In diesem Tutorial zeigen wir Ihnen, wie Sie Proxys in cURL verwenden, damit Sie unabhängig von der Größenordnung die gewünschten Daten erhalten.
Was ist cURL?
cURL, ein Akronym für Client URL, ist ein Befehlszeilentool und eine Bibliothek zum Senden und Empfangen von Daten mit URLs. Es ermöglicht die Ausführung von Aufgaben wie das Senden von HTTP-Anfragen, das Herunterladen/Hochladen von Daten, die Interaktion mit APIs und die Erstellung von Automatisierungsskripten.
cURL unterstützt verschiedene Netzwerkprotokolle, darunter HTTP, HTTPS, FTP, FTPS, SCP, SFTP, LDAP, TELNET, IMAP, POP3, SMTP usw.
Es unterstützt außerdem viele Authentifizierungsmethoden wie Basic, Digest und OAuth für die Interaktion mit geschützten APIs.
Ingenieure verwenden es häufig zum Testen von APIs, indem sie Anfragen senden und Antworten direkt von der Befehlszeile aus überprüfen, was die Interaktion mit Webdiensten während der Entwicklung und beim Debuggen erleichtert.
Auf vielen Systemen ist cURL installiert, aber das ist nicht immer der Fall. Um sicherzustellen, dass Sie dieser Anleitung folgen können, beginnen wir mit dem grundlegenden ersten Schritt: der Installation von cURL.
cURL auf Ihrem Computer installieren
Installieren Sie cURL unter Windows
Standardmäßig wird Windows 10 und höher mit dem geliefert curl Befehl, aber es ist ein Alias für die PowerShell Invoke-WebRequest Befehl. Wenn Sie also den Befehl ausführen, wird eine Webanforderung aufgerufen, was nicht das ist, was wir wollen, da das von uns geschriebene Skript nicht interoperabel ist.
Um die Standard-cURL zu verwenden, müssen Sie sie manuell installieren, indem Sie die folgenden Schritte ausführen:
- Gehen Sie zu https://curl.se/windows; Sie sehen die neueste Version auf der Seite (8.6.0) und laden die 64-Bit-Version herunter.
- Gehen Sie zum Download-Ordner und suchen Sie die heruntergeladene ZIP-Datei mit dem Namen „curl-8.6.0_2-win64-mingw.zip”; Klicken Sie mit der rechten Maustaste auf die Datei und klicken Sie auf das Menü „Alle extrahieren“.
- Ein neuer Ordner namens „curl-8.6.0_2-win64-mingw” wird generiert; Die ausführbare cURL-Datei befindet sich im Ordner „bin“.
- Benennen Sie es um in „Locken” und verschieben Sie es auf die Festplatte C; Der Speicherort der cURL-Ausführungsdatei ist jetzt „C:\curl\bin\curl.exe”
- Fügen Sie den ausführbaren cURL-Pfad zur Systemumgebungsvariablen unter den Eigenschaften hinzu „Weg” und speichern Sie die Änderungen.
