
Wozu dient ein Proxyserver?
Ein Proxyserver fungiert als Standortanzeiger und Gateway zwischen Ihrem Gerät und dem Internet und sieht folgendermaßen aus: 161.77.55.119.
Wenn Sie einen Proxyserver verwenden, fließt der Internetverkehr über den Proxyserver an die von Ihnen angeforderte Adresse.
Proxyserver maskieren außerdem Ihre IP-Adresse, sodass Sie anonym im Internet surfen oder es so aussehen kann, als würden Sie von einem anderen Standort aus surfen. Dies kann sehr nützlich sein, wenn Sie auf aufgrund Ihres geografischen Standorts eingeschränkte Inhalte zugreifen.
Damit kommen wir zu der Frage, wie nützlich Proxy-Pools sein können. Da Ihr Proxy an Ihre IP-Adresse gebunden ist und Ihre IP-Adresse an Ihren Wohnort, helfen Ihnen Proxy-Pools dabei, Ihren Standort zwischen verschiedenen Proxys zu wechseln, sodass Ihr tatsächlicher Standort nicht erkannt wird.
Aber wie kann ein Proxy in einem anderen Land „geortet“ werden? Das hängt ganz vom physischen Standort und der IP-Adresse des Servers ab. Ein „US“-Proxyserver ist also einfach ein Server, der sich physisch in den Vereinigten Staaten befindet und dem eine US-basierte IP-Adresse zugewiesen ist.
Notiz: Um mehr über Proxyserver und ihre Funktionsweise zu erfahren, lesen Sie unseren ausführlichen Leitfaden: Was ist ein Proxy?
Warum ist der Proxy-Standort wichtig?
Der Proxy-Standort bezieht sich auf den geografischen Standort des von Ihnen verwendeten Proxy-Servers. Dieser Aspekt ist aus mehreren Gründen für das Web Scraping von entscheidender Bedeutung:
- Umgehen Sie geografische Beschränkungen: Nur wer an bestimmten Orten lebt, kann auf bestimmte Websites zugreifen. Wer außerhalb lebt, bleibt also außen vor. Sobald Sie die Proxys dieser Länder haben, können Sie problemlos auf deren lokale Daten zugreifen.
- Sicherheit: Sie sollten Proxys verwenden, wenn Sie das Internet nutzen möchten, ohne Ihren tatsächlichen Standort preiszugeben. Dies trägt zur Wahrung der Anonymität bei und sorgt dafür, dass Ihre Standortdaten im Allgemeinen nicht erkennbar sind.
- Lokalisierte Daten abrufen: Einige Websites zeigen je nach IP-Standort unterschiedliche Informationen an. Durch rotierende Proxys können Sie Daten aus einem bestimmten Land abrufen, so wie es lokale Benutzer tun würden. Ein gutes Beispiel hierfür ist das Sammeln von Suchdaten aus Großbritannien im Vergleich zu den USA.
Ein praktisches Beispiel für die Bedeutung des Proxy-Standorts ist Home Depot. Wenn Sie versuchen, von einer IP-Adresse außerhalb der USA auf die US-Site von Home Depot zuzugreifen, werden Sie feststellen, dass der Inhalt blockiert ist. Dies kann für Geschäftsinhaber und Datenanalysten, die Preise auf dem US-Markt vergleichen möchten, frustrierend sein.
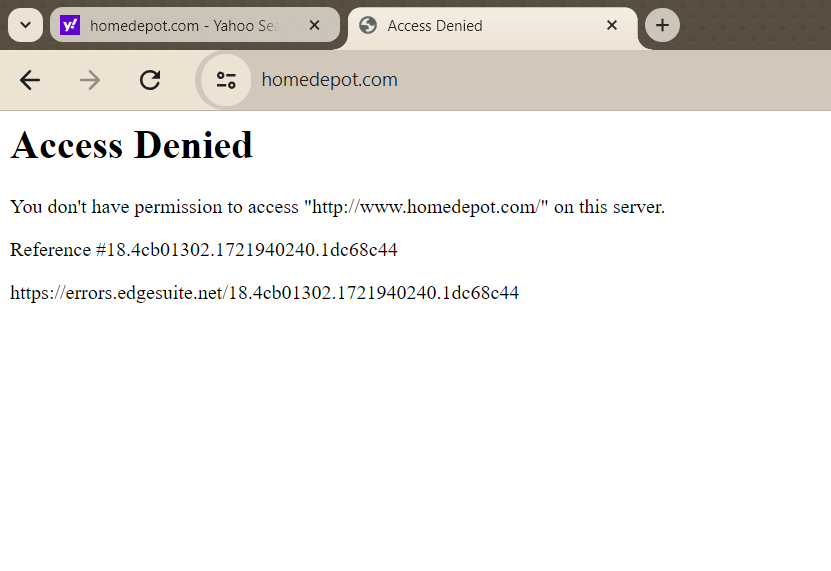
Durch die Verwendung eines Proxys mit Sitz in den USA lässt sich dieses Problem jedoch problemlos lösen. Außerdem können Sie so Daten erfassen, als würden Sie von den USA aus surfen.
Notiz: Weitere Informationen dazu, warum Ihr Scraper möglicherweise blockiert wird und wie Proxys helfen können, finden Sie in diesem Artikel: Warum wird mein Scraper blockiert?
Ändern Ihres IP-Standorts mit Proxys für Web Scraping
Nachdem Sie nun wissen, wie die IP-Standortbestimmung Ihre Web-Scraping-Versuche einschränken kann, ist es wichtig zu wissen, wie Sie Ihren Standort einfach mit Proxys ändern und die Blockade umgehen können.
Bevor Sie Ihren IP-Standort in ein bestimmtes Land ändern können, benötigen Sie zunächst Zugriff auf einen Pool von Proxys, die sich in diesem Land befinden. Wenn Sie Ihre Anfrage über diesen Proxy-Pool senden, erkennt die Zielwebsite den Proxy-IP-Standort und ermöglicht Ihnen den Zugriff auf die benötigten Daten.
Um die Dinge einfacher zu machen (sowohl von der Entwicklungs- als auch von der Geschäftsseite), verwenden wir ScraperAPI, um unsere Proxys zu rotieren und nutzen dessen Geotargeting-Funktion, um drei häufige Herausforderungen im Zusammenhang mit geosensiblen Daten zu bewältigen:
1. Geografisch eingeschränkte Inhalte scrapen
Angenommen, Sie möchten die Website von HomeDepot nach Produktdaten durchsuchen.
import requests
from bs4 import BeautifulSoup
url = "https://www.homedepot.com/b/Furniture-Living-Room-Furniture-Sofas-Couches/N-5yc1vZc7oy?NCNI-5&searchRedirect=couch&semanticToken=k27r10r00f22000000000e_202407231926267546513699920_us-east4-wskn%20k27r10r00f22000000000e%20%3E%20st%3A%7Bcouch%7D%3Ast%20ml%3A%7B24%7D%3Aml%20nr%3A%7Bcouch%7D%3Anr%20nf%3A%7Bn%2Fa%7D%3Anf%20qu%3A%7Bcouch%7D%3Aqu%20ie%3A%7B0%7D%3Aie%20qr%3A%7Bcouch%7D%3Aqr"
response = requests.get(url)
# You will encounter an error or get blocked.
print(response.status_code)
Ohne die Verwendung von US-Proxys kann unsere Anfrage jedoch fehlschlagen oder blockiert werden, was zu einem Fehlercode wie diesem führt: 403 Forbidden – und das passiert mit dem obigen Code. Dies geschieht, weil die Website erkennt, dass die Anfrage von einer IP-Adresse kommt, die nicht auf den Inhalt zugreifen darf.
Um diese Einschränkung zu überwinden, verwenden wir ScraperAPI, um unsere Anfrage über den US-Proxy-Pool zu senden.
Erstellen Sie zunächst ein kostenloses ScraperAPI-Konto und kopieren Sie Ihren API-Schlüssel. Sie benötigen diesen Schlüssel später, um Ihre Anfrage zu senden. Stellen Sie dann sicher, dass Sie die erforderlichen Abhängigkeiten installiert haben. Sie können sie mit dem folgenden Befehl installieren:
pip install requests beautifulsoup4 lxml
Sobald alles eingerichtet ist, können wir ScraperAPIs verwenden country_code Parameter, um anzuweisen, alle unsere Anfragen nur über in den USA ansässige Proxys zu senden, etwa so:
import requests
API_KEY = "Your_Api_key"
url = "https://www.homedepot.com/b/Furniture-Living-Room-Furniture-Sofas-Couches/N-5yc1vZc7oy?NCNI-5&searchRedirect=couch&semanticToken=k27r10r00f22000000000e_202407231926267546513699920_us-east4-wskn%20k27r10r00f22000000000e%20%3E%20st%3A%7Bcouch%7D%3Ast%20ml%3A%7B24%7D%3Aml%20nr%3A%7Bcouch%7D%3Anr%20nf%3A%7Bn%2Fa%7D%3Anf%20qu%3A%7Bcouch%7D%3Aqu%20ie%3A%7B0%7D%3Aie%20qr%3A%7Bcouch%7D%3Aqr"
payload = {"api_key": API_KEY, "url": url, "render": True, "country_code":"us" }
response = requests.get("http://api.scraperapi.com", params=payload)
print(response.status_code)
Notiz: Denken Sie daran, zu ersetzen Your_Api_key mit Ihrem aktuellen ScraperAPI API-Schlüssel.
Durch einfaches Hinzufügen der country_code Parameter zu Ihrer ScraperAPI-Anfrage hinzufügen, können Sie auf HomeDepot zugreifen, als ob Sie von den USA aus surfen würden. Dies ist der neue Antwortcode dieses Scraping-Skripts:
2. Lokalisierte Daten scrapen
Ein weiteres Szenario, in dem Sie Ihren IP-Standort mit Proxys ändern können, ist, wenn sich die Antwort, die Sie erhalten, je nach Ihrem Standort ändert. Ein Paradebeispiel hierfür sind Suchmaschinen-Ergebnisseiten (SERPs).
Damit Sie leicht verstehen, was ich meine, verwenden wir den Google Search-Endpunkt von ScraperAPI, um Suchdaten aus Google-Suchergebnissen in den USA und Großbritannien abzurufen und zu vergleichen. Dieser Endpunkt wandelt die Daten in nutzbares JSON um, wodurch die Analyse regionaler Trends und Präferenzen erleichtert wird.
US-Suchergebnisse
Beginnen wir mit dem Abrufen von Suchergebnissen für das Schlüsselwort „Sofa“ aus den USA:
import requests
import json
APIKEY= "Your_Api_key"
QUERY = "Sofa"
payload = {'api_key': APIKEY, 'query': QUERY, 'country_code': 'us'}
r = requests.get('https://api.scraperapi.com/structured/google/search', params=payload)
# Parse the response text to a JSON object
data = r.json()
# Write the JSON object to a file
with open('Us_google_results.json', 'w') as json_file:
json.dump(data, json_file, indent=4)
print("Results have been stored in Us_google_results.json")
Dieser Code sendet eine Anfrage an den Google SERP-Endpunkt von ScraperAPI und gibt die USA als Zielland an. Die Antwort wird dann analysiert und in einer JSON-Datei mit dem Namen gespeichert. Us_google_results.json. Die in dieser Datei gespeicherten Ergebnisse spiegeln die lokalisierten Daten aus den USA wider.
