Bereit, loszulegen? Lass uns eintauchen!
Google AI-Übersichten verstehen
Google AI Snippets oder Übersichten sind mehr als nur schnelle Antworten – sie stecken voller wertvoller Erkenntnisse. Wenn Google ein KI-generiertes Snippet oben in den Suchergebnissen anzeigt, liefert es die seiner Meinung nach beste Antwort auf eine Frage, basierend auf der Analyse von Millionen von Webseiten.
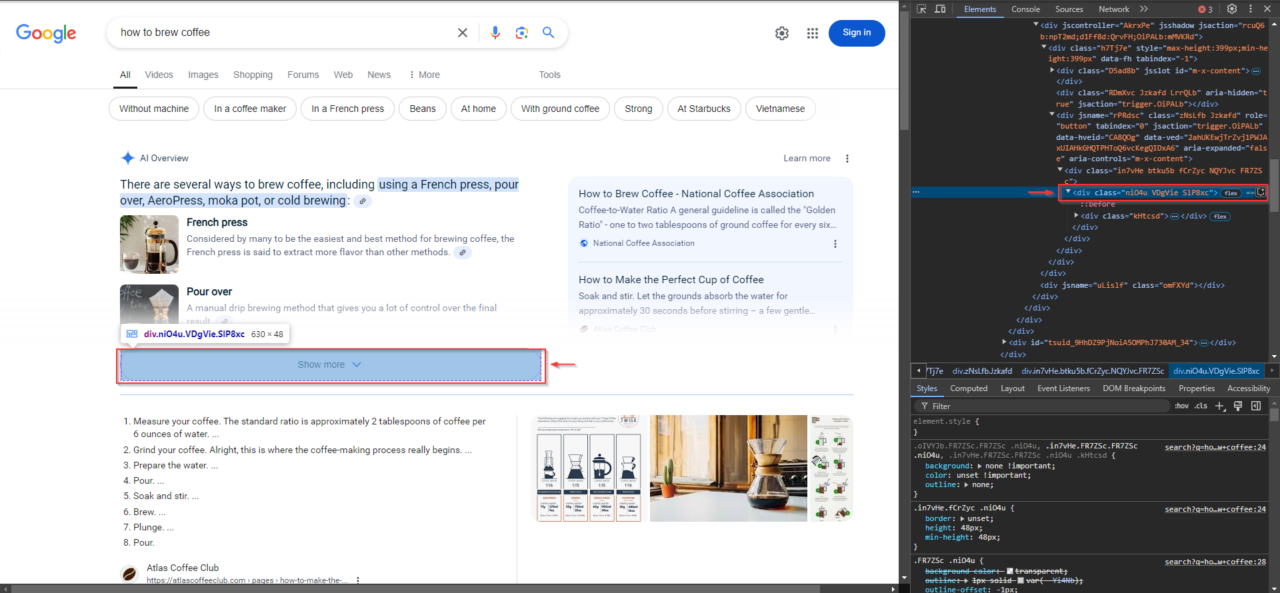
Schauen wir uns ein reales Beispiel an. Wenn Sie auf Google nach „Wie brüht man Kaffee“ suchen, wird möglicherweise eine KI-Übersicht angezeigt, die etwa so aussieht:
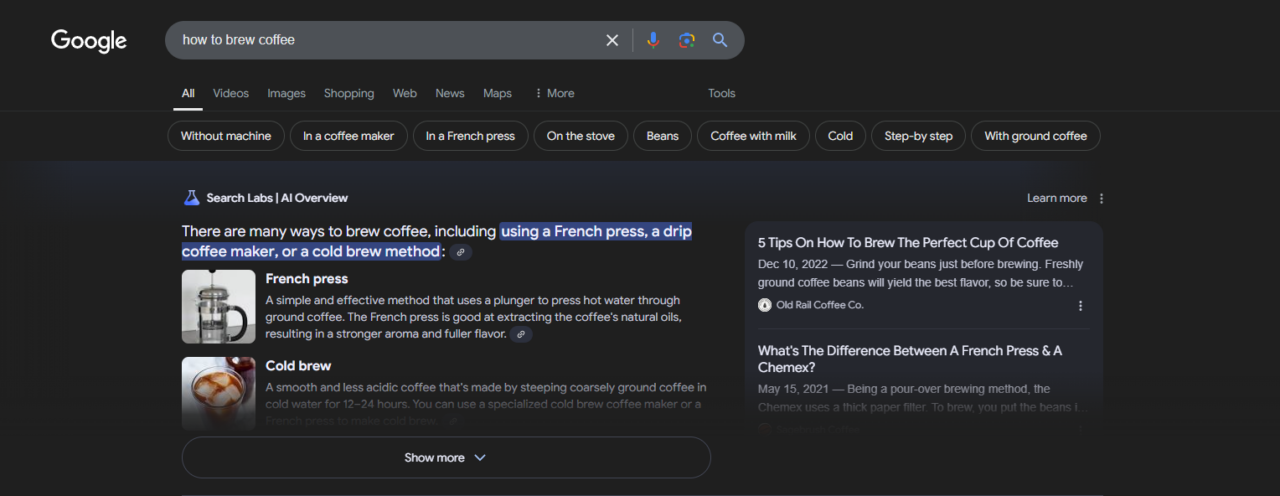
Um diese Daten effektiv zu extrahieren, ist es wichtig, die richtigen Selektoren für jeden Teil des Snippets zu identifizieren. So habe ich es gemacht:
1. Identifizieren der Inhaltsklasse
Der Hauptinhalt des AI-Snippets befindet sich in Elementen mit der Klasse WaaZC. Zu diesen Elementen gehören Textbeschreibungen und relevante Snippets zur Suchanfrage. Mit dem Inspect-Tool Ihres Browsers können Sie diese Klasse finden und sehen, wie Google diese Informationen strukturiert.
