
Amazon, einer der größten Online-Marktplätze für den Kauf und Verkauf von Dingen, verfügt über einen Schatz an Informationen, die für Forscher, Wirtschaftsanalysten und Unternehmer wertvoll sind. Aber der Zugriff auf Daten kann bei Amazon, wie bei vielen anderen Websites auch, eine Herausforderung sein. Dabei geht es darum, die Daten zu analysieren und den besten Weg zu finden, sie zu extrahieren.
In diesem Artikel werden wir verschiedene Methoden zum Sammeln von Daten von Amazon-Websites mithilfe von Python untersuchen. Wir beginnen mit der Untersuchung der Struktur der Produktseiten von Amazon und schließen mit der Erstellung automatisierter Tools für die Webdatenextraktion ab.
Außerdem besprechen wir die Herausforderungen, denen Sie beim Sammeln von Daten bei Amazon gegenüberstehen könnten, und geben praktische Tipps zu deren Bewältigung. Wir untersuchen Techniken zur Vermeidung von IP-Adressblöcken, verwenden APIs zum Sammeln von Daten und bieten Beispiele für Code und Tools, die Ihnen dabei helfen, die benötigten Daten effizient zu sammeln.
Analyse der Amazon-Produktseite
Amazon ist ein riesiger und bekannter Marktplatz. Die daraus resultierende Datenverarbeitung kann zeitaufwändig sein, kann aber automatisiert werden. Bevor wir mit der Entwicklung unseres Amazon-Scrapers in Python beginnen, untersuchen wir die Struktur von Produktseiten.
Seitenelemente
Jede Amazon-Produktseite enthält viele Informationen, von denen einige spezifisch für eine bestimmte Kategorie sind. Wir extrahieren jedoch nur Informationen aus den Elementen, die allen Produktseiten gemeinsam sind.
Schauen wir uns eine Produktseite an und identifizieren wir die Elemente, die wir entfernen möchten:
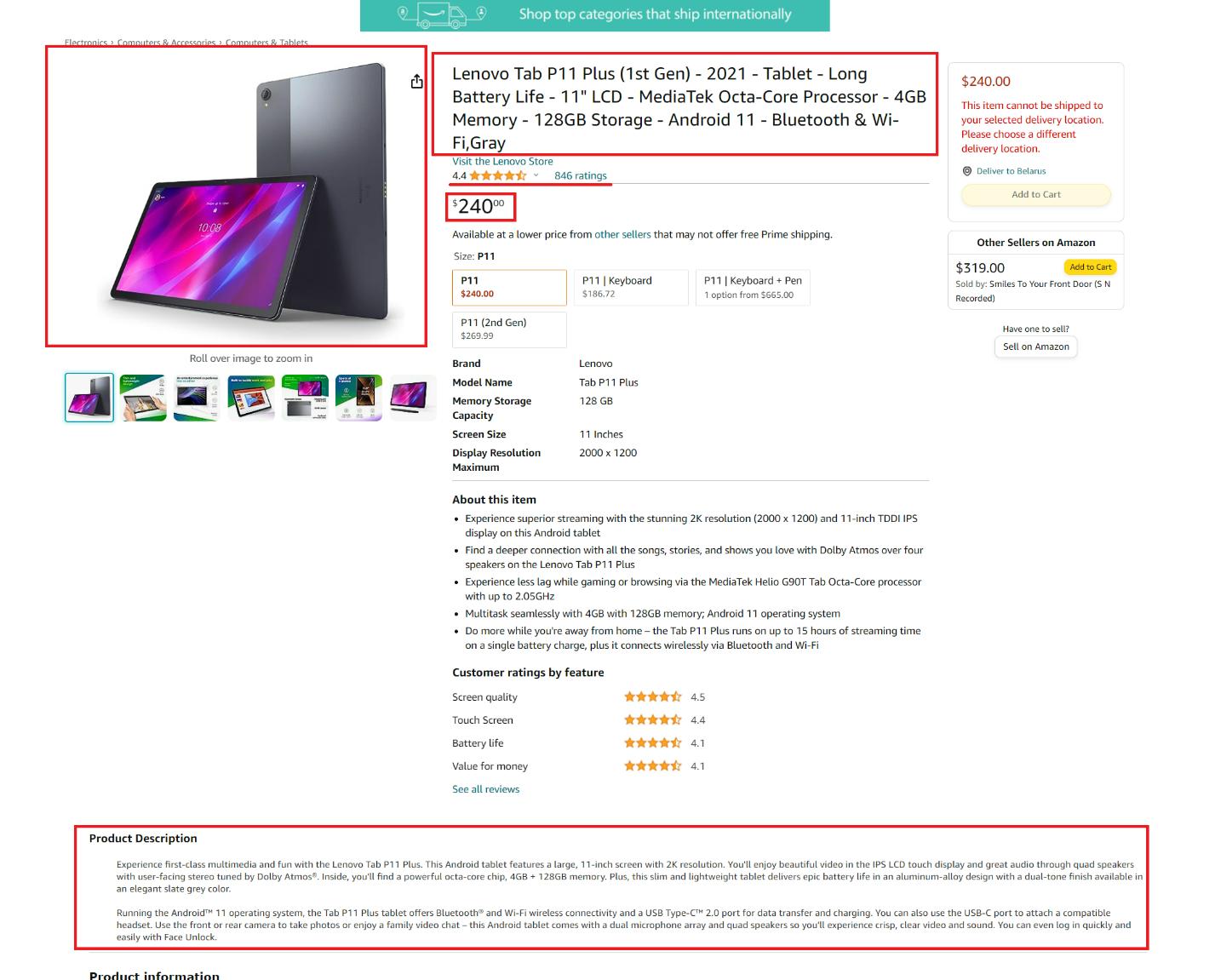
Hier können wir folgende Elemente hervorheben:
- Der Titel oder Produktname.
