
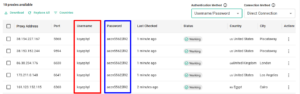
Die Authentifizierung über Benutzername und Passwort ist eine der häufigsten Methoden, um Proxyserver abzusichern. Statt einer festen IP-Adresse werden in diesem Fall Zugangsdaten verwendet, um festzulegen, wer auf den Proxy zugreifen darf. Diese Methode ist flexibel, weit verbreitet und technisch einfach umzusetzen.
Im Gegensatz zur IP-Authentifizierung ist sie unabhängig vom Standort oder der IP-Adresse des Nutzers. Der Zugriff funktioniert von überall – solange die richtigen Zugangsdaten übermittelt werden.
Was ist das und wie funktioniert es?
Bei dieser Methode wird der Zugriff über ein klassisches Login-Verfahren gesteuert: Der Client sendet bei jeder Verbindung einen HTTP-Header mit codierten Zugangsdaten, meist im Format „Basic Auth“.
Beispiel:
Alternativ werden Benutzername und Passwort direkt in die Proxy-URL eingebunden, zum Beispiel:
Die meisten Programme, Skripte, Browser und Bibliotheken unterstützen diesen Aufbau nativ. Die Methode ist plattformübergreifend kompatibel und funktioniert mit HTTP-, HTTPS- sowie SOCKS5-Proxys (je nach Anbieter).
Alternative Bezeichnungen
Viele Anbieter verwenden unterschiedliche Begriffe für diese Methode. Gängig sind unter anderem:
„Benutzer-/Passwort-Authentifizierung“, „Login-Zugang“, „User:Pass Login“, „Proxy-Zugangsdaten“ oder einfach „Proxy mit Login“.
Vorteile in der Praxis
-
Unabhängig von der IP-Adresse:
Funktioniert auch bei dynamischen oder mobilen Verbindungen, ohne dass die IP ständig beim Anbieter aktualisiert werden muss. Besonders praktisch bei ADSL- oder LTE-Zugängen. -
Ein Proxy-Paket für viele Systeme:
Ermöglicht den parallelen Einsatz eines Proxy-Zugangs von mehreren Servern oder Standorten aus – etwa bei Nutzung mehrerer VPS –, ohne dass zusätzliche IPs freigegeben oder neue Pakete gebucht werden müssen. -
Kompatibel mit allen Tools:
Die meisten Anwendungen und Automatisierungswerkzeuge (wie Scraper, Bots, Anti-Detect-Browser) setzen auf Login-basierte Authentifizierung. Auch cURL, wget, Python-Clients und viele andere unterstützen diese Methode direkt. -
Zugangsdaten leicht änderbar:
In vielen Panels lassen sich Benutzername und Passwort einfach neu generieren oder anpassen – ideal bei Teamarbeit oder temporärem Zugriff.
Nachteile und Risiken
-
Etwas geringere Geschwindigkeit:
Durch das ständige Mitsenden von Zugangsdaten bei jeder Verbindung kann es zu leicht erhöhten Latenzen kommen – besonders bei sehr vielen gleichzeitigen Verbindungen. -
Erkennbar durch Proxy-Detektoren:
Einige Prüfsysteme erkennen Proxys daran, dass beim Verbindungsaufbau eine Login-Abfrage erfolgt. Dies kann zur Sperrung der Proxy-IP führen, insbesondere bei öffentlich sichtbaren Diensten. -
Sicherheitsrisiko bei unsachgemäßer Nutzung:
Wenn Zugangsdaten in Konfigurationsdateien oder Logs gespeichert werden, besteht das Risiko, dass sie Dritten zugänglich sind. Eine sorgfältige Handhabung ist wichtig.
Tipps aus der Praxis
-
Vor dem Kauf prüfen:
Unbedingt beim Anbieter nachfragen, ob eine Begrenzung für gleichzeitige Verbindungen besteht. Manche Provider setzen Drosselung (Throttling) ein, wenn zu viele Sessions gleichzeitig aufgebaut werden – als Schutz gegen „gruppenweisen“ Zugriff. -
Zugang nicht offen weitergeben:
Wer den Proxy-Zugang mit anderen teilt, sollte die Zugangsdaten regelmäßig ändern oder rotieren, um Missbrauch zu vermeiden. -
Zugang per User/Pass sinnvoll planen:
Wenn mehrere Systeme gleichzeitig auf denselben Proxy zugreifen müssen – etwa von verschiedenen VPS – ist die Login-Authentifizierung meist die einfachste Lösung.
