
Unabhängig davon, ob Sie ein Investor sind, der Ihre Finanzportfolio -Leistung verfolgt oder ein Investmentunternehmen nach neuen Investitionsmöglichkeiten sucht, können Sie auf Web -Scraping -Aktienmarktdaten auf die neuesten Finanzinformationen und Trends zugreifen, um Ihre Anforderungen zu unterstützen.
In diesem Tutorial für Web -Scraping zeigen wir Ihnen, wie Sie ein Web -Scraping -Tool erstellen, um Börsenmarktdaten mithilfe von Python und BeautifulSoup zu extrahieren. Darüber hinaus werden Sie mit dem Beispiel übermitteln, wie Sie mehrere Aktienkurse verfolgen und extrahieren und zur weiteren Analyse in einer CSV -Datei organisieren. Lassen Sie uns direkt hineinspringen.
So erstellen Sie einen Börsendatenschaber
Für diese Übung werden wir Investing.com abkratzen, um aktuelle Aktienkurse von Microsoft, Coca-Cola und Nike zu extrahieren und sie in einer CSV-Datei zu speichern. Wir zeigen Ihnen auch, wie Sie Ihren Web-Scraping-Bot vor Anti-Scraping-Mechanismen und -techniken unter Verwendung von Scraperapi vor dem Schrott schützen.
Notiz: Das Skript wird auch ohne Scraperapi für die Krankheit der Aktienmarktdaten erfassen, ist jedoch entscheidend, um Ihr Projekt später zu skalieren.
Obwohl wir Sie durch jeden Schritt des Börsenmärktionsdatenextraktionsprozesses durchlaufen werden, ist es hilfreich, im Voraus einige Kenntnisse der schönen Suppenbibliothek zu haben. Wenn Sie in dieser Bibliothek völlig neu sind, lesen Sie unser schönes Suppen -Tutorial für Anfänger. Es ist voller Tipps und Tricks und geht die Grundlagen durch, die Sie wissen müssen, um fast alles zu kratzen.
Lassen Sie uns damit in den Code springen, damit Sie lernen können, wie Sie Aktienmarktdaten abkratzen.
1. Einrichten unseres Börsen -Web -Scraping -Projekts
Zunächst erstellen wir einen Ordner mit dem Namen „Scraper-STOCK-Project“ und öffnen ihn von VSCODE (Sie können jeden möchten, den Sie möchten). Als nächstes öffnen wir ein neues Terminal und installieren unsere beiden Hauptabhängigkeiten für dieses Projekt:
- PIP3 Installieren Sie BS4
- PIP3 -Anfragen installieren
Danach erstellen wir eine neue Datei mit dem Namen „StockData-scraper.py“ und importieren unsere Abhängigkeiten dazu.
import requests
from bs4 import BeautifulSoup
Mit Anfragen können wir eine HTTP -Anfrage zum Herunterladen der HTML -Datei senden, die dann zur Parsen an BeautifulSoup weitergegeben wird. Testen wir es, indem wir eine Anfrage an die Aktienseite von Nike senden:
url = 'https://www.investing.com/equities/nike'
page = requests.get(url)
print(page.status_code)
Wenn wir den Statuscode der Seitenvariablen (das sind unsere Anfrage) drucken, wissen wir sicher, ob wir die Seite kratzen können oder nicht. Der Code, den wir suchen, ist eine 200, was bedeutet, dass es sich um eine erfolgreiche Anfrage handelte.

Erfolg! Bevor wir fortfahren, werden wir die in der Seite gespeicherte Antwort zur schönen Suppe zum Parsen übergeben:
soup = BeautifulSoup(page.text, 'html.parser')
Sie können jeden von Ihnen gewünschten Parser verwenden, aber wir gehen mit html.parser, weil es das ist, das wir mögen.
Verwandte Ressource: Was ist die Daten an der Daten im Web -Scraping? (Code -Ausschnitte im Inneren)
2. Überprüfen Sie die HTML -Struktur der Website (Investing.com)
Bevor wir anfangen zu kratzen, lassen Sie uns in unserem Browser https://www.investing.com/equities/nike öffnen, um mit der Website mehr vertraut zu werden.
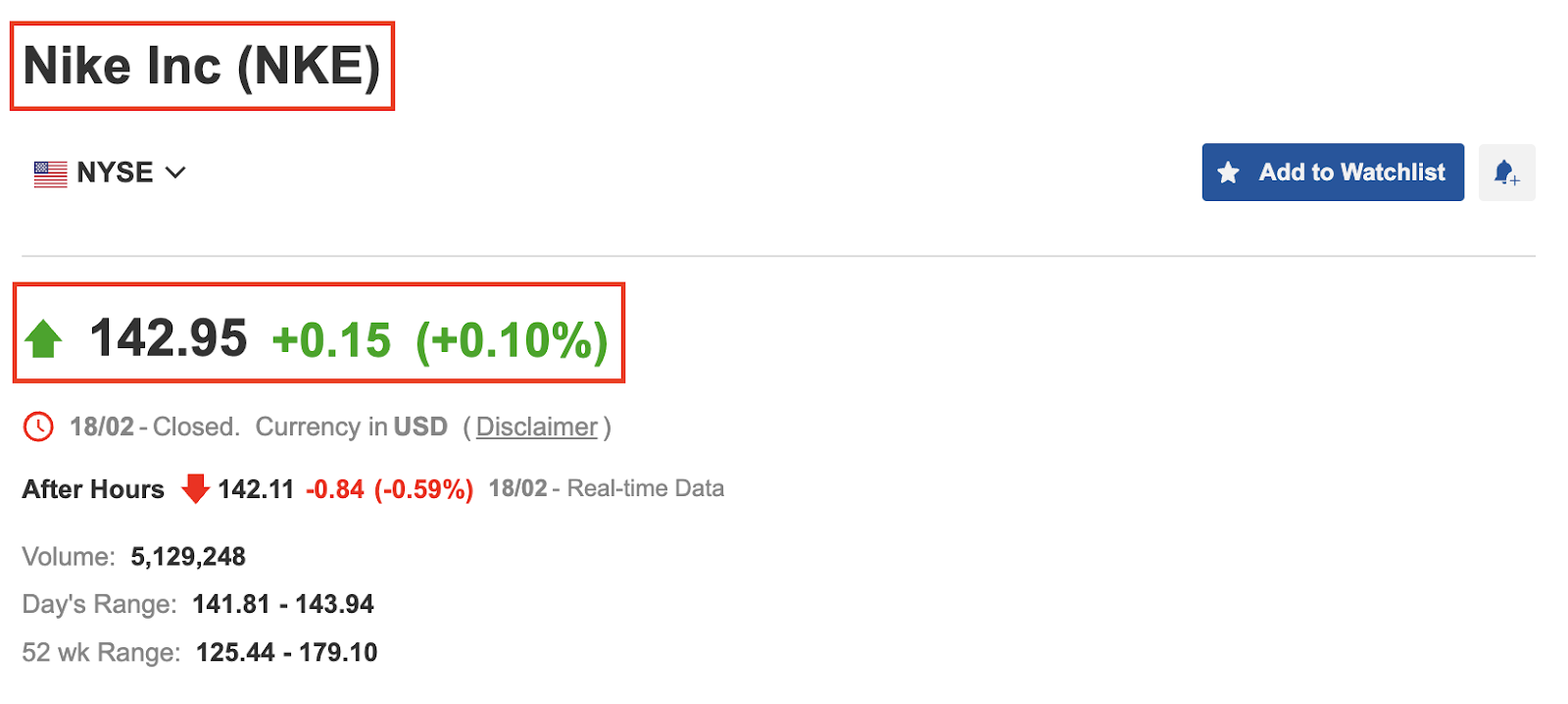
Wie Sie im obigen Screenshot sehen können, zeigt die Seite den Namen, das Aktiensymbol, der Preis und die Preisänderung des Unternehmens an. Zu diesem Zeitpunkt haben wir drei Fragen zu beantworten:
- Werden die Daten JavaScript injiziert?
- Mit welchem Attribut können wir die Elemente auswählen?
- Sind diese Attribute auf allen Seiten konsistent?
Überprüfen Sie, ob JavaScript
Es gibt verschiedene Möglichkeiten, zu überprüfen, ob ein Skript ein Datenstück injiziert, aber am einfachsten ist es, mit der rechten Maustaste zu klicken und die Seitenquelle anzeigen.
