
Schritt 2: Senden einer Anfrage und Analysieren der Antwort
Wir erstellen eine payload Objekt, das unseren API-Schlüssel und die G2-URL enthält, die wir scannen möchten. Das payload wird dann verwendet, um a zu senden get() Anfrage an unsere Scraping-API, die die Komplexität des Web-Scrapings wie intelligente IP- und Header-Rotation, CAPTCHA-Verarbeitung und mehr mithilfe von maschinellem Lernen und statistischer Analyse bewältigt.
payload = {"api_key": API_KEY, "url": url}
html = requests.get("https://api.scraperapi.com", params=payload)
Dann können wir es verwenden BeautifulSoup um die HTML-Antwort zu analysieren und als zu speichern soup Objekt – so können wir dann mithilfe von CSS-Selektoren durch den analysierten Baum navigieren.
soup = BeautifulSoup(html.text, "lxml")
Schritt 3: Extrahieren von G2-Softwarebewertungen
Dieser Schritt umfasst die Initialisierung eines Wörterbuchs zum Speichern der Ergebnisse und das Extrahieren des Produktnamens, der Anzahl der Bewertungen und Benutzerbewertungsdaten aus der analysierten HTML-Antwort.
Wir beginnen mit der Erstellung eines Wörterbuchs namens „Ergebnisse“, um die Daten zu speichern, die wir extrahieren.
results = {"product_name": "", "number_of_reviews": "", "reviews": ()}
Hier, product_name Und number_of_reviews sind Zeichenfolgen, die den Namen des Produkts bzw. die Gesamtzahl der Bewertungen enthalten reviews ist eine Liste mit Wörterbüchern, die jeweils eine einzelne Rezension darstellen.
Sobald wir unser Wörterbuch fertig haben, extrahieren wir den Produktnamen aus dem analysierten HTML.
Wir verwenden BeautifulSoup's select_one() Methode, um das erste Element auszuwählen, das dem CSS-Selektor entspricht .product-head__title a. Wir erhalten dann den Text dieses Elements und weisen ihn zu results('product_name').
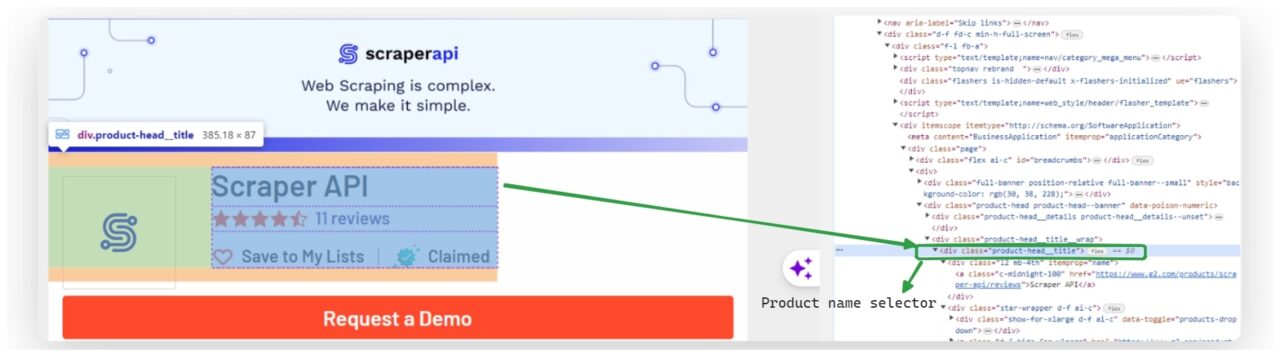
product_name_element = soup.select_one(".product-head__title a")
results("product_name") = product_name_element.get_text(strip=True) if product_name_element else "Product name not found"
Ebenso extrahieren wir die Anzahl der Bewertungen, indem wir das Element mit dem CSS-Selektor auswählen li.list--piped__li und seinen Text erhalten.

reviews_element = soup.find("li", {"class": "list--piped__li"})
results("number_of_reviews") = reviews_element.get_text(strip=True) if reviews_element else "Number of reviews not found"
Danach gehen wir alle Bewertungen auf der Seite durch. Jede Rezension wird mit dem Selektor ausgewählt .paper.paper--white.paper--box. Wir extrahieren die Nutzername, Zusammenfassung, vollständige Rezension, Datum, URLUnd Bewertung Für jede Rezension speichern Sie diese Informationen dann in einem neuen Wörterbuch mit dem Namen review_data.
Extrahieren des Benutzernamens
Der Benutzername befindet sich normalerweise in einem Anker (a) Etikett. Um es zu extrahieren, suchen wir nach dem Ankertag mit einer Klasse, die angibt, dass es den Benutzernamen enthält.
Wenn der Klassenname beispielsweise lautet link--header-colorverwenden wir dann BeautifulSoup, um dies zu finden a markieren und dann den Textinhalt abrufen.

username_element = review.find("a", {"class": "link--header-color"})
review_data("username") = username_element.get_text(strip=True) if username_element else "No username found"
Extrahieren der Rezensionszusammenfassung
Die Zusammenfassung der Rezension finden Sie in einem h3 Überschrift mit einer Klasse auf m-0 l2.
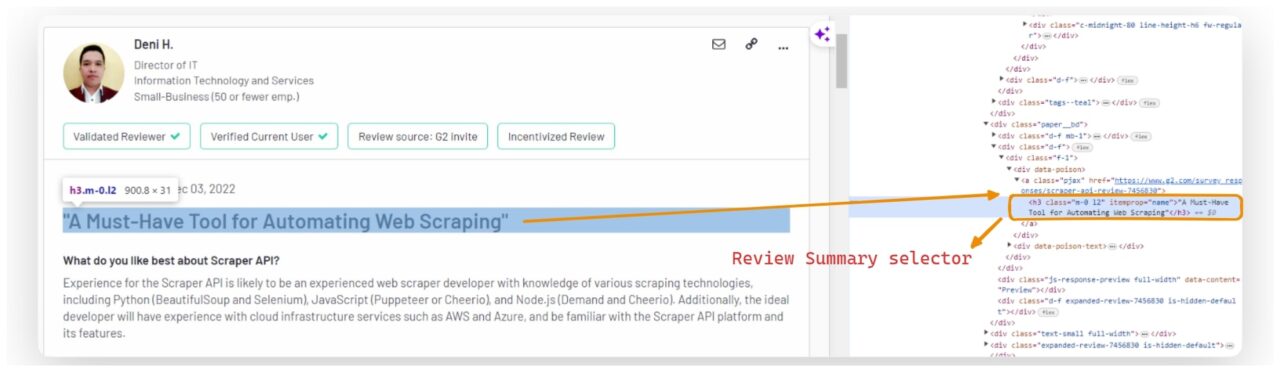
summary_element = review.find("h3", {"class": "m-0 l2"})
review_data("summary") = summary_element.get_text(strip=True).replace('"', "") if summary_element else "No summary found"
Extrahieren des Überprüfungstextes
Der vollständige Text der Rezension ist normalerweise in einem enthalten div mit einem itemprop Attribut auf gesetzt reviewBody. Um den Rezensionstext zu extrahieren, finden wir diesen div und den Textinhalt abrufen.
