche Amazon -URL mit rosa Teddybären ausstellen und dann versuchen, die Webseite zu kratzen. Durch die Verwendung des Scraperapi-LangChain-Agenten wird es einfacher, komplexe Daten mit minimaler Codierung und Ressourcen sofort abzurufen.
So erhalten Sie QWEN3 von OpenRouter
Wenn wir von OpenRouter ein großes Sprachmodell verwenden, müssen wir ein Konto einrichten und den API -Schlüssel herausholen, bevor wir Anfragen stellen können.
Was QWEN -Modelle auszeichnet, ist ihre Effizienz und Skalierbarkeit, insbesondere wenn es um diejenigen, die auf der Mischung aus Experten (MOE) -Scharchitektur basieren. Im Gegensatz zu herkömmlichen großsprachigen Modellen, bei denen alle Parameter für jede Abfrage aktiviert werden, enthalten MOE-Modelle mehrere „Experten“ -Subnetzwerke.
Dies bedeutet, dass MOE-Modelle, wenn sie Informationen verarbeiten, nur eine kleine Untergruppe spezialisierter Unter-Networks („Experten“) basierend auf erlernten Routing-Entscheidungen aktivieren und ihnen ermöglicht, eine Abfrage zu interpretieren, zu verstehen und auf sie zu reagieren, ohne das vollständige Modell einzubeziehen. Diese selektive Aktivierung ermöglicht es MOE -Modellen, eine hohe Leistung aufrechtzuerhalten und gleichzeitig die Rechenaufwand und die Kosten erheblich zu verringern.
Infolgedessen liefert QWEN3 konsequent Antworten, die sehr kontextbezogen, informativ und relevant sind.
Hier ist eine Anleitung zum Zugriff auf ein Modell von OpenRouter:
- Melden Sie sich bei OpenRouter anAnwesend Melden Sie sich an und erstellen Sie ein kostenloses Konto:
- Nachdem Sie Ihre E -Mail überprüft haben, melden Sie sich in der Suchleiste an und suchen Sie nach QWEN3 -Modellen (oder einem anderen LLM unserer Wahl):
- Gehen Sie zum QWEN3 -Modell Ihrer Wahl:
- Klicken Sie auf „API“ Erstellen Sie einen persönlichen API -Zugriffsschlüssel für Ihr Modell.
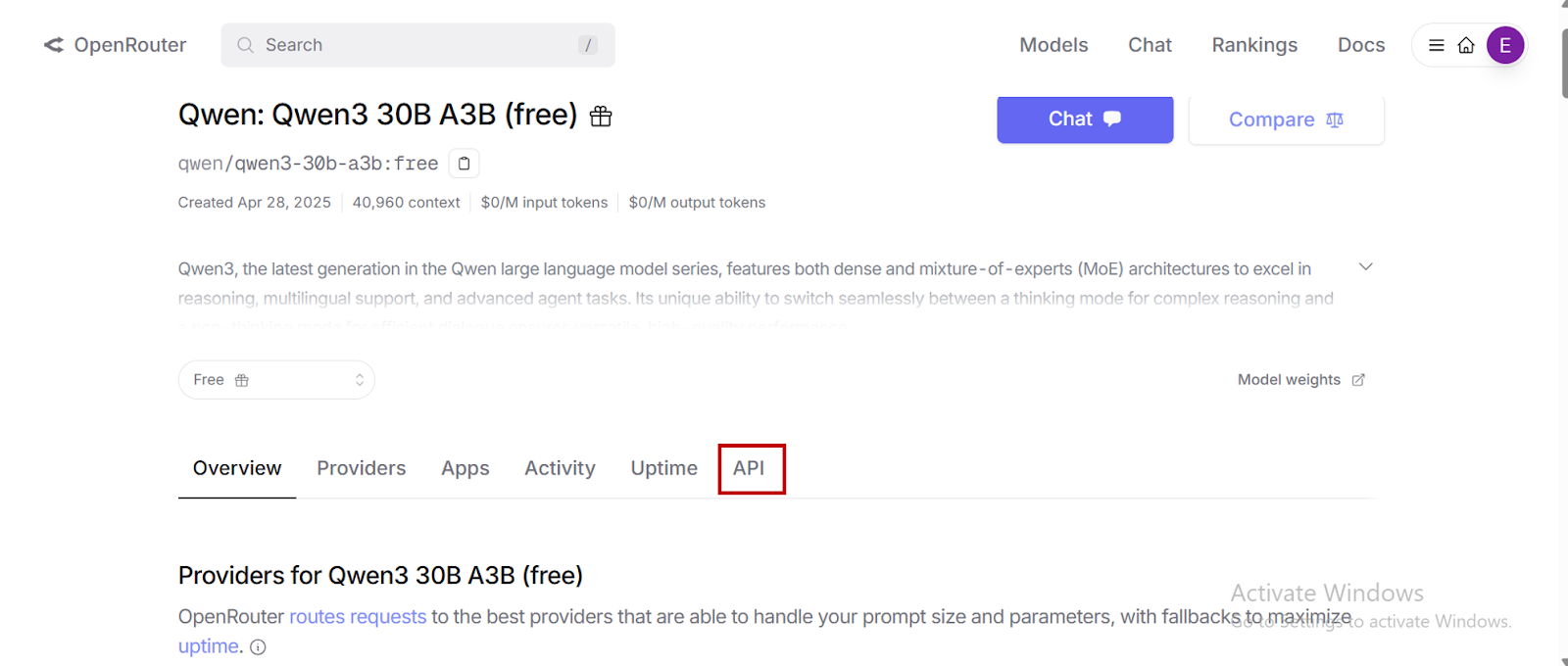
- Wählen „API -Schlüssel erstellen“ Kopieren Sie und speichern Sie dann Ihren neu erstellten API -Schlüssel.
