
Das Erlernen von PHP Web Scraping ist in verschiedenen Bereichen von Vorteil. Unabhängig davon, ob Sie ein Vermarkter oder ein SEO-Forscher sind, ist der Zugriff auf aktuelle Daten immer wichtig und die manuelle Datenerfassung kann zeitaufwändig sein. Hier kommt Web Scraping ins Spiel. Es kann in vielen Bereichen hilfreich sein, von Suchmaschinenoptimierung und SEO-Marketing bis hin zur Big-Data-Analyse.
Warum Scrapen mit PHP?
PHP ist eine leistungsstarke objektorientierte Programmiersprache, die speziell für die Webentwicklung entwickelt wurde. Dank der benutzerfreundlichen Syntax ist es auch für Anfänger leicht zu erlernen und zu verstehen. PHP ist nicht nur benutzerfreundlich, sondern verfügt auch über eine außergewöhnliche Leistung, sodass PHP-Skripte schnell und effizient ausgeführt werden können.
Die starke Unterstützung durch die PHP-Community stellt sicher, dass Sie Zugriff auf zahlreiche Ressourcen, Tutorials und Foren haben, in denen Sie Anleitungen erhalten und Wissen austauschen können. Insgesamt bietet PHP die perfekte Kombination aus Einfachheit, Geschwindigkeit und Vielseitigkeit, was es zu einer hervorragenden Programmiersprache für Web Scraping macht.
Einrichten der Umgebung für Web Scraping mit PHP
Um einen PHP-Scraper zu erstellen, müssen wir PHP einrichten und die Bibliotheken herunterladen, die wir später in unsere Projekte einbinden werden. Es gibt jedoch zwei Möglichkeiten, wie wir dies tun können. Sie können alle Bibliotheken manuell herunterladen und die Initialisierungsdatei konfigurieren oder sie mit Composer automatisieren.
Da es unser Ziel ist, die Skripterstellung so weit wie möglich zu vereinfachen und Ihnen zu zeigen, wie es geht, installieren wir Composer und erklären Ihnen, wie Sie es verwenden.
Einbau der Komponenten
Laden Sie zunächst PHP von der offiziellen Website herunter. Wenn Sie Windows haben, laden Sie die neueste stabile Version als Zip-Archiv herunter. Entpacken Sie es dann an einem leicht zu merkenden Ort, beispielsweise im Ordner „PHP“ auf Ihrem Laufwerk C.
Wenn Sie Windows verwenden, müssen Sie den Pfad zu den PHP-Dateien in Ihrem System festlegen. Öffnen Sie dazu einen beliebigen Ordner auf Ihrem Computer und gehen Sie zu den Systemeinstellungen (klicken Sie mit der rechten Maustaste auf diesen PC und gehen Sie zu Eigenschaften).
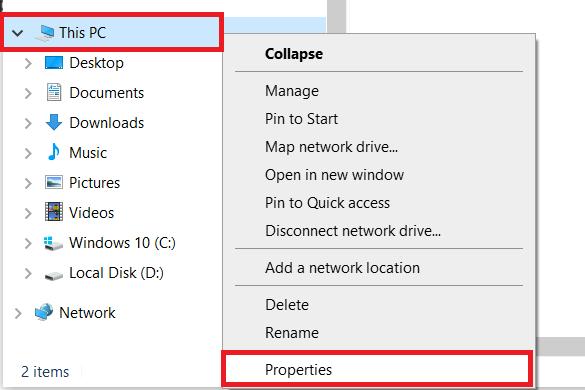
Suchen Sie auf der Seite nach der Option „Erweiterte Systemeinstellungen“ und klicken Sie darauf.
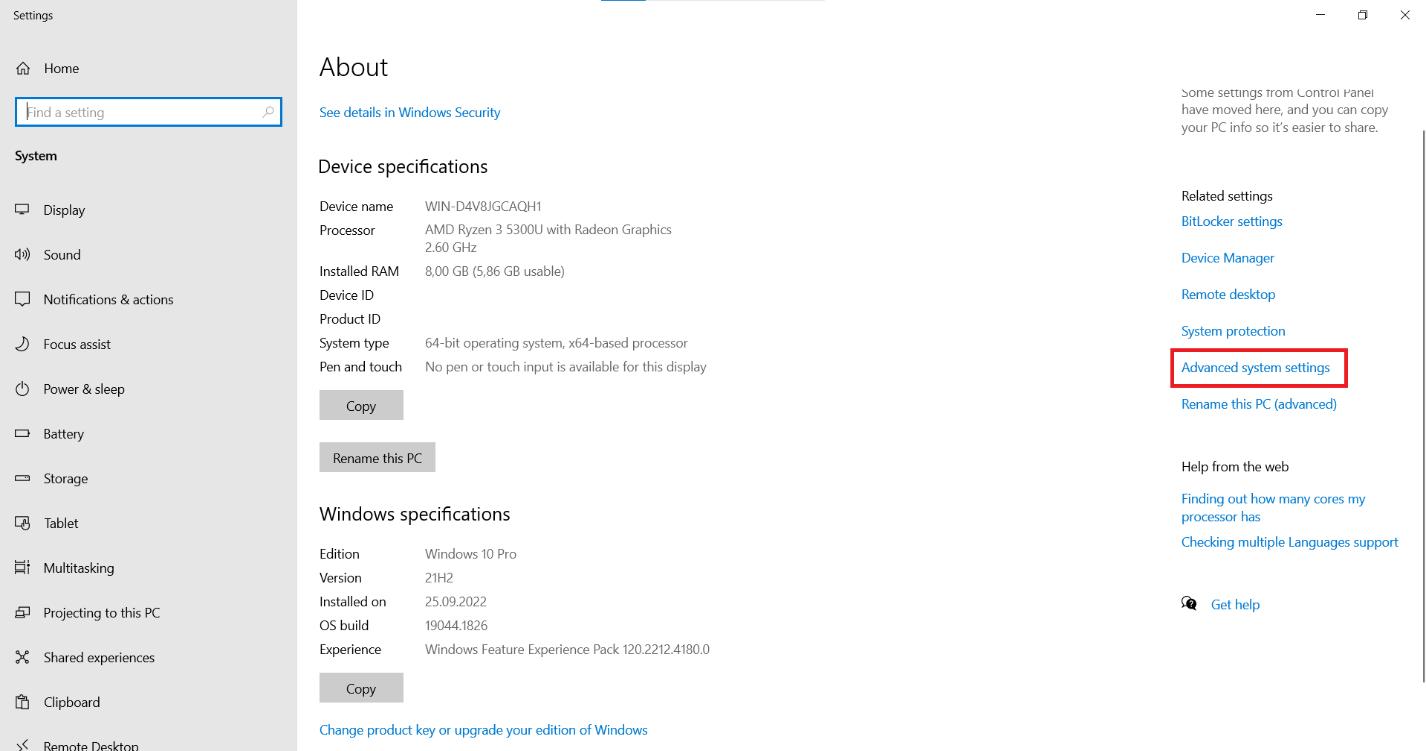
Suchen Sie auf der Registerkarte „Erweitert“ nach der Schaltfläche „Umgebungsvariablen“ und klicken Sie darauf.
