
In diesem Tutorial erfahren Sie, was Web Scraping ist und wie Sie es mit PHP durchführen können. Wir extrahieren die 250 bestbewerteten IMDB-Filme mit PHP. Am Ende dieses Artikels verfügen Sie über fundierte Kenntnisse zur Durchführung von Web Scraping mit PHP und verstehen die Einschränkungen der Datenerfassung in großem Maßstab und wissen, welche Optionen Sie haben, wenn Sie solche Anforderungen haben.
Was ist Web-Scraping?
Wir surfen jeden Tag im Internet auf der Suche nach Informationen, die wir für einen Auftrag oder einfach zur Bestätigung bestimmter Vermutungen benötigen. Manchmal müssen Sie möglicherweise einige dieser Daten oder Inhalte von einer Website kopieren und zur späteren Verwendung in einem Ordner speichern. Wenn Sie das getan haben, herzlichen Glückwunsch, Sie haben im Wesentlichen Web Scraping durchgeführt. Willkommen im Klub!
Wenn Sie jedoch große Datenmengen benötigen, erweist sich die typische Methode zum Kopieren und Einfügen als mühsam. Daten als Ware machen nur dann Sinn, wenn Sie sie in einem Kontext in großem Maßstab extrahieren.
Web Scraping oder Datenextraktion ist der Prozess, bei dem Daten aus mehreren Quellen im Web gesammelt und in einem lesbaren Format gespeichert werden.
Daten sind heutzutage so etwas wie eine Währung, und Unternehmen streben zunehmend danach, datengesteuert zu sein.
Aber ohne einen geeigneten Rahmen und Datenverwaltungsprotokolle, die den gesamten Datenlebenszyklus abdecken, ist die Währung des 21. Jahrhunderts so gut wie ein abgelaufener Coupon. Wir haben immer behauptet, dass schlechte Daten nicht besser sind als keine Daten. Lesen Sie hier mehr über die fünf Hauptmerkmale hochwertiger Daten:
Der Hauptzweck dieses Artikels besteht darin, Sie in die Welt der Datenextraktion mit PHP, einer der beliebtesten serverseitigen Skriptsprachen für Websites, einzuführen.
Wir werden ein einfaches PHP-Skript verwenden, um die 250 besten Filme der IMDB zu extrahieren und sie in einer lesbaren CSV-Datei zu präsentieren. Da PHP eine der am meisten gefürchteten Programmiersprachen ist, sollten Sie sich diese genauer ansehen. Der Schwierigkeitsgrad des Web-Scrapings mit PHP hängt nur von der Perspektive ab.
PHP-Grundlagen für Web Scraping
Die Technologie, die eine Verbindung zwischen Ihrem Webbrowser und den vielen Websites im Internet herstellt, ist komplex und kompliziert.
Ungefähr 40 % des Webs basieren auf PHP, das sowohl aus logischen als auch aus syntaktischen Gründen seit jeher als chaotisch gilt.
PHP ist eine objektorientierte Programmiersprache. Es unterstützt alle wichtigen Eigenschaften der objektorientierten Programmierung wie Abstraktion und Vererbung, was sich am besten für langfristige Scraping-Zwecke eignet.
Obwohl die Datenextraktion mit anderen Programmiersprachen relativ einfacher ist, verfügen die meisten Websites heutzutage über mehr als nur einen Hauch von PHP, sodass es praktisch ist, schneller einen Crawler zu schreiben und ihn in Websites zu integrieren.
Bevor wir fortfahren, skizzieren wir kurz den Inhalt dieses Artikels:
- Voraussetzungen
- Definitionen
- Aufstellen
- Erstellen des Schabers
- Erstellen der CSV
- Letzte Worte
Zuerst müssen wir definieren, was wir tun und was wir für dieses Scraping-Tutorial verwenden werden. Unser allgemeiner Arbeitsablauf besteht aus der Einrichtung eines Projektverzeichnisses und der Installation der für die Datenextraktion erforderlichen Tools.
Die meisten davon sind plattformunabhängig und können in jedem Betriebssystem Ihrer Wahl ausgeführt werden.
Anschließend werden wir jeden Schritt des Schreibens des Scrapers in PHP unter Verwendung der genannten Bibliotheken durchgehen und erklären, was jede Zeile bewirkt.
Abschließend gehen wir auf die Einschränkungen des Crawlings ein und erläutern, was bei groß angelegtem Crawling zu tun ist.
Der Artikel geht auf Fehler ein, die man unwissentlich machen könnte. Wir schlagen Ihnen auch eine passendere Lösung vor.
Definitionen für den Einstieg in PHP Web Scraping
Bevor wir mitten ins Geschehen einsteigen, wollen wir uns mit einigen grundlegenden Begriffen befassen, die Ihnen beim Lesen dieses Artikels begegnen werden. Zur Vereinfachung der Demonstration werden hier alle Fachbegriffe definiert.
