Diese Anleitung zeigt, wie Sie Scraperapi in Ferrum integrieren können, einem kopflosen Browser -Werkzeug für Ruby. Sie lernen, wie Sie Ruby und Ferrum auf Ihrer Maschine einrichten, über Scraperapis Proxy herstellen und dynamische Websites kratzen, auf denen Inhalte mit JavaScript geladen werden. Ziel ist es, echte, nutzbare Daten zu erhalten, schnell und sauber.
Erste Schritte mit Ferrum (kein Proxy)
So sieht ein grundlegendes Ferrum -Skript ohne Scraperapi aus:
require 'ferrum'
browser = Ferrum::Browser.new
browser.goto('https://example.com')
puts browser.current_title
browser.quit
Dies funktioniert gut für einfache Seiten. Wenn Sie dies jedoch auf Websites versuchen, die das Schaben blockieren, JavaScript verwenden, um Inhalte zu rendern oder Captchas zu werfen, werden Sie eine Wand treffen. Ferrum dreht IPs nicht oder verarbeitet das Blockieren von Advanceds von selbst.
Dort kommt Scraperapi ins Spiel.
Empfohlene Methode: Verwenden Sie Scraperapi als Proxy
Diese Methode sendet Ihren gesamten Ferrum -Verkehr über Scraperapis Proxy. Es gibt Ihnen IP-Rotation, Länder-Targeting, Captcha-Bypass und Unterstützung für JS-hochwertige Websites.
Anforderungen
- Ruby (v2.6 oder höher)
- Bundler (
gem install bundler) - Chrom oder Chrom, die auf Ihrem System installiert sind
- Scraperapi -Schlüssel (Sie können einen erhalten, indem Sie sich anmelden!)
- Ferrum
Installation und Setup
Wenn Sie es noch nicht haben, installieren Sie Ruby und bundler:
sudo apt update
sudo apt install ruby-full -y
sudo gem install bundler
Erstellen a Gemfile In Ihrem Projektordner:
Und fügen Sie Folgendes hinzu:
# Gemfile
source 'https://rubygems.org'
gem 'ferrum'
gem 'dotenv'
Dann rennen:
Dies installiert die erforderlichen Edelsteine mit Bundler.
.Env -Datei
Erstellen Sie in Ihrem Projektordner a .env Datei mit Folgendes:
SCRAPERAPI_KEY=your_api_key_here
Dein Skript
Fügen Sie in einer Datei test_scraper.rb Folgendes ein:
require 'ferrum'
require 'dotenv/load'
SCRAPERAPI_KEY = ENV('SCRAPERAPI_KEY')
proxy_url = "http://api.scraperapi.com:8001?api_key=#{SCRAPERAPI_KEY}&render=true"
browser = Ferrum::Browser.new(browser_options: { 'proxy-server': proxy_url })
browser.goto('https://news.ycombinator.com/')
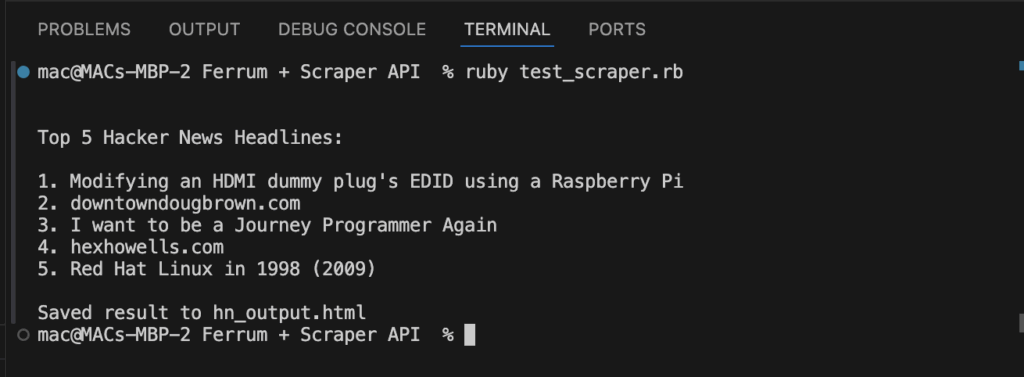
puts "\nTop 5 Hacker News Headlines:\n\n"
browser.css('.athing .titleline a').first(5).each_with_index do |link, index|
puts "#{index + 1}. #{link.text.strip}"
end
# Save output to HTML file for browser inspection
File.write('output.html', browser.body)
puts "\nSaved result to output.html"
browser.quit
# Optional: open the file in Chrome
system("open -a 'Google Chrome' output.html")
Das obige Skript verwendet Ferrum, um eine Website zu besuchen, die sich auf JavaScript stützt. Es sendet die Anfrage über Scraperapi mit render=true Dynamische Inhalte laden. Es kratzt die Top 5 Schlagzeilen von Hacker News, spart die volle HTML und ermöglicht es, sie in Chrom zu öffnen, um die Ergebnisse zu überprüfen.
