Kategorie: Web-Scraping
Automatisiertes Extrahieren von Daten aus Webseiten. In dieser Kategorie finden Sie Artikel über Tools, Techniken für effizientes Web Scraping.

Integration von Spritzer in Schakerapi integrieren
In diesem Handbuch erfahren Sie, wie Sie Scraperapi problemlos in Splash integrieren können, um mit...
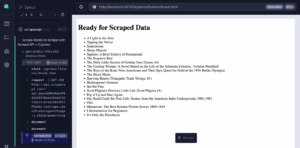
So verwenden Sie Scraperapi mit Zypressen für das Abkratzen und Tests von Web
Verwenden Sie Scraperapi mit Zypressen, um javaScript-hochwertige Websites zu kratzen und End-to-End-Tests durchzuführen. Es ist...
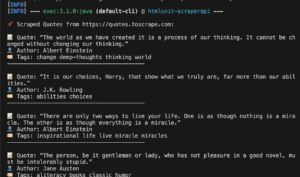
So verwenden Sie Scraperapi mit htmlunit in Java
Scraperapi ist ein leistungsstarkes Scraping -Tool, das automatisch Proxies, Browser und Captchas übernimmt. In dieser...
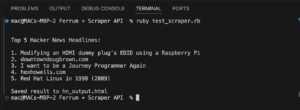
So verwenden Sie Scraperapi mit Ferrum (Ruby), um Websites zu kratzen
Diese Anleitung zeigt, wie Sie Scraperapi in Ferrum integrieren können, einem kopflosen Browser -Werkzeug für...

So verwenden Sie Scraperapi mit Dramatikern Erste Schritte Integrationsmethoden Best Practices Führen Sie den Code aus:
Scraperapi ist ein zuverlässiges Tool, das Proxies, Browser und Captchas während des Schabrierens von Webseiten...

So verwenden Sie Scraperapi mit Chromedp für Web -Scraping in Go Erste Schritte: Chromedp ohne Schaber -API -Integrationsmethoden Führen Sie den Code aus
Scraperapi hilft Ihnen, Websites zu kratzen, ohne blockiert zu werden. Es kümmert sich um Proxys,...

Dramatiker gegen Puppenspieler im Jahr 2025: Welches Browser -Automatisierungswerkzeug ist für Sie geeignet?
Wenn Sie mit kopflosen Browsern arbeiten, werden Sie sich wahrscheinlich vor einer wichtigen Entscheidung stellen:...

Erstellen Sie ein Tiktok-Brand-Influencer-Scouting-Tool mit dem Scraperapi-Langchain-Agenten, Qwen3 und Streamlit
Erstellen Sie ein benutzerdefiniertes Tiktok -Influencer -Scouting -Tool, mit dem Sie die Ersteller nach Land,...

So kratzen Sie geo-beschränkte Daten, ohne verboten zu werden
Während das Internet oft als kostenlos und offen für alle angesehen wird, werden auf einigen...

Langchain -Integration
Das Langchain Scraperapi-Paket ermöglicht es KI-Agenten, im Internet zu durchsuchen und auf Echtzeitinformationen zuzugreifen, ohne...

Beschleunigen Sie das Abkratzen von Web -Threads mit den gleichzeitigen Threads
Wenn Sie jemals einen Web -Schaber erstellt haben, kennen Sie den Schmerz. Sie bauen einen...
Python Pyppeteer Scraperapi -Integration
In dieser Anleitung zeige ich Ihnen, wie Sie mit Pythons Pyppeteer -Bibliothek für Kopflosen Browser...

Integration von Scraperapi in Datenreinigungsleitungen
Das Sammeln von sauberen, verwendbaren Daten ist die Grundlage für ein erfolgreiches Web -Scraping -Projekt....

Erstellen Sie ein Walmart -Bewertungs -Analyse -Tool mit Scraperapi, Vader, Gemini und Streamlit
Kundenbewertungen sind mehr als nur Feedback. Sie sind eine reiche, oft ungenutzte Quelle von Business...

Retry-Logik & Fehlerhandling beim Scraping
Retry-Logik & Fehlerhandling beim Scraping – so geh ich damit um Ausgangspunkt Selbst bei...

User-Agents beim Scraping
Mobile User-Agents beim Scraping – warum sie oft besser funktionieren Ausgangspunkt Bei einigen Webseiten...

Cookies beim Scraping
Cookies beim Scraping speichern und wiederverwenden – so klappt’s Ausgangspunkt Bei manchen Webseiten reicht...

User-Agent-Rotation beim Scraping
User-Agent-Rotation beim Scraping – so hab ich’s gelöst Ausgangspunkt Bei mehreren Requests auf dieselbe...

JSON-Daten aus XHR-Requests extrahieren
JSON-Daten aus XHR-Requests extrahieren – mein Praxisbeispiel Ausgangspunkt Ich wollte Produktdaten von einer...

Cloudflare umgehen mit Puppeteer – mein Setup
Cloudflare umgehen mit Puppeteer Ausgangspunkt Ich wollte eine Seite scrapen, die von Cloudflare...

Die 10 besten Alternativen für das Web -Scraping im Jahr 2025
Verwirrt durch die Komplexität von Apify und die Suche nach Apify -Alternativen? Suchen Sie nicht...

Top 10 Zenrows -Alternativen für das Web -Scraping im Jahr 2025
1. Scraperapi – Die beste Zenrows -Alternative im Jahr 2025 Scraperapi bietet die beste Mischung...

KYC bei Proxy-Anbietern – Was bedeutet es und warum wird es verlangt?
Was ist KYC bei Proxy-Anbietern? KYC (Know Your Customer) ist ein Verfahren, das von Proxy-Anbietern...

Zapier -Integration
Durch die Straffung Ihrer Datenerfassungs- und Lieferprozesse können Sie die Vorgänge Ihres Teams verändern. Die...

So erstellen Sie einen PHP-Web-Scraper mit Goutte + Codebeispielen
PHP ist eine weit verbreitete Backend-Sprache. Von vielen gehasst und für viele Anwendungen wie WordPress...
So entfernen Sie KI-Snippets in den Google-Suchergebnissen
Bereit, loszulegen? Lass uns eintauchen! Google AI-Übersichten verstehen Google AI Snippets oder Übersichten sind mehr...

So umgehen und entfernen Sie die Amazon WAF-Bot-Kontrolle mit Python
Was ist AWS WAF Bot Control? AWS WAF (Web Application Firewall) Bot Control ist Teil...

Die 8 besten Web-Scraping-APIs im Jahr 2024 (Vor- und Nachteile, Preise)
Starten Sie Ihr Web-Scraping-Projekt und suchen Sie nach der besten Web-Scraping-API, die derzeit auf dem...

Sichere Proxys für die Aggregation von Finanzdaten
Das manuelle Sammeln von Finanzdaten aus Millionen von Quellen ist jedoch zeitaufwändig und mühsam. Um...

Beste Proxys zur Umgehung von YouTube-Bot-Blockern
TL;DR: Beste Proxys zur Umgehung von YouTube-Bot-Blockern (im Vergleich) YouTube-Proxy-Anbieter Bewertung Rang Kostenlose Testversion Die...