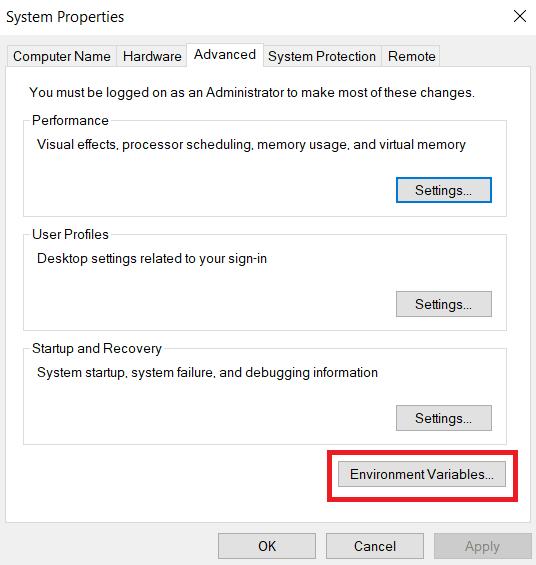
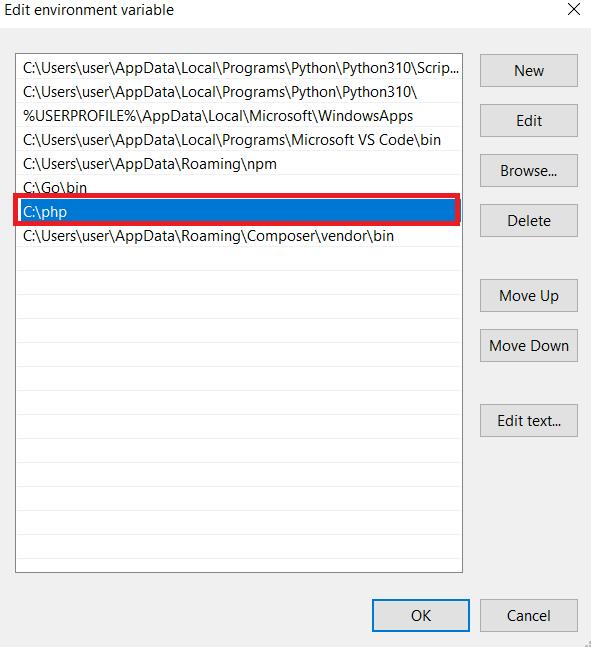
Suchen Sie im Abschnitt „Benutzervariablen für Benutzer“ die Variable „Pfad“ und klicken Sie auf die Schaltfläche „Bearbeiten“.
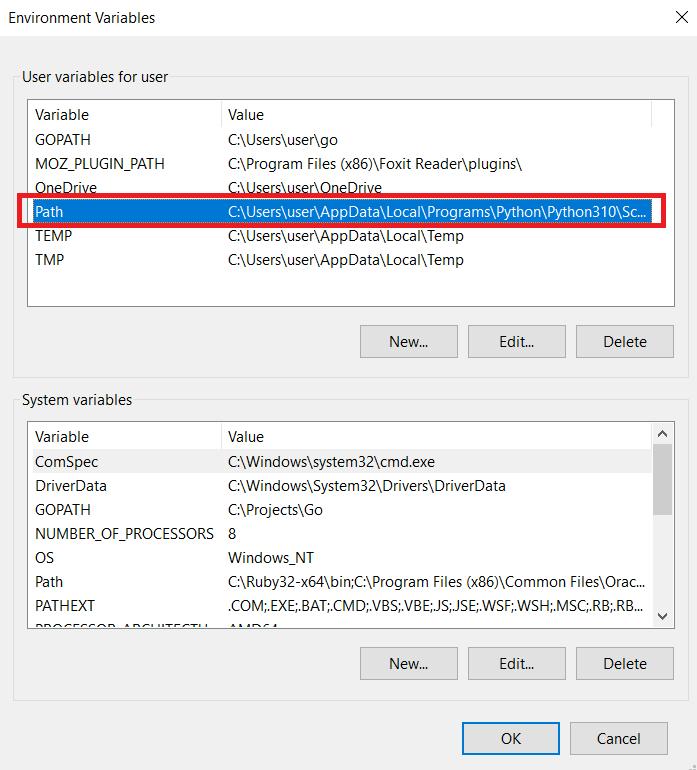
Es öffnet sich ein neues Fenster, in dem Sie den Wert der Variable „Pfad“ bearbeiten können. Fügen Sie den Pfad zu den PHP-Dateien am Ende des vorhandenen Werts hinzu. Klicken Sie auf die Schaltfläche „OK“, um die Änderungen zu speichern. Wenn Sie noch Fragen haben, können Sie die Dokumentation lesen.
Jetzt installieren wir Composer, einen Abhängigkeitsmanager für PHP, der die Verwaltung und Installation von Bibliotheken von Drittanbietern in Ihrem Projekt vereinfacht. Sie können alle Pakete von github.com herunterladen, unserer Erfahrung nach ist Composer jedoch praktischer.
Gehen Sie zunächst auf die offizielle Website und laden Sie Composer herunter. Befolgen Sie dann die Anweisungen in der Installationsdatei. Sie müssen auch den Pfad angeben, in dem sich PHP befindet. Stellen Sie daher sicher, dass er richtig eingestellt ist.
Erstellen Sie im Stammverzeichnis Ihres Projekts eine neue Datei mit dem Namen „composer.json“. Diese Datei enthält Informationen zu den Abhängigkeiten Ihres Projekts. Wir haben eine einzelne Datei vorbereitet, die alle im heutigen Tutorial verwendeten Bibliotheken enthält, damit Sie unsere Einstellungen kopieren können.
{
"require": {
"fabpot/goutte": "^4.0",
"facebook/webdriver": "^1.1",
"guzzlehttp/guzzle": "^7.7",
"imangazaliev/didom": "^2.0",
"j4mie/idiorm": "^1.5",
"jaeger/querylist": "^4.2",
"kriswallsmith/buzz": "^0.15.0",
"nategood/httpful": "^0.3.2",
"php-webdriver/webdriver": "^1.1",
"querypath/querypath": "^3.0",
"sunra/php-simple-html-dom-parser": "^1.5",
"symfony/browser-kit": "^6.3",
"symfony/dom-crawler": "^6.3"
},
"config": {
"platform": {
"php": "8.2.7"
},
"preferred-install": {
"*": "dist"
},
"minimum-stability": "stable",
"prefer-stable": true,
"sort-packages": true
}
}Navigieren Sie zunächst in der Befehlszeile zu dem Verzeichnis, das die Datei „composer.json“ enthält, und führen Sie den folgenden Befehl aus:
composer install Der Composer lädt die angegebenen Abhängigkeiten herunter und installiert sie im Herstellerverzeichnis Ihres Projekts.
Sie können diese Bibliotheken jetzt mit einem Befehl in der Datei mit Ihrem Code in Ihr Projekt importieren.
require 'vendor/autoload.php';Jetzt können Sie Klassen aus den installierten Bibliotheken verwenden, indem Sie sie einfach in Ihrem Code aufrufen.
Seitenanalyse
Nachdem wir nun die Umgebung vorbereitet und alle Komponenten eingerichtet haben, analysieren wir die Webseite, die wir durchsuchen werden. Als Beispiel verwenden wir diese Demo-Website. Gehen Sie zur Website und öffnen Sie die Entwicklerkonsole (F12 oder klicken Sie mit der rechten Maustaste und gehen Sie zu „Inspizieren“).
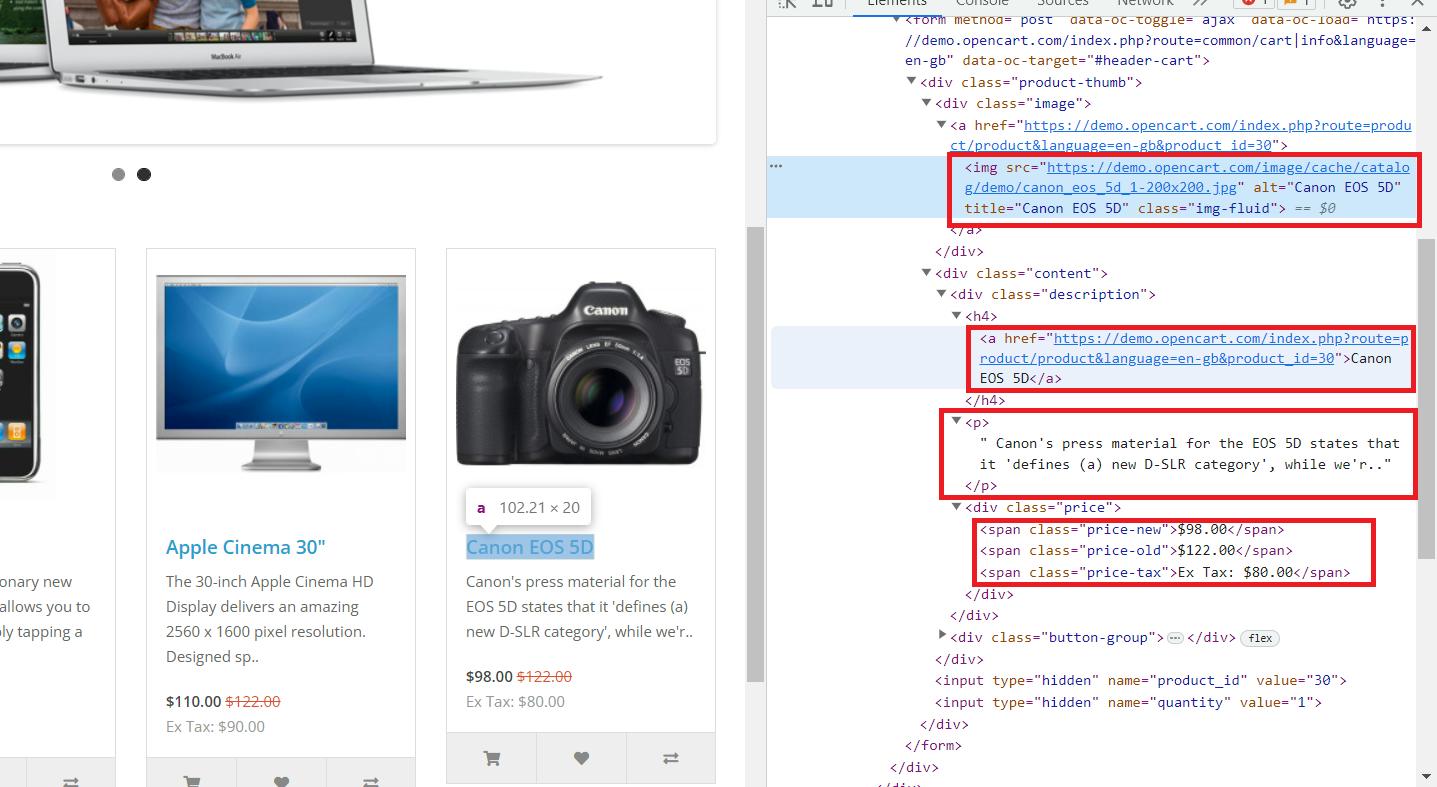
Hier sehen wir, dass alle notwendigen Daten im übergeordneten Tag „div“ mit dem Klassennamen „col“ gespeichert sind, der alle Produkte auf der Seite enthält. Es enthält die folgenden Informationen:
- Das Tag „img“ enthält den Link zum Produktbild im Attribut „src“.
- Das „a“-Tag enthält den Produktlink im „href“-Attribut.
- Der Tag „h4“ enthält den Produkttitel.
- Das „p“-Tag enthält die Produktbeschreibung.
- Preise werden im Tag „span“ mit verschiedenen Klassen gespeichert:
5.1. „Preis-alt“ zum Originalpreis.
5.2. „Neupreis“ zum reduzierten Preis.
5.3. „Preissteuer“ für die Steuer.
Da wir nun wissen, wo die benötigten Informationen gespeichert sind, können wir mit dem Scraping beginnen.
Top 10 der besten PHP-Web-Scraping-Bibliotheken
Es gibt so viele Bibliotheken in PHP, dass es schwierig ist, sie alle umfassend abzudecken. Wir haben jedoch die beliebtesten und am häufigsten verwendeten ausgewählt und werden sie nun einzeln betrachten.
Fressen
Wir beginnen unsere Sammlung mit der Guzzle Library. Das Einzige, was diese Bibliothek kann, ist, Anfragen zu bearbeiten, aber sie macht das außergewöhnlich gut.
Vor- und Nachteile der Bibliothek
Wie bereits erwähnt, ist Guzzle eine Bibliothek zum Stellen von Anfragen. Es kann zwar den Code der gesamten Seite abrufen, die erforderlichen Daten jedoch nicht verarbeiten und extrahieren. Unsere Liste enthält jedoch auch Bibliotheken, die sich hervorragend zum Parsen eignen, aber keine Abfragen durchführen können. Daher ist Guzzle zum Schaben unerlässlich.
Anwendungsbeispiel
Erstellen wir eine neue Datei mit der Erweiterung *.php und importieren wir unsere Bibliotheken. Wir haben diesen Befehl bereits verwendet, als wir die PHP-Web-Scraping-Bibliotheken installiert haben.
<?php
require 'vendor/autoload.php';
// Here will be code
?>Jetzt können wir den Guzzle-Client erstellen.
use GuzzleHttp\Client;
$client = new Client();Viele Menschen stoßen jedoch auf Probleme mit dem SSL-Zertifikat. Wenn Sie in einer lokalen Entwicklungsumgebung arbeiten, können Sie die SSL-Zertifikatsüberprüfung vorübergehend deaktivieren, um Ihre Arbeit fortzusetzen. Dies wird in einer Produktionsumgebung nicht empfohlen, kann jedoch eine vorübergehende Lösung für Entwicklungs- und Testzwecke sein.
$client = new Client(('verify' => false));Geben Sie nun die URL der Seite an, die wir scrapen möchten.
$url="https://demo.opencart.com/";Jetzt müssen wir nur noch eine Anfrage an die Zielwebsite senden und das Ergebnis auf dem Bildschirm anzeigen. In dieser Phase treten jedoch häufig Fehler auf, daher schließen wir diesen Codeblock in eine try…catch()-Anweisung ein, um mögliche Probleme zu beheben, ohne dass das Skript angehalten wird.
try {
$response = $client->request('GET', $url);
$body = $response->getBody()->getContents();
echo $body;
} catch (Exception $e) {
echo 'Error: ' . $e->getMessage();Wir könnten Daten von dieser Seite mit regulären Ausdrücken abrufen, aber diese Methode wäre nicht einfach, da wir eine beträchtliche Datenmenge benötigen. Vollständiger Code:
<?php
require 'vendor/autoload.php';
use GuzzleHttp\Client;
$client = new Client(('verify' => false));
$url="https://demo.opencart.com/";
try {
$response = $client->request('GET', $url);
$body = $response->getBody()->getContents();
echo $body;
} catch (Exception $e) {
echo 'Error: ' . $e->getMessage();
}
?>Kommen wir nun zur nächsten Bibliothek.
HTTPful
HTTPful ist eine weitere funktionale und nützliche Abfragebibliothek. Es unterstützt alle Anfragen, einschließlich POST, GET, DELETE und PUT.
Vor- und Nachteile der Bibliothek
Die Bibliothek ist einfach und benutzerfreundlich, hat aber eine kleinere Community als Guzzle. Leider verfügt es über weniger Funktionalität und ist trotz seiner Einfachheit weniger beliebt. Darüber hinaus wurde es schon längere Zeit nicht mehr aktualisiert, sodass es bei der Verwendung zu Problemen kommen kann.
Anwendungsbeispiel
Da es sich um eine Abfragebibliothek handelt, geben wir ein besonders kleines Beispiel für die Durchführung einer Abfrage, da wir zum Parsen eine andere Bibliothek verwenden müssten:
<?php
require 'vendor/autoload.php';
use Httpful\Request;
$response = Request::get('https://demo.opencart.com/')->send();
$html = $response->body;
?>Sie können es also in Ihren Scraping-Projekten verwenden, wir empfehlen Ihnen jedoch, etwas anderes zu verwenden.
Symfony
Symfony ist ein Framework, das viele Komponenten zum Scraping enthält. Es unterstützt verschiedene Möglichkeiten, HTML-Dokumente zu verarbeiten und Abfragen auszuführen.
Vor- und Nachteile der Bibliothek
Mit Symfony können Sie beliebige Daten aus einer HTML-Struktur extrahieren und sowohl CSS-Selektoren als auch XPath verwenden. Unabhängig von der Größe der Seite erfolgt die Verarbeitung recht schnell.
Obwohl Symfony als eigenständiges Scraping-Tool verwendet werden kann, ist es ein sehr großes und schweres Framework. Aus diesem Grund ist es üblich, nicht das gesamte Framework, sondern nur eine bestimmte Komponente zu verwenden.
Anwendungsbeispiel
Nutzen wir also den Crawler zum Verarbeiten von Seiten und die bereits besprochene Guzzle-Bibliothek zum Stellen von Anfragen. Wir werden es nicht noch einmal durchgehen und sehen, wie man einen Client erstellt und eine Abfrage ausführt.
Fügen Sie „use“ hinzu, das besagt, dass wir den Crawler der Symfony-Bibliothek verwenden werden.
use Symfony\Component\DomCrawler\Crawler;Verbessern Sie als Nächstes den Code, den wir im try{…}-Block geschrieben haben. Wir werden die Anfrage bearbeiten und alle Elemente mit der Klasse „.col“ abrufen.
$body = $response->getBody()->getContents();
$crawler->addHtmlContent($body);
$elements = $crawler->filter('.col');Jetzt müssen wir nur noch jeden gesammelten Artikel durchgehen und die gewünschten Informationen auswählen. Dazu verwenden wir den XPath der Elemente, die wir bei der Analyse der Seite berücksichtigt haben.
Möglicherweise ist Ihnen jedoch aufgefallen, dass nicht alle Artikel den alten Preis haben. Da Artikel mit der Klasse „.price-old“ möglicherweise nicht existieren, zeigen wir dies im Skript an und verwenden „-“ anstelle von Preis.
foreach ($elements as $element) {
$image = $crawler->filterXPath('.//img', $element)->attr('src');
$title = $crawler->filterXPath('.//h4', $element)->text();
$link = $crawler->filterXPath('.//h4/a', $element)->attr('href');
$desc = $crawler->filterXPath('.//p', $element)->text();
$old_p_element = $crawler->filterXPath('.//span.price-old', $element);
$old_p = $old_p_element->count() ? $old_p_element->text() : '-';
$new_p = $crawler->filterXPath('.//span.price-new', $element)->text();
$tax = $crawler->filterXPath('.//span.price-tax', $element)->text();
// Here will be code
}Und schließlich müssen wir nur noch alle gesammelten Daten auf dem Bildschirm anzeigen:
echo 'Image: ' . $image . "\n";
echo 'Title: ' . $title . "\n";
echo 'Link: ' . $link . "\n";
echo 'Description: ' . $desc . "\n";
echo 'Old Price: ' . $old_p . "\n";
echo 'New Price: ' . $new_p . "\n";
echo 'Tax: ' . $tax . "\n";
echo "\n";Somit haben wir alle Daten in die Konsole bekommen:
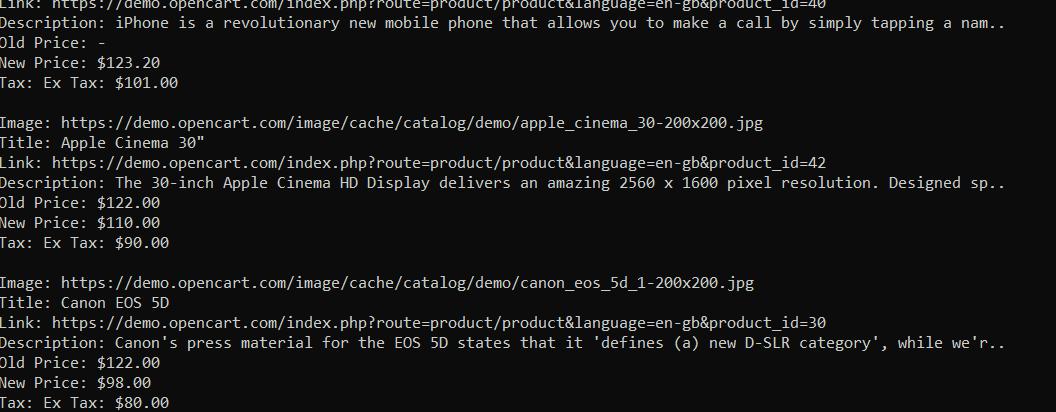
Wenn Sie am endgültigen Code interessiert sind oder uns während des Tutorials verloren haben, finden Sie hier das vollständige Skript:
<?php
require 'vendor/autoload.php';
use GuzzleHttp\Client;
use Symfony\Component\DomCrawler\Crawler;
$client = new Client((
'verify' => false
));
$crawler = new Crawler();
$url="https://demo.opencart.com/";
try {
$response = $client->request('GET', $url);
$body = $response->getBody()->getContents();
$crawler->addHtmlContent($body);
$elements = $crawler->filter('.col');
foreach ($elements as $element) {
$image = $crawler->filterXPath('.//img', $element)->attr('src');
$title = $crawler->filterXPath('.//h4', $element)->text();
$link = $crawler->filterXPath('.//h4/a', $element)->attr('href');
$desc = $crawler->filterXPath('.//p', $element)->text();
$old_p_element = $crawler->filterXPath('.//span.price-old', $element);
$old_p = $old_p_element->count() ? $old_p_element->text() : '-';
$new_p = $crawler->filterXPath('.//span.price-new', $element)->text();
$tax = $crawler->filterXPath('.//span.price-tax', $element)->text();
echo 'Image: ' . $image . "\n";
echo 'Title: ' . $title . "\n";
echo 'Link: ' . $link . "\n";
echo 'Description: ' . $desc . "\n";
echo 'Old Price: ' . $old_p . "\n";
echo 'New Price: ' . $new_p . "\n";
echo 'Tax: ' . $tax . "\n";
echo "\n";
}
} catch (Exception $e) {
echo 'Error: ' . $e->getMessage();
}
?>Wenn Sie nur das Symfony-Framework verwenden möchten, können Sie dessen Panther-Komponente verwenden. Wir gehen die Panther-Nutzung nicht Schritt für Schritt durch, sondern geben Ihnen ein Beispiel, das die gleichen Daten liefert:
<?php
require 'vendor/autoload.php';
use Symfony\Component\Panther\Panther;
$client = Panther::createChromeClient();
$crawler = $client->request('GET', 'https://demo.opencart.com/');
$elements = $crawler->filter('.col');
$elements->each(function ($element) {
$image = $element->filter('img')->attr('src');
$title = $element->filter('h4')->text();
$link = $element->filter('h4 > a')->attr('href');
$desc = $element->filter('p')->text();
$old_p_element = $element->filter('span.price-old');
$old_p = $old_p_element->count() > 0 ? $old_p_element->text() : '-';
$new_p = $element->filter('span.price-new')->text();
$tax = $element->filter('span.price-tax')->text();
echo 'Image: ' . $image . "\n";
echo 'Title: ' . $title . "\n";
echo 'Link: ' . $link . "\n";
echo 'Description: ' . $desc . "\n";
echo 'Old Price: ' . $old_p . "\n";
echo 'New Price: ' . $new_p . "\n";
echo 'Tax: ' . $tax . "\n";
echo "\n";
});
$client->quit();
?> Kommen wir nun zu einer Bibliothek, die die beiden besprochenen ersetzen kann.
Goutte
Goutte ist eine PHP-Bibliothek, die eine bequeme Möglichkeit zum Scrapen von Webseiten bietet. Es basiert auf Symfony-Komponenten wie DomCrawler und BrowserKit und nutzt Guzzle als HTTP-Client. Daher vereint es die Vorteile dieser beiden Bibliotheken.
Vor- und Nachteile der Bibliothek
Goutte verfügt über eine einfache Funktionalität, die das Scrapen von Webseiten für Anfänger einfach macht. Es unterstützt außerdem sowohl CSS-Selektoren als auch XPath.
Obwohl Goutte eine leistungsstarke und praktische Bibliothek für Web Scraping in PHP ist, weist sie einige Einschränkungen und Nachteile auf. Es fehlt die integrierte Unterstützung für die Ausführung von JavaScript auf der Seite. Wenn die Zielseite für die Anzeige oder das Laden von Daten stark auf JavaScript angewiesen ist, ist Goutte möglicherweise nicht die beste Wahl.
Anwendungsbeispiel
Wenn man bedenkt, dass die Guotte-Bibliothek auf Guzzle und Symfony basiert, entspricht ihre Verwendung der, die wir bereits betrachtet haben. Auch hier verwenden wir Methoden wie filter() und attr() oder text(), um die benötigten Daten, wie Bilder, Titel oder Links, zu extrahieren:
<?php
require 'vendor/autoload.php';
$guzzleClient = new \GuzzleHttp\Client((
'verify' => false
));
$client = new \Goutte\Client();
$client->setClient($guzzleClient);
try {
$crawler = $client->request('GET', 'https://demo.opencart.com/');
$elements = $crawler->filter('.col');
$elements->each(function ($element) {
$image = $element->filter('img')->attr('src');
$title = $element->filter('h4')->text();
$link = $element->filter('h4 > a')->attr('href');
$desc = $element->filter('p')->text();
$old_p_element = $element->filter('span.price-old');
$old_p = $old_p_element->count() ? $old_p_element->text() : '-';
$new_p = $element->filter('span.price-new')->text();
$tax = $element->filter('span.price-tax')->text();
echo 'Image: ' . $image . "\n";
echo 'Title: ' . $title . "\n";
echo 'Link: ' . $link . "\n";
echo 'Description: ' . $desc . "\n";
echo 'Old Price: ' . $old_p . "\n";
echo 'New Price: ' . $new_p . "\n";
echo 'Tax: ' . $tax . "\n";
echo "\n";
});
} catch (Exception $e) {
echo 'Error: ' . $e->getMessage();
}
?>Wir haben also die gleichen Daten erhalten, aber mit einer anderen Bibliothek:
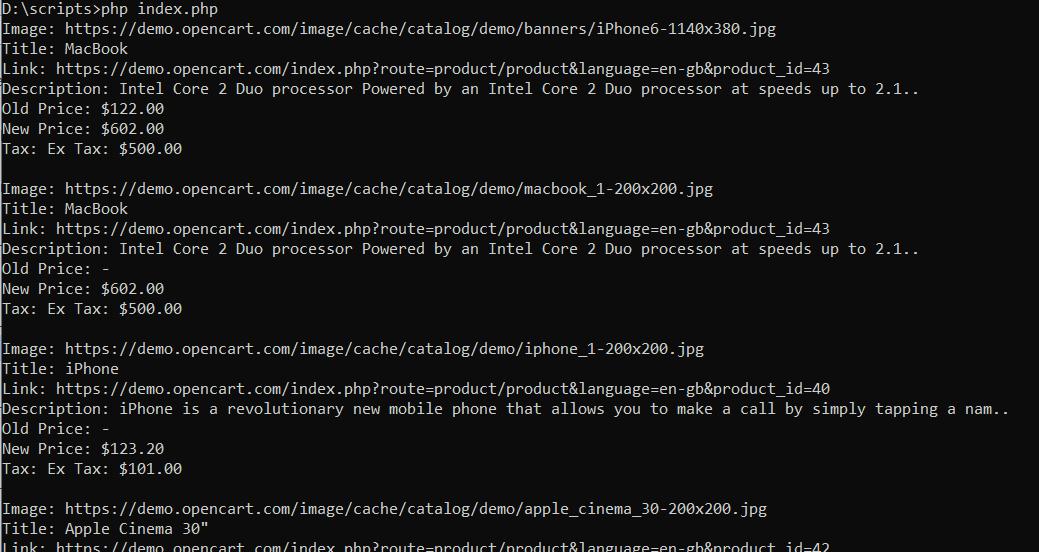
Wie Sie sehen, ist Goutte eine recht praktische PHP-Web-Scraping-Bibliothek.
Scrape-It.Cloud-API
Die Scrape-It.Cloud API ist eine spezielle Schnittstelle, die wir entwickelt haben, um den Scraping-Prozess zu vereinfachen. Beim Scraping von Daten stehen Entwickler häufig vor mehreren Herausforderungen, wie z. B. JavaScript-Rendering, Captcha, Blöcken usw. Durch die Verwendung unserer API können Sie diese Probleme jedoch umgehen und sich auf die Verarbeitung der Daten konzentrieren, die Sie bereits erhalten haben.
Vor- und Nachteile der Bibliothek
Wie bereits erwähnt, hilft Ihnen unsere Web-Scraping-API, viele Herausforderungen bei der Entwicklung Ihres Scrapers zu vermeiden. Darüber hinaus sparen Sie Geld. Wir haben bereits die Top 10 Proxy-Anbieter besprochen und die Kosten für den Kauf rotierender Proxys und unseres Abonnements verglichen.
Wenn Sie außerdem einige Daten benötigen und keinen Scraper entwickeln möchten, können Sie unsere No-Code-Scraper für die beliebtesten Websites verwenden. Wenn Sie Zweifel haben und es ausprobieren möchten, melden Sie sich auf unserer Website an und erhalten Sie im Rahmen der Testversion kostenlose Credits.
Anwendungsbeispiel
Um die API nutzen zu können, müssen wir eine Anfrage stellen. Wir werden die Guzzle-Bibliothek verwenden, die wir bereits besprochen haben. Lassen Sie es uns verbinden und den API-Link festlegen.
require 'vendor/autoload.php';
use GuzzleHttp\Client;
$apiUrl="https://api.scrape-it.cloud/scrape";Jetzt müssen wir eine Anfrage mit zwei Teilen erstellen – den Anfrageheadern und dem Anfragetext. Richten Sie zunächst die Header ein:
$headers = (
'x-api-key' => 'YOUR-API-KEY',
'Content-Type' => 'application/json',
);Sie müssen „YOUR-API-KEY“ durch Ihren eindeutigen Schlüssel ersetzen, den Sie nach der Anmeldung auf unserer Website in Ihrem Konto finden.
Dann müssen wir den Hauptteil der Anfrage so festlegen, dass er der API mitteilt, welche Daten wir benötigen. Hier können Sie die Datenextraktionsregeln, den Proxy und die Art des Proxys, den Sie verwenden möchten, das zu extrahierende Skript, den Link zur Ressource und vieles mehr angeben. Eine vollständige Liste der Parameter finden Sie in unserer Dokumentation.
$data = (
'extract_rules' => (
'Image' => 'img @src',
'Title' => 'h4',
'Link' => 'h4 > a @href',
'Description' => 'p',
'Old Price' => 'span.price-old',
'New Price' => 'span.price-new',
'Tax' => 'span.price-tax',
),
'wait' => 0,
'screenshot' => true,
'block_resources' => false,
'url' => 'https://demo.opencart.com/',
);Wir haben Extraktionsregeln verwendet, um nur die gewünschten Daten zu erhalten. Die API gibt die Antwort im JSON-Format zurück, mit dem wir nur die Extraktionsregeln aus der Antwort extrahieren können.
$data = json_decode($response->getBody(), true);
if ($data('status') === 'ok') {
$extractionData = $data('scrapingResult')('extractedData');
foreach ($extractionData as $key => $value) {
echo $key . ": " . json_encode($value) . "\n\n";
}
} else {
echo "An error occurred: " . $data('message');
}Wir erhalten die gewünschten Informationen, indem wir das von uns erstellte Skript ausführen. Das Beste daran ist, dass dieses Skript unabhängig von der Website funktioniert, die Sie durchsuchen möchten. Sie müssen lediglich die Extraktionsregeln ändern und den Link zur Zielressource bereitstellen.
Vollständiger Code:
<?php
require 'vendor/autoload.php';
use GuzzleHttp\Client;
$apiUrl="https://api.scrape-it.cloud/scrape";
$headers = (
'x-api-key' => 'YOUR-API-KEY',
'Content-Type' => 'application/json',
);
$data = (
'extract_rules' => (
'Image' => 'img @src',
'Title' => 'h4',
'Link' => 'h4 > a @href',
'Description' => 'p',
'Old Price' => 'span.price-old',
'New Price' => 'span.price-new',
'Tax' => 'span.price-tax',
),
'wait' => 0,
'screenshot' => true,
'block_resources' => false,
'url' => 'https://demo.opencart.com/',
);
$client = new Client(('verify' => false));
$response = $client->post($apiUrl, (
'headers' => $headers,
'json' => $data,
));
$data = json_decode($response->getBody(), true);
if ($data('status') === 'ok') {
$extractionData = $data('scrapingResult')('extractedData');
foreach ($extractionData as $key => $value) {
echo $key . ": " . json_encode($value) . "\n\n";
}
} else {
echo "An error occurred: " . $data('message');
}
?>Das Ergebnis ist:
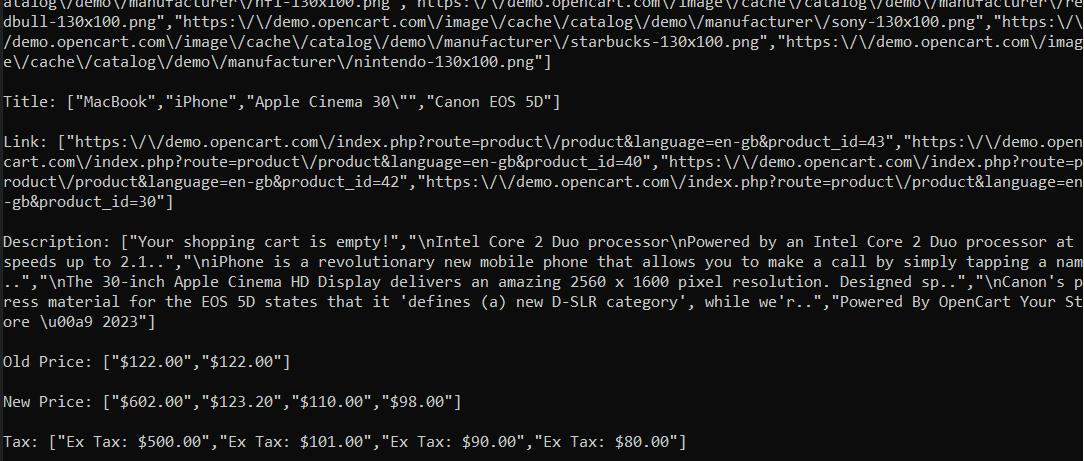
Mit unserer Web-Scraping-API können Sie Ergebnisse von jeder Website erhalten, unabhängig davon, ob diese in Ihrem Land zugänglich ist oder der Inhalt dynamisch generiert wird.