Speichern Sie Ihr Skript als test_scraper.rbdann führen Sie es aus:
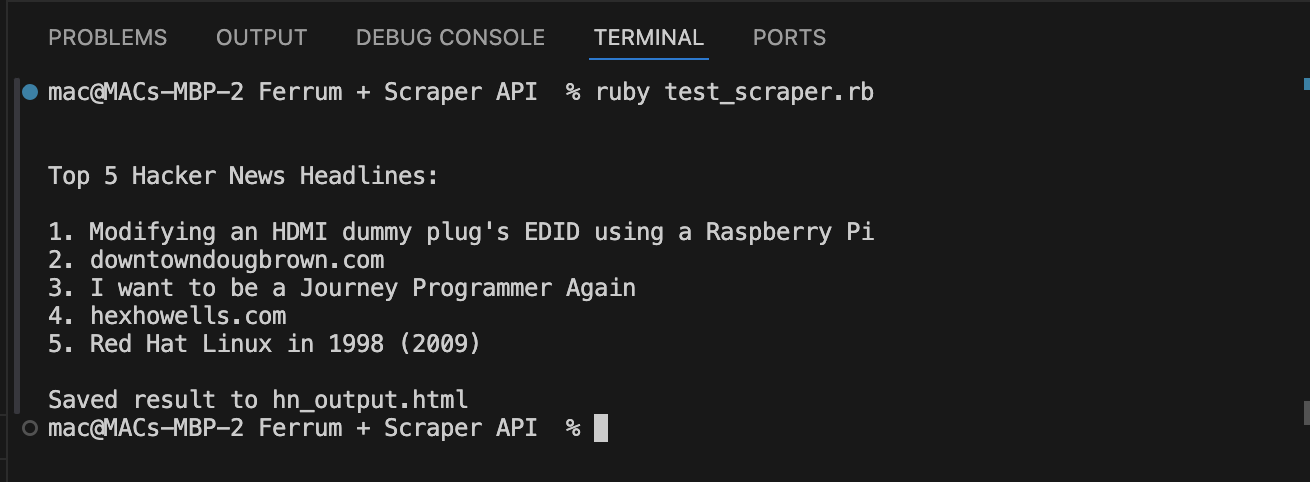
Es sollte auf Chrom wie dieses geladen werden:
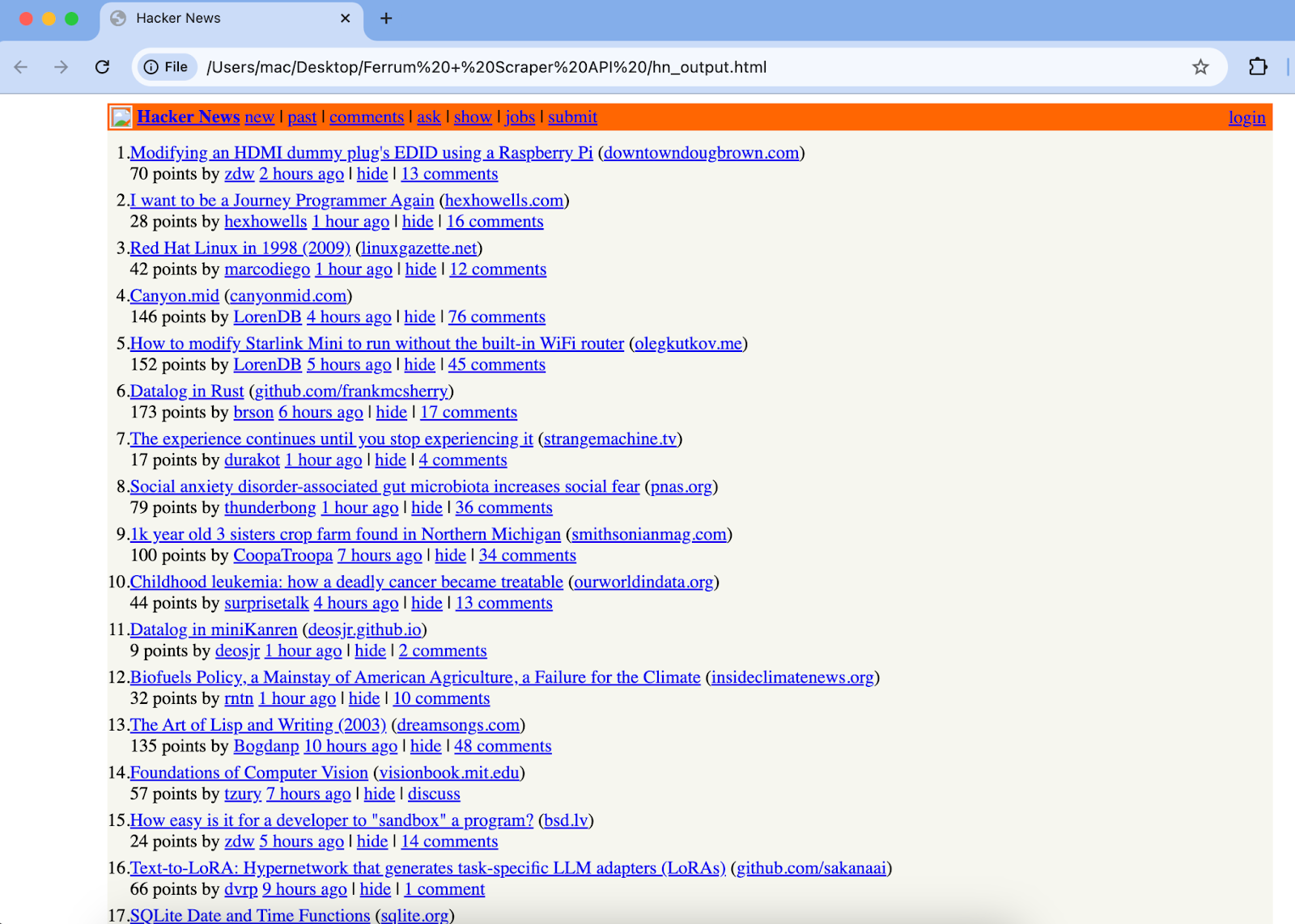
Dies bestätigt, dass Scraperapi die Anfrage bearbeitet.
Optionale Parameter
Mit Scraperapi können Sie zusätzliche Optionen über Abfrageparameter übergeben:
{
Render = true, // Load JavaScript
CountryCode = "us", // Use US IP
Premium = true, // Enable CAPTCHA solving
SessionNumber = 123 // Maintain session across requests
};
| Parameter | Was es tut | Wann man es benutzt |
render=true |
Fordert Scraperapi an, JavaScript auszuführen | Verwendung für Spas und dynamische Inhalte |
country_code=us |
Routenanfragen über US -Proxies | Ideal für geo-blockierte Inhalte |
premium=true |
Ermöglicht CAPTCHA-Lösung und fortgeschrittene Anti-BOT-Maßnahmen | Essentiell für stark geschützte Stellen |
session_number=123 |
Behält die gleiche Proxy -IP über Anfragen hinweg bei | Verwenden Sie, wenn Sie Anmeldesitzungen beibehalten müssen |
Diese Parameter decken die meisten Schablonen -Szenarien ab. Weitere Optionen finden Sie in der Dokumentation der Schaferapi.
Beispiel
proxy_url = "http://api.scraperapi.com:8001?api_key=#{SCRAPERAPI_KEY}&render=true&country_code=us&session_number=123"
Konfiguration und Best Practices
Parallelität
Verwenden Sie Threads, um mehrere Ferrum -Sitzungen auszuführen:
threads = 5.times.map do
Thread.new do
browser = Ferrum::Browser.new(...)
browser.goto('https://httpbin.org/ip')
puts browser.body
browser.quit
end
end
threads.each(&:join)
Logik wiederholen
Wickeln Sie instabile Anfragen in Wiederholungsblöcke ein:
begin
browser.goto('https://targetsite.com')
rescue Ferrum::StatusError => e
sleep 1
retry
end
Für weitere Informationen können Sie die Dokumentation der Scraperapi überprüfen.