- Der Preis des Produkts.
- Die allgemeine Beschreibung des Produkts.
- Ein Link zum Produktbild.
- Produktbewertung.
- Die Anzahl der Bewertungen für das Produkt.
Diese Elemente sind allen Produktkategorien gemeinsam und können mit dem Schaber extrahiert werden. Wenn die Seite zusätzliche kategoriespezifische Elemente enthält, können Sie später Code hinzufügen, um diese selbst zu extrahieren.
Seiten-HTML abrufen
Bevor wir mit der Verarbeitung der Seite und dem Abrufen bestimmter Daten fortfahren, schreiben wir eine einfache Abfrage, um die gesamte Seite abzurufen und diese Daten anzuzeigen. Erstellen Sie dazu eine neue Datei mit dem *.py Erweiterung und importieren Sie die Requests-Bibliothek:
import requestsUm es uns später einfacher zu machen, fügen wir den Link zur Seite in eine Variable ein:
url="https://www.amazon.com/Lenovo-Tab-P11-Plus-1st/dp/B09B17DVYR/ref=sr_1_2?qid=1695021332&rnid=16225007011&s=computers-intl-ship&sr=1-2&th=1"Jetzt müssen wir Header für unsere Anfrage festlegen. Dies ist nicht erforderlich, um die Anfrage selbst zu senden, Amazon stellt Ihnen jedoch die Seiteninhalte nicht zur Verfügung, wenn Sie diese nicht angeben. Da Amazon nicht bereit ist, Daten an Bots und Programme weiterzugeben, müssen Sie Ihr Skript menschlicher gestalten, um die Daten zu erhalten. Eine Möglichkeit hierfür ist die Verwendung von Headern:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36'
}Jetzt können wir die Abfrage ausführen und die Daten ausgeben, wenn sie erfolgreich ist, oder einen Fehler ausgeben, wenn sie fehlschlägt:
response = requests.get(url, headers=headers)
if response.status_code == 200:
print (response.text)
else:
print(str(response.status_code)+' - Error loading the page')Mit dieser unkomplizierten Methode können Sie Daten von fast jeder Website sammeln. Diese Methode macht das Skript zwar menschlicher, ist aber möglicherweise nicht so zuverlässig. Um menschliche Handlungen wirklich nachzuahmen, benötigen Sie einen Headless-Browser und Bibliotheken wie Pyppeteer oder Selenium.
Da diese für Anfänger jedoch schwierig sein können, werden wir sie hier nicht behandeln. Stattdessen werden wir später in diesem Artikel besprechen, wie Sie den ganzen Ärger vermeiden können, indem Sie eine Web-Scraping-API verwenden.
Scraping von Amazon-Produktdetails mithilfe von Python-Bibliotheken
Da wir nun den Inhalt der Seite haben, können wir ihn analysieren und die spezifischen Elemente abrufen, die wir zuvor besprochen haben. Dafür benötigen wir die BeautifulSoup-Bibliothek, also importieren wir sie und analysieren dann die gesamte Seite, um bestimmte Seitenelemente mithilfe ihrer CSS-Selektoren zu extrahieren.
import requests
from bs4 import BeautifulSoup
url="https://www.amazon.com/Lenovo-Tab-P11-Plus-1st/dp/B09B17DVYR/ref=sr_1_2?qid=1695021332&rnid=16225007011&s=computers-intl-ship&sr=1-2&th=1"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# Extract data here
else:
print(str(response.status_code)+' - Error loading the page')Betrachten wir nun jedes Element, das wir benötigen, und fügen wir seine Extraktion zu unserem Code hinzu.
Produktname
Besorgen Sie sich zunächst den Produkttitel. Gehen Sie dazu zur Produktseite und öffnen Sie DevTools (F12 oder klicken Sie mit der rechten Maustaste auf den Bildschirm und wählen Sie „Inspizieren“). Wählen Sie dann den Produktnamen auf der Seite aus und sehen Sie, welcher Teil des Codes ihn beschreibt.