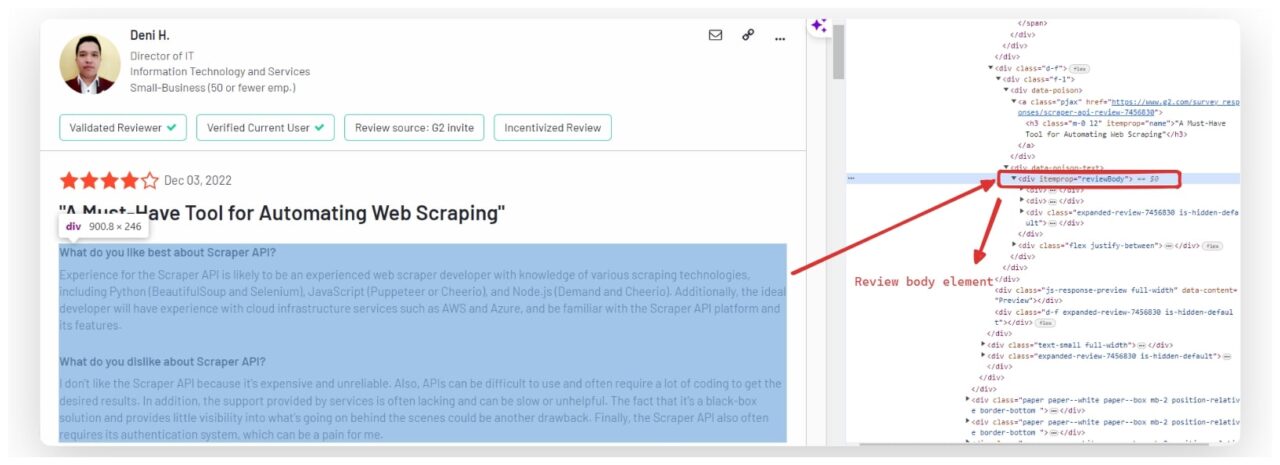
user_review_element = review.find("div", itemprop="reviewBody")
review_data("review") = user_review_element.get_text(strip=True) if user_review_element else "No review found"
Extrahieren des Überprüfungsdatums
Das Datum der Überprüfung liegt häufig innerhalb von a time Element.
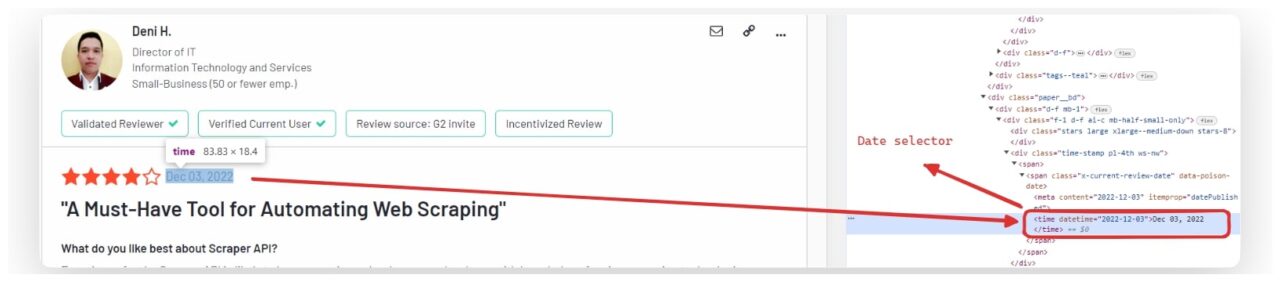
review_date_element = review.find("time")
review_data("date") = review_date_element.get_text(strip=True) if review_date_element else "No date found"
Extrahieren der Bewertungs-URL
Um die URL jeder Bewertung zu extrahieren, suchen wir nach einem Anker-Tag, das Folgendes enthält href Attribut. Konkret interessiert uns die a Tags mit der Klasse pjaxda dies die Klasse ist, die G2 für die Links zu den einzelnen Bewertungen verwendet.
So können wir dies in unseren Extraktionsprozess einbeziehen:
review_url_element = review.find("a", {"class": "pjax"})
review_data("url") = review_url_element("href") if review_url_element else "No URL found"
Extrahieren der Bewertung
Bewertungen finden Sie innerhalb von a meta Tag mit einem Attribut itemprop einstellen ratingValue. Wir suchen nach diesem Tag und extrahieren es content Attribut, um den Bewertungswert zu erhalten.
rating_element = review.find("meta", itemprop="ratingValue")
review_data("rating") = rating_element("content") if rating_element else "No rating found"
Jedes Datenelement wird dann in einem Wörterbuch namens gespeichert review_data. Nachdem wir die Daten für jede Bewertung extrahiert haben, fügen wir sie an review_data Zu results('reviews').
results("reviews").append(review_data)
Am Ende dieses Schritts ist das Ergebnis ein Wörterbuch, das den Produktnamen, die Anzahl der Rezensionen und eine Liste von Wörterbüchern enthält, die jeweils eine einzelne Rezension darstellen.
