
Google Trends ist ein unschätzbar wertvolles Tool, um Einblicke in Suchanfragen zu gewinnen. Es ermöglicht Benutzern, Trends immer einen Schritt voraus zu sein, neue Schlüsselwörter und Themen zu identifizieren und ein tieferes Verständnis für die aktuellen Interessen ihrer Zielgruppe zu gewinnen.
Um Google Trends effektiv nutzen zu können, ist es jedoch oft erforderlich, innerhalb kurzer Zeit eine große Menge an Schlüsselwörtern und Abfragen zu verarbeiten. Diese Aufgabe kann sich als schwierig erweisen, wenn sie manuell ausgeführt wird. Um dieses Problem zu lösen, werden wir uns mit verschiedenen Methoden zur Automatisierung des Daten-Scrapings befassen, die auf Benutzer mit unterschiedlichen Kenntnisstufen zugeschnitten sind.
Da die Fähigkeitsniveaus unterschiedlich sind, stellen wir verschiedene Optionen vor – von Optionen, die keine Programmierkenntnisse erfordern, bis zu Optionen, die solide Kenntnisse in Programmierung und Skripterstellung voraussetzen.
Praktische Anwendungen von Google Trends-Daten
Google Trends bietet eine Fülle von Daten mit vielfältigen Anwendungsmöglichkeiten in verschiedenen Bereichen. Bevor wir uns mit automatisierten Datenerfassungsmethoden befassen, wollen wir die potenziellen Verwendungsmöglichkeiten und Anwendungen von Google Trends-Daten untersuchen.
Marktforschung
Eine der gängigsten und effektivsten Möglichkeiten, Google Trends-Daten zu nutzen, ist die Marktforschung. Google Trends bietet wertvolle Einblicke in das Suchanfragevolumen in verschiedenen Regionen und Zeiträumen.
Die Analyse von Suchtrends im Zeitverlauf kann wertvolle Informationen über das schwankende Interesse an einem Produkt oder einer Dienstleistung liefern. Diese Informationen können verwendet werden, um Marketingkampagnen in Zeiten mit höchstem Interesse strategisch zu planen. Darüber hinaus ermöglicht Google Trends eine vergleichende Analyse der Markenpopularität, sodass Unternehmen Branchenführer und potenzielle Wachstumsbereiche identifizieren können.
Regionale Suchdaten können auch genutzt werden, um geografische Schwankungen in der Nachfrage zu verstehen. Diese können von Faktoren beeinflusst werden, die über Produktbekanntheit und Saisonalität hinausgehen, wie etwa regionale Vorlieben und kulturelle Trends. Durch das Verständnis dieser Schwankungen können Unternehmen ihre Marketingstrategien optimieren, um bestimmte Regionen effektiv anzusprechen.
SEO und Content-Strategie
Das Scraping von Google Trends-Daten kann eine wertvolle Ergänzung Ihrer SEO-Strategie sein. Hier sind einige Möglichkeiten, wie Sie damit das Suchranking und den organischen Traffic Ihrer Website verbessern können:
- Trend-Keywords identifizieren. Durch die Analyse von Google Trends-Daten können Sie Schlüsselwörter entdecken, die in Ihrer Nische immer beliebter werden. Die Einbindung dieser Schlüsselwörter in Ihren Inhalt kann Ihnen dabei helfen, mehr relevanten Verkehr auf Ihre Website zu lenken.
- Optimieren Sie das Content-Timing. Google Trends kann zeigen, wann das Interesse an bestimmten Themen besonders hoch ist. Nutzen Sie diese Informationen, um die Veröffentlichung Ihrer Blogbeiträge, Artikel und anderer Inhalte so zu planen, dass sie mit diesen Spitzenwerten der Suchanfragen zusammenfallen.
- Wettbewerber recherchieren. Führen Sie mit Google Trends eine Wettbewerbsanalyse durch, um Lücken in Ihrer Content-Strategie zu identifizieren. Finden Sie heraus, für welche Keywords und Themen Ihre Mitbewerber ein Ranking erzielen, für Sie jedoch nicht, und erstellen Sie Content, der auf diese Bereiche abzielt.
Mithilfe der Google Trends-Daten können Sie also mehr organischen Verkehr auf Ihre Website lenken.
Andere Anwendungsfälle
Die Anwendungsmöglichkeiten der aus dem Internet extrahierten Google Trends-Daten sind praktisch unbegrenzt. Unabhängig von Ihrer Branche können Sie die am besten geeignete Anwendung für die von Ihnen gesammelten Daten finden, von der Finanzforschung und Stimmungsanalyse bis hin zur Verfolgung der Konkurrenz und der Prognose zukünftiger Trends auf der Grundlage der von Ihnen gesammelten Daten.
In jedem Fall bieten Google Trends-Daten eine breite Palette an Analysemöglichkeiten sowie Möglichkeiten zur Ideenfindung und Lösungsfindung in verschiedenen Bereichen und sind somit ein wertvolles Tool für Unternehmen, Forschung und Planung. Und durch das Scraping dieser Daten erhalten Sie automatisch die aktuellsten Daten.
Auswählen einer Web Scraping-Methode
Da das Scraping von Google Trends-Daten bei Personen mit unterschiedlichen Programmierkenntnissen sehr gefragt ist, werden wir verschiedene Optionen untersuchen, beginnend mit denen, die überhaupt keine Programmierkenntnisse erfordern, und endend mit komplexeren Methoden zum Erstellen Ihres Scrapers.
Option 1: Verwenden eines Google Trends No-Code Scrapers
Wie bereits erwähnt, können Sie auch ohne Programmierkenntnisse problemlos auf die Google Trends-Daten zugreifen. Sie können dies tun, indem Sie Dienste nutzen, die automatisierte Datenerfassungsfunktionen bieten und gebrauchsfertige Datensätze in einem Format bereitstellen, das Ihren Anforderungen entspricht.
Diese Methode ist unkompliziert und bequem, bietet aber auch die geringste Flexibilität. Sie können den Scraper nicht anpassen oder das Datenformat ändern. Da diese Dienste eine vollständige und gebündelte Lösung bieten, sind Sie auf die von ihnen angebotenen Funktionen beschränkt.
Daher empfiehlt sich diese Vorgehensweise, wenn Sie die Daten schnell benötigen, keine laufende Datenerfassung benötigen und mit den Filtermöglichkeiten und dem Datenformat des gewählten Google Trends No-Code Scrapers zufrieden sind.
Option 2: Verwenden einer Web Scraping API
Neben No-Code-Scrapern und Web-Scraping-Bibliotheken besteht eine weitere Möglichkeit zum Zugriff auf Google Trends-Daten darin, eine Google Trends-API zu verwenden. Google Trends bietet zwar keine offizielle API, es sind jedoch mehrere APIs von Drittanbietern verfügbar, die Ihnen Google Trends-Daten bereitstellen können.
Werfen wir einen Blick auf die Vorteile der Verwendung einer Google Trends-API:
- Vereinfacht den Daten-Scraping-Prozess. APIs bieten eine strukturierte und organisierte Möglichkeit, auf Google Trends-Daten zuzugreifen, sodass keine komplexen Web-Scraping-Techniken mehr erforderlich sind.
- Erhöht die Flexibilität. APIs bieten im Vergleich zu No-Code-Scrapern mehr Flexibilität und ermöglichen Ihnen die Anpassung Ihrer Datenanforderungen und das Abrufen spezifischer Datenpunkte.
- Reduziert die Entwicklungszeit. Durch die Verwendung einer API können Sie Zeit und Aufwand sparen, die Sie sonst für die Entwicklung und Wartung Ihrer Web-Scraping-Lösung aufwenden müssten.
- Mildert häufige Scraping-Herausforderungen. APIs übernehmen Aufgaben wie Proxy-Verwaltung und Captcha-Lösung, die beim manuellen Web Scraping zeitaufwändig und schwierig sein können.
Insgesamt ist die Verwendung einer Google Trends-API ein effizienter und effektiver Ansatz für Entwickler, die den Prozess der Erfassung und Analyse von Google Trends-Daten optimieren möchten.
Option 3: Verwenden einer Web Scraping-Bibliothek
Die nächst schwierigere Methode ist die Verwendung spezialisierter Bibliotheken zum Scrapen von Google Trends-Daten. Die beliebteste davon ist pyTrends. Bevor man es jedoch verwendet, muss man sich über seine Vor- und Nachteile informieren.
