
Was ist Snscrape (Python)?
Snscrape ist eine Open-Source-Python-Bibliothek, mit der Sie Daten aus sozialen Netzwerkdiensten (SNS) extrahieren können. Für X.com umfasst dies das Scrapen von Benutzerprofilen, Hashtags, Suchanfragen, Tweets (einzelner oder umgebender Thread), Listenbeiträgen und Trends.
Da wir Snscrape anstelle der Twitter-API verwenden, müssen wir uns keine Gedanken über Scraping-Limits machen, sodass Sie X.com-Daten für verschiedene Anwendungsfälle aggregieren können.
Vorbereitung des Twitter (X.com) Scraping-Projekts
Um das X.com-Scraping-Projekt zu starten, öffnen wir ein neues Verzeichnis auf VScode (oder Ihrer bevorzugten IDE) und öffnen ein Terminal. Von dort aus installieren Sie Snscrape einfach mit pip:
Alle erforderlichen Dateien werden automatisch heruntergeladen. Damit es funktioniert, muss jedoch Python 3.8 oder höher installiert sein. Um Ihre Python-Version zu überprüfen, verwenden Sie den Befehl python –version auf Ihrem Terminal.
Notiz:Wenn Sie es noch nicht haben, installieren Sie Pandas auch mit pip install pandas. Wir verwenden es, um die gescrapten Daten zu visualisieren und alles in eine CSV-Datei zu exportieren.
Erstellen Sie als Nächstes eine neue Datei mit dem Namen tweet-scraper.py und importieren Sie die Abhängigkeiten oben:
import snscrape.modules.twitter as sntwitter
import pandas as pd
Und jetzt können wir mit dem Scrapen der Daten beginnen!
Die Struktur der Antwort von X.com verstehen
Genau wie bei Websites müssen wir die Struktur der von Snscrape bereitgestellten Twitter-Daten verstehen, damit wir die Datenbits auswählen können, die uns tatsächlich interessieren.
Nehmen wir an, wir möchten wissen, worüber die Leute zum Thema Web Scraping sprechen. Um dies zu ermöglichen, müssen wir über das Twitter-Modul von Snscrape eine Anfrage wie folgt an Twitter senden:
query = "web scraping"
for tweet in sntwitter.TwitterSearchScraper(query).get_items():
print(vars(tweet))
break
Die Methode .TwitterSearchScraper() ähnelt im Grunde der Verwendung der Suchleiste von Twitter auf der Website. Wir übergeben ihm eine Abfrage (in unserem Fall Web Scraping) und erhalten die aus der Suche resultierenden Elemente.
Weitere Snscrape-Methoden
Hier ist eine Liste aller anderen Methoden, mit denen Sie Twitter mithilfe des Sntwitter-Moduls abfragen können:
- TwitterSearchScraper
- TwitterUserScraper
- TwitterProfileScraper
- TwitterHashtagScraper
- TwitterTweetScraperMode
- TwitterTweetScraper
- TwitterListPostsScraper
- TwitterTrendsScraper
Während die Funktion vars() alle Attribute eines Elements zurückgibt, in diesem Fall tweet.
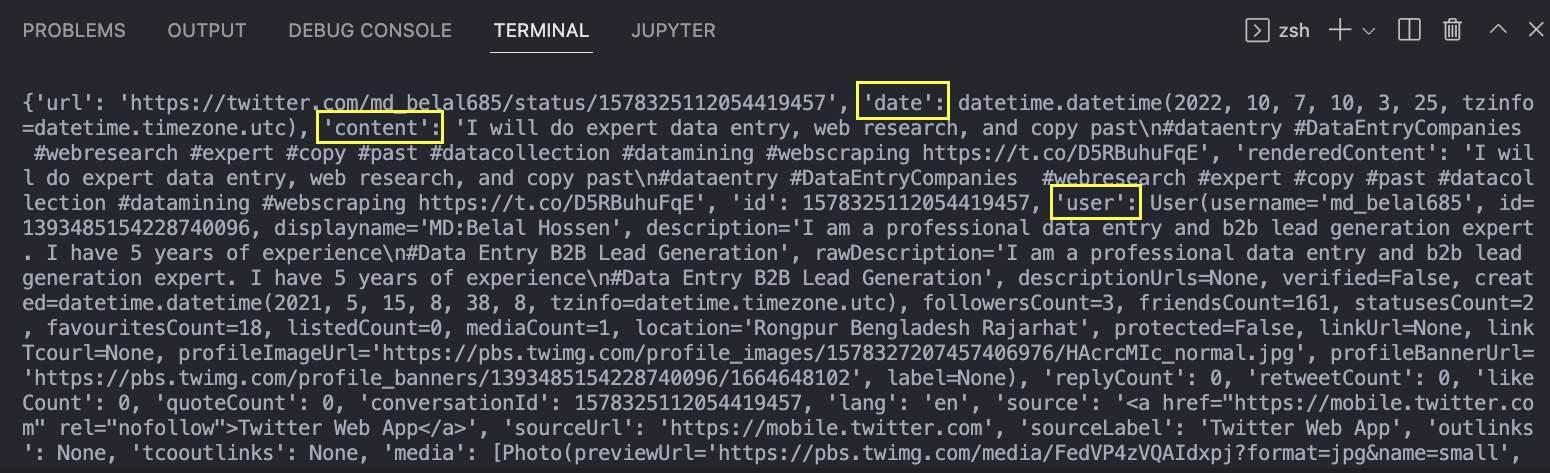
Der zurückgegebene JSON enthält alle mit dem Tweet verknüpften Informationen. Im Bild haben wir die drei für uns wichtigsten angeheftet: die Daten des Tweets, den Inhalt des Tweets (also den Tweet selbst) und den Benutzer, der ihn getwittert hat.
Wenn Sie bereits mit JSON-Daten gearbeitet haben, ist der Zugriff auf den Wert dieser Felder einfach:
- tweet.datum
- tweet.content
- tweet.user.username
Der dritte ist anders, weil wir nicht den gesamten Wert von „user“ wollen, sondern stattdessen auf das Feld „user“ zugreifen und dann nach unten zum Feld „username“ gehen.
Scraping komplexer Twitter-Anfragen in Snscrape
Obwohl es mehrere Möglichkeiten gibt, Ihre Abfragen zu erstellen, ist es am einfachsten, die Suchleiste von Twitter zu verwenden, um eine Abfrage mit genau den Parametern zu generieren, die wir benötigen.
Gehen Sie zunächst zu Twitter und geben Sie die gewünschte Suchanfrage ein:
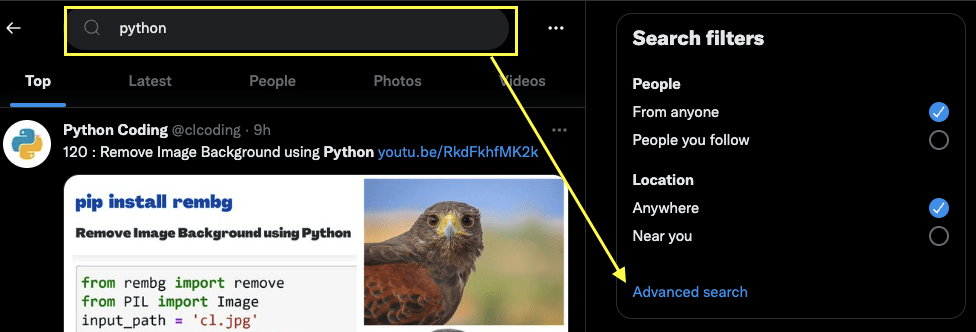
Und nun klicken Sie auf Erweiterte Suche:
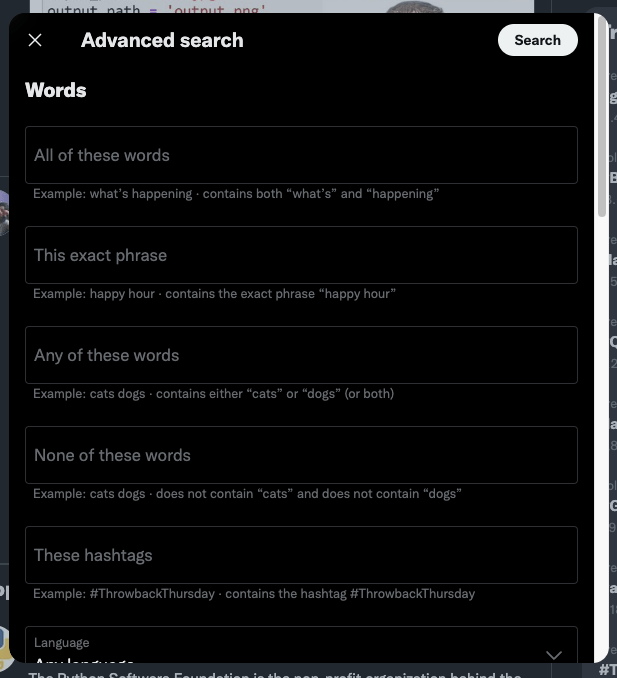
Füllen Sie nun das Formular mit dem Parameter aus, der Ihren Anforderungen entspricht. Für dieses Beispiel verwenden wir die folgenden Informationen:
| Feld | Wert |
|---|---|
| Genau diese Worte | Web-Scraping |
| Sprache | Englisch |
| Ab Datum | 12. Januar 2022 |
| Miteinander ausgehen | 12. Juni 2023 |
Notiz: Sie können auch bestimmte Konten und Filter festlegen und weniger restriktive Wortkombinationen verwenden.
Sobald das fertig ist, klicken Sie oben rechts auf die Suchschaltfläche.
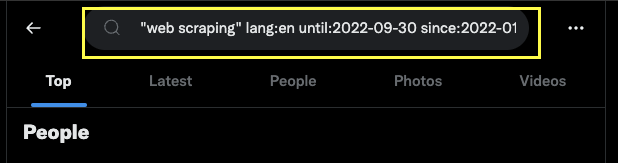
Es wurde eine benutzerdefinierte Abfrage erstellt, die wir in unserem Code verwenden können, um sie an die TwitterSearchScraper()-Methode zu übergeben.
Legen Sie ein Limit für Ihren Twitter Scraper fest
Es gibt VIELE Tweets auf Twitter. Es werden einfach unglaublich viele Tweets jeden Tag generiert. Legen wir also ein Limit für die Anzahl der Tweets fest, die wir löschen möchten, und unterbrechen wir die Schleife, sobald wir dieses erreicht haben.
Das Festlegen des Limits ist ganz einfach:
Wenn wir Tweets jedoch nur ausdrucken, wird es nie wirklich eine Grenze geben. Damit es funktioniert, müssen wir die Tweets in einer Liste speichern.
Mit diesen beiden Elementen können wir unserer for-Schleife ohne Probleme die folgende Logik hinzufügen:
for tweet in sntwitter.TwitterSearchScraper(query).get_items():
if len(tweets) == limit:
break
else:
tweets.append((tweet.date, tweet.user.username, tweet.content))
Erstellen eines Datenrahmens mit Pandas
Nur zum Testen ändern wir den Grenzwert auf 10 und drucken das Array aus, um zu sehen, was es zurückgibt:

Etwas schwer zu lesen, aber Sie können die beiden Benutzernamen, die Daten und die Tweets deutlich erkennen. Perfekt!
Geben wir ihm nun eine bessere Struktur, bevor wir die Daten exportieren. Bei Pandas müssen wir lediglich unser Array an die Methode .DataFrame() übergeben und die Spalten erstellen.
df = pd.DataFrame(tweets, columns=('Date', 'User', 'Tweet'))
#print(df)
Notiz: Diese sollten mit den von uns gescrapten Daten und der Reihenfolge, in der sie gescrapt werden, übereinstimmen.
Sie können den Datenrahmen ausdrucken, um sicherzustellen, dass Sie alle in der Limit-Variablen angegebenen Tweets erhalten, aber das sollte problemlos funktionieren.
Exportieren Ihres Datenrahmens in eine CSV/JSON-Datei
Wie könnte man Python nicht lieben, wenn es das Exportieren so einfach macht?
Lassen Sie uns das Limit auf 1000 setzen und unser Skript ausführen!
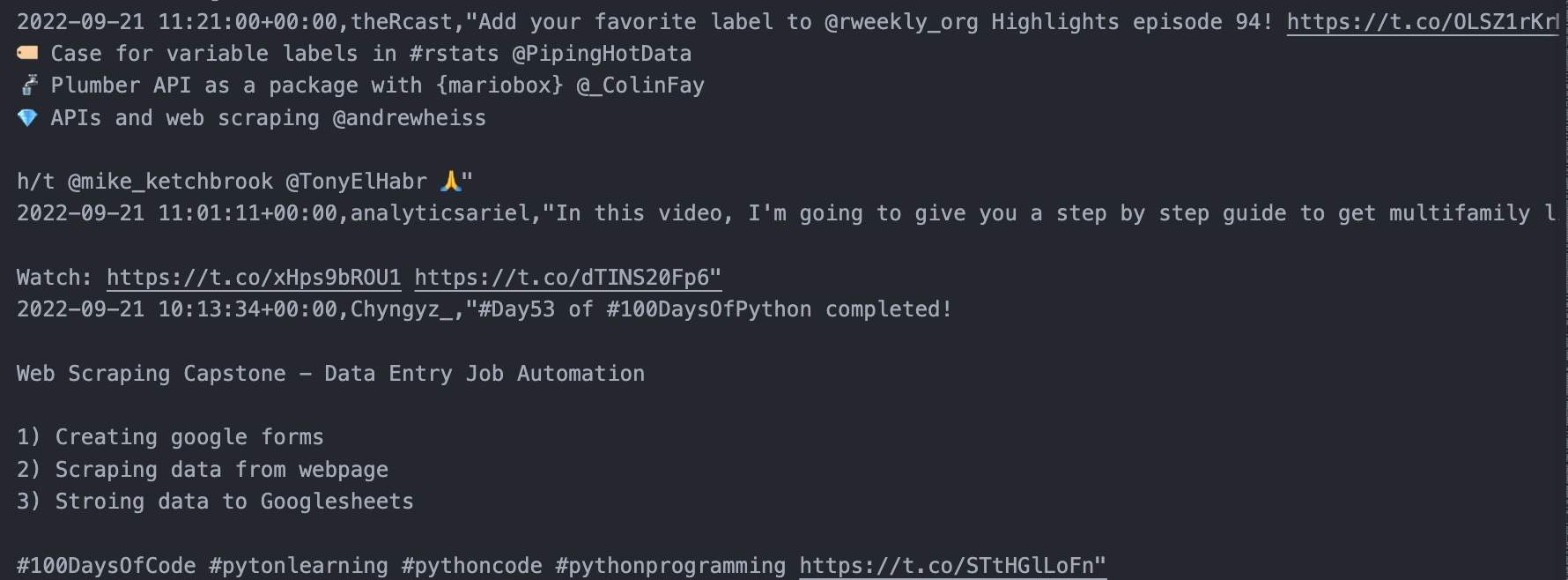
Exportieren in CSV:
df.to_csv('scraped-tweets.csv', index=False, encoding='utf-8')
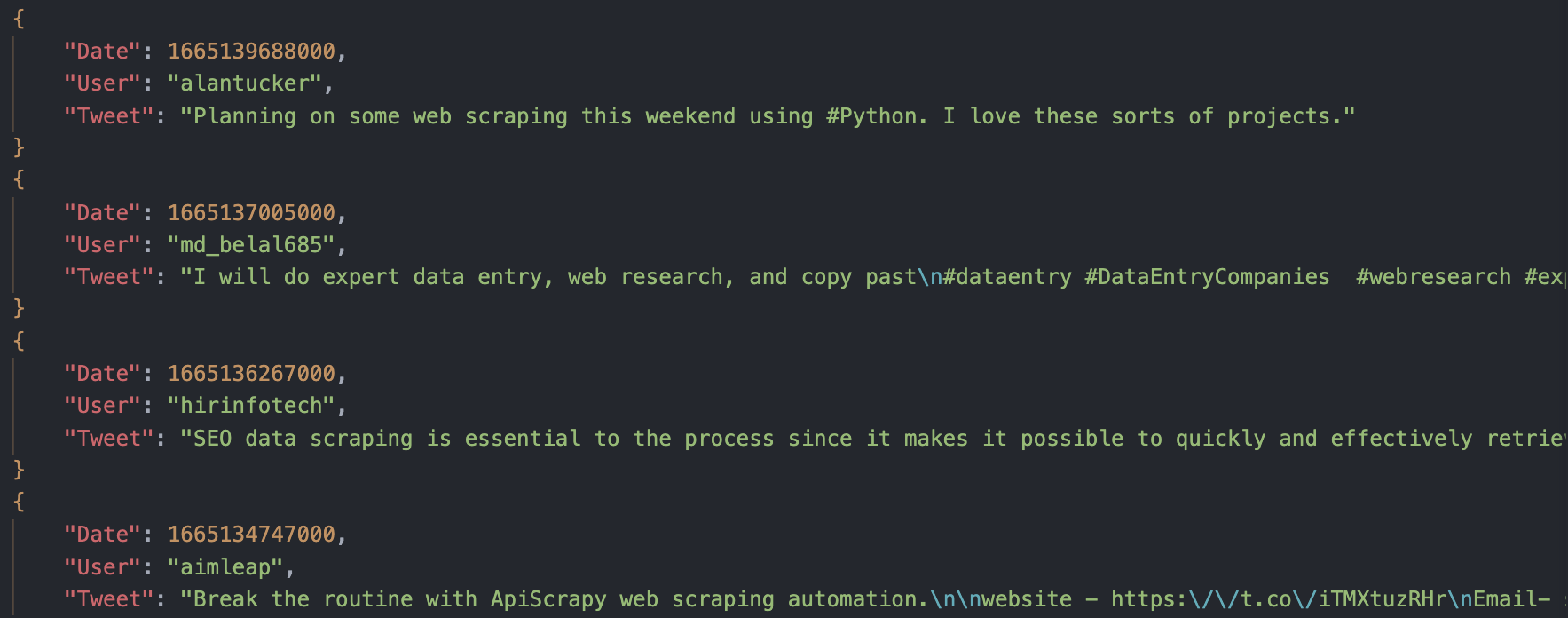
Export nach JSON:
df.to_json('scraped-tweets.json', orient='records', lines=True)
Notiz: Natürlich wird das Skript länger als zuvor brauchen, um alle Daten zu extrahieren. Machen Sie sich also keine Sorgen, wenn es ein paar Minuten dauert, bis die Tweets zurückgegeben werden.
Glückwunsch! Sie haben gerade in wenigen Minuten 1.000 Tweets von Januar bis September 2022 gecrawlt.
Mit dieser Methode können Sie Tweets aus jedem Zeitbereich herausfiltern und beliebige Filter verwenden, um Ihre Recherche präziser zu gestalten.
Einfaches Scrapen von X.com (Twitter).
Snscrape ist ein nützliches Tool für Anfänger und Profis zum Sammeln von X.com-Daten mit einer einfach zu verwendenden API.
Damit können Sie alle wichtigen Details aus Tweets sammeln, ohne komplizierte Workarounds erstellen oder Hunderttausende Dollar für die Twitter-API ausgeben zu müssen.
Bis zum nächsten Mal, viel Spaß beim Twitter-Scraping!
Schauen Sie sich diese Web-Scraping-Tutorials für soziale Medien und Foren an:
