
Wenn Sie jemals einen Web -Schaber erstellt haben, kennen Sie den Schmerz. Sie bauen einen Schaber, und es funktioniert großartig auf 1.000 Seiten, aber sobald Sie bis zu 10.000 oder mehr skalieren, werden die Dinge langsam. Hier ist die gute Nachricht: Es gibt eine Lösung!
In diesem Artikel lernen Sie alles über:
- Welche gleichzeitigen Fäden sind
- So richten Sie die gleichzeitigen Threads von Scraperapi ein
- So verwenden Sie sie, um Webseiten schneller und effizienter zu kratzen
Also, was sind gleichzeitige Threads?
Wenn Sie zuvor Scraperapi verwendet haben, kennen Sie bereits die Grundlagen – Sie haben die API getroffen, um die von Ihnen benötigten Seiten abzurufen. Mit gleichzeitigen Threads können Sie gleichzeitig mehrere Anfragen senden. Anstatt eine Seite zu kratzen, zu warten und dann die nächste zu kratzen, können Sie mehrere Anfragen parallel ausführen und Ergebnisse schneller erzielen.
Nehmen wir an, Sie verwenden 5 gleichzeitige Threads. Das bedeutet, dass Sie 5 Anfragen zum Schäfer gleichzeitig stellen, die alle parallel laufen. Je mehr Thread Sie verwenden, desto mehr Anfragen können Sie gleichzeitig senden, und je schneller Ihr Schaber ausgeführt wird.
Jeder Scraperapi -Plan verfügt über eine eigene Fadengrenze. Zum Beispiel:
- Der Geschäftsplan gibt Ihnen bis zu 100 gleichzeitige Fäden
- Der Skalierungsplan stößt auf bis zu 200 Fäden
Wenn Ihre Kratzerbedürfnisse darüber hinausgehen, haben wir Sie mit unserem Unternehmensplan bedeckt. Bei Enterprise gibt es keine feste Kappe. Wir arbeiten mit Ihnen zusammen, um ein benutzerdefiniertes Thread -Limit basierend auf Ihrem genauen Anwendungsfall anzupassen, damit Sie die beste Geschwindigkeit und Leistung erhalten.
Wie erhöht man Ihre Kratzgeschwindigkeit?
Nachdem wir wissen, was gleichzeitige Threads sind, ist es Zeit, sie in Aktion zu sehen.
Wir werden ein einfaches Experiment durchführen, um zu testen, wie Leistungsskalen mit unterschiedlichen Fadengrenzen skaliert und zeigen, wie viel Geschwindigkeit Sie freischalten können.
Zunächst erstellen wir eine Liste von mehr als 1000 URL -Proben. Dazu kriechen wir https://edition.cnn.com/business/tech und extrahieren URLs mit Open-Source-Tools wie Scrapy. Dieser Schritt besteht nur darin, die Beispiel -URLs zu erhalten, die wir kratzen möchten. In Ihrem Fall wären diese URLs die tatsächlichen Seiten, die Sie kratzen müssen.
Sobald wir die Liste der URLs haben, drücken wir zweimal auf den Scraperapi -Endpunkt:
- Erstens mit 100 gleichzeitigen Threads.
- Dann wieder mit 500 gleichzeitigen Fäden.
Schließlich werden wir messen, wie lange jeder Lauf dauert.
Stufe 1: Erstellen Sie eine Liste von Beispiel -URLs zum Kratzen
Befolgen Sie diese Schritte, um eine Liste von URLs von https://edition.cnn.com/business/tech zu erstellen:
Schritt 1: Öffnen Sie die Eingabeaufforderung oder das Terminal, gehen Sie zu Ihrem Projektordner und installieren Sie Scrapy und BeautifulSoup (die wir später benötigen).