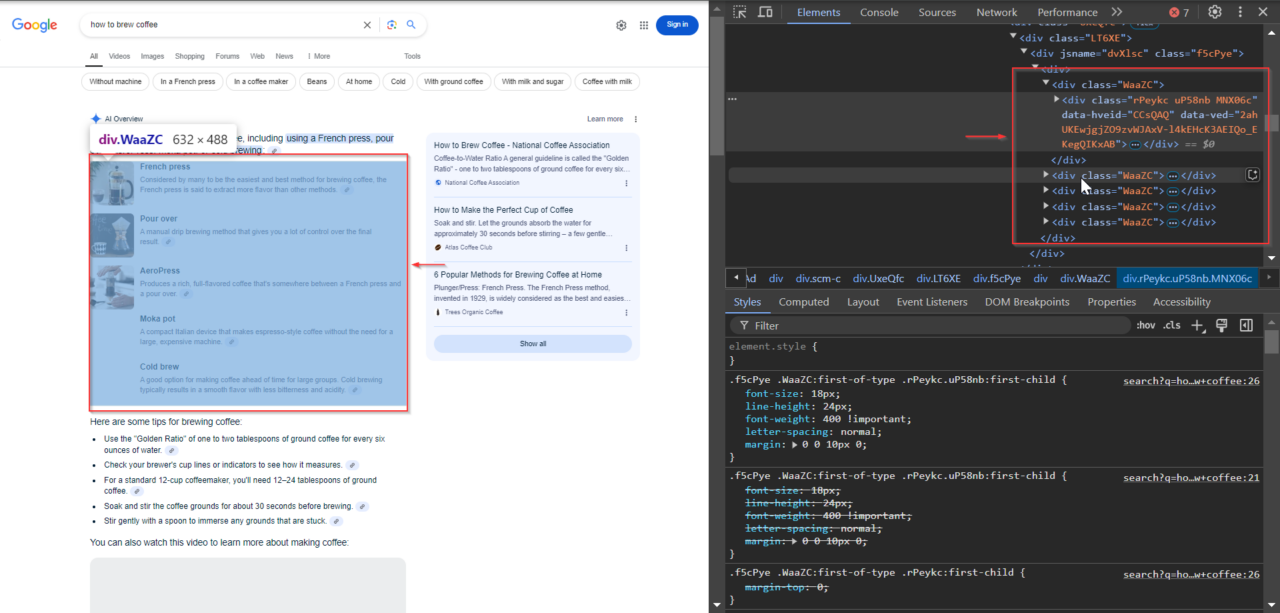
2. Finden der verwandten Links
Unter den Snippets fügt Google häufig verwandte Links zu maßgeblichen Quellen ein, die das Unternehmen zur Erstellung des Snippets verwendet hat. Diese Links befinden sich in Elementen mit der VqeGe-Klasse. Bei der Untersuchung der Struktur wird der Container sichtbar, der diese Links enthält, sodass sie zusammen mit dem Snippet extrahiert werden können.
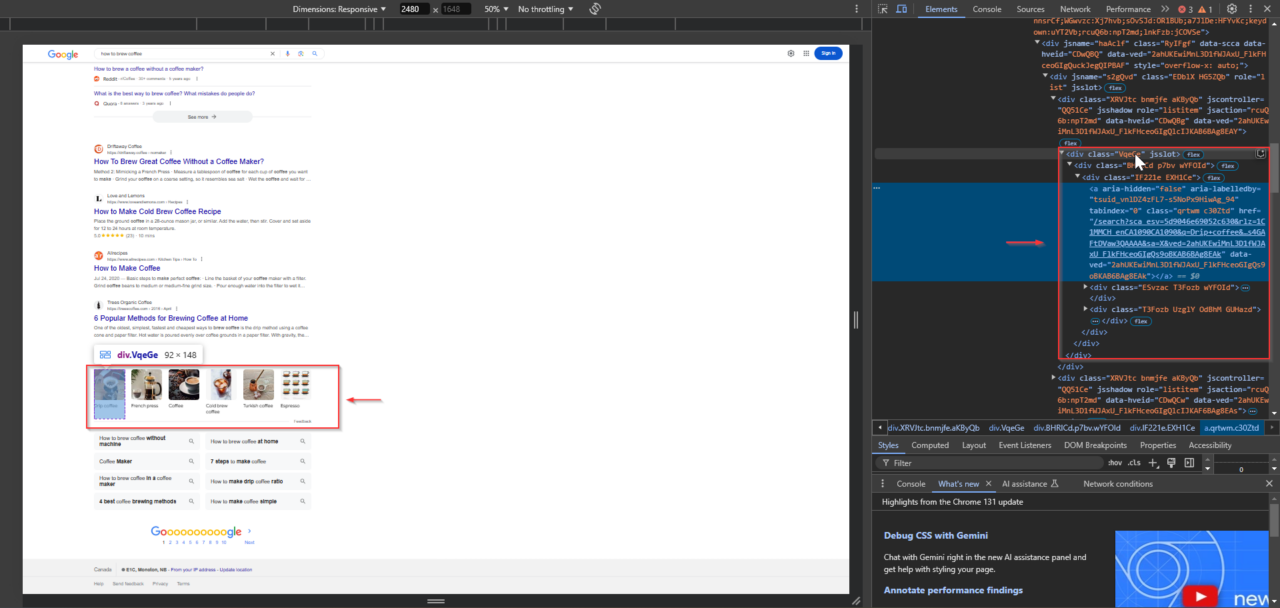
3. Suchen Sie die Schaltfläche „Mehr anzeigen“.
Bei Abfragen mit längeren AI-Snippet-Inhalten wird möglicherweise die Schaltfläche „Mehr anzeigen“ angezeigt. Diese Schaltfläche ist für die Erweiterung des Inhalts von entscheidender Bedeutung, um sicherzustellen, dass nichts übersehen wird. Um es zu identifizieren, klicken Sie mit der rechten Maustaste auf die Schaltfläche „Mehr anzeigen“ in Ihrem Browser und wählen Sie aus „Überprüfen“klicken Sie dann mit der rechten Maustaste auf das hervorgehobene Element im DevTools-Bereich und wählen Sie „XPath kopieren“.
Diese Ausschnitte können Ihnen helfen, Folgendes zu verstehen:
- Was die Leute wissen wollen: Indem Sie sich ansehen, welche Fragen KI-Snippets erhalten, können Sie ein Gefühl dafür bekommen, wonach Menschen suchen und wie Google ihre Fragen beantwortet. So können Sie schnell sehen, was beliebt und relevant ist.
- Worauf Google Wert legt: Google wählt bestimmte Arten von Antworten zur Hervorhebung aus, etwa Schritt-für-Schritt-Anleitungen, Listen oder kurze Definitionen. Wenn Sie auf diese Muster achten, können Sie erkennen, welche Arten von Inhalten die KI von Google am meisten schätzt.
- So verbessern Sie Ihre Inhalte: Da diese Snippets Googles Vorstellung von einer guten Antwort widerspiegeln, kann Ihnen das Studium ihres Wortlauts und ihrer Struktur dabei helfen, zu verstehen, wie Sie Ihre Inhalte suchfreundlicher gestalten können.
KI-Snippets enthalten häufig auch Links zu den Quellen, aus denen Google Informationen bezieht. Diese Links erhöhen die Glaubwürdigkeit des Snippets und zeigen, welche Websites Google für das Thema als maßgeblich erachtet. Das Scrapen dieser Links und des Snippets kann nützliche Zusammenhänge für weitere Recherchen aufdecken.
Der Zugriff auf diese Snippets kann eine Herausforderung sein, da Google aktiv versucht, den automatisierten Zugriff zu blockieren. Aber keine Sorge – dieser Leitfaden zeigt Ihnen genau, wie Sie diese Hindernisse umgehen und die benötigten Daten extrahieren!
Projektanforderungen
Folgendes benötigen Sie, um mit dem Projekt zu beginnen:
1. Selendraht
Selenium Wire ist eine Bibliothek, die die Funktionalität von Selenium erweitert. Dies erleichtert die Einrichtung von Proxys, sodass Ihre Anfragen so aussehen, als kämen sie von verschiedenen IP-Adressen. Diese Funktion ist von entscheidender Bedeutung, da Google Anfragen von derselben IP blockieren kann, wenn sie zu häufig eingehen.
Durch die Verwendung von Selenium Wire mit ScraperAPI können Sie Google-Suchen automatisieren und gleichzeitig das Risiko einer Blockierung minimieren. ScraperAPI kümmert sich um Dinge wie IP-Rotation und CAPTCHA-Lösung, die für eine reibungslose Interaktion mit den Suchmaschinen-Ergebnisseiten (SERP) von Google erforderlich sind.
Installieren Sie es mit pip:
pip install selenium selenium-wire
Sie benötigen außerdem ChromeDriver oder einen anderen kompatiblen WebDriver, der Ihrer Browserversion entspricht. Stellen Sie sicher, dass es in Ihrem verfügbar ist PATHoder geben Sie den Pfad in Ihrem Skript an.
2. ScraperAPI
Melden Sie sich bei ScraperAPI an, um Ihren API-Schlüssel zu erhalten, falls Sie dies noch nicht getan haben. Nach der Anmeldung erhalten Sie einen eindeutigen Schlüssel, den Sie zur Authentifizierung Ihrer Anfragen benötigen.
3. Schöne Suppe
BeautifulSoup hilft uns, die Suchergebnisse von Google effizient zu analysieren, nachdem ScraperAPI die Seite geladen hat.
Installieren Sie es mit pip:
pip install beautifulsoup4
Wenn diese Werkzeuge vorhanden sind, können wir mit dem Schaben beginnen!
So scrapen Sie Google AI Snippets mit ScraperAPI und Python
Nachdem wir nun KI-Snippets verstanden haben und unsere Tools bereit haben, beginnen wir mit dem eigentlichen Scraping-Prozess.
Schritt 1: Bibliotheken importieren und Variablen einrichten
Bevor wir uns mit den Hauptfunktionen befassen, beginnen wir mit dem Importieren der erforderlichen Bibliotheken und dem Einrichten der Variablen. Hier ist ein kurzer Überblick darüber, was die einzelnen Teile bewirken:
- Importe:
seleniumwire.webdriver: Dies ist das primäre Tool, mit dem wir den Browser steuern, sodass unser Skript mit den Google-Suchergebnissen interagieren kann, als wäre es ein echter Benutzer.selenium.webdriver.common.by: Wir verwenden dies, um Elemente auf der Seite zu finden, z. B. die Schaltfläche „Mehr anzeigen“ mitBy.XPATH.selenium.common.exceptions: Wir werden dies verwenden, um Fehler wie zu behandelnNoSuchElementExceptionUndTimeoutExceptionwodurch unser Skript widerstandsfähiger wird.time: Wir fügen Verzögerungen hinzutimeum dynamischen Inhalten die Möglichkeit zu geben, geladen zu werden, bevor wir sie entfernen.csv: Wir werden verwendencsvum unsere extrahierten Daten zur einfachen Analyse in einer CSV-Datei zu speichern.BeautifulSoup: Wir verwenden BeautifulSoup, um den HTML-Code der Seite zu analysieren, um die spezifischen Datenpunkte zu finden und zu extrahieren, die wir benötigen.
- Variablen:
url: Die URL der Google-Suchanfrage (z. B. „wie man Kaffee zubereitet“). Ändern Sie dies in eine beliebige Abfrage, die Sie durchsuchen möchten.show_more_xpath: Der XPath wird verwendet, um die Schaltfläche „Mehr anzeigen“ zu finden, damit wir versteckte Inhalte erweitern können, falls sie vorhanden sind.content_classUndlink_classes: CSS-Klassennamen, die uns dabei helfen, den KI-Snippet-Inhalt der Seite und zugehörige Links gezielt anzusprechen.output_file: Der Name der CSV-Datei, in der wir die extrahierten Daten speichern.max_retries: Legt die maximale Anzahl von Wiederholungsversuchen fest, wenn beim Scraping ein Fehler auftritt.
- ScraperAPI-Konfiguration:
API_KEY: Ersetzen"Your_ScraperAPI_Key"mit Ihrem einzigartigen ScraperAPI-Schlüssel.proxy_options: Konfiguriert die ScraperAPI-Proxy-Einstellungen für Selenium Wire.
Die Proxy-Port-Methode von ScraperAPI ist eine einfache Möglichkeit, Proxy-Funktionen wie IP-Rotation, CAPTCHA-Lösung und JavaScript-Rendering in Ihren Scraper zu integrieren. Anstatt mehrere komplexe Optionen zu konfigurieren, verbinden Sie sich einfach über einen Proxyserver, der alles für Sie erledigt.
So ist es in unserem Code eingerichtet:
proxy_options = {
'proxy': {
'https': f'http://scraperapi.render=true:{API_KEY}@proxy-server.scraperapi.com:8001',
'no_proxy': 'localhost,127.0.0.1'
}
}
proxy-server.scraperapi.com:8001: Dies ist der Proxyserver von ScraperAPI, der den Port überwacht8001. Es verarbeitet alle Anfragen, einschließlich IP-Rotation, CAPTCHA-Lösung und Darstellung von JavaScript-Inhalten.render=true: Dieser Parameter ermöglicht das JavaScript-Rendering, das für das vollständige Laden der dynamischen Seiten von Google unerlässlich ist.- Authentifizierung: Der
API_KEYist direkt in die Proxy-URL eingebettet und authentifiziert Ihre Anfragen, ohne dass eine zusätzliche Einrichtung erforderlich ist. - Ausschlüsse:
no_proxysorgt für lokale Anfragen (wielocalhost) umgehen den Proxy und vermeiden so unnötigen Overhead.
Die Verwendung dieser Methode vereinfacht die Proxy-Integration, sodass Sie sich auf Ihre Scraping-Logik konzentrieren können, während ScraperAPI die schwere Arbeit im Hintergrund übernimmt.
Ausführliche Informationen zur Proxy-Port-Methode und den Konfigurationsoptionen von ScraperAPI finden Sie in unserer Dokumentation.
Hier ist der vollständige Ersteinrichtungscode:
from seleniumwire import webdriver
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException, TimeoutException
import time
import csv
from bs4 import BeautifulSoup
# Variables
url = 'https://www.google.com/search?q=how+to+brew+coffee'
show_more_xpath = "/html/body/div(3)/div/div(13)/div(1)/div(2)/div/div/div(1)/div/div(1)/div/div/div/div(1)/div/div(3)/div/div"
content_class = "WaaZC"
link_classes = "VqeGe"
output_file = "extracted_data.csv"
max_retries = 3
# ScraperAPI configuration
API_KEY = "Your_Scraperapi_Key"
proxy_options = {
'proxy': {
'https': f'http://scraperapi.render=true:{API_KEY}@proxy-server.scraperapi.com:8001',
'no_proxy': 'localhost,127.0.0.1'
}
}
Schritt 2: Einrichten des WebDrivers
Als nächstes müssen wir den WebDriver einrichten, der uns die Steuerung des Browsers und die Interaktion mit Google ermöglicht. Der setup_driver Die Funktion initialisiert eine Selenium WebDriver-Instanz mit der Proxy-Konfiguration von ScraperAPI.
Diese Funktion öffnet auch die Ziel-URL (in diesem Beispiel eine Google-Suche nach „wie man Kaffee brüht“) und gibt die Treiberinstanz zurück.
def setup_driver():
driver = webdriver.Chrome(seleniumwire_options=proxy_options)
driver.get(url)
return driver
Durch den Aufruf dieser Funktion können wir den Treiber in mehreren Schritten wiederverwenden, ohne den Proxy jedes Mal neu zu konfigurieren oder den Browser neu zu öffnen.
Schritt 3: Klicken Sie auf die Schaltfläche „Mehr anzeigen“.
Manchmal enthalten die KI-Snippets von Google zusätzliche Informationen, die hinter einer Schaltfläche „Mehr anzeigen“ verborgen sind. Im Bild von vorhin zeigt das Snippet beispielsweise mehrere Kaffeezubereitungsmethoden, einige dieser Inhalte sind jedoch möglicherweise erst zugänglich, nachdem Sie auf „Mehr anzeigen“ geklickt haben.
Um sicherzustellen, dass wir alle verfügbaren Daten in diesen Snippets erfassen, muss unser Skript die Schaltfläche „Mehr anzeigen“ finden und darauf klicken, sofern sie vorhanden ist. Auf diese Weise können wir das Snippet erweitern und alle zusätzlichen Inhalte entfernen.
Der click_show_more Die Funktion versucht mithilfe ihres XPaths, die Schaltfläche „Mehr anzeigen“ zu finden und anzuklicken. Bei Erfolg wird „True“ zurückgegeben, wodurch der Rest unseres Codes weiß, dass der Inhalt erweitert wurde. Wenn die Schaltfläche nicht gefunden wird oder ein Fehler vorliegt, wird False zurückgegeben.
def click_show_more(driver):
"""Attempt to find and click the 'Show More' button"""
try:
element_to_click = driver.find_element(By.XPATH, show_more_xpath)
element_to_click.click()
print("Show More button clicked successfully.")
return True
except NoSuchElementException:
print("Show More button not found")
return False
except Exception as e:
print(f"Error clicking Show More button: {e}")
return False
Schritt 4: Inhalte und Links extrahieren
Sobald der Inhalt vollständig sichtbar ist, können wir mit dem Extrahieren beginnen. Die Funktion extract_content entfernt Textinhalte und zugehörige Links von der Seite.
- Textinhalt: Wir verwenden BeautifulSoup, um den Quell-HTML der Seite zu analysieren und alle Elemente mit der in definierten Klasse zu finden
content_class. Diese Klasse zielt auf die Abschnitte ab, die KI-Snippets enthalten. Der Text aus jedem Snippet wird extrahiert und in einem gespeichertcontentListe als Wörterbücher mit dem Schlüssel"Section Text". - Verwandte Links: Ebenso suchen wir verwandte Linkelemente mit
link_classes. Jeder LinkhrefDas Attribut (die URL) wird in einer Linkliste als Wörterbücher mit dem Schlüssel gespeichert"Related Links".
Beide content und Linklisten werden zusammengefasst combined_datadas alle extrahierten Informationen enthält, die im nächsten Schritt gespeichert werden sollen.
def extract_content(driver):
"""Extract text content and links from the specified elements"""
content = ()
links = ()
try:
# Extracting text content
soup = BeautifulSoup(driver.page_source, 'html.parser')
text_elements = soup.find_all('div', class_=content_class)
for text_element in text_elements:
extracted_text = text_element.text
print(f"Extracted Text: {extracted_text}")
content.append({"Section Text": extracted_text})
except Exception as e:
print(f"Error extracting content: {e}")
try:
# Extracting related links
related_link_divs = soup.find_all('div', class_=link_classes)
for div in related_link_divs:
href = div.find('a')('href')
print(href)
links.append({"Related Links": href})
except Exception as e:
print(f"Error extracting links: {e}")
# Combine content and links into a single list for CSV
combined_data = content + links
return combined_data
Schritt 5: Daten in einer CSV-Datei speichern
Nachdem wir die Daten nun gesammelt haben, ist es an der Zeit, sie zur Analyse zu speichern. Der save_to_csv Die Funktion schreibt den extrahierten Inhalt und die Links in eine CSV-Datei.
So machen wir es:
- Suchen Sie nach Daten: Zuerst prüfen wir, ob Daten gespeichert werden können. Wenn nicht, geben wir eine Nachricht aus und beenden die Funktion sofort.
- CSV-Datei öffnen: Wenn Daten verfügbar sind, öffnen (oder erstellen) wir eine CSV-Datei mit dem in angegebenen Namen
output_file. Wir setzen die Überschriften auf „Abschnittstext“ und „Verwandte Links“, um sie an unsere Datenstruktur anzupassen. - Daten schreiben: Zum Schluss schreiben wir jeden Eintrag aus
combined_dataZeile für Zeile in die CSV-Datei einfügen, um für die Analyse bereit zu sein.
def save_to_csv(data, filename):
"""Save extracted data to CSV file"""
if not data:
print("No data to save")
return False
headers = ('Section Text', 'Related Links')
try:
with open(filename, 'w', newline='', encoding='utf-8') as file:
writer = csv.DictWriter(file, fieldnames=headers)
writer.writeheader()
for item in data:
writer.writerow(item)
print(f"Data saved to {filename} successfully.")
return True
except Exception as e:
print(f"Error saving to CSV: {e}")
return False
Dadurch wird sichergestellt, dass unsere extrahierten Daten sicher in einem benutzerfreundlichen CSV-Format gespeichert werden.
Schritt 6: Alles in der Hauptfunktion zusammenführen
Lassen Sie uns nun alles in unserem zusammenführen main Funktion zur Abwicklung des gesamten Schabevorgangs von Anfang bis Ende. So machen wir es:
- Wiederholungslogik: Wir beginnen mit der Einstellung
retry_countauf Null, um den Scraping-Vorgang bis zu wiederholenmax_retrieswenn irgendwelche Probleme auftauchen. - WebDriver initialisieren: Wir rufen an
setup_driver()um den Browser zu öffnen und die Suchseite zu laden. - Klicken Sie auf „Mehr anzeigen“ und extrahieren Sie den Inhalt: Wir versuchen es
click_show_more()nächste. Wenn der Klick zum Erweitern weiterer Inhalte erfolgreich ist, extrahieren wir alle sichtbaren Daten mitextract_content(). - Daten im CSV-Format speichern: Wir rufen an
save_to_csv()um es in die CSV-Datei zu schreiben, sobald wir Daten haben. Wenn dieser Schritt erfolgreich abgeschlossen wurde, sind wir fertig! - Schließen Sie den Browser und versuchen Sie es bei Bedarf erneut: Nach jedem Versuch schließen wir den WebDriver und warten 2 Sekunden, bevor wir es bei Bedarf erneut versuchen. Wenn die Anzahl der Wiederholungsversuche ausgeschöpft ist, werden wir in einer Meldung darüber informiert, dass wir das Limit erreicht haben.
def main():
retry_count = 0
while retry_count
Vergessen Sie zum Schluss nicht, Ihre Hauptfunktion aufzurufen, um alles in Gang zu setzen und Ihre Daten zu extrahieren:
if __name__ == "__main__":
main()
Hier ist ein Beispiel dafür, wie die CSV-Datei aussehen könnte:
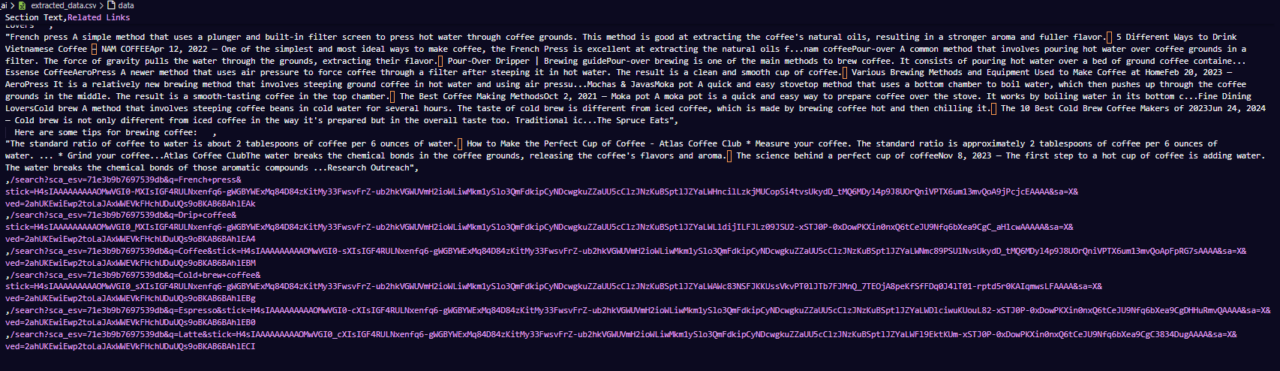
Dieser letzte Schritt fasst alles zusammen und gibt uns ein vollautomatisches Skript, das bereit ist, Google AI-Snippets zu extrahieren und zur Analyse zu speichern!
Vollständiger Code
Hier ist der vollständige Code, wenn Sie direkt mit dem Scrapen beginnen möchten:
from seleniumwire import webdriver
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException, TimeoutException
import time
import csv
from bs4 import BeautifulSoup
# Variables
url = 'https://www.google.com/search?q=how+to+brew+coffee'
show_more_xpath = "/html/body/div(3)/div/div(13)/div(1)/div(2)/div/div/div(1)/div/div(1)/div/div/div/div(1)/div/div(3)/div/div"
content_class = "WaaZC"
link_classes = "VqeGe"
output_file = "extracted_data.csv"
max_retries = 3
# ScraperAPI configuration
API_KEY = "Your_ScraperAPI_Key"
proxy_options = {
'proxy': {
'https': f'http://scraperapi.render=true:{API_KEY}@proxy-server.scraperapi.com:8001',
'no_proxy': 'localhost,127.0.0.1'
}
}
def setup_driver():
driver = webdriver.Chrome(seleniumwire_options=proxy_options)
driver.get(url)
return driver
def click_show_more(driver):
"""Attempt to find and click the 'Show More' button"""
try:
element_to_click = driver.find_element(By.XPATH, show_more_xpath)
element_to_click.click()
print("Show More button clicked successfully.")
return True
except NoSuchElementException:
print("Show More button not found")
return False
except Exception as e:
print(f"Error clicking Show More button: {e}")
return False
def extract_content(driver):
"""Extract text content and links from the specified elements"""
content = ()
links = ()
try:
# Extracting text content
soup = BeautifulSoup(driver.page_source, 'html.parser')
text_elements = soup.find_all('div', class_=content_class)
for text_element in text_elements:
extracted_text = text_element.text
print(f"Extracted Text: {extracted_text}")
content.append({
"Section Text": extracted_text
})
except Exception as e:
print(f"Error extracting content: {e}")
try:
# Extracting related links
related_link_divs = soup.find_all('div', class_=link_classes)
for div in related_link_divs:
href = div.find('a')('href')
print(href)
links.append({
"Related Links": href
})
except Exception as e:
print(f"Error extracting links: {e}")
# Combine content and links into a single list for CSV
combined_data = content + links
return combined_data
def save_to_csv(data, filename):
"""Save extracted data to CSV file"""
if not data:
print("No data to save")
return False
# Define the CSV headers
headers = ('Section Text', 'Related Links')
try:
with open(filename, 'w', newline='', encoding='utf-8') as file:
writer = csv.DictWriter(file, fieldnames=headers)
writer.writeheader()
for item in data:
writer.writerow(item)
print(f"Data saved to {filename} successfully.")
return True
except Exception as e:
print(f"Error saving to CSV: {e}")
return False
def main():
retry_count = 0
while retry_count
Extra-Tipps: Umgang mit fehlenden KI-Snippets
Manchmal wird das KI-Snippet von Google selbst bei gut formulierten Abfragen nicht konsistent angezeigt. Hier sind ein paar zusätzliche Tipps, die Ihnen bei der Bewältigung von Fällen helfen, in denen das KI-Snippet nicht sofort verfügbar ist:
1. Erhöhen Sie die Anzahl der Wiederholungsversuche
Unser aktueller Code enthält bereits Wiederholungslogik. Wenn KI-Schnipsel jedoch inkonsistent angezeigt werden, sollten Sie eine Erhöhung in Betracht ziehen max_retries. Wenn Sie mehr Versuche zulassen, hat das Skript eine bessere Chance, das Snippet zu erfassen, wenn es bei einem späteren Versuch geladen wird. Beginnen Sie damit, die Wiederholungsversuche zu verdoppeln, wenn nach Ihren ersten Versuchen Snippets fehlen.
2. Fügen Sie leichte Verzögerungen zwischen den Wiederholungsversuchen hinzu
Einführung einer kleinen Verzögerung zwischen den Wiederholungsversuchen, like time.sleep(5)kann die Ergebnisse verbessern, indem Google zusätzliche Zeit zum Laden des Snippets erhält. Das Hinzufügen dieser Verzögerung nach jedem erneuten Versuch trägt dazu bei, zu vermeiden, dass Google wiederholt zu schnell aufgerufen wird, was ebenfalls zu Ratenbegrenzungen führen könnte.
3. Experimentieren Sie mit ähnlichen Abfragen
Wenn Sie das KI-Snippet immer noch nicht sehen, kann es hilfreich sein, mit leicht unterschiedlichen Abfragevarianten zu experimentieren, die das Snippet zuverlässiger auslösen könnten. Wenn Ihre erste Frage beispielsweise „Wie bereitet man Kaffee“ lautet, versuchen Sie es mit verwandten Formulierungen wie „Beste Art, Kaffee zuzubereiten“ oder „Schritte zum Zubereiten von Kaffee“.
4. Protokollieren Sie das Ergebnis jedes Versuchs
Erwägen Sie das Hinzufügen einer Protokollierungsfunktion, um zu verfolgen, ob bei jedem Versuch ein Snippet erfolgreich erfasst wird. Dies hilft Ihnen, Muster im Laufe der Zeit zu analysieren – etwa bei bestimmten Abfragen oder wenn Snippets häufiger auftauchen –, sodass Sie Ihren Ansatz bei Bedarf verfeinern können.
5. Auf leere Daten überwachen
Wenn extract_content() Gibt nach allen Wiederholungsversuchen ein leeres Ergebnis zurück, sollten Sie es als erfolglosen Versuch protokollieren. Wenn Sie nachverfolgen, welche Abfragen keine Snippets auslösen, können Sie Ihren Ansatz anpassen und vermeiden, dass diese Abfragen wiederholt gelöscht werden.
Zusammenfassung
Und das ist es! Die KI-Snippets von Google geben nicht nur schnelle Antworten – sie zeigen auch, wofür sich die Leute interessieren, was im Trend liegt und welche Inhalte Google schätzt. Durch die Erfassung und Analyse dieser Snippets sammeln Sie Daten und gewinnen Erkenntnisse, die Ihnen bei der Erstellung relevanterer und wirkungsvollerer Inhalte helfen können.
Mit den von uns beschriebenen Schritten verfügen Sie über alles, was Sie zum Sammeln dieser Daten benötigen. Um es noch einfacher zu machen, probieren Sie ScraperAPI aus – es übernimmt die IP-Rotation, CAPTCHAs und das Rendering, sodass Sie diese Erkenntnisse nutzen können, um Ihre Content-Strategie zu verbessern, ohne sich um die technischen Hürden kümmern zu müssen.
Viel Spaß beim Schaben!