Zu den unbedingten Vorteilen dieser Bibliothek gehört die Möglichkeit, Daten ganz einfach abzurufen (im Vergleich zur letzten Option), aber Sie müssen die Probleme im Falle einer Blockierung oder eines Captchas selbst lösen. Darüber hinaus benötigen Sie für die normale Verwendung auf jeden Fall Proxys.
Diese Option eignet sich für diejenigen, die bereits recht gut im Programmieren sind und bereit sind, sich den Schwierigkeiten zu stellen, aber ihren Scraper nicht von Grund auf neu schreiben möchten und nach einer Bibliothek suchen, die beim Abrufen von Daten von der Google Trends-Seite hilfreich sein könnte.
Option 4: Verwenden eines Headless-Browsers
Die Verwendung von Headless-Browserbibliotheken zum Erstellen Ihres Google Trends-Scrapers ist die komplexeste der drei Optionen. Sie setzt voraus, dass Sie mit allen Schritten zum Sammeln und Verarbeiten der erforderlichen Daten vertraut sind, was gute Programmierkenntnisse erfordert.
Wenn Sie mit solchen Bibliotheken nicht vertraut sind, aber mehr darüber erfahren möchten, lesen Sie unseren Artikel zum Headless-Browser-Scraping. Wenn Sie von Ihren Fähigkeiten überzeugt sind und Ihr eigenes Scraping-Tool für Google Trends erstellen möchten, bietet Ihnen dieser Artikel ebenfalls eine Anleitung.
Zusammenfassend lässt sich sagen, dass dies der anspruchsvollste Ansatz ist, der jedoch die meisten Anpassungsmöglichkeiten bietet und es Ihnen ermöglicht, alle benötigten Daten zu extrahieren.
Voraussetzungen
Node.js und Python sind die beiden beliebtesten Programmiersprachen für Web Scraping. Python gilt jedoch im Allgemeinen als einfacher zu erlernen und zu verwenden, selbst für Anfänger. Daher werden wir in diesem Tutorial Python verwenden.
Um den Beispielen in diesem Tutorial folgen zu können, benötigen Sie Folgendes:
- Python 3.10 oder höher;
- Eine Python-IDE oder ein beliebiger Code-Editor mit Syntaxhervorhebung.
Wenn Sie neu in der Python-Programmierung sind, können Sie unseren Einführungsartikel lesen, der den Installationsprozess und die Erstellung Ihres ersten Web Scrapers behandelt.
Zusätzlich zu Python müssen wir auch die folgenden Bibliotheken installieren:
pip install requests json csv pytrends seleniumFür die volle Funktionalität mit Selenium benötigen Sie möglicherweise auch zusätzliche Dateien, z. B. einen Webtreiber (nur für ältere Versionen von Selenium erforderlich). Weitere Informationen finden Sie in unserem Leitfaden zum Web Scraping mit Selenium.
Verwenden von Google Trends Scrapern ohne Code
Wie versprochen beginnen wir mit den einfachsten Methoden zum Daten-Scraping, für die nicht einmal Programmierkenntnisse erforderlich sind, und gehen dann zu komplexeren und fortgeschritteneren Methoden über. Beginnen wir daher mit der einfachsten Methode und zeigen Ihnen, wie Sie mit vorgefertigten Tools an Google Trends-Daten gelangen.
Für dieses Beispiel verwenden wir den No-Code-Scraper „Google Trends“ von HasData. Um zu beginnen, müssen Sie sich auf unserer Website anmelden. Melden Sie sich nach der Registrierung an und navigieren Sie zum No-Code-Scraper-Marktplatz.
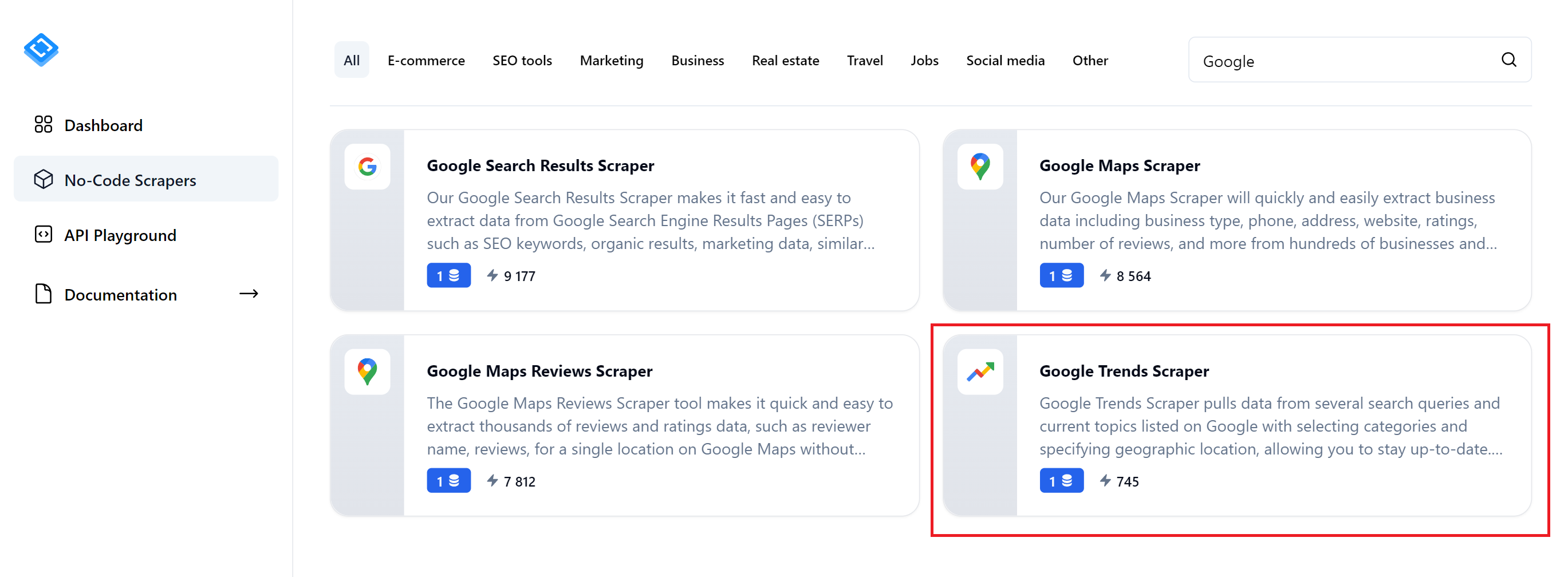
Suchen und navigieren Sie zur Seite eines No-Code-Scrapers für Google Trends.
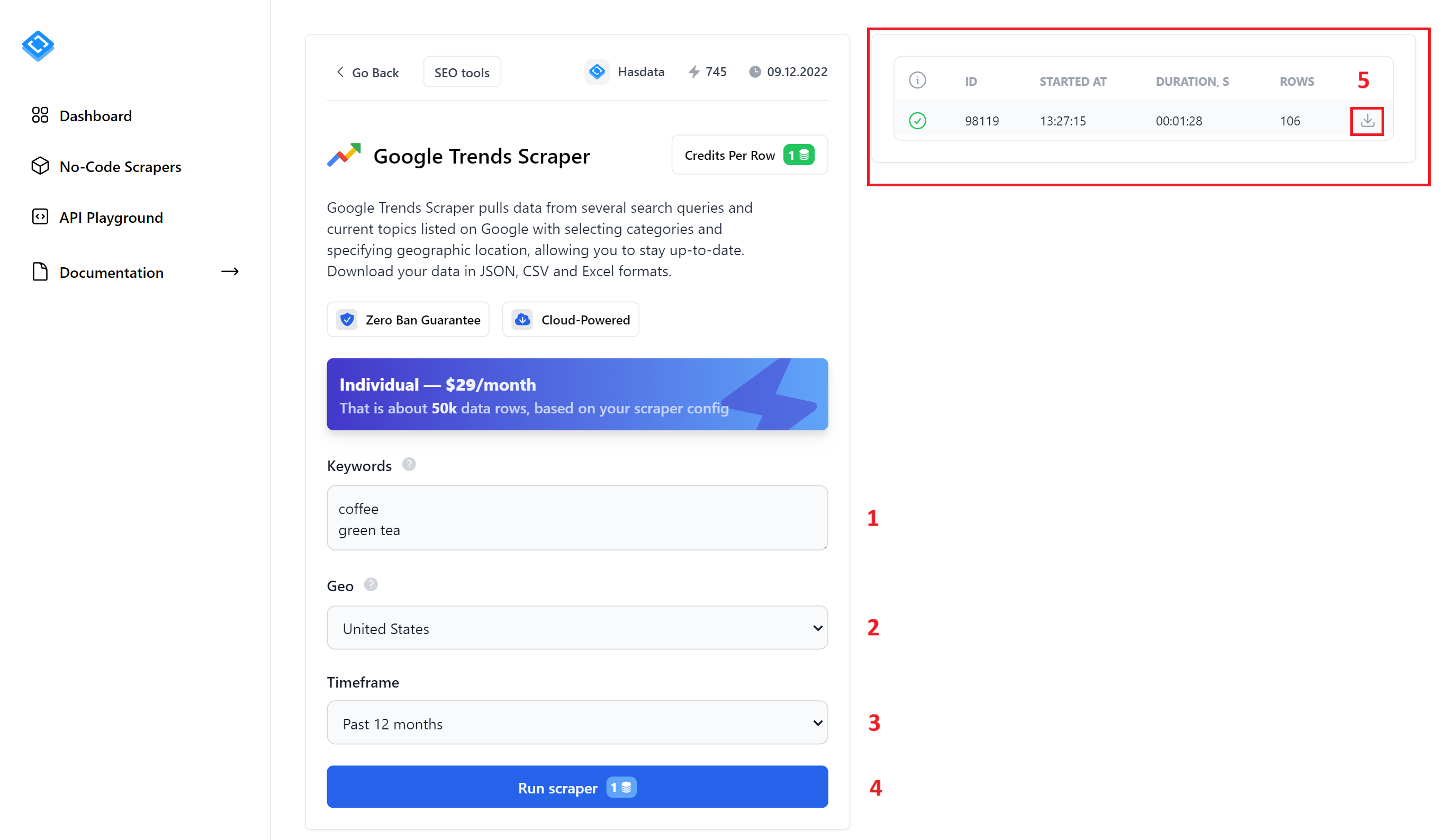
Lassen Sie uns die Elemente auf dieser Seite aufschlüsseln:
- Schlüsselwörter. Geben Sie hier Ihre Zielschlüsselwörter ein, eines pro Zeile.
- Geo. Geben Sie die Region an, die Sie ansprechen möchten.
- Zeitfenster. Legen Sie den Datumsbereich für Ihre Suchergebnisse fest.
- Scraper ausführen. Wenn Sie alle Parameter eingestellt haben, klicken Sie auf diese Schaltfläche, um den Scraping-Vorgang zu starten. Ihr Fortschritt wird auf der rechten Seite des Bildschirms angezeigt.
- Scraping-Ergebnisse. Dieser Abschnitt zeigt Ihnen alle Ergebnisse Ihrer No-Code-Scraping-Läufe. Sie können die Daten auch in einem praktischen Format herunterladen: JSON, CSV oder XLSX.
Wie Sie sehen, ist die Einrichtung und Ausführung dieses Tools ganz einfach. Hier ist ein Beispiel für die Daten, die Sie erwarten können:
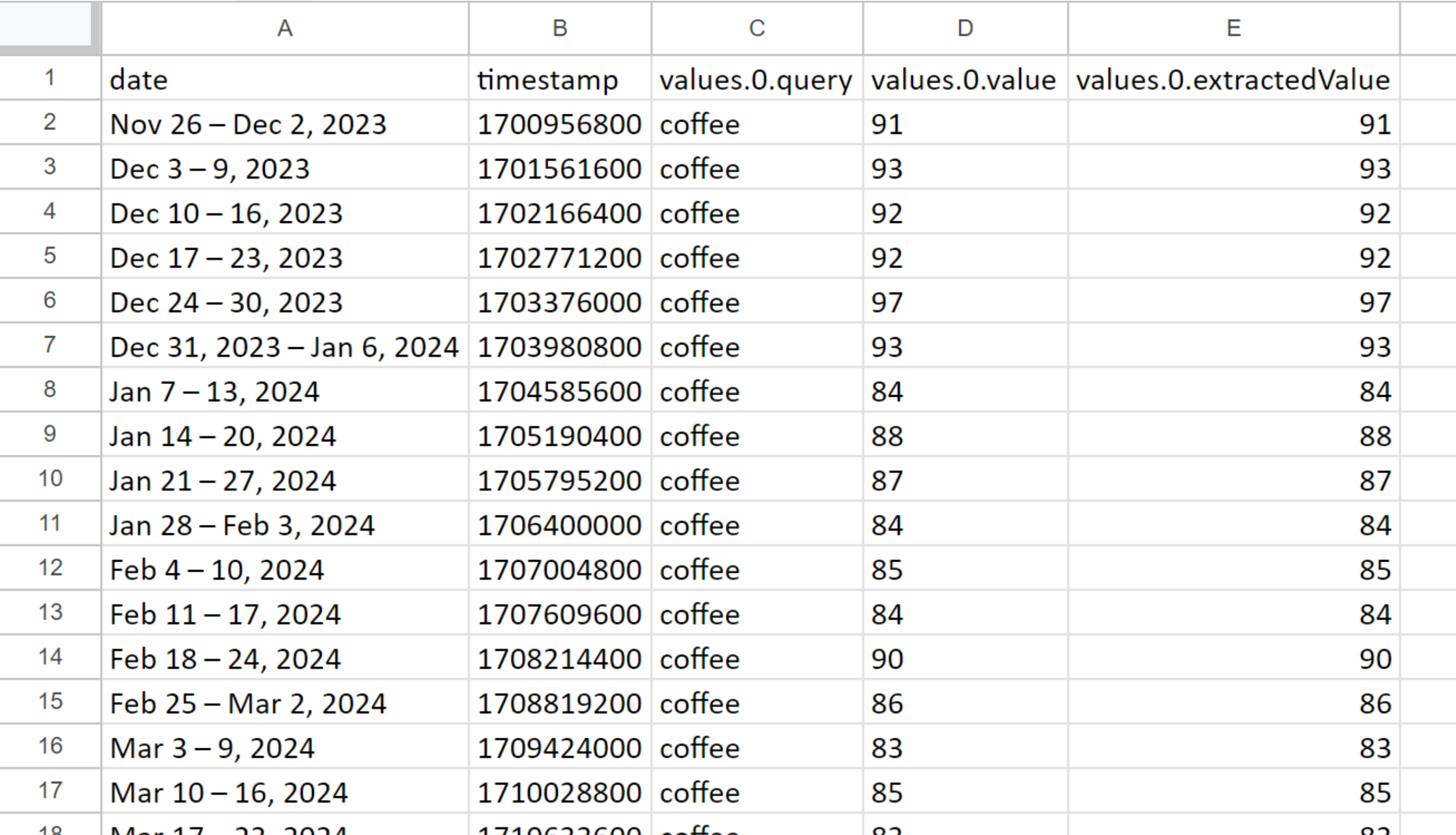
Wie Sie sehen, können Sie mit dem No-Code-Scraper von Google Trends auch ohne Programmierkenntnisse auf Suchdaten für jeden Zeitraum zugreifen, der Sie interessiert.
Holen Sie sich die Daten mit der Google Trends API
Wenn Sie Ihr Skript erstellen möchten, verwenden wir anstelle eines No-Code-Scrapers die Google Trends API von HasData und erstellen unser Skript. Dazu müssen Sie sich wie bei der vorherigen Methode auf unserer Website anmelden, um einen API-Schlüssel zu erhalten. Sie finden ihn auf der Hauptseite Ihres Kontos.
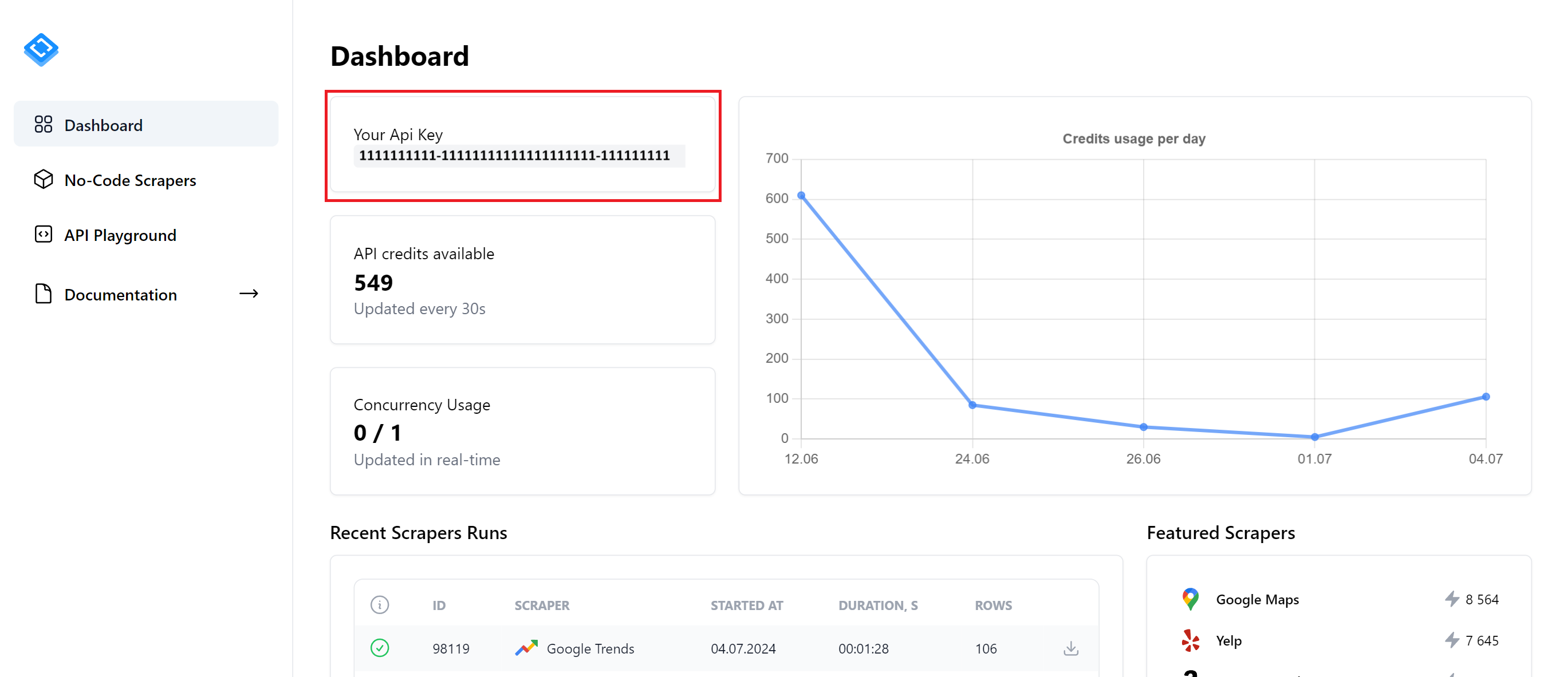
Als Nächstes können Sie den API Playground verwenden, um Ihre Parameter festzulegen und Code in einer beliebigen Programmiersprache zu generieren, oder Sie können die Dokumentation verwenden und den Code selbst schreiben.
Im Gegensatz zu einem No-Code-Scraper bietet die Google Trends API eine größere Auswahl an Parametern, mit denen Sie Ihre Abfrage anpassen können. Mit der API können Sie die folgenden Parameter angeben:
- Suchanfrage. Das Herzstück Ihrer Suche. Es definiert das Schlüsselwort oder die Phrase, die Sie untersuchen möchten.
- Standort. Geben Sie den geografischen Bereich für Ihre Abfrage an und beschränken Sie die Ergebnisse auf ein bestimmtes Land, eine bestimmte Region oder eine bestimmte Stadt.
- Region. Nutzen Sie die Funktion „Regionalsuche“, mit der Sie gezielt nach Gebieten wie Städten, Ballungsräumen, Ländern oder Unterregionen suchen können.
- Datentyp. Wählen Sie den abzurufenden Datentyp aus: Interesse im Zeitverlauf, Interesse nach Region, verwandte Themen oder verwandte Abfragen.
- Zeitzone. Definieren Sie die relevante Zeitzone, um Suchmuster in verschiedenen Regionen genau interpretieren zu können.
- Kategorie. Grenzen Sie Ihre Suche ein, indem Sie eine bestimmte Kategorie auswählen, ähnlich der Funktion auf der Google Trends-Website.
- Google-Eigentum. Filtern Sie die Ergebnisse basierend auf der Suchquelle, z. B. Google-Suche, Nachrichten, Bilder oder YouTube-Suche.
- Datumsbereich. Geben Sie den Zeitraum an, für den Sie Daten abrufen möchten, und stellen Sie sicher, dass Sie die relevantesten Trends erfassen.
Mit diesen Parametern können Sie die Anfrage auf die für Sie am besten geeignete Weise anpassen. Wie bereits erwähnt, können Sie alle erforderlichen Parameter im API-Spielplatz festlegen und den vorgefertigten Code einfach in eine beliebige Programmiersprache kopieren, die für Sie geeignet ist. Wir erstellen beispielsweise einen solchen Code von Grund auf neu.
Sie können die vorgefertigte Version des betreffenden Skripts auch im Google Collaboratory anzeigen und ausführen.
Erstellen Sie zunächst eine neue Datei mit der Erweiterung .py und importieren Sie die erforderlichen Bibliotheken. Da die meiste Arbeit von der API erledigt wird, benötigen wir nur eine Bibliothek, um Anfragen zu stellen und mit JSON-Daten zu arbeiten, da die API Daten im JSON-Format zurückgibt.
import requests
import jsonAls nächstes definieren wir Variablen mit den Parametern, die wir festlegen möchten. Eine vollständige Liste der Parameter finden Sie in unserer offiziellen Dokumentation.
query = "Coffee"
geo = "US-NY"
region = "dma"
data_type = "geoMap"
category = "65"
date_range = "now 7-d".replace(" ", "+")Dann verfassen Sie den Link:
url = f"https://api.hasdata.com/scrape/google-trends/search?q={query}&geo={geo}®ion={region}&dataType={data_type}&cat={category}&date={date_range}"Fügen Sie Ihren API-Schlüssel in die Anforderungsheader ein:
headers = {
'Content-Type': 'application/json',
'x-api-key': 'PUT-YOUR-API-KEY'
}Stellen Sie die Anfrage und drucken Sie die Antwort auf dem Bildschirm aus:
response = requests.request("GET", url, headers=headers)
print(response.text)Als Ergebnis erhalten Sie Daten wie in diesem Beispiel:
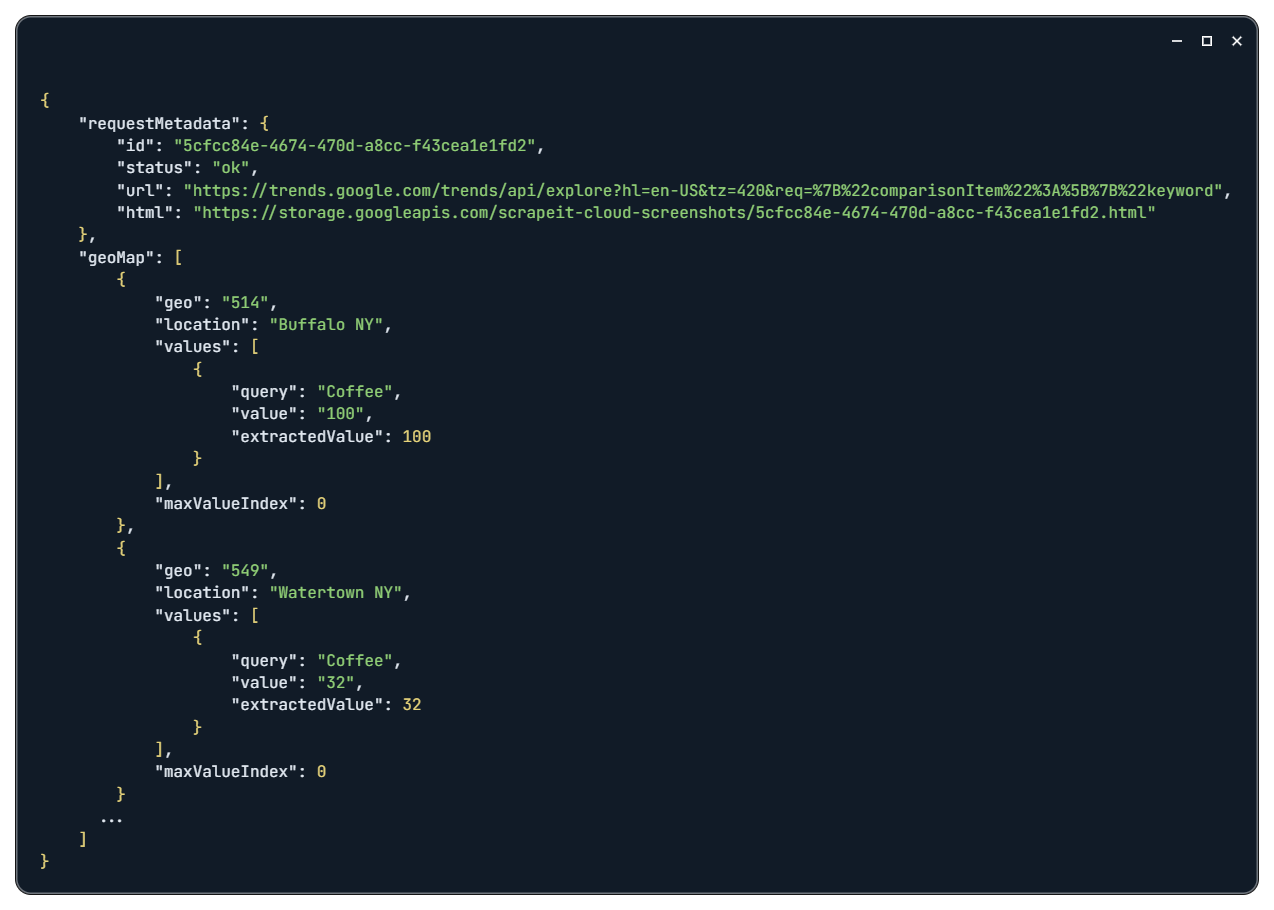
Wie Sie sehen, gibt die API zusätzlich zu den Daten selbst auch eine Anforderungs-URL und einen Screenshot der ausgeführten Abfrageseite zurück.
Mit diesen Informationen können Sie die abgerufenen Daten entweder verarbeiten oder für die spätere Verwendung speichern. Lassen Sie uns die Daten beispielsweise in einer JSON-Datei speichern:
data = response.json()
with open("google_trends_data.json", "w") as json_file:
json.dump(data, json_file, indent=4)Sie können die Daten auch in einer Datei in einem anderen für Sie geeigneten Format speichern, beispielsweise CSV.
Scrapen Sie Google Trends mithilfe der PyTrends-Bibliothek
Eine andere Methode besteht in der Verwendung der PyTrends-Bibliothek, die den Daten-Scraping-Prozess rationalisiert. Sie basiert auf einfachen Abfragen und verwendet die Bibliotheken Requests und BeautifulSoup zum Scraping, weist also gewisse Einschränkungen auf.
Scrapen Sie die Daten mit PyTrends
Lassen Sie uns einen einfachen Web Scraper erstellen, um Daten über Interessen nach Region zu extrahieren. Erstellen Sie dazu ein neues Python-Skript und importieren Sie die erforderlichen Bibliotheken in das Projekt:
from pytrends.request import TrendReqErstellen Sie dann ein Sitzungs-pyTrend-Objekt:
pytrend = TrendReq()Und stellen Sie eine Anfrage, um ein TOKEN zu erhalten:
pytrend.build_payload(kw_list=('coffee', 'green tea'))Anschließend können Sie auf die gewünschten Keyword-Daten zugreifen. Um beispielsweise Daten nach Region abzurufen und anzuzeigen, verwenden Sie den folgenden Code:
interest_by_region_df = pytrend.interest_by_region()
print(interest_by_region_df.head())Als Ergebnis erhalten Sie folgende Daten:
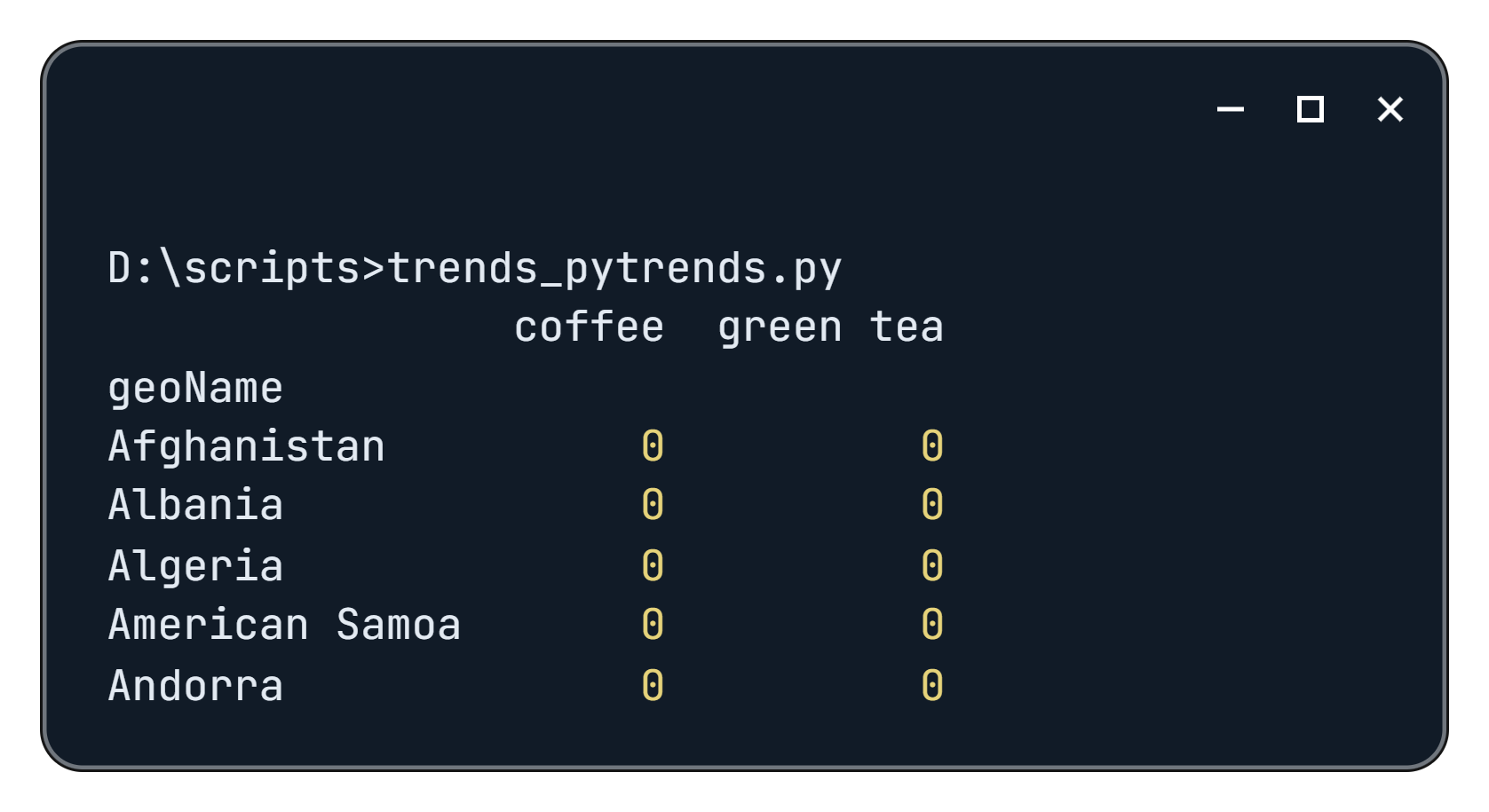
Leider hat die Verwendung der PyTrends-Bibliothek, wie bereits erwähnt, ihre Nachteile und Einschränkungen. Für die volle Funktionalität müssen Sie Proxys verwenden. Wenn Sie sich entscheiden, diese nicht zu verwenden, schlägt Ihr Skript mit einem 429-Fehler fehl.
429 Fehler für PyTrends
Die vollständige Fehlermeldung lautet „pytrends.exceptions.TooManyRequestsError: Die Anfrage ist fehlgeschlagen: Google hat eine Antwort mit dem Code 429 zurückgegeben“. Dies weist normalerweise darauf hin, dass Google Ihre Anfrage als verdächtig markiert hat und sich weigert, Daten zurückzugeben. Um dieses Problem zu beheben, müssen Sie in Ihrem Skript Proxys verwenden.
Wir haben bereits besprochen, wie man Proxys in Python verwendet. Es ist jedoch erwähnenswert, dass PyTrends spezielle Funktionen für diesen Zweck bietet. Geben Sie einfach die erforderlichen Parameter während der Objekterstellung an:
pytrend = TrendReq(hl="en-US", tz=360, proxies=('https://128.3.21.11:8080',))Es ist wichtig hervorzuheben, dass PyTrends nur HTTPS-Proxys unterstützt. Sie können entweder kostenlose Proxys auf unserer Seite mit der Liste kostenloser Proxys finden, um diese Funktionalität zu testen, oder Proxys von einem zuverlässigen Anbieter erwerben.
Verwenden Sie Selenium, um Google Trends zu scrapen
Die komplexeste und zugleich flexibelste Möglichkeit zum Scrapen von Daten aus Google Trends besteht darin, Ihr Tool mithilfe einer Bibliothek wie Selenium oder einer anderen Bibliothek zu erstellen, die Headless-Browser unterstützt.
Zur Beschaffung der benötigten Daten diskutieren wir hier zwei Möglichkeiten:
- Standardmethode. Bei dieser Methode müssen Sie zur Seite navigieren und deren Inhalt analysieren. Dies ist eine komplexere Methode, da es etwas schwierig sein kann, die erforderlichen Selektoren zu finden.
- Ein kleiner Trick, um an die benötigten Daten zu kommen. Auf diese Weise können Sie alle benötigten Daten abrufen, auch wenn Sie sich nicht mit Selektoren befassen möchten.
Egal für welche Methode Sie sich entscheiden, Sie erhalten alle benötigten Daten von Google Trends.
Standard-Schabeverfahren
Bei dieser Methode wird ein Headless-Browser wie Selenium verwendet, um Benutzerinteraktionen zu simulieren und Daten aus Webseiten zu extrahieren. Dieser Ansatz ist zwar relativ einfach, kann aber zeitaufwändig sein. Um ihn zu verwenden, folgen Sie einfach diesem Algorithmus:
- Formulierung der URL. Erstellen Sie die URL basierend auf den angegebenen Parametern. Dazu müssen Sie die URL-Struktur verstehen und die gewünschten Suchbegriffe, Zeiträume und Standortfilter integrieren.
- Zur Seite navigieren. Verwenden Sie einen Headless-Browser wie Selenium, um einen Benutzerbesuch der erstellten URL zu simulieren. Dies ermöglicht die Interaktion mit der dynamischen Webseite ohne physischen Browser.
- Scraping der Daten. Verwenden Sie Web Scraping-Techniken, um die relevanten Daten aus dem HTML-Inhalt der Seite zu extrahieren. Dies kann das Identifizieren und Parsen bestimmter Elemente mithilfe von XPath- oder CSS-Selektoren beinhalten.
- Verarbeitung und Speicherung der Daten. Bereinigen, organisieren und formatieren Sie die extrahierten Daten in ein strukturiertes Format wie CSV oder JSON. Speichern Sie die verarbeiteten Daten zur weiteren Analyse oder Visualisierung.
Lassen Sie uns nun den besprochenen Algorithmus implementieren. Zunächst müssen wir die Muster identifizieren, die die Bildung der URL bestimmen. Dazu besuchen wir die Google Trends-Seite und untersuchen alle verfügbaren Filter. Anschließend analysieren wir, wie sich die URL basierend auf den ausgewählten Parametern ändert.
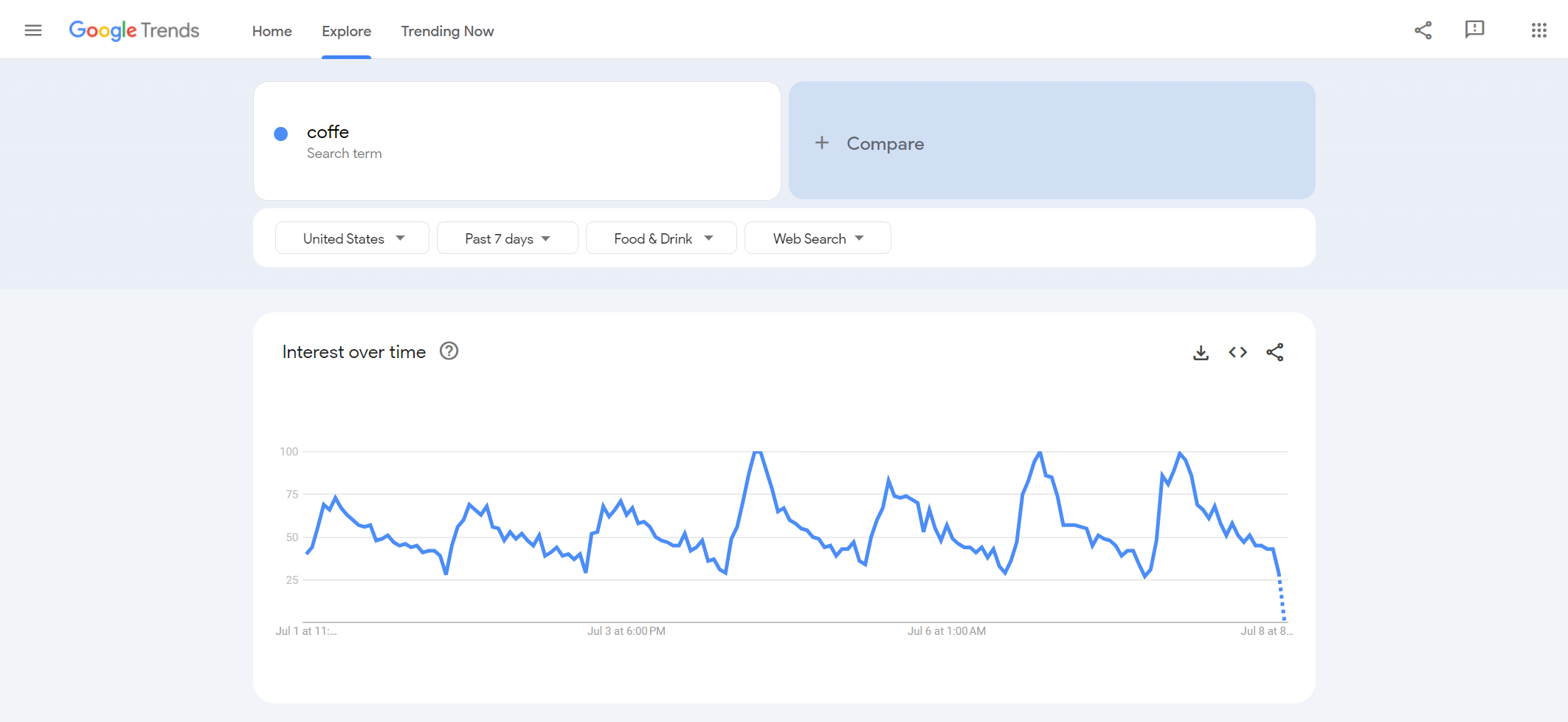
Beispielsweise wäre unter Verwendung der besprochenen Parameter (Land – USA, Kategorie – Essen und Getränke, Zeit – letzte 7 Tage, Schlüsselwort – Kaffee) der folgende Link relevant:
https://trends.google.com/trends/explore?cat=71&date=now%207-d&geo=US&q=coffeBeginnen wir mit der Erstellung eines Skripts und dem Importieren der erforderlichen Bibliotheken und Module:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
import timeAls nächstes konfigurieren wir die Einstellungen und generieren einen Link:
category = "71"
date_range = "now 7-d"
geo = "US"
query = "coffee"
url = f"https://trends.google.com/trends/explore?cat={category}&date={date_range}&geo={geo}&q={query}"Erstellen Sie dann ein WebDriver-Objekt:
chrome_options = Options()
driver = webdriver.Chrome(options=chrome_options)Jetzt können Sie mit der Seite fortfahren. Allerdings gibt es hier eine kleine Nuance. Wenn Sie einem direkten Link direkt zur Seite mit den erforderlichen Parametern folgen, erhalten Sie die folgende Fehlermeldung:
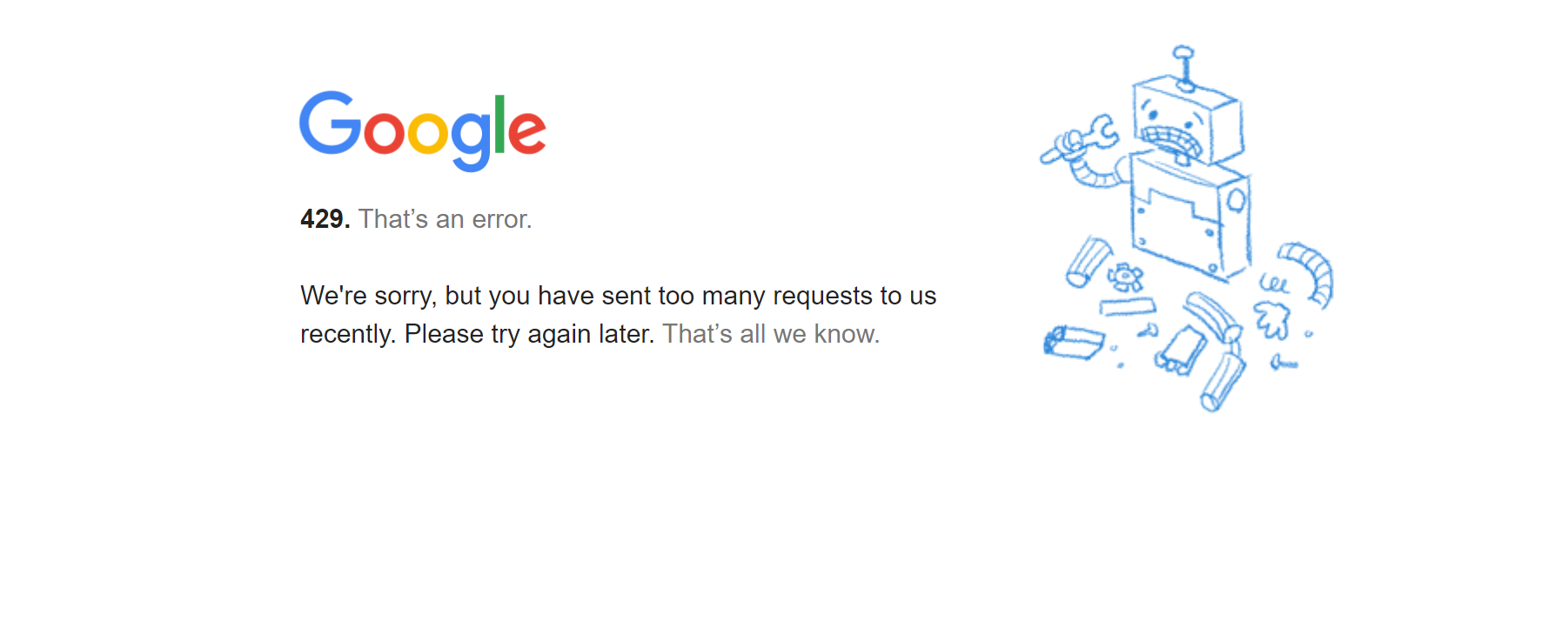
Dieser Fehler lässt sich leicht vermeiden, indem Sie die Seite von der Hauptseite von Google Trends aus aufrufen oder dem Link zweimal folgen:
driver.get(url)
driver.get(url)Schauen wir uns die Seite genauer an und verwenden einen der Blöcke, um den Daten-Scraping-Prozess zu veranschaulichen. Als Beispiel sammeln wir Daten zu „Ähnlichen Abfragen“. Sehen wir uns diesen Abschnitt genauer an:
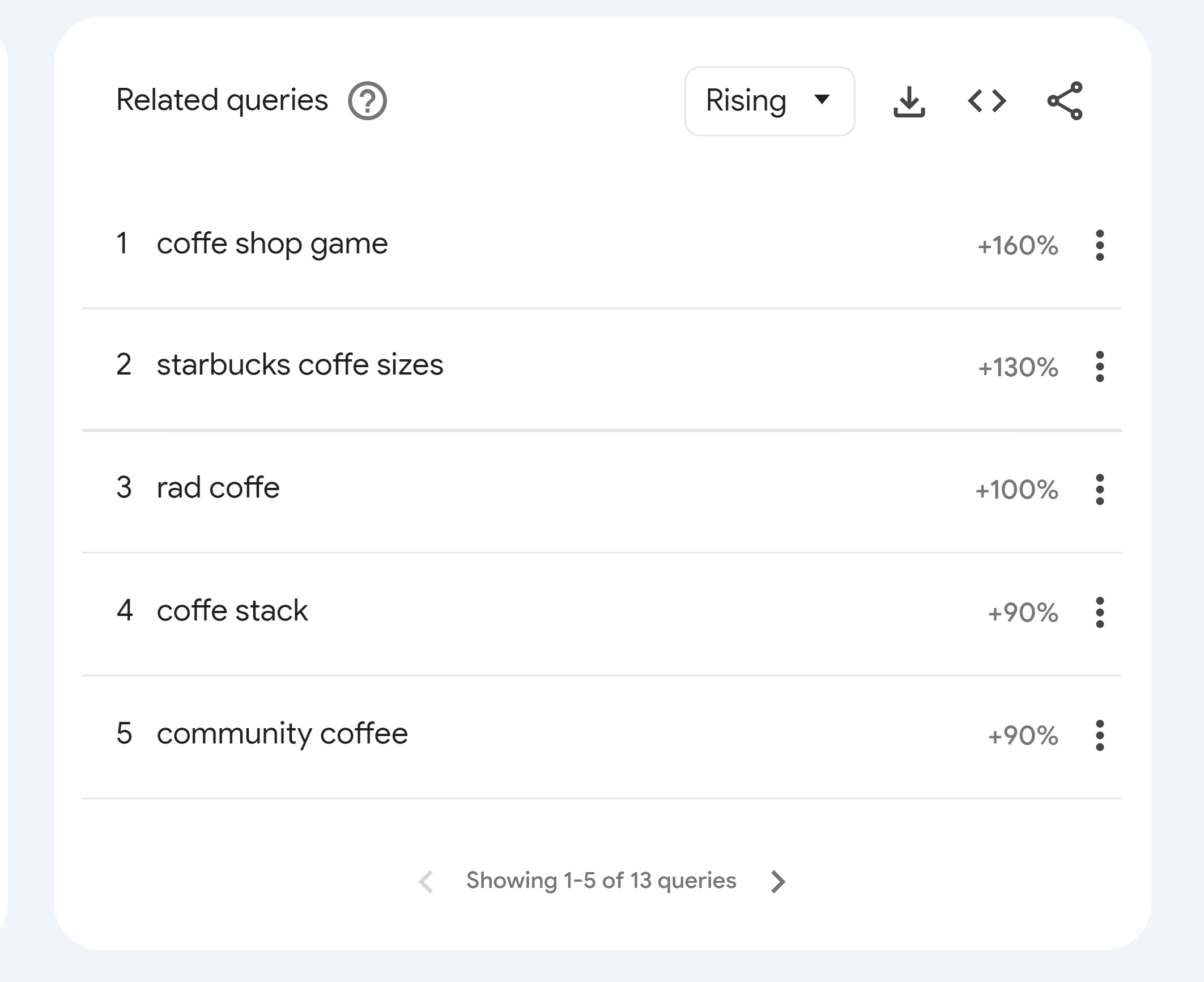
Wenn Sie das HTML der Seite mit DevTools überprüfen (drücken Sie F12 oder klicken Sie mit der rechten Maustaste und wählen Sie „Überprüfen“), wird deutlich, dass der Abschnitt „Ähnliche Suchvorgänge“ in einem Div-Element mit der Klasse „.fe-related-queries“ enthalten ist. Die einzelnen verwandten Suchelemente in diesem Abschnitt haben die Klasse „.item“.
Fahren wir mit dem Scraping dieser Daten fort:
related_queries_div = driver.find_element(By.CSS_SELECTOR, '.fe-related-queries')
items = related_queries_div.find_elements(By.CSS_SELECTOR, '.item')Um die Datenorganisation zu verbessern, verwenden wir ein Listenformat:
related_queries = ()
for item in items:
parts = item.text.split('\n')
if len(parts) == 4:
rank, title_category, score, more = parts
title, category = title_category.split(' - ')
related_queries.append({
'rank': rank,
'title': title,
'category': category,
'score': score
})Drucken Sie die Google Trends-Daten auf dem Bildschirm aus und schließen Sie den Webtreiber:
print(related_queries)
driver.quit()Als Ergebnis erhalten Sie folgende Daten:
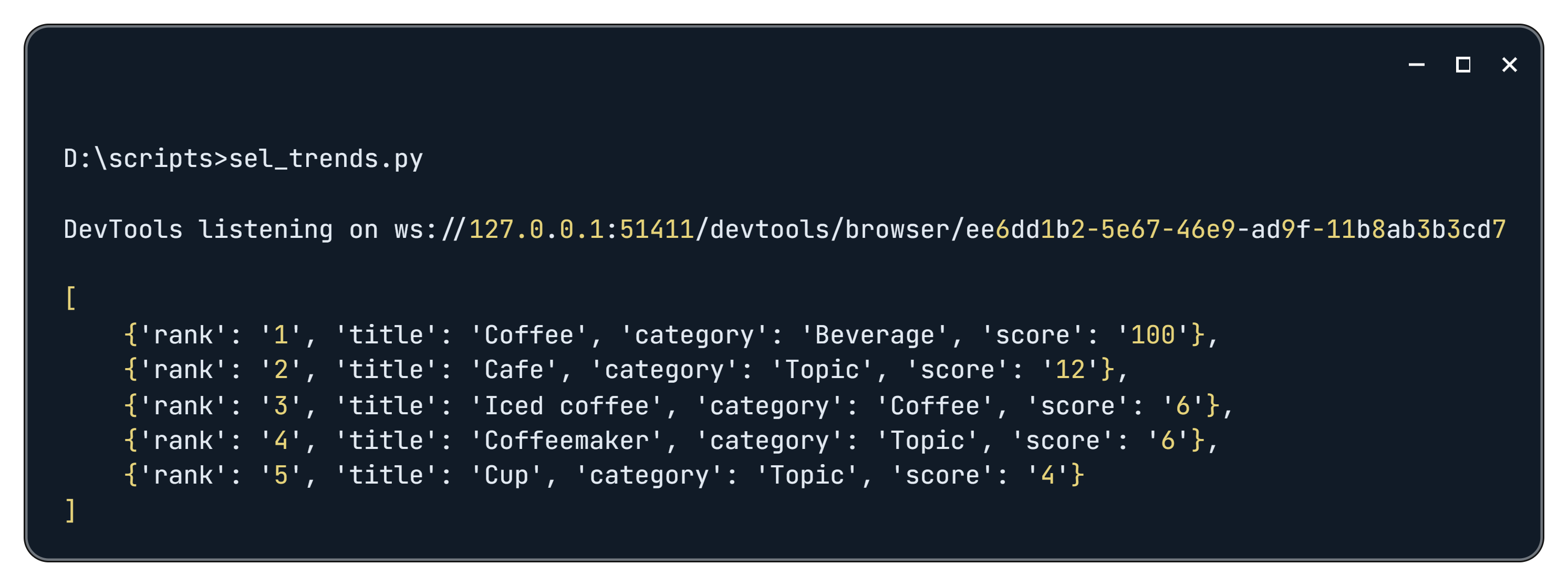
Sie können Selenium auch zur Paginierung verwenden, um möglichst umfassende Daten zu sammeln. Darüber hinaus können Daten aus anderen Blöcken auf ähnliche Weise extrahiert werden, da sich nur die Selektoren unterscheiden.
Ein Trick, um schnell und einfach an Daten zu kommen
Wie wir eingangs erwähnt haben, gibt es einen viel einfacheren Weg, an Google Trends-Daten zu gelangen, nämlich sie einfach herunterzuladen. Neben jedem Block befindet sich eine Download-Schaltfläche, mit der Sie die Daten herunterladen können:
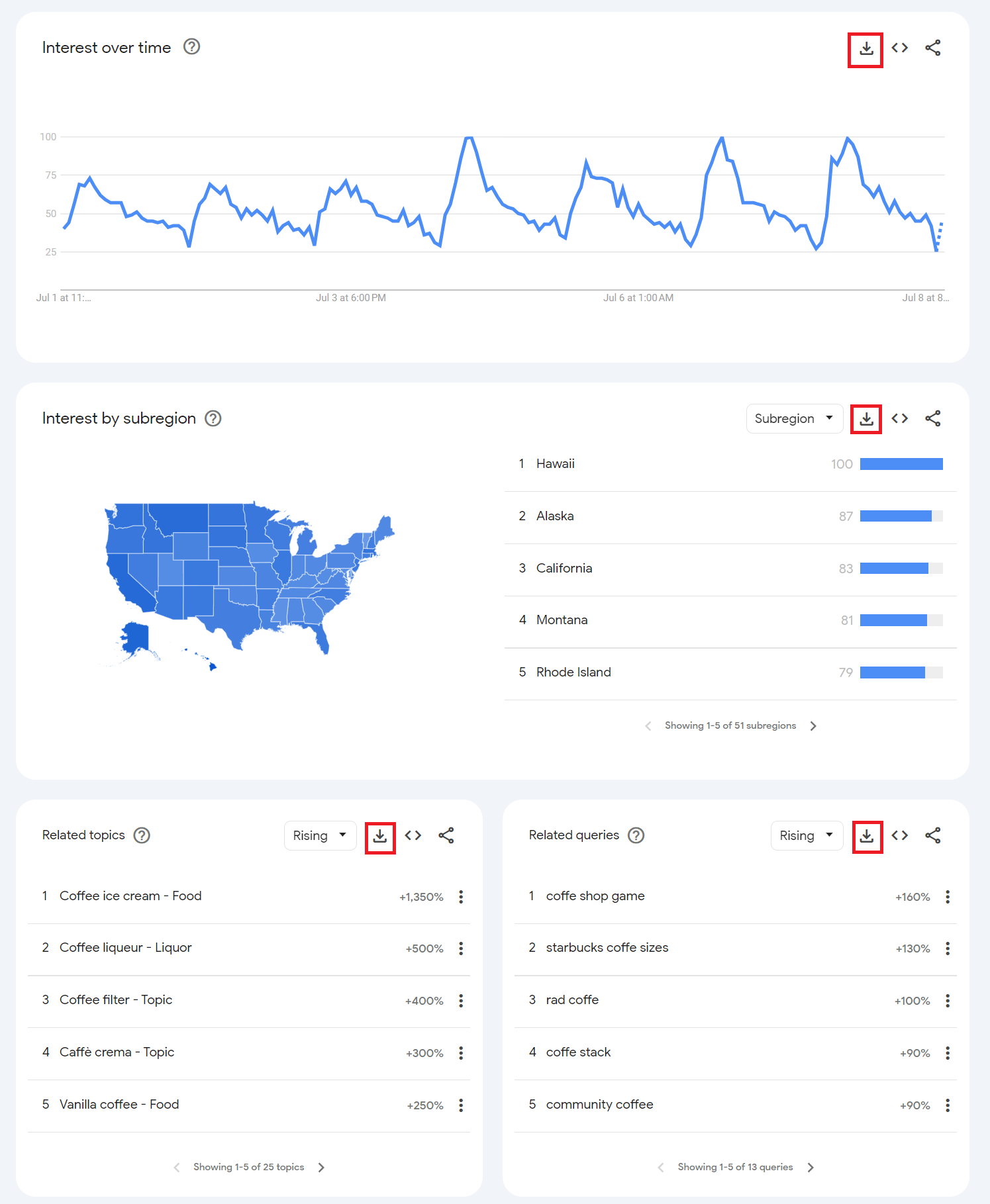
Anstatt diese Daten manuell zu erfassen, können wir sie einfach alle auf einmal herunterladen. Die Skriptstruktur bleibt bis auf den Seitennavigationsteil gleich:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
category = "71"
date_range = "now 7-d"
geo = "US"
query = "coffee"
url = f"https://trends.google.com/trends/explore?cat={category}&date={date_range}&geo={geo}&q={query}"
chrome_options = Options()
driver = webdriver.Chrome(options=chrome_options)
driver.get(url)
driver.get(url)Laden Sie dann die verfügbaren Google Trends-Daten herunter:
export_buttons = driver.find_elements(By.CSS_SELECTOR, '.widget-actions-item.export')
for button in export_buttons:
button.click()
time.sleep(1) Als Ergebnis erhalten wir vier Dateien mit allen Daten der Seite:
Durch diese Vorgehensweise erhalten Sie alle Daten schnell und unkompliziert. Zudem sind die Daten gut strukturiert und können für die weitere Verarbeitung genutzt werden.
Abschluss
Dieser Artikel befasst sich mit den praktischen Anwendungen von Google Trends-Daten in verschiedenen Branchen und Anwendungsfällen. Wir haben Methoden untersucht, die von einfachen No-Code-Lösungen bis hin zu fortgeschrittenen Web-Scraping-Techniken unter Verwendung von APIs und Bibliotheken reichen.
Darüber hinaus haben wir Algorithmen und Beispiele für den Aufbau Ihrer Scraper bereitgestellt, damit Sie in Zukunft selbstständig Daten sammeln können. Abschließend haben wir einen raffinierten Trick enthüllt, mit dem Sie alle erforderlichen Daten relativ einfach und ohne großen Aufwand erfassen können.
In diesem Leitfaden haben wir versucht, alle möglichen Scraping-Methoden für Google Trends abzudecken und die Vor- und Nachteile jedes Ansatzes hervorzuheben. Darüber hinaus haben wir durch die Einbeziehung auch nicht-codierender Optionen sichergestellt, dass jeder, unabhängig von seinem technischen Fachwissen, eine geeignete Methode finden kann.
