
Warum Alternativen zu ScrapingBee in Betracht ziehen?
Während ScrapingBee nützliche Funktionen bietet, machen einige Einschränkungen die Verwendung seiner Automatisierungsfunktionen weniger attraktiv:
- Erweiterte Funktionen wie JavaScript-Rendering und Premium-Proxys verbrauchen mehr API-Credits, was zu höheren Kosten führt.
- Die Bearbeitung von Millionen von Anfragen kann umständlich und teuer werden. Einige Benutzer stoßen beim Scraping bestimmter Websites auf Einschränkungen, was auf mögliche Einschränkungen bei den Scraping-Funktionen des Tools hinweist.
- Für blockierte Anfragen werden oft Credits berechnet.
Was jedoch noch wichtiger ist, ist, dass ScrapingBee im Hinblick auf die Automatisierung durch die Abhängigkeit von einem Drittanbieter-Tool bedeutet, dass Sie sich um ein weiteres Abonnement kümmern müssen und außerdem den Aufwand erleiden müssen, den Prozess scheinbar nicht in Ihren Workflow integrieren zu können.
Lassen Sie uns vor diesem Hintergrund die besten ScrapingBee-Alternativen erkunden, die für bestimmte Anwendungsfälle im Zusammenhang mit der automatischen Datenerfassung geeignet sein könnten.
1. ScraperAPI (Bestes Web-Scraping-Automatisierungstool für Entwicklerteams)
ScraperAPI behebt viele der Einschränkungen von ScrapingBee und bietet erweiterte Funktionen, die besser für Entwickler und Großprojekte geeignet sind.
ScraperAPI konzentriert sich auf die Bereitstellung eines leistungsstarken automatisierten Scraping-Erlebnisses mit minimalem Overhead. Seine API wurde entwickelt, um umfangreiche Datenextraktionsaufgaben effizient zu bewältigen und Benutzern einen schnellen und zuverlässigen Zugriff auf Webdaten zu ermöglichen.
Die fortschrittliche Anti-Bot-Erkennung von ScraperAPI beherrscht auch fortschrittliche Bot-Blocker wie DataDome und PerimeterX, Javascript-Rendering und automatische CAPTCHA-Lösung, um eine Erfolgsquote von nahezu 100 % zu gewährleisten.
Schauen wir uns einige der besten Automatisierungsfunktionen von ScraperAPI genauer an:
DataPipeline (gehosteter Scraping-Scheduler)
DataPipeline ist ein benutzerfreundlicher Web-Scraping-Planer, der Ihre Web-Scraping-Aufgaben vereinfacht und automatisiert. Mit DataPipeline können Sie bis zu 10.000 URLs, Schlüsselwörter, Amazon-ASINs oder Walmart-IDs gleichzeitig ausführen und komplexe Scraper erstellen, ohne benutzerdefinierte Scraping-Skripte zu pflegen, Proxys zu verwalten oder CAPTCHAs zu verwalten.
Benutzer können vorkonfigurierte Jobs für benutzerdefinierte URLs und strukturierte Datenendpunkte planen, ihre Ergebnisse in JSON oder CSV abrufen oder sie an einen Webhook liefern lassen. Dies erleichtert die Integration in Ihre bestehende Architektur.

Notiz: Um zu beginnen, erstellen Sie einfach ein kostenloses ScraperAPI-Konto. Dadurch erhalten Sie Zugriff auf DataPipeline und 5.000 API-Credits um mit dem Schaben zu beginnen.
ScraperAPI hat kürzlich eine neue Funktion eingeführt, um Benutzern mehr Kontrolle über ihre DataPipeline-Projekte zu geben. Mit den DataPipeline-Endpunkten können Benutzer ihre Interaktionen mit der DataPipeline über eine Liste von APIs automatisieren und so Benutzern, die mehrere Projekte gleichzeitig verwalten, mehr Effizienz und Flexibilität bieten.
Mit dieser neuen Funktion können Benutzer ihre Projekte über eine API statt über das Dashboard einrichten, bearbeiten und verwalten, was eine bessere Integration in Ihren Workflow und noch mehr Optionen zur Automatisierung ganzer Scraping-Szenarien bietet.
Sehen wir uns ein Beispiel für die Erstellung eines DataPipeline-Projekts mithilfe des API-Endpunkts an:
curl -X POST \
-H 'Content-Type: application/json' \
--data '{ "name": "Google search project", "projectInput": {"type": "list", "list": ("iPhone", "Android") }, "projectType": "google_search", "notificationConfig": {"notifyOnSuccess": "weekly", "notifyOnFailure": "weekly"}}' \
'https://datapipeline.scraperapi.com/api/projects/?api_key=YOUR_API_KEY'
Wenn Sie den bereitgestellten Code selbst testen möchten, gehen Sie folgendermaßen vor:
- Erstellen Sie ein ScraperAPI-Konto.
- Ersetzen Sie die
YOUR_API_KEYText im Code mit Ihrem eigenen ScraperAPI-API-Schlüssel.
Diese Anfrage erstellt ein neues Google Search DataPipeline-Projekt mit den Suchbegriffen „iPhone“ Und „Android„.
Notiz: Eine vollständige Liste der Endpunkte und Parameter finden Sie in der Dokumentation.
So würde die API-Antwort aussehen:
{
"id": 125704,
"name": "Google search project",
"schedulingEnabled": true,
"scrapingInterval": "weekly",
"createdAt": "2024-09-27T08:02:19.912Z",
"scheduledAt": "2024-09-27T08:02:19.901Z",
"projectType": "google_search",
"projectInput": { "type": "list", "list": ("iPhone", "Android") },
"notificationConfig": {
"notifyOnSuccess": "weekly",
"notifyOnFailure": "weekly"
}
}
Wenn Sie zu Ihrem Dashboard navigieren, sehen Sie, dass dieses Projekt erstellt wurde.
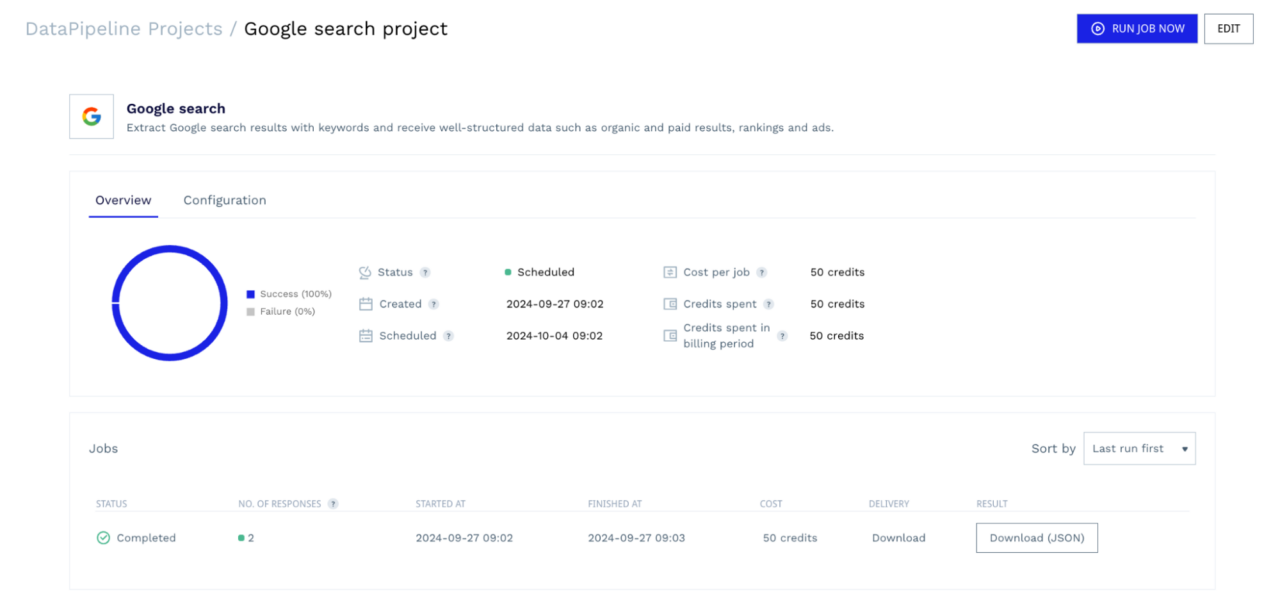
Von diesem Dashboard aus können Sie den Fortschritt Ihres Scrapers überwachen, laufende Jobs bei Bedarf abbrechen, Ihre Konfigurationen überprüfen und die Scraping-Daten herunterladen, sobald die Jobs abgeschlossen sind. Alle diese Informationen können Sie auch über die entsprechenden Endpunkte überwachen. Sie benötigen keine Tools von Drittanbietern oder müssen Ihre Entwicklungsumgebung verlassen.
Diese nahtlose Integration macht die DataPipeline von ScraperAPI zu einer besseren Option als die Integration von ScrapingBee mit Make.
Render-Befehlssätze
Der Umgang mit Websites mit dynamischen Inhalten erfordert eine genaue Darstellung von JavaScript. Mit dem Render-Anweisungssatz von ScraperAPI können Sie über einen API-Aufruf Anweisungen an einen Headless-Browser senden und ihn anleiten, welche Aktionen beim Rendern der Seite ausgeführt werden sollen. Diese Anweisungen werden als JSON-Objekt in den API-Anfrageheadern gesendet.
