
PHP ist eine weit verbreitete Programmiersprache, die für ihre Benutzerfreundlichkeit und serverseitigen Ausführungsfunktionen bekannt ist. Dies macht es zu einer idealen Wahl für die Entwicklung von Web-Scrapern, da Sie die Ausführung des Scrapers von Ihrem lokalen Computer auf die Ressourcen des Servers verlagern können. Darüber hinaus können Sie durch die Integration von PHP mit Planungstools wie Crontab automatisierte Scraping-Aufgaben einrichten, die in regelmäßigen Abständen ausgeführt werden.
Dieser Artikel befasst sich mit dem umfassenden Prozess der Erstellung eines PHP-Web-Scrapers und umfasst alles vom Einrichten der Entwicklungsumgebung und Installieren der erforderlichen Komponenten bis hin zum Erstellen von Webanforderungen, Analysieren von Daten und Speichern der extrahierten Informationen in einer Datei. Wir untersuchen auch sowohl grundlegende Scraping-Techniken als auch fortgeschrittene Strategien, um die Effizienz und Nützlichkeit Ihres Scrapers zu verbessern.
Warum PHP für Web Scraping verwenden?
PHP ist eine leistungsstarke objektorientierte Programmiersprache, die speziell für die Webentwicklung entwickelt wurde. Dank der benutzerfreundlichen Syntax ist sie selbst für Anfänger leicht zu erlernen und zu verstehen. PHP ist nicht nur benutzerfreundlich, sondern bietet auch eine außergewöhnliche Leistung, sodass PHP-Skripte schnell und effizient ausgeführt werden können.
Insgesamt bietet PHP die perfekte Kombination aus Einfachheit, Geschwindigkeit und Vielseitigkeit. PHP verfügt über eine große und aktive Community sowie eine umfangreiche Sammlung von Open-Source-Bibliotheken für Web Scraping, wie Simple HTML DOM Parser, Goutte und Symfony Panther.
Ein wichtiger Aspekt ist die serverseitige Ausführung (PHP-Skripte können direkt auf Servern ausgeführt werden, wodurch lokale Installationen oder Browserautomatisierung überflüssig werden), was es ideal für Web-Scraping-Aufgaben macht, die effizient ausgeführt werden müssen, ohne von Ihrem lokalen Computer abhängig zu sein.
Einrichten der Umgebung
Um einen PHP-Scraper zu erstellen, müssen wir PHP einrichten und die Bibliotheken herunterladen, die wir später in unsere Projekte einbinden werden. Es gibt jedoch zwei Möglichkeiten, wie wir dies tun können. Sie können alle Bibliotheken manuell herunterladen und die Initialisierungsdatei konfigurieren oder dies mit Composer automatisieren.
Da unser Ziel darin besteht, die Skripterstellung so einfach wie möglich zu gestalten und Ihnen zu zeigen, wie das geht, installieren wir Composer und erklären, wie Sie ihn verwenden.
PHP unter Linux und MacOS installieren
Der Prozess zur Installation von PHP unter Linux und macOS ist recht ähnlich. Öffnen Sie zunächst ein Terminalfenster und stellen Sie mit dem folgenden Befehl sicher, dass die Paketinformationen Ihres Systems auf dem neuesten Stand sind:
sudo apt updateSobald die Paketinformationen aktualisiert sind, fahren Sie mit der Installation von PHP mit dem folgenden Befehl fort:
sudo apt install php-cliDieser Befehl installiert die neueste Version von PHP zusammen mit den erforderlichen Abhängigkeiten.
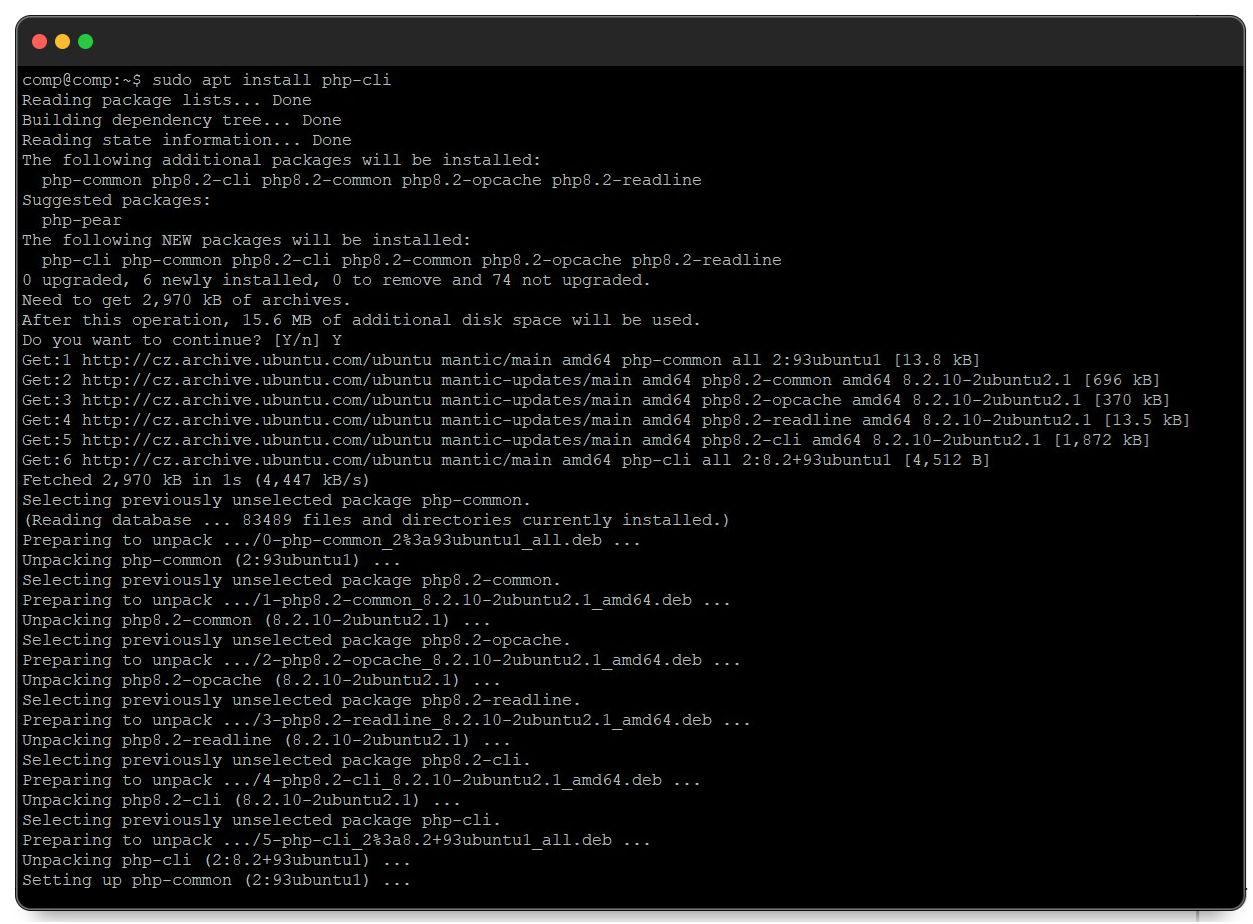
Danach können Sie das installierte PHP zum Ausführen von Skripten verwenden.
PHP unter Windows installieren
Laden Sie zunächst PHP von der offiziellen Website herunter. Wenn Sie Windows haben, laden Sie die neueste stabile Version als Zip-Archiv herunter. Entpacken Sie es dann an einem leicht zu merkenden Ort, beispielsweise im Ordner „PHP“ auf Ihrem Laufwerk C.
Wenn Sie Windows verwenden, müssen Sie den Pfad zu den PHP-Dateien in Ihrem System festlegen. Öffnen Sie dazu einen beliebigen Ordner auf Ihrem Computer und gehen Sie zu den Systemeinstellungen (klicken Sie mit der rechten Maustaste auf diesen PC und gehen Sie zu Eigenschaften).
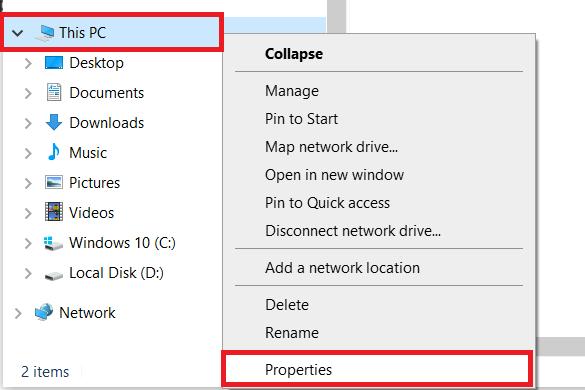
Suchen Sie auf der Seite nach der Option „Erweiterte Systemeinstellungen“ und klicken Sie darauf.
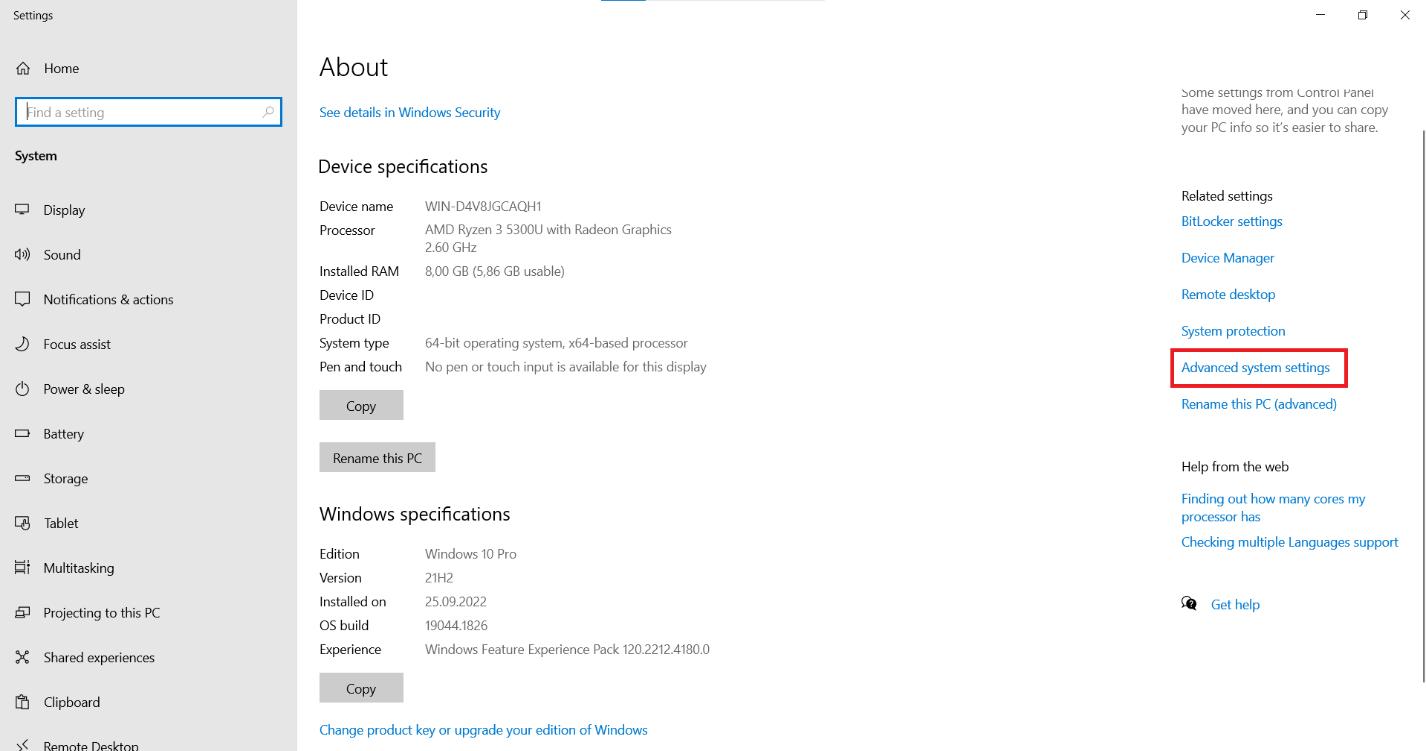
Suchen Sie auf der Registerkarte „Erweitert“ nach der Schaltfläche „Umgebungsvariablen“ und klicken Sie darauf.
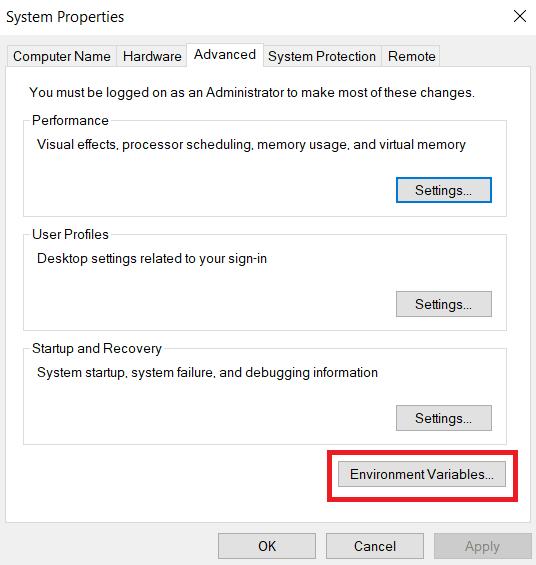
Suchen Sie im Abschnitt „Benutzervariablen für Benutzer“ die Variable „Pfad“ und klicken Sie auf die Schaltfläche „Bearbeiten“.
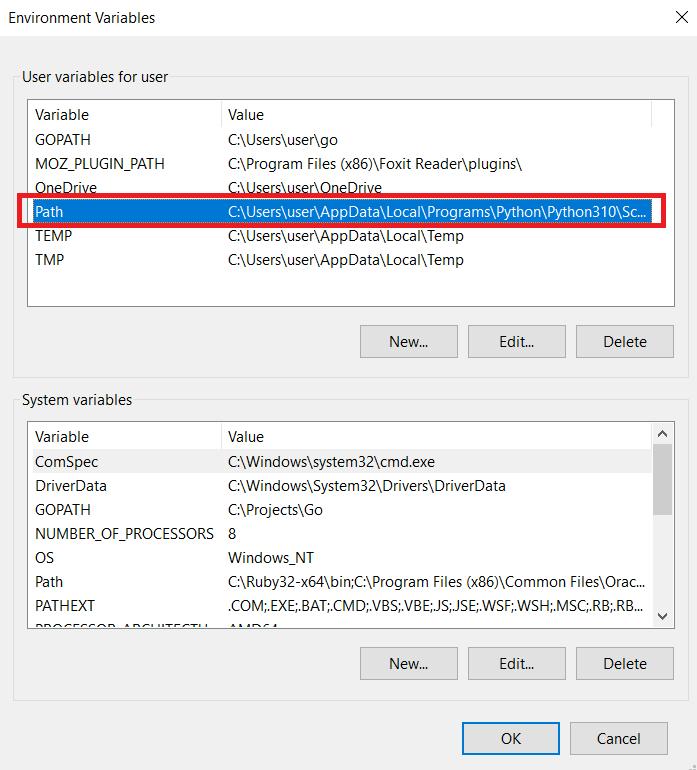
Es öffnet sich ein neues Fenster, in dem Sie den Wert der Variable „Path“ bearbeiten können. Fügen Sie am Ende des bestehenden Wertes den Pfad zu den PHP-Dateien hinzu. Klicken Sie auf die Schaltfläche „OK“, um die Änderungen zu speichern. Wenn Sie noch Fragen haben, können Sie die Dokumentation lesen.
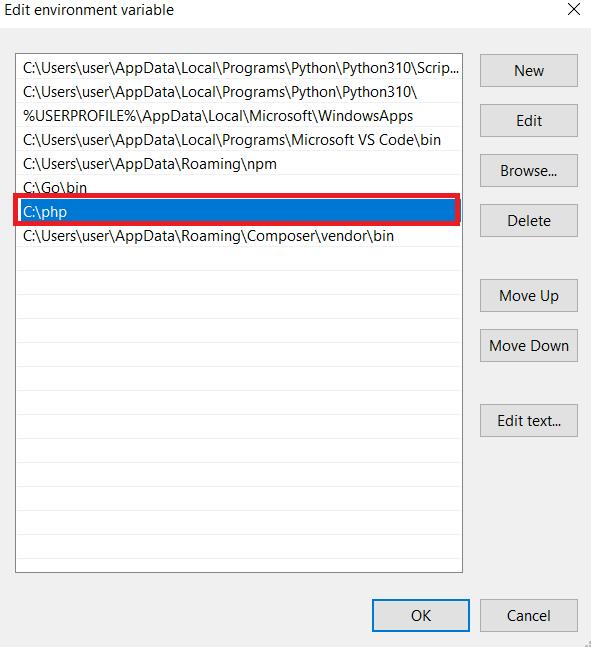
Installieren wir nun Composer, einen Abhängigkeitsmanager für PHP, der die Verwaltung und Installation von Drittanbieterbibliotheken in Ihrem Projekt vereinfacht. Sie können alle Pakete von github.com herunterladen, aber unserer Erfahrung nach ist Composer praktischer.
Um zu beginnen, gehen Sie auf die offizielle Website und laden Sie Composer herunter. Folgen Sie dann den Anweisungen in der Installationsdatei. Sie müssen auch den Pfad angeben, in dem sich PHP befindet. Stellen Sie daher sicher, dass dieser richtig eingestellt ist.
Erstellen Sie im Stammverzeichnis Ihres Projekts eine neue Datei mit dem Namen composer.json. Diese Datei enthält Informationen zu den Abhängigkeiten Ihres Projekts. Wir haben eine einzelne Datei vorbereitet, die alle im heutigen Tutorial verwendeten Bibliotheken enthält, damit Sie unsere Einstellungen sehen können.
{
"require": {
"guzzlehttp/guzzle": "^7.7",
"sunra/php-simple-html-dom-parser": "^1.5"
},
"config": {
"platform": {
"php": "8.2.7"
},
"preferred-install": {
"*": "dist"
},
"minimum-stability": "stable",
"prefer-stable": true,
"sort-packages": true
}
}Navigieren Sie zunächst in der Befehlszeile zu dem Verzeichnis, das die Datei composer.json enthält, und führen Sie den folgenden Befehl aus:
composer install Der Composer lädt die angegebenen Abhängigkeiten herunter und installiert sie im Vendor-Verzeichnis Ihres Projekts.
Sie können diese Bibliotheken jetzt mit einem Befehl in der Datei mit Ihrem Code in Ihr Projekt importieren.
require 'vendor/autoload.php';Jetzt können Sie Klassen aus den installierten Bibliotheken verwenden, indem Sie sie einfach in Ihrem Code aufrufen
Grundlegendes Web Scraping mit PHP
Das Parsen einfacher Websites umfasst normalerweise die Verwendung einer grundlegenden Anforderungs- und Parsebibliothek. Für Anforderungen verwenden wir die Bibliothek cURL (Client URL Library) und für das Parsen abgerufener HTML-Seiten die Bibliothek Simple HTML DOM Parser. Dieser Ansatz führt grundlegende Beispiele ein und hilft beim Verständnis einfacher Page Scraping-Techniken.
Leider ermöglichen nicht alle Websites ein derart müheloses Datenscraping. Daher müssen Sie in Zukunft möglicherweise auf fortgeschrittenere Bibliotheken zurückgreifen. Um Ihnen die Auswahl der für Ihre Anforderungen am besten geeigneten Bibliothek zu erleichtern, haben wir einen separaten Artikel zusammengestellt, in dem alle gängigen PHP-Scraping-Bibliotheken beschrieben werden.
Seitenanalyse
Nachdem wir nun die Umgebung vorbereitet und alle Komponenten eingerichtet haben, analysieren wir die Webseite, die wir scrapen werden. Wir werden diese Demo-Website als Beispiel verwenden. Gehen Sie zur Website und öffnen Sie die Entwicklerkonsole (F12 oder Rechtsklick und gehen Sie zu „Untersuchen“).
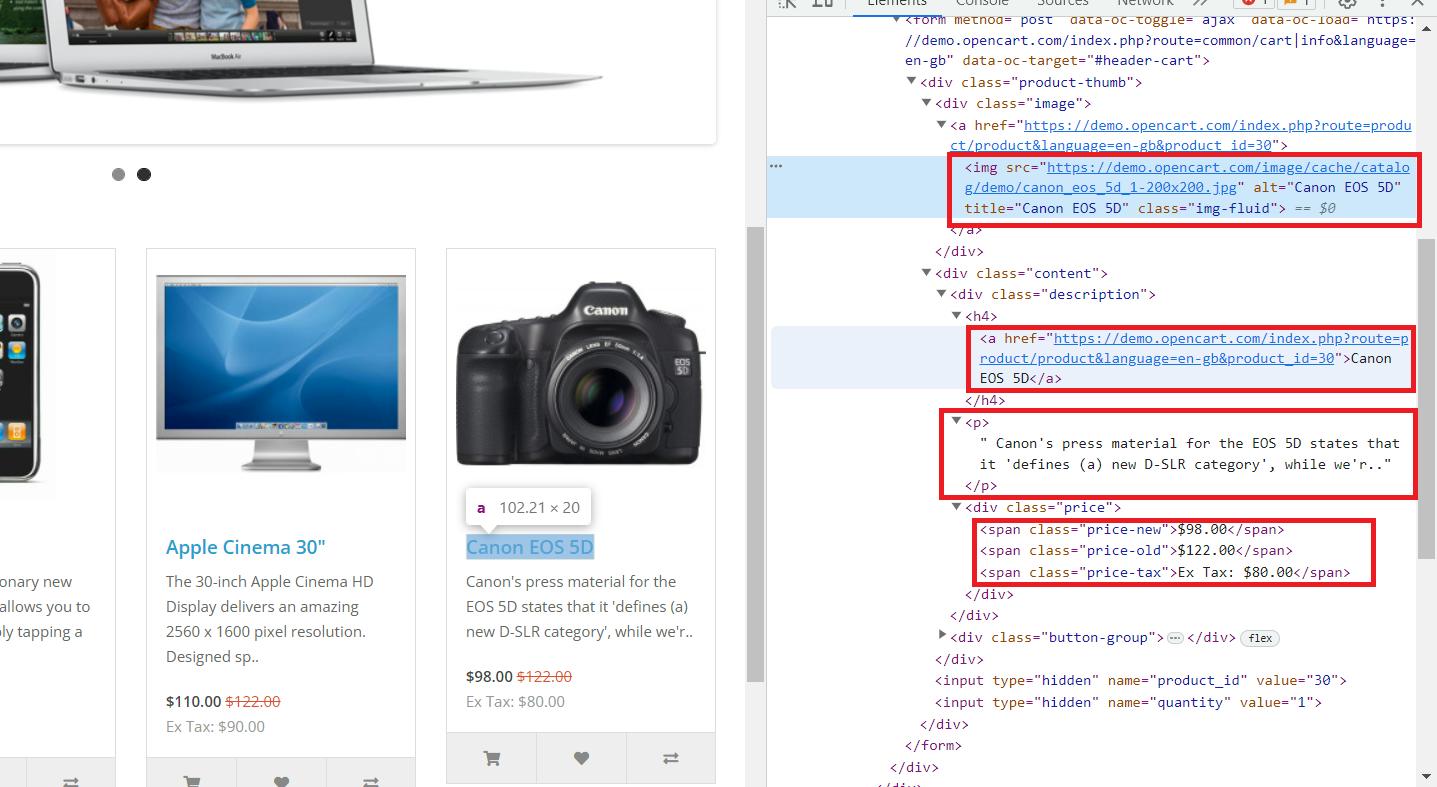
Hier sehen wir, dass alle notwendigen Daten im übergeordneten Tag „div“ mit dem Klassennamen „col“ gespeichert sind, der alle Produkte auf der Seite enthält. Er enthält die folgenden Informationen:
- Der „img“-Tag enthält den Link zum Produktbild im „src“-Attribut.
- Der „a“-Tag enthält den Produktlink im „href“-Attribut.
- Das „h4“-Tag enthält den Produkttitel.
- Das „p“-Tag enthält die Produktbeschreibung.
- Preise werden im Tag „span“ mit verschiedenen Klassen gespeichert:
- „Preis-alt“ zum Originalpreis.
- „Neupreis“ zum Aktionspreis.
- „Preis-Steuer“ für die Steuer.
Nachdem wir nun wissen, wo die benötigten Informationen gespeichert sind, können wir mit dem Scraping beginnen.
Verwenden von cURL zum Abrufen von Webseiten
Die cURL-Bibliothek bietet eine breite Palette an Funktionen zum Verwalten von Anfragen. Sie eignet sich hervorragend zum Abrufen des Codes von Seiten, von denen Daten erfasst werden müssen. Darüber hinaus können Sie damit Daten verwalten, z. B. durch die Verwendung der SSL-Zertifikatsüberprüfung bei einer Anfrage oder das Hinzufügen zusätzlicher Optionen wie Benutzeragenten.
Um die Fähigkeiten dieser Bibliothek besser zu verstehen, holen wir uns den HTML-Code der zuvor besprochenen Website. Erstellen Sie dazu eine neue Datei mit dem *.php Erweiterung und Initialisierung von cURL:
Geben Sie anschließend die Website-Adresse und den Datentyp als Parameter an, beispielsweise in Form einer Zeichenfolge:
curl_setopt($ch, CURLOPT_URL, "https://demo.opencart.com");
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);Sie können in diesem Schritt auch verschiedene weitere Parameter als Optionen angeben, beispielsweise:
1. Benutzeragenten. Sie können einen der aktuellsten User Agents von unserer Seite nehmen und ihn in Ihrem Skript angeben.
curl_setopt($ch, CURLOPT_USERAGENT, "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36");2. SSL-Zertifikate verwalten und deaktivieren Sie deren Überprüfung:
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);Oder geben Sie den Pfad zum CA-Bundle an:
curl_setopt($ch, CURLOPT_CAINFO, "/cacert.pem");3. Konfigurieren von Timeouts.
curl_setopt($ch, CURLOPT_TIMEOUT, 30); // Maximum time in seconds to allow cURL functions to execute
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10); // Maximum time in seconds to wait while trying to connect4. Cookies anpassen. Sie können sie in einer Datei speichern:
curl_setopt($ch, CURLOPT_COOKIEJAR, "cookies.txt");Sie können sie auch aus einer Datei verwenden:
curl_setopt($ch, CURLOPT_COOKIEFILE, "cookies.txt");Nachdem Sie Ihre Anfrage konfiguriert haben, müssen Sie sie ausführen:
$response = curl_exec($ch);Als nächstes zeigen wir das Abfrageergebnis oder ggf. eine Fehlermeldung auf dem Bildschirm an:
if ($response === false) {
echo 'cURL error: ' . curl_error($ch);
} else {
echo $response;
}Denken Sie unbedingt daran, die Verbindung am Ende zu schließen:
curl_close($ch);Behalten wir nur die notwendigen Parameter bei und geben ein Beispiel des endgültigen Skripts an:
Dadurch wird der gesamte HTML-Code der angeforderten Seite abgerufen. Wir müssen den abgerufenen Code analysieren, um bestimmte Daten zu extrahieren, und dafür benötigen wir eine weitere Bibliothek.
HTML mit Simple HTML DOM Parser analysieren
Lassen Sie uns das zuvor besprochene Skript verfeinern, um nur die relevanten Daten von der Seite zu extrahieren. Dazu binden wir vor dem Initialisieren der cURL-Sitzung eine zusätzliche Bibliothek ein:
require 'simple_html_dom.php';Wenn Sie Composer zur Abhängigkeitsverwaltung verwenden, müssen Sie den Simple HTML DOM Parser zu Ihrer Datei composer.json hinzufügen:
"require": {
"sunra/php-simple-html-dom-parser": "^1.5.2"
}Aktualisieren Sie dann Ihre Abhängigkeiten mit dem folgenden Befehl:
composer updateSobald dies erledigt ist, können Sie die Bibliothek in Ihr Skript importieren:
require 'vendor/autoload.php';
use Sunra\PhpSimple\HtmlDomParser;Die Schritte zur Anforderungsinitialisierung und -konfiguration bleiben gleich. Wir ändern nur den Teil zur Antwortverarbeitung:
if ($response === false) {
echo 'cURL error: ' . curl_error($ch);
} else {
// Here will be parsing process
}Analysieren Sie die gesamte Seite als HTML-Code:
$html = HtmlDomParser::str_get_html($response);Als nächstes extrahieren und zeigen Sie alle Produktdaten an:
$products = $html->find('.col');
foreach ($elements as $element) {
$image = $element->find('img', 0)->src;
$title = $element->find('h4', 0)->plaintext;
$link = $element->find('h4 > a', 0)->href;
$desc = $element->find('p', 0)->plaintext;
$old_p_element = $element->find('span.price-old', 0);
$old_p = $old_p_element ? $old_p_element->plaintext : '-';
$new_p = $element->find('span.price-new', 0)->plaintext;
$tax = $element->find('span.price-tax', 0)->plaintext;
echo 'Image: ' . $image . "\n";
echo 'Title: ' . $title . "\n";
echo 'Link: ' . $link . "\n";
echo 'Description: ' . $desc . "\n";
echo 'Old Price: ' . $old_p . "\n";
echo 'New Price: ' . $new_p . "\n";
echo 'Tax: ' . $tax . "\n";
echo "\n";
}Am Ende werden wir Ressourcen freigeben:
$html->clear();Dadurch erhalten wir Informationen zu allen Produkten auf der Seite und können diese in einem benutzerfreundlichen Format anzeigen. Als Nächstes erklären wir, wie Sie diese Daten in einer Datei speichern, um einfacher darauf zugreifen und sie bearbeiten zu können.
Datenspeicherung und -bearbeitung
Die Datenspeicherung ist ein entscheidender Aspekt des Datenerfassungsprozesses. Scraped-Daten werden je nach Verwendungszweck üblicherweise in den Formaten JSON, Datenbanken oder CSV gespeichert. JSON eignet sich zur Weiterverarbeitung oder Übertragung, Datenbanken ermöglichen eine organisierte Speicherung und Abfrage und CSV bietet Einfachheit und Kompatibilität.
Bereinigen und Verarbeiten von Daten
Die Datenbereinigung ist ein wesentlicher Schritt bei der Datenvorverarbeitung. Sie stellt die Genauigkeit und Konsistenz der Daten sicher, bevor sie gespeichert oder analysiert werden. Dabei werden Fehler, Inkonsistenzen und unerwünschte Muster in den Daten identifiziert und korrigiert. Dies kann dazu beitragen, Berechnungsfehler, Datenanalysen und maschinelle Lernmodelle zu vermeiden.
Zunächst ist es wichtig, den Text von allen unnötigen HTML-Tags zu befreien, die möglicherweise von der Formatierung übrig geblieben sind. Dies kann mithilfe des strip_tags() Funktion:
$cleanText = strip_tags($dirtyText);Darüber hinaus können Sie alle Leerzeichen am Anfang und Ende des Textes oder Strings entfernen:
$cleanText = trim($dirtyText);Um ungewollte Zeichen, wie beispielsweise Sonderzeichen, zu eliminieren oder zu ersetzen, ist die Zeichenersetzungsfunktion hilfreich:
$cleanText = preg_replace('/(^A-Za-z0-9\-)/', '', $dirtyText);Manchmal können Fehler auftreten, wenn die Variable keine Daten enthält. In solchen Fällen können Sie den leeren Wert durch einen Standardwert ersetzen:
$cleanText = empty($dirtyText) ? 'default' : $dirtyText;Durch den Einsatz dieser Techniken können Sie Ihren Rohdatensatz effektiv für die spätere Speicherung vorbereiten. Dies ist von größter Bedeutung, da ein versehentlich gelassenes Leerzeichen am Ende einer Zeile zu Berechnungsfehlern oder Datenbeschädigungen führen kann.
Speichern von Scraped-Daten
Anstatt die abgerufenen Daten auf dem Bildschirm auszugeben, können wir sie in einer CSV-Datei speichern, indem wir ein Datenarray erstellen und es schreiben. Lassen Sie uns den Abschnitt zum Datenabruf ändern, um die Daten in einer Variablen zu speichern, anstatt sie anzuzeigen:
$products = $html->find('.col');
$data = ();
foreach ($products as $element) {
$image = $element->find('img', 0)->src;
$title = $element->find('h4', 0)->plaintext;
$link = $element->find('h4 > a', 0)->href;
$desc = $element->find('p', 0)->plaintext;
$old_p_element = $element->find('span.price-old', 0);
$old_p = $old_p_element ? $old_p_element->plaintext : '-';
$new_p = $element->find('span.price-new', 0)->plaintext;
$tax = $element->find('span.price-tax', 0)->plaintext;
$data() = (
'image' => $image,
'title' => $title,
'link' => $link,
'description' => $desc,
'old_price' => $old_p,
'new_price' => $new_p,
'tax' => $tax
);
}Erstellen Sie eine CSV-Datei und schreiben Sie die Daten:
$csvFile = fopen('products.csv', 'w');
fputcsv($csvFile, ('Image', 'Title', 'Link', 'Description', 'Old Price', 'New Price', 'Tax'));
foreach ($data as $row) {
fputcsv($csvFile, $row);
}
fclose($csvFile);Um die Daten im JSON-Format zu speichern, können wir dasselbe Datenarray verwenden, das zuvor erstellt wurde:
file_put_contents('products.json', json_encode($data, JSON_PRETTY_PRINT));Um Daten in einer Datenbank zu speichern, müssen Sie eine Verbindung herstellen und die Daten zeilenweise einfügen. Die genaue Schreib- und Verbindungsmethode hängt vom gewählten Datenbankverwaltungssystem (DBMS) ab.
Fortgeschrittene Techniken
Um Daten effizienter zu scrapen, müssen Sie fortgeschrittenere Methoden und Bibliotheken einsetzen, die das Sammeln von Daten aus einer größeren Bandbreite von Quellen ermöglichen. Dieser Abschnitt befasst sich mit zusätzlichen Techniken und bietet Beispiele für das Scrapen von Daten von dynamischen Webseiten, die Verwendung von Proxys und die Verbesserung der Scraping-Geschwindigkeit.
Umgang mit dynamischem Inhalt
Das Scraping dynamischer, mit JavaScript generierter Inhalte kann mit herkömmlichen Web Scraping-Techniken eine Herausforderung sein. Hier sind zwei gängige Ansätze:
- Headless-Browser. Nutzen Sie Bibliotheken, die die Interaktion mit Headless-Browsern ermöglichen. So können Sie den Scraping-Prozess steuern und das Benutzerverhalten simulieren, wodurch das Risiko einer Blockierung verringert wird. PHP erfordert jedoch fortgeschrittene Kenntnisse und ist nicht die am besten geeignete Sprache für Headless-Browser.
- Web Scraping-APIs. Verwenden Sie spezielle APIs, die für das Scraping dynamischer Inhalte entwickelt wurden. Diese APIs bieten häufig Proxy-Unterstützung und ermöglichen so den Zugriff auf regionsspezifische Daten. Darüber hinaus erfolgt die Datenerfassung auf der Seite des API-Anbieters, wodurch Ihre Sicherheit und Anonymität gewährleistet wird.
Erstellen wir beispielsweise ein Skript, um dieselben Daten zu sammeln, allerdings nur mit der Web Scraping API von HasData. Melden Sie sich dazu auf unserer Website an und kopieren Sie Ihren API-Schlüssel aus Ihrem Konto.
Erstellen Sie ein neues PHP-Skript und initialisieren Sie eine neue Sitzung:
$curl = curl_init();Legen Sie Anforderungsparameter fest, einschließlich CSS-Selektoren und Ihres API-Schlüssels:
curl_setopt_array($curl, (
CURLOPT_URL => "https://api.hasdata.com/scrape/web",
CURLOPT_RETURNTRANSFER => true,
CURLOPT_CUSTOMREQUEST => "POST",
CURLOPT_POSTFIELDS => json_encode((
'url' => 'https://demo.opencart.com/',
'proxyCountry' => 'US',
'proxyType' => 'datacenter',
'extractRules' => (
'Image' => 'img @src',
'Title' => 'h4',
'Link' => 'h4 > a @href',
'Description' => 'p',
'Old Price' => 'span.price-old',
'New Price' => 'span.price-new',
'Tax' => 'span.price-tax'
)
)),
CURLOPT_HTTPHEADER => (
"Content-Type: application/json",
"x-api-key: PUT-YOUR-API-KEY"
),
));Stellen Sie die Anfrage und zeigen Sie das Ergebnis an:
$response = curl_exec($curl);
$err = curl_error($curl);
curl_close($curl);
if ($err) {
echo "cURL Error #:" . $err;
} else {
echo $response;
}Dieses Beispiel zeigt die Verwendung einer Scraping-API zum Sammeln von Daten von einer beliebigen Website. Wenn die Website, an der Sie interessiert sind, jedoch über eine eigene dedizierte Scraping-API verfügt, wird im Allgemeinen empfohlen, stattdessen diese zu verwenden. Dadurch erhalten Sie in der Regel auf einfachste Weise die umfassendsten Daten.
Paralleles Scraping
Sie benötigen eine weitere Bibliothek, die die erforderliche Funktionalität für die Arbeit mit Streams bietet. Wir verwenden beispielsweise die Guzzle-Bibliothek, die sich gut zum Erstellen von Anfragen und zum Parsen von Daten eignet. Fügen Sie zunächst den Import zu Composer hinzu oder importieren Sie die Bibliothek direkt:
"require": {
"guzzlehttp/guzzle": "^7.7"
}Aktualisieren Sie Composer und geben Sie den Import im Skript an:
require 'vendor/autoload.php';
use GuzzleHttp\Client;
use GuzzleHttp\Pool;
use GuzzleHttp\Psr7\Request;
use GuzzleHttp\Exception\RequestException;Platzieren Sie die URLs der Seiten, die Sie scrapen möchten, in einer Variable:
$urls = (
"https://demo.opencart.com",
"https://example.com"
);Erstellen Sie einen HTTP-Client zur Verarbeitung der Anforderungen:
$client = new Client();
$requests = function ($urls) {
foreach ($urls as $url) {
yield new Request('GET', $url);
}
};Erstellen Sie einen Multiprocessing-Pool mit 2 Threads:
$pool = new Pool($client, $requests($urls), (
'concurrency' => 2,
'fulfilled' => function ($response, $index) {
echo "Response received from request #$index: " . $response->getBody() . "\n";
},
'rejected' => function (RequestException $reason, $index) {
echo "Request #$index failed: " . $reason->getMessage() . "\n";
},
));Überweisungen initiieren und Versprechen erstellen:
$promise = $pool->promise();Warten Sie dann, bis der Anforderungspool abgeschlossen ist:
$promise->wait();Insgesamt verbessert dieser Multiprocessing-Ansatz die Geschwindigkeit und Effizienz von Data-Scraping-Aufgaben erheblich.
Rotierende Proxys
Um Ihre IP-Adresse beim Scraping zu maskieren und verschiedene Einschränkungen zu umgehen, können Sie Proxys verwenden. Wir haben bereits besprochen, was Proxys sind, warum Sie sie verwenden sollten und wo Sie sowohl kostenpflichtige als auch kostenlose Proxys finden. Kommen wir also in diesem Tutorial zu den praktischen Anwendungen.
Wir nehmen das zuvor besprochene Skript als Grundlage und fügen die Verwendung zufälliger Proxys aus der Liste hinzu. Dazu erstellen wir eine Variable und fügen ihr Proxys hinzu:
$proxies = (
'http://38.10.90.246:8080',
'http://103.196.28.6:8080',
'http://79.174.188.153:8080',
);Anschließend ändern wir die Anforderungsausführung leicht, um die Proxys zu berücksichtigen:
$requests = function ($urls, $proxies) {
foreach ($urls as $url) {
$proxy = $proxies(array_rand($proxies));
yield new Request('GET', $url, ('proxy' => $proxy));
}
};
$pool = new Pool($client, $requests($urls, $proxies), (
'concurrency' => 2,
'fulfilled' => function ($response, $index) {
echo "Response received from request #$index: " . $response->getBody() . "\n";
},
'rejected' => function (RequestException $reason, $index) {
echo "Request #$index failed: " . $reason->getMessage() . "\n";
},
));Der restliche Code bleibt gleich, aber jetzt wird für jede Anfrage eine zufällige Zeile mit einem Proxy aus der in der Variablen gespeicherten Liste ausgewählt. Mit diesem Ansatz können Sie die Blockierung jedes einzelnen Proxys länger vermeiden und die allgemeine Zuverlässigkeit des Skripts erhöhen.
Scraping-Aufgabe zu Cron hinzufügen
PHP ist eine Skriptsprache und nicht für den Dauerbetrieb geeignet. Sie eignet sich besser für die periodische Ausführung, bei der Aufgaben ausgeführt und das Skript dann geschlossen wird. Wenn Sie also ständig Daten erfassen müssen, ist es bequemer, die automatische Ausführung zu einem bestimmten Zeitpunkt oder nach einem bestimmten Intervall einzurichten.
Um diese Aufgabe in Linux-Systemen zu lösen, können Sie Crontab verwenden, mit dem Sie Aufgabenpläne erstellen können. Um die Skriptausführung zum Zeitplan hinzuzufügen, starten Sie das Terminal und führen Sie den folgenden Befehl aus:
crontab -eDadurch werden Cron-Aufgaben zum Bearbeiten gestartet. Am Ende der Datei müssen Sie Daten im Format „Wann ausführen – Tool zum Ausführen – Was ausführen“ schreiben. Um beispielsweise das Skript auszuführen /home/comp/php_scripts/scraper.php mit /usr/bin/php jede Minute müssen Sie am Ende der Datei Folgendes hinzufügen:
* * * * * /usr/bin/php /home/comp/php_scripts/scraper.phpEs sollte so aussehen:
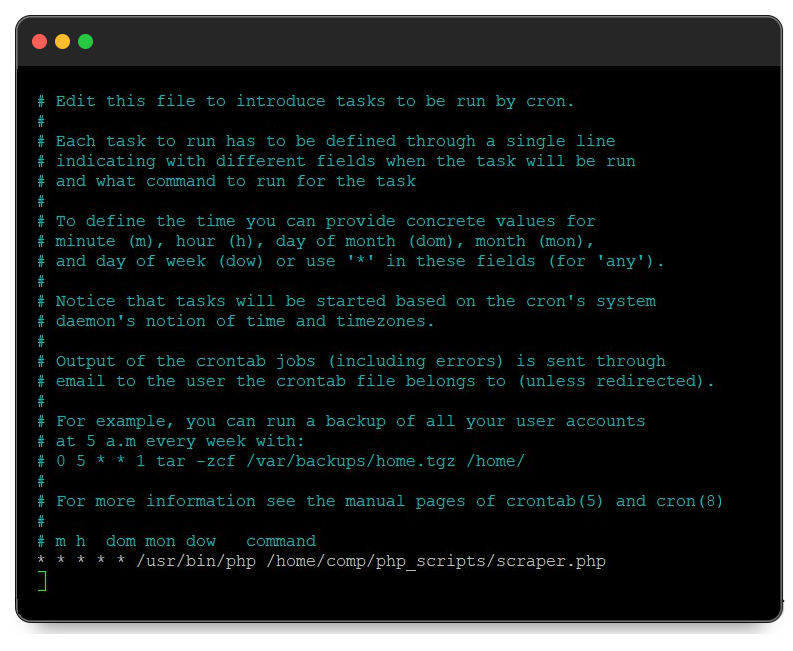
Sobald Sie Ihre Änderungen vorgenommen haben, speichern Sie die Datei mit der Tastenkombination Strg+O. Das Skript wird dann mit der gewünschten Häufigkeit ausgeführt.
Abschluss
PHP bietet eine robuste und flexible Plattform für Web Scraping, unterstützt durch leistungsstarke Tools wie cURL und Simple HTML DOM Parser. Wenn Sie einen Scraper in PHP schreiben, kann das Skript auf dem Server und nicht auf einem PC ausgeführt werden, wodurch Serverressourcen aus praktischen Gründen genutzt werden. Darüber hinaus kann das Skript mithilfe von Planungstools wie Crontab so eingestellt werden, dass es in regelmäßigen Abständen ausgeführt wird, was die kontinuierliche Datenextraktion äußerst praktisch macht.
In diesem Artikel wurde der gesamte Prozess der Erstellung eines solchen Scrapers untersucht. Wir begannen mit der Einrichtung der Umgebung und der Installation der erforderlichen Komponenten. Anschließend stellten wir HTTP-Anfragen, analysierten die abgerufenen Daten und speicherten sie in einer Datei. Außerdem behandelten wir die Erstellung einfacher Tools und Techniken, um Ihr Skript effizienter und nützlicher zu machen.
Durch die Verwendung von PHP für das Web Scraping können Sie die Datenerfassung und -verarbeitung automatisieren und so sicherstellen, dass Ihre Aufgaben effizient und zuverlässig auf Serverressourcen ausgeführt werden.