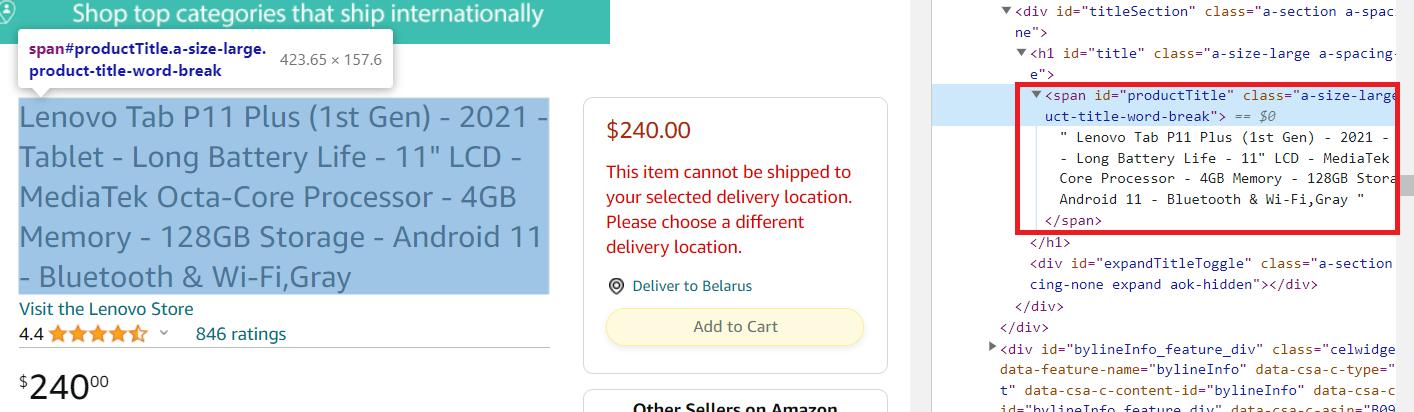
Wie wir sehen können, befindet sich dieses Element innerhalb des span Tag mit der eindeutigen Kennung productTitle. Wir können es also mit dem folgenden Code extrahieren:
title_element = soup.find('span', id='productTitle')
title = title_element.get_text()Es kann jedoch sein, dass die Seite mit einem Fehler zurückkehrt. Wenn das Element in diesem Fall nicht gefunden wird, erhalten wir eine Fehlermeldung und unser Skript funktioniert nicht mehr. Lassen Sie uns die zweite Zeile ein wenig ändern, um je nach Vorhandensein einen Wert zuzuweisen:
title = title_element.get_text(strip=True) if title_element else 'Title not found'Jetzt können Sie die extrahierten Daten auf dem Bildschirm anzeigen:
print(f'Title: {title}')Kommen wir nun zum nächsten Element.
Produktbild
Wir werden den Bildlink aus der Vorschau entfernen. Es wird keine hochauflösenden Bilder geben, aber unsere Bibliotheken eignen sich hervorragend für Anfänger und sind zum Extrahieren von Informationen aus Meta-Tags ungeeignet.
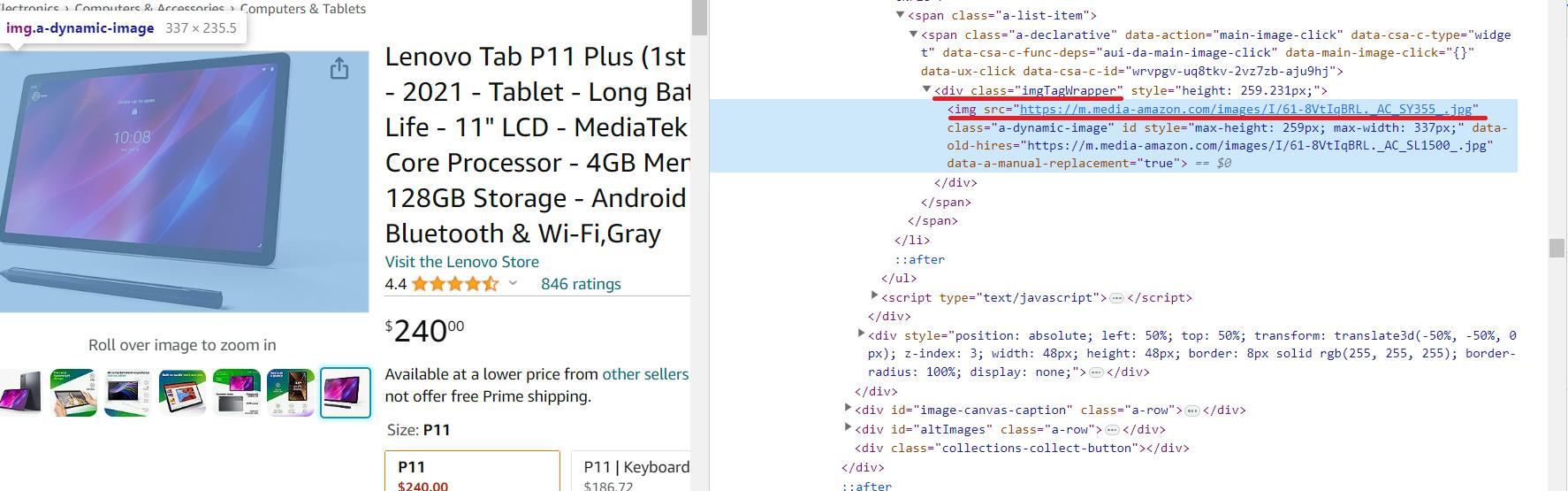
Der Link zum hochauflösenden Produktbild befindet sich im verschachtelten img Tag des div Element mit dem id=imgTagWrapperId. Im Gegensatz zu anderen Elementen wird der Link zum Produktbild nicht als Text in einem Tag, sondern als Attribut des Tags gespeichert. Daher wird der Code zum Scrapen etwas anders sein.
image_element = soup.find('div', id='imgTagWrapperId')
if image_element:
image_url = image_element.find('img')('src')
else:
image_url="Image link not found"Und dann die Daten auf dem Bildschirm anzeigen:
print(f'Image link: {image_url}')Obwohl es etwas anders ist, das Bild zu bekommen, ist es auch recht einfach.
Produktbeschreibung
Die Produktbeschreibung ist eine wichtige und nützliche Information. Verschiedene Produktkategorien verfügen möglicherweise über zusätzliche Beschreibungen und Funktionen, diese sind jedoch vorübergehend, dynamisch und von Kategorie zu Kategorie unterschiedlich. Daher erhalten wir nur eine allgemeine Produktbeschreibung, die auf allen Produktseiten vorhanden ist.
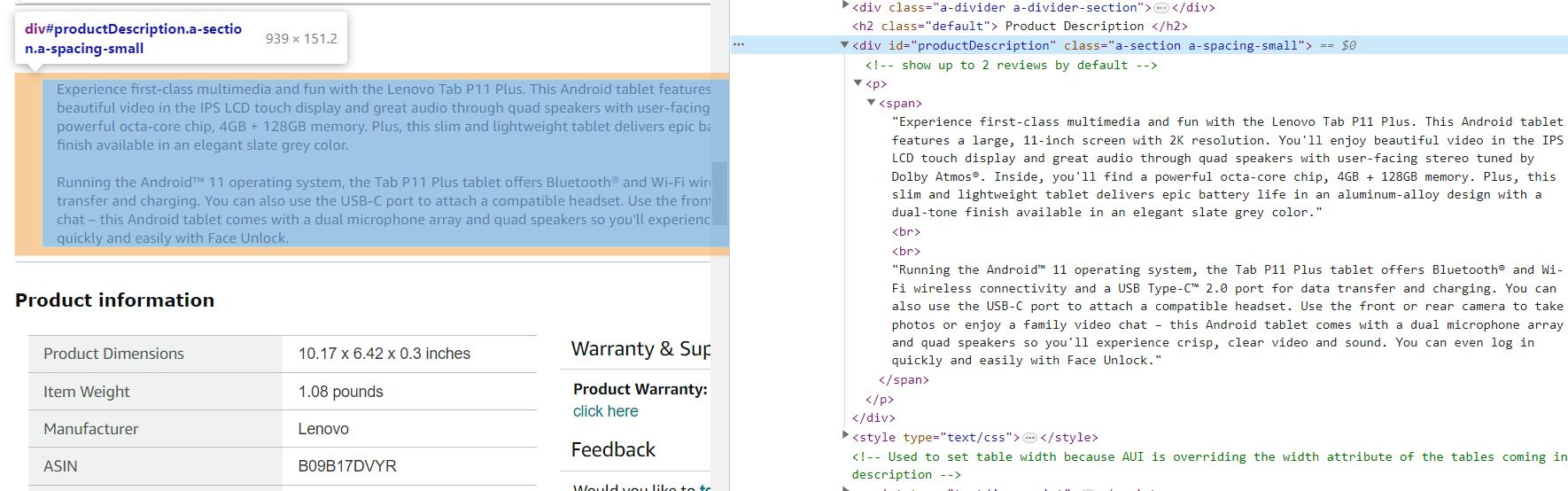
Wie wir sehen können, befindet sich die Produktbeschreibung in der div Element mit der eindeutigen Kennung productDescription:
description_element = soup.find('div', id='productDescription')
description = description_element.get_text() if description_element else 'Description not found'Die Anzeige von Informationen auf dem Bildschirm ist dasselbe:
print(f'Description: {description}')Auf einigen Seiten kann die Beschreibung unterschiedliche Tags haben oder gar nicht übertragen werden, da sie dynamisch angezeigt wird, nachdem die gesamte Seite geladen wurde. Dies sollte auch beim Schaben berücksichtigt werden.
Produktpreis
Für einige Artikel auf Amazon gibt es möglicherweise mehrere Preise und ihre Tags und Klassen können je nach Kategorie variieren. Der allgemeine Preis des Produkts wird jedoch standardmäßig auf allen Seiten angezeigt. Deshalb werden wir genau das abkratzen.
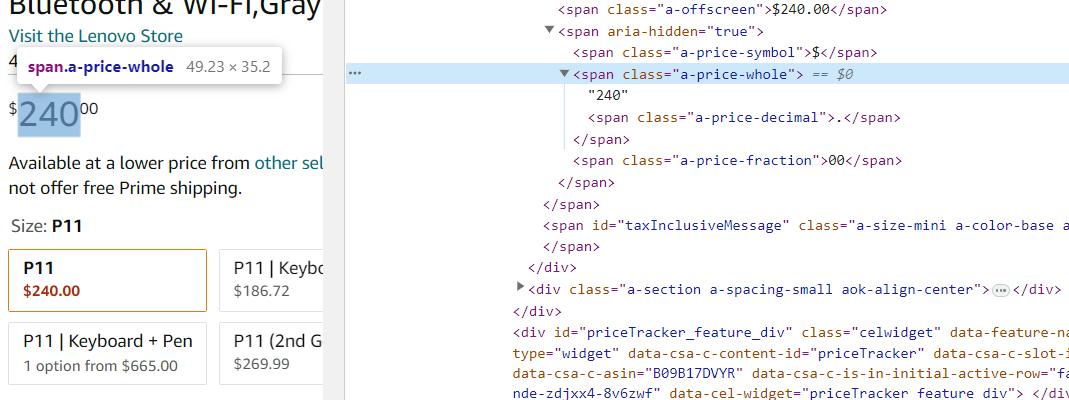
Der Preis des Produkts ist in der span Element mit Klasse a-price-whole. Lassen Sie uns diese Daten mit BeautifulSoup abrufen:
price_element = soup.find('span', class_='a-price-whole')
price = price_element.get_text(strip=True) if price_element else 'Price not found'Für die Ausgabe verwenden Sie print:
print(f'Price: {price}')Bei diesem Ansatz erfassen Sie die tatsächlichen Preise von Produktseiten und erhalten die Daten in Form einer Zahl ohne Angabe der Währung. Wenn Sie Preise zusammen mit der Angabe der Währung extrahieren müssen, verwenden Sie einen anderen, allgemeineren Selektor.
Rezensionen und Bewertung
Wir werden Bewertungen und Rezensionen zusammen betrachten, da sie miteinander in Zusammenhang stehen. Da es sich jedoch um zwei unterschiedliche Elemente handelt, werden wir sie mit unterschiedlichen Selektoren extrahieren.
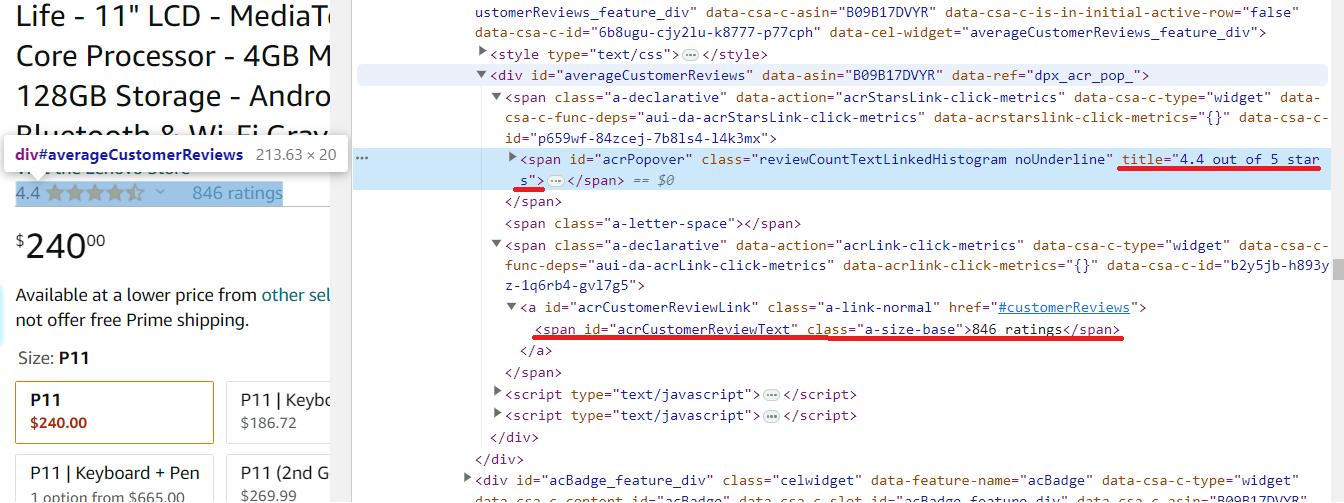
Die Produktbewertung befindet sich im span Element mit der Klasse reviewCountTextLinkedHistogramund sein Wert ist über verfügbar title Attribut. Die Anzahl der Bewertungen zum Produkt finden Sie im span Element mit der eindeutigen Kennung acrCustomerReviewText.
# Extract the product rating
rating_element = soup.find('span', class_='reviewCountTextLinkedHistogram')
rating = rating_element('title') if rating_element else 'Rating not found'
# Extract the number of reviews
reviews_element = soup.find('span', id='acrCustomerReviewText')
reviews = reviews_element.get_text(strip=True) if reviews_element else 'Number of reviews not found'Und dann diese Daten auf dem Bildschirm anzeigen:
print(f'Rating: {rating}')
print(f'Number of reviews: {reviews}')Nachdem wir nun alle erforderlichen Daten gesammelt haben, fügen wir der CSV-Datei eine Speicherung hinzu und sehen uns das resultierende Skript an.
Vollständiger Code mit Datenspeicherung
Um frei mit CSV-Dateien arbeiten zu können, benötigen wir die csv Bibliothek. Importieren Sie es in das Skript::
import csvVerwenden Sie es nun, um nach der Ausführung alle gesammelten Daten zu speichern:
with open('product_data.csv', mode="w", newline="") as csv_file:
writer = csv.writer(csv_file)
writer.writerow(('Title', 'Price', 'Description', 'Image Link', 'Rating', 'Number of Reviews'))
writer.writerow((title, price, description, image_url, rating, reviews))
print('Data has been saved to product_data.csv')Nach der Ausführung des Skripts erhalten wir die Informationen nicht in der Befehlszeile, sondern in der Datei product_data.csv. Diese Methode ist beispielsweise praktischer, wenn Sie viele Produktseiten haben und alle zusammenfassenden Daten in einer Datei erhalten möchten.

Vollständiger Code:
import requests
from bs4 import BeautifulSoup
import csv
url="https://www.amazon.com/Lenovo-Tab-P11-Plus-1st/dp/B09B17DVYR/ref=sr_1_2?qid=1695021332&rnid=16225007011&s=computers-intl-ship&sr=1-2&th=1"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
title_element = soup.find('span', id='productTitle')
title = title_element.get_text(strip=True) if title_element else 'Title not found'
price_element = soup.find('span', class_='a-price-whole')
price = price_element.get_text(strip=True) if price_element else 'Price not found'
description_element = soup.find('div', id='productDescription')
description = description_element.get_text() if description_element else 'Description not found'
image_element = soup.find('div', id='imgTagWrapperId')
if image_element:
image_url = image_element.find('img')('src')
else:
image_url="Image link not found"
rating_element = soup.find('span', class_='reviewCountTextLinkedHistogram')
rating = rating_element('title') if rating_element else 'Rating not found'
reviews_element = soup.find('span', id='acrCustomerReviewText')
reviews = reviews_element.get_text(strip=True) if reviews_element else 'Number of reviews not found'
with open('product_data.csv', mode="w", newline="") as csv_file:
writer = csv.writer(csv_file)
writer.writerow(('Title', 'Price', 'Description', 'Image Link', 'Rating', 'Number of Reviews'))
writer.writerow((title, price, description, image_url, rating, reviews))
print('Data has been saved to product_data.csv')
else:
print(str(response.status_code)+' - Error loading the page')Sie können es für weitere Daten verfeinern oder es unverändert verwenden.
Erstellen eines Crawlers für Produktlinks
Im vorherigen Beispiel haben wir eine Skriptoption zum Extrahieren von Informationen aus einer Produktseite betrachtet. Wir haben den Link zur Produktseite manuell angegeben, konnten ihn jedoch automatisch erfassen. Dazu gehen wir auf die Kategorieseite und sehen, wo die Links zu den Produkten gespeichert sind, um einen kleinen Crawler zum Sammeln dieser Links zu erstellen.
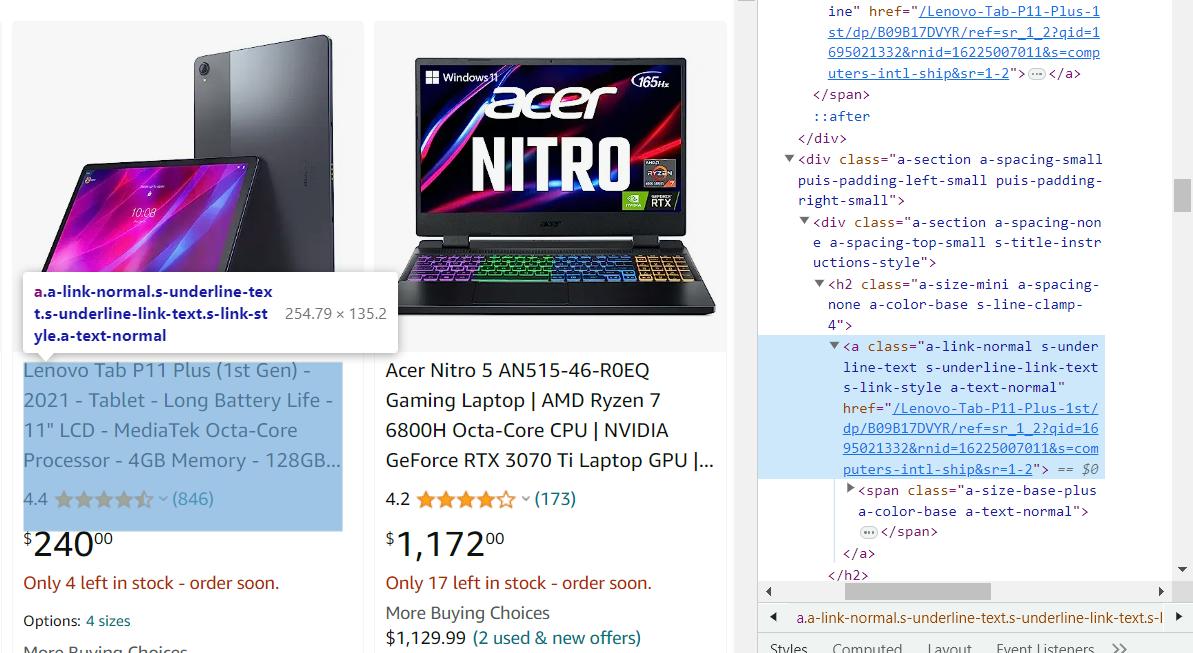
Das Scraping von Links unterscheidet sich nicht vom Ausführen von Daten von der Produktseite, daher stellen wir Ihnen den resultierenden Code gleich zur Verfügung:
import requests
from bs4 import BeautifulSoup
url="https://www.amazon.com/s?bbn=16225007011&rh=n%3A16225007011%2Cn%3A13896617011&dc&qid=1695021317&rnid=16225007011&ref=lp_16225007011_nr_n_2"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
product_links = soup.find_all('a', class_='a-link-normal s-underline-text s-underline-link-text s-link-style a-text-normal')
for link in product_links:
product_url="https://www.amazon.com" + link('href')
print(product_url)
else:
print(response.status_code)Wenn Sie möchten, dass Ihr Webspider automatisch Links und Produktinformationen sammelt, anstatt Links nur auf dem Bildschirm anzuzeigen, können Sie das Skript verwenden, das wir uns zuvor angesehen haben.
Herausforderungen beim Amazon Scraping: Probleme und Lösungen
Web Scraping kann aus mehreren Gründen eine herausfordernde Aufgabe sein. Das Erstellen des Scrapers selbst kann eine herausfordernde Aufgabe sein, aber es ist noch schwieriger, eine Blockierung während des Scrapings zu vermeiden und mit den Änderungen Schritt zu halten, die die Entwickler an der gescrapten Site vorgenommen haben. Wenn Sie Ihren Amazon-Schaber nicht ständig unterstützen und verbessern, verliert er schnell an Wirksamkeit. Schauen wir uns also an, wie Sie die häufigsten Probleme beim Scraping von Daten vermeiden können.
Erstens verbieten die Nutzungsbedingungen von Amazon ausdrücklich Web Scraping, also das Extrahieren von Daten von der Amazon-Website mithilfe automatisierter Tools oder Roboter. Dies bedeutet, dass jeglicher automatisierte Zugriff auf die Website von Amazon verboten ist, einschließlich des Auslesens von Produktinformationen, Preisen, Rezensionen, Bewertungen und anderen relevanten Daten aus den Produktlisten von Amazon.
Technische Maßnahmen
Amazon verfügt über eine Reihe von Maßnahmen, um Scraping zu erkennen und zu verhindern, z. B. die Begrenzung der Anfragen, das Verbot von IP-Adressen und die Verwendung von Browser-Fingerprinting zur Identifizierung von Bots. Verdächtige Online-Aktivitäten können zu einer potenziellen Blockierung führen. Allerdings überprüft Amazon in der Regel die Identität des Benutzers, indem es eine CAPTCHA-Abfrage darstellt, bevor Einschränkungen umgesetzt werden, um die Unterscheidung zwischen Menschen und Bots sicherzustellen.
Wir haben bereits darüber gesprochen und darüber, wie man Blockaden vermeidet. Wenn Sie jedoch das Lesen eines weiteren Artikels vermeiden möchten, finden Sie hier eine schnelle Lösung: Verwenden Sie eine Web-Scraping-API, um Produktdetails zu sammeln. Dies ist die beste Möglichkeit, CAPTCHAs zu umgehen und eine Blockierung zu verhindern.
Häufige Änderungen der Website-Struktur
Amazon verändert seine Website ständig, fügt neue Dinge hinzu und verändert ihr Erscheinungsbild. Dies kann dazu führen, dass Scraper, die zum Sammeln von Daten von diesen Websites erstellt wurden, nicht mehr funktionieren. Um dieses Problem zu vermeiden, ist es notwendig, Änderungen auf der Site zu überwachen. Dies kann manuell, durch Durchsuchen der Website oder mithilfe von Änderungsüberwachungstools erfolgen.
Wenn Sie außerdem davon ausgehen, dass ein Teil möglicherweise anders aussieht oder sich wahrscheinlich bald ändern wird, können Sie try..exclusive verwenden, um zu verhindern, dass der gesamte Code beschädigt wird. Selbst wenn sich die Struktur ändert, erhalten Sie auf diese Weise immer noch die erforderlichen Daten, wenn auch in etwas geringerem Umfang.
Eine weitere Möglichkeit besteht darin, vorhandene Tools zum Scrapen von Amazon-Produktdaten zu verwenden. Sie können zum Beispiel unseren No-Code-Scraper verwenden. In diesem Fall müssen Sie sich keine Gedanken über die Seitenstruktur oder sonstiges machen – Sie erhalten lediglich die Daten, die Sie benötigen.
Amazon-Datenerfassung mithilfe der Web Scraping API
Wie bereits erwähnt, können wir zur Lösung der anstehenden Aufgaben eine Web-Scraping-API nutzen. Es kümmert sich für Sie um die Bearbeitung der Anfragen. Das bedeutet, dass Sie sich keine Sorgen machen müssen, dass Ihre IP-Adresse blockiert wird, und dass Sie keine Proxyserver verwenden müssen, um CAPTCHA zu umgehen. Darüber hinaus können Sie mit unserer Web-Scraping-API mithilfe von CSS-Selektoren und Extraktionsregeln schnell Daten sammeln.
API-Schlüssel abrufen
Um zu beginnen, benötigen Sie einen API-Schlüssel. Sie finden es in Ihrem Konto, nachdem Sie sich bei Scrape-It.Cloud registriert haben. Darüber hinaus erhalten Sie 1.000 Gratis-Credits, wenn Sie sich zum Testen unserer Funktionen registrieren.
Sie benötigen diesen API-Schlüssel in zukünftigem Code.
Jetzt erhalten wir die gleichen Daten wie in den vorherigen Beispielen, verwenden jedoch die Web-Scraping-API. Außerdem speichern wir alle Daten, die wir erhalten, in einer Excel-Datei. Importieren Sie alle Bibliotheken, die wir verwenden werden:
import requests
import json
import pandas as pdWir benötigen die Requests-Bibliothek, um Anfragen an die API zu stellen. Dann verwenden wir das JSON Bibliothek zur Verarbeitung der Antwort von der API, die im JSON-Format vorliegt. Und am Ende verwenden wir die Pandas-Bibliothek, um einen Datenrahmen zu erstellen und die Daten in einer Excel-Datei zu speichern.
Nun legen wir die Variablen und Parameter fest, die wir im gesamten Skript verwenden werden:
url="https://www.amazon.com/s?bbn=16225007011&rh=n%3A16225007011%2Cn%3A13896617011&dc&qid=1695021317&rnid=16225007011&ref=lp_16225007011_nr_n_2"
api_url="https://api.scrape-it.cloud/scrape"
api_key = 'PUT-YOUR-API-KEY'
headers = {
'x-api-key': api_key,
'Content-Type': 'application/json'
}Hier sollten Sie Ihren Link zur Produktseite und Ihren persönlichen API-Schlüssel angeben. Bilden Sie dann den Hauptteil der Abfrage, um alle Links auf der Seite abzurufen:
payload = json.dumps({
"url": url,
"js_rendering": True,
"block_ads": True,
"extract_rules": {
'links': 'a.a-link-normal.s-underline-text.s-underline-link-text.s-link-style.a-text-normal @href'
},
"proxy_type": "datacenter",
"proxy_country": "US"
})Hier haben wir in den Extraktionsregeln einen CSS-Selektor angegeben, um die benötigten Daten sofort zu erhalten. Jetzt führen wir die Anfrage aus und analysieren die Antwort im JSON-Format, um eine Liste mit Links zu erhalten:
response = requests.request("POST", api_url, headers=headers, data=payload)
if response.status_code == 200:
data = response.json()
product_links = data('scrapingResult')('extractedData')('links')Legen Sie Extraktionsregeln fest, die die von uns benötigten Daten erhalten:
extract_rules = {
"title": "span#productTitle",
"price": "span.a-price-whole",
"description": "div#productDescription",
"image": "div#imgTagWrapperId img",
"rating": "span.reviewCountTextLinkedHistogram",
"reviews": "span#acrCustomerReviewText"
}Füge hinzu ein for Schleife, um alle Links durchzugehen und Anfragen zu stellen, um Daten von jedem von ihnen zu erhalten:
for product_link in product_links:
url = str("https://www.amazon.com/")+str(product_link)
print(url)
payload = json.dumps({
"extract_rules": extract_rules,
"wait": 0,
"block_resources": False,
"url": url
})
response = requests.post(api_url, headers=headers, data=payload)Jetzt müssen Sie nur noch die Daten in einer Datei speichern. Hierzu verwenden wir die Pandas-Bibliothek, die die Header selbst erstellt und es uns ermöglicht, die notwendigen Daten bequem zu speichern:
if response.status_code == 200:
data = response.json()
data = data('scrapingResult')('extractedData')
df = pd.DataFrame(data)
df.to_excel("scraped_data.xlsx", index=False)
else:
print(f'Error: {response.status_code} - Error loading the page for {product_link}')Obwohl wir jetzt über eine Datendatei verfügen, die alle Produkte enthält, die wir durch die Kombination früherer Beispiele hätten erhalten können, müssen wir uns bei der Verwendung einer API keine Gedanken über Probleme wie Blockierung oder den Erhalt dynamischer Inhalte machen.
Abschluss
In diesem Artikel haben wir verschiedene Möglichkeiten zur Datenerfassung von Amazon-Seiten besprochen. Wir haben auch die Probleme besprochen, mit denen Sie konfrontiert werden, wenn Sie Ihren Schaber verwenden, und Methoden zur Überwindung dieser Probleme.
Sie können die Web-Scraping-API verwenden, um Probleme wie IP-Blockierung und den Umgang mit dynamischen Inhalten zu vermeiden. Wenn Sie keine Schwierigkeiten haben möchten, können Sie unseren vorgefertigten No-Code-Amazon-Scraper verwenden, der Ihnen Amazon-Produktdetails in einem praktischen Format liefert.