1. Paketmanager
Ein Paketmanager hilft Ihnen bei der Installation wichtiger Pakete über einen zentralen Verteilungsspeicher. Es handelt sich im Grunde um ein Software-Repository, das ein Standardformat für die Verwaltung von Abhängigkeiten von PHP-Software und -Bibliotheken bereitstellt.
Obwohl sie nicht auf die Verwaltung von PHP-Bibliotheken beschränkt sind, können Paketmanager auch die gesamte auf unseren Computern installierte Software wie einen App Store verwalten, allerdings spezifischer auf den Code.
Einige Beispiele für Paketmanager sind: Composer (für PHP), npm (für JavaScript), apt (für Ubuntu-Derivat-Linux), Brew (für MacOS), Winget (für Windows) usw.
2. Entwicklerkonsole
Es ist ein Teil des Webbrowsers, der verschiedene Tools für Webentwickler enthält. Es ist auch einer der am häufigsten genutzten Bereiche des Browsers, wenn wir mit dem Scrapen von Daten von Websites beginnen wollen.
Mit der Konsole können Sie ermitteln, welche Aufgaben ein Webbrowser ausführt, wenn er mit einer beobachteten Website interagiert. Obwohl es viele Abschnitte zur Auswahl gibt, werden wir in diesem Artikel nur die Abschnitte „Elemente“, „Netzwerk“ und „Anwendungen“ verwenden.
3. HTML-Tags
Tags sind spezifische Anweisungen in Klartext, die in dreieckige Klammern (Größer-als-/Kleiner-als-Zeichen) eingeschlossen sind.
Beispiel:
<html> … </html>
Sie werden verwendet, um dem Webbrowser Anweisungen zu geben, wie eine Webseite benutzerfreundlich dargestellt werden soll.
4. Dokumentobjektmodell (DOM)
Das DOM besteht aus der logischen Struktur von Dokumenten und der Art und Weise, wie auf sie zugegriffen und sie bearbeitet werden.
Einfach ausgedrückt handelt es sich bei DOM um Modelle, die aus einer HTML-Antwort generiert werden und durch einfache Abfragen referenziert werden können, ohne dass eine komplexe Verarbeitung erforderlich ist.
Ein gutes Beispiel wäre ein interaktives Buch, in dem jedes komplexe Wort mit seiner Bedeutung verknüpft wird, sobald man auf das Wort klickt.
5. Guzzle/guzzlehttp
Es handelt sich um ein externes Paket, das von unserem Scraper verwendet wird, um Anfragen an und vom Webserver zu senden, ähnlich wie bei einem Webbrowser. Dieser Mechanismus wird oft als HTTP-Handshake bezeichnet, bei dem unser Code eine Anfrage (als GET-Anfrage bezeichnet) an die IMDB-Server sendet.
Als Antwort sendet uns der Server einen Antworttext, der aus einer Reihe von Anweisungen mit dem richtigen Antworttext, Cookies (manchmal) und anderen Befehlen besteht, die im Webbrowser ausgeführt werden.
Da unser Code in sequentieller Form (ein Prozess nach dem anderen) ausgeführt wird, verarbeiten wir keine anderen Anweisungen, die von den IMDB-Servern bereitgestellt werden. Wir konzentrieren uns nur auf den Antworttext. Die Dokumentation zu diesem Paket finden Sie hier.
6. Paquette/php-html-parser
Wie guzzle ist dies auch ein externes Paket, das verwendet wird, um die Rohantwort der vom Guzzle-Client empfangenen Webseite in ein richtiges DOM umzuwandeln.
Durch die Konvertierung in ein DOM können wir leicht auf die empfangenen Teile des Dokuments verweisen und auf einzelne Teile des Dokuments zugreifen, die wir durchsuchen möchten. Den Quellcode und die Dokumentation für dieses Paket finden Sie hier.
7. Basis-URL
Basis-URLs sind die URLs von Websites, die auf das Stammverzeichnis des Webservers verweisen.
Sie können die Basis-URL besser verstehen, indem Sie sich ansehen, wie eine Ordnerstruktur im Computersystem funktioniert.
Nehmen Sie einen Ordner mit dem Namen „Dokumente“ auf dem Computer. Das ist es, was der Webserver dem Internet zugänglich macht. Es kann von jedem Benutzer aufgerufen werden, der eine Antwort von der Webseite anfordert.
Wir können jeden neuen Ordner im Dokumentenordner öffnen. Die Navigation zum neuen Ordner ist lediglich eine Frage des Durchlaufens Documents/newfolder/path.
Ähnlich wie Webseiten auf der Grundlage einer Hierarchie verwaltet werden, sind die Basis-URLs das Stammverzeichnis des gesamten Webdokuments der Webseite, und alle neuen Seiten sind einfach „Ordner“ innerhalb dieses Basis-URL-Ordners.
Header sind Anweisungen für die Webserver und nicht für unser Clientsystem. Sie bieten eine einfache Sammlung vordefinierter Definitionen, die es Webservern ermöglichen, Client-Antworten genau zu dekodieren.
Ein einfaches Beispiel wäre eine Download-Windows-Seite, beispielsweise auf Microsoft.com.
Anhand des User-Agent-Headers kann der Webserver leicht ableiten, dass die an seinen Server gesendete Anfrage von einem Windows-PC stammt. Daher muss es Informationen senden, die für die Plattform relevant sind. Die gleiche Logik gilt für Sprachunterschiede zwischen Webseiten.
9. CSS-Selektoren
CSS-Selektoren sind einfach eine Sammlung von Textsyntax, die ein Dokument in einem DOM lokalisieren kann, ohne große Verarbeitungsressourcen zu verbrauchen.
Es ähnelt dem Inhaltsverzeichnisabschnitt in einem physischen Buch. Durch einen Blick auf das Inhaltsverzeichnis kann der Leser zu den Abschnitten gelangen, die ihn interessieren.
Aber im Gegensatz zum Inhaltsverzeichnis können CSS-Selektoren mehr Filter akzeptieren und diese nutzen, um Rauschen (unwichtige Daten) aus den tatsächlichen Daten zu reduzieren, die wir im DOM durchsuchen müssen.
Sie werden hauptsächlich beim Webdesign verwendet, sind aber beim Web-Scraping sehr hilfreich.
Ab diesem Punkt geht der Artikel davon aus, dass Sie über grundlegende Kenntnisse der objektorientierten Programmierung und PHP verfügen. Sie sollten die im obigen Abschnitt dargestellte Definition überflogen haben.
Es vermittelt Ihnen die Grundkenntnisse, die Sie benötigen, um mit dem Tutorial in den folgenden Abschnitten fortzufahren. Wir werden uns nun mit dem Aufbau des Crawlers befassen.
Komponist
Zunächst installieren wir einen Paketmanager (1) namens Composer über den Paketmanager für Ihre Systeme. Für Linux-Varianten ist es einfach Sudo apt Install Composer (Ubuntu) oder mit einem beliebigen Paketmanager auf unserem Computer. Weitere Informationen zu den Schritten zur Installation von Composer finden Sie hier.
Visual Studio Code (oder ein beliebiger Texteditor; sogar Notepad reicht aus)
Dies dient zum Schreiben des eigentlichen Schabers. Visual Studio Code verfügt über mehrere Erweiterungen, die Sie bei der Entwicklung von Programmen in verschiedenen Programmiersprachen unterstützen.
Es ist jedoch nicht die einzige Möglichkeit, diesem Tutorial zu folgen. Zum Schreiben eines Scrapers kann jeder Texteditor, auch ein einfacher, verwendet werden.
Wir empfehlen IDE aufgrund der automatischen Syntaxhervorhebung und anderer grundlegender Funktionen dringend. Es kann über die Stores einzelner Plattformen installiert werden.
Unter Linux ist die Installation über die Paketmanager oder Snap oder Flatpaks viel einfacher. Informationen zur Windows- und MacOS-Installation finden Sie hier.
Nachdem wir nun alles haben, was wir brauchen, um den Scraper zu schreiben, um die Details der 250 am besten bewerteten Filme in der IMDB zu extrahieren, können wir mit dem Schreiben des eigentlichen Drehbuchs fortfahren.
Erstellen des Web Scrapers
Über diesen Link möchten wir die bisher 250 am besten bewerteten Filme der IMDB für die folgenden Details durchsuchen:
- Rang
- Titel
- Direktor
- Führt
- URL
- Bild URL
- Bewertung
- Anzahl der Bewertungen
- Erscheinungsjahr
Aber es gibt einen kleinen Schluckauf. Auf der Website werden nicht alle von uns benötigten Informationen angezeigt.
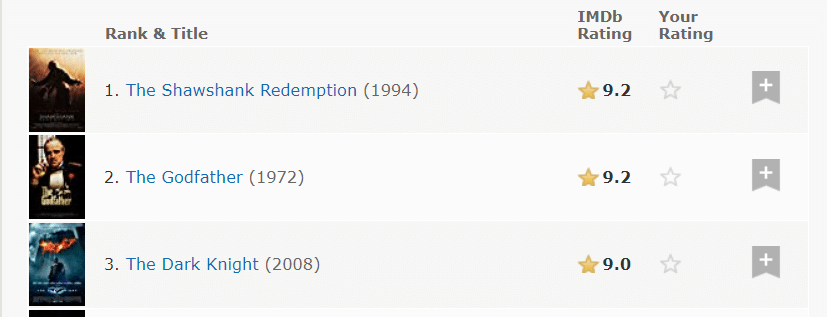
Nur Rang, Titel, Jahr, Bewertung und Bild sind direkt sichtbar.
Der erste Schritt beim Web Scraping besteht darin, herauszufinden, was die Website vor uns verbirgt.
Sie könnten Websites als vom Webserver gesendete Textwände betrachten. Beim Lesen durch den Webbrowser kann die Website abhängig von den Anweisungen auf den vom Webserver gesendeten Textwänden unterschiedliche Strukturen anzeigen.
Jeder Hover in jedem Element der Website ist lediglich eine Anweisung an den Webbrowser, der vom Server empfangenen Textantwort zu folgen und entsprechend zu handeln.
Als Scraper besteht unsere Aufgabe darin, diesen empfangenen Text zu manipulieren und alle Informationen zu extrahieren, die die Website vor uns verbergen möchte, es sei denn, wir klicken auf die gewünschte Option.
Schritt 1:
Öffnen Sie die Entwicklertools (2) im Browser, um zu überprüfen, was die Website vor uns verborgen hat. Um die Entwicklerkonsole zu öffnen, drücken Sie F12 auf der Tastatur oder Ctrl+Shift+I (Command+Shift+I for Mac). Sobald Sie die Entwicklerkonsole öffnen, werden Sie mit dem folgenden Bildschirm begrüßt.
Dies ist im Grunde das, was die aktuelle Website an unser System gesendet hat, um die Website auf der Leinwand des Webbrowsers anzuzeigen.
Schritt 2:
Klicken Sie nun auf die Schaltfläche „Inspizieren“ (Pfeiltaste oben links), um den Inspektionsmodus für die Website zu starten.
Bei diesem Modus handelt es sich um einen Entwicklermodus, der zur Interaktion mit der Webseite verwendet wird, als ob wir versuchen würden, das interaktive Element auf der Website auf seine tatsächliche Anweisungsquelle in den Textwänden (Antwort genannt) zurückzuführen, die vom Webserver der IMDB gesendet werden .
Jetzt klicken wir einfach auf einen der Filmnamen und in der Konsole können wir sehen, wie die tatsächliche Textantwort lautete.
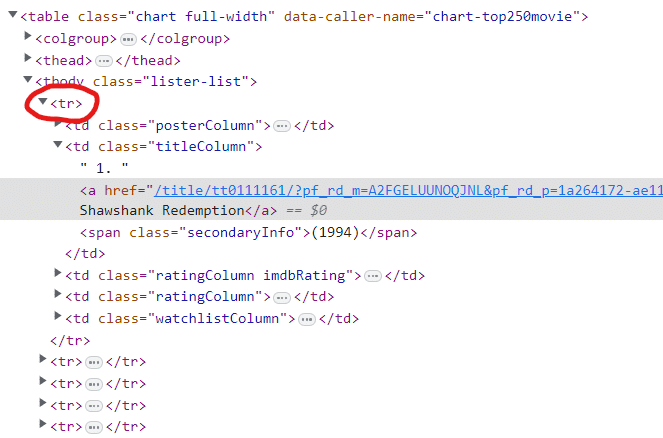
Im Bild oben sehen wir, dass es 250 sind tr Stichworte (3). Tags in HTML sind lediglich Anweisungen für Webseiten, um die Informationen in einem ansprechenderen Format anzuzeigen.
Diese Information wird später nützlich sein.
Konzentrieren wir uns zunächst auf das erste tr Mitglied in der Antwort. Alles maximieren td Elemente können wir zu jedem Filmeintrag mehr Informationen sehen, als zuvor auf der Webseite sichtbar waren.
Allein mit diesen Informationen können wir nun die Seitenantwort in unserem PHP-Code verwenden, um all diese zufälligen Informationen auf der Seite in ein geeignetes Tabellenformat zu übertragen, sodass wir daraus umsetzbare Daten generieren können.
Mit diesem Wissen können wir nun mit der echten Programmierung fortfahren.
Schritt 3:
Erstellen Sie ein Projektverzeichnis.
Benennen wir den Ordner ‚imdb_com‘ zur einfacheren Verwendung und Referenz. Öffnen Sie den Ordner über den Texteditor und führen Sie darin ein Terminal (Eingabeaufforderung) aus.
Geben Sie nach dem Öffnen des Terminalfensters Folgendes ein:
composer init
Dieser Befehl ruft den Composer auf, um ein Projekt im aktuell aktiven Ordner zu starten.
In unserem Fall ist es der Ordner, den wir gerade erstellt haben, d. h. imdb_com. Der Komponist wird uns um weitere Informationen bitten. Überfliegen Sie einfach den Vorgang und fügen Sie die folgenden Pakete hinzu, wenn Sie während der Ersteinrichtung von der Composer-Eingabeaufforderung dazu aufgefordert werden.

Schritt 4:
Geben Sie im oben gezeigten Bildschirm Folgendes ein:
guzzlehttp/guzzle
Drücken Sie die Eingabetaste und fügen Sie dann das endgültige Paket ein, das wir benötigen:
paquettg/php-html-parser
Sobald der Paket-Download abgeschlossen ist, verfügen wir über ein Verzeichnis für das Projekt, wie unten gezeigt:
Schritt 5:
Erstellen Sie nun eine neue Datei und nennen Sie sie „imdb.php‘ im selben Stammverzeichnis wie Composer.json Datei. Wir werden für den Rest des Tutorials an dieser Datei arbeiten.
Um den Scraper zu starten, müssen wir definieren, was die PHP-Datei ist. Beginnen mit <?php in der ersten Zeile ist ein guter Anfang.
Importieren Sie die Autoload-Funktion mit diesem Schlüsselwort:
require_once "vendor/autoload.php";
Diese Zeile lädt die Datei in den Vendor-Ordner im Stammverzeichnis. Es lädt alle Dateien, die wir gerade mit Composer in der Anfangsphase unseres Scrapers installiert haben.
use GuzzleHttpClient;
use PHPHtmlParserDom;
Der Crawler kann nun mit der Verwendung der von uns heruntergeladenen Pakete beginnen. Die Frage ist nun: Warum beides verwenden? require_once und das obige Skript gleichzeitig?
Die Antwort : Require_once stellt das Verzeichnis bereit, das die notwendigen Dateien enthält, um die Pakete zu verwenden, die wir mit dem Composer heruntergeladen haben. Das Schlüsselwort „use“ fordert das Programm auf, die Client- und Dom-Mitglieder der jeweiligen Klassen zu laden, damit wir diese Funktionen in unserem Crawler verwenden können.
Schritt 6:
Definieren Sie ein Objekt für die GuzzleHttpClient and PHPHtmlParserDom.
$client = new Client((
'base_uri' => 'https://www.imdb.com',
'headers' => (
'user-agent' => 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36',
'accept' => 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8',
'accept-language' => 'en-US,en;q=0.8'
),
));Dieser Code definiert eine Basis-URL (7) und Header (8) für die Website, die wir crawlen.
$dom = new Dom();
Das Gleiche gilt für die andere Bibliothek, die wir gerade in den Anfangsphasen des Crawlers definiert haben.
Schritt 7:
Nachdem nun alle unsere Tools im Crawler geladen sind, können wir zum Kern des Programms vordringen.
Senden Sie eine „GET“-Anfrage an diese Webseite.
Beachten Sie, dass wir https://www.imdb.com bereits als Basis-URL für unseren Crawler definiert haben. Unser eigentlicher Dokumentenpfad wäre also chart/top/?ref_=nv_mp_mv250und um die Anfrage zu senden, müssten wir Folgendes schreiben:
$response = $client->request('GET', '/chart/top/?ref_=nv_mp_mv250');
Da wir bereits über die vom Webserver gesendete Antwort verfügen, laden wir diese Antwort in eine Textvariable und senden sie an unseren DOM-Parser, um ein DOM zu generieren, sodass das Referenzieren von Teilen von Dokumenten viel schneller und einfacher ist.
$dom->loadStr($response->getBody());
Schritt 8:
Wir besuchen erneut die Entwicklerkonsole des Webbrowsers mit den zuvor gesammelten Informationen, nämlich den 250 tr-Tags, die alle Daten enthalten, die wir zu den Filmen benötigen.
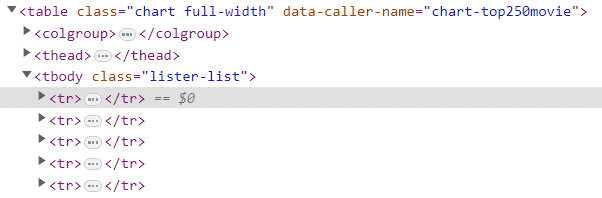
tbody Etikett. Wir sehen, dass alle Filmdaten, die wir benötigen, im enthalten sind tbody Etikett. Der tbody Das Tag liegt wiederum im Gültigkeitsbereich des Tabellen-Tags.
Anstatt das gesamte Dokument zu verarbeiten, da wir mithilfe der externen Bibliothek ein DOM-Element erstellt haben, können wir einfach mithilfe von CSS-Selektoren auf den Tabellenteil des Dokuments verweisen (9).
$movies = $dom->find('table(data-caller-name="chart-top250movie") > tbody > tr');
Jetzt durchsuchen wir das gesamte DOM nach einer Tabelle, deren Attribut data-caller-name ist chart-top250movie. Sobald das gefunden ist, gehen wir eine Ebene tiefer und finden alles tbody Stichworte.
Dann finden wir alle tr-Tags, indem wir eine weitere Ebene tiefer in die eintauchen tbody tag und schließlich alle diese Tags und ihre Mitglieder (Daten) zurückgeben und in der Variable movies speichern.
Weitere Informationen zu verschiedenen Syntaxen von CSS-Selektoren finden Sie unter diesem Link.
Sobald dies erledigt ist, werden alle unsere Filminformationen in der Variablen movies gespeichert. Das Durchlaufen der einzelnen Filme führt nun zu unseren Daten mit 250 Filminformationen, die in einem geeigneteren Format strukturiert sind.
Sie können die Filme mit Folgendem durchlaufen:
foreach ($movies as $mId => $movie) {
}Schritt 9:
Bevor wir an den einzelnen Feldern arbeiten, können wir ein neues Konzept zum Überschreiben der DOM-Elemente einführen.
Da die Variable „Filme“ bereits alle Informationen zu allen benötigten Filmen enthält, ist die Wiederverwendung des DOM-Objekts, das die gesamte Antwort vom Webserver geladen hat, eher eine Optimierungstechnik, die eingesetzt wird, um den Speicherbedarf des Crawlers zu reduzieren.
Um es wiederzuverwenden, ersetzen wir daher das gesamte Dokument durch nur einen winzigen Teil des Dokuments.
Wir werden nach einer kleinen Segway-Fahrt auf ein anderes Konzept näher eingehen. Wir wissen, dass die tr Tags enthalten alle Informationen zu den Filmen.
Einen kopieren tr Wenn wir alle Mitglieder markieren und erweitern, erhalten wir die folgenden Informationen zu jedem Film (in diesem Fall nur zum ersten).
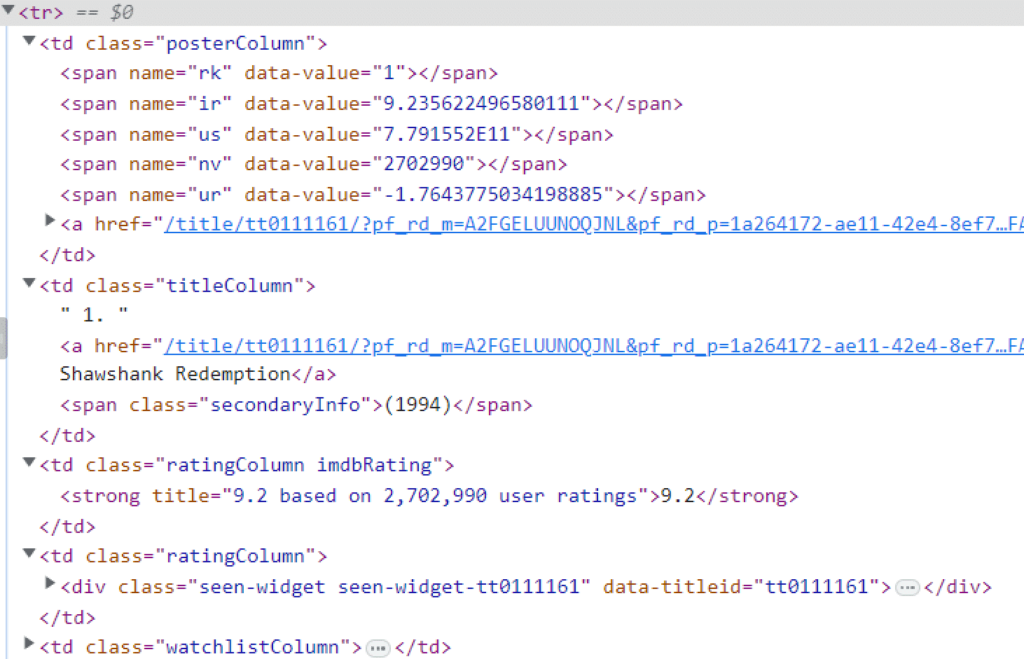
td Elemente. Alle Informationen, die wir benötigen, sind in den verschachtelten td-Elementen vorhanden. Jetzt können wir das Konzept der Wiederverwendung umsetzen. Da wir nicht mehr das gesamte Dokument benötigen, ersetzen wir einfach diese Informationen über den Film, die im tr-Tag im DOM-Objekt enthalten sind, damit wir dieselbe find()-Methode verwenden können, um die richtigen Informationen zu extrahieren, die wir benötigen. Wir können das tun, indem wir Folgendes verwenden:
$dom->loadStr($movie);
Schritt 10:
Beginnen Sie, das Array mit dem richtigen Schlüssel und Wertindex zu füllen.
Da wir das DOM-Objekt in vielen Schritten der Schleife ersetzen, ist es ratsam, alle DOM-Mitglieder zunächst in einer separaten, nicht ersetzbaren Variablen abzulegen.
$posterColumn = $dom->find('td.posterColumn');
$titleColumn = $dom->find('td.titleColumn');
$ratingColumn = $dom->find('td.ratingColumn.imdbRating');Wie wir sehen können, ist der Rang im Hauptmitglied vorhanden td Tag mit dem Klassennamen titleColumn. Um den Rang zu extrahieren, schreiben Sie den folgenden Code:
$arr('Rank') = $dom->find('td.titleColumn')->text;
Wenn Sie nur den obigen Code verwenden, kann dies zu einem kleinen Problem führen td Die Liste, die wir gerade gescrollt haben, enthält nicht nur den Rang, sondern auch den Titel des Films.
Das Ganze ziehen td tag as text ruft auch alle Mitglieder des Elements ab, die nicht von Tags umgeben sind. Daher verwenden wir PHP-Funktionen, um den gesamten Text aufzuteilen dot (.) und extrahieren Sie nur die ersten Daten aus dem Array, das sich aus der Aufteilung ergibt.
$arr('Rank') = array_shift(explode('.', $dom->find('td.titleColumn')->text));
Da wir nun nicht wissen, ob der Text, den wir geschabt haben, unsichtbare Leerzeichen enthält, werden durch das Einschließen mit trim alle unerwünschten Leerzeichen entfernt, was zu einem numerischen Ergebnis führt arr(‘Rank’);
$arr('Rank') = trim(array_shift(explode('.', $dom->find('td.titleColumn')->text)));Um die Attribute aus einem Tag zu extrahieren, verwenden Sie die getAttributes() Methode:
$arr('ImageURL') = $dom->loadStr($posterColumn)->find('img')->getAttributes()('src');Hier, getAttributes generiert ein Array mit Schlüssel-Wert-Paaren, wobei Attributnamen die Schlüssel und Attributwerte die Werte sind. Das Aufrufen der einzelnen Attributnamen, z. B. das Aufrufen eines Array-Mitglieds mithilfe von Indizes, gibt den benötigten Wert zurück.
Ebenso erhalten Sie durch das Ausfüllen aller Array-Schlüsselwerte alle Informationen, die Sie über den ersten Film benötigen. Die Fortsetzung der Schleife für jeden der 250 Filme führt dazu, dass unser Crawler alle benötigten Daten zu den 250 Filmen aussortiert.
Und whoa, unser Scraper ist fast fertig!
Erstellen der CSV
Nachdem wir nun den Scraper erstellt haben, ist es an der Zeit, die Daten in ein geeignetes Format zu bringen, um daraus umsetzbare Erkenntnisse zu ziehen. Dazu erstellen wir ein CSV-Dokument. Da der CSV-Ersteller bereits in der PHP-Bibliothek vorhanden ist, benötigen wir keine externen Tools oder Bibliotheken.
Öffnen Sie einen Dateistream in einem beliebigen Verzeichnis und verwenden Sie ihn fputcsv in jeder Schleife des Schabers, den wir erstellt haben. Am Ende unseres Programms wird effektiv eine CSV-Datei generiert.
$file = fopen("./test.csv", "w");
foreach ($movies as $mId => $movie) {
fputcsv($file, $arr);
}Nachdem wir dieses Programm ausgeführt haben, können wir feststellen, dass die von uns generierte CSV-Datei keine Spaltenüberschriften enthält. Um dies zu beheben, stellen wir eine Bedingung ein, um die Schlüssel des Arrays, das wir beim Scraping generiert haben, in der Schleife direkt darüber zu sichern fputcsv Linie.
foreach ($movies as $mId => $movie) {
if ($mId == 0) {
fputcsv($file, array_keys($arr));
}
fputcsv($file, $arr);
}Auf diese Weise wird zu Beginn jeder Schleife nur beim ersten Film der Schlüssel dieses Arrays verwendet, um eine Header-Datei am Anfang der CSV-Datei auszugeben.
Der gesamte Code sieht folgendermaßen aus:
<?php
require_once "vendor/autoload.php";
use GuzzleHttpClient;
use PHPHtmlParserDom;
$fieldsRequired = (
'Rank', 'Title', 'Director', 'Leads', 'URL', 'ImageURL', 'Rating', 'NoOfReview', 'ReleaseYear'
);
$baseUrl="https://www.imdb.com";
$pageUrl="/chart/top/?ref_=nv_mp_mv250";
$headers = (
'user-agent' => 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36',
'accept' => 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8',
'accept-language' => 'en-US,en;q=0.8'
);
$file = fopen("./test.csv", "w");
$client = new Client(
'base_uri' => $baseUrl,
'headers' => $headers,
));
$response = $client->request('GET', $pageUrl);
$dom = new Dom();
$dom->loadStr($response->getBody());
$movies = $dom->find('table(data-caller-name="chart-top250movie") > tbody > tr');
foreach ($movies as $mId => $movie) {
$dom->loadStr($movie);
$posterColumn = $dom->find('td.posterColumn');
$titleColumn = $dom->find('td.titleColumn');
$ratingColumn = $dom->find('td.ratingColumn.imdbRating');
$arr = ();
$arr('Rank') = trim(array_shift(explode('.', $titleColumn->text)));
$arr('Title') = $dom->loadStr($titleColumn)->find('a')->text;
$names = $dom->loadStr($titleColumn)->find('a')->getAttributes()('title');
$arr('Director') = array_shift(explode(" (dir.), ", $names));
$arr('Leads') = array_pop(explode(" (dir.), ", $names));
$arr('URL') = $baseUrl.$dom->loadStr($titleColumn)->find('a')->getAttributes()('href');
$arr('ImageURL') = $dom->loadStr($posterColumn)->find('img')->getAttributes()('src');
$arr('Rating') = $dom->loadStr($ratingColumn)->find('strong')->text;
$ratingText = $dom->loadStr($ratingColumn)->find('strong')->getAttributes()('title');
preg_match_all("/(0-9,)+/", $ratingText, $reviews);
$arr('NoOfReviews') = str_replace(",", "", array_pop($reviews(0)));
$arr('ReleaseYear') = str_replace(("(", ")"), "", $dom->loadStr($titleColumn)->find('span')->text);
if ($mId == 0) {
fputcsv($file, array_keys($arr));
}
fputcsv($file, $arr);
}Als Ergebnis unserer harten Arbeit erhalten wir den folgenden Datensatz, der alle Filme enthält, nach denen wir gesucht haben. Laden Sie die Liste hier herunter.
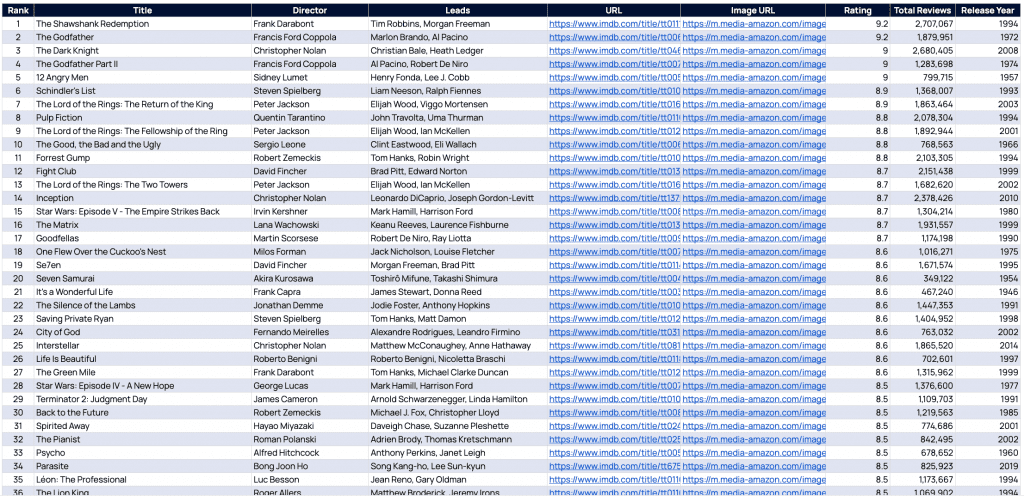
Web Scraping mit PHP ist einfach (oder auch nicht!)
Puh! Da haben wir ziemlich viel Material behandelt, nicht wahr? Das ist im Grunde die Art und Weise, wie man einen Crawler erstellt, aber wir müssen verstehen, dass die Webverarbeitung für Benutzer konzipiert ist und nicht für Crawler.
Wenn die Datenextraktion willkürlich durchgeführt wird, entzieht sie den Webservern teure Verarbeitungszeit und schadet ihrem Geschäft, da die tatsächlichen Benutzer den Dienst nicht erhalten.
Dies hat dazu geführt, dass Quellwebsites verschiedene Blockierungstechniken einsetzen, um die Crawler daran zu hindern, Anfragen an ihre Server zu senden.
Bei kleineren Projekten können Sie den Crawler auch selbst schreiben. Wenn jedoch der Umfang des Projekts zunimmt, können die auftretenden Komplikationen zu groß sein, als dass ein kleines Team sie bewältigen könnte, geschweige denn eine Einzelperson.
Grepsr ist mit seiner langjährigen Erfahrung in der Datenextraktion darauf spezialisiert, Informationen aus dem Web zu extrahieren, ohne die Funktion der Webserver zu beeinträchtigen. Lesen Sie hier über die Rechtmäßigkeit von Web Scraping:
Wir hoffen, dass Sie nun über das grundlegende Know-how verfügen, um einen Web-Scraper mit PHP zu erstellen. Wenn Sie jemals das Bedürfnis verspüren, Ihre Datenextraktionsbemühungen zu erweitern, zögern Sie nicht, uns anzurufen. Wir helfen Ihnen gerne weiter.
Verwandte Lektüre:
