
Erfahren Sie, wie Sie mit Python eine Daten-QA durchführen können. Die Datenveredelung bereitet Datenwissenschaftlern und Datenanalysten große Kopfschmerzen. Wie wir immer wieder erwähnt haben, verbringen die meisten Datenexperten 50 bis 80 Prozent ihrer Zeit damit, Daten zu verfeinern. Um diese Hürde zu überwinden, verfügen wir über verschiedene Systeme, um die höchste Qualität Ihrer Daten sicherzustellen.
In einem unserer früheren Artikel haben wir gelernt, wie man mit Python Daten aus dem Web extrahiert. Aus den vielen Erkenntnissen, die wir gewonnen haben, war die wichtigste Erkenntnis, dass der Umgang mit großen Datenmengen nie ein einfacher Prozess ist.
In den meisten Fällen verwenden wir die Daten nicht, sobald der Crawler mit dem Extrahieren der Daten fertig ist.
Wir müssen uns mit mehreren Komplexitäten befassen, bevor die Daten zur Bereitstellung bereit sind. Um die Integrität eines Datensatzes ordnungsgemäß zu überprüfen, kommen verschiedene Qualitätssicherungstechniken ins Spiel.
In diesem Artikel werden wir uns einige pythonische Möglichkeiten ansehen, um die überlegene Qualität eines Datensatzes sicherzustellen und die mit Ihren geschäftlichen Anwendungsfällen verbundenen Bedenken auszuräumen.
Warum Python für Ihre Datenqualitätssicherung verwenden?
Python ist eine universelle Programmiersprache, die sehr intuitiv zu verwenden ist. Es verfügt über eine umfangreiche Community und mehrere Bibliotheken, darunter, aber nicht beschränkt auf: Pandas, scikit-learnUnd pyspark.
Diese Bibliotheken können nahezu alle Ihre Anforderungen an die Datenanalyse und -bearbeitung erfüllen. Um genauer zu sein, pyspark stellt eine API für bereit Apache Spark das eine groß angelegte Datenverarbeitung in Echtzeit ermöglicht.
Daher ist Python die optimale Wahl für die Datenverarbeitung und -validierung. Zum besseren Verständnis verwenden wir pandas für den Rest dieses Blogs.
Daten-QA-Black-Box-Tests mit Python
Black Box im Allgemeinen ist eine Methode zum Testen von Software, die die Funktionalität einer Anwendung untersucht, ohne einen Blick auf ihre internen Strukturen oder Funktionsweisen zu werfen.
Inspiriert von dieser überaus erfolgreichen Methode zum Testen von Software haben wir eine eigene Black Box geschaffen, sozusagen eine Data QA Black Box.
Bei Grepsr ist es der Ausgangspunkt aller unserer Qualitätssicherungsprozesse. Wir verwenden es für automatische Tests, um Auffälligkeiten in einem Datensatz zu kennzeichnen.
Das QA-Team leitet jedes einzelne Datenprojekt durch die Black Box. Basierend auf voreingestellten statistischen und logischen Prozessen liefert es einen Musterbericht. Mithilfe des Beispielberichts ziehen wir aussagekräftige Erkenntnisse und nehmen die notwendigen Änderungen vor.
Da es nicht plausibel ist, die Datenintegrität mit denselben Prozessen zu verallgemeinern, passen wir die Black Box häufig an die Anforderungen an. Sie sind herzlich eingeladen, Ihre Bedenken mitzuteilen. Wir können die Skripte der Black Box entsprechend Ihren Vorschlägen aktualisieren.
Dies ermöglicht es dem QA-Team zweifellos, die Anomalien eines Datensatzes zu beheben und Möglichkeiten zu finden, diese zu beheben.
Von hier an ist die test_dataset.csv wird der Hauptdatensatz sein, an dem wir arbeiten werden. Beginnen wir mit dem Laden in die pandas.DataFrame.
import pandas as pd
import chardet
import re
import numpy as np
with open("./test_dataset.csv", "rb") as f:
enc = chardet.detect(f.read())
df = pd.read_csv("./test_dataset.csv", encoding= enc("encoding"))
df.dropna(how="all",axis=0,inplace=True)Das Wichtigste zuerst: Sie erhalten die Daten in der von Ihnen bevorzugten Kodierung. Wir haben ein eigenes Skript, um auf solche Bedenken einzugehen.
Anforderungsanalyse für Ihr Daten-QA-Projekt mit Python
Der erste Schritt im QA-Prozess besteht darin, zu prüfen, ob der Datensatz Ihren Anforderungen entspricht. Sehen wir uns einige Anwendungsfälle an:
1. Vergleich der Eingabelisten
In vielen Anwendungsfällen, auf die wir stoßen, erwarten unsere Kunden, dass wir die Produkte mit bestimmten SKUs crawlen. Um die Anforderungen zu erfüllen, gleichen wir die eingehenden SKUs mit der vordefinierten Liste der SKUs ab.
Mal sehen, ob die SKUs identisch sind:
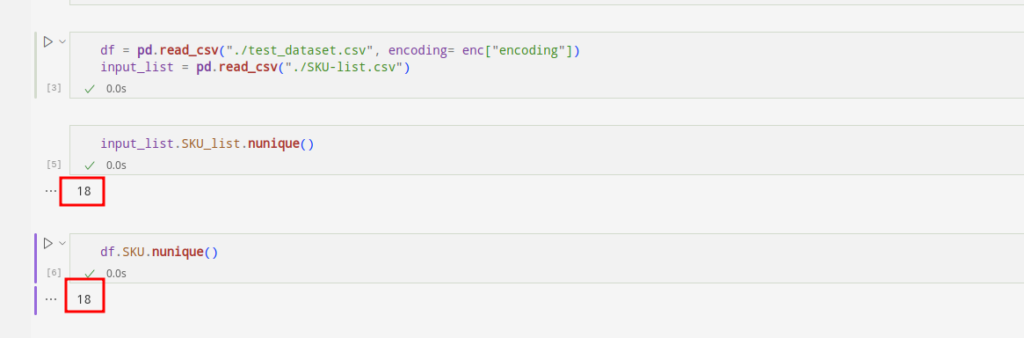
df(~df.SKU.isin(input_list.SKU_list.unique().tolist())).loc(:,"SKU").unique().tolist()input_list(~input_list.SKU_list.isin(df.SKU.unique().tolist())).loc(:,"SKU_list").unique().tolist()
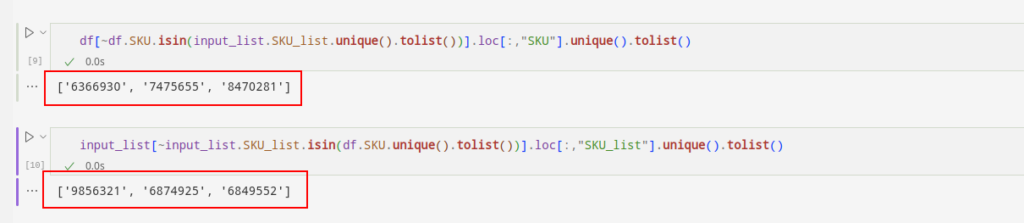
Wir können sehen, dass die erste Liste der SKUs die fehlenden SKUs anzeigt. Die fehlenden sind im Eingabeblatt vorhanden, aber nicht im Datensatz. Die zweite Liste der SKUs zeigt ein gegenteiliges Dilemma.
Auf diese Weise können wir die fehlenden SKUs ermitteln und sie dem von Ihnen benötigten Originaldatensatz hinzufügen.
2. Befolgen Sie die Regel
Wenn es in Ihrem Datensatz eine Spalte gibt, für die wir Regeln definieren können, implementieren wir diese Regeln in unserem Skript. Durch die Ausführung dieser Skripte können wir die Integrität Ihres Datensatzes sicherstellen.
Nehmen wir an, Sie ziehen product_code von einer E-Commerce-Website, die eine Kombination aus einem Alphabet und vier Zahlen enthält. Durch die Implementierung eines Skripts können wir Produkte kennzeichnen, die nicht den Regeln entsprechen.

Die oben hervorgehobenen Abschnitte sind die Anomalien in unserem Datensatz. Sie halten sich nicht an die Regeln. In diesem speziellen Fall ist der Datensatz klein, sodass wir die Anomalien ohne großen Aufwand lokalisieren können. Aber je größer die Datensätze sind, desto komplizierter wird auch die Komplexität. Es wird schwieriger sein, die Kuriositäten herauszufiltern, wie wir es hier getan haben.
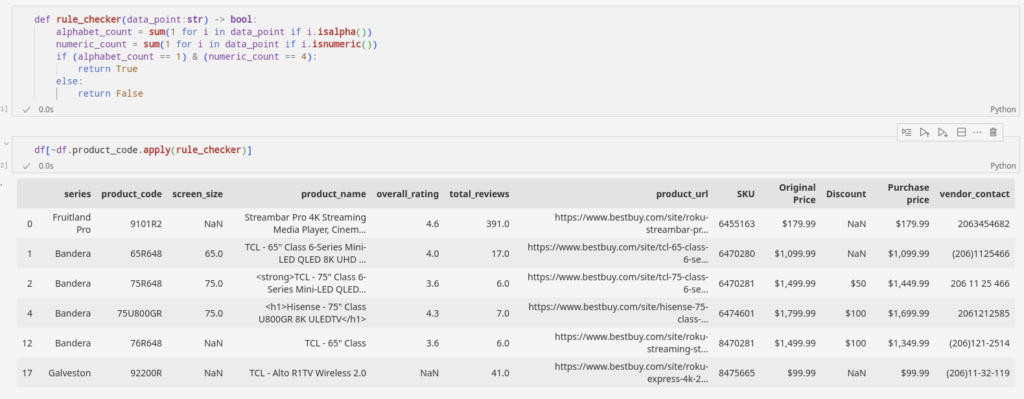
def rule_checker(data_point:str) -> bool:
alphabet_count = sum(1 for i in data_point if i.isalpha())
numeric_count = sum(1 for i in data_point if i.isnumeric())
if (alphabet_count == 1) & (numeric_count == 4):
return True
else:
return False
df(~df.product_code.apply(rule_checker))Dieses praktische Tool in Python kann uns die schwere Arbeit abnehmen. Wir können entweder die Merkwürdigkeiten aus dem Datensatz herausfiltern oder den Crawler aktualisieren, um solche Probleme zu beheben.
Kennzeichnung von Anomalien im Datensatz für die Qualitätssicherung
Der nächste Schritt besteht nun darin, die wahrscheinlichen Unregelmäßigkeiten in unserem Datensatz zu lokalisieren. Unregelmäßigkeiten sind hier diejenigen Datenpunkte, die nicht der Logik unserer Datenpunkte entsprechen. Gehen wir die folgenden Beispiele durch, um die Inkonsistenzen, die in einem Datensatz auftreten können, vollständig zu verstehen:
1. Fehlende Datenfelder
Es ist sehr wahrscheinlich, dass beim ersten Extrahieren von Daten leere Datenfelder empfangen werden. Für das QA-Team ist es jetzt an der Zeit, seinen Dienst anzutreten.
Nachdem wir einen Beispieldatensatz, den die Black Box erstellt hat, durch eine umfassende statistische Analyse analysiert haben, machen wir uns an die Arbeit.
Der Beispieldatensatz berücksichtigt alle fehlenden Felder im Datensatz. Darauf aufbauend validieren wir die fehlenden Punkte manuell. Aber das ist nicht alles. Wir können die Skripte an bestimmte Fälle anpassen, indem wir Prioritäten für die Spalten festlegen, die für Sie wichtig sind.
Sie können beispielsweise kein Leerzeichen haben product_name Daten in einem E-Commerce-Datensatz. Daher greifen wir auf den Beispielbericht zurück, um die fehlenden Variablen zu finden.
Hier ist ein einfacher Python-Code, der Auffälligkeiten herausfiltert. Es ermöglicht uns, die fehlenden Werte im Datensatz zu unterstellen. Auf die Einzelheiten gehen wir später im Abschnitt „Nachbearbeitung“ ein.

2. Logikprüfung
Ein weiterer Knoten, der uns mit der Black Box entwirrt, ist die logische Überprüfung der Spalten in unserem Datensatz. Zum besseren Verständnis betrachten wir das Feld „Telefonnummer“.
Für dieses Datenfeld gelten feste Regeln hinsichtlich des Ländercodes und der numerischen Anzahl. Beispielsweise bestehen US-Telefonnummern aus zehnstelligen Zahlen und der Ortsvorwahl. Immer wenn wir Spalten mit Telefonnummern und Ländern finden, ziehen wir Informationen aus der Metadatendatenbank und wenden die Logik entsprechend an.
Nehmen wir an, wir stellen anhand der verfügbaren Vorwahl und nach einem kurzen Blick in die Metadaten fest, dass die phone_numerical_count ist 10. Wenn wir mit diesen Informationen fortfahren, können wir Datenpunkte trennen, die dieser Regel nicht entsprechen.

phone_numeral_count = 10
df(df.vendor_contact.apply(lambda x: True if sum(1 for i in x if i.isnumeric())!=phone_numeral_count else False))
Dies war eine einfache Darstellung, wie wir Beispiele basierend auf der Feldlogik erstellt haben, die wir im Skript eingerichtet haben. Es gibt viele statistische und logische Operationen, die in die Black Box geschrieben werden, um eine umfassende Anomaliestichprobe zu erstellen.
Nachbearbeitung der Datenqualitätssicherung
Datenpunkte, die wir aus Webquellen beziehen, sind nicht immer ohne weiteres nutzbar. Einige eingebettete Anomalien können die Integrität des Datensatzes beeinträchtigen und die Entscheidungsfindung verlangsamen.
Durch die Nachbearbeitung der Datenqualitätssicherung können wir nicht nur eine hohe Datenqualität aufrechterhalten, sondern auch eine schnellere Bereitstellung der Datenprojekte gewährleisten. Dies erreichen wir, indem wir die TAT (Turn Around Time) deutlich reduzieren.
Sehen wir uns einige Nachbearbeitungstechniken an, mit denen sich unsere Qualitätsexperten häufig beschäftigen.
1. HTML-Tags im Textfeld
Wir schicken die Rohdaten, die wir aus dem Internet sammeln, oft durch verschiedene Verarbeitungsstufen. Wenn die Rohdaten direkt über eine API zugänglich gemacht werden, können wir davon ausgehen, dass sie keine HTML-Tags enthalten. Die Situation ist jedoch völlig anders, wenn wir die Daten durch Parsen von HTML-Dokumenten extrahieren.
Unter solchen Umständen stellt das Vorhandensein von HTML-Tags im Datensatz ein großes Problem dar. Eine weitere Analyse kann durch den in die HTML-Tags eingebetteten Inhalt erschwert werden.
Aber keine Sorge. Sie können reguläre Ausdrücke in das Feld implementieren, um den Datensatz zu retten. Unten finden Sie einen Ausschnitt des Python-Codes, um die HTML-Tags aus Ihren Datenpunkten zu entfernen:
def remove_tags(raw_text):
CLEANR = re.compile('<.*?>')
cleantext = re.sub(CLEANR, '', str(raw_text))
return cleantext
Der Beispieldatensatz berücksichtigt im HTML-Tag eingebettete Daten:

Wir wenden das an remove_tags Funktion für die Spalten, die die Anomalie enthalten. Dadurch werden die HTML-Tags entfernt und als Ergebnis saubere Daten erzeugt.
Hier wenden wir diese Funktion auf an product_name Spalte, um die HTML-Tags in jedem Fall zu entfernen:
df.product_name = df.product_name.apply(lambda x : remove_tags(x) if pd.notna(x) else np.nan)Dadurch werden HTML-Tags aus allen Instanzen in der Spalte entfernt, sofern vorhanden.

Wir können sehr deutlich erkennen, dass der Produktname aus der zweiten Zeile frei vom HTML-Tag ist.
Ebenso können wir alle Zeichenfolgen, Zeichen und Zahlen aus dem Datenfeld entfernen, bei denen festgestellt wird, dass sie die Integrität des Datensatzes gefährden.
2. Imputation der leeren Felder
Der Löwenanteil der Datensätze liegt im kategorialen und numerischen Format vor. Wie wir oben besprochen haben, ist es oft unvermeidlich, leere Felder in einem Datensatz zu erhalten.
Wir unternehmen diesen besonderen Schritt, um die fehlenden Datenfelder zu validieren, wenn der Datenpunkt sogar auf der Quellwebsite fehlt.
Wenn Sie von uns verlangen, dass wir die fehlenden Datenfelder imputieren, damit der Datensatz einen Sinn ergibt, können wir entsprechend vorgehen.
Sie können beispielsweise das fehlende Feld in kategorialen Daten zuweisen, indem Sie Werte mithilfe des Moduswerts oder mithilfe des Regressionsansatzes zuweisen.
Für numerische Daten hingegen können Sie statistische Tools wie den Mittelwert, den Median und die lineare Regression verwenden.
Schauen wir uns das an overall_rating Spalte für diesen Fall. Ein negativer Wert im Feld kann den Imputationswert verzerren. Daher besteht der erste Schritt darin, sicherzustellen, dass das Feld negative Werte haben kann. Wir wissen, dass die Werte in diesem Fall nicht negativ sein können.
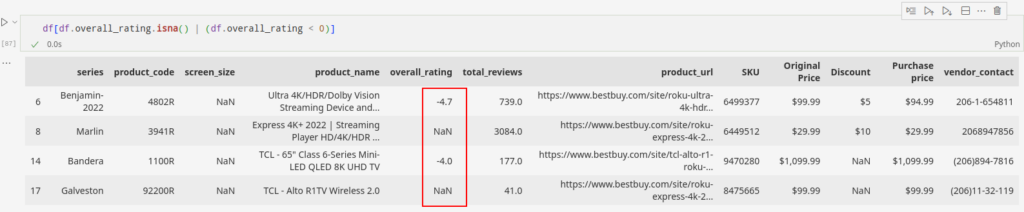
Die Daten enthalten sowohl negative als auch leere Werte overall_rating Feld. Lassen Sie uns die Indizes dieser Felder speichern und mit der Lösung fortfahren.
overall_rating_flagged_index = df(df.overall_rating.isna() | (df.overall_rating < 0)).indexDieser einfache Code unten stellt sicher, dass die overall_rating ist frei von jeglichen negativen Einträgen.
df.overall_rating = df.overall_rating.abs()Kommen wir nun zur Anrechnung. Tragen wir den Medianwert in die fehlenden Felder der Spalte ein.
df.overall_rating.fillna(df.overall_rating.median(), inplace=True)Nach der Anwendung dieser einfachen Technik können wir sehen, dass wir die Feldinformationen bestmöglich beibehalten haben.
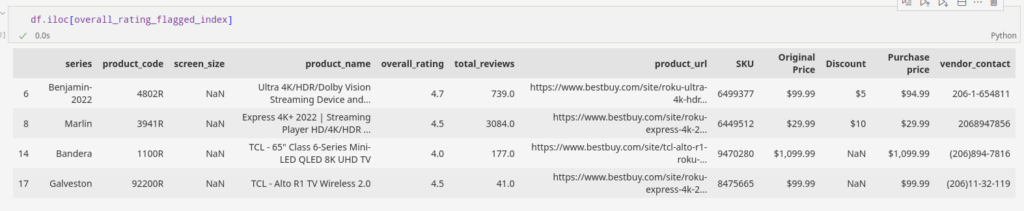
Wir können die fehlenden Datenfelder durch verschiedene univariate und multivariate Techniken imputieren. Davon abgesehen greifen wir meistens auf die Technik der Nächsten-Nachbarn-Imputation zurück.
3. Kreuzspaltenbeziehung
Wir finden häufig Datensätze mit zwei oder mehr Spalten, die auf der Grundlage von Feldlogiken miteinander in Beziehung stehen. Insbesondere gibt es in den angegebenen Beispieldaten solche Spalten, in denen das Attribut „Rabatt„ kann aus den Attributen „ abgeleitet werdenOriginal Preis“ Und „Kaufpreis„.
Alternativ können wir sagen, dass „KaufpreisDas Attribut wird von den Attributen abgeleitet.Original Preis“ Und „Rabatt„. Hier ist eine Teilmenge unseres Datensatzes, um die obige Beziehung zu demonstrieren.
df(('Original Price', 'Discount', 'Purchase price')).head(10)
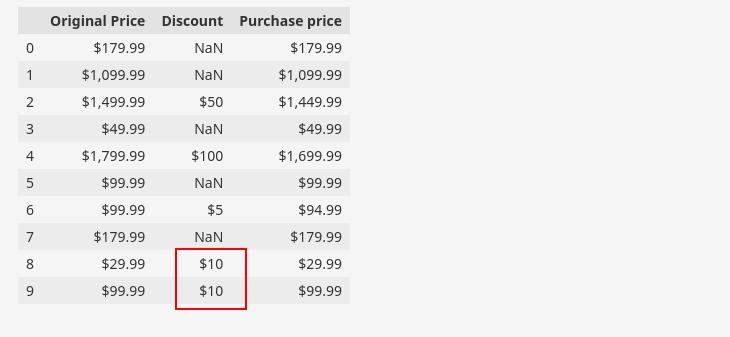
Wir können die Beziehung nutzen, um die Richtigkeit unserer Daten zu überprüfen. In der Abbildung haben wir eine ungültige Instanz hervorgehoben, was darauf hinweist, dass die Daten darauf hindeuten, dass entweder der Kaufpreis oder der Rabattpreis für diese bestimmte Zeile ungültig ist.
Verwendung von Python für die Datenqualitätssicherung
Wir können solche Zeilen mithilfe von Python-Code identifizieren, wie unten gezeigt:
df((df('Original Price') <= df('Purchase price')) &
df('Discount').notna())
Nachdem wir solche ungültigen Beziehungen im Internet durch unser manuelles Team überprüft haben, können wir feststellen, ob der Rabatt, der Kaufpreis oder der Originalpreis ungültig sind.
Sobald wir das spezifische Attribut identifiziert haben, das ungültig ist, können wir mit Nachbearbeitungsschritten fortfahren, um die Gültigkeit der Instanz sicherzustellen.
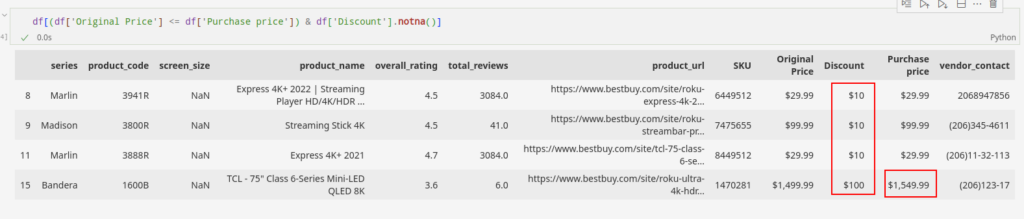
Die Nachbearbeitungsschritte umfassen das Finden der richtigen Daten und deren Imputation, um die ungültigen Werte zu ersetzen.
In unserem Beispieldatensatz führt das Vorhandensein des „$“-Zeichens in den nicht leeren Instanzen dazu, dass die Instanzen in den Spalten „Originalpreis“, „Rabatt“ und „Kaufpreis“ Zeichenfolgeninstanzen sind.
Um Berechnungen oder Vergleiche mit diesen Werten durchzuführen, muss die Zeichenfolge durch Entfernen des Währungssymbols in ein numerisches Format umgewandelt werden.
df('Original Price') = pd.to_numeric(df('Original Price').str.replace('(^d.)', '', regex=True), errors="coerce")
df('Discount') = pd.to_numeric(df('Discount').str.replace('(^d.)', '', regex=True), errors="coerce")
df('Purchase price') = pd.to_numeric(df('Purchase price').str.replace('(^d.)', '', regex=True), errors="coerce")
Nachdem die Preiswerte nun in Float umgewandelt wurden, können wir mit weiteren Berechnungen fortfahren. Aufgrund unserer manuellen Prüfung der Musterdaten halten wir den Rabatt und den Originalpreis für gültig. Daher können wir mit diesen Werten Berechnungen und Analysen durchführen.
Auf diese Weise können Sie den Index finden, für den die ungültige Zeile vorhanden ist.
index_=list(df((df('Original Price')<=df('Purchase price')) & df('Discount').notna()).index)

Jetzt ersetzen wir den ungültigen Kaufpreis durch den korrekten Preis, dh Kaufpreis = Originalpreis – Rabatt.
Der Python-Code für eine solche Operation lautet:
df.loc(index_,'Purchase price')=df.loc(index_,'Original Price') - df.loc(index_,'Discount')Wir können die Gültigkeit der aktualisierten Werte überprüfen, indem wir die Indizes der zuvor ungültigen Zeilen überprüfen.
df.loc(index_,('Original Price','Discount','Purchase price'))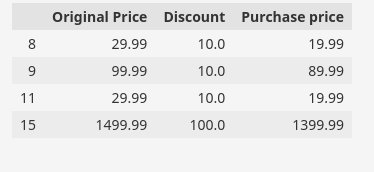
Agile Entwicklung im Bereich Daten-QA-Black-Box-Tests
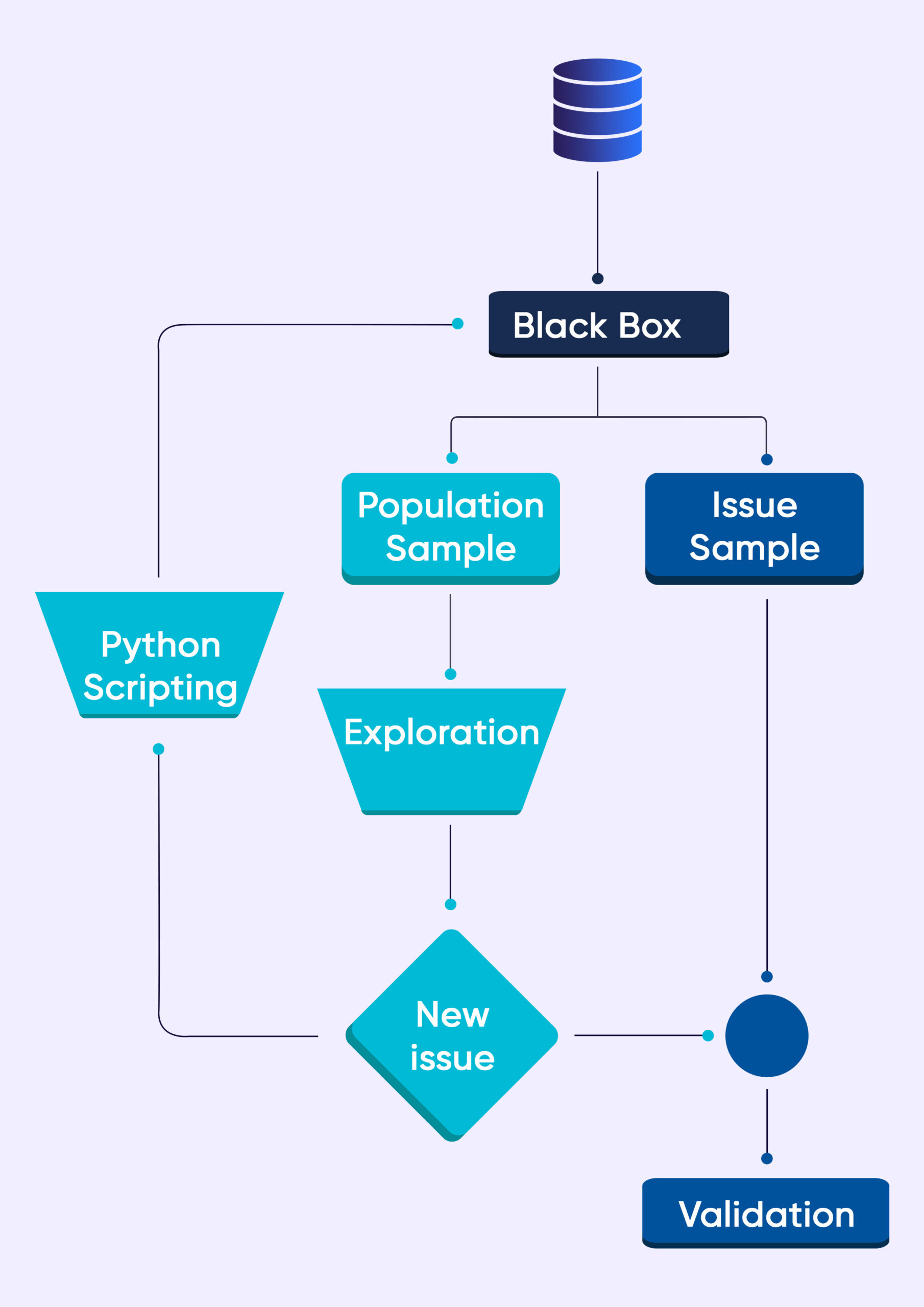
Wie alle anderen Prozesse in Grepsr erfolgt auch die Entwicklung der Data QA Black Box auf agile Weise.
Das obige Flussdiagramm zeigt eine einfache Vorgehensweise. Wenn wir die Daten in die Blackbox einspeisen, werden zwei Beispieldatensätze generiert.
Probe 1 ist das Ergebnis einer Zufallsstichprobe. Beispiel 2 besteht aus den Daten, die uns helfen, die Probleme zu überprüfen (dafür ist ein vordefiniertes Regelwerk bereits in der Black Box verantwortlich).
Unsere manuellen QA-Experten überprüfen die Bevölkerungsstichprobe. Wenn wir bisher unbekannte Probleme finden, schreiben unsere QA-Automatisierungsexperten neue Skripte (Problemerkennungsmechanismus), die in die Data QA Black Box eingespeist werden.
Umso besser, wenn wir im Beispieldatensatz keine Probleme entdecken. Unser QA-Team führt weitere Datenuntersuchungen und -manipulationen durch. In vielen Fällen geben wir unsere Erkenntnisse an Lieferingenieure weiter.
Anschließend verbessern die Ingenieure die Crawler, um Platz für die neue Entdeckung zu schaffen.
Der Data QA Black Box-Mechanismus arbeitet mit einem strengen Wahrscheinlichkeitsrahmen und prüft die aufgezeichneten Daten sorgfältig auf etwaige Ungleichheiten oder Anomalien. Wir nutzen fortschrittliche mathematische Techniken, um probabilistische Muster zu erkennen.
Auf diese Weise können wir eine präzise Qualitätssicherung großer Datenmengen durchführen und unsere TAT (Turn Around Time) radikal verbessern.
Schlussfolgern
In diesem Blog wird nur ein kleiner Teil der Prozesse und Tools erläutert, die wir zur Sicherstellung der Datenqualität verwenden.
Unser Black-Box-Testansatz, der von Python und seinen Bibliotheken unterstützt wird, ermöglicht es uns, komplexe Datenqualitätsprobleme effektiv zu lösen.
Wir können die Black Box-Skripte an Ihre spezifischen Anforderungen an die Datenqualität anpassen.
Unabhängig davon können Sie sich darauf verlassen, dass Grepsr Ihnen qualitativ hochwertige Daten liefert, die Ihren Geschäftszielen entsprechen.
Verwandte Lektüre:
