
WordPress ist in Verbindung mit dem WooCommerce-Plugin eine beliebte und praktische Wahl für die Erstellung von Online-Marktplätzen. Es bietet eine benutzerfreundliche Plattform zum Aufbau schöner und funktionaler E-Commerce-Shops mit minimalem Aufwand.
WooCommerce Web Scraping ist eine Methode zur automatisierten Datenextraktion aus WooCommerce-Shops. Diese Methode ermöglicht verschiedene Zwecke, darunter Preisüberwachung und dynamische Preisgestaltung, die Verfolgung der Produktpreise der Wettbewerber und die automatische Aktualisierung der Produktpreise, um wettbewerbsfähig zu bleiben. Es ermöglicht auch die Automatisierung von Routineaufgaben wie dem Abrufen von Produktbeschreibungen und -spezifikationen, der automatischen Aktualisierung von Produktinformationen und dem Sammeln von Produktbewertungen.
Somit erleichtern WooCommerce-Scraper nicht nur die Arbeit von Ladenbesitzern, indem sie ihnen einen schnellen Zugriff auf wichtige Wettbewerbsinformationen ermöglichen, sondern helfen ihnen auch, ihr Geschäft effektiver zu verwalten, indem sie datengesteuerte Entscheidungen treffen.
In diesem Artikel werden die verschiedenen Arten von Scrapern untersucht und Sie durch die Erstellung einer universellen Lösung zum Scrapen der meisten WooCommerce-Shops mit Python geführt. Wir stellen vorgefertigte Skripte zur Verfügung, die jeder auch mit minimalen Programmierkenntnissen nutzen kann. Wenn Sie sich jedoch für Scraping interessieren, aber keine Programmiererfahrung haben, empfehlen wir Ihnen, unseren Artikel über Web Scraping mit Google Sheets zu lesen. In diesem Artikel haben wir den Prozess anhand eines WooCommerce-Shops als Beispiel beschrieben.
Arten von WooCommerce-Scrapern
WooCommerce-Scraper sind Tools zum Extrahieren von Daten aus WooCommerce-basierten Online-Shops. Diese Schaber gibt es je nach Funktionalität, Komplexität und Zweck in verschiedenen Ausführungen. Hier sind einige gängige Arten von WooCommerce-Scrapern:
- Produktschaber. Sammeln Sie Produktinformationen wie Name, Beschreibung, Preis, Bilder, Kategorien und SKUs.
- Preisschaber. Verfolgen Sie Preisänderungen, Rabatte, Sonderangebote und Versandkosten.
- Bewertungsschaber. Sammeln Sie Kundenfeedback, Bewertungen, Kommentare und andere hilfreiche Informationen.
Während die Kategorisierung von Web-Scrapern in verschiedene Typen bei der Auswahl eines vorgefertigten Tools hilfreich sein kann, sollten Sie bedenken, dass Sie durch die Erstellung Ihres eigenen Scrapers die vollständige Kontrolle über die erhaltenen Informationen haben. Einer der Hauptvorteile eines benutzerdefinierten Scrapers ist die Möglichkeit, alle erforderlichen Informationen ohne Einschränkungen zu extrahieren.
Bei der Erstellung Ihres Schabers können Sie die von Ihnen benötigten Daten genau definieren und den Schaber entsprechend konfigurieren. Sie werden nicht durch vordefinierte Scraper-Typen oder Einschränkungen durch Tools von Drittanbietern eingeschränkt.
Darüber hinaus bietet Ihnen der Bau Ihres eigenen Schabers die Flexibilität, ihn an die individuellen Anforderungen Ihres Projekts anzupassen. Sie können neue Funktionen hinzufügen, die Leistung verbessern und den Scraper flexibel an Änderungen auf der Website oder Ihre Geschäftsanforderungen anpassen.
So erstellen Sie einen WooCommerce-Scraper
Bevor Sie mit dem Scrapen von WooCommerce beginnen, ist es wichtig, sich für die Vorgehensweise zu entscheiden. Es gibt zwei Hauptansätze:
- Daten von der Produktseite entfernen. Bei dieser Methode werden Produktinformationen direkt von den Seiten extrahiert, auf denen sie präsentiert werden. Mit diesem Ansatz können wir grundlegende Informationen wie Produktname, Preis und Foto erhalten. Allerdings können wir von der allgemeinen Produktseite keine Bewertungen, Beschreibungen oder andere detaillierte Informationen erhalten.
- Verwenden Sie SiteMap, um eine Liste der Produkte abzurufen und diese dann zu durchsuchen. Die zweite Möglichkeit besteht darin, auf die SiteMap der Website zuzugreifen, die alle Produktseiten auflistet. Anschließend können Sie diese Seiten durchlaufen und Informationen zu jedem Produkt sammeln. Der Vorteil besteht darin, dass wir absolut alle verfügbaren Informationen für jedes Produkt erhalten können, und der Nachteil besteht darin, dass wir Anfragen an absolut alle Seiten stellen müssen, was mehr Zeit und Ressourcen in Anspruch nehmen kann.
Beide Ansätze haben Vor- und Nachteile und ihre Wahl hängt von den spezifischen Anforderungen des Projekts ab. In diesem Artikel werden wir beide Methoden betrachten, ihre Funktionen beschreiben und vorgefertigte Skripte bereitstellen, die Sie sofort zum Scrapen von Daten aus WooCommerce verwenden können.
Scrapen Sie Produktdaten von einer Suchseite
Beginnen wir mit dem einfachsten Ansatz: Analysieren Sie die Produktseite, identifizieren Sie die Elementselektoren und extrahieren Sie sie. Um das Beispiel vielfältiger zu gestalten, erhalten wir den Seitencode anders, indem wir die Bibliotheken „Requests“ und „BeautifulSoup“ und komplexere Optionen mithilfe einer Web-Scraping-API verwenden.
Identifizieren Sie Zieldaten
Definieren wir zunächst Zielelemente am Beispiel einer der Sites. Gehen Sie dazu zur Produktseite einer WooCommerce-Site, die wie folgt aussieht: „https://example.com/shop“ und öffnen Sie DevTools (F12 oder Rechtsklick und „Inspizieren“).
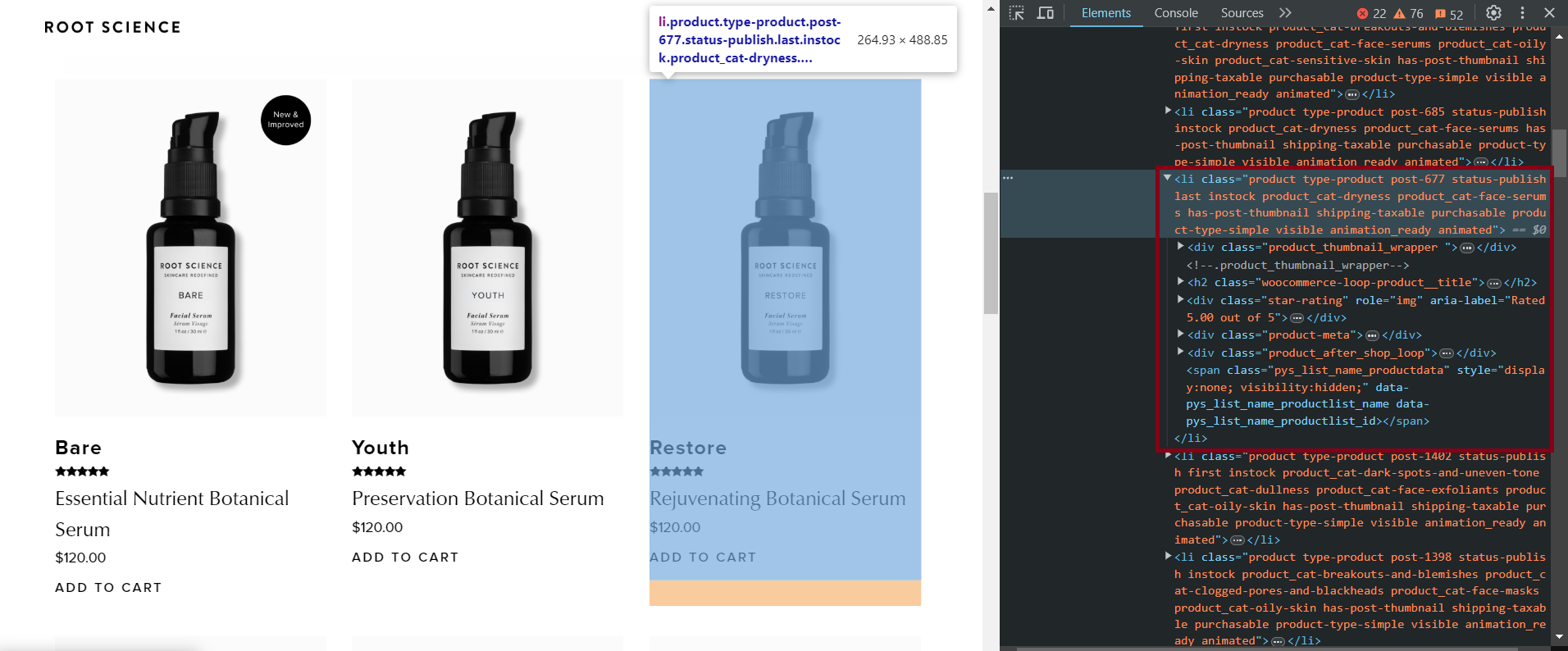
Hier sind die CSS-Selektoren für verschiedene Elemente, mit denen alle verfügbaren Produktinformationen extrahiert werden können:
- Titel:
h2.woocommerce-loop-product__title - Bewertung:
.star-rating - Beschreibung:
.product-meta - Preis:
.price .woocommerce-Price-amount - Bildlink:
img - Link zur Produktseite:
.woocommerce-LoopProduct-link
Diese Selektoren wurden auf mehreren WooCommerce-Websites getestet und haben festgestellt, dass sie für die meisten Websites funktionieren. Einige Ressourcen verfügen jedoch möglicherweise nicht über bestimmte Elemente, z. B. Produktbeschreibungen.
Statisches Schaben
Wir werden Python für die Skripterstellung verwenden, aber machen Sie sich keine Sorgen, wenn Sie keine Programmiererfahrung haben. Wir haben uns für Python entschieden, weil es einfach und funktional ist und es uns ermöglicht, vorgefertigte Skripte problemlos über Google Colaboratory zu teilen, die Sie sofort ausführen und verwenden können.
Ein fertiges Skript können Sie hier finden und nutzen. Um es zu verwenden, ersetzen Sie einfach die Website-URL durch die URL, die Sie scannen möchten, und führen Sie dann jeden Codeblock nacheinander aus.
Um ein Skript auf Ihrem PC auszuführen (nicht in Colaboratory), benötigen Sie Python Version 3.10 oder höher. Anweisungen zum Einrichten Ihrer Umgebung und zum Erstellen von Scrapern finden Sie in unserem Einführungsartikel zum Python-Scraping.
Erstellen Sie eine neue *.py-Datei und importieren Sie die erforderlichen Bibliotheken:
import requests
from bs4 import BeautifulSoupDefinieren Sie eine Variable zum Speichern der WooCommerce-Website-URL und hängen Sie den Abschnitt „Shop“ an, in dem sich alle Produkte befinden.
base_url = "https://www.shoprootscience.com/"
url = base_url + "shop"Erstellen Sie eine Variable zum Speichern der Produkte:
all_products = ()Senden Sie eine GET-Anfrage an die URL und rufen Sie den HTML-Code der gesamten Seite ab:
response = requests.get(url)Überprüfen Sie, ob der Antwortstatuscode 200 ist, was auf eine erfolgreiche Antwort hinweist:
if response.status_code == 200:Erstellen Sie ein BeautifulSoup-Objekt und analysieren Sie die Seite, um die Navigation und das Abrufen von Elementen zu erleichtern:
soup = BeautifulSoup(response.content, 'html.parser')Identifizieren Sie den am besten geeigneten Selektor zum Auffinden von Produktelementen. Basierend auf Beobachtungen von mehreren WooCommerce-Websites werden Produkte wahrscheinlich entweder in „li“- oder „div“-Tags mit der „product“-Klasse gespeichert:
products = soup.find_all(('li', 'div'), class_='product')Durchlaufen Sie alle gefundenen Produkte nacheinander:
for product in products:Extrahieren Sie alle verfügbaren Daten:
# Extract product title
title_elem = product.find('h2', class_='woocommerce-loop-product__title')
title_text = title_elem.text.strip() if title_elem else '-'
# Extract product rating
rating_elem = product.find('div', class_='star-rating')
rating_text = rating_elem('aria-label') if rating_elem else '-'
# Extract product description
description_elem = product.find('div', class_='product-meta')
description_text = description_elem.text.strip() if description_elem else '-'
# Extract product price
price_elem = product.find('span', class_='price')
price_text = price_elem.text.strip() if price_elem else '-'
# Extract product image link
image_elem = product.find('img')
image_src = image_elem('src') if image_elem else '-'
# Extract product page link
product_link_elem = product.find('a', class_='woocommerce-LoopProduct-link')
product_link = product_link_elem('href') if product_link_elem else '-'In diesem Code behandeln wir die Möglichkeit fehlender Produktdaten. Anstatt einen Wert anzuzeigen, fügen wir an dessen Stelle einfach ein „-“ ein. Dieser Ansatz hilft uns nicht nur, die Ausgabe zu organisieren, sondern auch Fehler zu vermeiden, wenn ein Element fehlt.
Drucken Sie die Produktliste mit allen gesammelten Daten aus:
print(f"Title: {title_text}")
print(f"Rating: {rating_text}")
print(f"Description: {description_text}")
print(f"Price: {price_text}")
print(f"Image Link: {image_src}")
print(f"Product Page Link: {product_link}")
print('-' * 50)Speichern Sie die Produktdaten zur späteren Speicherung in einer Variablen:
all_products.append((title_text, rating_text, description_text, price_text, image_src, product_link))Behandeln Sie Fehler, wenn der Statuscode nicht 200 ist:
else:
print("Error fetching page:", response.status_code)Dieser Code ruft eine Liste von Produkten mit allen Daten ab, die wir gesammelt haben:
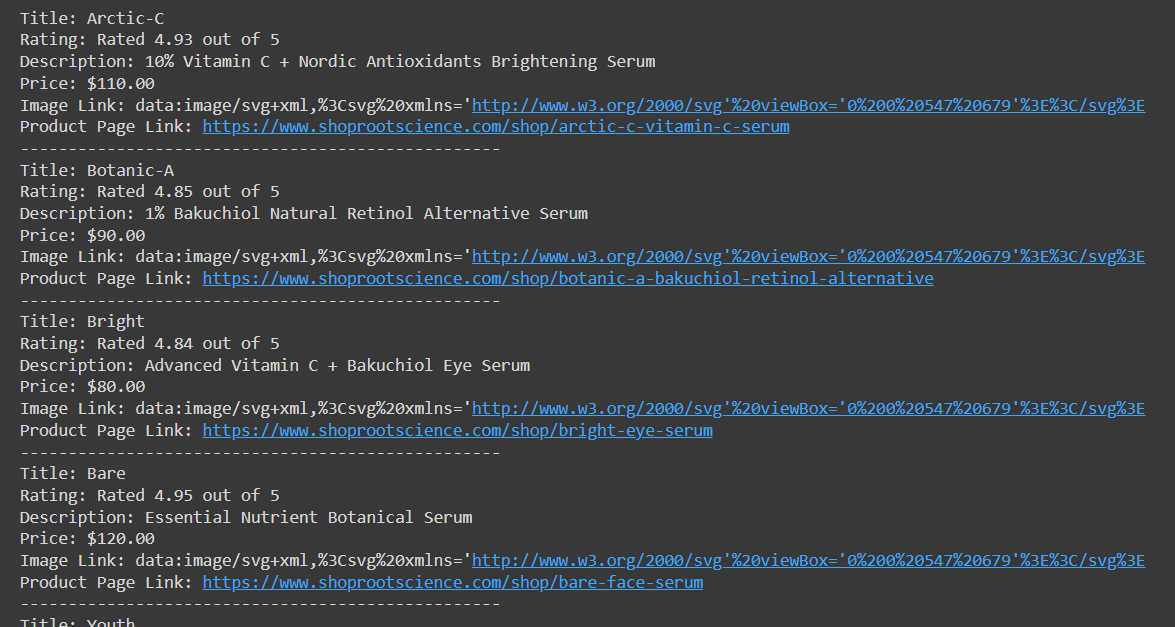
Etwas später werden wir über das Speichern von Daten in CSV sprechen, aber zunächst wollen wir über die Nachteile dieser Datenerfassungsmethode sprechen. Obwohl wir auf diese Weise erfolgreich Daten extrahieren können, erkennen einige Websites ein solches Skript leicht als Bot und blockieren seinen Zugriff auf die Ressource.
Sie können dies beispielsweise sehen, wenn Sie versuchen, eine andere WooCommerce-Website mit Schutz wie dieser zu scannen. Wenn Sie versuchen, mit dem zuvor erstellten Skript Daten daraus zu sammeln, erhalten Sie den Statuscode „403 Forbidden“. Aber keine Sorge, dieses Problem lässt sich auf zwei Arten leicht lösen:
- Verwenden Sie die Selenium-, Pyppeteer- oder PlayWright-Bibliothek zum Scrapen mit einem Headless-Browser um reales Nutzerverhalten zu simulieren. Sie müssen außerdem einen Proxy anschließen, um sich zu schützen und eine größere Anonymität sowie einen Captcha-Lösungsdienst zu erreichen, der nützlich sein wird, wenn sie angezeigt werden.