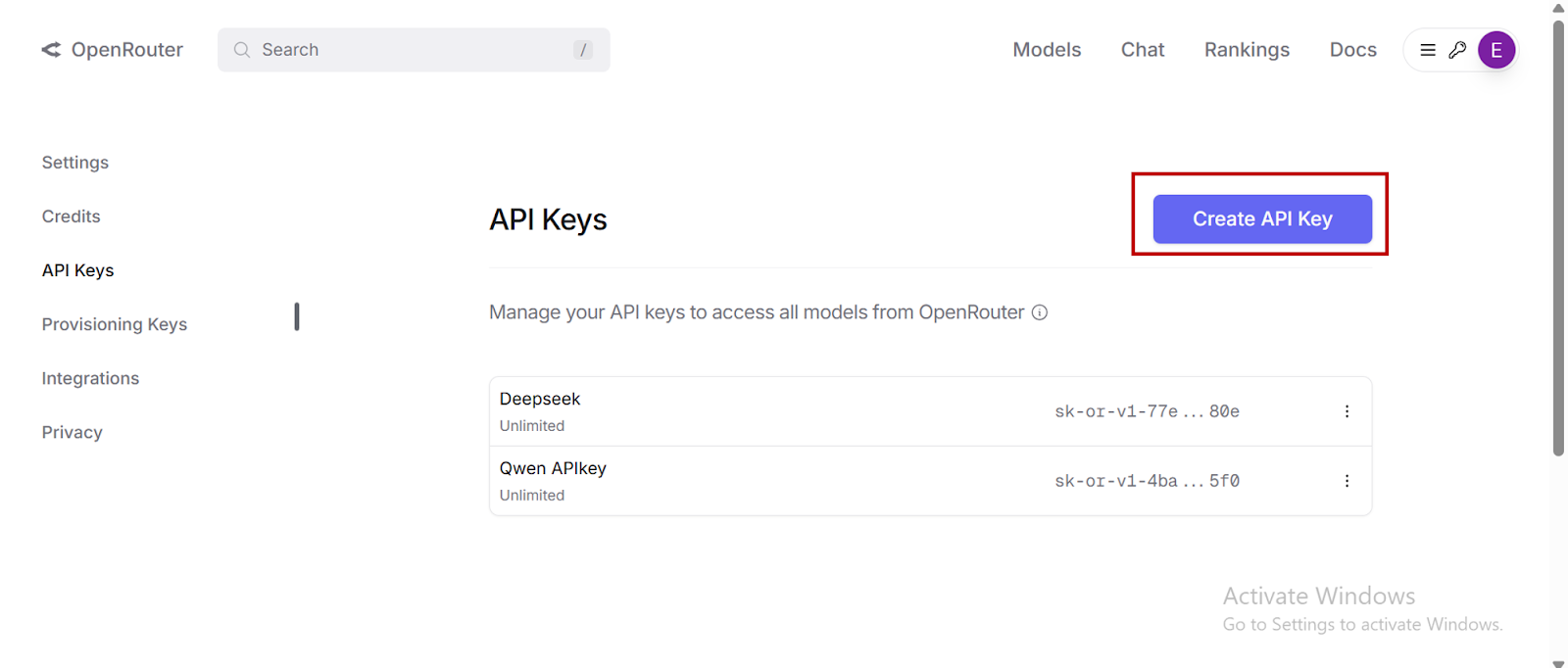
- Teilen Sie Ihren API -Schlüssel nicht öffentlich.
Erste Schritte mit Schakerapi
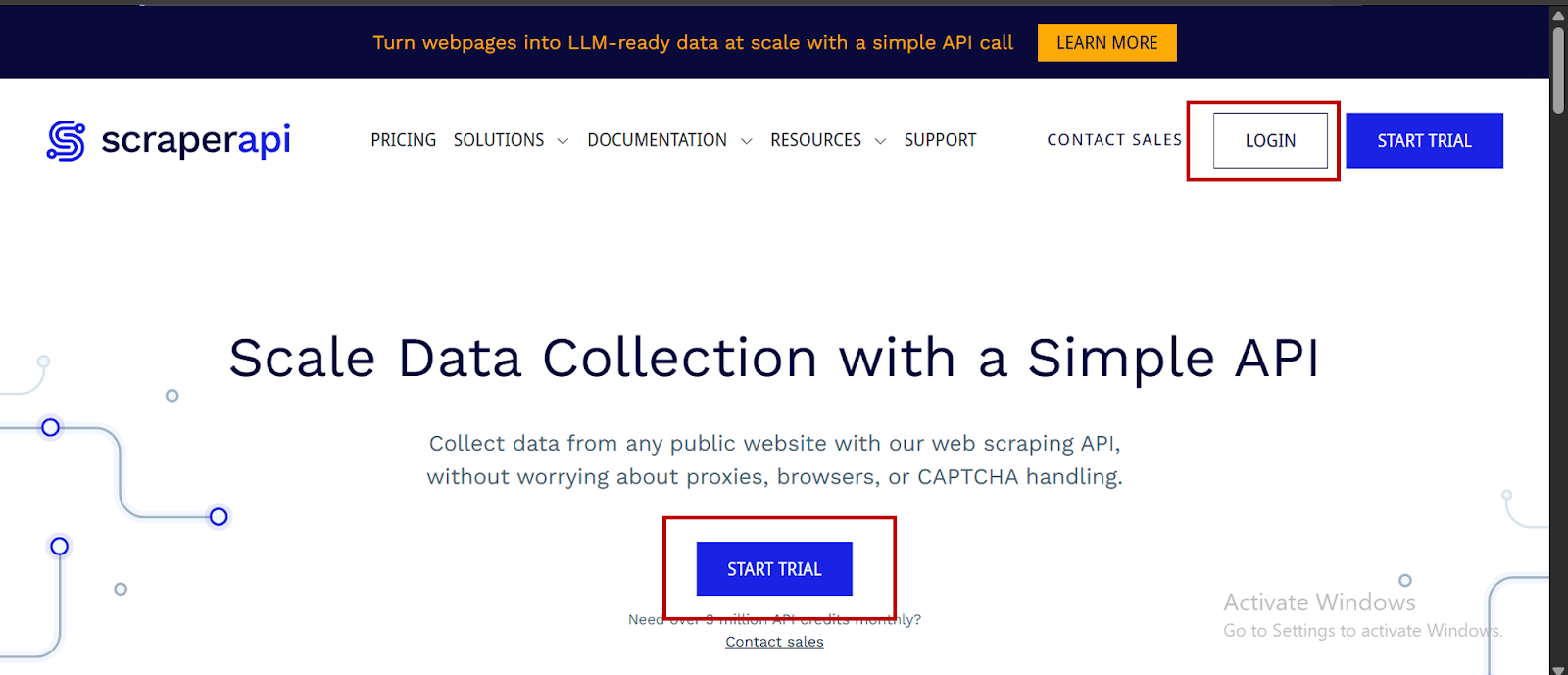
- Gehen Sie zunächst zu Scraperapis Dashboard. Wenn Sie noch kein Konto haben, klicken Sie auf “Versuch beginnenUm einen zu erstellen:
- Nachdem Sie Ihr Konto erstellt haben, haben Sie Zugriff auf ein Dashboard, die Ihnen eine zur Verfügung stellen API -SchlüsselAnwesend Zugriff auf 5000 API -Credits (7-Tage-begrenzte Testzeit) und Informationen über das Abkratzen.
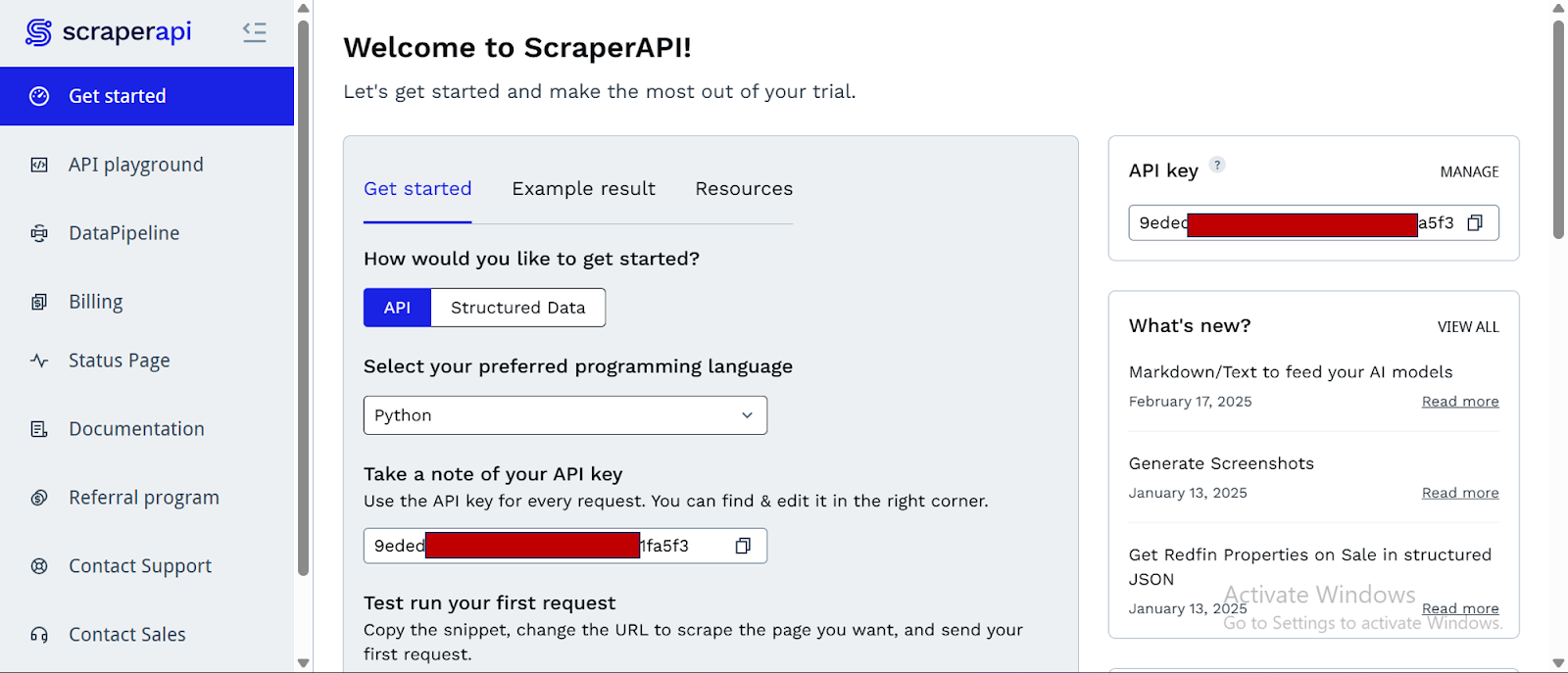
- Um auf weitere Credits und erweiterte Funktionen zuzugreifen, klicken Sie nach unten und klicken Sie auf „Upgrade auf größeren Plan.“
- Scraperapi bietet Dokumentation für verschiedene Programmiersprachen und Frameworks – wie PHP, Java und Node.js -, die mit seinen Endpunkten interagieren. Sie können diese Ressourcen finden, indem Sie auf die Dashboard -Seite nach unten scrollen und klicken “Alle Dokumente anzeigen”:
Jetzt sind wir alle festgelegt, lass uns unser Werkzeug erstellen.
