
Schritt 3: Analysieren Sie den HTML-Code
Das Parsen des HTML-Codes mit BeautifulSoup ermöglicht es uns, mit einer einfacheren, verschachtelten BeautifulSoup-Datenstruktur anstelle von reinem HTML zu arbeiten, was die Navigation in der Seitenstruktur erleichtert.
soup = BeautifulSoup(html_response, "lxml")
Bevor wir jedoch durch den analysierten Baum navigieren, müssen wir verstehen, wie wir auf unsere gewünschten Elemente abzielen.
Schritt 4: Die Website-Struktur von Macy's verstehen
Bei der Suche nach unserer Zielabfrage liefert die Website von Macy’s ähnliche Ergebnisse wie die unten gezeigten:
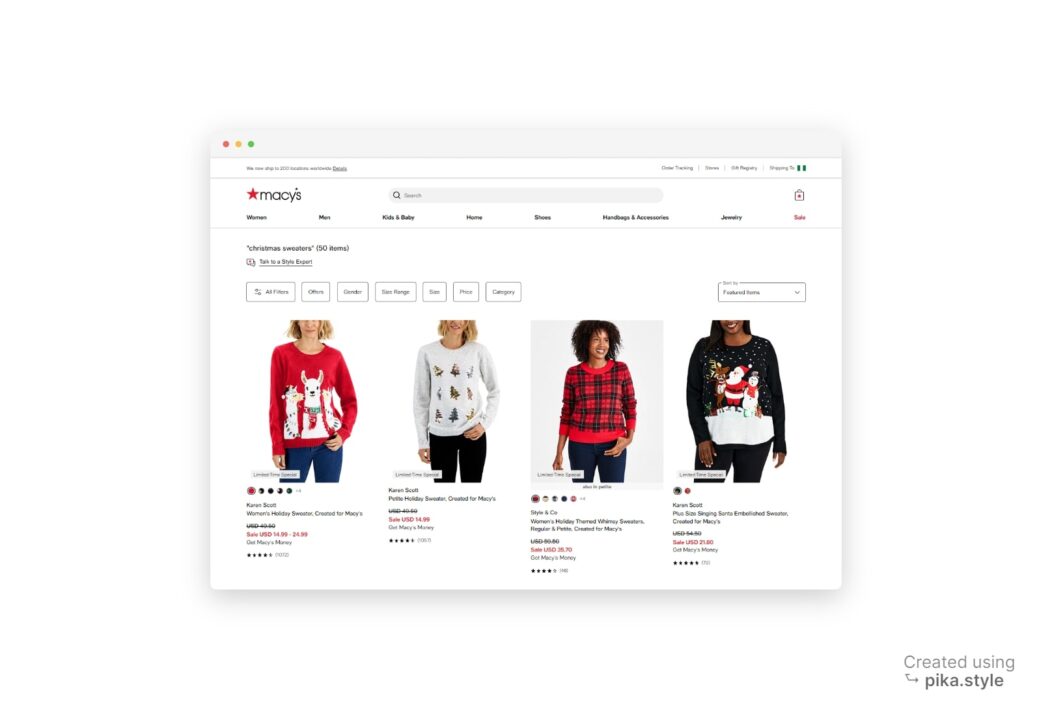
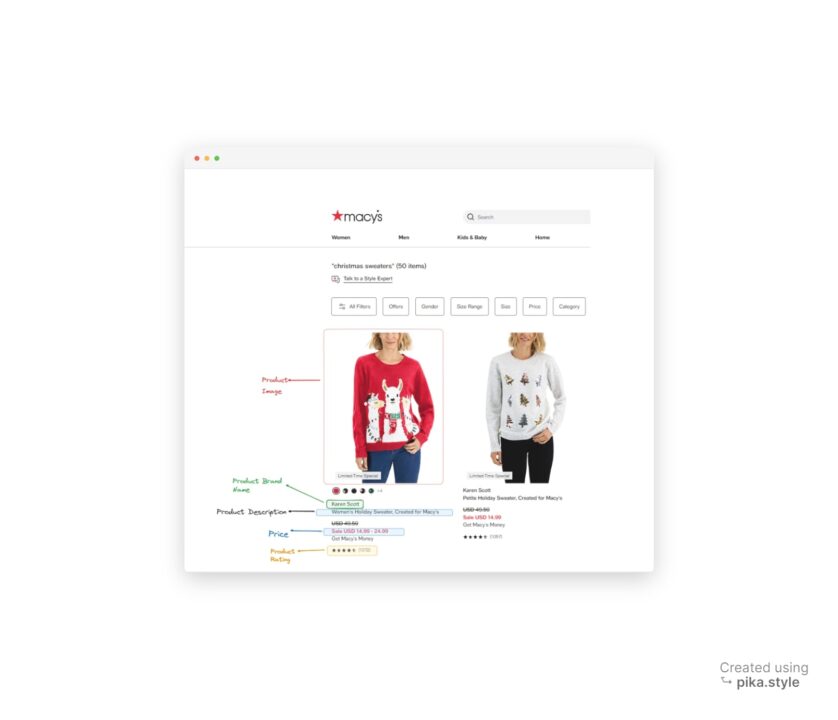
Alle unter „Weihnachtspullover” können extrahiert werden, einschließlich ihrer Markennamen, Preise, Beschreibungen, Bewertungen, Bilder und Produktlinks, wie im kommentierten Screenshot unten zu sehen ist.
Es ist sehr wichtig, das HTML-Layout einer Seite zu verstehen. Dank der Entwicklertools, einer Funktion, die in den meisten gängigen Webbrowsern verfügbar ist, müssen Sie jedoch kein HTML-Experte sein.
Um auf die Entwicklertools zuzugreifen, können Sie mit der rechten Maustaste auf die Webseite klicken und „Prüfen” oder verwenden Sie die Verknüpfung „STRG+UMSCHALT+I” für Windows-Benutzer oder „Option + ⌘ + I” auf dem Mac. Dadurch wird der Quellcode der Webseite geöffnet, auf die wir abzielen.
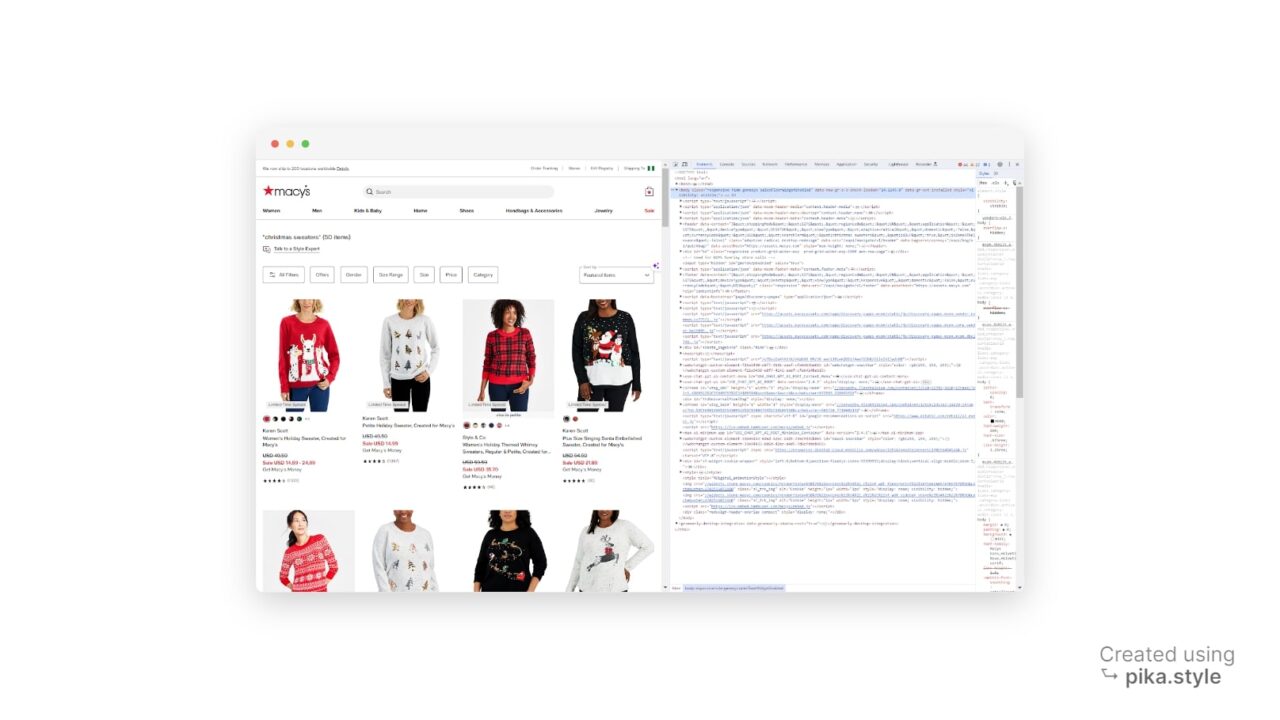
Wie oben zu sehen ist, werden alle Produkte als Elemente aufgeführt, daher müssen wir alle diese Auflistungen sammeln.
Um ein HTML-Element zu scrapen, benötigen wir eine damit verknüpfte Kennung. Dies könnte das „Ausweis” des Elements, ein beliebiger Klassenname oder ein beliebiges anderes HTML-Attribut des Elements. In unserem Fall verwenden wir den Klassennamen als Bezeichner.
Nach Durchsicht der Suchergebnisseite stellen wir fest, dass es sich bei jedem Produktcontainer um einen handelt div Element mit der Klasse productThumbnail.
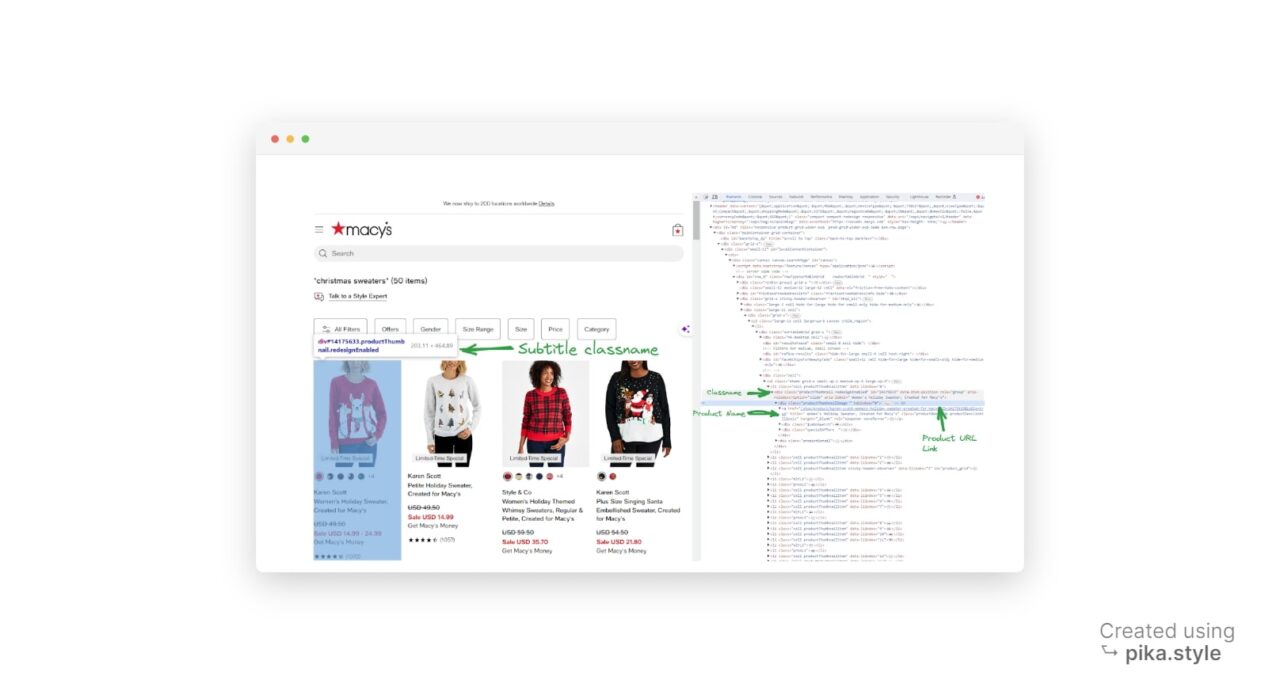
Wir können dieses HTML-Element mithilfe von BeautifulSoup abrufen
find_all() Funktion zum Finden aller Instanzen von a div mit der Klasse productThumbnail.
product_containers = soup.find_all("div", class_="productThumbnail")
Jedes von diesen div Elemente stellt einen Produktcontainer auf der Webseite dar.
Wir können dem gleichen Prozess folgen, um den Klassennamen für jedes Element zu finden, das wir durchsuchen möchten.
Schritt 5: Extrahieren Sie die Produktdaten
Um die notwendigen Daten zu extrahieren, müssen wir jeden Produktcontainer mit a durchlaufen for Schleife und mit der select_one() Und
find() Funktionen, die das erste passende Element zurückgeben:
product_data_list = ()
for product_container in product_containers:
# Extract brand
brand_element = product_container.select_one(".productBrand")
brand_name = brand_element.text.strip() if brand_element else None
# Extract price
price_element = product_container.select_one(".prices .regular")
price = price_element.text.strip() if price_element else None
# Extract description
description_element = product_container.select_one(".productDescription .productDescLink")
description = description_element("title").strip() if description_element else None
# Extract rating
rating_element = product_container.select_one(".stars")
rating = rating_element("aria-label") if rating_element else None
# Extract image URL
image_element = product_container.find("img", class_="thumbnailImage")
image_url = image_element("src") if image_element and "src" in image_element.attrs else None```
Nach dem Extrahieren der Daten erstellen wir ein Wörterbuch und hängen es an eine Liste mit dem Namen an product_data.
product_data = {
"Product Brand Name": brand_name,
"Price": price,
"Description": description,
"Rating": rating,
"Image URL": image_url,
"Product URL": product_url,
}
# Append the product data to the list
product_data_list.append(product_data)
Der text.strip() Die Funktion extrahiert den Textinhalt des Elements und entfernt alle führenden oder nachgestellten Leerzeichen.
Schritt 6: Schreiben Sie die Ergebnisse in eine JSON-Datei
Schließlich speichern wir die gescrapten Daten in einer JSON-Datei, indem wir eine Datei im Schreibmodus öffnen (mit „w' als zweites Argument zu open()) und mit der json.dump() Funktion zum Schreiben der Produktdatenliste in die Datei:
output_file = "Macy_product_results.json"
with open(output_file, "w", encoding="utf-8") as json_file:
json.dump(product_data_list, json_file, indent=2)
print(f"Scraped data has been saved to {output_file}")
Als Rückmeldung geben wir nach dem Erstellen der Datei eine Erfolgsmeldung an die Konsole aus.
Herzlichen Glückwunsch, Sie haben gerade die Produktdaten von Macy's gelöscht!
Hier ist eine Vorschau der Ausgabe des Scrapers, wie im zu sehen
Macy_product_results.json Datei:
{
"Product Brand Name": "Karen Scott",
"Price": "$49.50",
"Description": "Women's Holiday Sweater, Created for Macy's",
"Rating": "4.4235 out of 5 rating with 1072 reviews",
"Image URL": "https://slimages.macysassets.com/is/image/MCY/products/1/optimized/26374821_fpx.tif?$browse$&wid=224&fmt=jpeg",
"Product URL": "/shop/product/karen-scott-womens-holiday-sweater-created-for-macys?ID=14175633&isDlp=true"
},
{
"Product Brand Name": "Style & Co",
"Price": "$59.50",
"Description": "Women's Holiday Themed Whimsy Sweaters, Regular & Petite, Created for Macy's",
"Rating": "4.2391 out of 5 rating with 46 reviews",
"Image URL": "https://slimages.macysassets.com/is/image/MCY/products/0/optimized/24729680_fpx.tif?$browse$&wid=224&fmt=jpeg",
"Product URL": "/shop/product/style-co-womens-holiday-themed-whimsy-sweaters-regular-petite-created-for-macys?ID=16001406&isDlp=true"
},
{
"Product Brand Name": "Charter Club",
"Price": "$59.50",
"Description": "Holiday Lane Women's Festive Fair Isle Snowflake Sweater, Created for Macy's",
"Rating": "4.8571 out of 5 rating with 7 reviews",
"Image URL": "https://slimages.macysassets.com/is/image/MCY/products/2/optimized/23995392_fpx.tif?$browse$&wid=224&fmt=jpeg",
"Product URL": "/shop/product/holiday-lane-womens-festive-fair-isle-snowflake-sweater-created-for-macys?ID=15889755&isDlp=true"
}, … More JSON Data,
Zusammenfassung
In diesem Tutorial haben wir Folgendes behandelt:
- Umgehen Sie die Anti-Scraping-Mechanismen von Macy mit ScraperAPI
- Navigieren Sie mit BeautifulSoup durch die Website-Struktur von Macy
- Extrahieren Sie Produktlisten in eine JSON-Datei
Ich hoffe, Ihnen gefällt dieser Leitfaden. Gerne können Sie dieses Skript in Ihrem Projekt verwenden. Wenn Sie Fragen haben, wenden Sie sich bitte an unser Support-Team. Wir helfen Ihnen gerne weiter.
Benötigen Sie mehr als 3M API-Credits?
Kontaktieren Sie unser Vertriebsteam, um die beste Lösung für Ihr Projekt zu entwickeln.
