
In diesem Artikel führen wir Sie durch eine Schritt-für-Schritt-Anleitung zum Scrapen von Realtor.com-Daten mit Python (zum Schreiben unseres Skripts) und der Standard-API von ScraperAPI, um eine Blockierung zu vermeiden.
TL;DR: Vollständiger Realtor.com-Scraper
Für diejenigen, die es eilig haben, ist hier das vollständige Skript, das wir in diesem Tutorial erstellen werden:
import requests
from bs4 import BeautifulSoup
import json
output_data = ()
base_url = "https://www.realtor.com/realestateandhomes-search/Atlanta_GA/show-newest-listings/sby-6"
API_KEY = "API_KEY"
def scrape_listing(num_pages):
for page in range(1, num_pages + 1):
# To scrape page 1
if page == 1:
url = f"{base_url}"
else:
url = (
f"{base_url}/pg-{page}" # Adjust the URL structure based on the website
)
print(f"Scraping data from page {page}... {url}")
payload = {"api_key": API_KEY, "url": url}
# Make a request to the ScraperAPI
r = requests.get("http://api.scraperapi.com", params=payload)
html_response = r.text
# Parse the HTML response using BeautifulSoup
soup = BeautifulSoup(html_response, "lxml")
# scraping individual page
listings = soup.select("div(class^='BasePropertyCard_propertyCardWrap__')")
print("Listings found!")
for listing in listings:
price = listing.find("div", class_="card-price")
price = price.get_text(strip=True) if price else "nil"
full_address = listing.find("div", class_="card-address")
full_address = full_address.get_text(strip=True) if full_address else "nil"
address_parts = full_address.split(", ")
address = address_parts(0) if address_parts else "nil"
township = address_parts(1) if len(address_parts) > 1 else "nil"
property_url_elements = listing.select("a(class^='LinkComponent_anchor__')")
property_url = "nil" # Default value if property_url_elements is empty
for element in property_url_elements:
property_url = "https://www.realtor.com" + element("href")
break
beds = listing.find(
"li",
class_="PropertyBedMetastyles__StyledPropertyBedMeta-rui__a4nnof-0",
)
beds = (
beds.find("span", {"data-testid": "meta-value"}).text.strip()
if beds
else "nil"
)
baths = listing.find(
"li",
class_="PropertyBathMetastyles__StyledPropertyBathMeta-rui__sc-67m6bo-0",
)
baths = baths.find("span").text.strip() if baths else "nil"
sqft = listing.find(
"li",
class_="PropertySqftMetastyles__StyledPropertySqftMeta-rui__sc-1gdau7i-0",
)
sqft = (
sqft.find("span", {"data-testid": "screen-reader-value"}).text.strip()
if sqft
else "nil"
)
plot_size = listing.find(
"li",
class_="PropertyLotSizeMetastyles__StyledPropertyLotSizeMeta-rui__sc-1cz4zco-0",
)
plot_size = (
plot_size.find(
"span", {"data-testid": "screen-reader-value"}
).text.strip()
if plot_size
else "nil"
)
property_data = {
"price": price,
"address": address,
"township": township,
"url": property_url,
"beds": beds,
"baths": baths,
"square_footage": sqft,
"plot_size": plot_size,
}
output_data.append(property_data)
num_pages = 5 # Set the desired number of pages
# Scrape data from multiple pages
scrape_listing(num_pages)
# our property count
output_data.append({"num_hits": len(output_data)})
# Write the output to a JSON file
with open("Realtor_data.json", "w") as json_file:
json.dump(output_data, json_file, indent=2)
print("Output written to output.json")
Notiz: Ersatz API_KEY Geben Sie im Code Ihren tatsächlichen API-Schlüssel ein, bevor Sie das Skript ausführen.
Möchten Sie erfahren, wie wir es gebaut haben? Lesen Sie weiter, um eine Schritt-für-Schritt-Erklärung zu erhalten.
Scraping der Produktdaten von Realtor.com
Bevor Sie mit dem Scraping beginnen, müssen Sie unbedingt festlegen, welche spezifischen Informationen Sie aus der Webseite extrahieren möchten. In diesem Tutorial konzentrieren wir uns auf die folgenden Details:
- Verkaufspreis der Immobilie
- Immobilien-Adresse
- URL des Immobilieneintrags
- Anzahl der Betten und Bäder
- Grundstücksfläche
- Grundstücksgröße
Voraussetzungen
Die Hauptvoraussetzungen für dieses Tutorial sind die Bibliotheken Python, Requests, BeautifulSoup und Lxml. Führen Sie diesen Befehl aus, um die entsprechende Installation durchzuführen.
pip install beautifulsoup4 requests lxml
Schritt 1: Einrichten Ihres Projekts
Notiz: Bevor Sie beginnen, stellen Sie sicher, dass Sie sich für ein kostenloses ScraperAPI-Konto anmelden, um Ihren API-Schlüssel zu erhalten.
Zuerst importieren wir die notwendigen Python-Bibliotheken oben in unserem .py Datei.
import requests
from bs4 import BeautifulSoup
import json
Anschließend initialisieren wir die Variablen, die wir in unserem Skript verwenden.
output_data = ()
base_url = "https://www.realtor.com/realestateandhomes-search/Atlanta_GA/show-newest-listings/sby-6"
API_KEY = "YOUR_API_KEY"
output_dataspeichert die Datenbase_urlist die URL der Realtor.com-Seite, die wir durchsuchen möchten – zumindest die ursprüngliche URL – die Sie erhalten können, indem Sie zur Website navigieren und eine Suche durchführenAPI_KEYenthält unseren ScraperAPI-Schlüssel als Zeichenfolge
Schritt 2: Definieren Sie Ihre Scraping-Funktion
Wir definieren eine Funktion, scrape_listing()das die Anzahl der zu scannenden Seiten als Argument verwendet, sodass wir mehrere Seiten scrapen können.
def scrape_listing(num_pages):
for page in range(1, num_pages + 1):
# To scrape page 1
if page == 1:
url = f"{base_url}"
else:
url = f"{base_url}/pg-{page}" # Adjust the URL structure based on the website
print(f"Scraping data from page {page}... {url}")
payload = {"api_key": API_KEY, "url": url}
# Make a request to the ScraperAPI
r = requests.get("http://api.scraperapi.com", params=payload)
html_response = r.text
soup = BeautifulSoup(html_response, "lxml")
Wir durchlaufen jede Seite, erstellen die URL für die Seite, stellen eine GET-Anfrage an ScraperAPI und zaubern ein BeautifulSoup-Objekt für jede Seite.
Notiz: Wir müssen unsere Anfragen über ScraperAPI senden, um zu verhindern, dass unsere IP gesperrt wird, sodass wir Daten in großem Umfang sammeln können.
Schritt 3: HTML-Antwort analysieren
Indem wir die HTML-Antwort mit BeautifulSoup analysieren, können wir den rohen HTML-Code in einen analysierten Baum umwandeln, in dem wir mithilfe von CSS-Selektoren navigieren können.
Wenn wir uns die Seite ansehen, können wir sehen, dass jeder Eintrag in einer Karte verpackt ist (div) mit dem BasePropertyCard_propertyCardWrap__ Klasse.
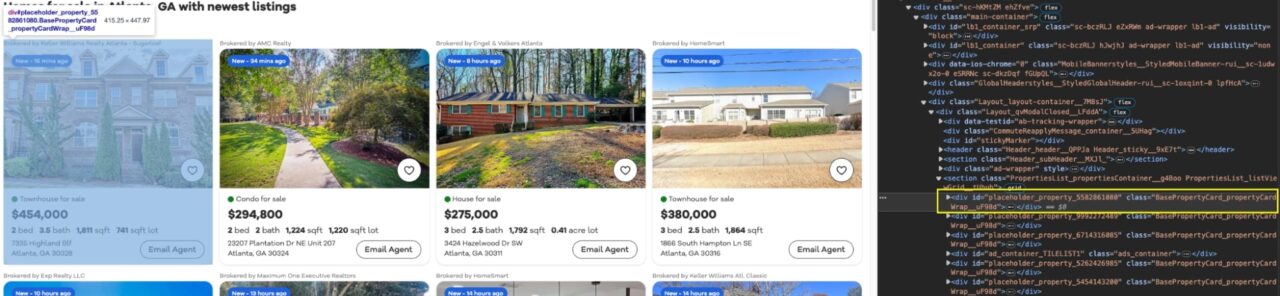
Mit dieser Klasse können wir jetzt alle Eigenschaften speichern listings in eine Auflistungsvariable.
# Parse the HTML response using BeautifulSoup
soup = BeautifulSoup(html_response, "lxml")
# scraping individual page
listings = soup.select("div(class^='BasePropertyCard_propertyCardWrap__')")
print("Listings found!")
Wir geben eine Erfolgsmeldung an die Konsole aus, um während der Ausführung unseres Codes Feedback zu erhalten.
Schritt 4: Immobiliendaten extrahieren
Für jedes gefundene Inserat extrahieren wir die Immobiliendaten wie Preis, Adresse, URL, Anzahl der Schlafzimmer, Badezimmer, Quadratmeterzahl und Grundstücksgröße.
Um die Preise für jedes Angebot zu extrahieren, verwenden wir den Selektor div(class^='card-price'). Dieser Selektor zielt auf die div Elemente, deren Klasse mit beginnt card-price. Diese Divs enthalten den Preis der Immobilie.

price = listing.find("div", class_="card-price")
price = price.get_text(strip=True) if price else "nil"
Um die Adresse aus der Immobilienliste zu extrahieren, verwenden wir den Selektor div(class^='card-address'). Diese Divs enthalten die Adresse der Immobilie.

full_address = listing.find("div", class_="card-address")
full_address = full_address.get_text(strip=True) if full_address else "nil"
address_parts = full_address.split(", ")
address = address_parts(0) if address_parts else "nil"
township = address_parts(1) if len(address_parts) > 1 else "nil"
Um weitere Details zum Immobilieneintrag zu extrahieren, gehen wir ein paar durch li Elemente, die die Selektoren enthalten PropertyBedMetastyles__StyledPropertyBedMeta-rui__a4nnof-0 Und PropertySqftMetastyles__StyledPropertySqftMeta-rui__sc-1gdau7i-0.

Die Anzahl der Betten und Bäder sowie die Quadratmeterzahl jeder aufgelisteten Immobilie finden Sie in diesen CSS-Selektoren.
for listing in listings:
price = listing.find("div", class_="card-price")
price = price.get_text(strip=True) if price else "nil"
full_address = listing.find("div", class_="card-address")
full_address = full_address.get_text(strip=True) if full_address else "nil"
address_parts = full_address.split(", ")
address = address_parts(0) if address_parts else "nil"
township = address_parts(1) if len(address_parts) > 1 else "nil"
property_url_elements = listing.select("a(class^='LinkComponent_anchor__')")
property_url = "nil" # Default value if property_url_elements is empty
for element in property_url_elements:
property_url = "https://www.realtor.com" + element("href")
break
beds = listing.find(
"li",
class_="PropertyBedMetastyles__StyledPropertyBedMeta-rui__a4nnof-0",
)
beds = (
beds.find("span", {"data-testid": "meta-value"}).text.strip()
if beds
else "nil"
)
baths = listing.find(
"li",
class_="PropertyBathMetastyles__StyledPropertyBathMeta-rui__sc-67m6bo-0",
)
baths = baths.find("span").text.strip() if baths else "nil"
sqft = listing.find(
"li",
class_="PropertySqftMetastyles__StyledPropertySqftMeta-rui__sc-1gdau7i-0",
)
sqft = (
sqft.find("span", {"data-testid": "screen-reader-value"}).text.strip()
if sqft
else "nil"
)
plot_size = listing.find(
"li",
class_="PropertyLotSizeMetastyles__StyledPropertyLotSizeMeta-rui__sc-1cz4zco-0",
)
plot_size = (
plot_size.find(
"span", {"data-testid": "screen-reader-value"}
).text.strip()
if plot_size
else "nil"
)
property_data = {
"price": price,
"address": address,
"township": township,
"url": property_url,
"beds": beds,
"baths": baths,
"square_footage": sqft,
"plot_size": plot_size,
}
output_data.append(property_data)
Diese Daten werden in einem Wörterbuch gespeichert und angehängt output_data Liste. Jedes Datenelement wird mithilfe von extrahiert .find() -Methode und den entsprechenden CSS-Selektor.
Schritt 5: Daten von mehreren Seiten extrahieren
Wir nennen das scrape_listing() Funktion zum Scrapen von Daten aus der gewünschten Anzahl von Seiten. Fühlen Sie sich frei, das zu ändern num_pages Variable, um bei Bedarf Daten von mehreren Seiten zu extrahieren.
num_pages = 5 # Set the desired number of pages
# Scrape data from multiple pages
scrape_listing(num_pages)