Schritt 2: Starten Sie ein neues Scrapy -Projekt.
scrapy startproject cnn_scraper
cd cnn_scraper
Schritt 3: Gehen Sie in den Ordner /spiders und erstellen Sie eine Python -Datei.
cd spiders
touch cnn_spider.py
Schritt 4: In deiner Ideal gehen cnn_scraper/spiders/cnn_spider.py und fügen Sie den folgenden Code ein:
import scrapy
from urllib.parse import urljoin, urlparse
class CnnSpider(scrapy.Spider):
name = "cnn"
allowed_domains = ("edition.cnn.com")
start_urls = ("https://edition.cnn.com/business/tech")
seen_urls = set()
custom_settings = {
'USER_AGENT': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
def parse(self, response):
links = response.css("a::attr(href)").getall()
for link in links:
if link.startswith("/"):
full_url = urljoin("https://edition.cnn.com", link)
elif link.startswith("http") and "edition.cnn.com" in link:
full_url = link
else:
continue
if full_url not in self.seen_urls:
self.seen_urls.add(full_url)
yield {"url": full_url}
yield response.follow(full_url, callback=self.parse)
if len(self.seen_urls) >= 1000:
self.crawler.engine.close_spider(self, "URL limit reached")
Im obigen Code, custom_settings Legt die Benutzer-Agent-Header Scrapy mit jeder Anfrage fest, wodurch die Spinnen wie ein echter Browser aussieht. Die Funktion PARSE () verwendet die integrierte GetAll () -Funktion, um alle Links auf der aktuellen Seite zu sammeln und zu verarbeiten, und verwandeln sie in vollständige Links. Die IF -Bedingung (wenn full_url nicht in self.seen_urls) nur dazu dient, Links zu verarbeiten, die Sie noch nie gesehen haben.
Schritt 5: Führen Sie den folgenden Befehl aus dem aus, um den obigen Code auszuführen und die URLs in einer JSON -Datei zu speichern cnn_scraper/spiders folder:
scrapy crawl cnn -o urls.json
Stufe 2: Kratzen wir die gespeicherten URLs mit dem Scraperapi kratzen
Schritt 1: Erstellen Sie eine Python -Datei – ich habe meine benannt scraper_api.pyAber Sie können den für Sie funktionierenden Namen auswählen – und fügen Sie den folgenden Code darin ein:
import requests
import json
import csv
import time
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor
API_KEY = 'ScraperAPI API_key'
NUM_RETRIES = 3
NUM_THREADS = 100
with open("path/to/URLs_json_file", "r") as file:
raw_data = json.load(file)
list_of_urls = (item("url") for item in raw_data if "url" in item)
def scrape_url(url):
params = {
'api_key': API_KEY,
'url': url
}
for _ in range(NUM_RETRIES):
try:
response = requests.get('http://api.scraperapi.com/', params=params)
if response.status_code in (200, 404):
break
except requests.exceptions.ConnectionError:
continue
else:
return {
'url': url,
'h1': 'Failed after retries',
'title': '',
'meta_description': '',
'status_code': 'Error'
}
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
h1 = soup.find("h1")
title = soup.title.string.strip() if soup.title else "No Title Found"
meta_tag = soup.find("meta", attrs={"name": "description"})
meta_description = meta_tag("content").strip() if meta_tag and meta_tag.has_attr("content") else "No Meta Description"
return {
'url': url,
'h1': h1.get_text(strip=True) if h1 else 'No H1 found',
'title': title,
'meta_description': meta_description,
'status_code': response.status_code
}
else:
return {
'url': url,
'h1': 'No H1 - Status {}'.format(response.status_code),
'title': '',
'meta_description': '',
'status_code': response.status_code
}
start_time = time.time()
#concurrent threads
with ThreadPoolExecutor(max_workers=NUM_THREADS) as executor:
scraped_data = list(executor.map(scrape_url, list_of_urls))
elapsed_time = time.time() - start_time
print(f"Using 100 concurrent threads, scraping completed in {elapsed_time:.2f} seconds.")
# Save to CSV
with open("cnn_h1_1000_1_results.csv", "w", newline='', encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=("url", "h1", "title", "meta_description", "status_code"))
writer.writeheader()
writer.writerows(scraped_data)
Die Funktion scrape_url(url) Sendet eine Anfrage an Scraperapi mit der angegebenen URL. Wenn der Antwortstatuscode nicht 200 oder 404 ist, wird er bis zu NUM_RETRIES mal. Wenn es eine bekommt 200 OKEs verwendet BeautifulSoup, um den H1-, Titel- und Meta -Beschreibung analysieren.
Der Teil ThreadPoolExecutor(max_workers=NUM_THREADS) Sendet die gleichzeitigen Anfragen an Scraperapi. Am Ende speichert der Code die abgekratzten Daten in einer CSV -Datei.