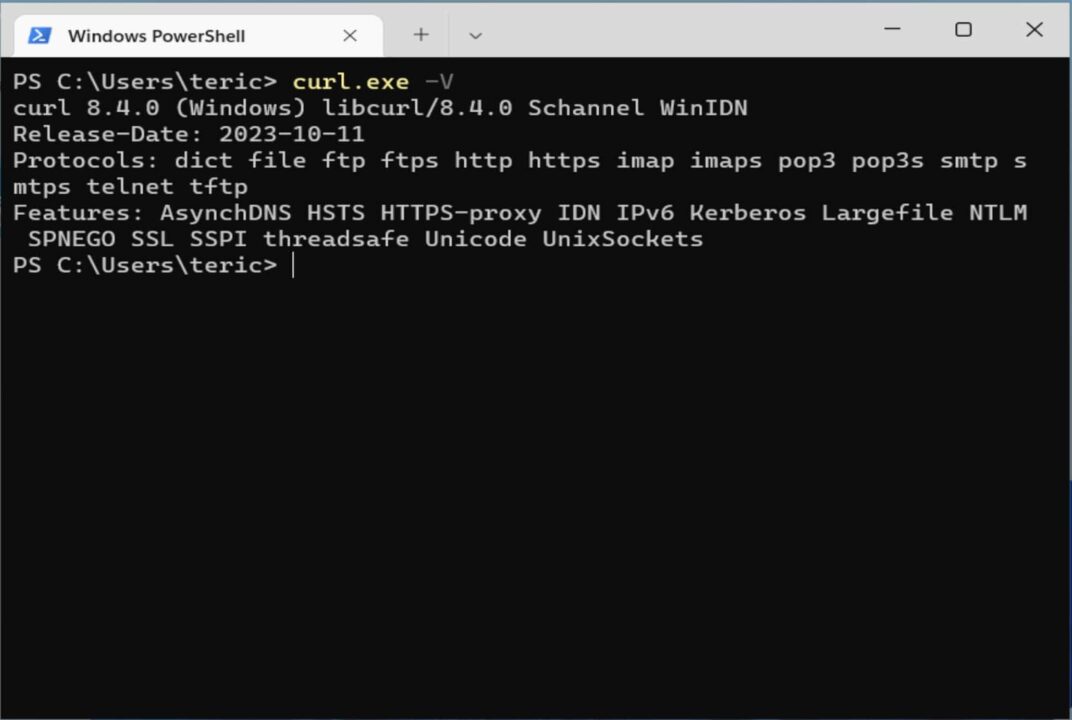
- Öffnen Sie Ihr Terminal und geben Sie ein
curl.exe -V
Installieren Sie cURL unter Linux
Die Installation hängt von der verwendeten Distribution ab. Auf Ubuntu und Fedora ist es bereits installiert.
Unter Debian müssen Sie den folgenden Befehl ausführen, um cURL zu installieren:
sudo apt update
sudo apt install curl
Unter CentOS müssen Sie das Quellpaket herunterladen und manuell erstellen.
Verwenden Sie denselben Befehl, curl -Vum sicherzustellen, dass es korrekt installiert ist.
Installieren Sie cURL unter MacOS
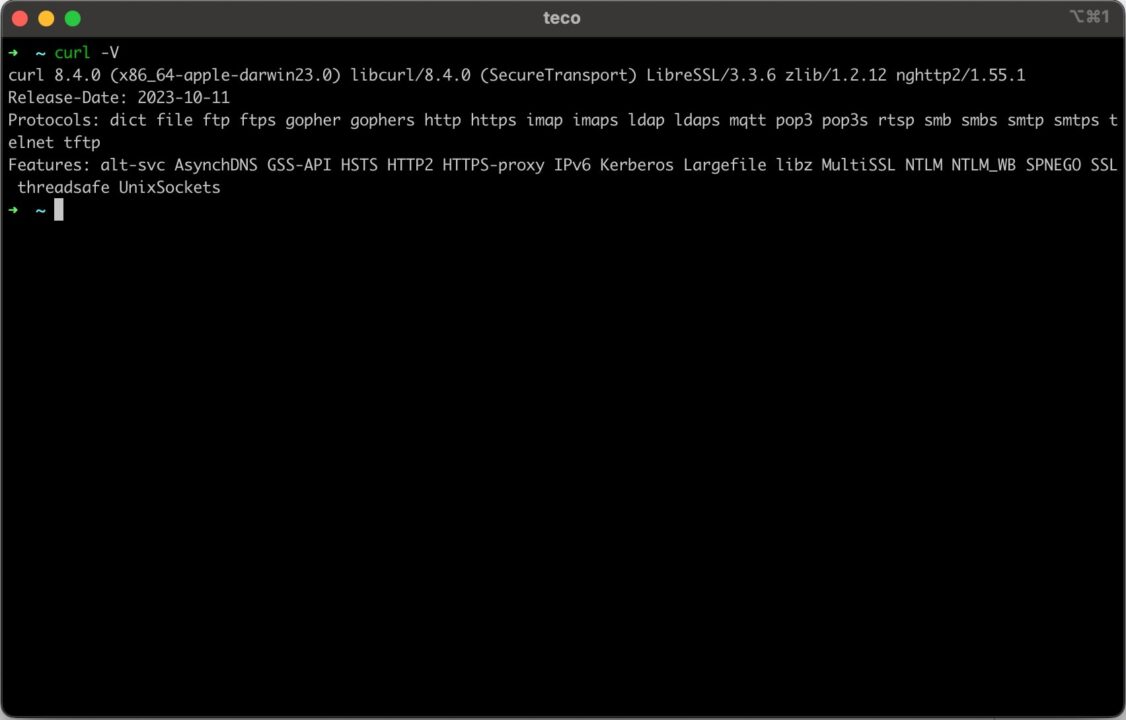
Sie müssen nichts tun, da auf MacOS cURL bereits installiert ist. Öffnen Sie Ihr Terminal und geben Sie ein curl -V
Nachdem cURL nun installiert ist, führen wir einen HTTP-Aufruf durch, um unsere IP-Adresse abzurufen.
Unter Linux und MacOS lautet der Befehl wie folgt.
curl http://httpbin.org/ip
Unter Windows lautet der Befehl wie folgt.
curl.exe http://httpbin.org/ip
Wie Sie sehen, müssen Sie die Erweiterung „.exe” zum Curl-Befehl unter Windows, aber die Argumente bleiben die gleichen wie unter Linux und MacOS.
Grundlegendes zur Proxy-URL-Syntax von cURL
Ein Proxy ist ein Vermittler zwischen einem Client, der eine Anfrage sendet, und dem Ziel eines Remote-Servers. Wenn der Client eine Anfrage sendet, fängt der Proxy diese ab und nimmt einige Änderungen an der ursprünglichen Anfrage vor, bevor er sie unter einer neuen Identität an das Ziel weiterleitet. Der Remote-Server kann nicht der Ursprung des Clients sein.
Die Verwendung eines Proxys ist in folgendem Anwendungsfall hilfreich:
- Verbergen Sie die IP-Adresse, um anonym im Internet zu navigieren
- Greifen Sie auf Inhalte oder Rabatte zu, die auf Ihre Region beschränkt sind
- Rufen Sie in kleinen Abständen Daten aus mehreren Quellen ab
- Umgehen Sie den Anti-Web-Scraping-Schutz im Zusammenhang mit IP-Blacklist und Ratenbegrenzung
- Web Scraping und Data Mining, um Daten von Websites zu extrahieren, ohne blockiert zu werden
Die Syntax einer Proxy-URL sieht folgendermaßen aus:
Die folgende Tabelle beschreibt jeden Teil der URL:
| Proxy-URL-Teil | Beschreibung |
| Protokoll | Das Netzwerkprotokoll, das für die Verbindung zum Proxyserver verwendet wird. Die möglichen Werte sind HTTP, HTTPS und SOCKS. |
| Nutzername | Der Benutzer muss sich am Proxyserver authentifizieren. |
| Passwort | Das Passwort des Benutzers dient der Authentifizierung am Proxyserver. |
| Gastgeber | Die IP-Adresse oder URL der Proxyserver. |
| Hafen | Die Portnummer, die der Proxyserver überwacht. |
Der folgende Abschnitt zeigt einen realen Anwendungsfall des Sendens einer Anfrage mit einem Proxy mithilfe von cURL.
Integration von cURL in den ScraperAPI-Proxy-Modus
ScraperAPI erleichtert Entwicklern das problemlose Scrapen von Webdaten in großem Maßstab.
Nehmen wir an, Sie möchten die 100 besten Bücher zum Lesen auf Amazon heraussuchen – die URL lautet https://www.amazon.com/gp/browse.html?node=8192263011
Als Voraussetzung müssen Sie über ein ScraperAPI-Konto verfügen. Erstellen Sie einfach ein kostenloses ScraperAPI-Konto, um Zugriff auf Ihren API-Schlüssel und 5.000 API-Credits zum Testen des Tools zu erhalten.
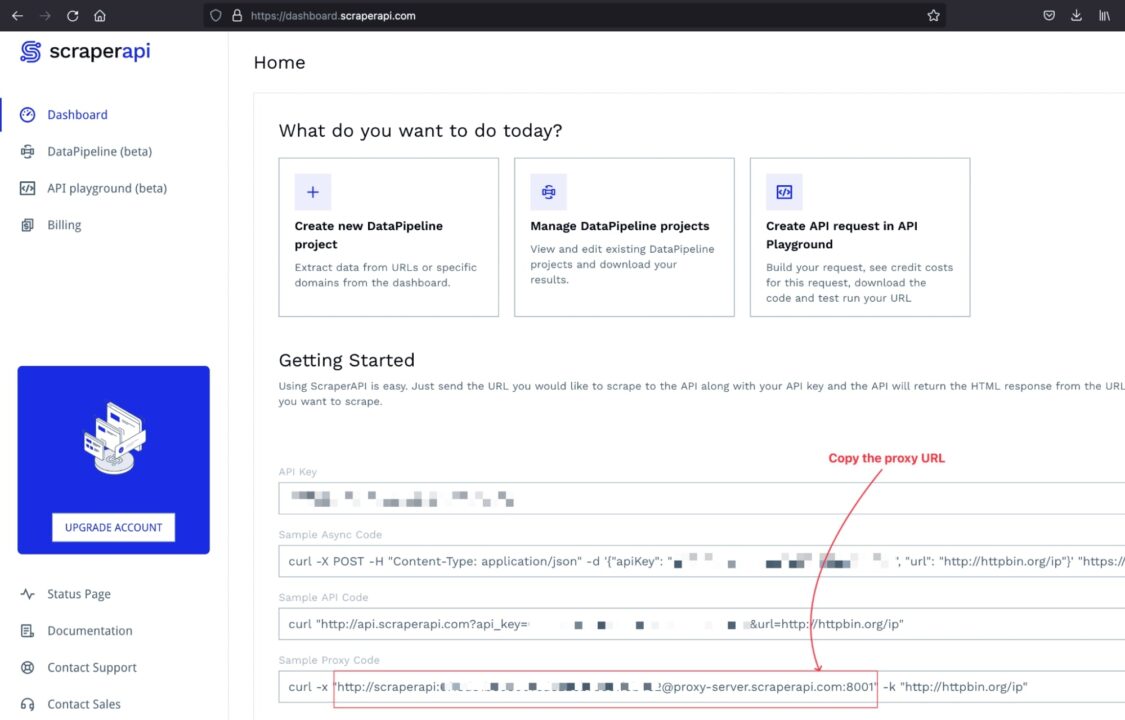
Schritt 1: Holen Sie sich die ScraperAPI-Proxy-URL
Melden Sie sich bei Ihrem Konto an und Sie werden zum Dashboard weitergeleitet, wo Sie Beispielcode für die Interaktion mit dem Proxy-Pool der ScraperAPI finden.
Schritt 2: Senden Sie eine Proxy-Anfrage mit cURL
Die Syntax zum Senden einer Anfrage über einen Proxy zum Scrapen einer Website mithilfe von cURL lautet wie folgt:
| curl -x |
Der <proxy_url> muss durch die Proxy-URL ersetzt werden, in unserem Fall die ScraperAPI-URL.
Der <website_target_ur> muss durch die Website-URL ersetzt werden, die Sie scannen möchten.
So würden Sie diese Anfrage von jedem System aus senden:
cURL-Proxy-Anfrage unter Windows:
curl.exe -x "http://scraperapi:[email protected]:8001" -k "https://www.amazon.com/gp/browse.html?node=8192263011"
cURL-Proxy-Anfragen unter Linux und MacOS
curl -x "http://scraperapi:[email protected]:8001" -k "https://www.amazon.com/gp/browse.html?node=8192263011"
Notiz: Der hier verwendete API-Schlüssel ist gefälscht. Ersetzen Sie ihn daher durch Ihren eigenen, um zu verhindern, dass Ihre Anfrage fehlschlägt.
Führen Sie diesen Befehl auf dem Terminal aus. Sie erhalten die folgende Ausgabe:
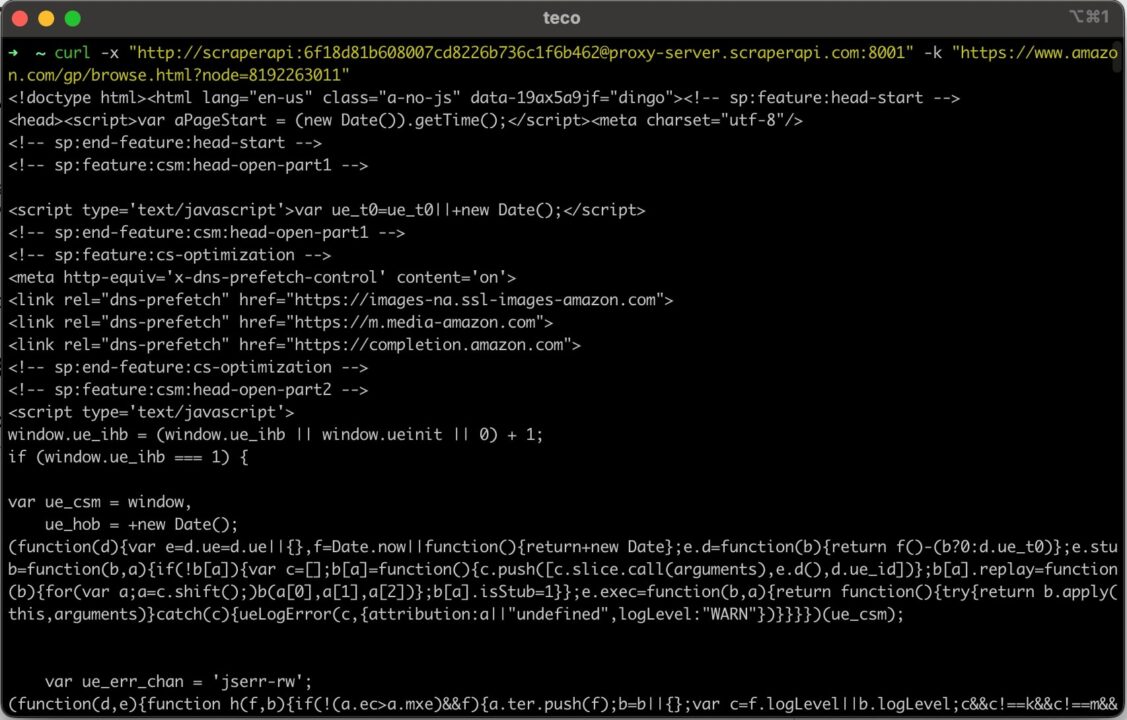
Verwendung von cURL mit rotierenden Proxys
Rotierende Proxys sind Proxyserver, die Ihre IP-Adresse bei jeder Anfrage oder in einem bestimmten Intervall automatisch ändern können. Dies ist hilfreich, um die Anti-Web-Scraping-Schutzmaßnahmen zu umgehen, die die meisten datenintensiven Websites verwenden.
Bei intensivem Web-Scraping mit derselben IP-Adresse führt das Senden zu vieler Anfragen in einem kleinen Bruchteil der Zeit dazu, dass der Server die Anfrage drosselt oder, schlimmer noch, die IP-Adresse auf die schwarze Liste setzt.
Ein rotierender Proxy wählt eine IP-Adresse aus dem Pool der verfügbaren IP-Proxys aus und weist sie der Anfrage zu. Für den Zielserver wird jede Anfrage wie eine neue behandelt.
Mit der von ScraperAPI bereitgestellten Scraping-API erhalten Sie diese Funktion sofort, ohne dass eine Konfiguration erforderlich ist. Sie geben Ihre Anfrage ein und der Proxyserver von ScraperAPI kümmert sich um den Rest.
Die Scraping-API verstehen
ScraperAPI bietet einige Optionen für erweiterte Web-Scraping-Techniken, z. B. das Rendern von JavaScript oder den Zugriff auf Websites, die auf einige Länder beschränkt sind.
- Um JavaScript zu rendern, müssen Sie den Parameter angeben
rendermit dem auf eingestellten Werttrue. - Um auf Inhalte zuzugreifen, die auf ein Land beschränkt sind, müssen Sie dem Parameter Land den Wert geben, der auf einen der unterstützten Ländercodes eingestellt ist. Schauen Sie sich die vollständige Liste an.
Die Syntax zum Hinzufügen von Parametern zur Proxy-URL lautet wie folgt:
Senden Sie cURL-Anfragen über ScraperAPI
Nehmen wir an, Sie möchten die „Smart Home-Seite“ der Home Depot-Website durchsuchen – hier ist die URL: https://www.homedepot.com/b/Smart-Home/N-5yc1vZc1jw.
Die Website lädt JavaScript und ist nur in den USA zugänglich; Um die Anfrage mit cURL zu senden, fügen wir der Proxy-URL den Parameter hinzu, der das Geotargeting ermöglicht.
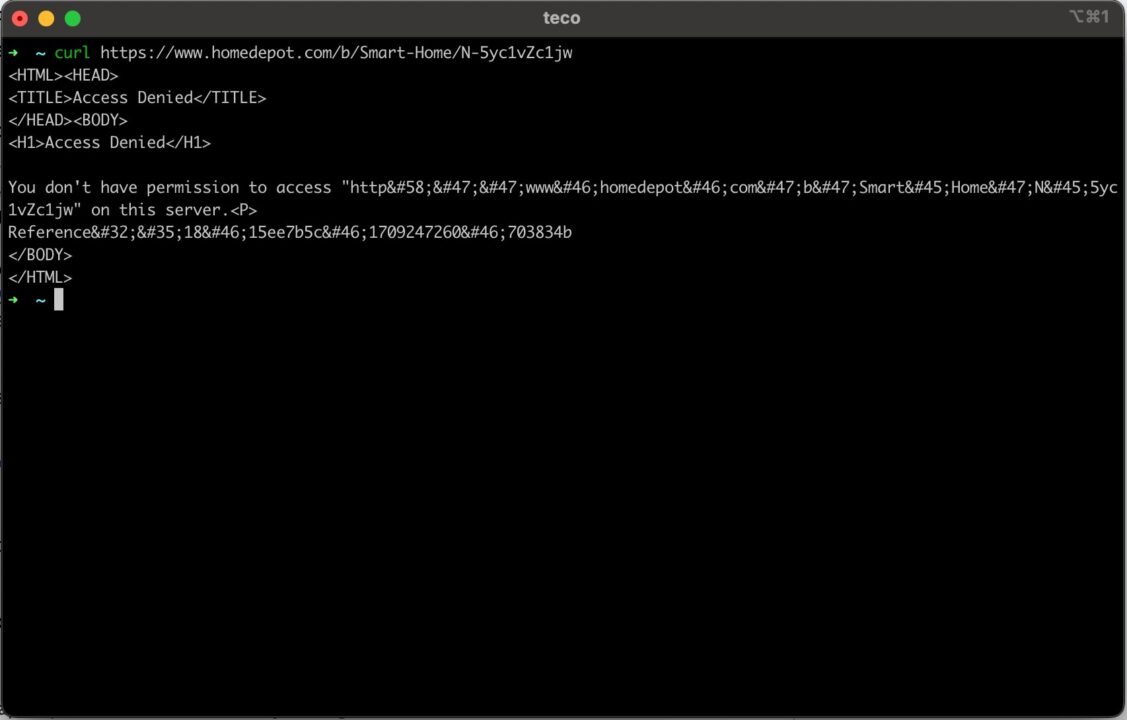
Wenn Sie mit dem folgenden Befehl eine klassische cURL-Anfrage (ohne Proxy) an diese Home Depot-Seite senden:
curl https://www.homedepot.com/b/Smart-Home/N-5yc1vZc1jw
Im Bild unten sehen Sie, dass wir nicht auf die Seite zugreifen können.
Senden wir eine Anfrage mit cURL und der Proxy-URL mit den definierten erweiterten Parametern:
curl -x "http://scraperapi.render=true.country=us:[email protected]:8001" -k "https://www.homedepot.com/b/Smart-Home/N-5yc1vZc1jw"
Jetzt erhalten wir wie erwartet den HTML-Inhalt der Seite
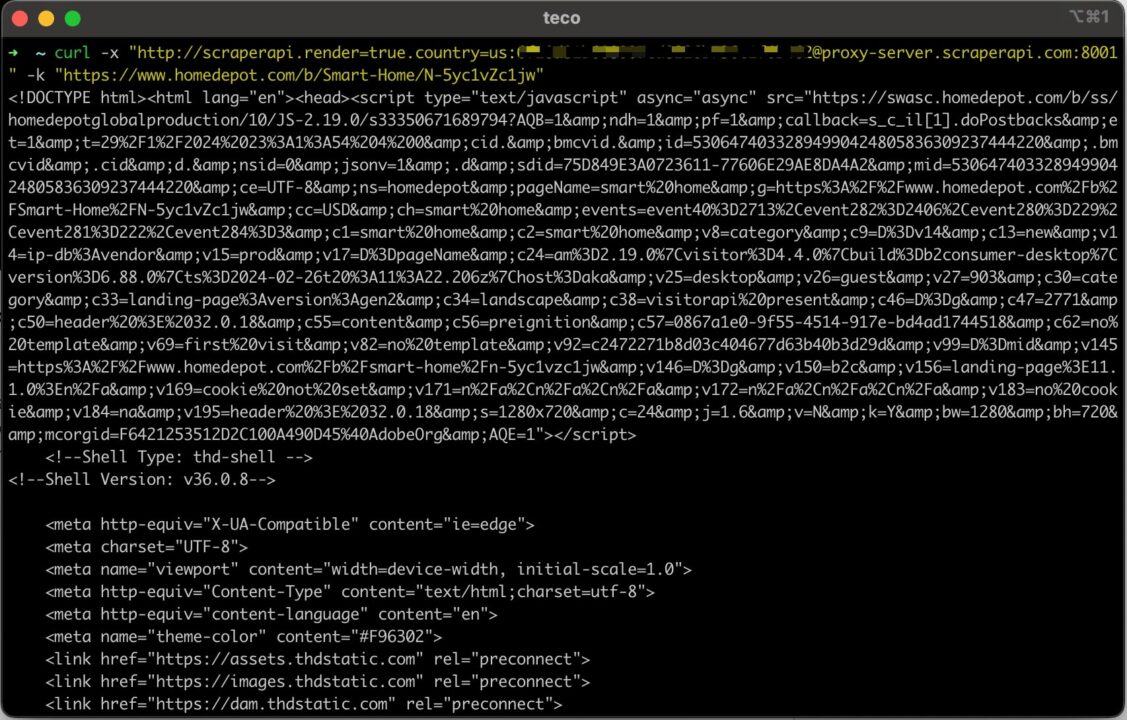
Wenn Sie diese Schritte befolgen, können Sie jetzt sicher sein, dass Sie immer die gewünschten Daten erhalten, unabhängig von der Website.
Zusammenfassung
Das Senden einer Anfrage mit cURL über einen Proxy ist einfach und kann in den folgenden Schritten zusammengefasst werden:
- Installieren Sie cURL auf Ihrem Betriebssystem.
- Holen Sie sich eine Proxy-URL; Wir haben die ScraperAPI-Proxy-URL für das Web-Scraping verwendet.
- Kombinieren Sie die Proxy-URL und die Zielwebsite, um eine Anfrage mit cURL zu senden.
- Verwenden Sie erweiterte ScraperAPI-Proxy-Parameter, um auf eingeschränkte Inhalte zuzugreifen.
Die Scraping-API kann mehr als nur ein Proxy-Pool sein. Wir haben gesehen, dass die Kombination mit cURL dazu beitragen kann, das Web-Scraping von Tausenden von Websites zu automatisieren, ohne durch deren Anti-Scraping-Mechanismen blockiert zu werden.
Obwohl die ML-Modelle von ScraperAPI die Verwendung einer gesunden Mischung von Proxy-Typen ermöglichen, können Sie den Parameter auch verwenden premium einstellen true ausschließlich Privat-Proxys zu verwenden.
Möchten Sie mehr erfahren? Schauen Sie sich die ScraperAPI-Proxy-Dokumentation an, um andere Proxy-Server-Protokolle wie SOCKS zu erkunden, oder schreiben Sie ein automatisiertes Skript, um mit der ScraperAPI Web-Scraping in großem Maßstab durchzuführen.
Bis zum nächsten Mal, viel Spaß beim Schaben!