- Verwenden Sie die Web Scraping API. Diese Drittanbieterressource verwendet bereits Proxys, umgeht Captchas und fordert die Zielseite an. In diesem Fall erhalten Sie lediglich die HTML-Seite der Website und benötigen nichts anderes.
Wir werden die zweite Option verwenden, da diese viel einfacher ist und im Gegensatz zu Headless-Browsern auch in Google Colaboratory verwendet werden kann.
Scraping mit API
Wie bereits erwähnt, reagieren nicht alle Websites positiv auf die Verwendung der Requests-Bibliothek. Erwägen wir daher die Verwendung der Web-Scraping-API von Hasdata. Um es zu nutzen, müssen Sie sich lediglich auf der Website registrieren und sich bei Ihrem persönlichen Konto anmelden, um Ihren API-Schlüssel zu finden.
Sie können auch die finden fertiges Skript in Colab Researchund um es zu verwenden, müssen Sie lediglich Ihren API-Schlüssel und die URL der WooCommerce-Website eingeben, die Sie durchsuchen möchten.
Schauen wir uns nun Schritt für Schritt an, wie man ein solches Skript erstellt. Erstellen Sie zunächst eine neue Datei mit der Erweiterung *.py und importieren Sie die erforderlichen Bibliotheken:
import requests
from bs4 import BeautifulSoup
import csv
import jsonWie Sie sehen, importieren wir hier auch die JSON-Bibliothek, da die Web Scraping API Daten im JSON-Format zurückgibt.
Anschließend erstellen wir Variablen und geben den API-Schlüssel, die URL der Website, die gescrapt werden soll, und den API-Endpunkt an:
api_key = "YOUR-API-KEY"
base_url = "https://bloomscape.com/"
url = base_url + "shop"
base_api_url = "https://api.scrape-it.cloud/scrape/web"
all_products = ()Definieren wir nun den Anforderungstext und die Header für die API. Hier können Sie den bevorzugten Proxy-Typ und das Land angeben, ob ein Seiten-Screenshot erstellt, E-Mails extrahiert werden soll und vieles mehr. Eine vollständige Liste der Parameter finden Sie auf der Dokumentationsseite.
payload = json.dumps({
"url": url,
"js_rendering": True,
"proxy_type": "datacenter",
"proxy_country": "US"
})
headers = {
"x-api-key": api_key,
"Content-Type": "application/json"
}Eine Anfrage stellen:
response = requests.request("POST", base_api_url, headers=headers, data=payload)Dann ist das Skript identisch mit dem vorherigen Beispiel, außer dass wir den HTML-Code der Seite aus der JSON-Antwort der Web-Scraping-API erhalten:
if response.status_code == 200:
data = json.loads(response.text)
html_content = data("content")
soup = BeautifulSoup(html_content, 'html.parser')
products = soup.find_all(('li', 'div'), class_='product')
for product in products:
title_elem = product.find('h2', class_='woocommerce-loop-product__title')
title_text = title_elem.text.strip() if title_elem else '-'
rating_elem = product.find('div', class_='star-rating')
rating_text = rating_elem('aria-label') if rating_elem else '-'
description_elem = product.find('div', class_='product-meta')
description_text = description_elem.text.strip() if description_elem else '-'
price_elem = product.find(('span','div'), class_='price')
price_text = price_elem.text.strip() if price_elem else '-'
image_elem = product.find('img')
image_src = image_elem('src') if image_elem else '-'
product_link_elem = product.find('a', class_='woocommerce-LoopProduct-link')
product_link = product_link_elem('href') if product_link_elem else '-'
print(f"Title: {title_text}")
print(f"Rating: {rating_text}")
print(f"Description: {description_text}")
print(f"Price: {price_text}")
print(f"Image Link: {image_src}")
print(f"Product Page Link: {product_link}")
print('-' * 50)
all_products.append((title_text, rating_text, description_text, price_text, image_src, product_link))
else:
print("Error fetching data from the API:", response.status_code)Dieser Ansatz ermöglicht den Zugriff auf bisher nicht verfügbare Daten:
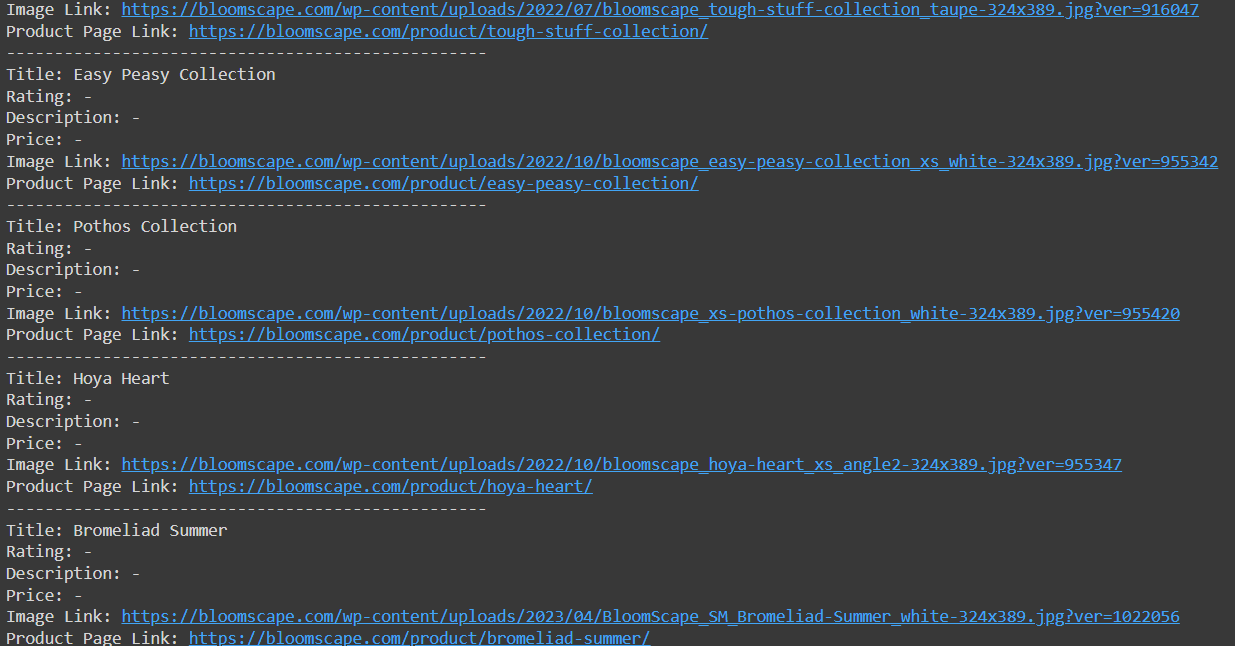
Jetzt müssen wir nur noch die bereits erfassten Daten speichern.
Gekratzte Daten speichern
Um Daten in einer CSV-Datei in Python zu speichern, verwenden wir die CSV-Bibliothek und die Daten aus der Variablen all_products. Erstellen Sie ein CSVWriter-Objekt mit csv.writer() Funktion. Geben Sie dann den Dateinamen einschließlich der Erweiterung *.csv an, öffnen Sie ihn im Schreibmodus ('w') und schreiben Sie die Spaltenüberschriften mit writerow() Methode und schreiben Sie die Datenzeilen mit der writerows() Methode. Übergeben Sie die all_products Variable als Argument:
with open('products.csv', 'w', newline="", encoding='utf-8') as csvfile:
csvwriter = csv.writer(csvfile)
csvwriter.writerow(('Title', 'Rating', 'Description', 'Price', 'Image Link', 'Product Page Link'))
csvwriter.writerows(all_products)Sie können je nach Bedarf einen anderen Dateinamen wählen. Wenn Sie beispielsweise Daten von mehreren Websites haben, können Sie den Namen der Website als Dateinamen verwenden. Sie können auch das aktuelle Datum in den Dateinamen einfügen, um die Aktualität der Daten im Auge zu behalten.
Entfernen von Produktlinks und Daten aus der Sitemap
Die meisten auf WordPress mit dem WooCommerce-Plugin erstellten Websites haben eine ähnliche HTML-Seitenstruktur und Sitemap. Damit können wir schnell Links zu allen Produktseiten abrufen, diese crawlen und vollständige Informationen zu allen Produkten auf der Website sammeln. Obwohl die Struktur je nach Thema leicht variieren kann, betrachten wir das häufigste Szenario.
Wenn Sie ein fertiges Skript wünschen, gehen Sie zur Google Colaboratory-Skriptseite, legen Sie Ihre Parameter fest und erhalten Sie alle erforderlichen Informationen.
Abrufen der Sitemap-XML-Datei
Lassen Sie uns zunächst ein Skript erstellen, um Produktseitenlinks von verschiedenen WooCommerce-Websites zu sammeln. Dazu navigieren wir zur Sitemap-Seite und untersuchen deren Struktur. Die meisten Sitemaps folgen diesem Format:
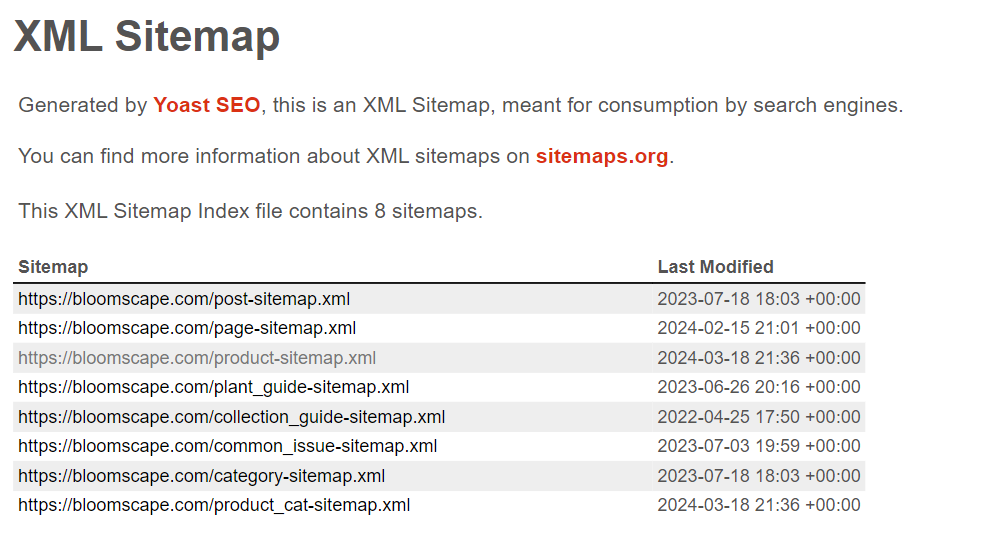
Einige Details können je nach installiertem Theme variieren. Das Wichtigste ist jedoch, eine Liste mit Produktlinks zu finden product-sitemap.xml Seite.

Um den Inhalt dieser Seite zu erhalten, benötigen wir die zuvor besprochene Requests-Bibliothek zum Senden von Anfragen und die LXML-Bibliothek zum Verarbeiten der XML-Daten der Seite. Lassen Sie uns eine neue Datei erstellen und die erforderlichen Bibliotheken importieren:
import requests
from lxml import etreeUm den Inhalt der Seite abzurufen, können wir wie zuvor die Requests-Bibliothek verwenden:
domain = "shoprootscience.com"
sitemap_url = f"https://{domain}/product-sitemap.xml"
response = requests.get(sitemap_url)Nachdem wir den XML-Seiteninhalt erfolgreich abgerufen haben, müssen wir ihn nur noch analysieren, um die erforderlichen Links zu extrahieren.
Bauen wir auf dem vorherigen Beispiel auf und überprüfen wir, ob wir den Statuscode 200 erhalten haben:
if response.status_code == 200:Wenn ja, speichern wir alle gefundenen Links in einer Variablen:
sitemap_content = response.content
root = etree.fromstring(sitemap_content)
urls = ()
for child in root:
for sub_child in child:
urls.append(sub_child.text)
if urls:
print(f"Sitemap found for {domain}:")
for url in urls:
if domain in url:
print(url)
else:
print(f"No URLs found in the sitemap for {domain}.")Andernfalls drucken Sie die Benachrichtigung aus:
else:
print(f"No sitemap found for {domain}.")Wenn Sie lediglich Produktlinks von WooCommerce-Websites sammeln müssen, können Sie unser Colab Research-Skript verwenden.
Durchsuchen Sie alle Produktseiten
Lassen Sie uns unser Skript weiter verbessern, indem wir den Links folgen, anstatt sie auf dem Bildschirm anzuzeigen, und alle notwendigen Daten zu jedem Produkt sammeln.
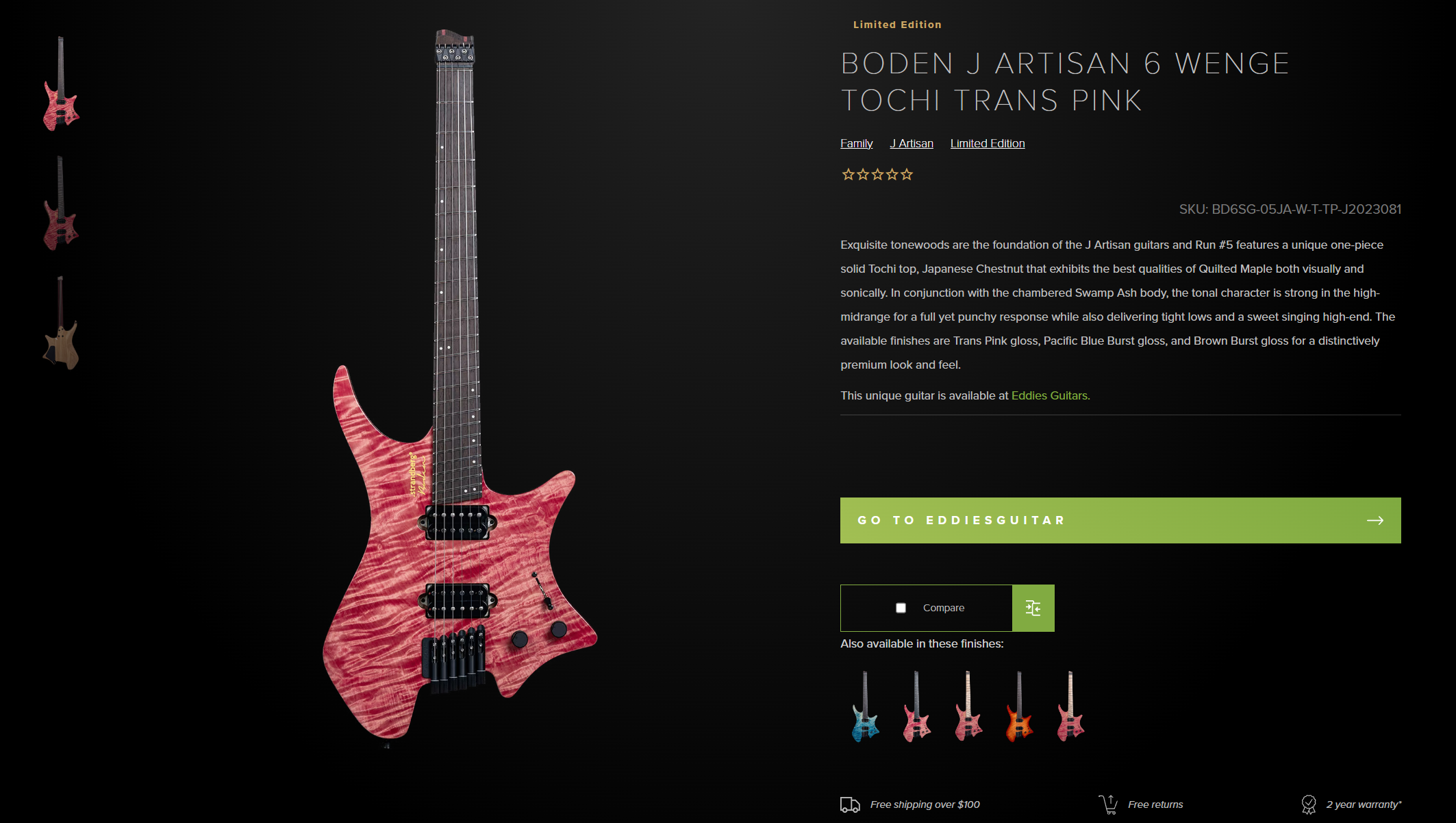
Erstellen Sie eine separate Variable, in der wir die Produktdaten speichern.
all_products = ()Importieren Sie die BeautifulSoup-Bibliothek, um die Daten auf der Seite analysieren zu können:
from bs4 import BeautifulSoupKommen wir nun zu dem Teil, in dem wir die gesammelten Links durchlaufen und sie auf dem Bildschirm anzeigen. Möglicherweise ist Ihnen aufgefallen, dass beim Scrapen von Links aus einer Sitemap der erste Link immer zur Seite mit allen Produkten führt und mit „Shop“ endet. Fügen wir also eine Überprüfung hinzu, um sicherzustellen, dass es sich nicht um die aktuelle URL handelt:
if domain in url and not url.endswith("shop"):Der Rest ist derselbe wie das, was wir bereits gemacht haben, nur verwenden wir leicht unterschiedliche Selektoren, die für die Produktseite geeignet sind:
response_product = requests.get(url)
if response_product.status_code == 200:
soup = BeautifulSoup(response_product.content, 'html.parser')
title_elem = soup.find('h1', class_='product_title')
title_text = title_elem.text.strip() if title_elem else '-'
rating_elem = soup.find('div', class_='star-rating')
rating_text = rating_elem('aria-label') if rating_elem else '-'
description_elem = soup.find('div', class_='woocommerce-product-details__short-description')
description_text = description_elem.text.strip() if description_elem else '-'
price_elem = soup.find(('div', 'span'), class_='woocommerce-Price-amount')
price_text = price_elem.text.strip() if price_elem else '-'
product = soup.find(('li', 'div'), class_='product')
image_elem = product.find('img')
image_src = image_elem('src') if image_elem else '-'
product_link = urlZeigen Sie die Daten auf dem Bildschirm an und speichern Sie sie in einer Variablen, um sie später in einer Datei zu speichern:
print(f"Title: {title_text}")
print(f"Rating: {rating_text}")
print(f"Description: {description_text}")
print(f"Price: {price_text}")
print(f"Image Link: {image_src}")
print(f"Product Page Link: {product_link}")
print('-' * 50)
all_products.append((title_text, rating_text, description_text, price_text, image_src, product_link))Lassen Sie uns den Code ausführen und seine Funktionalität überprüfen:
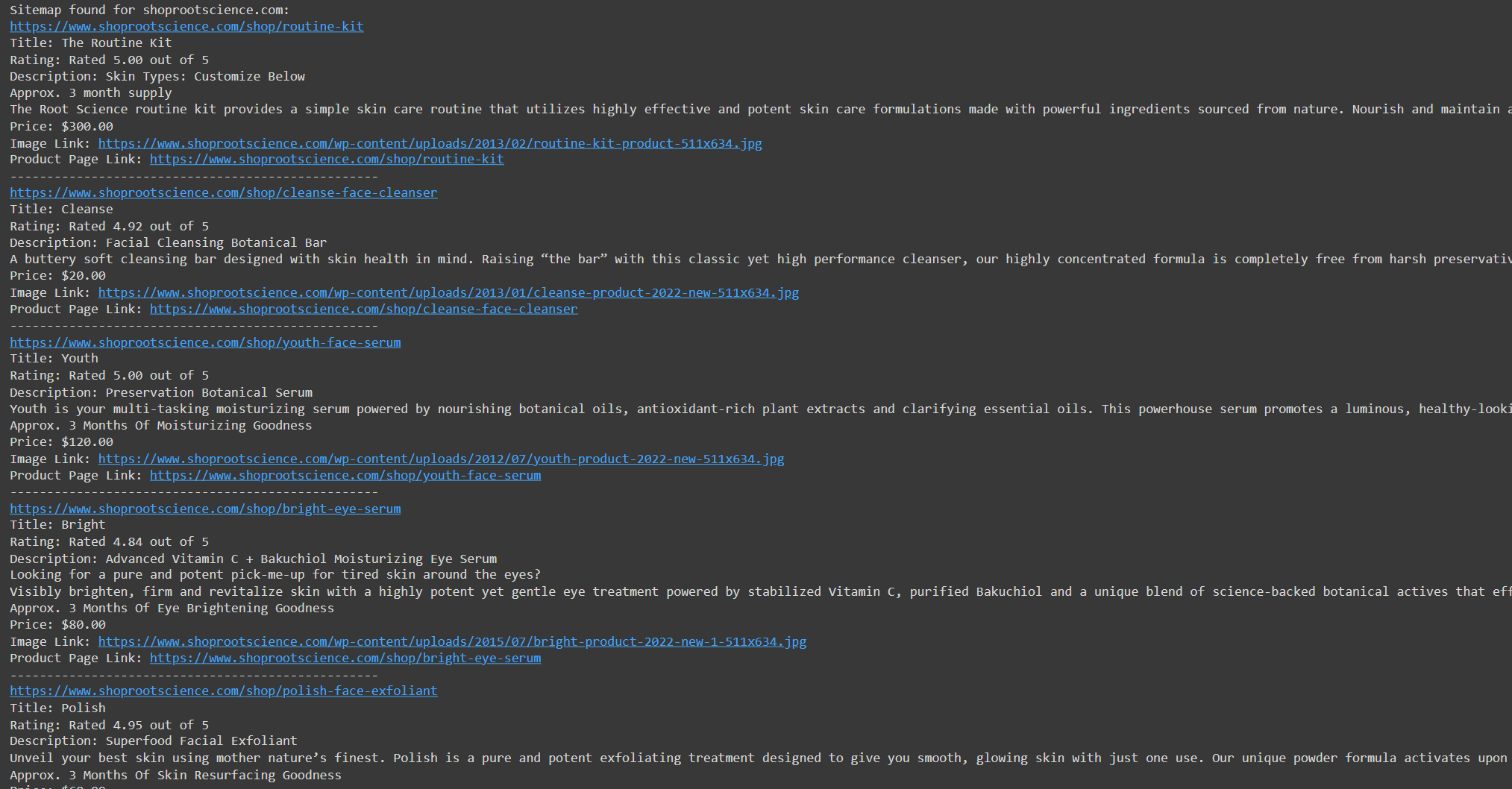
Speichern wir nun die extrahierten Daten in verschiedenen Formaten.
Speichern Sie Daten in CSV, JSON oder DB
Die gängigsten Datenspeicherformate sind CSV und JSON. Wir zeigen auch, wie man Daten in einer Datenbank speichert. Wir wählen die einfachste Option und verwenden die SQLite3-Bibliothek, um Daten in eine DB-Datei zu schreiben. Wir werden eine andere Bibliothek, Pandas, verwenden, um Daten in JSON und CSV zu speichern, da dies viel einfacher zu implementieren ist.
Importieren wir die Bibliotheken:
import pandas as pd
import sqlite3Am Ende des Skripts implementieren wir das Speichern von Daten in einer CSV-Datei mithilfe der Pandas-Bibliothek:
df = pd.DataFrame(all_products, columns=('Title', 'Rating', 'Description', 'Price', 'Image Link', 'Product Page Link'))
df.to_csv('products.csv', index=False)Wir werden denselben Datenrahmen verwenden und die Daten in JSON speichern:
df.to_json('products.json', orient="records")Abschließend erstellen wir eine Verbindung zur Datenbankdatei, fügen die Daten ein und schließen die Verbindung:
conn = sqlite3.connect('products.db')
df.to_sql('products', conn, if_exists="replace", index=False)
conn.close()Wie Sie sehen, können Sie mit Pandas dank Datenrahmen Daten schnell genug speichern. Diese Bibliothek unterstützt viel mehr Speicheroptionen als berücksichtigt. Weitere Informationen zu dieser Bibliothek und ihren Funktionen finden Sie in der offiziellen Dokumentation.
Testen Sie den Scraper auf verschiedenen WooCommerce-Sites
Lassen Sie uns dieses Skript auf drei WooCommerce-Websites testen, um seine Vielseitigkeit sicherzustellen. Wir ändern das Skript so, dass es mehrere Websites statt nur einer durchläuft, und speichern die extrahierten Daten in einer CSV-Datei.
Sie finden das Skript auf Google Colaboratory. Hier zeigen wir nur die Ergebnisse seiner Ausführung auf verschiedenen Websites:
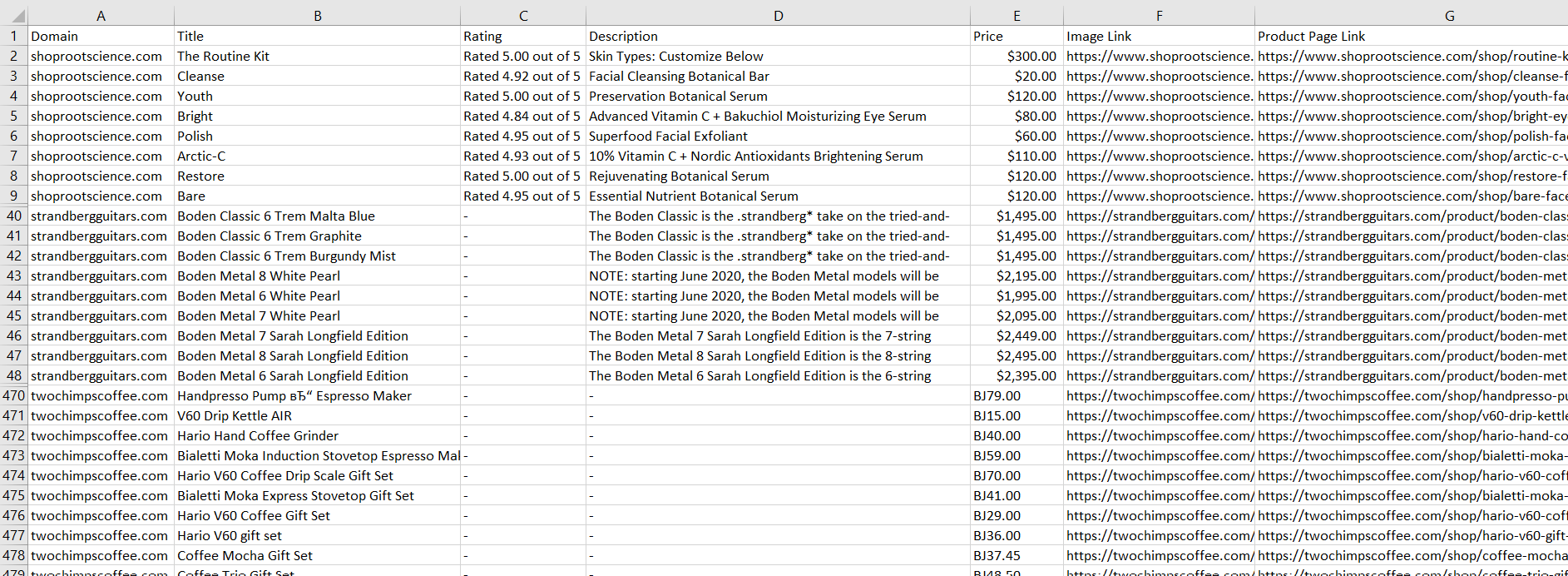
Wie Sie dem Screenshot entnehmen können, können wir aufgrund der ähnlichen Struktur aller WooCommerce-Seiten mit einem universellen Tool problemlos die erforderlichen Daten extrahieren.
Fazit und Erkenntnisse
Dieser Leitfaden bietet einen Überblick über die Erstellung eines WooCommerce-Scrapers für den Zugriff auf Produktdaten und andere wichtige Elemente eines Online-Shops. Wir haben uns mit zwei Hauptmethoden befasst: dem direkten Scrapen von Produktseiten und der Verwendung der SiteMap für Produktlisten. Die bereitgestellten Skripte sind aufgrund ihrer ähnlichen Strukturen an die meisten WooCommerce-Websites anpassbar.
Beim Scraping von Produktseiten haben wir den Einsatz von Python und BeautifulSoup demonstriert, um wichtige Produktdetails wie Titel, Preise, Beschreibungen und Bilder zu extrahieren. Alternativ haben wir durch Parsen der SiteMap mit Python und lxml gezeigt, wie Produkt-URLs und relevante Informationen extrahiert werden.
Während Scraping Herausforderungen wie Bot-Schutz oder technische Einschränkungen mit sich bringt, kann eine Web-Scraping-API eine effizientere und zuverlässigere Lösung bieten. Sie können das zuvor bereitgestellte Skript verwenden, das keine Umgehung von Blöcken oder das Lösen von CAPTCHAs erfordert; es nutzt einfach die Web Scraping API.
Zusammenfassend lässt sich sagen, dass der Aufbau eines WooCommerce-Scraper es Unternehmen ermöglicht, sich einen Wettbewerbsvorteil zu verschaffen. Da die Selektoren identisch bleiben, ist eine Anpassung beim Scraping einer anderen WooCommerce-Site nicht erforderlich. Durch die Nutzung der Möglichkeiten des Scrapings und der Automatisierung können neue Wege für Wachstum und Erfolg erschlossen werden.
