
Wie kann man eBay mit Python durchsuchen?
Python zeichnet sich aufgrund seiner Benutzerfreundlichkeit, einfachen Syntax und der großen Auswahl an verfügbaren Bibliotheken als eine der besten Sprachen für Web Scraping aus.
Um eBay mit Python zu crawlen, verwenden wir die Requests-Bibliothek und BeautifulSoup für die HTML-Analyse. Darüber hinaus senden wir unsere Anfragen über ScraperAPI, um Anti-Scraping-Maßnahmen zu vermeiden.
Voraussetzungen
Dieses Tutorial basiert auf Python 3.10aber es sollte mit jeder Python-Version ab funktionieren 3.8. Stellen Sie sicher, dass Sie eine kompatible Python-Version installiert haben, bevor Sie fortfahren.
Lassen Sie uns nun ein Python-Projekt in einer virtuellen Umgebung namens „ebay-scraper“ initiieren. Führen Sie die folgenden Befehle nacheinander aus, um Ihre Projektstruktur einzurichten:
mkdir ebay-scraper
cd ebay-scraper
python -m venv env
Zum besseren Verständnis geschieht Folgendes in jeder Zeile der oben aufgeführten Befehle:
- Zunächst wird ein Verzeichnis mit dem Namen „ebay–scrapper“ erstellt.
- Anschließend wechselt Ihr Terminal in das tatsächliche Verzeichnis, in dem Sie gerade erstellen
- Schließlich erstellt t lokal die virtuelle Python-Umgebung für das Projekt
Geben Sie den Projektordner ein und fügen Sie einen hinzu main.py-Datei. Diese Datei würde bald die Logik zum Scrapen von eBay enthalten.
Sie müssen außerdem die folgenden Python-Bibliotheken installieren:
- Anfragen: Diese Bibliothek gilt weithin als die beliebteste HTTP-Client-Bibliothek für Python. Es vereinfacht das Senden von HTTP-Anfragen und die Bearbeitung von Antworten, sodass Sie die Suchergebnisseiten von eBay herunterladen können.
- Schöne Suppe: Dies ist eine umfassende Python-HTML- und XML-Parsing-Bibliothek. Es hilft, durch die Struktur der Webseite zu navigieren und die notwendigen Daten zu extrahieren.
- lxml: Diese Bibliothek ist für ihre Geschwindigkeit und funktionsreichen Funktionen zur Verarbeitung von XML und HTML in Python bekannt.
Sie können diese Bibliotheken ganz einfach zusammen mit dem Python Package Installer (PIP) installieren:
pip install requests beautifulsoup4 lxml
Wenn diese Voraussetzungen erfüllt sind, können Sie mit dem nächsten Schritt fortfahren!
Grundlegendes zur Struktur der eBay-Suchergebnisseite
Wenn Sie nach einem bestimmten Begriff wie „Airpods Pro“ suchen, zeigt eBay Ergebnisse ähnlich der folgenden Seite an:
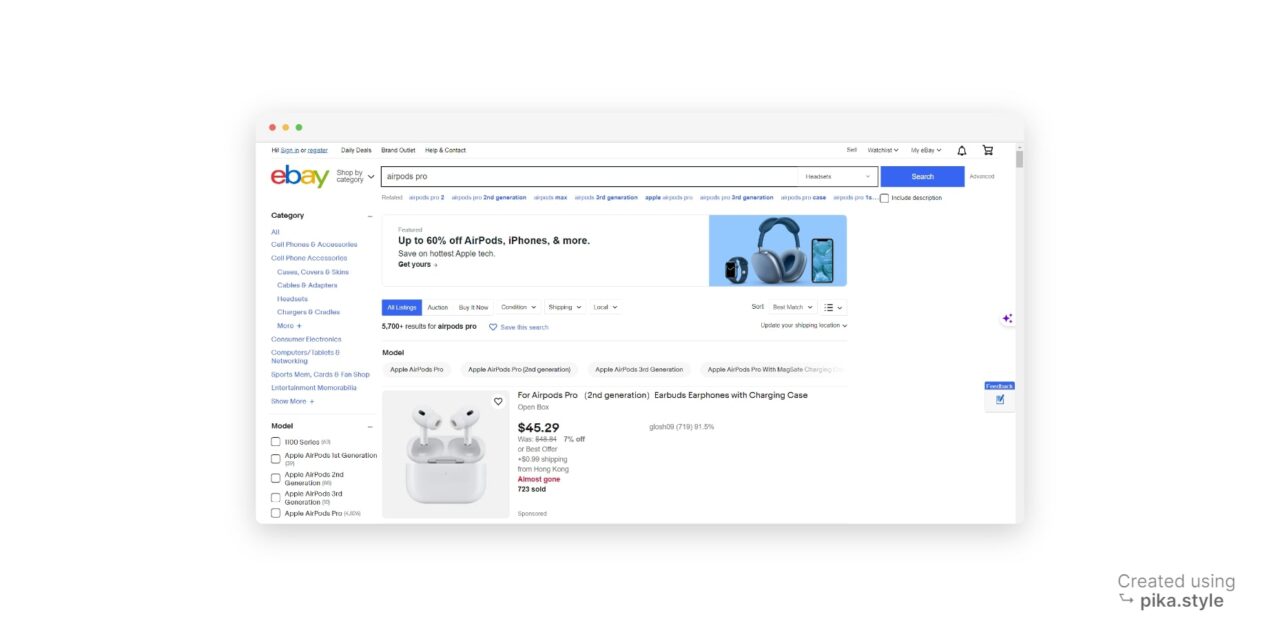
Alle unter „airpods pro“ aufgeführten Produkte können extrahiert werden, ebenso deren Links, Titel, Preise, Bewertungen und Bilder.
Bevor Sie mit dem Schreiben Ihres Skripts beginnen, müssen Sie unbedingt festlegen, welche Daten Sie sammeln möchten. Bei diesem Projekt konzentrieren wir uns auf die Extraktion der folgenden Produktdetails:
- Produktname
- Preis
- Produktbild
- Eine kurze Produktbeschreibung
- Die Produkt-URL
Im Screenshot unten sehen Sie, wo diese Attribute zu finden sind:

Nachdem wir nun wissen, an welchen Informationen wir interessiert sind und wo wir sie finden können, ist es an der Zeit, unseren Scraper zu erstellen.
Schritt 1: Einrichten unseres Projekts
Öffnen Sie Ihren Code-Editor und fügen Sie die folgenden Codezeilen hinzu, um unsere Abhängigkeiten zu importieren:
import requests
from bs4 import BeautifulSoup
import csv
Notiz: Wir haben auch die CSV-Bibliothek importiert, da wir unsere Daten in diesem Format exportieren möchten.
Als Nächstes müssen wir die URL der eBay-Seite einrichten, die wir durchsuchen möchten. In diesem Beispiel suchen wir nach „Airpods Pro„. Ihre URL sollte so aussehen:
url = "https://www.ebay.com/sch/i.html?_from=R40&_trksid=p4432023.m570.l1312&_nkw=airpods+pro&_sacat=0"
Schritt 2: Senden Sie die Anfrage und analysieren Sie den HTML-Code
Jetzt senden wir eine ERHALTEN Anfrage an die eBay-Seite senden und den HTML-Code mit BeautifulSoup analysieren.
html = requests.get(url)
print(html.text)
Dieser Code verwendet die requests Bibliothek, um eine „GET-Anfrage“ an unsere eBay-Suchergebnisseite zu senden, den HTML-Inhalt der Webseite abzurufen und ihn in der zu speichern html Variable.
Sobald Sie diesen Code jedoch ausführen, werden Sie feststellen, dass eBay einige Anti-Bot-Maßnahmen ergriffen hat.
Sie können diese Anti-Bot-Maßnahme umgehen, indem Sie als Teil der Anfrage einen richtigen User-Agent-Header senden, um einen Webbrowser nachzuahmen:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Accept-Language": "en-US, en;q=0.5",
}
html = requests.get(url, headers=headers)
soup = BeautifulSoup(html.text, "lxml")
Um den HTML-Inhalt zu analysieren, erstellt der Code durch Übergabe ein BeautifulSoup-Objekt html.text und der Parsertyp (lxml) zum BeautifulSoup() Funktion. Dies ermöglicht uns eine einfache Navigation und das Extrahieren von Daten aus dem HTML.
Schritt 3: Suchen Sie die Produktelemente auf der Seite
Im Allgemeinen müssen wir das HTML-Layout einer Seite verstehen, um die Ergebnisse herauszubekommen. Dies ist ein wichtiger und kritischer Teil des Web Scraping.
Machen Sie sich jedoch keine Sorgen, wenn Sie sich mit HTML nicht so gut auskennen.
Wir werden Entwicklertools verwenden, eine Funktion, die in den meisten gängigen Webbrowsern verfügbar ist, um unsere erforderlichen Daten zu extrahieren.
Führen Sie auf der Suchergebnisseite „Element prüfen“ aus und öffnen Sie das Fenster mit den Entwicklertools. Alternativ drücken Sie „STRG+UMSCHALT+I” für Windows-Benutzer oder „Option + ⌘ + I” auf dem Mac
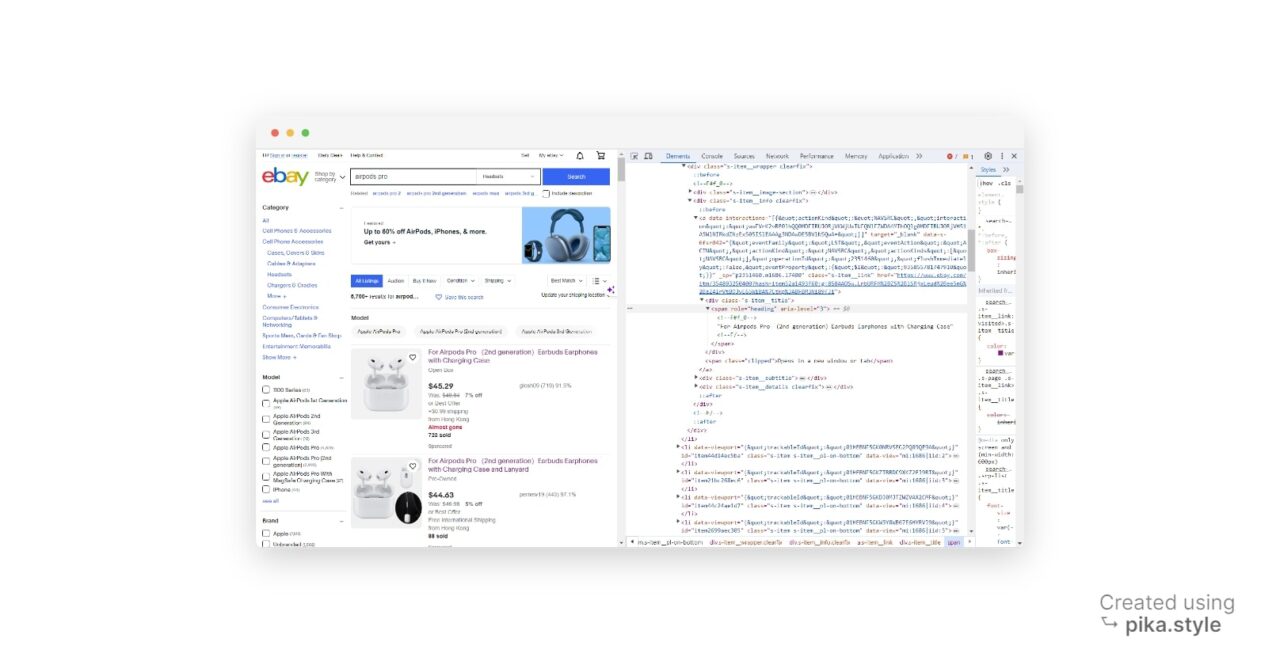
Im neuen Fenster finden Sie den Quellcode der Zielwebseite. In unserem Fall werden alle Produkte als Listenelemente erwähnt, also müssen wir uns alle diese Listen schnappen.
Um einen zu schnappen HTML-Element, wir benötigen eine damit verknüpfte Kennung. Es kann ein sein Ausweis dieses Elements, irgendein Klassennameoder irgend ein anderer HTML-Attribut des jeweiligen Elements.
In unserem Fall verwenden wir den Klassennamen als Bezeichner. Alle Listen haben den gleichen Klassennamen, also S-Item.
Bei näherer Betrachtung haben wir die Klassennamen für den Produktnamen und den Produktpreis erhalten: „s-item__title“ Und „s-item__price„, jeweils.
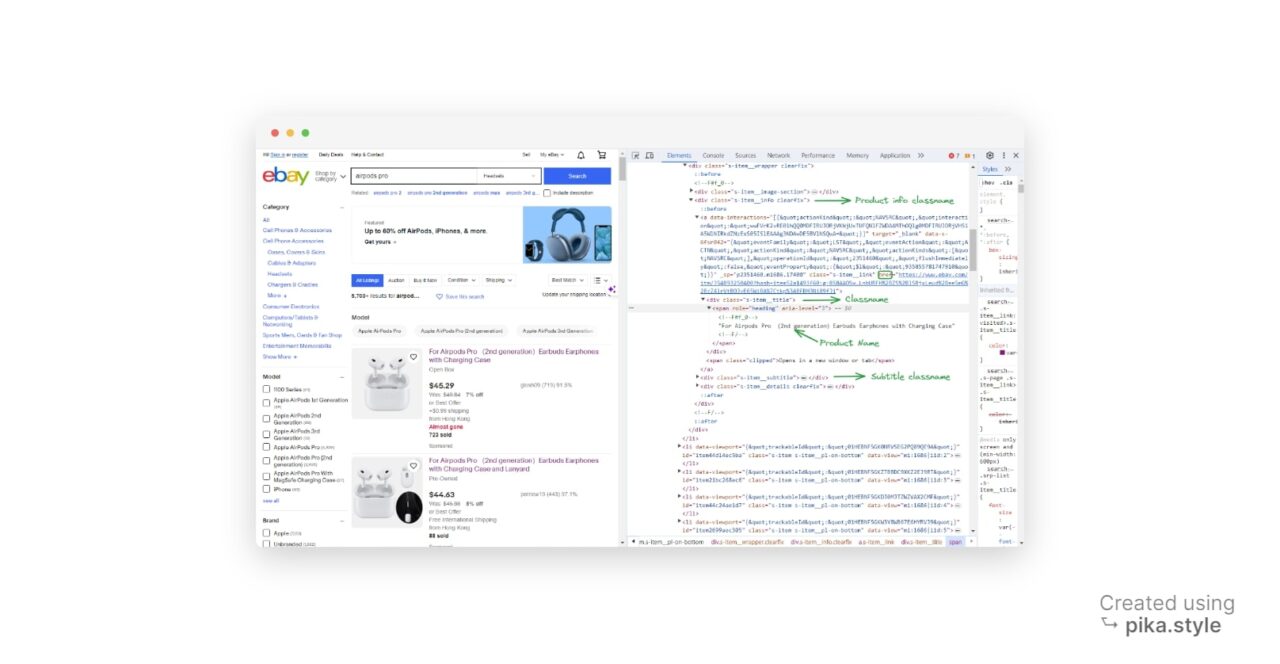
Der nächste Schritt besteht darin, die Produktartikel auf der Seite zu finden. Der Code verwendet die find_all() Methode des BeautifulSoup-Objekts, um alle div-Elemente mit der Klasse „ zu findens-item__info clearfix„.
Diese div-Elemente stellen die Produktelemente auf der Seite dar. Mit dem gleichen Ansatz findet das Programm auch die entsprechenden Bildcontainer.
Fügen Sie Ihrer Datei die folgenden Codezeilen hinzu:
import requests
from bs4 import BeautifulSoup
import csv
url = "https://www.ebay.com/sch/i.html?_from=R40&_trksid=p4432023.m570.l1312&_nkw=airpods+pro&_sacat=0"
html = requests.get(url)
print(html.text)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Accept-Language": "en-US, en;q=0.5",
}
html = requests.get(url, headers=headers)
soup = BeautifulSoup(html.text, "lxml")
listings = soup.find_all("div", class_="s-item__info clearfix")
images = soup.find_all("div", class_="s-item__wrapper clearfix")
Schritt 4: Extrahieren Sie die gewünschten Informationen
Für jeden Produktartikel extrahieren wir den Titel, den Preis, die Produkt-URL, den Produktstatus und die Bild-URL.
import requests
from bs4 import BeautifulSoup
import csv
url = "https://www.ebay.com/sch/i.html?_from=R40&_trksid=p4432023.m570.l1312&_nkw=airpods+pro&_sacat=0"
html = requests.get(url)
print(html.text)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Accept-Language": "en-US, en;q=0.5",
}
html = requests.get(url, headers=headers)
soup = BeautifulSoup(html.text, "lxml")
listings = soup.find_all("div", class_="s-item__info clearfix")
images = soup.find_all("div", class_="s-item__wrapper clearfix")
result_list = ()
for listing, image_container in zip(listings, images):
title = listing.find("div", class_="s-item__title").text
price = listing.find("span", class_="s-item__price").text
product_url = listing.find("a")
link = product_url("href")
product_status_element = listing.find("div", class_="s-item__subtitle")
product_status = (
product_status_element.text
if product_status_element is not None
else "No status available"
)
if title and price:
title_text = title.strip()
price_text = price.strip()
status = product_status.strip()
image = image_container.find("img")
image_url = image("src")
result_dict = {
"title": title_text,
"price": price_text,
"image_url": image_url,
"status": status,
"link": link,
}
result_list.append(result_dict)
Innerhalb einer Schleife extrahiert der Code den Titel, den Preis, die Produkt-URL, den Produktstatus und die Bild-URL für jeden Produktartikel. Es nutzt die find() Methode des BeautifulSoup-Objekts, um bestimmte Elemente innerhalb jedes Produktelements zu finden.
Die extrahierten Daten werden dann in einem Wörterbuch namens gespeichert result_dict und angehängt an die result_list.
Schritt 5: Schreiben Sie die Ergebnisse in eine CSV-Datei
Nach dem Extrahieren der Daten erstellen wir eine CSV-Datei mit dem Namen „ebay_results.csv” im Schreibmodus mit dem open() Funktion.
with open("ebay_results.csv", "w", newline="", encoding="utf-8") as csv_file:
fieldnames = ("title", "price", "image_url", "status", "link")
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
# Write the header row
writer.writeheader()
# Write the data rows
for result in result_list:
writer.writerow(result)
Es entsteht ein DictWriter Objekt aus dem CSV Bibliothek, um die Daten in die CSV-Datei zu schreiben. Der „fieldnamesDer Parameter „gibt die Spaltennamen in der CSV-Datei an.
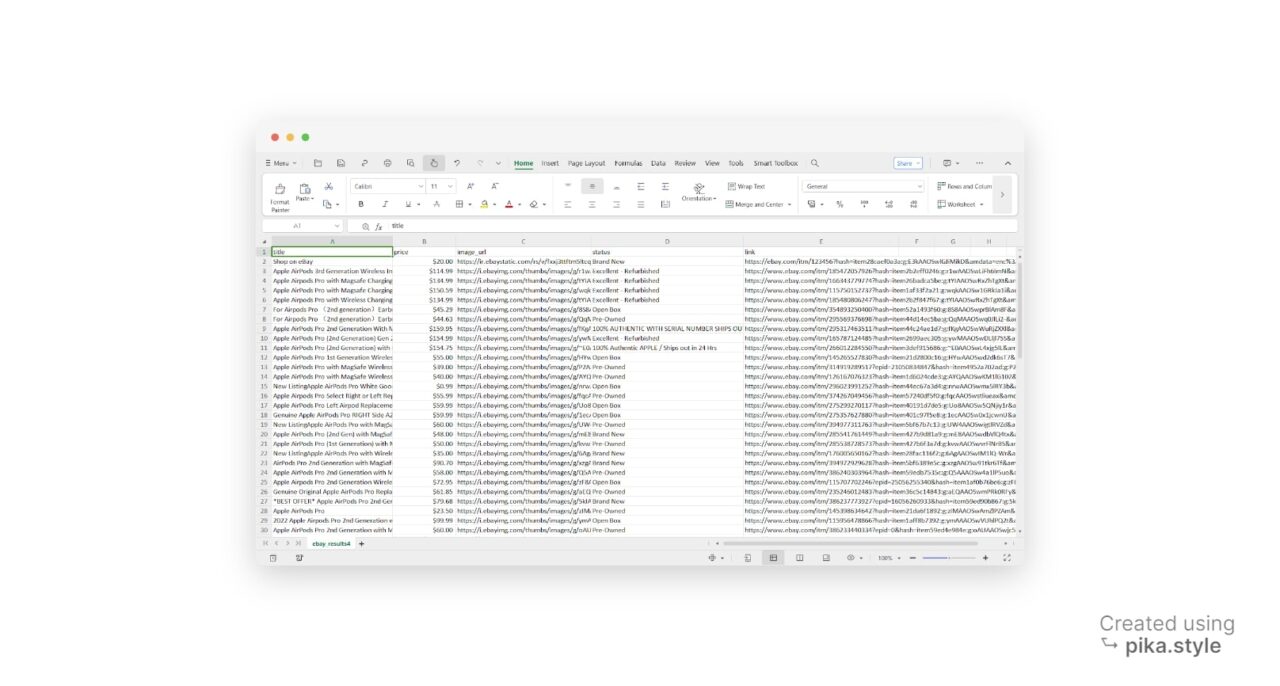
Wir können die extrahierten Daten auch auf der Konsole ausdrucken.
for result in result_list:
print("Title:", result("title"))
print("Price:", result("price"))
print("Image URL:", result("image_url"))
print("Status:", result("status"))
print("Product Link:", result("link"))
print("\n")
Der obige Code durchläuft jedes Element im result_list und gibt die entsprechenden Werte für jeden Schlüssel aus. In diesem Fall: Titel, Preis, Bild-URL, Produktstatus und Produkt-URL.

Vollständiger Scraping-Code
Da nun alle Puzzleteile vorhanden sind, schreiben wir den vollständigen Scraping-Code. Dieser Code kombiniert alle von uns besprochenen Techniken und Schritte und ermöglicht Ihnen die Erfassung von eBay-Produktdaten in einem einzigen Schritt.
import requests
from bs4 import BeautifulSoup
import csv
url = "https://www.ebay.com/sch/i.html?_from=R40&_trksid=p4432023.m570.l1312&_nkw=airpods+pro&_sacat=0"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Accept-Language": "en-US, en;q=0.5",
}
html = requests.get(url, headers=headers)
soup = BeautifulSoup(html.text, "lxml")
result_list = ()
# Find all product items on the page
listings = soup.find_all("div", class_="s-item__info clearfix")
images = soup.find_all("div", class_="s-item__wrapper clearfix")
for listing, image_container in zip(listings, images):
title = listing.find("div", class_="s-item__title").text
price = listing.find("span", class_="s-item__price").text
product_url = listing.find("a")
link = product_url("href")
product_status_element = listing.find("div", class_="s-item__subtitle")
product_status = (
product_status_element.text
if product_status_element is not None
else "No status available"
)
if title and price:
title_text = title.strip()
price_text = price.strip()
status = product_status.strip()
image = image_container.find("img")
image_url = image("src")
result_dict = {
"title": title_text,
"price": price_text,
"image_url": image_url,
"status": status,
"link": link,
}
result_list.append(result_dict)
# Write the result_list to a CSV file
with open("ebay_results4.csv", "w", newline="", encoding="utf-8") as csv_file:
fieldnames = ("title", "price", "image_url", "status", "link")
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
# Write the header row
writer.writeheader()
# Write the data rows
for result in result_list:
writer.writerow(result)
# Print the result list
for result in result_list:
print("Title:", result("title"))
print("Price:", result("price"))
print("Image URL:", result("image_url"))
print("Status:", result("status"))
print("Product Link:", result("link"))
print("\n")
Verwendung von ScraperAPI für eBay Data Scraping
Das Scrapen von eBay-Daten kann aufgrund der Anti-Bot-Maßnahmen von eBay und der häufigen Änderungen seiner Techniken eine anspruchsvolle Aufgabe sein.
Sie haben dies bereits zu Beginn dieses Tutorials gesehen, als eine Anfrage ohne die richtigen Header von eBay blockiert wurde.
Dieser Ansatz funktioniert jedoch nur für kleine Projekte (Scraping einiger Dutzend URLs).
Um unser Projekt zu skalieren und Millionen von Produktdetails zu sammeln, verwenden wir ScraperAPI. Diese Lösung soll Ihnen dabei helfen, diese Herausforderungen mühelos zu meistern. Es kümmert sich auch um die IP-Rotation und stellt so sicher, dass Ihr Scraping-Prozess reibungslos und ohne Unterbrechungen abläuft.
Erste Schritte mit ScraperAPI
Die Verwendung von ScraperAPI ist unkompliziert. Sie müssen lediglich die URL der Webseite, die Sie scrapen möchten, zusammen mit Ihrem API-Schlüssel senden. So funktioniert das:
- Melden Sie sich für ScraperAPI an: Gehen Sie zur ScraperAPI-Dashboard-Seite und registrieren Sie sich für ein neues Konto. Dazu gehören 5.000 kostenlose API-Credits für 7 Tage, sodass Sie die Funktionen des Dienstes erkunden können.
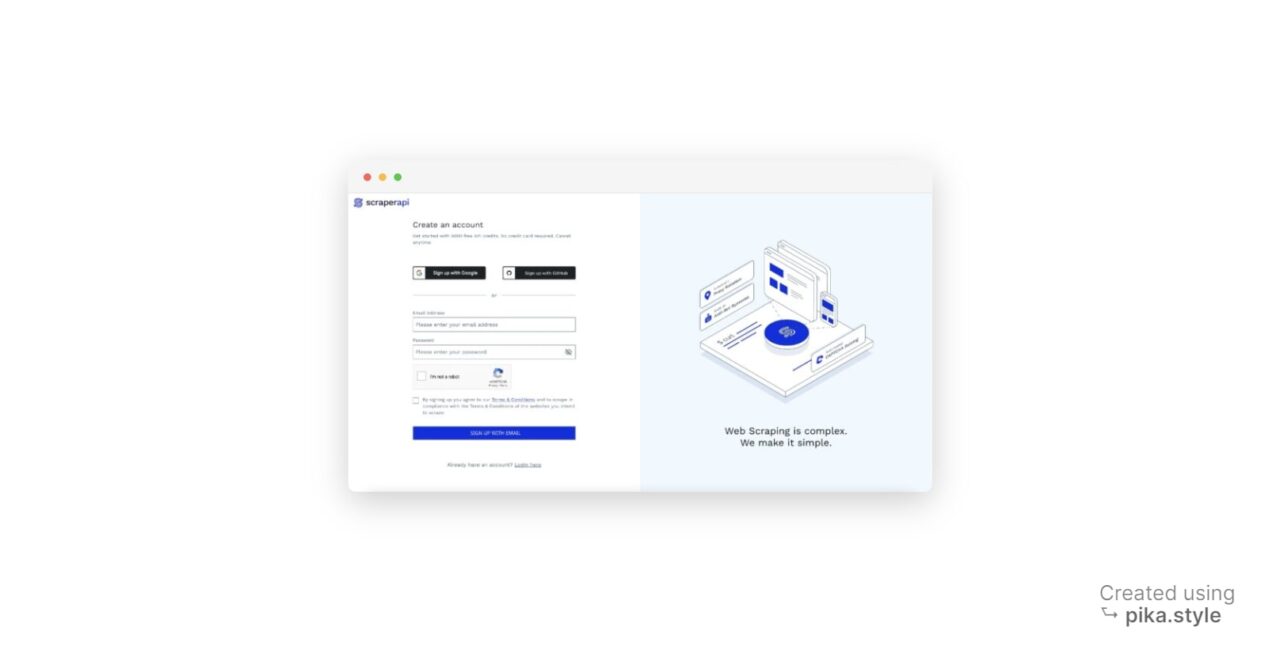
- Besorgen Sie sich Ihren API-Schlüssel: Bei der Anmeldung erhalten Sie Ihren API-Schlüssel.
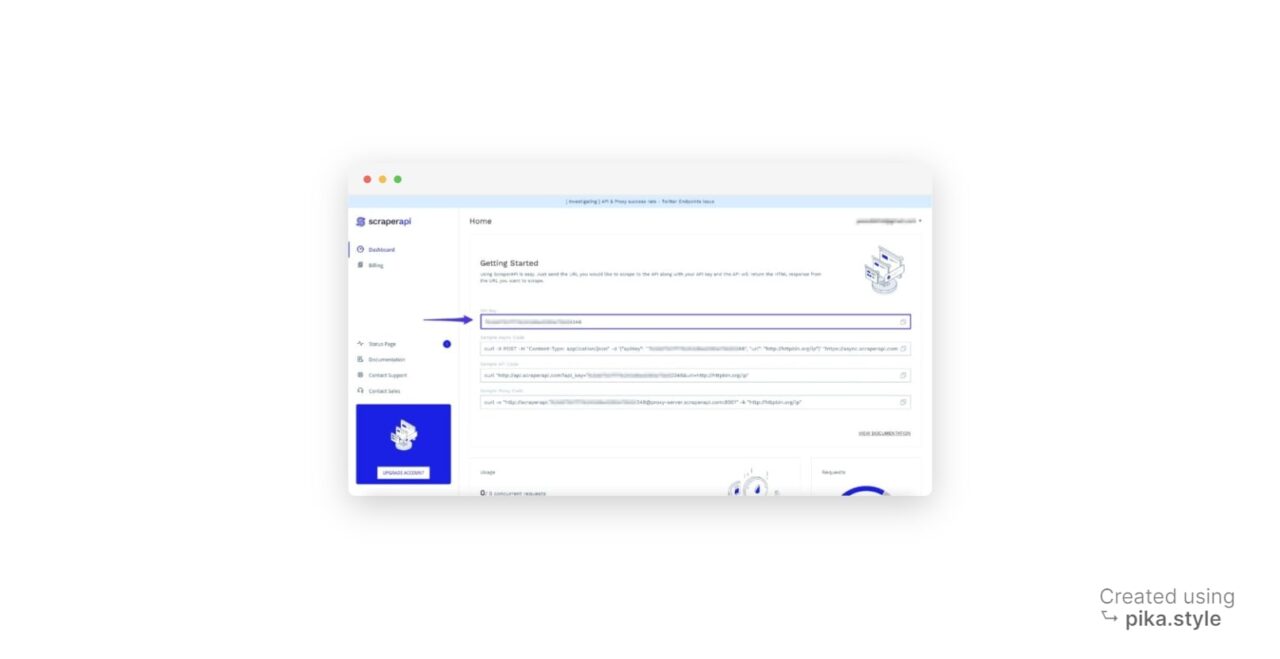
Jetzt können Sie mit dem folgenden Code auf die eBay-Suchergebnisse zugreifen.
Notiz: Ersetzen API-SCHLÜSSEL im Code mit Ihrem eigenen ScraperAPI-API-Schlüssel.
import requests
import json
from bs4 import BeautifulSoup
API_KEY = "YOUR_API_KEY"
url = "https://www.ebay.com/sch/i.html?_from=R40&_trksid=p4432023.m570.l1312&_nkw=airpods+pro&_sacat=0"
payload = {"api_key": API_KEY, "url": url}
r = requests.get("http://api.scraperapi.com", params=payload)
html_response = r.text
soup = BeautifulSoup(html_response, "lxml")
result_list = ()
# Find all product items on the page
listings = soup.find_all("div", class_="s-item__info clearfix")
images = soup.find_all("div", class_="s-item__wrapper clearfix")
for listing, image_container in zip(listings, images):
title = listing.find("div", class_="s-item__title").text
price = listing.find("span", class_="s-item__price").text
product_url = listing.find("a")
link = product_url("href")
product_status_element = listing.find("div", class_="s-item__subtitle")
product_status = (
product_status_element.text
if product_status_element is not None
else "No status available"
)
if title and price:
title_text = title.strip()
price_text = price.strip()
status = product_status.strip()
image = image_container.find("img")
image_url = image("src")
result_dict = {
"title": title_text,
"price": price_text,
"image_url": image_url,
"status": status,
"link": link,
}
result_list.append(result_dict)
# print(result_list)
# Output the result in JSON format
output_json = json.dumps(result_list, indent=2)
# Write the JSON data to a file
with open("ebay_results.json", "w", encoding="utf-8") as json_file:
json_file.write(output_json)
print("JSON data has been written to ebay_results.json")
Dies ist die Ausgabe, wie in der Abbildung zu sehen ebay_results.json Datei
(
{
"title": "Apple AirPods Pro",
"price": "$200.00",
"image_url": "https://ir.ebaystatic.com/rs/v/fxxj3ttftm5ltcqnto1o4baovyl.png",
"status": "Brand New",
"link": "https://ebay.com/itm/123456?hash=item28caef0a3a:g:E3kAAOSwlGJiMikD&amdata=enc%3AAQAHAAAAsJoWXGf0hxNZspTmhb8%2FTJCCurAWCHuXJ2Xi3S9cwXL6BX04zSEiVaDMCvsUbApftgXEAHGJU1ZGugZO%2FnW1U7Gb6vgoL%2BmXlqCbLkwoZfF3AUAK8YvJ5B4%2BnhFA7ID4dxpYs4jjExEnN5SR2g1mQe7QtLkmGt%2FZ%2FbH2W62cXPuKbf550ExbnBPO2QJyZTXYCuw5KVkMdFMDuoB4p3FwJKcSPzez5kyQyVjyiIq6PB2q%7Ctkp%3ABlBMULq7kqyXYA"
},
{
"title": "Apple AirPods Pro 2nd Generaci\u00f3n PRECINTADOS",
"price": "USD213.60",
"image_url": "https://i.ebayimg.com/thumbs/images/g/uYUAAOSwAnRlOs3r/s-l300.webp",
"status": "Totalmente nuevo",
"link": "https://www.ebay.com/itm/296009215198?hash=item44eb862cde:g:uYUAAOSwAnRlOs3r&amdata=enc%3AAQAIAAAA4C51eeZHbaBu1XSPHR%2Fnwuf7F8cSg34hoOPgosNeYJP9vIn%2F26%2F3mLe8lCmBlOXTVzw3j%2FBwiYtJw9uw7vte%2FzAb35Chru0UMEOviXuvRavQUj8eTBCYWcrQuOMtx1qhTcAscv4IBqmJvLhweUPpmd7OEzGczZoBuqmb%2B9iUbmTKjD74NWJyVZvMy%2B02JG1XUhOjAp%2BVNNLH0dU%2Bke530dAnRZSd1ECJpxuqSJrH8jn6WcvuPHt4YRVzKuKzd8DBnu%2F0q%2FwkEkBBYy8AlLKj6RuRf4BOimd5C5QFRRey1p9D%7Ctkp%3ABFBMoLnxs_Ni"
},
{
"title": "Apple AirPods Pro 2da Generaci\u00f3n con Estuche de Carga Inal\u00e1mbrico MagSafe - SELLADO",
"price": "USD74.24",
"image_url": "https://i.ebayimg.com/thumbs/images/g/ce4AAOSwA6NlP5jN/s-l300.webp",
"status": "Totalmente nuevo",
"link": "https://www.ebay.com/itm/155859459163?hash=item2449f29c5b:g:ce4AAOSwA6NlP5jN&amdata=enc%3AAQAIAAAA4A9XuJkJREhc3yfSLaVZvBooRWQQJkXbWAXmnSwndqFI7UgsJgH2U98ZoS6%2BiExiDMoeL6W7E6l7y9KCZDHdxwCixGLPwJKvM7WiZNcXhuH5NsSgCjcvJt56K%2BXCLMuQhmJvfih%2BWeZlqRXTwfUKDE0NMNSXE98u1tAOMohQ1skdT%2FKS7RDJ7Dpo%2BcGb1ZCt9KRAoNMKOkmnr5BVTMHFpzAOOC6fQAlRFt8e5yXrlZYwbyMchnboMF3F3xODe5dEvxv3YiHinOAoLl93pNmz1Yn1ToO%2FrIef4ZCbsiECkfk3%7Ctkp%3ABFBMoLnxs_Ni"
},
{
"title": "AURICULARES BLUETOOTH APPLE AIRPODS PRO AURICULARES CON ESTUCHE DE CARGA INAL\u00c1MBRICA",
"price": "USD80.99",
"image_url": "https://i.ebayimg.com/thumbs/images/g/v78AAOSw-NFkS37t/s-l300.webp",
"status": "De segunda mano",
"link": "https://www.ebay.com/itm/144890564294?hash=item21bc268ec6:g:v78AAOSw-NFkS37t&amdata=enc%3AAQAIAAAA4LD7XbJuhs0J9HL02DzzbH8fZ7T5wxLjkMhC2%2B%2Bwg5WrsH3ni7TcbBIqImnuOYtcDKznUPm%2F2%2FHNoD43mA6%2Ffw23995rH3%2BW9Wb5QPimLoCn3cA1PUbPBO6zG99gyg04JbxmtGH6f%2FYaZlfXVo3vWLvSqwux3ZsP1okWWuuz5y1OjJvXQB9ACVoLSCC6au2RpqS3DdOPwi%2FGrP0Osj44XNbT8UHtSKF6N%2FmbqNTLXoaJVunBjlnpjvE%2BPTKAxSuFX3GvptHXOqFCKAkdKpmH8%2BW8hRTX0q9gVxv9Nw6epsC%2B%7Ctkp%3ABFBMoLnxs_Ni"
},
{
"title": "Auriculares AirPods Pro 2 Bluetooth con estuche de carga inal\u00e1mbrica MagSafe para tel\u00e9fonos",
"price": "USD58.53",
"image_url": "https://i.ebayimg.com/thumbs/images/g/ol8AAOSw~e9lLfXD/s-l300.webp",
"status": "Nuevo (otro)",
"link": "https://www.ebay.com/itm/295718525142?hash=item44da3298d6:g:ol8AAOSw~e9lLfXD&amdata=enc%3AAQAIAAAA4GHg1xYgyvcQRhTwQRVL2l5CvX3zSMsR281hXacuujxxm9F%2F5pYTo9aEp9ZL7e8jsJB9qlUMUF7kLuYgPHFoEh%2B0qQtajGFWTi3NqY3h8vYwhFCWqITUnrV%2BhJ0voFK4qvh3CmnzDVbYnkYPY36OehktFXjrS%2B6WWx24w7a1TXAJSCwEi0Oh9SWqDyrkSH19m7Ft0t2gMq3EpMYy7IidY2HOfQkZe7MUpHNqVoUnzaNiKv129JAfiWGkOPtwABqRt2b09iKMpoPjTfPUIHMj%2F5yL97%2B%2BCj5A4zGc5TRPsIrG%7Ctkp%3ABFBMoLnxs_Ni"
},
)
Mit ScraperAPI können Sie sich auf das Extrahieren wertvoller eBay-Daten konzentrieren, ohne sich Gedanken über eine Blockierung machen zu müssen oder Ihren Scraper mit den sich weiterentwickelnden Anti-Bot-Techniken von eBay auf dem neuesten Stand zu halten.
Mit den gesammelten Daten können Sie vielfältige Analysen durchführen und diese für Ihre spezifischen Zwecke nutzen, unter anderem für Preisvergleiche und Marktforschung.
Zusammenfassung
Dieses Tutorial bietet einen kurzen Überblick darüber, wie Sie mit Python Daten aus eBay extrahieren. Es umfasste:
- Die beim Scraping von eBay erforderlichen Schritte umfassen das Senden von HTTP-Anfragen, das Parsen von HTML-Antworten mit BeautifulSoup und die Verwendung von ScraperAPI zur Durchführung von Anti-Bot-Maßnahmen.
- Die Seitenstruktur von eBay verstehen
- Verwenden Sie benutzerdefinierte Header, um eine erfolgreiche Antwort in geringerem Umfang sicherzustellen
- So extrahieren Sie Produktdetails von eBay
Wenn Sie bereit sind, Ihre Datensammlung auf Tausende oder sogar Millionen von Seiten zu skalieren, sollten Sie den Businessplan von ScraperAPI in Betracht ziehen, der erweiterte Funktionen, Premium-Support und einen Account Manager bietet.
Benötigen Sie mehr als 10 Millionen API-Credits? Kontaktieren Sie den Vertrieb für einen individuellen Plan.
Wenn Sie weitere Fragen haben oder Hilfe benötigen, können Sie sich gerne an uns wenden!
Bis zum nächsten Mal, viel Spaß beim Schaben!