Wann NUM_THREADS == 100Es dauerte 100,68 Sekunden, um die Titel zu kratzen.
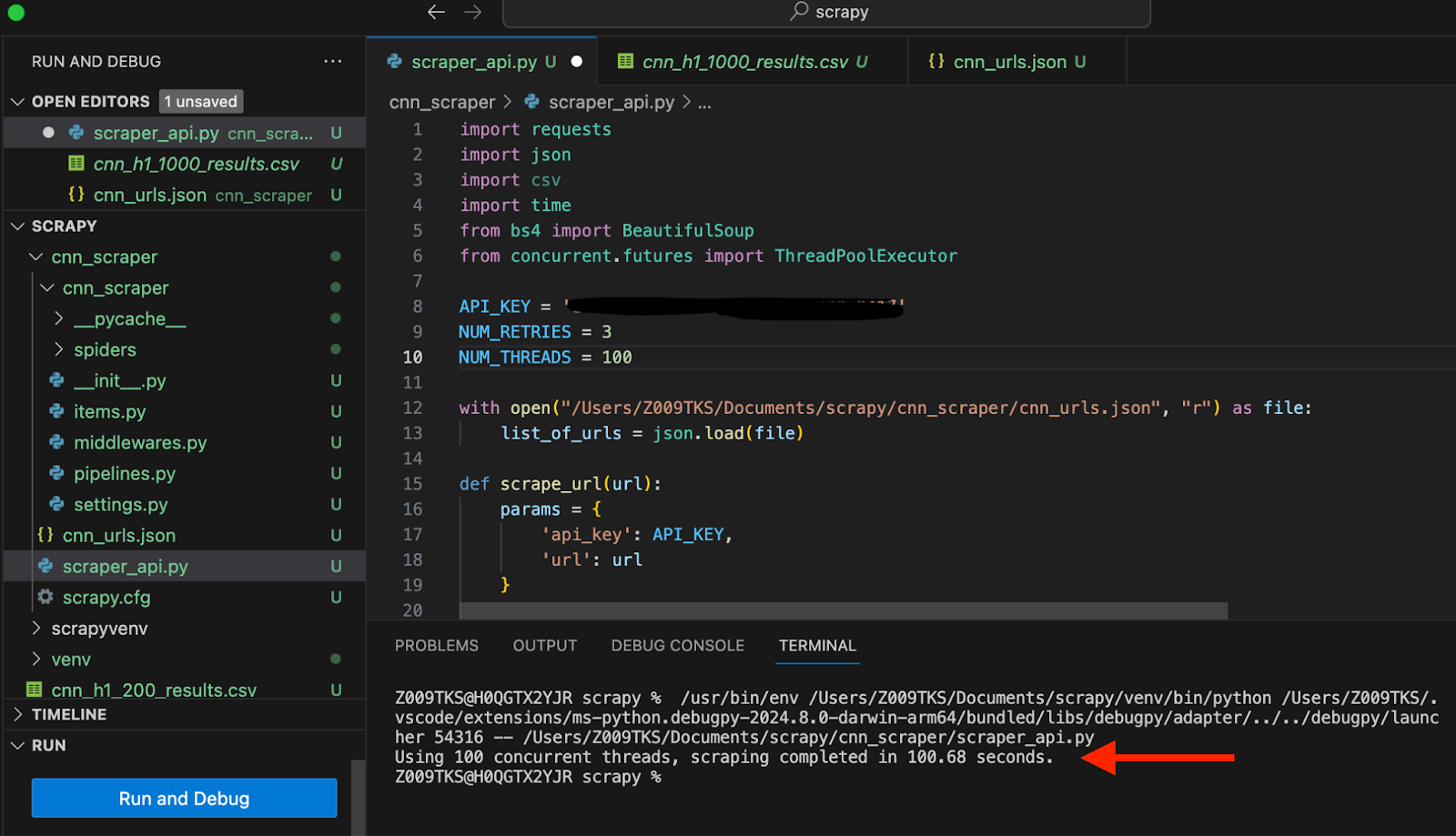
Im selben Code haben wir nur die Anzahl der gleichzeitigen Threads auf 500 geändert. Jetzt dauerte es nur 23,56 Sekunden.
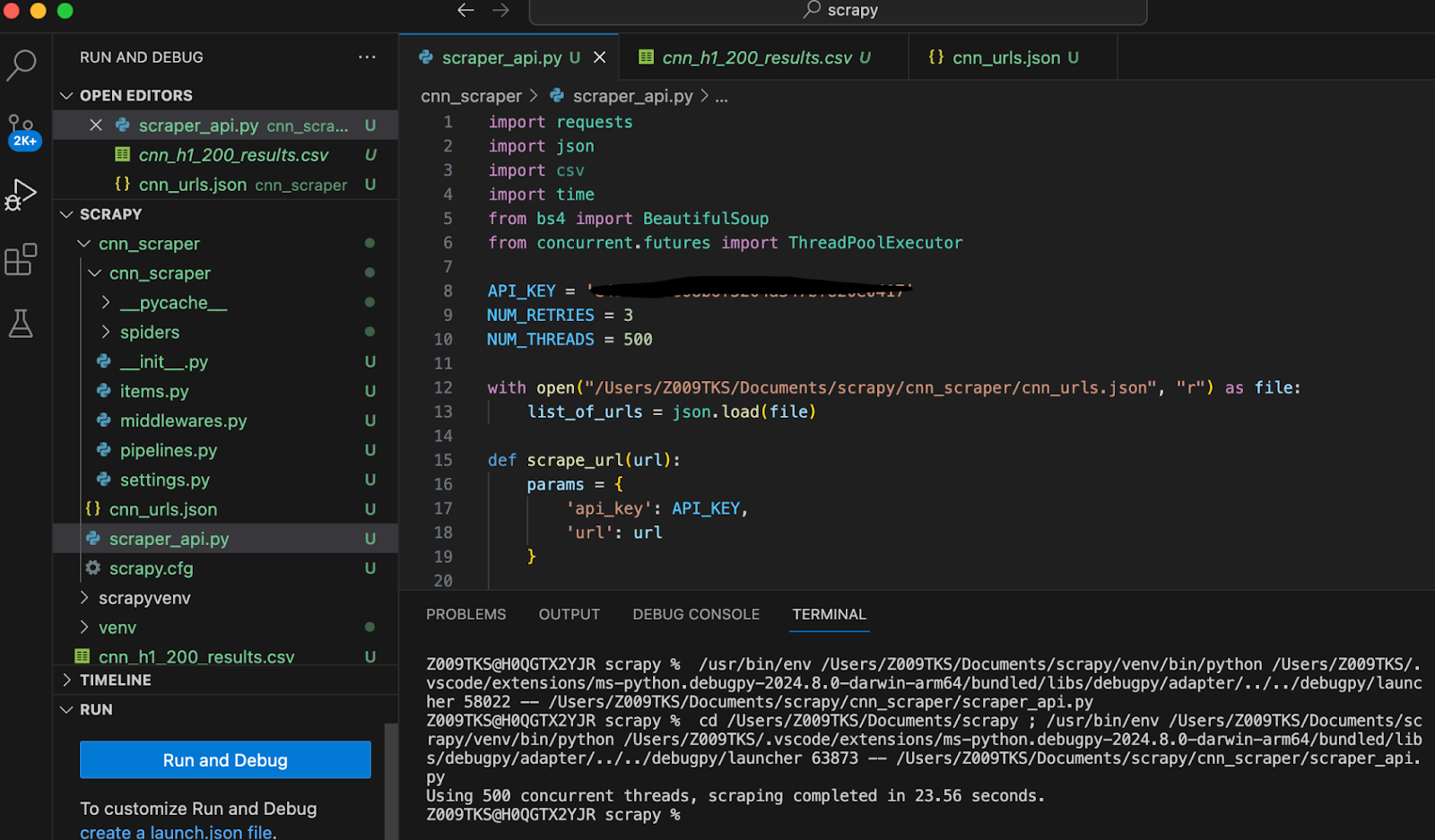
Einfach so habe ich die Kratzzeit von etwa 100 Sekunden auf nur 23 Sekunden gesenkt. Das ist fast 4 -mal schneller mit 500 Fäden im Vergleich zu 100!
Um Ihre Leistung mit benutzerdefinierten gleichzeitigen Threads zu optimieren, werden Sie noch heute in unseren benutzerdefinierten Unternehmensplan ein Upgrade einlegen.