Es sieht so aus, als ob es kein JavaScript gibt, das möglicherweise unseren Schaber beeinträchtigen könnte. Als nächstes machen wir das gleiche für den Rest der Informationen. Wir haben kein zusätzliches JavaScript gefunden, das wir noch gut gehen können.
Notiz: Die Überprüfung nach JavaScript ist wichtig, da Anfragen JavaScript nicht ausführen oder mit der Website interagieren können. Wenn die Informationen also hinter einem Skript stehen, müssten wir andere Tools verwenden, um sie wie Selen zu extrahieren.
Auswahl der CSS -Selektoren
Inspizieren wir nun die HTML der Site, um die Attribute zu identifizieren, mit denen wir die Elemente auswählen können.

Das Extrahieren des Namens des Unternehmens und des Aktiensymbols ist ein Kinderspiel. Wir müssen nur auf das abzielen H1 Tag mit Klasse ‘text-2xl font-semibold instrument-header_title__GTWDv mobile:mb-2’.
Der Preis, die Preisänderung und die prozentuale Veränderung werden jedoch in unterschiedliche Spannweiten unterteilt.
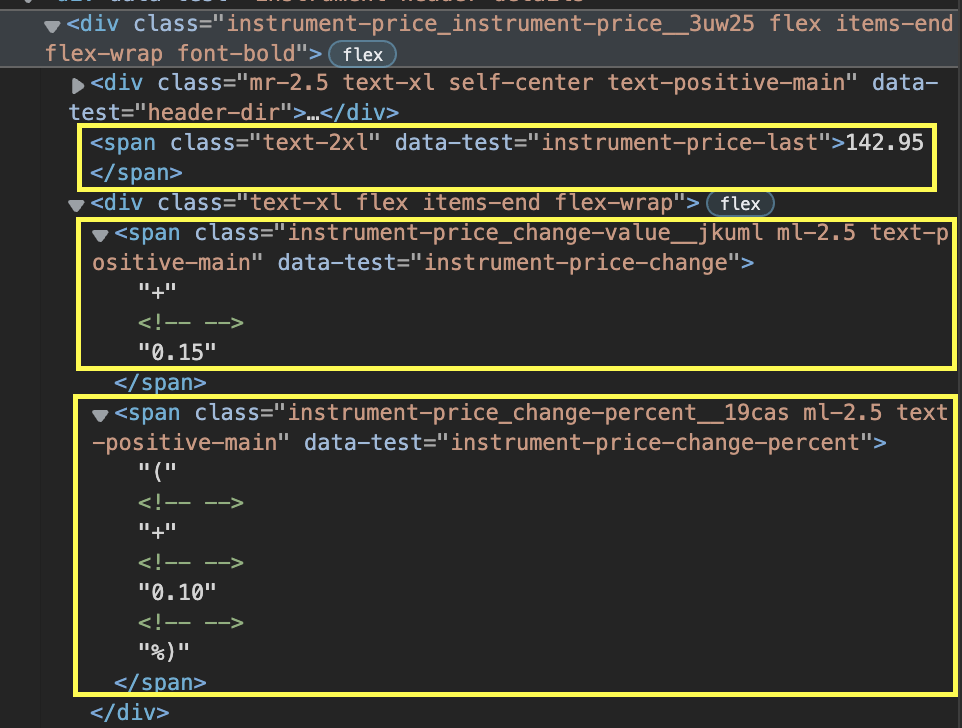
Darüber hinaus ändert sich die Klasse des Elements, je nachdem, ob die Änderung positiv oder negativ ist. Selbst wenn wir jede Spanne mit ihrem Klassenattribut auswählen, wird es immer noch Instanzen geben, in denen es nicht funktioniert.
Die gute Nachricht ist, dass wir einen kleinen Trick haben, um es herauszuholen. Da wunderschöne Suppe einen Parsen -Baum zurückgibt, können wir jetzt durch den Baum navigieren und das gewünschte Element auswählen, obwohl wir nicht die genaue CSS -Klasse haben.
Was wir in diesem Szenario tun werden, ist, in der Hierarchie zu steigen und eine übergeordnete DIV zu finden, die wir ausnutzen können. Anschließend können wir Find_all ('span') verwenden, um eine Liste aller Elemente, die das Span -Tag enthalten, zu erstellen – von dem wir unsere Zieldaten kennen. Und weil es sich um eine Liste handelt, können wir sie jetzt leicht navigieren und die wir auswählen, die wir brauchen.
Also hier sind unsere Ziele:
company = soup.find('h1', {'class': 'text-2xl font-semibold instrument-header_title__GTWDv mobile:mb-2'}).text
price = soup.find('div', {'class': 'instrument-price_instrument-price__3uw25 flex items-end flex-wrap font-bold'}).find_all('span')(0).text
change = soup.find('div', {'class': 'instrument-price_instrument-price__3uw25 flex items-end flex-wrap font-bold'}).find_all('span')(2).text
Nun zu einem Testlauf:
print('Loading: ', url)
print(company, price, change)
Und hier ist das Ergebnis:

3.. Kratzen Sie mehrere finanzielle Aktiendaten ab
Jetzt, da unser Parser arbeitet, skalieren wir dies auf und kratzen Sie mehrere Aktien. Schließlich ist ein Skript zur Verfolgung von nur einer Aktiendaten wahrscheinlich nicht sehr nützlich.
Wir können unseren Schaber auf mehrere Seiten analysieren und kratzen, indem wir eine Liste von URLs erstellen und sie durchführen, um die Daten auszugeben.
urls = (
'https://www.investing.com/equities/nike',
'https://www.investing.com/equities/coca-cola-co',
'https://www.investing.com/equities/microsoft-corp',
)
for url in urls:
page = requests.get(url)
soup = BeautifulSoup(page.text, 'html.parser')
company = soup.find('h1', {'class': 'text-2xl font-semibold instrument-header_title__GTWDv mobile:mb-2'}).text
price = soup.find('div', {'class': 'instrument-price_instrument-price__3uw25 flex items-end flex-wrap font-bold'}).find_all('span')(0).text
change = soup.find('div', {'class': 'instrument-price_instrument-price__3uw25 flex items-end flex-wrap font-bold'}).find_all('span')(2).text
print('Loading: ', url)
print(company, price, change)
Hier ist das Ergebnis nach dem Ausführen:
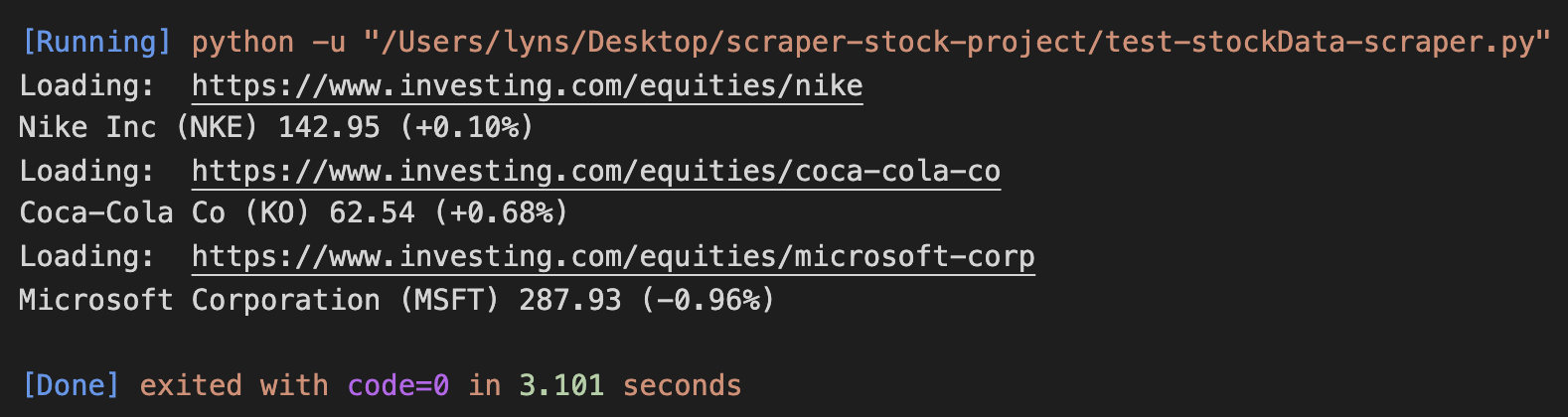
Super, es funktioniert auf ganzer Linie!
Wir können immer mehr Seiten zur Liste hinzufügen, aber schließlich werden wir eine große Straßensperre: Anti-Scraping-Techniken erreichen.
V.
Nicht jede Website wird aus gutem Grund gerne abgekratzt. Wenn wir eine Website abkratzen, müssen wir daran denken, dass wir den Datenverkehr an sie senden, und wenn wir nicht aufpassen, könnten wir die Bandbreite, die die Website für echte Besucher hat, oder sogar die Hostingkosten für den Eigentümer einschränken. Trotzdem haben wir keine Probleme mit unseren Projekten, solange wir das Web -Scraping -Best Practices respektieren, und wir werden die Websites, die wir Probleme kratzen, keine Probleme verursachen.
Für Unternehmen ist es jedoch schwierig, zwischen ethischen Schabern und denen zu unterscheiden, die ihre Websites brechen. Aus diesem Grund werden die meisten Server mit verschiedenen Systemen wie ausgestattet sein
- Browser -Verhaltensprofilerstellung
- Captchas
- Überwachung der Anzahl der Anforderungen einer IP -Adresse in einem Zeitraum
Diese Maßnahmen sind so konzipiert, dass sie Bots erkennen und sie für Tage, Wochen oder sogar für immer auf die Website zugreifen.
Anstatt alle diese Szenarien einzeln zu bewältigen, werden wir nur zwei Codezeilen hinzufügen, damit unsere Anfragen die Server von Scraperapis durchlaufen und alles für uns automatisiert werden.
Erstellen wir zunächst ein kostenloses Scraperapi -Konto, um auf unseren API -Schlüssel und 5000 kostenlose API -Credits für unser Projekt zuzugreifen.
Jetzt sind wir bereit, unserer Schleife eine neue Params -Variable hinzuzufügen, um unsere Schlüssel- und Ziel -URL zu speichern und mit Urlencode die URL zu konstruieren, mit der wir die Anforderung in der Seitenvariablen senden werden.
params = {'api_key': 'YOUR_API_KEY', 'url': url}
page = requests.get('http://api.scraperapi.com/', params=urlencode(params))
Oh! Und wir können nicht vergessen, unsere neue Abhängigkeit an die Spitze der Datei hinzuzufügen:
from urllib.parse import urlencode
Jede Anfrage wird nun über Scraperapi gesendet, wodurch unsere IP nach jeder Anfrage automatisch gedreht wird, Capchas verarbeitet und maschinelles Lernen und statistische Analysen verwendet werden, um die besten Header zu setzen, um den Erfolg zu gewährleisten.
Schneller Tipp: Mit Scraperapi können wir auch eine dynamische Site kratzen, indem wir „Render“ einstellen: TRUE als Parameter in unseren Params -Variablen. Scraperapi rendert die Seite, bevor er die Antwort zurücksendet.
5. Speichern Sie die extrahierten Finanzdaten in einer CSV -Datei
Um Ihre Daten in einer benutzerfreundlichen CSV-Datei zu speichern, fügen Sie einfach diese drei Zeilen zwischen Ihrer URL-Liste und Ihrer Schleife hinzu:
file = open('stockprices.csv', 'w')
writer = csv.writer(file)
writer.writerow(('Company', 'Price', 'Change'))=
Dadurch wird eine neue CSV -Datei erstellt und an unseren Schriftsteller (in der Autor -Variablen eingestellt) weitergeleitet, um die erste Zeile mit unseren Headern hinzuzufügen.
Es ist wichtig, es außerhalb der Schleife hinzuzufügen, oder es schreibt die Datei nach dem Abkratzen der Seite um, im Grunde genommen frühere Daten und gibt uns eine CSV -Datei mit nur den Daten aus der letzten URL aus unserer Liste.
Darüber hinaus müssen wir unserer Schleife eine weitere Zeile hinzufügen, um die abgekratzten Daten zu schreiben:
writer.writerow((company.encode('utf-8'), price.encode('utf-8'), change.encode('utf-8')))
Und noch einen außerhalb der Schleife, um die Datei zu schließen:
6. Fertiger Code: Börsenmärktungsdaten -Web -Scraper -Skript
Du hast es geschafft! Sie können dieses Skript jetzt mit Ihrem eigenen API -Schlüssel verwenden und so viele Aktien hinzufügen, wie Sie kratzen möchten:
#dependencies
import requests
from bs4 import BeautifulSoup
import csv
from urllib.parse import urlencode
#list of URLs
urls = (
'https://www.investing.com/equities/nike',
'https://www.investing.com/equities/coca-cola-co',
'https://www.investing.com/equities/microsoft-corp',
)
#starting our CSV file
file = open('stockprices.csv', 'w')
writer = csv.writer(file)
writer.writerow(('Company', 'Price', 'Change'))
#looping through our list
for url in urls:
#sending our request through ScraperAPI
params = {'api_key': 'YOUR_API_KEY', 'url': url}
page = requests.get('http://api.scraperapi.com/', params=urlencode(params))
#our parser
soup = BeautifulSoup(page.text, 'html.parser')
company = soup.find('h1', {'class': 'text-2xl font-semibold instrument-header_title__GTWDv mobile:mb-2'}).text
price = soup.find('div', {'class': 'instrument-price_instrument-price__3uw25 flex items-end flex-wrap font-bold'}).find_all('span')(0).text
change = soup.find('div', {'class': 'instrument-price_instrument-price__3uw25 flex items-end flex-wrap font-bold'}).find_all('span')(2).text
#printing to have some visual feedback
print('Loading :', url)
print(company, price, change)
#writing the data into our CSV file
writer.writerow((company.encode('utf-8'), price.encode('utf-8'), change.encode('utf-8')))
file.close()
Überlegen Sie, wann Sie Ihren Börsendatenschaber ausführen sollen
Sie müssen sich daran erinnern, dass der Aktienmarkt nicht immer geöffnet ist. Wenn Sie beispielsweise Daten von der Börse der NYC abkratzen, schließt sie freitags um 17 Uhr EST und öffnet am Montag um 9:30 Uhr. Es macht also keinen Sinn, über das Wochenende Ihren Schaber auszuführen. Es schließt auch um 16 Uhr, damit Sie danach keine Änderungen des Preises sehen.

Eine weitere Variable, die Sie beachten sollten, ist, wie oft Sie die Daten aktualisieren müssen. Die volatilsten Zeiten für die Börse sind die Öffnungs- und Schließzeiten. Es könnte also ausreichen, Ihr Skript um 9:30 Uhr, um 11 Uhr und um 16:30 Uhr auszuführen, um zu sehen, wie die Aktien geschlossen wurden. Die Eröffnung am Montag ist auch von entscheidender Bedeutung, um zu überwachen, da in dieser Zeit viele Geschäfte auftreten.
Im Gegensatz zu anderen Märkten wie Forex macht der Aktienmarkt in der Regel nicht zu viele verrückte Schwankungen. Allerdings können Nachrichten und Geschäftsentscheidungen häufig auf Aktienkurse auswirken – ein Meta -Aktien -Crash oder den Anstieg des GameStop -Aktienkurses als Beispiele -, so ist das Lesen der Nachrichten im Zusammenhang mit den Aktien, die Sie abkratzen, von entscheidender Bedeutung.
Planen Sie einfach Web -Scraping -Aktienmarktdaten mit Scraperapi's
Wir hoffen, dass dieses Tutorial Ihnen geholfen hat, Ihren eigenen Börsendatenschaber aufzubauen oder zumindest in die richtige Richtung zu zeigen.
Wenn Sie nach einer automatisierten Datenkratzlösung suchen, ist die Datenapipeline von Scraperapi eine gute Option. Die Planung Ihrer Aktienmärktungsdaten, die Projekte zum Abkratzen von Projekten einfach haben, müssen Sie sich also keine Sorgen um verschiedene Zeitzonen machen. Legen Sie einfach Ihre gewünschte Planungszeit fest, und das Web -Scraping -Tool von Scraperapi wird automatisch ausgeführt, wodurch Sie die neuesten Finanzdaten im strukturierten JSON -Format für Sie liefern. Melden Sie sich hier an, um mit einer 7-tägigen kostenlosen Testversion zu beginnen.
Bis zum nächsten Mal, glücklich zu kratzen!
(Tagstotranslate) Finanzdaten (T) Python (T) Börse (T) Web Scraping (T) Web Scraping Tipps
