
In diesem Tutorial erfahren Sie, wie Sie:
- Verwenden Sie Python und BeautifulSoup zum Extrahieren von Daten aus Trustpilot.
- Exportieren Sie diese wichtigen Daten in eine CSV-Datei.
- Verwenden Sie ScraperAPI, um die Anti-Scraping-Schutzmaßnahmen von Trustpilot zu überwinden.
TL;DR: Vollständige TrustPilot-Rezensionen Scraper
Hier ist der fertige Code für alle, die es eilig haben:
from bs4 import BeautifulSoup
import requests
import csv
company = "nookmart.com"
base_url = f"https://www.trustpilot.com/review/{company}"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'accept-language': 'en-US,en;q=0.9'
}
payload = {
'api_key': "YOUR API KEY",
'url': base_url,
'render': 'true',
'keep_headers': 'true',
}
try:
response = requests.get('https://api.scraperapi.com', params=payload, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
pages_to_scrape = 10
with open('trustpilot_reviews.csv', 'w', newline='', encoding='utf-8') as csvfile:
csv_writer = csv.writer(csvfile)
csv_writer.writerow(('Reviewer', 'Rating', 'Review', 'Date'))
for page in range(1, pages_to_scrape):
payload('url') = f"{base_url}?page={page}"
page_response = requests.get('https://api.scraperapi.com', params=payload, headers=headers)
page_soup = BeautifulSoup(page_response.content, 'html.parser')
reviews = page_soup.find_all('div', {"class": "styles_reviewCardInner__EwDq2"})
for review in reviews:
reviewer = review.find("span", attrs={"class": "typography_heading-xxs__QKBS8"}).text
rating = review.find("div", attrs={"class": "styles_reviewHeader__iU9Px"})("data-service-review-rating")
content_element = review.find("p", attrs={"class": "typography_body-l__KUYFJ"})
content = content_element.text if content_element else 'None'
date = review.find("p", attrs={"class":"typography_body-m__xgxZ_ typography_appearance-default__AAY17"}).text
csv_writer.writerow((reviewer, rating, content, date))
print("Data Extraction Successful!")
except Exception as e:
print("An error occurred:", e)
Bevor Sie den Code ausführen, fügen Sie Ihren API-Schlüssel hinzu api_key Parameter innerhalb der Nutzlast.
Notiz: Sie haben keinen API-Schlüssel? Erstellen Sie ein kostenloses ScraperAPI-Konto, um 5.000 API-Credits zu erhalten und alle unsere Tools 7 Tage lang auszuprobieren.
Möchten Sie sehen, wie wir es gebaut haben? Lesen Sie weiter und begleiten Sie uns auf dieser spannenden Scraping-Reise!
Anforderungen
Bevor wir mit dem Scrapen von Trustpilot-Bewertungen beginnen, ist es wichtig, unsere Umgebung mit allen wichtigen Tools und Bibliotheken einzurichten. So können Sie loslegen:
- Python-Installation: Stellen Sie sicher, dass Sie Python installiert haben, idealerweise Version 3.10 oder höher, das Sie von der offiziellen Python-Website herunterladen können.
- Bibliotheksinstallationen: Wir benötigen zwei wesentliche Python-Bibliotheken –
requestsUndBeautifulSoup(bs4). Öffnen Sie Ihr Terminal oder Ihre Eingabeaufforderung und installieren Sie sie mit dem folgenden Befehl:
pip install requests beautifulsoup4
requests: Diese Bibliothek ist unser vertrauenswürdiges Tool zum Senden von HTTP-Anfragen an ScraperAPI. Es ist wichtig, um den HTML-Inhalt von Trustpilot abzurufen und als Brücke zwischen unserem Skript und der Website zu fungieren. Im Wesentlichen ruft es den HTML-Code ab, den wir benötigen, und spielt eine wichtige Rolle bei der Verknüpfung unserer Datenextraktionsbemühungen mit den Online-Bewertungen von Trustpilot.- bs4 (
Beautiful Soup): BeautifulSoup ist unsere Anlaufstelle für das Parsen von HTML. Es navigiert durch die komplexe Struktur der Webseiten von Trustpilot und ermöglicht es uns, die spezifischen Daten zu extrahieren, die wir benötigen – die Rezensionen, Bewertungen und Benutzerkommentare. Dieser leistungsstarke Parser vereinfacht das Durchsuchen komplexer Seitenstrukturen und ermöglicht es uns, aussagekräftige Daten effizient zu extrahieren.
Das Website-Layout von Trustpilot verstehen
Nachdem wir nun unsere Umgebung für das Scraping eingerichtet haben, wollen wir uns die Einrichtung der Website von Trustpilot genauer ansehen, um herauszufinden, wie die von uns benötigten Informationen auf der Website gespeichert werden.
Für unser Scraping ist es von entscheidender Bedeutung, das Layout der Website zu verstehen und die wichtigsten HTML-Elemente zu identifizieren, die die Bewertungsdaten enthalten. Wir müssen wichtige Details aus jeder Bewertung ermitteln und extrahieren, wie etwa Bewertungen, Kundenkommentare und Namen der Rezensenten.
Durch die Nutzung der Webseitenstruktur von Trustpilot wird unser Scraping-Prozess optimiert und sichergestellt, dass wir die wertvollen Erkenntnisse, die diese Bewertungen bieten, genau erfassen.
In diesem Artikel werfen wir einen Blick auf die Trustpilot-Rezensionsseite der Firma „Nookmart“, einer Online-Plattform, auf der Spieler des Spiels „Animal Crossing: New Horizons“ verschiedene In-Game-Gegenstände erwerben können.
So sieht die Seite auf Trustpilot aus:
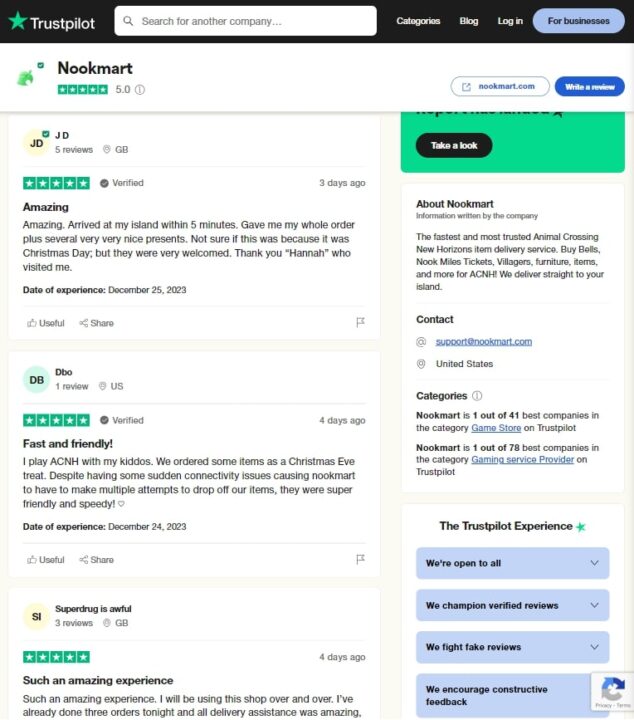
Wir werden jede einzelne Rezension durchsuchen, also müssen wir die HTML-Elemente finden, die die benötigten Daten enthalten. Dazu verwenden wir die Entwicklertools (klicken Sie mit der rechten Maustaste auf die Webseite und wählen Sie „Inspizieren“), um die HTML-Struktur zu untersuchen.
Das div Tag enthält die Informationen zu jeder einzelnen Bewertung: styles_reviewCardInner__EwDq2.
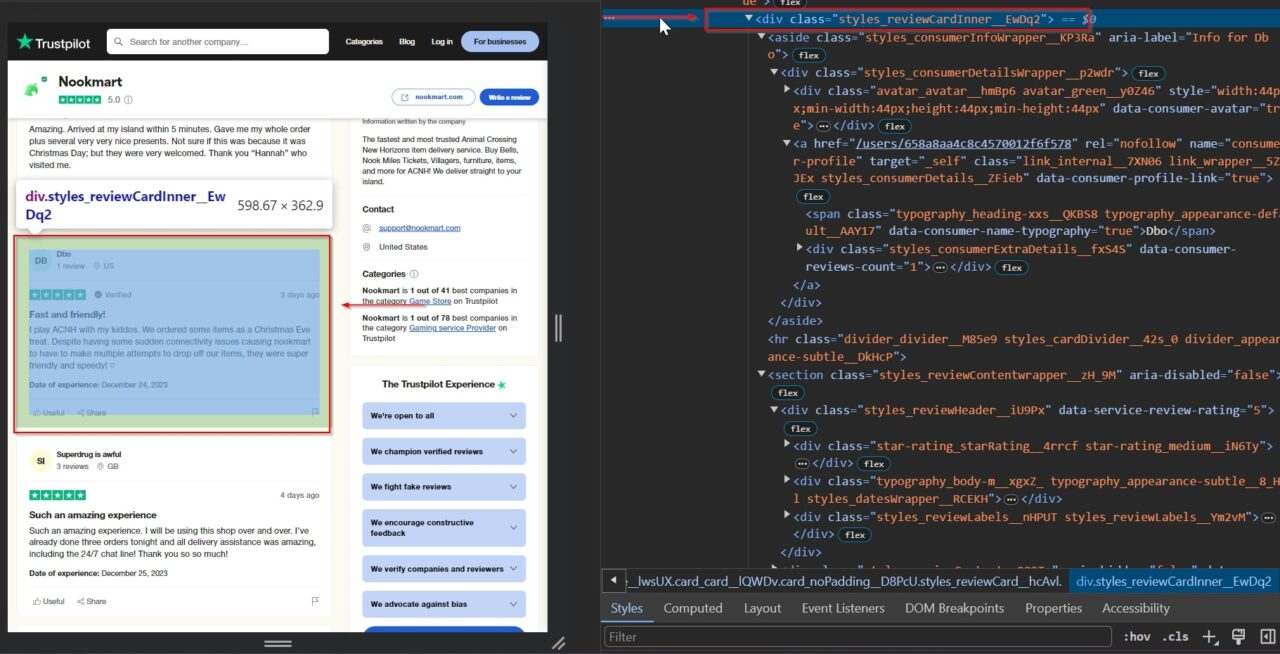
Das Extrahieren von Rezensentennamen aus Trustpilot hilft bei der Authentifizierung von Bewertungen, ermöglicht Trendanalysen aus wiederholtem Feedback und erleichtert die personalisierte Kundeneinbindung.
Darüber hinaus kann es auch demografische Einblicke bieten und beim Erstellen von Profilen für häufige Rezensenten helfen.
Das span Tag enthält den Namen des Rezensenten:
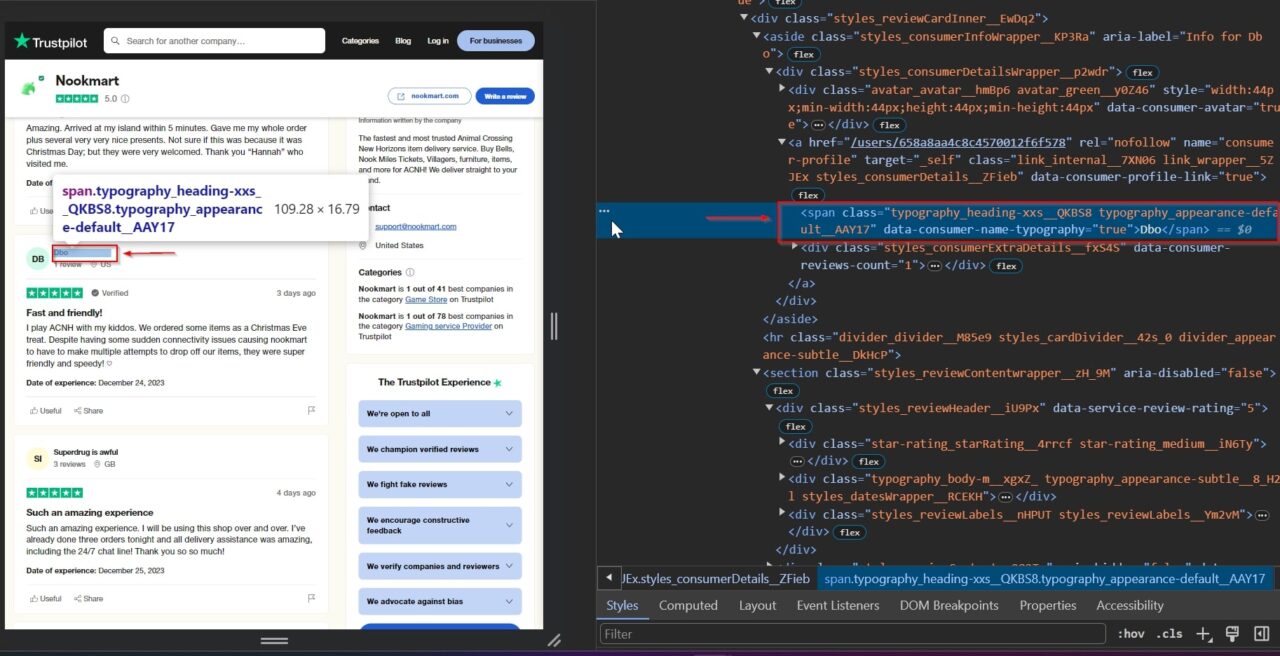
Wir werden auch die Bewertung des Rezensenten streichen. Die Bewertungen bieten ein direktes Maß für die Kundenzufriedenheit, das für die Beurteilung der Produkt- oder Servicequalität von entscheidender Bedeutung ist. Sie ermöglichen es Ihnen, die allgemeine Kundenstimmung einzuschätzen, Leistungstrends zu verfolgen und Vergleichsanalysen mit Wettbewerbern durchzuführen.
Die Analyse dieser Bewertungen kann wesentliche Bereiche für Verbesserungen aufzeigen und zur Verbesserung der Geschäftsangebote beitragen.
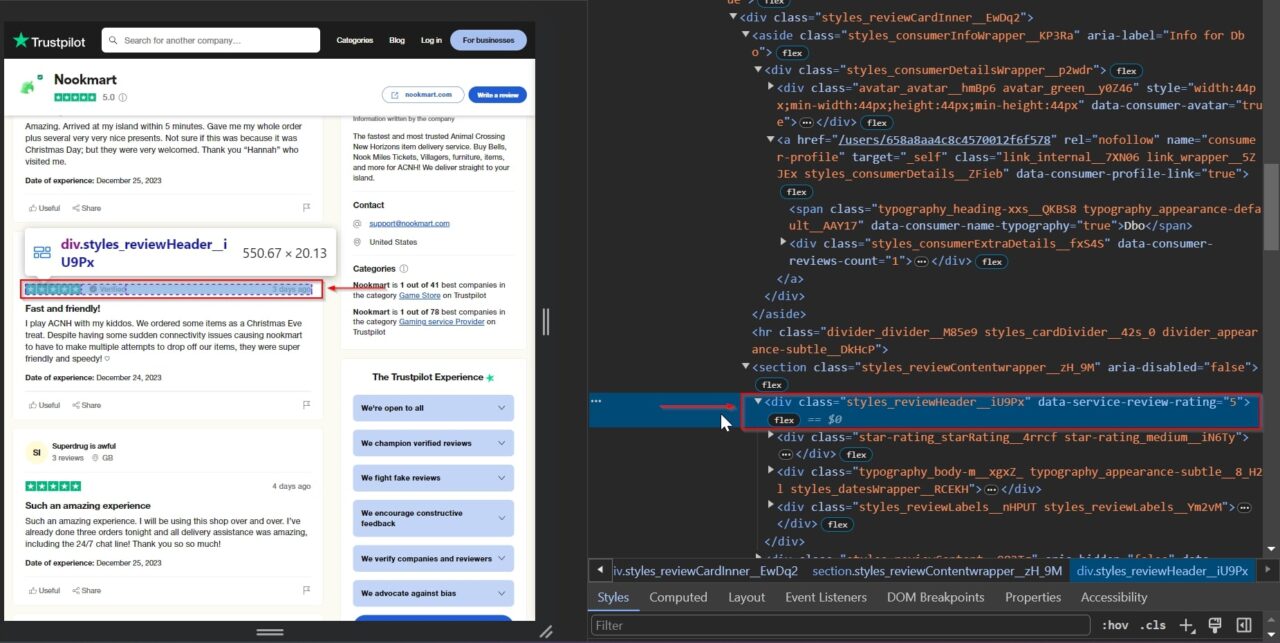
Dieses div-Tag enthält die Bewertung: styles_reviewHeader__iU9Px. Es wird in einem Attribut namens gespeichert data-service-review-rating.
Wir werden auch den eigentlichen Bewertungsinhalt extrahieren, was der Schlüssel zur Erschließung tieferer Kundeneinblicke ist. Dieser Inhalt ist von unschätzbarem Wert, um tiefere Einblicke in die Kundenzufriedenheit zu gewinnen, da er detailliertes Feedback enthält, das über reine Bewertungen hinausgeht.
Das Verständnis dieser Nuancen hilft dabei, gezielte Verbesserungen vorzunehmen, bessere Kundenbeziehungen zu fördern und letztendlich die Gesamtqualität Ihrer Angebote zu steigern.
Das p Tag enthält den eigentlichen Rezensionsinhalt: typography_body-l__KUYFJ
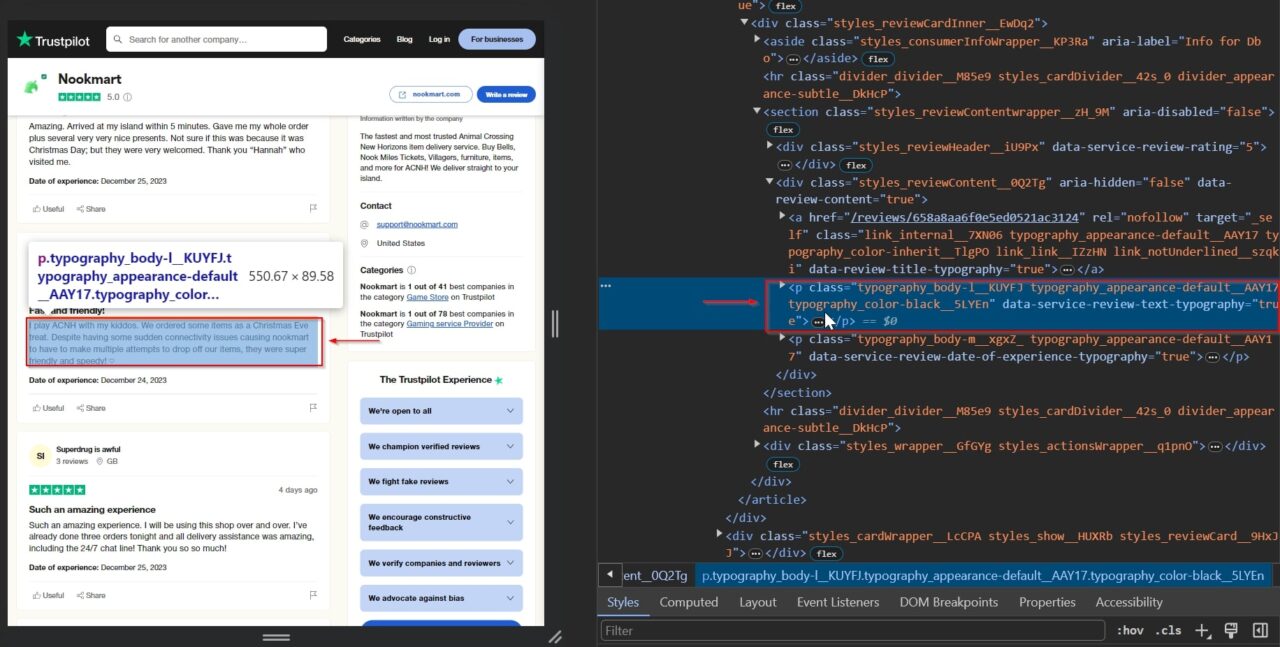
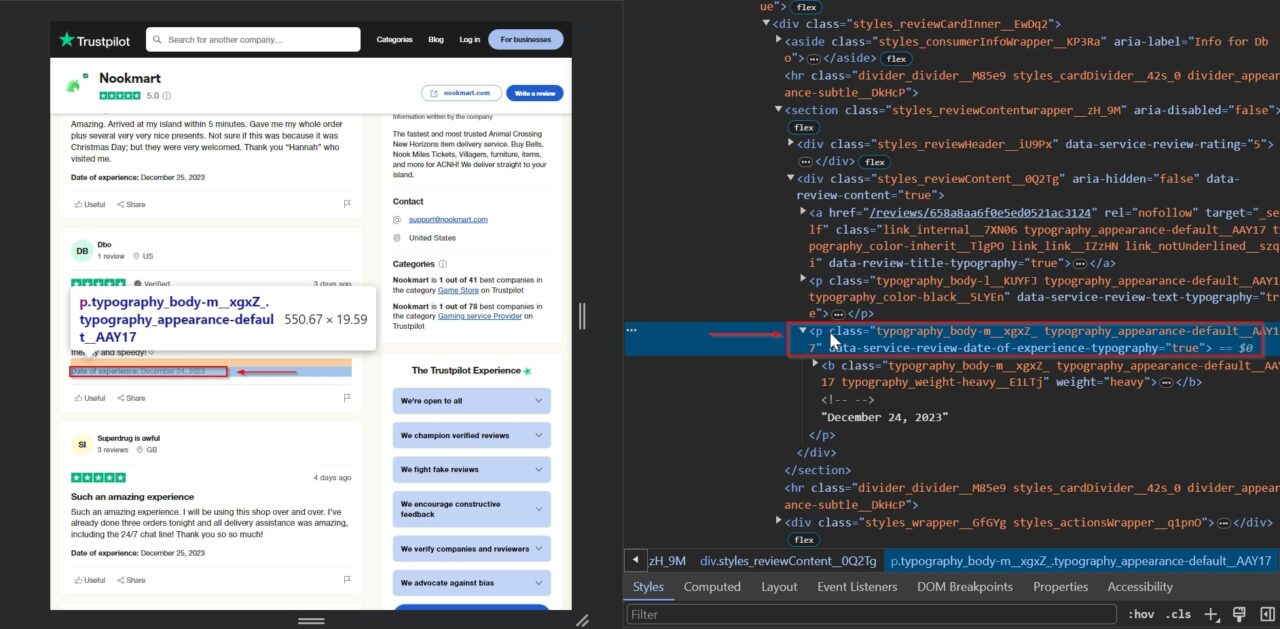
Abschließend streichen wir das Datum, an dem der Kunde erlebt hat, was er in der Bewertung beschreibt. Dies trägt dazu bei, der Bewertung einen Kontext zu geben und hilft uns zu verstehen, wann die beschriebene Erfahrung stattgefunden hat.
Das p Tag enthält das Datum der Erfahrung: typography_body-m__xgxZ_ typography_appearance-default__AAY17.
Jetzt können wir mit dem Schaben beginnen!
Scrapen Sie Trustpilot mit Python
Um Trustpilot-Bewertungen zu scannen, durchläuft unser Skript systematisch die Bewertungsseiten und sammelt wichtige Details wie Namen der Bewerter, Bewertungen, Inhalt der Bewertungen und das Datum der jeweiligen Erfahrung.
Dieser Ansatz gewährleistet einen optimierten und automatisierten Prozess, der es uns ermöglicht, einen umfassenden Datensatz an Kundenfeedbacks für eine eingehende Analyse zu sammeln.
Schritt 1: Bibliotheken importieren und Ziel-URL definieren
Wir beginnen mit dem Import der notwendigen Python-Bibliotheken – BeautifulSoup für HTML-Parsing, requests zum Stellen von HTTP-Anfragen und csv für Dateioperationen.
Wir definieren die Ziel-URL und verweisen auf die Trustpilot-Bewertungsseite von „nookmart.com“.
Der company Die Variable kann in jedes Unternehmen geändert werden, das Sie durchsuchen möchten.
from bs4 import BeautifulSoup
import requests
import csv
company = "nookmart.com"
base_url = f"https://www.trustpilot.com/review/{company}"
Schritt 2: Anforderungsparameter konfigurieren und Anforderung senden
Als Nächstes richten wir unser Skript so ein, dass es wie ein Browser mit dem Web interagiert. Dabei verwenden wir HTTP-Header und einen „User-Agent“, eine Zeichenfolge, die dem Server von Trustpilot mitteilt, welche Art von Browser wir verwenden.
Die Nutzlast, einschließlich unseres ScraperAPI-Schlüssels und der URL von Trustpilot, leitet ScraperAPI zur richtigen Seite. Wir ermöglichen auch das Rendern ganzer Seiten und stellen so sicher, dass dynamische Inhalte geladen werden.
headers = {
'User-Agent': 'Mozilla/5.0 ...',
'accept-language': 'en-US,en;q=0.9'
}
payload = {
'api_key': "YOUR_API_KEY",
'url': base_url,
'render': 'true',
'keep_headers': 'true',
}
Als nächstes senden wir unsere Anfrage an ScraperAPI; ScraperAPI greift dann in unserem Namen auf die Seite von Trustpilot zu, übernimmt mögliche Anti-Bot-Maßnahmen und ruft den HTML-Inhalt der Website ab, den unser Skript dann verarbeiten kann. Dieses Setup ist der Schlüssel zum erfolgreichen Scraping von Daten von Websites mit Anti-Scraping-Technologien.
response = requests.get('https://api.scraperapi.com', params=payload, headers=headers)
Schritt 3: Trustpilot mit BeautifulSoup analysieren
Wir verwenden BeautifulSoup, um den von Trustpilot erhaltenen HTML-Inhalt zu analysieren. Dies hilft uns dabei, die Webseitenstruktur für eine einfache Datenextraktion aufzuschlüsseln – was sehr wichtig ist, weil es uns ermöglicht, die Bewertungen herauszuholen und zu analysieren.
soup = BeautifulSoup(response.content, 'html.parser')
Schritt 4: Speichern Sie Trustpilot-Bewertungen in einer CSV-Datei
Nach dem Parsen öffnen wir eine CSV-Datei mit dem Namen 'trustpilot_reviews.csv' zum Schreiben. Anschließend bereiten wir Spaltenüberschriften vor, in denen die Namen der Rezensenten, Bewertungen, Rezensionsinhalte – einschließlich negativer Rezensionen – und das Datum der Rezension gespeichert werden.
with open('trustpilot_reviews.csv', 'w', newline='', encoding='utf-8') as csvfile:
csv_writer = csv.writer(csvfile)
csv_writer.writerow(('Reviewer', 'Rating', 'Review', 'Date'))
Schritt 5: Gehen Sie die Paginierung von Trustpilot durch und extrahieren Sie die Bewertungen
Jetzt kommen wir zum Kern unseres Schabeprozesses. Wir durchgehen 10 Seiten Trustpilot-Bewertungen für „Nookmart“.
Auf jeder Seite senden wir eine Anfrage und extrahieren dann wichtige Informationen aus jeder vorhandenen Bewertung mithilfe der zuvor identifizierten HTML-Elemente.
Für jede gefundene Bewertung schreiben wir diese Details in unser trustpilot_reviews.csv Datei, um sicherzustellen, dass die Daten ordentlich organisiert und für jede spätere Analyse bereit sind.
Durch die Verarbeitung mehrerer Seiten erstellen wir einen umfangreichen Datensatz, der ein breites Spektrum an Kundenerfahrungen und -meinungen darstellt und ein umfassendes Verständnis der Dienstleistungen des Unternehmens aus der Sicht seiner Kunden vermittelt.
for page in range(1, pages_to_scrape):
payload('url') = f"{base_url}?page={page}"
page_response = requests.get('https://api.scraperapi.com', params=payload, headers=headers)
page_soup = BeautifulSoup(page_response.content, 'html.parser')
reviews = page_soup.find_all('div', {"class": "styles_reviewCardInner__EwDq2"})
for review in reviews:
reviewer = review.find("span", attrs={"class": "typography_heading-xxs__QKBS8"}).text
rating = review.find("div", attrs={"class": "styles_reviewHeader__iU9Px"})("data-service-review-rating")
content_element = review.find("p", attrs={"class": "typography_body-l__KUYFJ"})
content = content_element.text if content_element else 'None'
date = review.find("p", attrs={"class":"typography_body-m__xgxZ_ typography_appearance-default__AAY17"}).text
csv_writer.writerow((reviewer, rating, content, date))
Auf diese Weise stellen wir sicher, dass wir uns nicht nur auf die Bewertungen auf der ersten Seite beschränken, sondern bereichern unsere Analyse mit verschiedenen Erkenntnissen aus einem größeren Pool an Kundenbewertungen.