Aufbau des Scouting-Tools von Tiktok Brand-Influencer
Schritt 1: Einrichten des Projekts
Erstellen Sie einen neuen Projektordner, eine virtuelle Umgebung und installieren Sie die erforderlichen Abhängigkeiten.
mkdir tiktok_influencer_project # Creates the project folder
cd tiktok_influencer_project # Moves you inside the project folder
python -m venv your-env-name # Creates a new envirobment
Aktivieren Sie die Umgebung:
your-env-name\Scripts\activate
source your-env-name/bin/activate
Und jetzt können Sie die Abhängigkeiten installieren, die wir benötigen:
pip install streamlit tiktoken langchain-openai langchain-scraperapi
Die wichtigsten Abhängigkeiten und ihre Funktionen sind:
streamlit: Wir brauchen dies, um die Benutzeroberfläche der App zu erstellen, damit Benutzer ihre Nischen- und andere Filter direkt eingeben können und gleichzeitig Ergebnisse in Echtzeit sehen können.tiktoken: Diese Bibliothek stammt aus OpenAI und wird zum Tokenisierungs -Text und zur Schätzung der Token -Zählungen verwendet. In unserem Projekt verwenden wir es, um die Länge der an das Sprachmodell gesendeten Abfragen zu schätzen, sodass wir die API -Grenzen nicht überschreiten.langchain-openai: Dies ist ein separates Paket, das die Integration mit OpenAI-kompatiblen großen Sprachmodellen (LLMs) bietet. Daher verwenden wir es, um QWEN über OpenRouter zu verbinden, damit unsere Bewerbung Eingabeaufforderungen gesendet und Antworten auf AI-generierte Antworten erhalten kann.langchain-scraperapi: Dies ist das Paket, das die Fähigkeiten von Scraperapi und Langchain in Form eines Agenten integriert, mit dem Web -Scraping und Google autonom sucht.
Schritt 2: Integration des Langchain-Craperapi-Pakets
Erinnern Sie sich am Anfang, als wir unseren Schaferapi -Schlüssel als Umgebungsvariable einstellen und die von uns benötigten Abhängigkeiten installiert haben? Wenn Sie dieselbe Umgebung nutzen, können Sie loslegen. Wenn Sie jedoch in einem neuen arbeiten, haben Sie noch nicht die Pakete, die Sie benötigen. Installieren Sie Langchain-Craperapi:
pip install -U langchain-scraperapi
Zuvor haben wir unseren Scraperapi -Schlüssel als Umgebungsvariable exportiert. Diesmal benötigen wir jedoch auch unseren OpenRouter -API -Schlüssel. Wir könnten beide exportieren, aber der Exportieren von Schlüssel in die Umgebung ist eine temporäre Lösung (die Anmeldeinformationen werden nur für eine begrenzte Zeit lokal gespeichert). Um sicherzustellen, dass wir sowohl unseren Schlüssel in unserer Umgebung sicher verstaut haben als auch jeden Moment bereit, Python-dotenv zu verwenden.
pip install python-dotenv
Erstellen Sie eine neue .env -Datei und fügen Sie Ihre API -Schlüssel hinzu:
SCRAPERAPI_API_KEY="your-scraperapi-key"
OPENROUTER_API_KEY="your-openrouter-key"
Schritt 3: Bibliotheken importieren und API -Schlüssel einrichten
Der nächste Schritt besteht darin, alle erforderlichen Bibliotheken zu importieren und die API -Schlüssel sicher zu laden, die für die Interaktion mit externen Diensten wie Scraperapi und OpenRouter (für LLM) erforderlich sind.
import os
import streamlit as st
import tiktoken
from langchain_openai import ChatOpenAI
from langchain.agents import initialize_agent, Tool
from langchain.agents.agent_types import AgentType
from langchain_scraperapi.tools import (
ScraperAPITool,
ScraperAPIGoogleSearchTool,
ScraperAPIAmazonSearchTool
)
from dotenv import load_dotenv
load_dotenv()
# Loading API Keys
scraperapi_key = os.environ.get("SCRAPERAPI_API_KEY")
openrouter_api_key = os.environ.get("OPENROUTER_API_KEY")
# Let’s include API Key checks as a safety net and for easier debugging
if not scraperapi_key:
st.warning("ScraperAPI key might not be correctly set. Using the provided default or placeholder.")
if scraperapi_key == "YOUR_SCRAPERAPI_API_KEY":
st.error("Please replace 'YOUR_SCRAPERAPI_API_KEY' with your actual key in the script.")
st.stop()
if not openrouter_api_key:
st.error("OPENROUTER_API_KEY not found or is still the placeholder. Please set it in the script.")
st.stop()
Der obige Code erreicht Folgendes:
Importe:
os: Wird verwendet, um mit dem Betriebssystem zu interagieren, insbesondere zum Einstellen und Erhalten von Umgebungsvariablen.streamlit as st: Die Kernbibliothek zum Erstellen der Benutzeroberfläche der Web -App.tiktoken: Für die Schätzung der Anzahl der Token innerhalb der Eingabeaufforderungen, die an die LLM gesendet wurden.langchain_openai.ChatOpenAI: Importiert die Klasse so, dass sie mit OpenAI-kompatiblen Chat-Modellen interagiert (wie das QWEN-Modell in diesem Fall über OpenRouter).langchain.agents.initialize_agent, Tool: Schlüsselkomponenten von Langchain zum Erstellen und Verwalten des KI -Agenten und der Tools, die es verwenden kann.langchain.agents.agent_types.AgentType: Gibt verschiedene Arten von Langchain -Agenten an.langchain_scraperapi.tools: Importiert spezifische Tools, die mit Scraperapi für Web -Scraping und -Suche gearbeitet haben.
API -Tasten Setup:
load_dotenv(): Lädt die Schlüssel aus.envscraperapi_key = os.environ.get("SCRAPERAPI_API_KEY"): Ruft den Wert der abSCRAPERAPI_API_KEYUmgebungsvariable.openrouter_api_key = os.environ.get("OPENROUTER_API_KEY"): Ruft den Wert der abOPENROUTER_API_KEYUmgebungsvariable.
API -Schlüsselprüfungen:
- Der
if not scraperapi_key:Undif not openrouter_api_key:Blöcke bieten eine grundlegende Validierung. Sie prüfen, ob die API -Schlüssel festgelegt wurden, oder geben Sie eine Warnung ab, ob sie fehlen oder die Platzhalterwerte enthalten. Wenn die Tasten nicht festgelegt sind, stoppt die Streamlit -App die Ausführung (st.stop()), um Fehler weiter unten zu verhindern.
Schritt 4: Erstellen des stromlitischen UI -Layouts
Hier richten wir das grundlegende Layout und die Texte für die streamlit -Web -Benutzeroberfläche ein.
# Streamlit UI Setup
st.set_page_config(page_title="TikTok Influencer Finder", layout="centered")
st.title("TikTok Influencer Finder 🧑🏼🤝🧑🏿🌐")
st.markdown("""
Welcome! This bot uses ScraperAPI's Langchain AI Agent for web scraping and a **Qwen LLM (via OpenRouter)**
to help you discover TikTok influencers who might be a great fit to promote your brand.
Please provide your brand's niche (e.g., 'sustainable running shoes', 'female luxury bags', 'men's watches').
""")
Hier ist, was der obige Code erreicht:
st.set_page_config(...): Konfiguriert die Seite „Streamlit „Tiktok Influencer Finder“ und das Layout zu „Zentriert.“st.title(...): Zeigt den Haupttitel der Anwendung auf der Webseite an.st.markdown(...): Rendert einen Block des Markdown -Textes und dient als willkommene Nachricht und eine kurze Erläuterung des Zwecks des Werkzeugs und der Funktionsweise.
Schritt 5: Initialisierung von Langchain -Werkzeugen
Jetzt werden wir die Tools vorbereiten, mit denen der Langchain -Agent mit dem externen Web interagieren wird. (Speziell, um Web -Suchanfragen auszuführen und Inhalte zu kratzen) mithilfe von Scraperapi.
# Initializing Tools
try:
scraper_tool = ScraperAPITool(scraperapi_api_key=scraperapi_key)
google_search_tool = ScraperAPIGoogleSearchTool(scraperapi_api_key=scraperapi_key)
except Exception as e:
st.error(f"Error initializing ScraperAPI tools: {e}.")
st.stop()
tools = (
Tool(
name="Google Search",
func=google_search_tool.run,
description="Useful for finding general information online, including articles, blogs, and lists of TikTok influencers."
),
Tool(
name="General Web Scraper",
func=scraper_tool.run,
description="Useful for scraping content from specific URLs after search."
)
)
Nachfolgend finden Sie eine weitere Aufschlüsselung dessen, was der obige Code tut:
Werkzeuginitialisierung:
scraper_tool = ScraperAPITool(...): Erstellt eine Instanz eines allgemeinen Web -Scabing -Tools vonlangchain-scraperapiauthentifiziert mit Ihremscraperapi_key. Dieses Tool kann Inhalte von einer bestimmten URL abkratzen.google_search_tool = ScraperAPIGoogleSearchTool(...): Erstellt eine Instanz eines Google -Such -Tools, das ebenfalls von Scraperapi betrieben wird. Mit diesem Tool kann der Agent Google -Suchvorgänge ausführen.- Der
try-exceptBlock behandelt potenzielle Fehler während der Initialisierung dieser Tools, wobei eine Fehlermeldung in Streamlit angezeigt wird und die App gestoppt wird, wenn etwas schief geht.
Toolsliste für Langchain Agent:
tools = (...): Definiert eine Liste vonToolObjekte. JedeToolist ein Wrapper, der dem Langchain -Agenten eine externe Funktion zur Verfügung stellt.- Tool „Google Search“: Mit dem Namen „Google Search“, seine Funktion (
func) ist aufgoogle_search_tool.runWenn der Agent dieses Tool „verwendet“, wird eine Google -Suche ausgeführt. Derdescriptionsagt dem LLM, wofür dieses Tool nützlich ist. - Tool „Allgemeines Web -Scraper“: Mit dem Namen „General Web Scraper“ ist seine Funktion
scraper_tool.run. Seine Beschreibung zeigt an, dass es sich um das Abkratzen bestimmter URLs handelt, normalerweise nach einer Suche.
Schritt 6: Initialisierung des großen Sprachmodells (LLM)
Es ist jetzt an der Zeit, das große Sprachmodell (LLM) zu initialisieren, das als „Gehirn“ des Agenten dient und es ermöglicht, Aufforderungen zu verstehen und über Aktionen zu entscheiden.
QWEN_MODEL_NAME = "qwen/qwen3-30b-a3b:free"
llm = None
try:
llm = ChatOpenAI(
model_name=QWEN_MODEL_NAME,
temperature=0.1,
openai_api_key=openrouter_api_key,
base_url="https://openrouter.ai/api/v1"
)
st.success(f"Successfully initialized Qwen model: {QWEN_MODEL_NAME}")
except Exception as e:
st.error(f"Error initializing Qwen LLM: {e}")
st.stop()
# Initialize agent here!
agent = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True,
max_iterations=3
)
Hier ist, was wir aus dem obigen Code verstehen können:
QWEN_MODEL_NAME: Definiert das spezifische QWEN -Modell, das wir von OpenRouter verwenden.llm = ChatOpenAI(...): Initialisiert dieChatOpenAIObjekt.model_name=QWEN_MODEL_NAME: Gibt an, welche LLM zu verwenden ist.temperature=0.1: Kontrolliert die Kreativität der Antworten des LLM. Ein niedrigerer Wert (wie 0,1) macht den Ausgang deterministischer und fokussierter.openai_api_key=openrouter_api_key: Bietet den API -Schlüssel zur Authentifizierung mit OpenRouter.base_url="https://openrouter.ai/api/v1": Gibt den API-Endpunkt für OpenRouter an, da OpenRouter eine OpenAI-kompatible API bietet.- Der
try-exceptBlock fängt während der LLM -Initialisierung Fehler auf, zeigt sie in Strom und stoppt die Anwendung, wenn das LLM nicht eingerichtet werden kann. agent = initialize_agent(...): Ermöglicht Ihren Schaltflächen -Rückruf zur Verwendungagent.run(query)richtig.
Schritt 7: Initialisierung des Langchain -Agenten
Dieser entscheidende Schritt bringt die LLM und die Tools zusammen, um einen intelligenten Agenten zu erstellen, der in der Lage ist, auf der Grundlage von Benutzeranforderungen zu argumentieren und Maßnahmen zu ergreifen.
# Initializing Agent
agent = None
if llm is not None:
try:
agent = initialize_agent(
tools=tools,
llm=llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True,
handle_parsing_errors=True,
max_iterations=15
)
except Exception as e:
st.error(f"Error initializing LangChain agent: {e}")
st.stop()
else:
st.error("LLM not initialized. Agent setup failed.")
st.stop()
Der Code erreicht Folgendes:
ifllm is not None:: Stellt sicher, dass das LLM erfolgreich initialisiert, bevor versucht wird, den Agenten zu erstellen.agent = initialize_agent(...): Dies ist die Kernfunktion Langchain, um einen Agenten einzurichten.tools=tools: Bietet die Liste vonToolObjekte (Google Search und allgemeiner Webschaber), den der Agent verwenden kann.llm=llm: Verbindet das initialisierte LLM mit dem Agenten und gibt ihm seine Argumentationsfunktionen.agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION: Gibt die Art des Agenten an. Dieser Agententyp verwendet die LLM, um zu entscheiden, welches Tool verwendet werden soll und wie es in einem einzigen „Gedanken“ -Schschritt verwendet werden soll, basierend auf einer Beschreibung der Tools und der aktuellen Aufgabe.verbose=True: Wenn der interne Denkprozess und der Werkzeugverbrauch des Agenten in die Konsole gedruckt werden, ist dies sehr hilfreich beim Debuggen.handle_parsing_errors=True: Ermöglicht dem Agenten, zu versuchen, sich von Parsenfehlern in seinem internen Denken wiederherzustellen.max_iterations=15: Legt eine Grenze fest, wie viele Schritte (Tool verwendet, Gedanken), die der Agent vor dem Aufgeben ausführen kann, und verhindern unendliche Schleifen.- Der
try-exceptBlock behandelt Fehler während der Initialisierung von Agenten, wird angezeigt und die App gestoppt, wenn der Agent nicht eingerichtet werden kann.
Schritt 8: Erstellen Sie die Benutzereingabebereiche
Hier definieren wir die interaktiven Elemente in der Benutzeroberfläche der App, in der der Benutzer Details für die Suche angeben kann.
# Inputting UI elements
user_niche = st.text_input(
"Enter your brand's niche:",
key="brand_niche_input",
placeholder="Type niche here..."
)
# --- Additional Filters ---
st.subheader("Optional Filters")
country_filter = st.text_input(
"Filter by Country (optional):",
key="country_filter",
placeholder="e.g., United States, UK, China"
)
min_followers = st.number_input(
"Minimum Follower Count (e.g., 500000 for 500K)",
min_value=0,
value=0,
step=10000,
key="min_followers"
)
Unten finden Sie eine Zusammenfassung dessen, was der obige Code erreicht:
st.text_input(...): Erstellt ein Texteingangsfeld, damit der Benutzer die Nische ihrer Marke eingeben kann.st.subheader("Optional Filters"): Zeigt eine kleinere Überschrift für den optionalen Filterabschnitt an.country_filter = st.text_input(...): Erstellt eine weitere Texteingabe für einen optionalen Länderfilter.min_followers = st.number_input(...): Erstellt ein numerisches Eingangsfeld für die Mindestanzahl der Follower.
Schritt 9: Tokenschätzungsfunktion
Die folgende Funktion hilft bei der Verwaltung der Länge der an die LLM gesendeten Eingabeaufforderungen, die normalerweise zu Token -Grenzen verfügen.
# Token Estimation function
def estimate_tokens(text):
try:
encoding = tiktoken.encoding_for_model("gpt-4")
except:
encoding = tiktoken.get_encoding("cl100k_base")
return len(encoding.encode(text))
Hier ist, was der Code erreicht:
- Funktionsdefinition: Definiert
estimate_tokens(text)der einen String -Text als Eingabe nimmt. - Tokenisierung: Es wird versucht, den Token-Encoder für das „GPT-4“ -Modell zu erhalten. Wenn das fehlschlägt, fällt es auf eine gemeinsame Basiscodierung zurück (
cl100k_base).encoding.encode(text)Konvertiert den Eingabetxt in eine Liste von Token -Zahlen, währendlen(...)Gibt die Anzahl dieser Token zurück.
Schritt 10: Hauptsuchlogik (Finden von Influencern)
Dies ist der funktionale Kernbestandteil der Anwendung. Es löst aus, wenn der Benutzer die Schaltfläche „Tiktok Influencer finden“ klickt. Der Code wird verwendet, um die definierende Eingabeaufforderungsabfrage zu konstruieren, den Agenten auszuführen und die Ergebnisse anzuzeigen.
# Main Search Logic
if st.button("Find TikTok Influencers ✨"):
if not user_niche:
st.warning("Please enter your niche.")
elif agent is None:
st.error("Agent not initialized.")
else:
query = f"""
Find a list of at least 5 TikTok influencers highly relevant to the niche: '{user_niche}'.
Apply these filters:
- Country: {country_filter or 'Any'}
- Minimum Follower Count: {min_followers}
For each influencer, provide:
1. TikTok Username
2. Full Name (if known)
3. Approximate Follower Count
4. Niche
5. TikTok profile or verified link
Format as Markdown list.
"""
token_count = estimate_tokens(query)
if token_count > 20000:
st.error(f"Query too long ({token_count} tokens). Try reducing text.")
st.stop()
st.info("🚀 Searching influencers...")
with st.spinner("Running agent..."):
try:
response = agent.run(query)
st.session_state("last_influencer_data") = response
st.subheader("💡 Influencers Found:")
st.markdown(response)
except Exception as e:
st.error(f"Agent failed: {e}")
Hier finden Sie weitere Informationen darüber, wie der Code funktioniert:
if st.button("Find TikTok Influencers ✨"):: Dieser Block wird ausgeführt, wenn ein Benutzer auf die Schaltfläche klickt.
Eingabevalidierung:
if not user_niche:: Überprüft, ob die Nischeneingabe leer ist und eine Warnung anzeigt.elif agent is None:: Überprüft, ob der Langchain -Agent erfolgreich initialisiert wurde und einen Fehler angezeigt wird, wenn nicht.
Abfragekonstruktion:
- Um unsere Ergebnisse in einem ordentlichen und präsentierbaren Format zu erhalten, müssen wir die manuell eingeben
queryDas wird an den Langchain -Agenten gesendet. Diese Abfrage weist den Agenten an, was zu finden ist (Tiktok -Influencer), welche Kriterien verwendet werden sollen (Nische, Land, Mindestanhänger), welche Informationen für jeden zu extrahieren sind, und das gewünschte Ausgangsformat (Markdown -Liste). {country_filter or 'Any'}: Ist ein ordentlicher Python -Trick, der verwendetcountry_filterWenn es einen Wert hat, ist es ansonsten standardmäßig an der Zeichenfolge 'beliebt'.
Token Count Check:
token_count = estimate_tokens(query): Ruft die zuvor definierte Funktion auf, um eine Schätzung der Token -Länge der Abfrage zu erhalten.if token_count > 20000:: Verhindert, dass übermäßig lange Anfragen an die LLM gesendet werden, was die API -Grenzen überschreiten könnte.
Ausführen des Agenten:
st.info("🚀 Searching influencers..."): Zeigt eine Informationsnachricht an den Benutzer an.- mit
st.spinner("Running agent..."):: Zeigt eine sich drehende Animation in der Benutzeroberfläche an, die angibt, dass die Anwendung ausgeführt wird. response = agent.run(query): Hier passiert die Magie. Der Langchain -Agent nimmt die Abfrage, nutzt seine LLM, um die Aufgabe zu begründen, und entscheidet, welches seinertools(Google Search, Web Scraper), um möglicherweise in mehreren Schritten die Anforderung zu erfüllen. Die endgültige Antwort des Agenten wird in gespeichertresponse.st.session_state("last_influencer_data") = response: Speichert die Antwort des Agenten in Streamlits Sitzungszustand und so die Daten in derselben Benutzersitzung, was für die Folge- und Antworten von entscheidender Bedeutung ist.
Ergebnisse anzeigen:
st.subheader("💡 Influencers Found:"): Zeigt einen Subheader an.st.markdown(response): Rendert die Reaktion des Agenten (die als Markdown formatiert ist) direkt in die optimistische Benutzeroberfläche.
Fehlerbehandlung: Der try-except Block fängt alle Ausnahmen, die während der Ausführung des Agenten auftreten, und zeigt eine Fehlermeldung an.
Schritt 11: Follow-up-Q & A-Logik
Damit Benutzer weitere Fragen zu den von ihnen gefundenen Influencern stellen können, werden wir eine Follow-up-Logik hinzufügen, die das LLM direkt mit den zuvor erhaltenen Daten als Kontext verknüpft.
# Follow-up Q&A code
st.markdown("---")
st.subheader("Ask a follow-up question about the influencers ✍️")
follow_up_question = st.text_input("Your question:", key="followup_question")
if follow_up_question and "last_influencer_data" in st.session_state:
context = st.session_state("last_influencer_data")
qna_prompt = f"""
Based on the following influencer data:
{context}
Answer the following question:
{follow_up_question}
"""
token_count = estimate_tokens(qna_prompt)
if token_count > 20000:
st.error(f"Follow-up too long ({token_count} tokens). Try shortening your question or data.")
else:
try:
st.info("🧠 Thinking...")
follow_up_response = llm.invoke(qna_prompt)
st.markdown(follow_up_response)
except Exception as e:
st.error(f"LLM follow-up failed: {e}")
Der Code erreicht Folgendes:
st.markdown("---"): Fügt eine horizontale Regel für die visuelle Trennung hinzu.st.subheader(...)Undst.text_input(...): Erstellen Sie einen Abschnitt, damit der Benutzer eine Folgefrage eingibt.context = st.session_state("last_influencer_data"): Ruft die zuvor gefundenen Influencer -Daten ab, um einen Kontext für die LLM bereitzustellen.qna_prompt = f"""...""": Erstellt eine neue Eingabeaufforderung für die LLM. Diese Eingabeaufforderung enthält den Kontext (die Influencer -Daten) und diefollow_up_questionAnweisungen der LLM, basierend auf diesen Informationen zu antworten.- Token Count Check: Ähnlich wie bei der Hauptsuche überprüft es die Tokenlänge der Follow-up-Eingabeaufforderung, um Fehler zu verhindern.
- Direkt auf den LLM aufrufen:
follow_up_response = llm.invoke(qna_prompt)im Gegensatz zuagent.run()Anwesendllm.invoke()sendet die Eingabeaufforderung direkt an die LLM, ohne die Argumentation des Werkzeugs zu verwendern. Das LLM verarbeitet dann die Eingabeaufforderung (Kontext + Frage) und generiert eine Antwort.follow_up_response.contentextrahiert den tatsächlichen Text der Antwort, währendst.markdown(follow_up_response.content)Zeigt die Antwort des LLM im Markdown -Format an.
Schritt 12: Fußzeile
Warum nicht eine einfache Fußzeile hinzufügen, um den von uns verwendeten Technologien zu Krediten zu schenken? Dies ist eine gute Praxis, insbesondere wenn Sie dieses Projekt aufbauen, das in Ihr persönliches Portfolio aufgenommen wird. Auf diese Weise können Personalvermittler auf einen Blick, die Tools, die Sie zur Entwicklung Ihrer App verwendet haben, leicht entdecken.
# --- Footer ---
st.markdown("---")
st.markdown("Powered by ScraperAPI, Langchain and OpenRouter (Qwen)
", unsafe_allow_html=True)
Hier ist die Erklärung für den obigen Code:
st.markdown("---"): Fügt eine weitere horizontale Regel hinzu.st.markdown(": Zeigt am Ende der Seite einen kleinen, zentrierten, grau gefärbten Text an, der die verwendeten Technologien gutgeschrieben hat....
", unsafe_allow_html=True)
unsafe_allow_html=Trueist notwendig, weil Sie rohe HTML einbetten () innerhalb des Markdowns.
Hier ist ein Ausschnitt davon, wie die Benutzeroberfläche des Werkzeugs aussieht:

Schritt 13: Führen Sie Ihr Skript aus
Jetzt, da alle Schritte vorhanden sind, können Sie Ihren Code mit Stream beleuchtet ausführen, indem Sie:
streamlit run your_script_name.py
Bereitstellung des Scouting-Tools von Tiktok Brand-Influencer mit Streamlit
Hier erfahren Sie in nur wenigen Schritten kostenlos auf Stromversuche:
Schritt 1: Richten Sie ein Github -Repository ein
Nach Strom müssen Ihr Projekt veranstaltet werden Github.
1. Erstellen Sie ein neues Repository auf GitHub
Erstellen Sie ein neues Repository auf GitHub und setzen Sie es als öffentlich.
2. Drücken Sie Ihren Code zu GitHub
Bevor Sie etwas anderes tun, erstellen Sie eine .gitignore Datei, um vermeiden, versehentlich sensible Dateien wie zu laden. Fügen Sie das Folgendes hinzu:
.env
__pycache__/
*.pyc
*.pyo
*.pyd
.env.*
.secrets.toml
Wenn Sie Git noch nicht eingerichtet und Ihr Repository verknüpft haben, verwenden Sie die folgenden Befehle in Ihrem Terminal in Ihrem Projektordner:
git init
git add .
git commit -m "Initial commit"
git branch -M main
# With HTTPS
git remote add origin https://github.com/YOUR_USERNAME/your_repo.git
# With SSH
git remote add origin [email protected]:YOUR_USERNAME/your-repo.git
git push -u origin main
Wenn Sie zum ersten Mal GitHub von dieser Maschine verwenden, müssen Sie möglicherweise eine SSH -Verbindung einrichten. So ist wie.
Schritt 2: Definieren Sie Abhängigkeiten und schützen Sie Ihre Geheimnisse!
Streamlit muss wissen, welche Abhängigkeiten Ihre App benötigt.
1. Erstellen Sie in Ihrem Projektordner automatisch eine Anforderungsdatei, indem Sie ausführen:
pip freeze > requirements.txt
2. Verlassen Sie es zu GitHub:
git add requirements.txt
git commit -m "Added dependencies”
git push origin main
3. Tun Sie dasselbe für Ihre App -Datei, die Ihren gesamten Code enthält:
git add your-script.py
git commit -m "Added app script"
git push origin main
Schritt 3: Bereitstellen in der streamlitischen Cloud
1.. Gehen Sie zu Stromlit Community Cloud.
2. Klicken Sie auf „Anmelden mit Github“ und die Stromversorgung autorisieren.
3. Klicken Sie „App erstellen.“
4.. Wählen Sie “Stellen Sie eine öffentliche App von Github Repo bereit. “
5. in der Repository -Einstellungeneingeben:
- Repository:
YOUR_USERNAME/TikTok-Influencer-Finder - Zweig:
main - Hauptdateipfad:
app.py(oder was auch immer Ihr streamlites Skript benannt ist)
6. Klicken Sie klicken „Einsetzen“ und warten Sie, bis die App die App erstellt.
7. Gehen Sie zu Ihrem bereitgestellten App -Dashboard, suchen Sie Ihre App und suchen Sie in „Einstellungen“ „Geheimnisse“. Fügen Sie Ihre Umgebungsvariablen (Ihre API -Schlüssel) hinzu, so wie Sie sie lokal in Ihrer .Env -Datei haben.
Schritt 4: Holen Sie sich Ihre Stromlit -App -URL
Nach dem Einsatz wird Streamlit a generieren öffentliche URL (z.B, https://your-app-name.streamlit.app). Sie können diesen Link jetzt freigeben, damit andere auf Ihr Tool zugreifen können!
Abschluss
In diesem Tutorial haben Sie gelernt, wie man ein Tiktok-Brand-Influencer-Scouting-Tool erstellt, mit dem der Scraperapi-Langchain-Agent für intelligente, autonome Datenextraktion, QWEN3 für kontextbezogene Einblicke und Follow-up-Abfragen verwendet wird, und nach dem Erstellen einer benutzerfreundlichen Schnittstelle, um die App zu erstellen, in der Cloud in der Cloud, in der Cloud, für die freie Ausrichtung zu haben.
Dieses Tool unterstützt das Influencer -Marketing und ermöglicht es Marken, Schöpfer zu identifizieren, deren Nische, Stimme und Vision perfekt mit ihren eigenen übereinstimmen. Durch die Einbeziehung von Filteroptionen und Follow-up-Fragen bewegt sich die nur grundlegenden Metriken, um Influencer zu finden, die wirklich authentisches Engagement auslösen und gezielte Marketingbemühungen vorantreiben können.
Bereit, Ihre eigenen zu bauen?
Verwenden Sie noch heute den Scraperapi und verwandeln Sie Ihren Influencer -Scouting -Prozess in eine optimierte, hochwirksame Strategie!