Einfaches HTML-DOM
Die Simple HTML DOM-Bibliothek ist eine der einfachsten PHP DOM-Bibliotheken. Es eignet sich hervorragend für Anfänger, verfügt über eine vollständige Scraping-Bibliothek und ist sehr einfach zu bedienen.
Vor- und Nachteile der Bibliothek
Diese Bibliothek ist sehr einfach zu verwenden und eignet sich perfekt zum Scrapen einfacher Seiten. Sie können jedoch keine Daten von dynamisch generierten Seiten sammeln. Darüber hinaus ermöglicht diese Bibliothek nur die Verwendung von CSS-Selektoren und unterstützt kein XPath.
Anwendungsbeispiel
Sehen wir uns anhand eines Beispiels an, dass es sehr einfach zu bedienen ist. Verbinden Sie zunächst die Abhängigkeiten und geben Sie die Site an, von der wir die Daten extrahieren möchten.
require 'vendor/autoload.php';
use Sunra\PhpSimple\HtmlDomParser;
$html = HtmlDomParser::file_get_html('https://demo.opencart.com/');Finden Sie nun alle Produkte mit der Funktion find() und dem CSS-Selektor.
$elements = $html->find('.col');Lassen Sie uns nun alle gesammelten Elemente durchgehen und die Daten auswählen, die wir benötigen. Dabei müssen wir angeben, was wir extrahieren möchten. Wir müssen den Attributnamen angeben, wenn es sich um einen Attributwert handelt. Wenn wir den Textinhalt eines Tags extrahieren möchten, verwenden wir „Plaintext“. Lassen Sie uns den Text wie zuvor sofort auf dem Bildschirm anzeigen.
foreach ($elements as $element) {
$image = $element->find('img', 0)->src;
$title = $element->find('h4', 0)->plaintext;
$link = $element->find('h4 > a', 0)->href;
$desc = $element->find('p', 0)->plaintext;
$old_p_element = $element->find('span.price-old', 0);
$old_p = $old_p_element ? $old_p_element->plaintext : '-';
$new_p = $element->find('span.price-new', 0)->plaintext;
$tax = $element->find('span.price-tax', 0)->plaintext;
echo 'Image: ' . $image . "\n";
echo 'Title: ' . $title . "\n";
echo 'Link: ' . $link . "\n";
echo 'Description: ' . $desc . "\n";
echo 'Old Price: ' . $old_p . "\n";
echo 'New Price: ' . $new_p . "\n";
echo 'Tax: ' . $tax . "\n";
echo "\n";
}Danach müssen wir nur noch Ressourcen freigeben und das Skript beenden.
$html->clear();Vollständiger Code:
<?php
require 'vendor/autoload.php';
use Sunra\PhpSimple\HtmlDomParser;
$html = HtmlDomParser::file_get_html('https://demo.opencart.com/');
$elements = $html->find('.col');
foreach ($elements as $element) {
$image = $element->find('img', 0)->src;
$title = $element->find('h4', 0)->plaintext;
$link = $element->find('h4 > a', 0)->href;
$desc = $element->find('p', 0)->plaintext;
$old_p_element = $element->find('span.price-old', 0);
$old_p = $old_p_element ? $old_p_element->plaintext : '-';
$new_p = $element->find('span.price-new', 0)->plaintext;
$tax = $element->find('span.price-tax', 0)->plaintext;
echo 'Image: ' . $image . "\n";
echo 'Title: ' . $title . "\n";
echo 'Link: ' . $link . "\n";
echo 'Description: ' . $desc . "\n";
echo 'Old Price: ' . $old_p . "\n";
echo 'New Price: ' . $new_p . "\n";
echo 'Tax: ' . $tax . "\n";
echo "\n";
}
$html->clear();
?>Das Ergebnis sind dieselben Daten wie in den vorherigen Beispielen, jedoch in nur wenigen Codezeilen.
Selen
Wir haben oft in Sammlungen für andere Programmiersprachen wie Python, R, Ruby und C# über Selenium geschrieben. Wir möchten diese Bibliothek noch einmal besprechen, weil sie unglaublich praktisch ist. Es verfügt über eine gut geschriebene Dokumentation und eine aktive Community, die es unterstützt.
Vor- und Nachteile der Bibliothek
Diese Bibliothek hat viele Vorteile und nur wenige Nachteile. Es verfügt über hervorragende Community-Unterstützung, umfangreiche Dokumentation und ständige Weiterentwicklung und Verbesserung.
Mit Selenium können Sie Headless-Browser verwenden, um echtes Benutzerverhalten zu simulieren. Dies bedeutet, dass Sie das Risiko einer Erkennung beim Schaben verringern können. Darüber hinaus können Sie mit Elementen auf einer Webseite interagieren, beispielsweise Formulare ausfüllen oder auf Schaltflächen klicken.
Was die Nachteile betrifft, ist es in PHP nicht so beliebt wie NodeJS oder Python und kann für Anfänger eine Herausforderung darstellen.
Anwendungsbeispiel
Schauen wir uns nun ein Beispiel für die Verwendung von Selen an. Damit es funktioniert, benötigen wir einen Webtreiber. Wir werden den Chrome-Webtreiber verwenden. Stellen Sie sicher, dass es mit der auf Ihrem Computer installierten Chrome-Browserversion übereinstimmt. Entpacken Sie den Webtreiber auf Ihr Laufwerk C.
Sie können jeden beliebigen Web-Treiber verwenden. Sie können beispielsweise Mozilla Firefox oder einen anderen von Selenium unterstützten Browser wählen.
Fügen Sie zunächst die erforderlichen Abhängigkeiten zu unserem Projekt hinzu.
require 'vendor/autoload.php';
use Facebook\WebDriver\Remote\DesiredCapabilities;
use Facebook\WebDriver\Remote\RemoteWebDriver;
use Facebook\WebDriver\WebDriverBy;Geben wir nun die Parameter des Hosts an, auf dem unser Webtreiber läuft. Führen Sie dazu die Web-Treiberdatei aus und prüfen Sie, auf welchem Port sie startet.
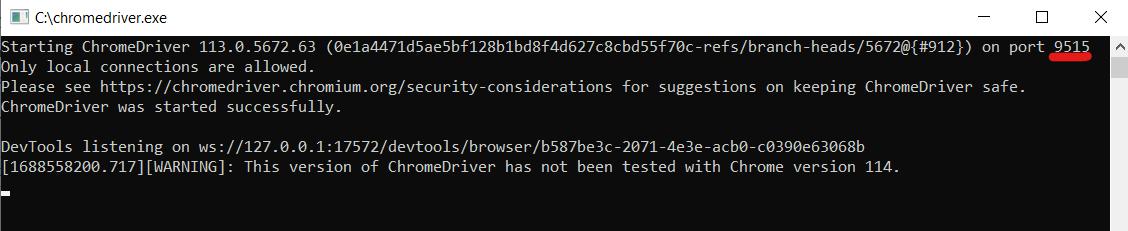
Geben Sie diese Parameter im Skript an:
$host="http://localhost:9515"; Als nächstes müssen wir einen Browser starten und zur Zielressource gehen.
$capabilities = DesiredCapabilities::chrome();
$driver = RemoteWebDriver::create($host, $capabilities);
$driver->get('https://demo.opencart.com/');Jetzt müssen wir die Produkte auf der Webseite finden, sie durchgehen und die gewünschten Daten erhalten. Danach sollten wir die Daten auf dem Bildschirm anzeigen. Da wir dies bereits in den vorherigen Beispielen getan haben, gehen wir nicht näher auf diesen Schritt ein.
$elements = $driver->findElements(WebDriverBy::cssSelector('.col'));
foreach ($elements as $element) {
$image = $element->findElement(WebDriverBy::tagName('img'))->getAttribute('src');
$title = $element->findElement(WebDriverBy::tagName('h4'))->getText();
$link = $element->findElement(WebDriverBy::cssSelector('h4 > a'))->getAttribute('href');
$desc = $element->findElement(WebDriverBy::tagName('p'))->getText();
$old_p_element = $element->findElement(WebDriverBy::cssSelector('span.price-old'));
$old_p = $old_p_element ? $old_p_element->getText() : '-';
$new_p = $element->findElement(WebDriverBy::cssSelector('span.price-new'))->getText();
$tax = $element->findElement(WebDriverBy::cssSelector('span.price-tax'))->getText();
echo 'Image: ' . $image . "\n";
echo 'Title: ' . $title . "\n";
echo 'Link: ' . $link . "\n";
echo 'Description: ' . $desc . "\n";
echo 'Old Price: ' . $old_p . "\n";
echo 'New Price: ' . $new_p . "\n";
echo 'Tax: ' . $tax . "\n";
echo "\n";
}Selenium bietet viele Möglichkeiten, verschiedene Elemente auf einer Seite zu finden. In diesem Tutorial haben wir die CSS-Selektorsuche und die Tag-Suche verwendet.
Am Ende sollten Sie den Browser schließen.
$driver->quit();Wenn wir das Skript ausführen, startet es den Browser, navigiert zur Seite und schließt sie nach der Datenerfassung.
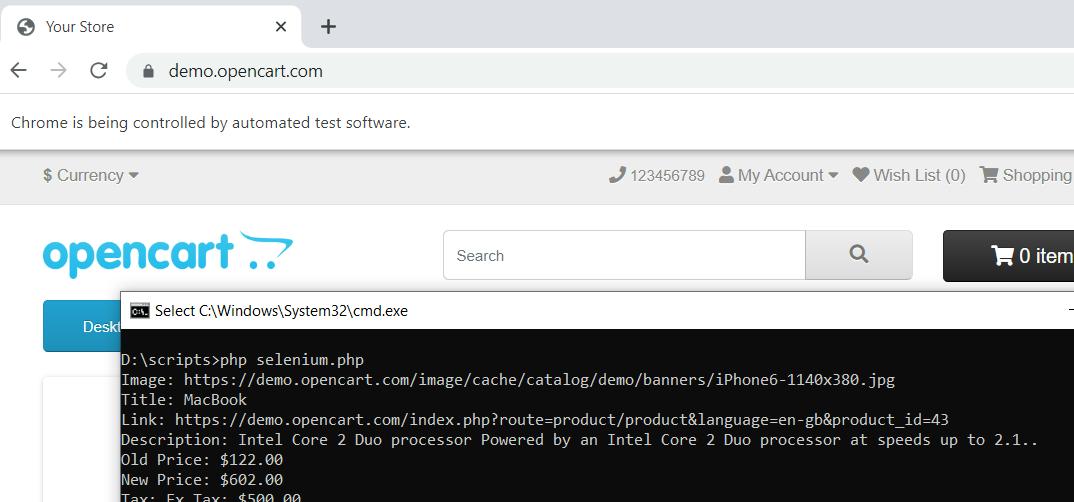
Wenn Sie verwirrt sind und etwas verpassen, finden Sie hier den vollständigen Skriptcode:
<?php
require 'vendor/autoload.php';
use Facebook\WebDriver\Remote\DesiredCapabilities;
use Facebook\WebDriver\Remote\RemoteWebDriver;
use Facebook\WebDriver\WebDriverBy;
$host="http://localhost:9515";
$capabilities = DesiredCapabilities::chrome();
$driver = RemoteWebDriver::create($host, $capabilities);
$driver->get('https://demo.opencart.com/');
$elements = $driver->findElements(WebDriverBy::cssSelector('.col'));
foreach ($elements as $element) {
$image = $element->findElement(WebDriverBy::tagName('img'))->getAttribute('src');
$title = $element->findElement(WebDriverBy::tagName('h4'))->getText();
$link = $element->findElement(WebDriverBy::cssSelector('h4 > a'))->getAttribute('href');
$desc = $element->findElement(WebDriverBy::tagName('p'))->getText();
$old_p_element = $element->findElement(WebDriverBy::cssSelector('span.price-old'));
$old_p = $old_p_element ? $old_p_element->getText() : '-';
$new_p = $element->findElement(WebDriverBy::cssSelector('span.price-new'))->getText();
$tax = $element->findElement(WebDriverBy::cssSelector('span.price-tax'))->getText();
echo 'Image: ' . $image . "\n";
echo 'Title: ' . $title . "\n";
echo 'Link: ' . $link . "\n";
echo 'Description: ' . $desc . "\n";
echo 'Old Price: ' . $old_p . "\n";
echo 'New Price: ' . $new_p . "\n";
echo 'Tax: ' . $tax . "\n";
echo "\n";
}
$driver->quit();
?>Wie Sie sehen, ist Selenium in PHP recht praktisch, aber etwas komplizierter als andere Bibliotheken.
Abfragepfad
QueryPath ist eine Bibliothek zum Extrahieren von Daten aus einer HTML-Seite, zum Filtern und Verarbeiten von Elementen.
Vor- und Nachteile der Bibliothek
Die QueryPath-Bibliothek ist sehr einfach zu verwenden und daher eine gute Option für Anfänger. Es unterstützt auch eine jQuery-ähnliche Syntax für die HTML/XML-Analyse und -Verarbeitung. Im Vergleich zu einigen anderen Bibliotheken verfügt sie jedoch über eine eingeschränkte Funktionalität.
Anwendungsbeispiel
Sie verfügt über ähnliche Suchbefehle wie die zuvor besprochenen Bibliotheken. Dank der Einfachheit müssen wir lediglich eine Anfrage an die Website stellen und die empfangenen Daten verarbeiten. Daher werden wir die bereits behandelten Schritte nicht wiederholen und ein vollständiges Beispiel für die Verwendung der Bibliothek bereitstellen:
<?php
require 'vendor/autoload.php';
use QueryPath\Query;
$html = file_get_contents('https://demo.opencart.com/');
$qp = Query::withHTML($html);
$elements = $qp->find('.col');
foreach ($elements as $element) {
$image = $element->find('img')->attr('src');
$title = $element->find('h4')->text();
$link = $element->find('h4 > a')->attr('href');
$desc = $element->find('p')->text();
$old_p_element = $element->find('span.price-old')->get(0);
$old_p = $old_p_element ? $old_p_element->text() : '-';
$new_p = $element->find('span.price-new')->text();
$tax = $element->find('span.price-tax')->text();
echo 'Image: ' . $image . "\n";
echo 'Title: ' . $title . "\n";
echo 'Link: ' . $link . "\n";
echo 'Description: ' . $desc . "\n";
echo 'Old Price: ' . $old_p . "\n";
echo 'New Price: ' . $new_p . "\n";
echo 'Tax: ' . $tax . "\n";
echo "\n";
}
$qp->unload();
?>Wie Sie sehen, gibt es also nur geringe Unterschiede zu den bereits besprochenen Bibliotheken.
Abfrageliste
Als nächstes steht auf unserer Liste die QueryList-Bibliothek. Sie verfügt über mehr Funktionalität als die vorherige Bibliothek. Wir können auch sagen, dass sich die Prinzipien seiner Verwendung geringfügig von den bereits besprochenen Bibliotheken unterscheiden.
Vor- und Nachteile der Bibliothek
QueryList ist ein leistungsstarkes und flexibles Tool zum Extrahieren und Verarbeiten von Daten aus HTML/XML. Allerdings kann es für Anfänger aufgrund der vielen Funktionen und Features kompliziert sein.
Anwendungsbeispiel
Verbinden Sie zunächst die Abhängigkeiten und fragen Sie die Zielsite ab.
require 'vendor/autoload.php';
use QL\QueryList;
$html = QueryList::get('https://demo.opencart.com/')->getHtml();Analysieren Sie dann den HTML-Code der Seite.
$ql = QueryList::html($html);Lassen Sie uns alle Daten verarbeiten, die wir haben, um die gewünschten Informationen zu extrahieren. Anschließend erstellen wir einen Datenrahmen und speichern die Daten darin.
$elements = $ql->find('.col')->map(function ($item) {
$image = $item->find('img')->attr('src');
$title = $item->find('h4')->text();
$link = $item->find('h4 > a')->attr('href');
$desc = $item->find('p')->text();
$old_p = $item->find('span.price-old')->text() ?: '-';
$new_p = $item->find('span.price-new')->text();
$tax = $item->find('span.price-tax')->text();
return (
'Image' => $image,
'Title' => $title,
'Link' => $link,
'Description' => $desc,
'Old Price' => $old_p,
'New Price' => $new_p,
'Tax' => $tax
);
});Gehen wir nun jedes Element durch und drucken es auf dem Display aus:
foreach ($elements as $element) {
foreach ($element as $key => $value) {
echo $key . ': ' . $value . "\n";
}
echo "\n";
}Das war's, wir haben die Daten, die wir brauchen, und wenn Sie etwas verpasst haben, geben wir Ihnen den vollständigen Code:
<?php
require 'vendor/autoload.php';
use QL\QueryList;
$html = QueryList::get('https://demo.opencart.com/')->getHtml();
$ql = QueryList::html($html);
$elements = $ql->find('.col')->map(function ($item) {
$image = $item->find('img')->attr('src');
$title = $item->find('h4')->text();
$link = $item->find('h4 > a')->attr('href');
$desc = $item->find('p')->text();
$old_p = $item->find('span.price-old')->text() ?: '-';
$new_p = $item->find('span.price-new')->text();
$tax = $item->find('span.price-tax')->text();
return (
'Image' => $image,
'Title' => $title,
'Link' => $link,
'Description' => $desc,
'Old Price' => $old_p,
'New Price' => $new_p,
'Tax' => $tax
);
});
foreach ($elements as $element) {
foreach ($element as $key => $value) {
echo $key . ': ' . $value . "\n";
}
echo "\n";
}
?>Diese Bibliothek verfügt über viele Features und einen umfangreichen Funktionsumfang. Für Anfänger kann es jedoch eine ziemliche Herausforderung sein, sich darin zurechtzufinden.
DiDOM
Die letzte Bibliothek in unserem Artikel ist DiDom. Es eignet sich hervorragend zum Extrahieren von Daten aus einem HTML-Code und zum Konvertieren in eine verwendbare Ansicht.
Vor- und Nachteile der Bibliothek
DiDom ist eine leichtgewichtige Bibliothek mit einfachen und klaren Funktionen. Es hat auch eine gute Leistung. Leider ist sie weniger beliebt und hat eine kleinere Support-Community als andere Bibliotheken.
Anwendungsbeispiel
Verbinden Sie die Abhängigkeiten und stellen Sie eine Anfrage an die Zielsite:
require 'vendor/autoload.php';
use DiDom\Document;
$document = new Document('https://demo.opencart.com/', true);Finden Sie alle Produkte mit der Klasse „.col“:
$elements = $document->find('.col');Gehen wir jeden einzelnen durch, sammeln die Daten und zeigen sie auf dem Bildschirm an:
foreach ($elements as $element) {
$image = $element->find('img', 0)->getAttribute('src');
$title = $element->find('h4', 0)->text();
$link = $element->find('h4 > a', 0)->getAttribute('href');
$desc = $element->find('p', 0)->text();
$old_p_element = $element->find('span.price-old', 0);
$old_p = $old_p_element ? $old_p_element->text() : '-';
$new_p = $element->find('span.price-new', 0)->text();
$tax = $element->find('span.price-tax', 0)->text();
echo 'Image: ' . $image . "\n";
echo 'Title: ' . $title . "\n";
echo 'Link: ' . $link . "\n";
echo 'Description: ' . $desc . "\n";
echo 'Old Price: ' . $old_p . "\n";
echo 'New Price: ' . $new_p . "\n";
echo 'Tax: ' . $tax . "\n";
echo "\n";
}An diesem Punkt ist das Skript fertig und Sie können die Daten nach Ihren Wünschen verarbeiten. Außerdem fügen wir ein vollständiges Codebeispiel bei:
<?php
require 'vendor/autoload.php';
use DiDom\Document;
$document = new Document('https://demo.opencart.com/', true);
$elements = $document->find('.col');
foreach ($elements as $element) {
$image = $element->find('img', 0)->getAttribute('src');
$title = $element->find('h4', 0)->text();
$link = $element->find('h4 > a', 0)->getAttribute('href');
$desc = $element->find('p', 0)->text();
$old_p_element = $element->find('span.price-old', 0);
$old_p = $old_p_element ? $old_p_element->text() : '-';
$new_p = $element->find('span.price-new', 0)->text();
$tax = $element->find('span.price-tax', 0)->text();
echo 'Image: ' . $image . "\n";
echo 'Title: ' . $title . "\n";
echo 'Link: ' . $link . "\n";
echo 'Description: ' . $desc . "\n";
echo 'Old Price: ' . $old_p . "\n";
echo 'New Price: ' . $new_p . "\n";
echo 'Tax: ' . $tax . "\n";
echo "\n";
}
?>Damit ist unsere Sammlung der besten PHP-Scraping-Bibliotheken abgeschlossen. Es ist an der Zeit, aus allen bewerteten Bibliotheken die beste auszuwählen.
Die beste PHP-Bibliothek für Scraping
Die Wahl der besten Web-Scraping-PHP-Bibliothek hängt von mehreren Faktoren ab: Projektzielen, Anforderungen und Ihren Programmierkenntnissen. Um Ihnen bei der Entscheidung zu helfen, haben wir die wichtigsten im Artikel besprochenen Informationen zusammengestellt und eine Vergleichstabelle der 10 besten Scraping-Bibliotheken erstellt.
|
Bibliothek |
Vorteile |
Nachteile |
Scraping dynamischer Daten |
Benutzerfreundlichkeit |
|---|---|---|---|---|
|
Fressen |
|
|
NEIN |
Dazwischenliegend |
|
HTTPful |
|
|
NEIN |
Anfänger |
|
Symfony |
|
|
Ja |
Fortschrittlich |
|
Goutte |
|
|
NEIN |
Anfänger |
|
Scrape-It.Cloud |
|
Ja |
Anfänger |
|
|
Einfaches HTML-DOM |
|
|
NEIN |
Anfänger |
|
Selen |
|
|
Ja |
Dazwischenliegend |
|
Abfragepfad |
|
|
NEIN |
Dazwischenliegend |
|
Abfrageliste |
|
|
Ja |
Dazwischenliegend |
|
DiDom |
|
|
NEIN |
Anfänger |
Dies wird Ihnen helfen, die beste PHP-Scraping-Bibliothek zu finden, mit der Sie Ihre Ziele erreichen können.
Fazit und Erkenntnisse
In diesem Artikel haben wir uns mit der Einrichtung einer PHP-Programmierumgebung befasst und die Möglichkeiten zur Automatisierung der Bibliotheksintegration und -aktualisierung untersucht. Wir haben außerdem die 10 besten Web-Scraping-Bibliotheken vorgestellt, um Ihnen verschiedene Optionen für Ihre Scraping-Projekte zu bieten.
Wenn Sie jedoch Schwierigkeiten haben, die beste Bibliothek auszuwählen, haben wir alle von uns in Betracht gezogenen Bibliotheken verglichen. Wenn Sie jedoch immer noch nicht wissen, was Sie wählen sollen, können Sie unsere Web-Scraping-API ausprobieren. Dies vereinfacht nicht nur den Datenerfassungsprozess, sondern hilft auch bei der Bewältigung potenzieller Herausforderungen. Mit seinen Funktionen können Sie Datenerfassungsaufgaben automatisieren und alle Schwierigkeiten überwinden.