Sehen wir uns nun ein Beispiel für die Verwendung des Render-Befehlssatzes auf derselben Test-E-Commerce-Site an:
import requests
from bs4 import BeautifulSoup
import json
api_key = 'YOUR_SCRAPER_API_KEY'
url = 'https://api.scraperapi.com/'
target_url = 'https://scrapeme.live/shop/'
config = ({
"type": "loop",
"for": 1,
"instructions": (
{
"type": "scroll",
"direction": "y",
"value": "bottom"
},
{
"type": "wait",
"value": 2
},
{
"type": "click",
"selector": {
"type": "css",
"value": "a.next.page-numbers"
}
},
{
"type": "wait",
"value": 5
}
)
})
# Convert the configuration to a JSON string
config_json = json.dumps(config)
# Construct the instruction set for Scraper API
headers = {
'x-sapi-api_key': api_key,
'x-sapi-render': 'true',
'x-sapi-instruction_set': config_json
}
payload = {'url': target_url, }
response = requests.get(url, params=payload, headers=headers)
soup = BeautifulSoup(response.text, "lxml")
products = soup.select('ul.products > li')
# Loop through each product and extract relevant information
for product in products:
title = product.select_one('.woocommerce-loop-product__title').get_text(strip=True)
image_url = product.select_one('img.attachment-woocommerce_thumbnail')('src')
product_url = product.select_one('a.woocommerce-LoopProduct-link')('href')
price = product.select_one('.price .woocommerce-Price-amount').get_text(strip=True)
currency_symbol = product.select_one('.woocommerce-Price-currencySymbol').get_text(strip=True)
print({
'title': title,
'image_url': image_url,
'product_url': product_url,
'price': price,
'currency_symbol': currency_symbol,
})
print('Response HTTP Status Code: ', response.status_code)
Richten Sie dazu Ihre API-Anmeldeinformationen ein (mit Ihrem ScraperAPI-API-Schlüssel). Definieren Sie als Nächstes eine Konfiguration config das den Render-Befehlssatz enthält.
Dieser Befehlssatz weist den Browser an:
- Scrollen Sie zum Ende der Seite („
scroll“ Aktion). - Warten Sie 2 Sekunden („
wait“ Aktion). - Klicken Sie mit dem CSS-Selektor auf die Schaltfläche „Weiter“
a.next.page-numbers” („click“ Aktion). - Warten Sie 5 Sekunden, damit die nächste Seite geladen werden kann („
wait“ Aktion).
Anschließend erstellen wir die Header für die API-Anfrage, einschließlich unseres API-Schlüssels, um das Rendern zu ermöglichen und den Befehlssatz hinzuzufügen.
Notiz: In der Dokumentation zum Render-Befehlssatz finden Sie eine vollständige Liste der unterstützten Anweisungen und erfahren, wie Sie Ihre Scraping-Aufgaben weiter anpassen können.
Diese Anweisungen geben Ihnen die gleiche Kontrolle über die Seitendarstellung wie die von ScrapingBee, jedoch ohne den eigensinnigen Prozess. ScraperAPI ist so konzipiert, dass es so funktioniert, wie Sie es tun, sodass Sie sich nicht auf starre Regeln zur „Datenextraktion“ beschränken müssen.
Strukturierte Datenendpunkte (SDEs)
ScraperAPI bietet nicht nur eine allgemeine API zum Scraping benutzerdefinierter URLs, sondern auch vorkonfigurierte Endpunkte, die für bestimmte beliebte Websites wie Amazon, Walmart und die Google-Suche entwickelt wurden. Mit dieser Funktion können Sie jede E-Commerce-Produktseite durchsuchen, ohne komplexe Parsing-Logik schreiben oder sich ständig an Website-Updates anpassen zu müssen, unabhängig von der Größe Ihres Projekts.
Die SDEs von ScraperAPI können sowohl mit der Standard-API als auch mit der Async-API verwendet werden. Die Async-API ist besonders für Großprojekte von Vorteil, da Sie eine höhere Scraping-Geschwindigkeit erreichen, gleichzeitig Millionen von Anfragen asynchron bearbeiten und strukturierte Daten (JSON oder CSV) über einen Webhook empfangen können.
Schauen wir uns ein Beispiel für die Verwendung der SDE von ScraperAPI zum Scrapen von Google-Suchergebnissen an:
import requests
import json
APIKEY= "YOUR_SCRAPERAPI_KEY"
QUERY = "EA FC25 game"
payload = {'api_key': APIKEY, 'query': QUERY, 'country_code': 'us'}
r = requests.get('https://api.scraperapi.com/structured/google/search', params=payload)
data = r.json()
# Write the JSON object to a file
with open('results.json', 'w') as f:
json.dump(data, f, indent=4)
print("Results have been stored at results.json")
Notiz: Um mehr zu erfahren, schauen Sie sich unser umfassendes Tutorial zum Scrapen von Daten aus Google-Suchergebnissen an.
In diesem Fall senden wir eine Anfrage an den Endpunkt der Google-Suche. Wir übergeben den Suchabfrageparameter „EA FC25-Spiel“ und geben „uns“ als an country_code um Ergebnisse von in den USA ansässigen IPs zu erhalten. Denken Sie daran, es auszutauschen “YOUR_SCRAPERAPI_KEY”.
So sieht ein organisches Standardergebnis in JSON aus:
{
"position": 1,
"title": "EA SPORTS FC 25",
"snippet": "EA SPORTS FC\u2122 25 gives you more ways to win for the club. Team up with friends in your favorite modes with the new 5v5 Rush, and manage your club to victory as\u00a0...",
"highlighs": (
"EA"
),
"link": "https://www.xbox.com/en-US/games/ea-sports-fc-25",
"displayed_link": "https://www.xbox.com \u203a en-US \u203a games \u203a ea-sports-fc-25"
},
{
"position": 2,
"title": "EA SPORTS FC\u2122 25: what's new, release date, and more",
"snippet": "4 days ago \u2014 The official release date for EAS FC 25 is September 27, 2024. The early access release date for EAS FC 25 is September 20, 2024 for the\u00a0...",
"highlighs": (
"EAS FC 25",
"EAS FC 25"
),
"link": "https://help.ea.com/en-us/help/ea-sports-fc/ea-sports-fc-release-date/",
"displayed_link": "https://help.ea.com \u203a en-us \u203a help \u203a ea-sports-fc-release-..."
},
{
"position": 3,
"title": "EA SPORTS FC\u2122 25",
"snippet": "EA SPORTS FC\u2122 25 gives you more ways to win for the club. Team up with friends in your favourite modes with the new 5v5 Rush, and manage your club to\u00a0...",
"highlighs": (
"EA"
),
"link": "https://store.steampowered.com/app/2669320/EA_SPORTS_FC_25/",
"displayed_link": "https://store.steampowered.com \u203a app \u203a EA_SPORTS_FC..."
},
Notiz: Aus Platzgründen zeigen wir nur einen Teil der Antwort.
Im Hinblick auf die Automatisierung können Sie diese Endpunkte mit DataPipeline nutzen – wie im vorherigen Beispiel gezeigt. Dies macht es einfacher, automatisch zusätzliche Daten abzurufen, ohne komplexe Parser erstellen oder warten zu müssen oder stundenlang Ihre Datensätze bereinigen zu müssen.
Notiz: Weitere Informationen zu strukturierten Datenendpunkten, ihrer Verwendung und Parametern finden Sie in der SDE-Dokumentation.
ScrapingAPI-Preise
ScraperAPI bietet eine spezielle kostenlose Testversion mit 5.000 API-Anfragen (begrenzt auf 7 Tage) an und wechselt anschließend zu ihrem kostenlosen Standardplan mit 1.000 API-Credits. Mit dieser großzügigen Testversion können Sie den Service gründlich testen, bevor Sie sich für einen kostenpflichtigen Plan entscheiden.
| Planen | Preise | API-Credits |
| Frei | – | 5000 |
| Hobby | 49 $ | 100.000 |
| Start-up | 149 $ | 1.000.000 |
| Geschäft | 299 $ | 3.000.000 |
| Unternehmen | Brauch | 3.000.000 + |
ScraperAPI berechnet pro Anfrage eine vordefinierte Menge an Credits. Die Menge der verbrauchten Credits variiert je nach den Parametern, die Sie in der Anfrage verwenden. Dieses System ist unkomplizierter als das von Scrapingbee und die ScraperAPI-Website kann Ihnen helfen, Ihren API-Guthabenverbrauch genau abzuschätzen, noch bevor Sie die Anfragen stellen.
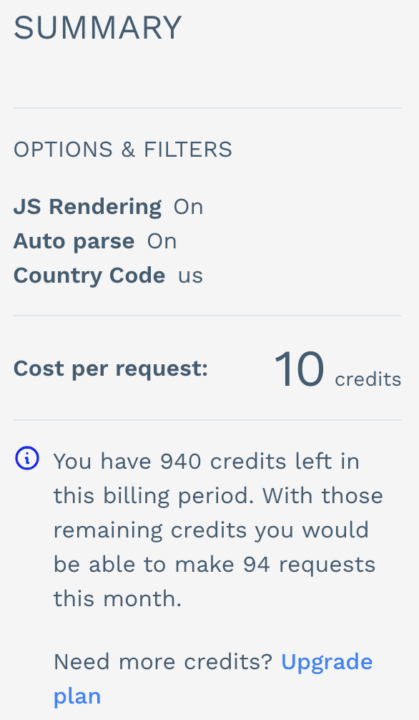
Die Geotargeting-Funktionalität von ScrapingBee ist nur bei Verwendung von Premium-Proxys verfügbar. Um es ins rechte Licht zu rücken, mit dem Geschäftsplan von ScrapingBee unter 299 $man kann ungefähr kratzen 300.000 statische Seiten Und 120.000 Mit JavaScript gerenderte Seiten.
Auf der anderen Seite bietet der Businessplan von ScraperAPI für 299 US-Dollar 3.000.000 API-Creditsso dass Sie bis zu kratzen können 3.000.000 statische Seiten oder 600.000 mit JavaScript gerenderte Seiten (da JS-Rendering mehr Credits pro Anfrage verbraucht). Dies bedeutet, dass Sie bis zu kratzen können 2.700.000 mehr statisch Seiten zum gleichen Preis, was ScraperAPI zu einer kostengünstigeren Lösung macht.
Warum ScraperAPI besser für die automatische Datenerfassung ist
In puncto Leistung halten beide Dienste, was sie versprechen und bieten zuverlässige Scraping-Lösungen. Hier sind jedoch einige Gründe, warum ScraperAPI den Zuschlag erhält:
- Einfach zu verwendende API: ScraperAPI bietet eine unkomplizierte API, mit der Sie mit einer einfachen GET-Anfrage innerhalb von Minuten mit dem Scraping beginnen können. Es ist keine zusätzliche Software oder komplexe Einrichtung erforderlich, sodass es auch für Web-Scraping-Neulinge zugänglich ist.