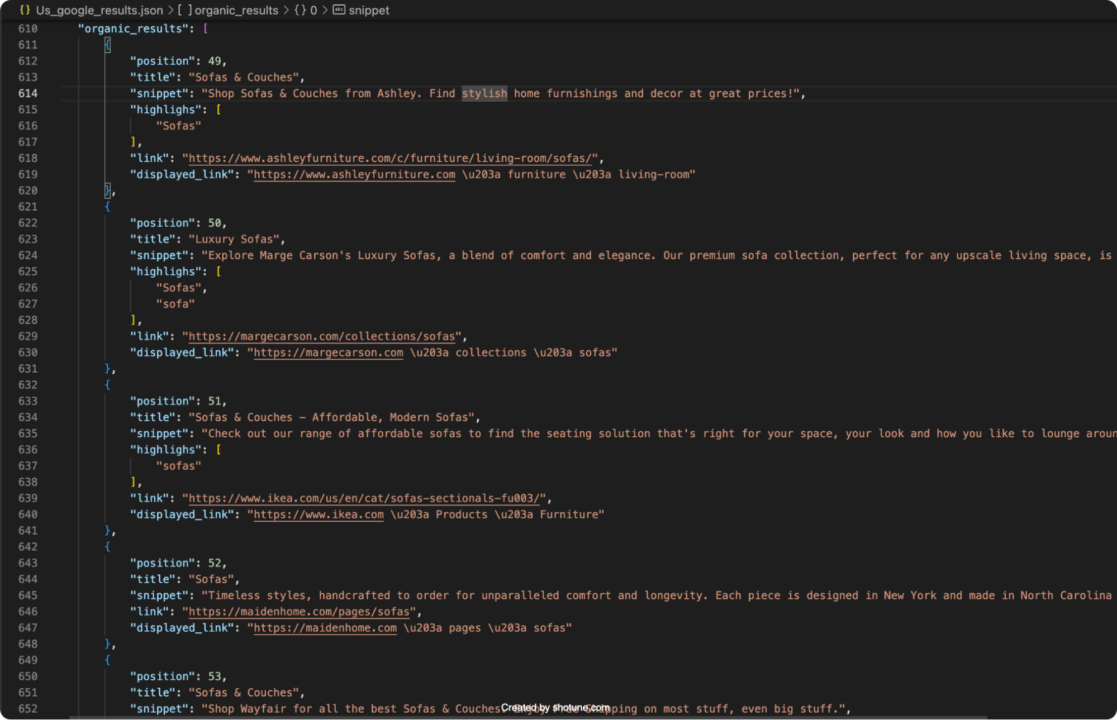
UK-Suchergebnisse
Als Nächstes machen wir dasselbe für Großbritannien:
import requests
import json
APIKEY= "Your_Api_key"
QUERY = "Sofa"
payload = {'api_key': APIKEY, 'query': QUERY, 'country_code': 'uk'}
r = requests.get('https://api.scraperapi.com/structured/google/search', params=payload)
# Parse the response text to a JSON object
data = r.json()
# Write the JSON object to a file
with open('Uk_google_results.json', 'w') as json_file:
json.dump(data, json_file, indent=4)
print("Results have been stored in Uk_google_results.json")
Notiz: Ersetzen
Dieser Code ruft Google-Suchergebnisse für das Schlüsselwort „Sofa“ ab, diesmal jedoch für Großbritannien. Die Daten werden gespeichert in Uk_google_results.jsonum die Unterschiede in den Suchergebnissen zwischen den beiden Regionen zu verdeutlichen.
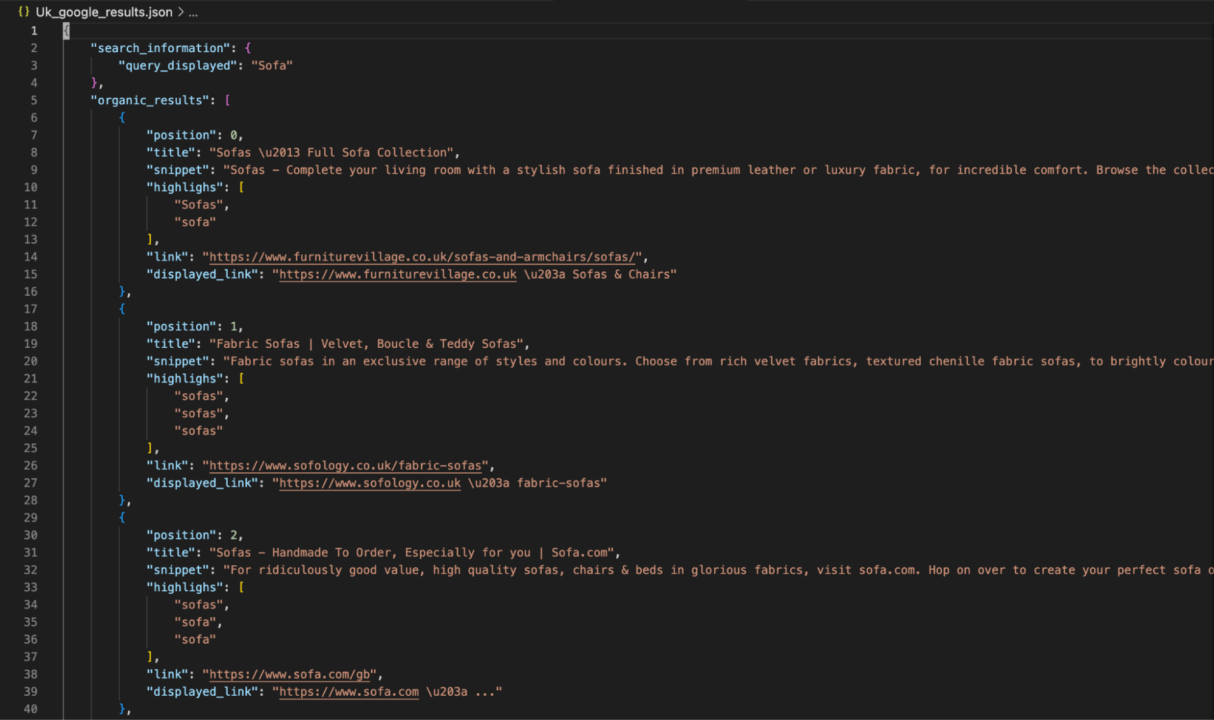
Durch die Änderung der country_code Parameter können Sie problemlos auf den jeweiligen Standort zugeschnittene Suchergebnisse abrufen und vergleichen und so regionale Trends und Vorlieben erkennen.
Dieser Ansatz ist von unschätzbarem Wert für Unternehmen, die Marktunterschiede verstehen, ihre SEO-Strategien optimieren oder Wettbewerbsanalysen in verschiedenen Regionen durchführen möchten. Weitere Einzelheiten zur Verwendung der SDEs von ScraperAPI finden Sie in der Dokumentation.
Vergleichen Sie Daten aus mehreren Regionen
In vielen Fällen müssen Sie denselben Datentyp aus verschiedenen Regionen zusammentragen, um umfassende Vergleiche durchführen zu können. Dies ist beispielsweise der Fall, wenn Sie die Preisstrategien eines Konkurrenten analysieren, der in mehreren europäischen Ländern tätig ist.
Mithilfe der Geotargeting-Funktion können Sie alle Daten so erfassen, wie sie für lokale Benutzer sichtbar sind. Auf diese Weise können Sie einen umfassenden Datensatz erstellen, der regionale Preisunterschiede und andere lokalisierte Informationen widerspiegelt.
Hier ist ein Beispiel für die Verwendung von ScraperAPI zum Sammeln von Daten aus den länderspezifischen Domänen von Amazon:
import requests
API_KEY = "YOUR_SCRAPERAPI_KEY"
target_countries = ("fr", "de", "es", "it") # France, Germany, Spain, Italy
base_url = "https://www.amazon"
for country_code in target_countries:
url = f"{base_url}.{country_code}/s?k=wireless+keyboard" # Modify URL structure as needed
payload = {"api_key": API_KEY, "url": url, "render": True, "country_code": country_code}
response = requests.get("http://api.scraperapi.com", params=payload)
# Extract and store product information for each country
if response.status_code == 200:
data = response.text
# Parse and extract relevant data here
print(f"Data from {country_code} has been successfully retrieved.")
else:
print(f"Failed to retrieve data from {country_code}. Status code: {response.status_code}")
Dieses Skript verwendet ScraperAPI, um Anfragen an die französischen, deutschen, spanischen und italienischen Domänen von Amazon zu senden und so einen lokalen Zugriff zu simulieren. country_code Der Parameter stellt sicher, dass die Daten das widerspiegeln, was ein lokaler Kunde sehen würde, einschließlich regionsspezifischer Preise und Produktverfügbarkeit.
Durch das Sammeln und Analysieren von Daten aus verschiedenen Regionen können Sie Muster und Unterschiede in Preisstrategien, Marketingtaktiken und Produktangeboten erkennen. Diese Informationen können für Marktanalysen, Wettbewerbsbeobachtungen und strategische Planungen von unschätzbarem Wert sein.
Für eine detaillierte Datenextraktion und -analyse müssen Sie Ihren Code möglicherweise weiter anpassen, um bestimmte HTML-Strukturen oder Datenformate zu verarbeiten, die von der Amazon-Site der einzelnen Regionen verwendet werden.
Möchten Sie Zeit beim Parsen und Bereinigen von HTML-Rohdaten sparen? Verwenden Sie unseren Amazon Scraper, um HTML-Rohdaten in gebrauchsfertige Produktdaten im JSON- oder CSV-Format umzuwandeln.
Welcher Web Scraping-Proxy ist der beste für Sie?
Wie immer hängt die Auswahl des besten Proxy-Anbieters für Web Scraping von Ihren genauen Anforderungen und Zielen ab.
Berücksichtigen Sie vor Ihrer Auswahl die folgenden Aspekte:
- Wie hoch ist Ihr Budget? Proxy-Dienste sind in vielen verschiedenen Preisplänen erhältlich, von kostenlosen Tarifen bis hin zu Abonnements auf Unternehmensebene.
- Wie groß ist Ihr Datenbedarf? Wie viele Anfragen müssen gleichzeitig ausgeführt werden? Größere Projekte erfordern robustere Lösungen, die hohe Anfragevolumina verarbeiten können.
- Benötigen Sie ein integriertes Analysepanel? Einige Anbieter bieten Dashboards zur Überwachung Ihrer Nutzung, Erfolgsraten und anderer hilfreicher Kennzahlen an.
- Benötigen Sie lediglich Proxys oder ist für Ihre Aufgaben auch ein Scraping-Tool hilfreich? Lesen Sie unseren Leitfaden zu den Optionen für eine Scraping-API anstelle von Proxys, um die richtige auszuwählen.
- Wird das Tool, das Sie in Betracht ziehen, Ihre Arbeit in zufriedenstellendem Maße automatisieren? Wie viel Zeit müssen Sie für Wartung und manuelle Aufgaben aufwenden? Suchen Sie nach Funktionen, die die Proxy-Verwaltung vereinfachen und Ihren Arbeitsaufwand reduzieren.
- Verfügt der Anbieter über eine API? Mithilfe von APIs können Sie das Tool problemlos in Ihren Stack integrieren, was für Web Scraping im großen Maßstab unerlässlich ist.
Wenn Sie nach einer leistungsstarken und zuverlässigen Web-Scraping-Lösung suchen, die alle Anforderungen erfüllt und über einen Pool von Proxys in über 50 Ländern verfügt, sollten Sie ScraperAPI in Betracht ziehen.
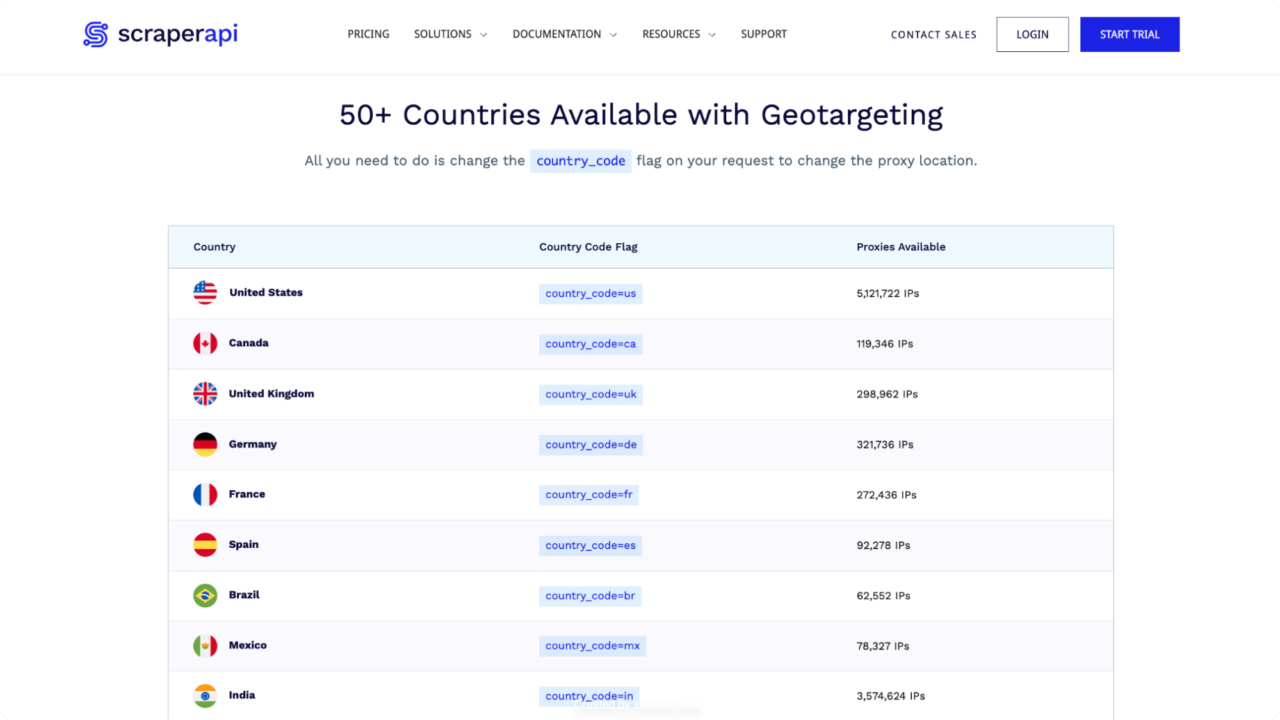
Hier ist der Grund:
- Umfangreicher IP-Pool: Zugriff auf über 40 Millionen IPs in mehr als 50 Ländern.
- Hohe Verfügbarkeit: Sorgt für eine Verfügbarkeit von 99,99 %, optimiert die Anforderungsgeschwindigkeit und entfernt IPs auf der schwarzen Liste.
- Automatisierung: Automatisiert IP- und HTTP-Header-Rotationen durch maschinelles Lernen für mehr Effizienz.
- Erweiterte Anti-Bot-Umgehung: Behandelt CAPTCHAs, Ratenbegrenzung, Fingerprinting und andere Abwehrmaßnahmen.
- Strukturierte Datenendpunkte: Bietet Endpunkte zum Umwandeln von reinem HTML in JSON- oder CSV-Daten von großen Domänen wie Amazon, Walmart und Google.
Die Verwendung dieser Endpunkte kann Ihre Datenerfassung erheblich beschleunigen, da ScraperAPI den gesamten Prozess übernimmt und Ihnen alle relevanten Daten bereitstellt, damit Sie Ihre Kunden basierend auf ihrem Standort ansprechen können.
Einpacken
Proxys sind ein wesentlicher Bestandteil des Web-Scrapings. Sie ermöglichen es Ihnen, Ihre IP-Adresse zu verbergen, Ratenbegrenzungen zu umgehen und auf geografisch eingeschränkte Inhalte zuzugreifen. Wenn Sie verstehen, wie Sie Proxys effektiv nutzen, können Sie:
- Überwinden Sie geografische Einschränkungen
- Sammeln Sie Daten aus bestimmten Regionen
- Reduzieren Sie das Risiko, blockiert zu werden
Sind Sie bereit für müheloses Web Scraping? Melden Sie sich noch heute für ein kostenloses ScraperAPI-Konto an und erhalten Sie 5.000 kostenlose Scraping-Credits, um loszulegen!
Informationen zu fortgeschritteneren Techniken finden Sie in diesen Ressourcen:
