
TL;DR: Vollständiger GitHub Repos Scraper
Hier ist der fertige GitHub Repository Scraper für alle, die es eilig haben:
import requests
from bs4 import BeautifulSoup
import json
url = 'https://github.com/psf/requests'
payload = {
'api_key': 'YOUR_API_KEY',
'url': url,
'render': 'true',
}
page = requests.get('https://api.scraperapi.com', params=payload)
soup = BeautifulSoup(page.text, 'html.parser')
repo = {}
name_html_element = soup.find('strong', {"itemprop": "name"})
repo('name') = name_html_element.get_text().strip()
relative_time_html_element = soup.find('relative-time')
repo('latest_commit') = relative_time_html_element('datetime')
branch_element = soup.find('span', {"class": "Text-sc-17v1xeu-0 bOMzPg"})
repo('branch') = branch_element.get_text().strip()
commit_element = soup.find('span', {"class": "Text-sc-17v1xeu-0 gPDEWA fgColor-default"})
repo('commit') = commit_element.get_text().strip()
stars_element = soup.find('span', {"id": "repo-stars-counter-star"})
repo('stars') = stars_element.get_text().strip()
forks_element = soup.find('span', {"id": "repo-network-counter"})
repo('forks') = forks_element.get_text().strip()
description_html_element = soup.find('p', {"class":"f4 my-3"})
repo('description') = description_html_element.get_text().strip()
main_branch = repo('branch')
readme_url = f'https://raw.githubusercontent.com/psf/requests/{main_branch}/README.md'
readme_page = requests.get(readme_url)
if readme_page.status_code != 404:
repo('readme') = readme_page.text
print(repo)
with open('repo.json', 'w') as file:
json.dump(repo, file, indent=4)
print('Data saved to repo.json')
Bevor Sie den Code ausführen, fügen Sie Ihren API-Schlüssel zum
api_key Parameter innerhalb der Nutzlast.
Notiz: Sie haben keinen API-Schlüssel? Erstellen Sie ein kostenloses ScraperAPI-Konto, um 5.000 API-Credits zu erhalten und alle unsere Tools sieben Tage lang auszuprobieren.
Möchten Sie sehen, wie wir es gebaut haben? Lesen Sie weiter!
Scraping von GitHub-Repos mit Python
Schritt 1: Richten Sie Ihr Projekt ein
Beginnen Sie mit der Einrichtung Ihrer Projektumgebung. Erstellen Sie ein neues Verzeichnis für Ihr Projekt und eine neue Datei für Ihr Skript.
Führen Sie Folgendes in Ihrem Terminal aus:
mkdir github-scraper
cd github-scraper
touch app.py
Schritt 2: Installieren Sie die erforderlichen Bibliotheken
Um Daten von GitHub abzurufen, benötigen Sie zwei wichtige Bibliotheken: requests und BeautifulSoup. Diese Bibliotheken übernehmen das Abrufen der Webseite und das Parsen ihres Inhalts.
requests ermöglicht Ihnen das einfache Senden von HTTP-Anfragen in Python und
BeautifulSoup wird zum Parsen von HTML- und XML-Dokumenten verwendet.
Installieren Sie beide Bibliotheken mit pip:
pip install requests beautifulsoup4
Schritt 3: Laden Sie die Zielseite mit ScraperAPI herunter
Wählen Sie ein GitHub-Repository aus, aus dem Sie Daten abrufen möchten. Für dieses Beispiel verwenden wir das Requests-Repository.
Zuerst importieren wir die notwendigen Bibliotheken: requests,
BeautifulSoupUnd JSON; dann legen wir die URL des GitHub-Repositorys fest, das wir scrapen möchten, indem wir es im
url Variable.
import requests
from bs4 import BeautifulSoup
import json
url = 'https://github.com/psf/requests'
Als Nächstes bereiten wir das Payload-Wörterbuch vor, das Ihren ScraperAPI-API-Schlüssel, die URL und den Renderparameter enthält.
Der Render-Parameter stellt sicher, dass der von JavaScript gerenderte Inhalt in die Antwort aufgenommen wird.
Notiz: Sie haben keinen API-Schlüssel? Erstellen Sie ein kostenloses ScraperAPI-Konto, um 5.000 API-Credits zu erhalten und alle unsere Tools 7 Tage lang auszuprobieren.
payload = {
'api_key': 'YOUR_API_KEY',
'url': url,
'render': 'true',
}
Wir gebrauchen requests.get() um eine GET-Anfrage an ScraperAPI zu senden und die Nutzlast als Parameter zu übergeben. ScraperAPI verarbeitet die Anfrage, kümmert sich um die IP-Rotation, um Anti-Scraping-Maßnahmen zu umgehen, und gibt den HTML-Inhalt zurück.
page = requests.get('https://api.scraperapi.com', params=payload)
Wichtig
Wir senden unsere Anfragen über ScraperAPI, um eine Blockierung durch die Anti-Bot-Erkennungssysteme von GitHub zu vermeiden.
ScraperAPI verwendet maschinelles Lernen und jahrelange statistische Analyse, um die richtige Kombination aus IP und Headern auszuwählen und diese beiden bei Bedarf intelligent zu wechseln, um eine erfolgreiche Anfrage sicherzustellen.
Schritt 4: Analysieren Sie das HTML-Dokument
Nach dem Herunterladen der Zielseite besteht der nächste Schritt darin, das HTML-Dokument zu analysieren, um die benötigten Daten zu extrahieren.
Wir übergeben den HTML-Inhalt an BeautifulSoup, um einen Parse-Baum zu erstellen. Dies ermöglicht Ihnen eine einfache Navigation und Suche in der HTML-Struktur:
soup = BeautifulSoup(page.text, 'html.parser')
Schritt 5: Das Seitenlayout des Github-Repository verstehen
Bevor wir die Daten extrahieren, müssen wir die HTML-Elemente auf der Webseite identifizieren, die die benötigten Daten enthalten.
Öffnen Sie dazu die Repository-Seite in Ihrem Browser und überprüfen Sie die HTML-Struktur mit DevTools. So können wir besser verstehen, wie wir Elemente auswählen und Daten effektiv extrahieren. Indem wir das Seitenlayout untersuchen und die Tags und Attribute identifizieren, sind wir besser gerüstet, um die benötigten Daten abzurufen.
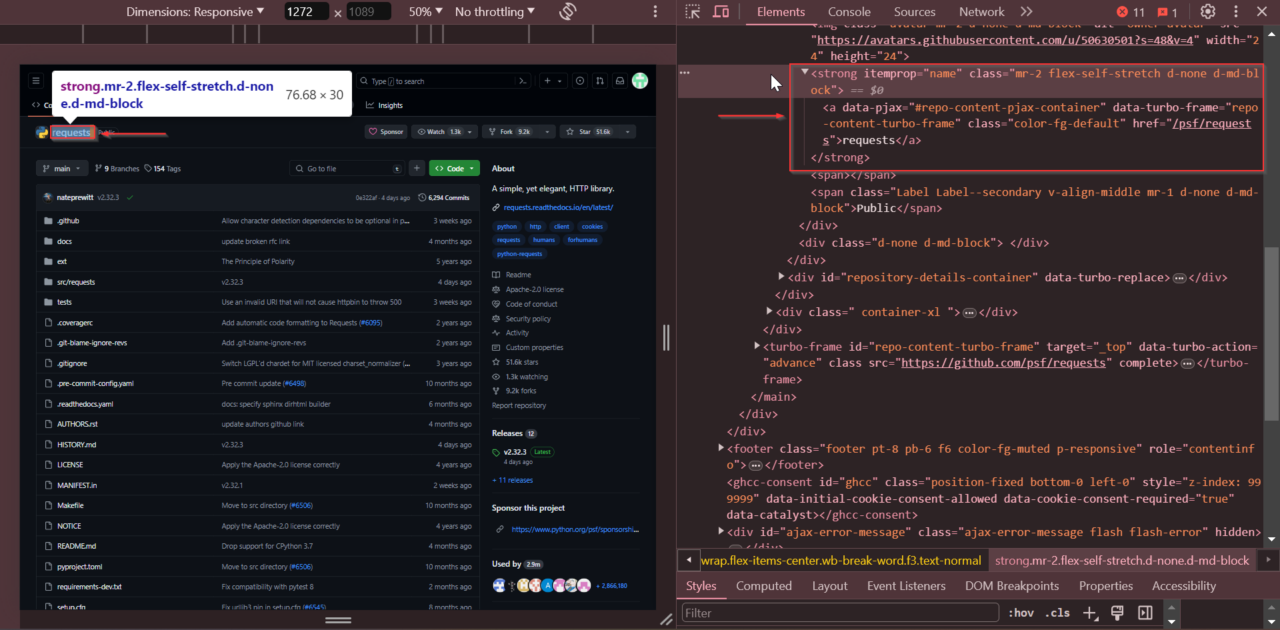
Das erste Element, das wir finden werden, ist der Name des Repositorys. Wenn Sie die Seite überprüfen, werden Sie sehen, dass der Repository-Name in einem
Tag mit dem Attribut
itemprop="name".
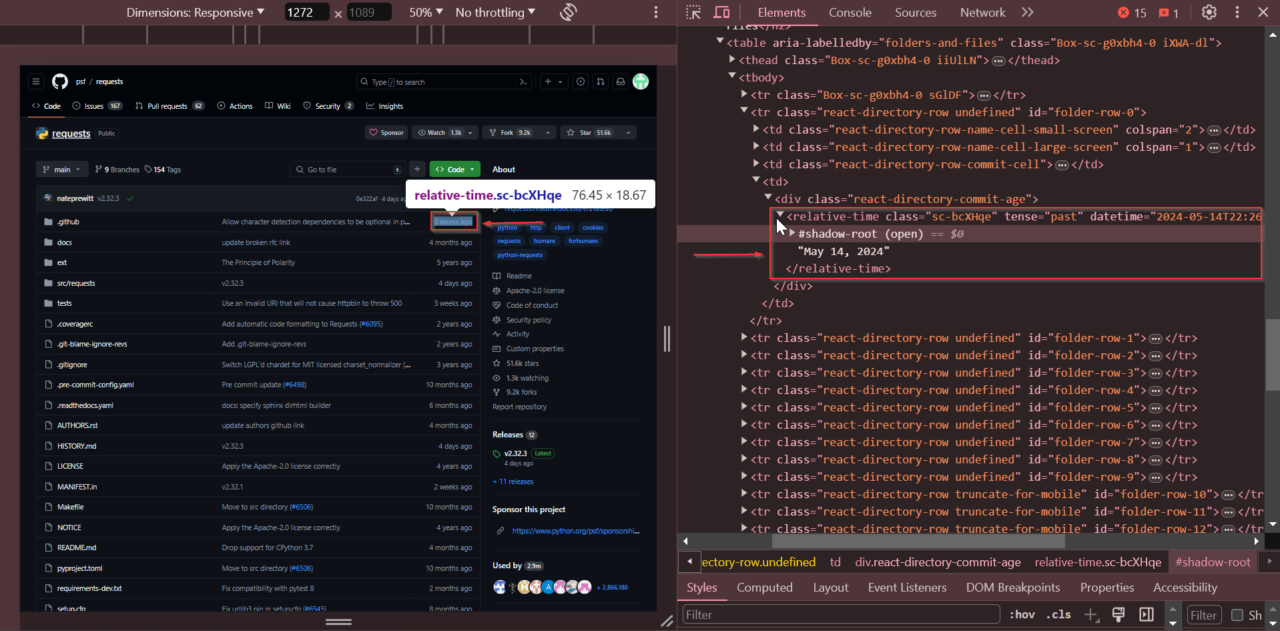
Als Nächstes suchen wir nach dem Zeitpunkt des letzten Commits des Repositorys. Scrollen Sie zum Abschnitt „Commit-Verlauf“, klicken Sie mit der rechten Maustaste auf das Datum des letzten Commits und wählen Sie „Untersuchen“.
Der späteste Commit-Zeitpunkt liegt innerhalb der ersten
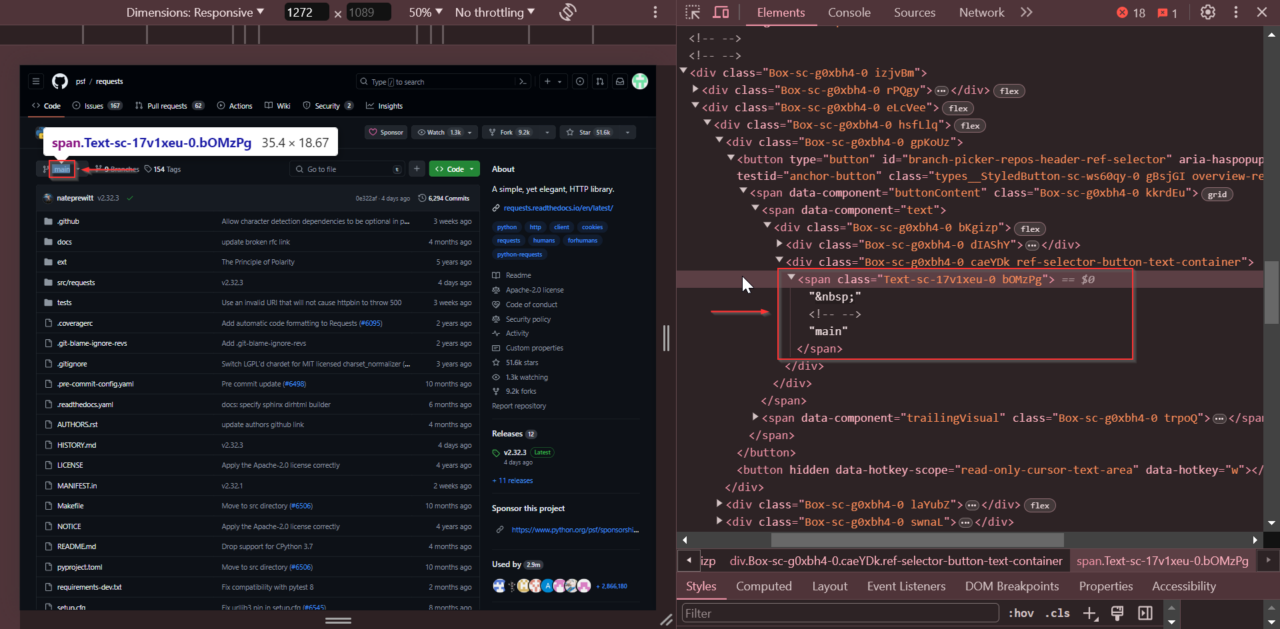
Danach suchen wir den aktuellen Zweignamen. Sehen Sie sich das Dropdown-Menü zur Zweigauswahl an, klicken Sie mit der rechten Maustaste auf den Zweignamen und wählen Sie „Untersuchen“.
Der Filialname wird gespeichert in Tag mit der Klasse Text-sc-17v1xeu-0 bOMzPg.
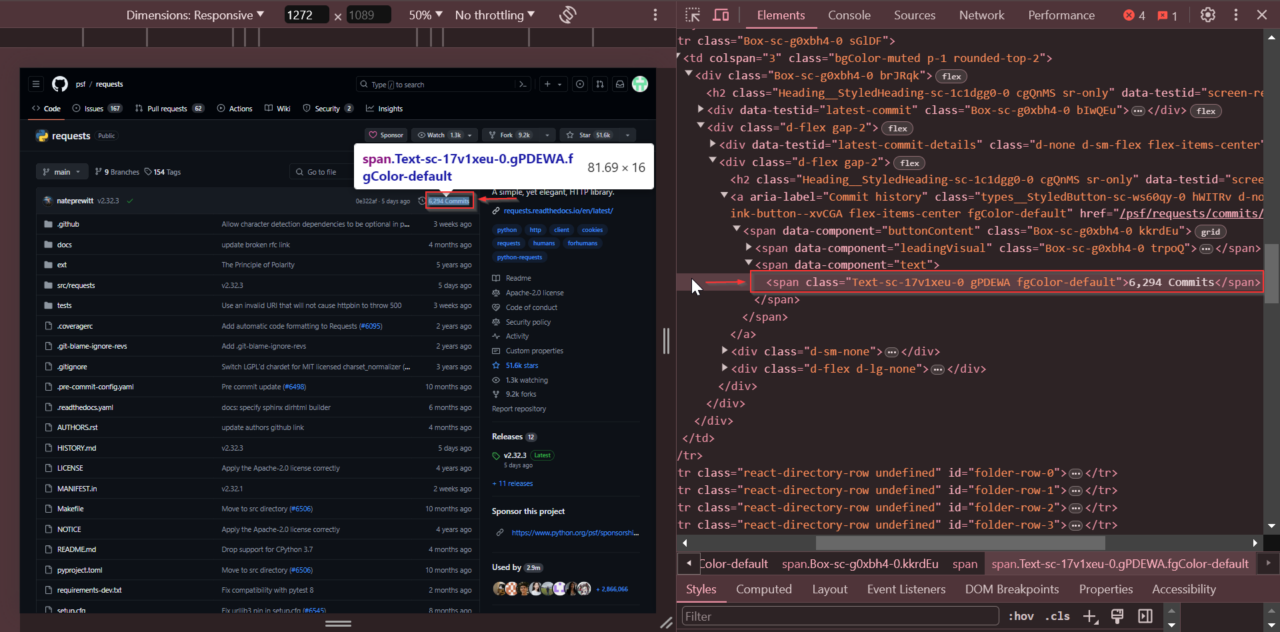
Als Nächstes ermitteln wir die Gesamtzahl der Commits. Suchen Sie den Abschnitt, der die Gesamtzahl der Commits anzeigt. Klicken Sie mit der rechten Maustaste auf die Commit-Anzahl und wählen Sie „Untersuchen“.
Die Anzahl der Commits wird in einem Tag mit der Klasse Text-sc-17v1xeu-0 gPDEWA fgColor-default.
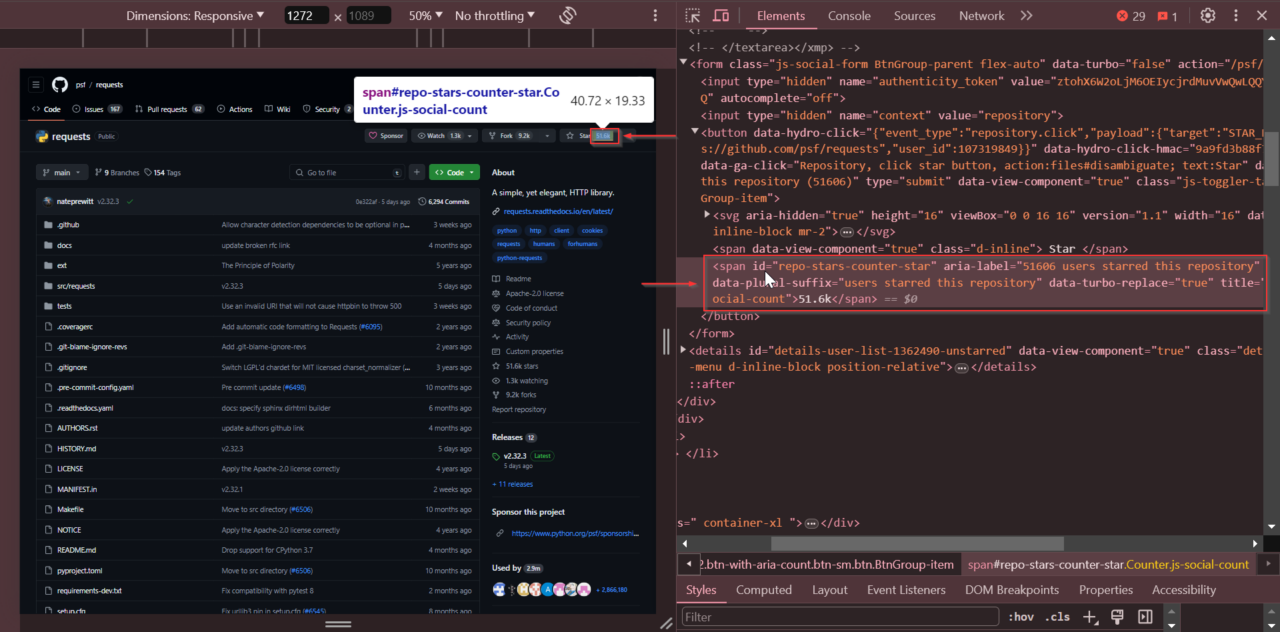
Als Nächstes suchen wir die Anzahl der Sterne. Suchen Sie die Anzahl der Sterne oben auf der Repository-Seite. Klicken Sie mit der rechten Maustaste auf die Anzahl der Sterne und wählen Sie „Untersuchen“.
Die Anzahl der Sterne liegt innerhalb einer Tag mit der ID
repo-stars-counter-star.
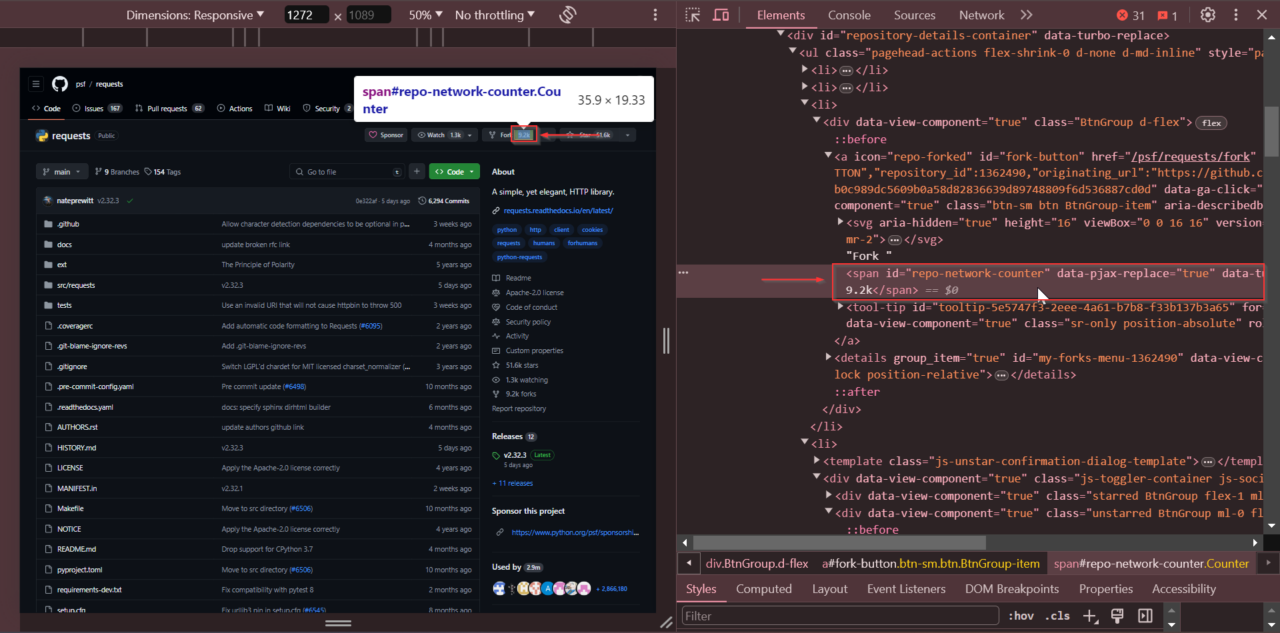
Klicken Sie außerdem mit der rechten Maustaste auf die Anzahl der Forks und wählen Sie „Untersuchen“, um die Anzahl der Forks zu erhalten. Die Anzahl der Forks wird in einem Tag mit der ID repo-network-counter.
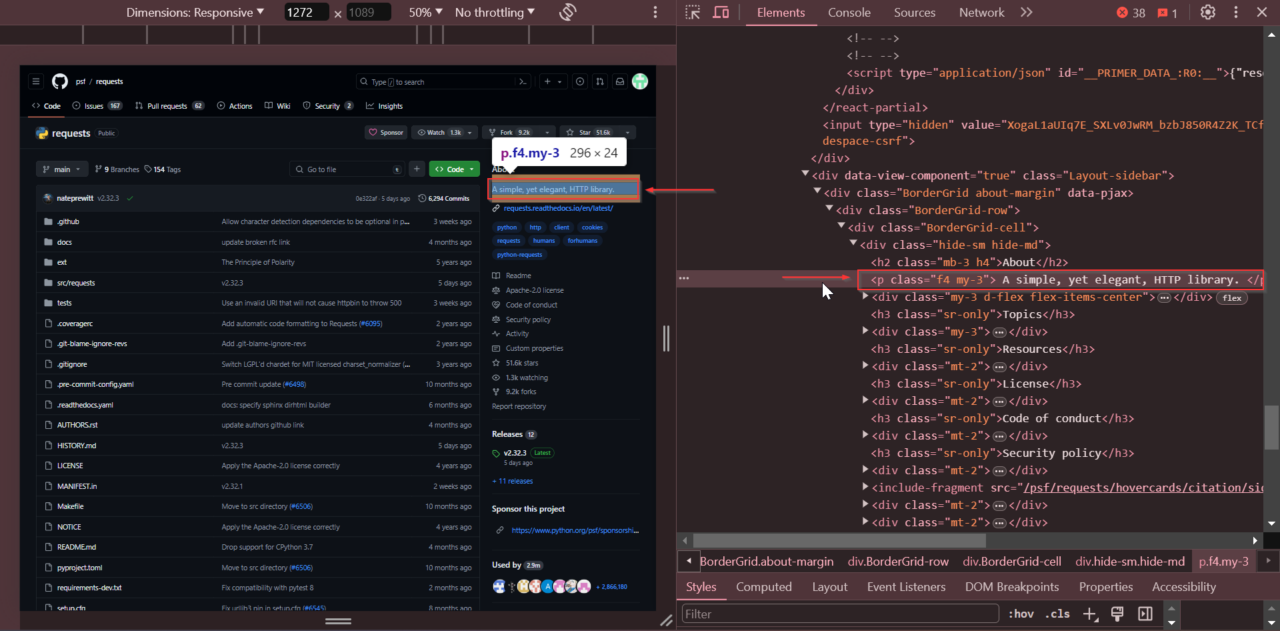
Als Nächstes suchen wir nach der Repository-Beschreibung. Suchen Sie oben auf der Seite im Abschnitt „Info“. Klicken Sie mit der rechten Maustaste darauf und wählen Sie „Untersuchen“.
Die Beschreibung wird gespeichert in einem Tag mit der Klasse
f4 my-3.
Mithilfe von DevTools zur Überprüfung dieser Elemente können wir die genauen Tags und Attribute ermitteln, die zum Extrahieren der gewünschten Daten erforderlich sind.
Da wir nun wissen, wo alles zu finden ist, können wir den Extraktionsprozess codieren.
Schritt 6: GitHub-Repository-Daten extrahieren
Nachdem wir uns nun mit der HTML-Struktur der GitHub-Repository-Seite vertraut gemacht haben, extrahieren wir die relevanten Daten.
Wir initialisieren ein Wörterbuch zum Speichern der Scraped-Daten und extrahieren dann Schritt für Schritt jede Information.
Zuerst erstellen wir ein leeres Wörterbuch namens repo um die extrahierten Daten zu speichern.
Um den Repository-Namen zu extrahieren, suchen wir das Tag mit dem Attribut itemprop="name". Wir verwenden soup.find(), um das Tag zu finden, und erhalten dann seinen Textinhalt mit get_text() und lagern Sie es im repo Wörterbuch unter dem Schlüssel name.
name_html_element = soup.find('strong', {"itemprop": "name"})
repo('name') = name_html_element.get_text().strip()
Als nächstes extrahieren wir die letzte Commit-Zeit, indem wir nach dem
soup.find() Um dieses Tag zu finden, extrahieren Sie seine datetime Attribut, um den genauen Zeitstempel zu erhalten, und speichern Sie ihn im Repo-Wörterbuch unter dem
latest_commit Schlüssel.
Der find() Methode findet den ersten
relative_time_html_element = soup.find('relative-time')
repo('latest_commit') = relative_time_html_element('datetime')
Als nächstes finden wir die Tag mit der ID
repo-stars-counter-star um die Anzahl der Sterne zu ermitteln. Ebenso finden wir die Tag mit der ID
repo-network-counter für die Gabelzählung.
Dann verwenden wir soup.find() um jedes Tag zu finden, dann holen Sie sich den Textinhalt mit get_text() und lagern Sie es im
repo Wörterbuch unter den Tasten stars Und
forksjeweils.
stars_element = soup.find('span', {"id": "repo-stars-counter-star"})
repo('stars') = stars_element.get_text().strip()
forks_element = soup.find('span', {"id": "repo-network-counter"})
repo('forks') = forks_element.get_text().strip()
Zum Schluss extrahieren wir die Repository-Beschreibung, indem wir den
Tag mit der Klasse f4 my-3. Wir gebrauchen
soup.find() um das Tag zu finden, dann seinen Textinhalt abrufen mit
get_text() und lagern Sie es im repo Wörterbuch.
description_html_element = soup.find('p', {"class": "f4 my-3"})
repo('description') = description_html_element.get_text().strip()