- Effiziente Proxy-Nutzung: Durch den Einsatz von maschinellem Lernen rotiert ScraperAPI auf intelligente Weise IPs und Header, um das Risiko einer Blockierung zu minimieren. Dadurch wird der Bedarf an teuren Proxys für Privatanwender reduziert, wodurch Sie Kosten sparen und gleichzeitig hohe Erfolgsquoten beibehalten.
- Spezialisierte E-Commerce-Endpunkte: ScraperAPI bietet vorgefertigte Endpunkte, die speziell für große E-Commerce-Plattformen wie Amazon, Walmart und Google Shopping entwickelt wurden. Diese Endpunkte ermöglichen eine effizientere Datenextraktion, ohne komplexe Parsing-Logik schreiben zu müssen.
- Bessere Kosteneffizienz: Die Pläne von ScraperAPI bieten erfolgreichere Anfragen zu einem niedrigeren Preis. Das unkomplizierte Preismodell und die effektive Proxy-Verwaltung sorgen für eine bessere Kosteneffizienz. Sie erhalten einen höheren Gegenwert für Ihre Investition, was sie zu einer wirtschaftlicheren Wahl für kleine und große Projekte macht.
- Nahtlose Workflow-Integration: Mit dem DataPipeline-Endpunkt können Sie komplette Scraping-Projekte direkt in Ihrer Entwicklungsumgebung erstellen und automatisieren. Dies bedeutet auch, dass Sie andere Aspekte Ihres Projekts automatisieren können, indem Sie DataPipeline mit dynamischen Eingabelisten versorgen.
Andere bemerkenswerte Alternativen
Während ScraperAPI hervorsticht, könnten auch andere Tools spezifische Anforderungen erfüllen:
2. Octoparse (Bester Point-and-Click-Scraper)
Octoparse ist eines der besten Screen-Scraping-Tools für Leute, die Websites scrapen möchten, ohne Programmieren zu lernen. Es verfügt über eine Point-and-Click-Oberfläche und eine integrierte Browseransicht, die dabei hilft, menschliches Verhalten nachzuahmen.
Es ist in der Lage, Daten aus anspruchsvollen, aggressiven oder dynamischen Webressourcen mit Dropdown-Menüs, unendlichem Scrollen, Anmeldeauthentifizierung, AJAX und mehr zu extrahieren.
Octoparse bietet auch Vorlagen, mit denen Benutzer Hunderte voreingestellter Vorlagen für die beliebtesten Websites durchsuchen und Daten sofort und ohne großen Aufwand abrufen können. Es hat kürzlich (2024) eine Beta-Version für macOS veröffentlicht und ist auch mit den neuesten Versionen von Windows-Betriebssystemen kompatibel. Die Benutzerfreundlichkeit dieser Software ist einer der Hauptgründe, warum sie bei vielen Benutzern Anklang findet.
Die Octoparse-Schnittstelle
Sobald Sie das Programm starten, werden Sie sofort aufgefordert, sich mit Ihrem Google-, Microsoft- oder E-Mail-Konto zu registrieren, um sich automatisch bei Ihrem Profil anzumelden. Ein kurzer Überblick führt Sie in die Funktionen des Programms ein, gefolgt von einer optionalen Schritt-für-Schritt-Anleitung, die Ihnen den Einstieg erleichtert.
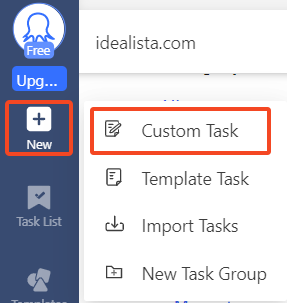
- Erstellen einer neuen Aufgabe
Jede Arbeit mit Octoparse beginnt mit der Erstellung einer Aufgabe, die aus Anweisungen für die Ausführung des Programms besteht. Klicken Sie in der Seitenleiste auf „NeuDas Symbol „“ bietet zwei Optionen:
- Benutzerdefinierte Aufgabe
- Aufgabenvorlage
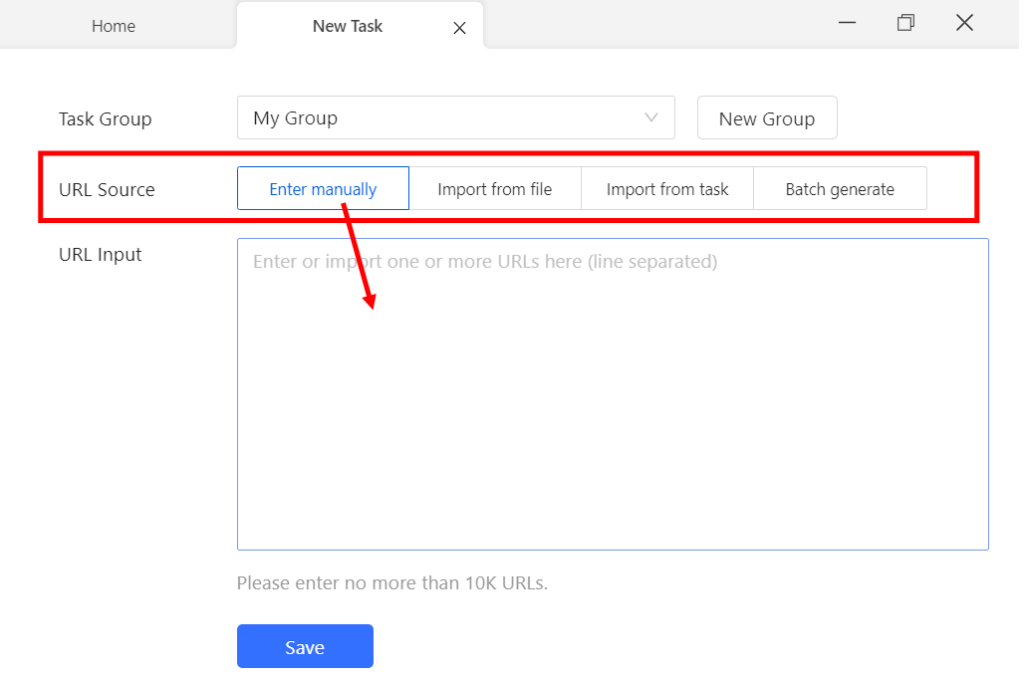
Sehen wir uns ein einfaches Beispiel für die Verwendung der benutzerdefinierten Aufgabe zum Scrapen von eBay-Angeboten an. Wählen Sie „Brauch Aufgabe” ermöglicht es Ihnen, die Quelle der URL zu bestimmen. Zu den Optionen gehören die manuelle Eingabe, der Import aus einer Datei oder die Verwendung einer vorhandenen Aufgabe.
- Vorlagen
Der „VorlagenDie Registerkarte „In Octoparse“ enthält eine Sammlung von Web-Scraping-Vorlagen. Hierbei handelt es sich um vorformatierte Aufgaben, die sofort verwendet werden können, ohne dass Scraping-Regeln festgelegt oder Code geschrieben werden müssen.
Lassen Sie uns nun einige Daten aus den Vorlagen extrahieren. Für diese Übung verwenden wir eine Amazon-Scraper-Vorlage.
Anwendung:
Schritt 1: Klicken Sie auf Vorlagen Tab
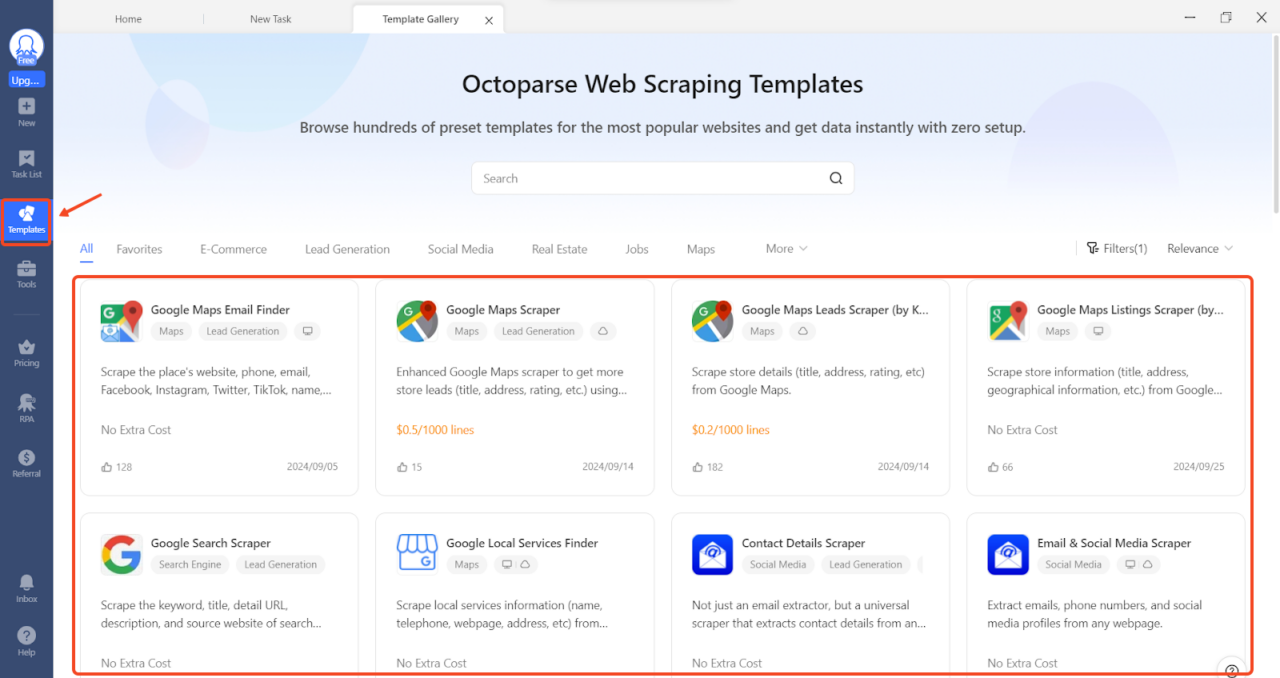
Schritt 2: Wählen Sie eine Amazon-Vorlage aus und bestätigen Sie. Geben Sie dann eine Liste mit Schlüsselwörtern ein (bis zu 5).
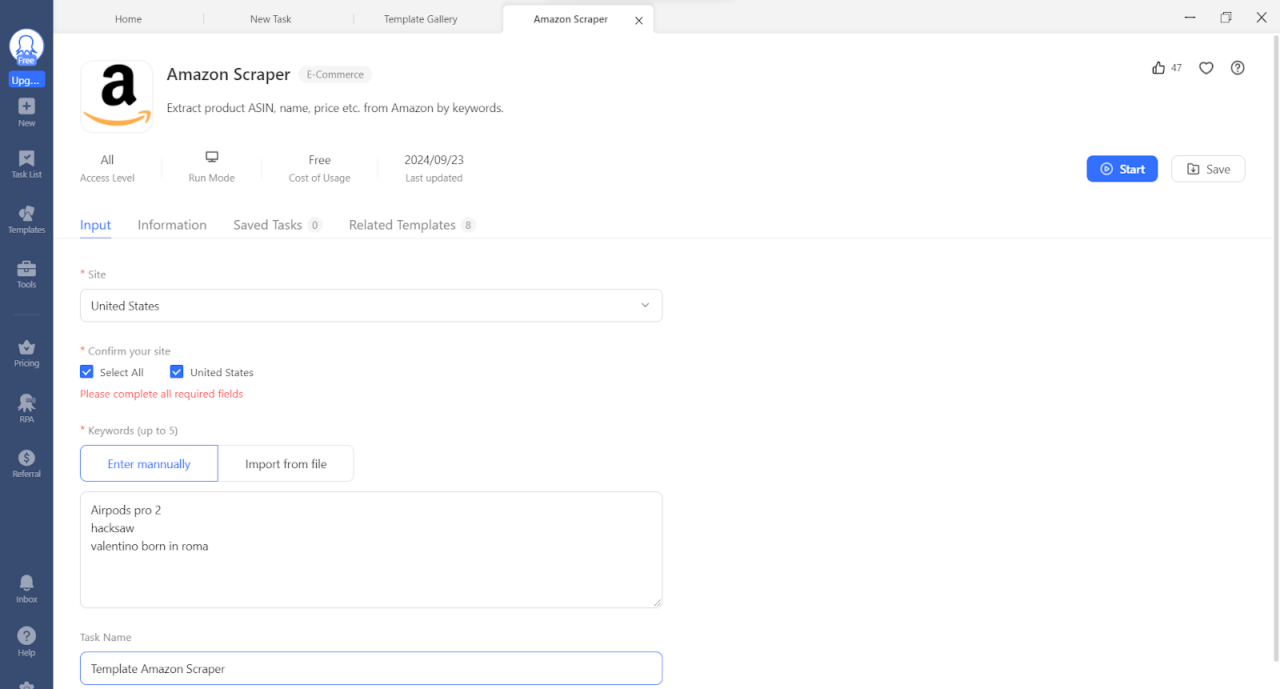
Schritt 3: Klicken Sie auf Start, um Ihren bevorzugten Ausführungsmodus auszuwählen.
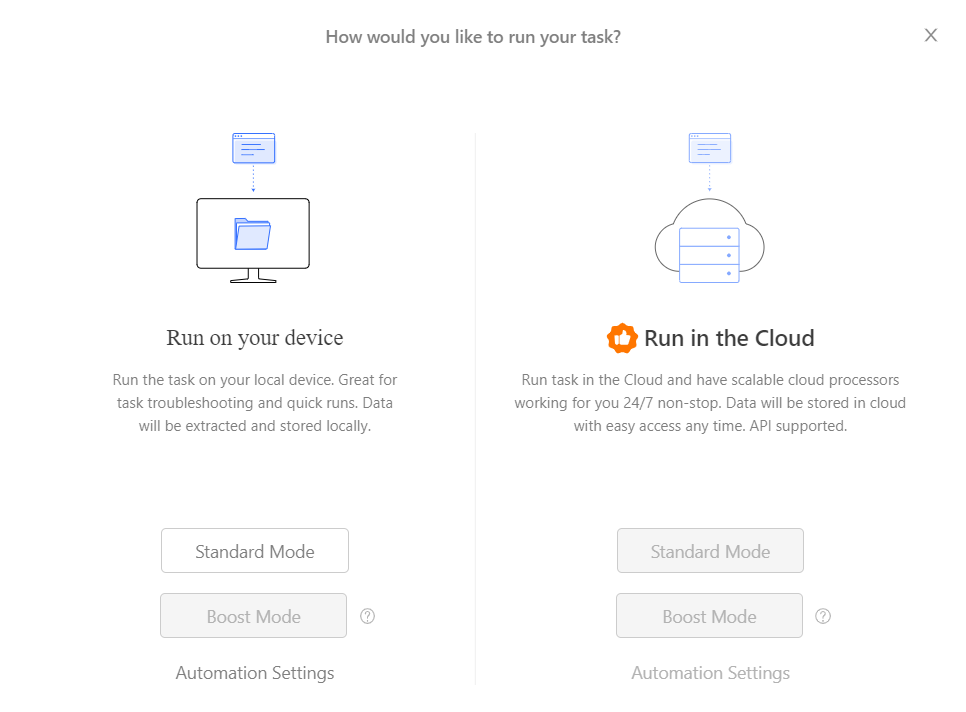
Octoparse-Preise
Octoparse kann kostenlos heruntergeladen und verwendet werden, verfügt jedoch über eingeschränkte Funktionen. Um das volle Potenzial auszuschöpfen, benötigen Sie ein kostenpflichtiges Abonnement. Octoparse bietet außerdem eine fünftägige Geld-zurück-Garantie für Benutzer, die seine Premium-Dienste ausprobieren möchten.
Da es bei Octoparse vor allem um Point-and-Click-Automatisierung geht, bieten sie eine aufgabenbasierte Preisgestaltung an. Dies bedeutet, dass Sie durch die Anzahl der Seiten oder erfolgreichen Anfragen nicht eingeschränkt werden. Stattdessen ist die einzige Grenze die Anzahl der „Schritte“, die Ihre Automatisierung ausführen kann.
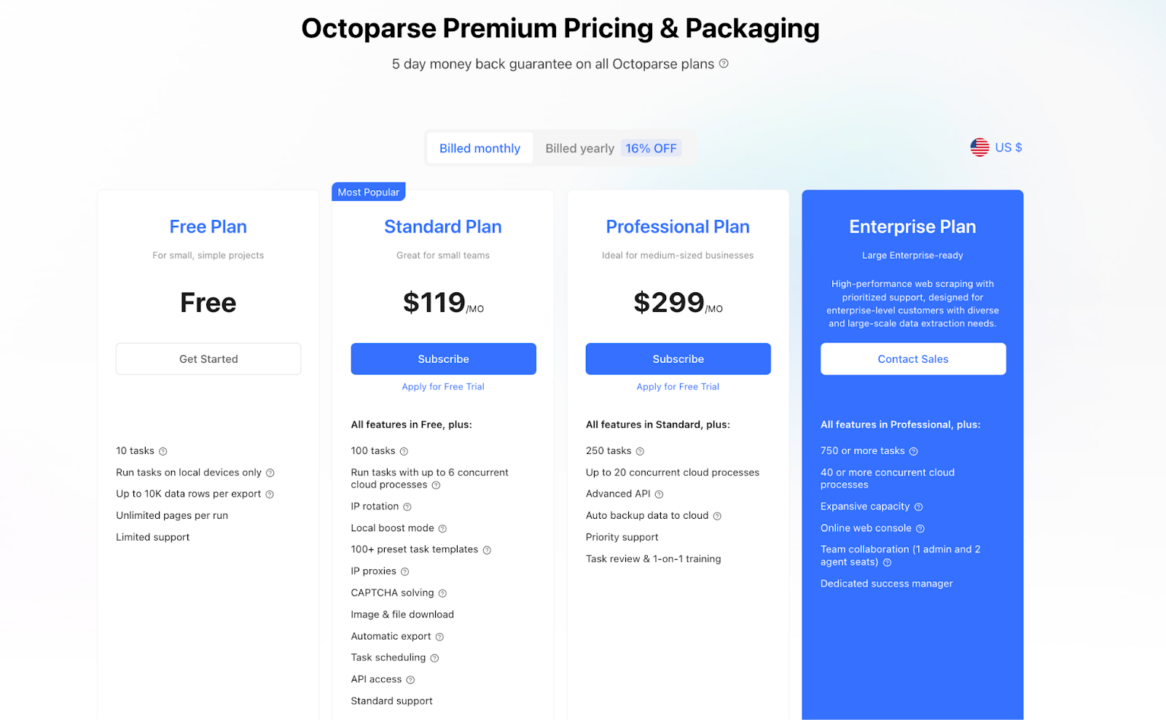
Einschränkungen von Octoparse
Trotz seiner benutzerfreundlichen Oberfläche und robusten Funktionen weist Octoparse einige Einschränkungen auf:
- Preise: Im Vergleich zu anderen Alternativen wie ScraperAPI sind die kostenpflichtigen Pläne von Octoparse teurer, insbesondere wenn man die in jedem Preispunkt enthaltenen Funktionen berücksichtigt.
- Kundensupport: Der Grad des Kundensupports variiert je nach Abonnementplan. Benutzer des kostenlosen Plans erhalten minimalen Support, der als „faule Unterstützung.“ Höhere Tarife bieten E-Mail-Support, aber es gibt keine Live-Chat-Option, was unpraktisch sein kann, wenn sofortige Hilfe benötigt wird.
Warum ScraperAPI besser ist
Im Vergleich zu Octoparse, ScraperAPI bietet eine kostengünstigere und skalierbarere Lösung für Web Scraping. Der Hobby-Plan von ScraperAPI beginnt bei 49 $/MonatAngebot 100.000 API-Credits (kann kratzen 100.000 Ergebnisse) mit Funktionen wie automatischer IP-Rotation, Geotargeting und JavaScript-Rendering. Dies ist deutlich günstiger als der Standardplan von Octoparse 119 $/Monatinsbesondere unter Berücksichtigung der Skalierbarkeit und der bereitgestellten Funktionen.
3. WebScraper.io (Beste Browser-Erweiterung)
WebScraper bietet zwei große Web-Scraping-Lösungen: Web Scraper Cloud und Web Scraper Browser Extension.
Die Browser-Erweiterung ist ein Point-and-Click-Tool, das in die Entwicklertools von Chrome und Firefox integriert ist und es Benutzern ermöglicht, Scraper direkt in ihren Browsern einzurichten und auszuführen.
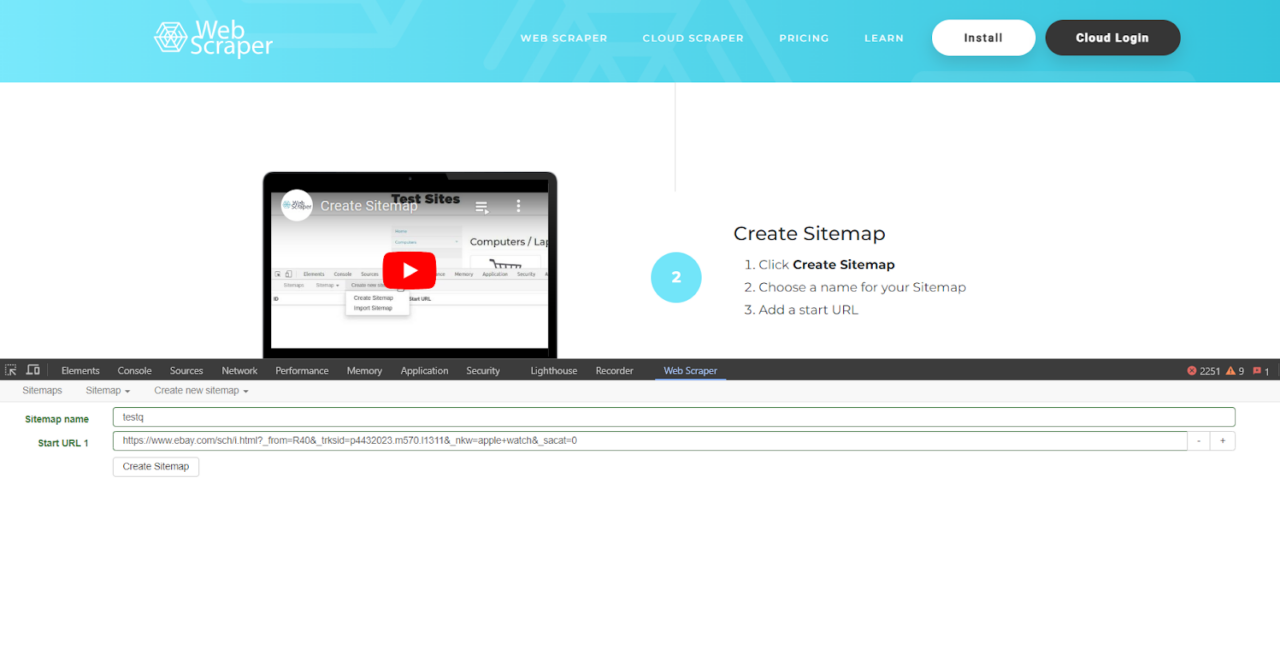
Es ist auf Benutzerfreundlichkeit ausgelegt und erfordert lediglich ein grundlegendes Verständnis von HTML- und CSS-Selektoren, sodass es für Anfänger und kleine Web-Scraping-Projekte geeignet ist.
Hauptfunktionen von WebScraper.io
- In Browser-Entwicklertools integrierte Point-and-Click-Schnittstelle
- Community-Sitemaps für beliebte Websites
- Cloudbasierte Ausführung (nur kostenpflichtige Pläne)
WebScraper.io bietet auch eine Sammlung von Von der Community bereitgestellte Sitemaps die das Scrapen von Daten von beliebten Websites wie Amazon vereinfachen. So verwenden Sie eine vorgefertigte Sitemap, um Daten von Amazon zu extrahieren:
- Um diese Funktion nutzen zu können, müssen Sie sich für ein Webscraper.io-Konto anmelden und einen der kostenpflichtigen Pläne auswählen. Die Browsererweiterung unterstützt diese Funktion nicht.
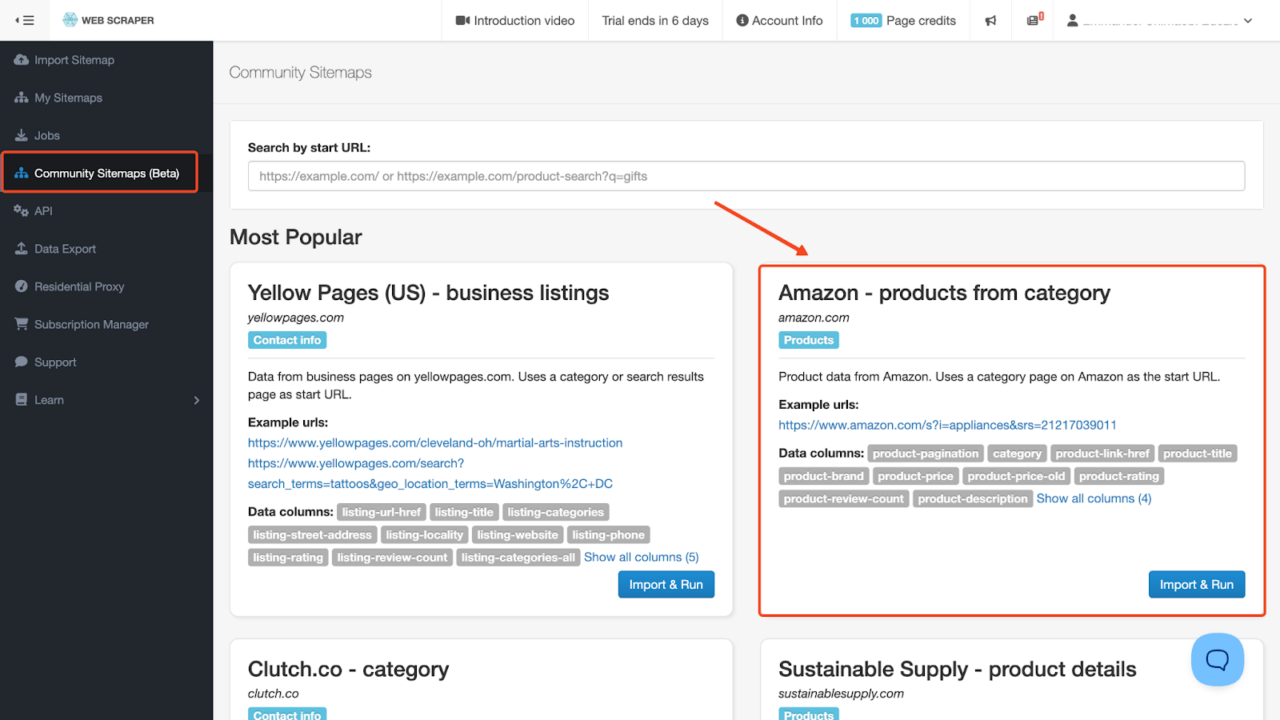
- Suchen Sie auf der Seite „Community-Sitemaps“ nach einem Amazon-Sitemap-Scraper, der Ihren Anforderungen entspricht, und klicken Sie darauf Importieren und ausführen.
- Passen Sie nun die notwendigen Schabeparameter an und klicken Sie auf Kratzen Taste.
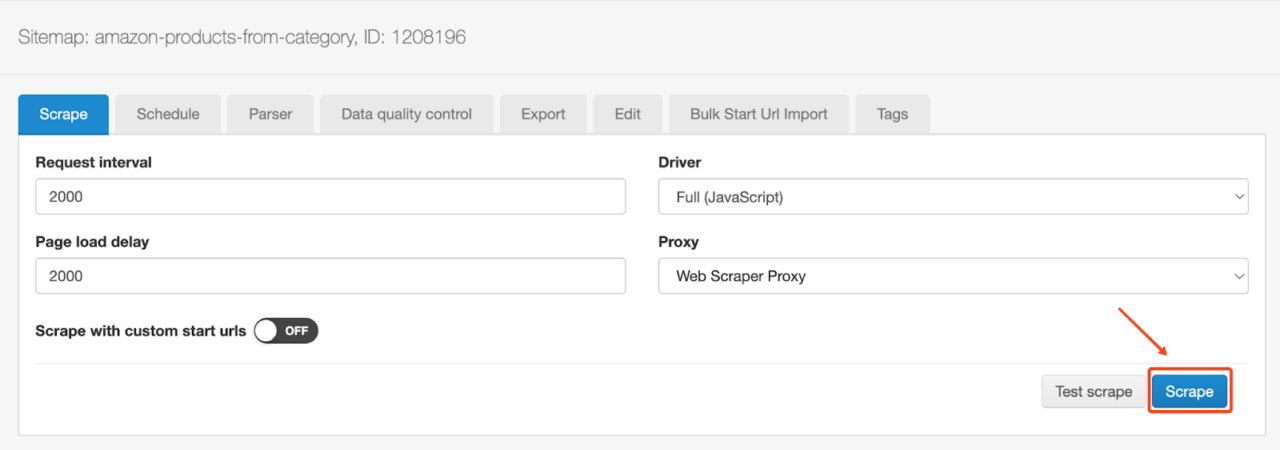
- Sobald die Schabearbeit begonnen hat, gibt es ein nettes kleines Dashboard, das Sie über den Schabefortschritt informiert. Sobald der Schaber fertig ist, klicken Sie auf Vorschau Klicken Sie auf die Schaltfläche, um Ihre Scraping-Ergebnisse anzuzeigen und zu exportieren.
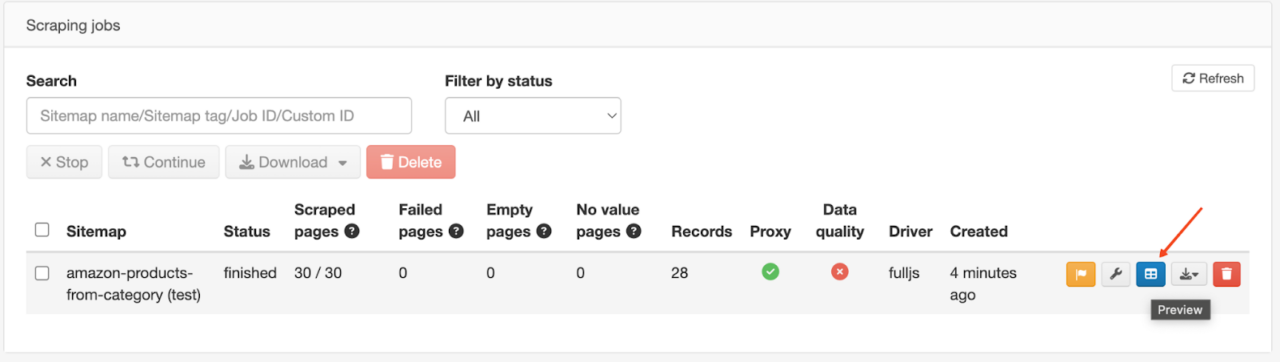
- Exportieren Sie die Daten in Ihrem bevorzugten Format (CSV, XLSX oder JSON).
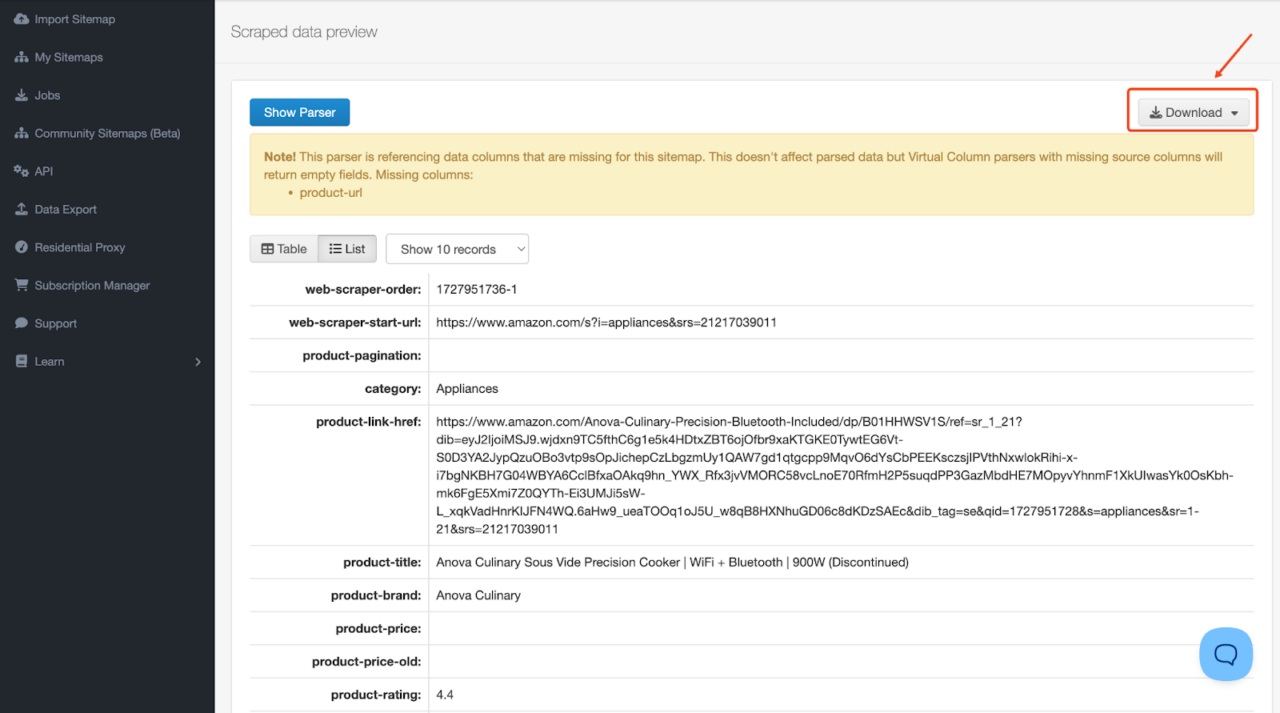
Webscraper-Preise
Webscraper.io ist für die regelmäßige und geplante Nutzung zum Extrahieren großer Datenmengen und zur einfachen Integration in andere Systeme konzipiert. Bezahlte Pläne bieten Funktionen wie Cloud-Extraktion, geplantes Scraping, IP-Rotation und API-Zugriff, was eine häufigere und umfangreichere Datenerfassung ermöglicht.

Notiz: Die Nutzung der Browser-Erweiterung ist kostenlos, Cloud-Funktionen und erweiterte Funktionen erfordern jedoch einen kostenpflichtigen Plan.
Unterschied zwischen Scraping in der Web Scraper Cloud und der Web Scraper-Browsererweiterung
| Web Scraper Cloud | Web Scraper-Browsererweiterung |
| Konsistenter Zugriff auf die Website während des Scrapings. | Begrenzter Zugang. Nur Websites, auf die Sie über Ihren Browser zugreifen können, können gescrapt werden. |
| Die gescrapten Daten werden für alle Scraping-Jobs innerhalb des Datenaufbewahrungszeitraums im Cloud-Speicher gespeichert. | Im lokalen Speicher des Browsers werden nur Daten des letzten Scraping-Jobs gespeichert. |
| Bilder werden beim Scrapen nicht geladen | Bilder werden beim Scrapen geladen |
Einschränkungen von WebScraper.io
Obwohl WebScraper.io benutzerfreundlich und ideal für Anfänger ist, weist es einige Einschränkungen auf:
- Proxy-Unterstützung: Der Browser-Erweiterung fehlt die integrierte Unterstützung für die Proxy-Integration, was beim Scraping von Websites mit strengen Anti-Scraping-Maßnahmen problematisch sein kann.
- Skalierbarkeit: Der Browser-Erweiterungs-Scraper ist durch die Ressourcen Ihres lokalen Computers begrenzt, sodass er für große Scraping-Projekte weniger geeignet ist. Dies gilt jedoch nicht für den Cloud Scraper.
- Datenvalidierung und -bereinigung: Es gibt keine integrierten Datenvalidierungs- oder Bereinigungsfunktionen, daher muss die Nachbearbeitung manuell erfolgen.
- Kundensupport: Der Support erfolgt hauptsächlich über ein Community-Forum, das im Vergleich zum dedizierten Kundendienst möglicherweise keine zeitnahe Hilfe bietet.
Warum ScraperAPI besser ist
ScraperAPI ist darauf ausgelegt, Millionen von Anfragen effizient zu bearbeiten. Daher ist es ideal für Großprojekte, die einen hohen Durchsatz und Zuverlässigkeit erfordern. ScraperAPI bietet gegenüber WebScraper auch mehrere Vorteile, darunter:
- Umfassendes Proxy-Management: ScraperAPI kümmert sich automatisch um die IP-Rotation und bietet Zugriff auf einen riesigen Pool an Proxys, einschließlich Privat- und Rechenzentrums-IPs. So können Sie IP-Verbote vermeiden und auf geografisch eingeschränkte Inhalte zugreifen.
- Professioneller Support: ScraperAPI bietet dedizierten Kundensupport für alle Pläne, einschließlich vorrangiger Unterstützung und einem dedizierten Account Manager für höherstufige Pläne.
4. ParseHub (browserähnliches Scraping-Tool)
ParseHub ist ein Web-Scraping-Tool, das mit Windows-, Mac- und Linux-Betriebssystemen kompatibel ist. Es soll Benutzern helfen, Daten von Websites zu extrahieren, ohne über Programmierkenntnisse zu verfügen.
Obwohl es keine E-Commerce-spezifischen Vorlagen oder automatische Erkennung bietet, können erfahrene Benutzer benutzerdefinierte Crawler erstellen, um Daten von verschiedenen Websites zu extrahieren, einschließlich solchen mit dynamischen Inhalten und interaktiven Elementen.
Um ParseHub zu verwenden, öffnen Sie eine Website Ihrer Wahl und klicken Sie auf die Daten, die Sie extrahieren möchten. Es ist keine Codierung erforderlich, wodurch dieses Tool sehr einfach zu verwenden ist.
Bezahlte Pläne umfassen Funktionen wie das Speichern von Bildern und Dateien in DropBox oder Amazon S3, IP-Rotation und Planung. Benutzer des kostenlosen Plans erhalten 200 Seiten pro Ausführung mit einer 14-tägigen Datenaufbewahrungsfrist.
ParseHub-Hauptfunktionen
- Point-and-Click-Oberfläche
- Cloudbasierte Datenerfassung und -speicherung
- Geplante Datenerfassung
Verwenden von ParseHub
Um mit ParseHub zu beginnen:
- Herunterladen Laden Sie die ParseHub-Anwendung von der offiziellen Website herunter und installieren Sie sie auf Ihrem Computer. Melden Sie sich dann bei Ihrem ParseHub-Konto an. Das Haupt-Dashboard ist übersichtlich und intuitiv. Es sieht wie folgt aus:
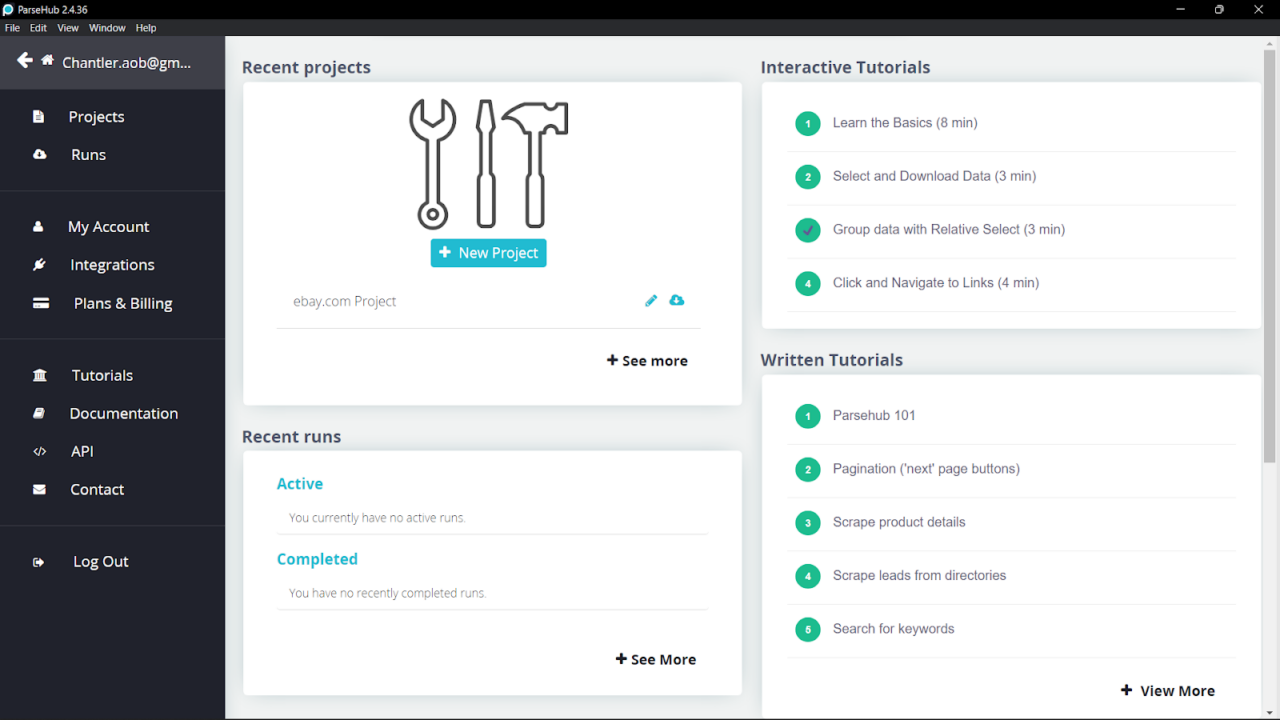
Das Haupt-Dashboard zeigt Zugriff und Verknüpfungen zu Ihrem „Aktuelle Projekte“ Und „Letzte Läufe” und Tutorials, die Ihnen den Einstieg in Parsehub erleichtern.
- Klicken „Neues Projekt” im Haupt-Dashboard, um ein neues Projekt zu erstellen.

- Geben Sie die URL der Website ein, die Sie scrapen möchten. So können Sie beispielsweise die Apple Watch-Angebote bei eBay durchsuchen:
https://www.ebay.com/sch/i.html?_nkw=apple+watch.
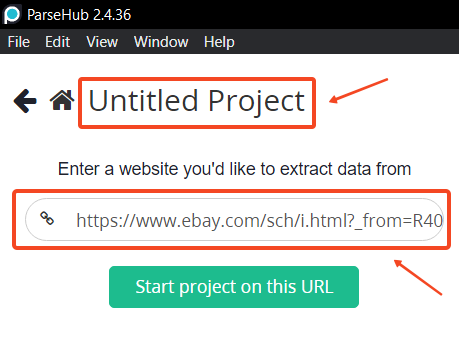
Sobald Sie die URL eingegeben haben, zeigt die Weboberfläche die Webseite auf der rechten Seite und die Steuerelemente auf der linken Seite an.
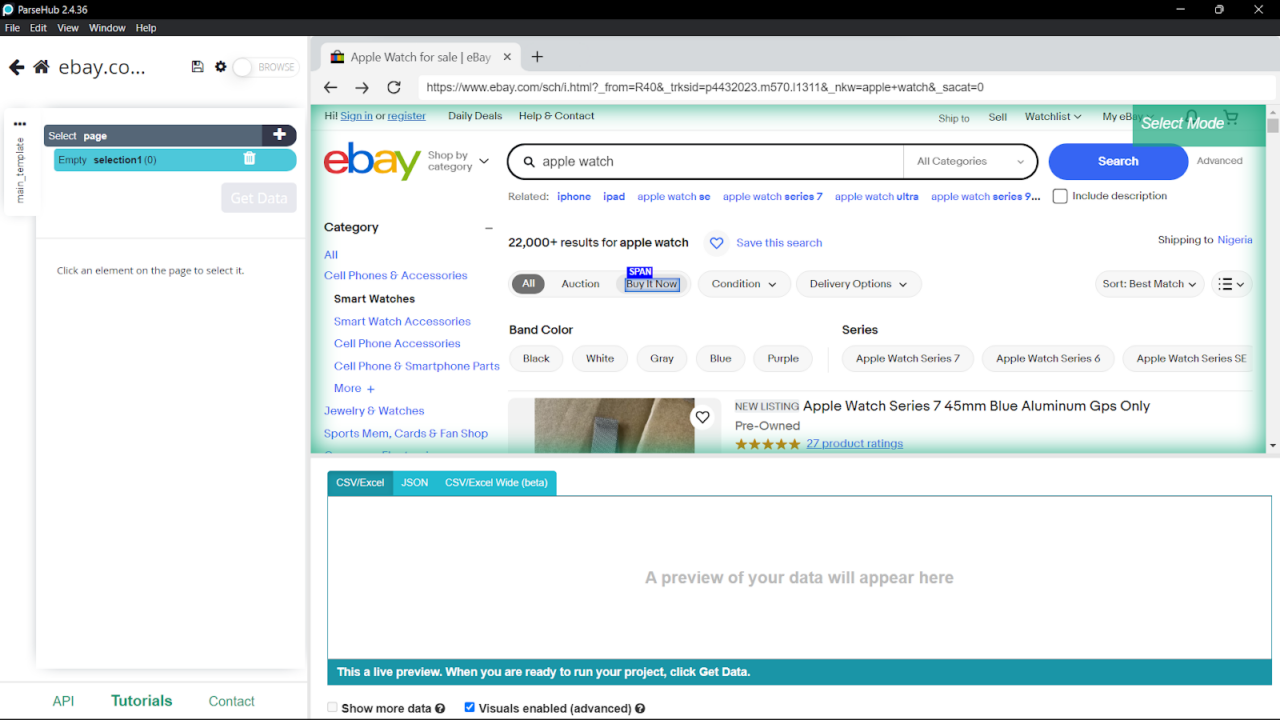
- Klicken Sie mit den Auswahlwerkzeugen auf die Daten, die Sie extrahieren möchten:
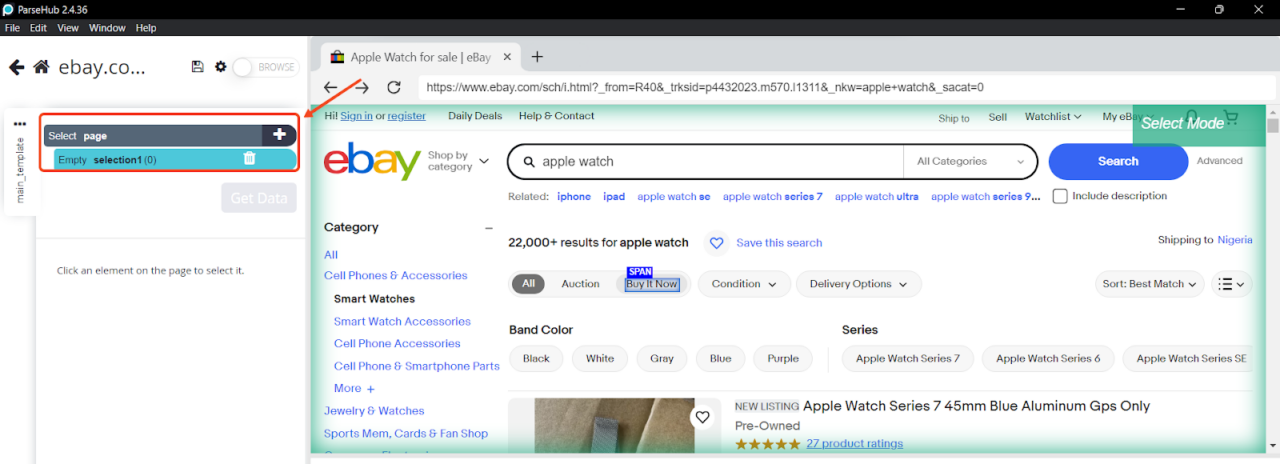
- Passen Sie Ihre Auswahl an, indem Sie Optionen wie „Auswählen“, „Relative Auswahl“, „Klicken“, „Extrahieren“ usw. auswählen. Geben Sie die zu extrahierenden Daten an, z. B. Text, Bilder, URLs oder Attribute:
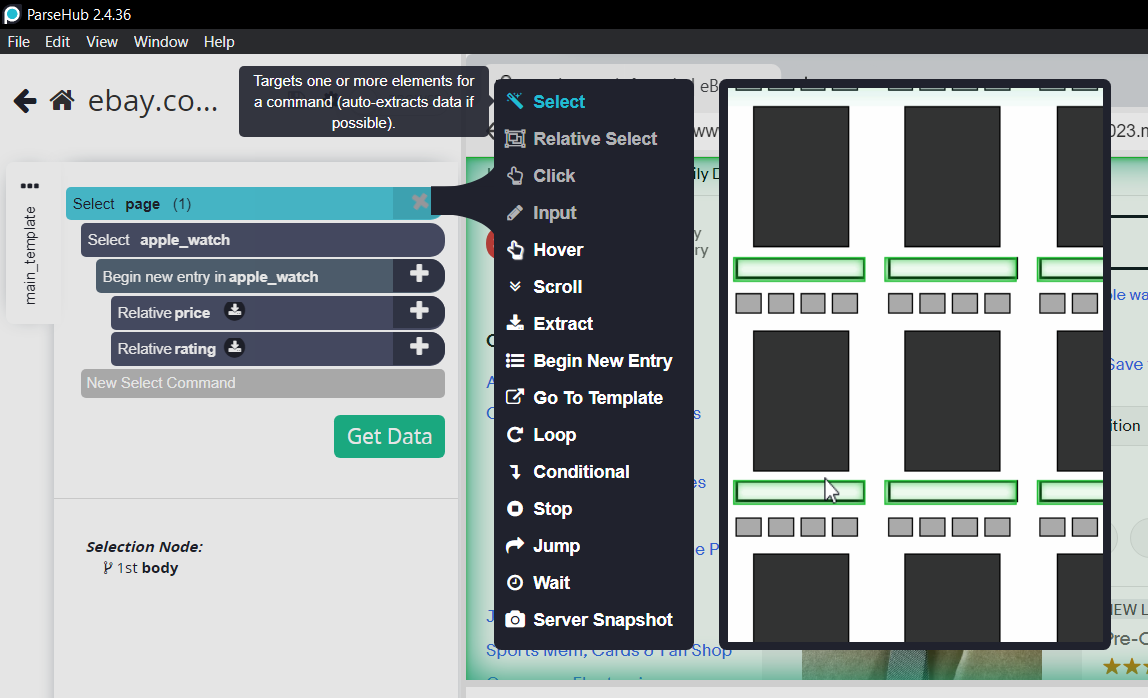
- Klicken Sie auf „Daten abrufen“ und wählen Sie „Laufen,” oder wählen Sie „Zeitplan” für später. Exportieren Sie Ihre Daten nach der Extraktion in den Formaten CSV, Excel oder JSON. Alternativ können Sie über die API oder Webhooks von ParseHub eine Verbindung zu anderen Plattformen herstellen.
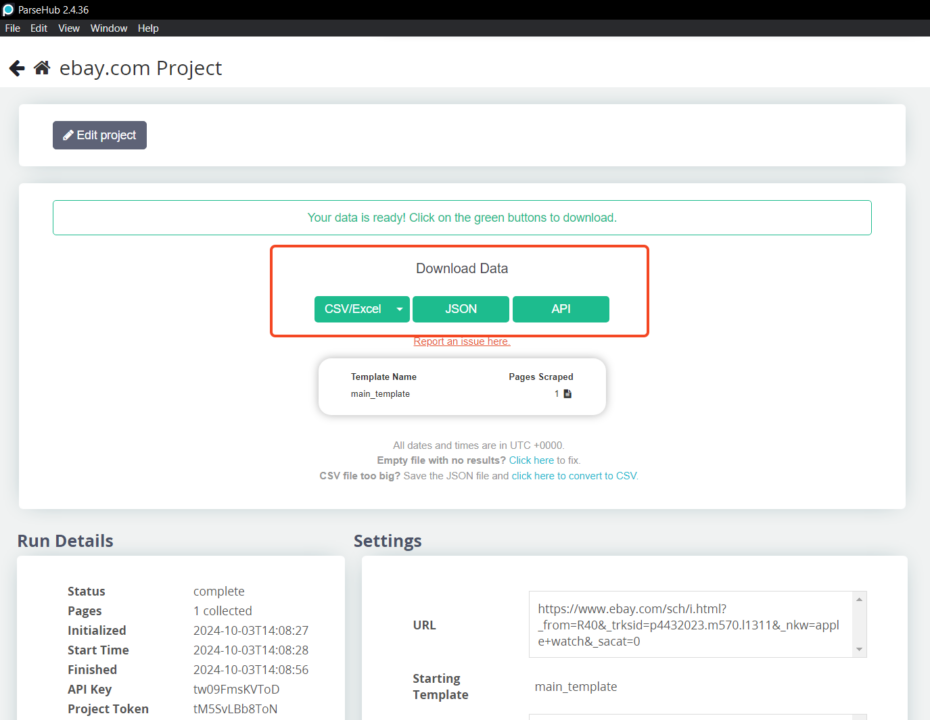
Mit Parsehub können Sie ohne große Schulung einen einfachen Web-Scrape durchführen. Sie müssen jedoch eine Lernkurve durchlaufen, um dieses Web-Scraping-Tool optimal nutzen zu können.
ParseHub-Preise
Obwohl ParseHub als kostenlose Web-Scraping-Lösung bekannt ist, ist das nur die halbe Wahrheit. Es gibt eine kostenlose Version mit eingeschränkten Funktionen, aber es gibt auch drei weitere kostenpflichtige Pläne: Standard (189 $ pro Monat), Professional (599 $ pro Monat) und Enterprise (individuelle Preise, Preise nur auf Anfrage).

Notiz: Bei jährlicher Abrechnung können die Preise variieren.
Während Sie mit dem Free-Plan das Wasser mit eingeschränkten Funktionen testen können, werden durch ein Upgrade auf den Standard- oder Professional-Plan zusätzliche Funktionen wie erhöhte Seitenlimits, gleichzeitige Ausführungen, Planung, IP-Rotation und API-Zugriff freigeschaltet. Allerdings sind diese Pläne im Vergleich zu anderen Alternativen teurer.
Einschränkungen
Trotz seiner benutzerfreundlichen Oberfläche und leistungsstarken Funktionen weist ParseHub einige Einschränkungen auf:
- Hohe Kosten: Die kostenpflichtigen Pläne von ParseHub sind relativ teuer, insbesondere für Großprojekte.
- Keine E-Commerce-Vorlagen: Es fehlen spezielle Vorlagen für beliebte E-Commerce-Plattformen, sodass Benutzer benutzerdefinierte Scraper von Grund auf erstellen müssen.
- Lernkurve: Obwohl keine Codierung erforderlich ist, kann das Einrichten komplexer Scraping-Aufgaben zeitaufwändig sein und ein tieferes Verständnis des Tools erfordern.
- Kundensupport: Kostenlose Benutzer haben begrenzten Support, obwohl in höheren Tarifen erweiterte Supportoptionen verfügbar sind.
Warum ScraperAPI besser ist
ScraperAPI bietet gegenüber ParseHub mehrere Vorteile, wodurch es sich besser für große und einfache Scraping-Projekte eignet:
- Kostengünstige Preisgestaltung: ScraperAPI bietet großzügige API-Credits zu niedrigeren Preisen. Beispielsweise bietet der Hobby-Plan für 49 $/Monat 100.000 API-Credits, was viel günstiger ist als der Standard-Plan von ParseHub, der 189 $/Monat kostet.
- Einfache Integration: Entwickler können ScraperAPI mit einer einfachen API in ihre bestehenden Arbeitsabläufe integrieren, ohne zusätzliche Software zu installieren.
- Spezialisierte E-Commerce-Endpunkte: ScraperAPI bietet vorgefertigte Endpunkte für große E-Commerce-Plattformen wie Amazon und Walmart, sodass keine benutzerdefinierten Scraper erstellt werden müssen.
All dies bietet gleichzeitig erweiterte Automatisierungsoptionen über DataPipeline und DataPipeline-Endpunkte sowie Async Scraper zur Bewältigung großer Anfragevolumina.
Bei der Auswahl eines automatischen Schabewerkzeugs zu berücksichtigende Faktoren
Berücksichtigen Sie bei der Auswahl eines Web-Scraping-Tools die folgenden Schlüsselfaktoren:
- Automatisierungsfunktionen: Suchen Sie nach Automatisierungsfunktionen wie der Planung von Aufgaben, automatisierter CAPTCHA-Lösung und automatischer Verwaltung von Cookies und Sitzungen.
- Benutzerfreundlichkeit: Bewerten Sie die Lernkurve, die Benutzeroberfläche und die verfügbare Dokumentation, um sicherzustellen, dass sie für diejenigen zugänglich ist, die sie verwenden.
- Skalierbarkeit: Bewerten Sie, wie gut das Tool die Datenextraktion in großem Maßstab bewältigt und wie gut es sich an steigende Datenmengen oder -anforderungen anpassen kann.
- Datenextraktionsfunktionen: Das Tool sollte verschiedene Datenformate unterstützen und Inhalte aus verschiedenen Webstrukturen extrahieren, einschließlich statischer HTML- und dynamischer JavaScript-Sites.
- IP-Rotation und Proxy-Unterstützung: Stellen Sie sicher, dass das Tool eine robuste IP-Rotation und Proxy-Verwaltung bietet, um zu verhindern, dass es von komplexeren Websites blockiert wird.
Durch sorgfältige Berücksichtigung dieser Faktoren können Sie ein automatisches Schabewerkzeug auswählen, das Ihren technischen Anforderungen und Projektanforderungen am besten entspricht.
Verwandt: So wählen Sie das richtige Web-Scraping-Tool aus.
Abschluss
In diesem Artikel wurden die Funktionen und Einschränkungen von ScrapingBee bei der Automatisierung von Web-Scraping-Aufgaben aus technischer Sicht untersucht. Wir haben uns auch mehrere Alternativen angesehen, darunter ScraperAPI, Oktoparse, WebScraper.ioUnd ParseHub.
Web-Scraping-Tools sind für jeden verfügbar, von denjenigen, die Lösungen ohne Code bevorzugen, bis hin zu erfahrenen Entwicklern, die erweiterte Funktionen suchen. Bei der Auswahl der besten ScrapingBee-Alternative kommt es häufig auf den Preis, die Benutzerfreundlichkeit und die spezifischen Funktionen an, die den Anforderungen Ihres Projekts entsprechen.
Arbeiten Sie an einem großen Datenautomatisierungsprojekt? Kontaktieren Sie unser Vertriebsteam, um mit einem individuellen Plan zu beginnen, der alle Premium-Funktionen, dedizierte Support-Slack-Kanäle und einen dedizierten Account Manager umfasst.
Verwandte Ressourcen:
