
In diesem Tutorial verwenden wir Python, um Produktdaten von der Walmart-Website zu extrahieren. Wir werden verschiedene Möglichkeiten zum Parsen und Extrahieren der benötigten Daten untersuchen und einige der potenziellen Herausforderungen besprechen, die mit Web Scraping verbunden sind.
Warum Walmart-Produktdaten löschen?
Walmart bietet in seinem Online-Shop eine große Auswahl an Produkten an, was es zu einem idealen Kandidaten für Web-Scraping-Projekte macht. Durch den Einsatz von Web-Scraping-Techniken können Sie die Erfassung von Produktdaten wie Preisen, Verfügbarkeit, Bildern, Beschreibungen, Bewertungen, Rezensionen und mehr automatisieren. Diese Daten können Sie dann in Ihren Anwendungen oder Analyseprojekten verwenden.
Einführung in Walmart Scraping
Um Produktdaten zu extrahieren, müssen Sie diese zunächst analysieren. Schauen wir uns die Produktseite an – sie sind alle vom gleichen Typ, und nachdem Sie eines analysiert haben, können Sie die benötigten Webdaten mithilfe des geschriebenen Skripts extrahieren.
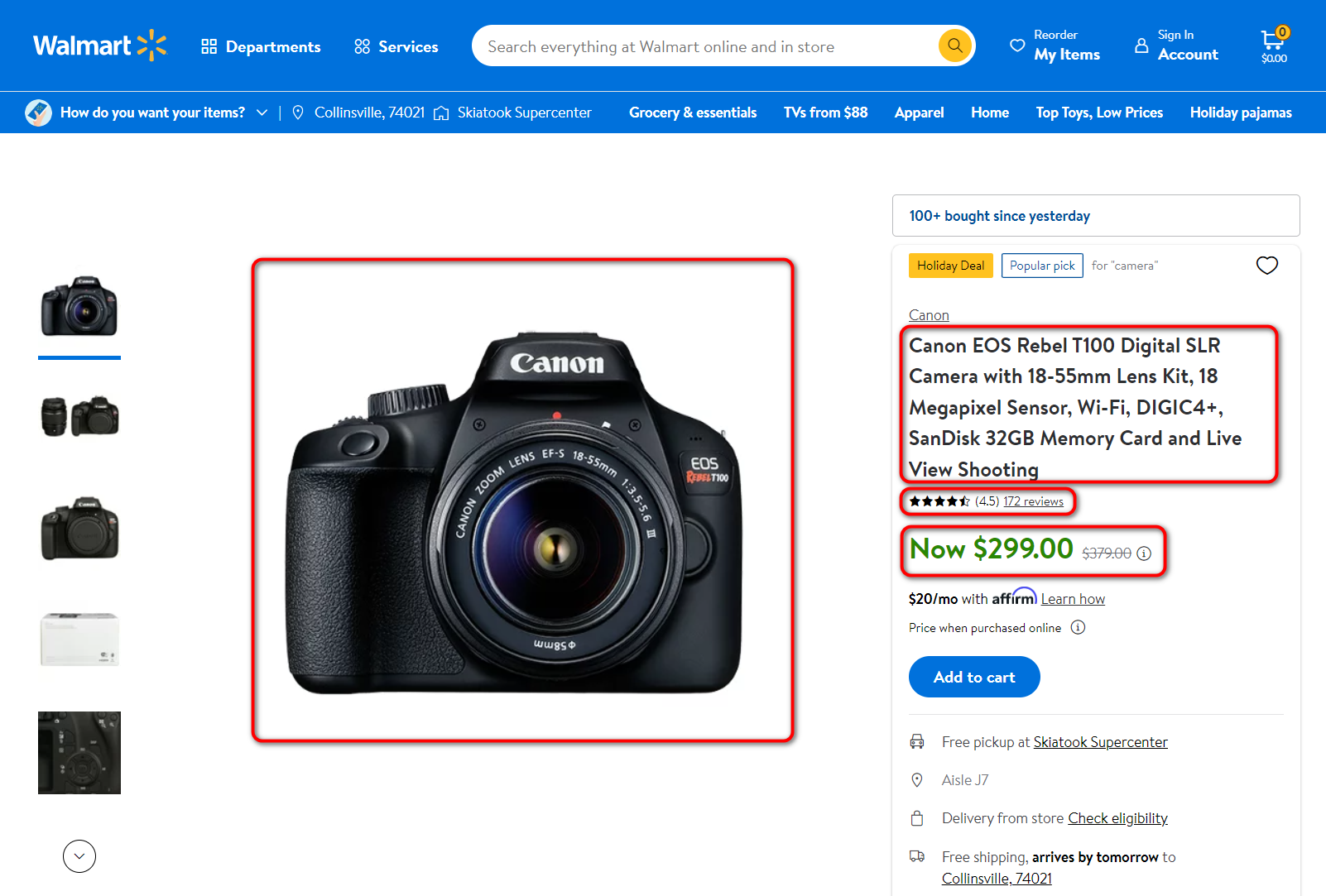
Wir sind an folgenden Bereichen zum Schaben interessiert:
- Produktname
- Produktpreis
- Die Anzahl der Bewertungen
- Bewertung
- Hauptbild
Natürlich benötigen Sie möglicherweise andere Felder mit anderen Daten für bestimmte Zwecke wie Beschreibung oder Marke, aber wir werden in diesem Beispiel nur die primären Produktdaten berücksichtigen. Die anderen Details können auf die gleiche Weise extrahiert werden. Lassen Sie uns als Beispiel einen Scraper erstellen, der Links aus einer CSV-Datei sammelt, jedem einzelnen Link folgt und die resultierenden Daten in einer anderen Datei speichert. Lesen Sie auch darüber cURL zu Python.
Sie können auch Produkt-URLs von Seiten und Kategorien mithilfe eines Skripts sammeln, um alle Produkte zu sammeln. Wir werden in diesem Handbuch jedoch nicht darauf eingehen. Wir haben zuvor einen Artikel über das Scraping von Daten von Amazon veröffentlicht und untersucht, wie Sie den Übergang zur Suchergebnisseite organisieren und alle Produktlinks sammeln können. Für Walmart kann dies ähnlich erfolgen.
Das Extrahieren von Daten ist bei Walmart problematisch genug, da das Unternehmen Produkt-Scraping nicht unterstützt und über ein Anti-Spam-System verfügt. Das Verfolgen und Blockieren von IP-Adressen wird wahrscheinlich die meisten Scraper blockieren, die versuchen, auf ihre Website zuzugreifen. Bevor wir einen Walmart-Scraper in Python erstellen, beachten wir daher, dass Sie sich beim Schreiben Ihres eigenen Scrapers auch um die Umgehung von Blöcken kümmern müssen.
Wenn es keine Möglichkeit oder Zeit gibt, ein System zur Umgehung von Sperren zu organisieren, können Sie Daten mithilfe der Web-Scraping-API scrapen, wodurch diese Probleme gelöst werden. Wie Sie Walmart mithilfe unserer API durchsuchen, erfahren Sie am Ende des Artikels ausführlich.
Installieren von Python-Bibliotheken für Scraping
Bevor wir nach Elementen zum Scrapen suchen, erstellen wir eine Python-Datei und fügen die erforderlichen Bibliotheken hinzu. Wir werden verwenden:
- Die Requests-Bibliothek zum Ausführen von Anfragen.
- Die BeautifulSoup-Bibliothek zur Vereinfachung des Parsens der Webseite.
Wenn Sie nicht über die BeautifulSoup-Bibliothek verfügen (die Anforderungsbibliothek ist integriert), verwenden Sie den folgenden Befehl in der Befehlszeile:
pip install beautifulsoup4Fügen Sie diese Bibliotheken in eine Python-Datei ein:
from bs4 import BeautifulSoup
import requestsLassen Sie uns die Datei erstellen oder löschen (überschreiben), in der wir die Daten von Walmart speichern. Benennen wir diese Datei result.csv und definieren wir die darin enthaltenen Spalten:
with open("result.csv", "w") as f:
f.write("title; price; rating; reviews; image\n")Öffnen Sie anschließend die Datei links.csv, in der Links zu Produktseiten gespeichert werden, die wir durchsuchen. Wir werden sie alle der Reihe nach durchgehen und für jede eine Datenverarbeitung durchführen. Der folgende Code wird es tun:
with open("links.csv", "r+") as links:
for link in links:Jetzt erhalten wir den gesamten Code der Seite, mit dem wir weiterarbeiten werden, und analysieren ihn mit BeautifulSoup:
html_text = requests.get(link).text
soup = BeautifulSoup(html_text, 'lxml')Zu diesem Zeitpunkt haben wir bereits den Produktseitencode und können ihn beispielsweise mit print(soup) anzeigen.
Weg 1. Den Seitentext analysieren
Um nur die notwendigen Informationen auszuwählen, analysieren wir die Seite, um Selektoren und Attribute zu finden, die die wesentlichen Daten eindeutig beschreiben.
Gehen wir zur Walmart-Website und schauen uns noch einmal die Produktseite an. Lassen Sie uns zuerst den Produkttitel finden. Gehen Sie dazu zu DevTools (F12) und suchen Sie den Elementcode (Strg + Umschalt + C und wählen Sie das Element aus):
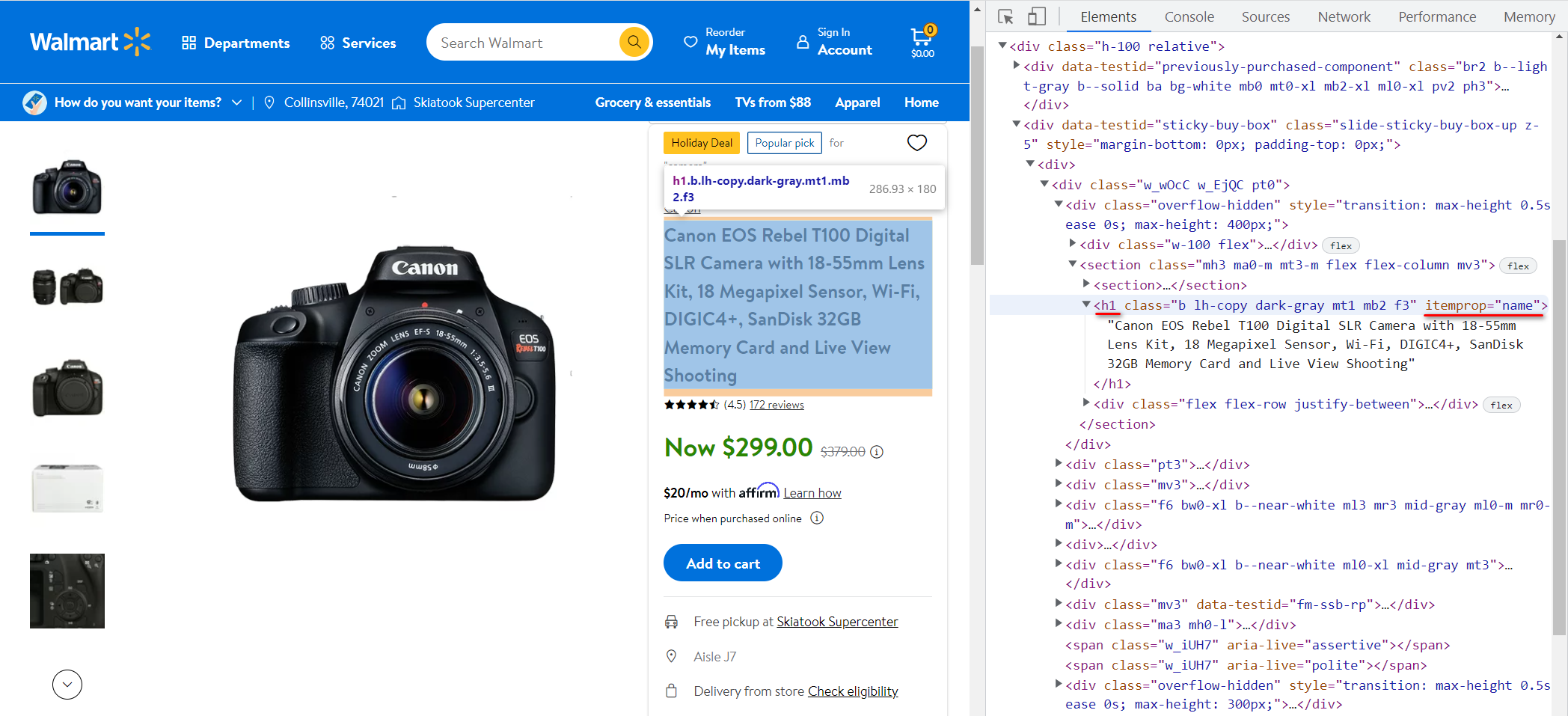
In diesem Fall ist es in der <h1> Tag und sein itemprop-Attribut hat den Wert „name„. Geben wir den Wert des in diesem Tag gespeicherten Textes in die Variable title ein:
title = soup.find('h1', attrs={'itemprop': 'name'}).textMachen wir dasselbe, aber jetzt zum Preis:
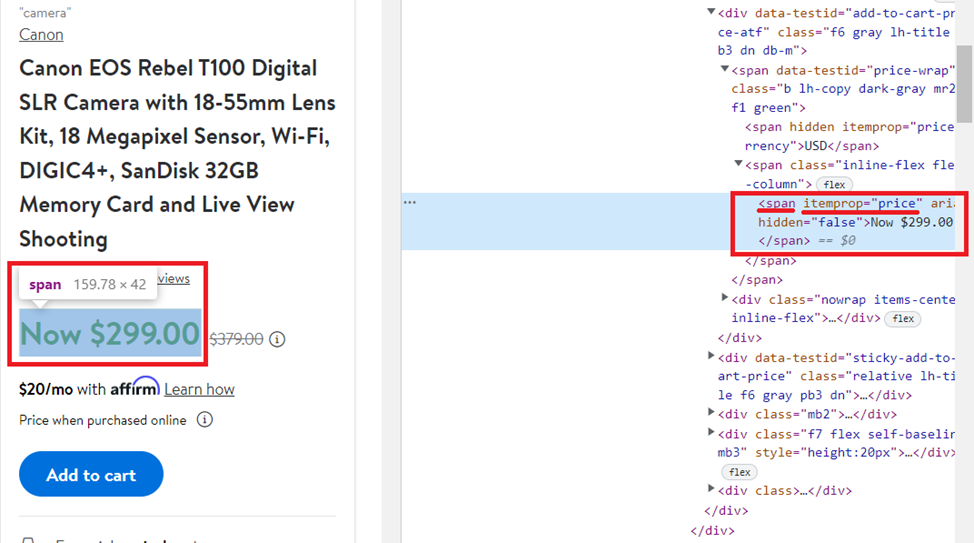
Holen Sie sich den Inhalt des <span> Tag mit dem Wert des itemprop-Attributs gleich „price„:
price = soup.find('span', attrs={'itemprop': 'price'}).textZur Überprüfung und Bewertung wird die Analyse auf ähnliche Weise durchgeführt, sodass wir ein fertiges Ergebnis schreiben:
reviews = soup.find('a', attrs={'itemprop': 'ratingCount'}).text
rating = soup.find('span', attrs={'class': 'rating-number'}).textBeim Bild ist alles etwas anders. Schauen wir uns die Produktseite und den Artikelcode an:
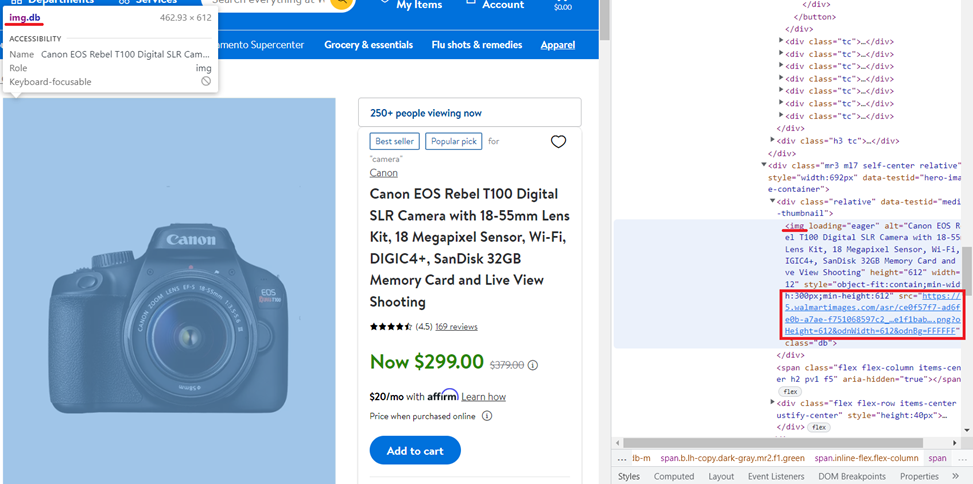
Dieses Mal müssen Sie den Wert des src-Attributs abrufen, der im gespeichert ist <img> Tag mit dem „db„Klasse und Ladeattribut gleich“eager„. Dank der BeautifulSoup-Bibliothek ist dies ganz einfach:
image = soup.find('img', attrs={'class': 'db','loading': 'eager'})("src")Wir sollten bedenken, dass in diesem Fall nicht jede Seite das Bild zurückgibt. Daher ist es besser, Informationen aus dem Meta-Tag zu verwenden:
image = soup.find('meta', property="og:image")("content")Wenn wir mit den oben genannten Variablen beginnen, erhalten wir die folgenden Produktdetails:
Canon EOS Rebel T100 Digital SLR Camera with 18-55mm Lens Kit, 18 Megapixel Sensor, Wi-Fi, DIGIC4+, SanDisk 32GB Memory Card and Live View Shooting
Now $299.00
172 reviews
(4.5)
https://i5.walmartimages.com/asr/ce0f57f7-ad6f-4e0b-a7ae-f751068597c2_1.b7e1f1bab1fd7f98cb9aef1ae9b783fb.pngSpeichern wir die empfangenen Daten in der zuvor erstellten/gelöschten Datei:
try:
with open("result.csv", "a") as f:
f.write(str(title)+"; "+str(price)+"; "+str(reviews)+"; "+str(rating)+"; "+str(image)+"\n")
except Exception as e:
print("There is no data")Es empfiehlt sich, dies in einem try…exclusive-Block zu tun, denn wenn keine Daten vorhanden sind oder der Link nicht korrekt angegeben ist, wird die Programmausführung unterbrochen. Mit dem try…exclusive-Block können Sie einen solchen Fehler „abfangen“, ihn melden und das Programm fortsetzen.
Wenn Sie dieses Programm ausführen, werden die gescrapten Daten in der Datei result.csv gespeichert:

Hier sehen wir mehrere Probleme. Erstens gibt es zusätzlichen Text in den Spalten Preis, Rezensionen und Bewertung. Zweitens: Wenn es einen Rabatt gibt, werden in der Preisspalte möglicherweise falsche Informationen oder zwei Preise angezeigt.
Natürlich ist es kein Problem, bei regulären Ausdrücken nur numerische Werte zu belassen, aber warum sollte man die Aufgabe verkomplizieren, wenn es einen einfacheren Weg gibt?
Weg 2. Parsen der strukturierten JSON-LD-Daten
Wenn Sie sich den Seitencode genau ansehen, werden Sie feststellen, dass alle notwendigen Informationen nicht nur im Seitenkörper gespeichert sind. Achten wir darauf <head>…</head> Tag, genauer gesagt zu seinem <script nonce type="application/ld+json">…</script> Etikett.
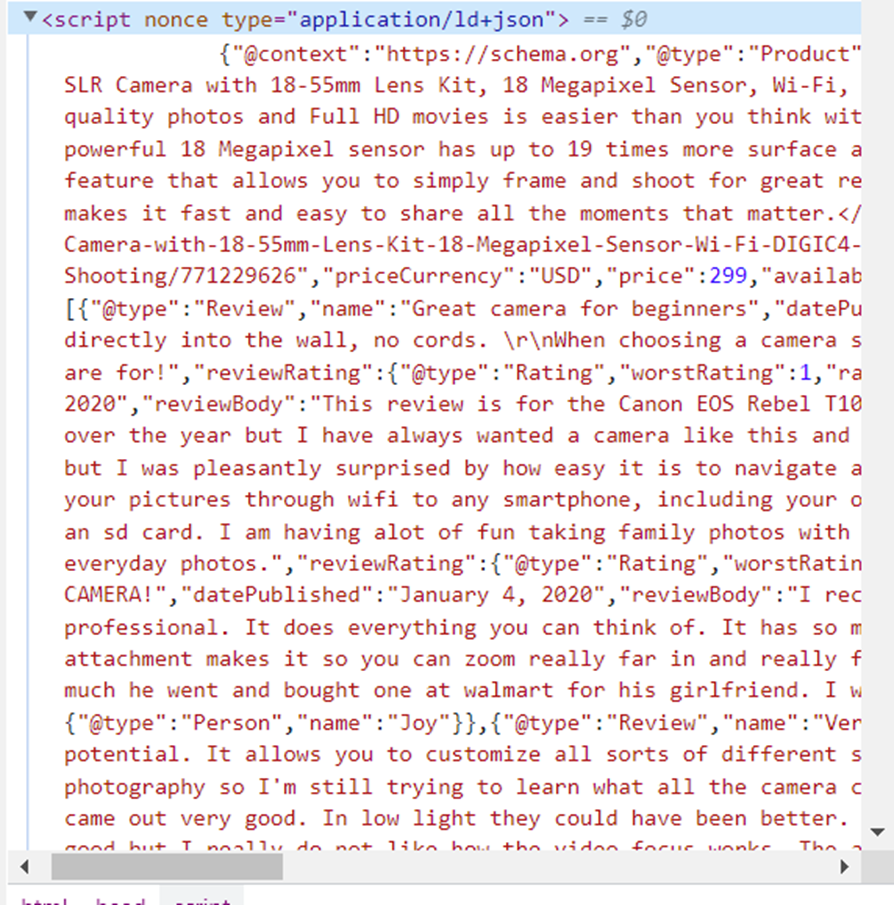
Dies ist das Schema-Markup „Produkt“ im JSON-Format. Das Produktschema ermöglicht das Hinzufügen spezifischer Produktattribute zu Produktlisten, die als Rich-Suchergebnisse auf der Ergebnisseite der Suchmaschine (SERP) angezeigt werden können. Kopieren wir es und formatieren es in eine praktische Form für die Recherche:
{
"@context": "https://schema.org",
"@type": "Product",
"image": "https://i5.walmartimages.com/asr/ce0f57f7-ad6f-4e0b-a7ae-f751068597c2_1.b7e1f1bab1fd7f98cb9aef1ae9b783fb.png",
"name": "Canon EOS Rebel T100 Digital SLR Camera with 18-55mm Lens Kit, 18 Megapixel Sensor, Wi-Fi, DIGIC4+, SanDisk 32GB Memory Card and Live View Shooting",
"sku": "771229626",
"gtin13": "013803300550",
"description": "<p>Creating distinctive stories with DSLR quality photos and Full HD movies is easier than you think with the 18 Megapixel Canon EOS Rebel T100. Share instantly and shoot remotely via your compatible smartphone with Wi-Fi and the Canon Camera Connect app. The powerful 18 Megapixel sensor has up to 19 times more surface area than many smartphones, and you can instantly transfer photos and movies to your smart device. The Canon EOS Rebel T100 has a Scene Intelligent Auto feature that allows you to simply frame and shoot for great results. It also features Guided Live View shooting with Creative Auto mode, and you can add unique finishes with Creative Filters. The Canon EOS Rebel T100 makes it fast and easy to share all the moments that matter.</p>",
"model": "T100",
"brand": {
"@type": "Brand",
"name": "Canon"
},
"offers": {
"@type": "Offer",
"url": "https://www.walmart.com/ip/Canon-EOS-Rebel-T100-Digital-SLR-Camera-with-18-55mm-Lens-Kit-18-Megapixel-Sensor-Wi-Fi-DIGIC4-SanDisk-32GB-Memory-Card-and-Live-View-Shooting/771229626",
"priceCurrency": "USD",
"price": 299,
"availability": "https://schema.org/InStock",
"itemCondition": "https://schema.org/NewCondition",
"availableDeliveryMethod": "https://schema.org/OnSitePickup"
},
"review": (
{
"@type": "Review",
"name": "Great camera for beginners",
"datePublished": "January 4, 2020",
"reviewBody": "Love this camera....",
"reviewRating": {
"@type": "Rating",
"worstRating": 1,
"ratingValue": 5,
"bestRating": 5
},
"author": {
"@type": "Person",
"name": "Sparkles"
}
},
{
"@type": "Review",
"name": "Perfect for beginners",
"datePublished": "January 7, 2020",
"reviewBody": "I am so in love with this camera!...",
"reviewRating": {
"@type": "Rating",
"worstRating": 1,
"ratingValue": 5,
"bestRating": 5
},
"author": {
"@type": "Person",
"name": "Brazilchick32"
}
},
{
"@type": "Review",
"name": "Great camera",
"datePublished": "January 17, 2020",
"reviewBody": "I really love all the features this camera has. Every time I use it, I'm discovering a new one. I'm pretty technologically challenged, but this hasn't hindered me. The zoom and focus give very detailed and sharp images. I cannot wait to take it on my next trip as right now I've only photographed the dog a million times",
"reviewRating": {
"@type": "Rating",
"worstRating": 1,
"ratingValue": 5,
"bestRating": 5
},
"author": {
"@type": "Person",
"name": "userfriendly"
}
}
),
"aggregateRating": {
"@type": "AggregateRating",
"ratingValue": 4.5,
"bestRating": 5,
"reviewCount": 172
}
}Jetzt ist es offensichtlich, dass diese Informationen ausreichen und in einer bequemeren Form gespeichert werden. Das heißt, es ist notwendig, den Inhalt der zu lesen <head>…</head> Tag und wählen Sie daraus ein Tag aus, das Daten in JSON speichert. Setzen Sie dann die Variablen auf die folgenden Werte:
-
Titelwert des
(name)Attribut. -
Preiswert der
(offers)(price)Attribut. -
Bewertungen Wert der
(aggregateRating)(reviewCount)Attribut. -
Bewertungswert des
(aggregateRating)(ratingValue)Attribut. -
Bildwert der
(image)Attribut.
Um mit JSON arbeiten zu können, reicht es aus, die integrierte Bibliothek einzubinden:
import jsonErstellen wir eine Datenvariable, in die wir die JSON-Daten einfügen:
data = (json.loads(soup.find('script', attrs={'type': 'application/ld+json'}).text))Danach geben wir die Daten in die entsprechenden Variablen ein:
title = data('name')
price = data('offers')('price')
reviews = data('aggregateRating')('reviewCount')
rating = data('aggregateRating')('ratingValue')
image = data('image')Der Rest bleibt gleich. Überprüfen Sie die Skriptausführung:
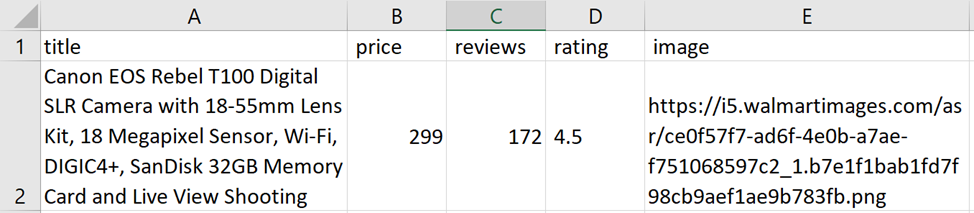
Vollständiges Skript:
from bs4 import BeautifulSoup
import requests
import json
with open("result.csv", "w") as f:
f.write("title; price; rating; reviews; image\n")
with open("links.csv", "r+") as links:
for link in links:
html_text = requests.get(link).text
soup = BeautifulSoup(html_text, 'lxml')
data = (json.loads(soup.find('script', attrs={'type': 'application/ld+json'}).text))
title = data('name')
price = data('offers')('price')
reviews = data('aggregateRating')('reviewCount')
rating = data('aggregateRating')('ratingValue')
image = data('image')
try:
with open("result.csv", "a") as f:
f.write(str(title)+"; "+str(price)+"; "+str(reviews)+"; "+str(rating)+"; "+str(image)+"\n")
except Exception as e:
print("There is no data")Walmart Anti-Bot-Schutz
Wie am Anfang des Artikels erwähnt, überwacht der Dienst jedoch Aktivitäten, die wie Bots aussehen, blockiert sie und bietet an, das Captcha zu lösen. Anstatt also eine Seite mit Daten zu erhalten, wird einmal eine andere Seite angezeigt:

Dies ist ein Vorschlag zur Lösung des Captchas. Um dies zu vermeiden, sollten Sie die zuvor beschriebenen Bedingungen einhalten.
Sie können dem Code auch Header hinzufügen, wodurch die Wahrscheinlichkeit einer Blockierung etwas verringert wird:
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36"}Dann sieht die Anfrage etwas anders aus:
html_text = requests.get(link, headers=headers).textDas Ergebnis des Schabers:
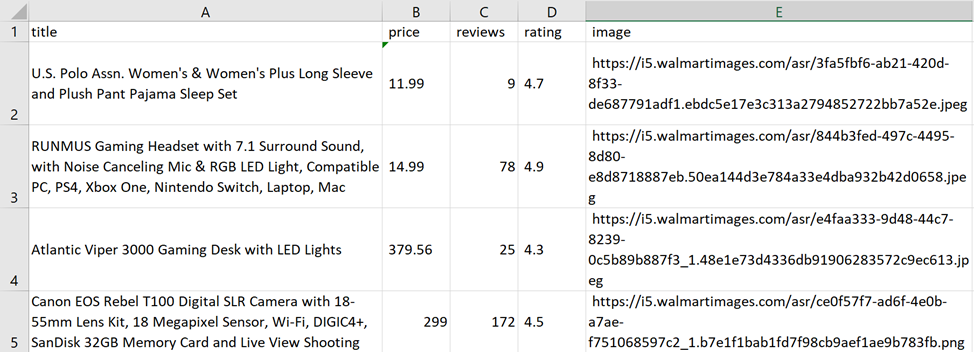
Leider hilft dies auch nicht immer, Blockaden zu vermeiden. Hier kommt die Web-Scraping-API ins Spiel.
Scrapen Sie Walmart-Produktdaten mit der Web Scraping API
Schauen wir uns einen Anwendungsfall für die Web-Scraping-API an, der sich um die Blockierungsvermeidung kümmert. Ein Teil des zuvor beschriebenen Skripts wird sich nicht ändern. Wir werden es nur ändern.
Erstellen Sie ein scrape-it.cloud-Konto. Danach erhalten Sie 1.000 Credits. Sie benötigen einen API-Schlüssel, den Sie in Ihrem Konto im Dashboard-Bereich finden:
Wir benötigen auch die JSON-Bibliothek, also fügen wir sie dem Projekt hinzu:
import jsonNun weisen wir der URL-Variablen den API-Wert zu und fügen den API-Schlüssel und den Inhaltstyp in die Header ein:
url = "https://api.scrape-it.cloud/scrape"
headers = {
'x-api-key': 'YOUR-API-KEY',
'Content-Type': 'application/json'
}So fügen Sie eine dynamische Abfrage hinzu:
temp = """{
"url": """+"\""+str(link)+"\""+""",
"block_resources": False,
"wait": 0,
"screenshot": True,
"proxy_country": "US",
"proxy_type": "datacenter"
}"""
payload = json.dumps(temp)
response = requests.request("POST", url, headers=headers, data=payload)Rufen Sie die Daten in „content“ ab, die den Code der Walmart-Seite speichern:
html_text = json.loads(response.text)("scrapingResult")("content")Schauen wir uns den vollständigen Code an:
from bs4 import BeautifulSoup
import requests
import json
url = "https://api.scrape-it.cloud/scrape"
headers = {
'x-api-key': 'YOUR-API-KEY',
'Content-Type': 'application/json'
}
with open("result.csv", "w") as f:
f.write("title; price; rating; reviews; image\n")
with open("links.csv", "r+") as links:
for link in links:
html_text = requests.get(link).text
soup = BeautifulSoup(html_text, 'lxml')
data = (json.loads(soup.find('script', attrs={'type': 'application/ld+json'}).text))
title = data('name')
price = data('offers')('price')
reviews = data('aggregateRating')('reviewCount')
rating = data('aggregateRating')('ratingValue')
image = data('image')
try:
with open("result.csv", "a") as f:
f.write(str(title)+"; "+str(price)+"; "+str(reviews)+"; "+str(rating)+"; "+str(image)+"\n")
except Exception as e:
print("There is no data")Zusätzlich zu den angegebenen Attributen können weitere im Anfragetext festgelegt werden. Mehr erfahren Sie im Dokumentation Oder probieren Sie es in Ihrem Konto auf der Registerkarte „Web-Scraping-API“ aus.
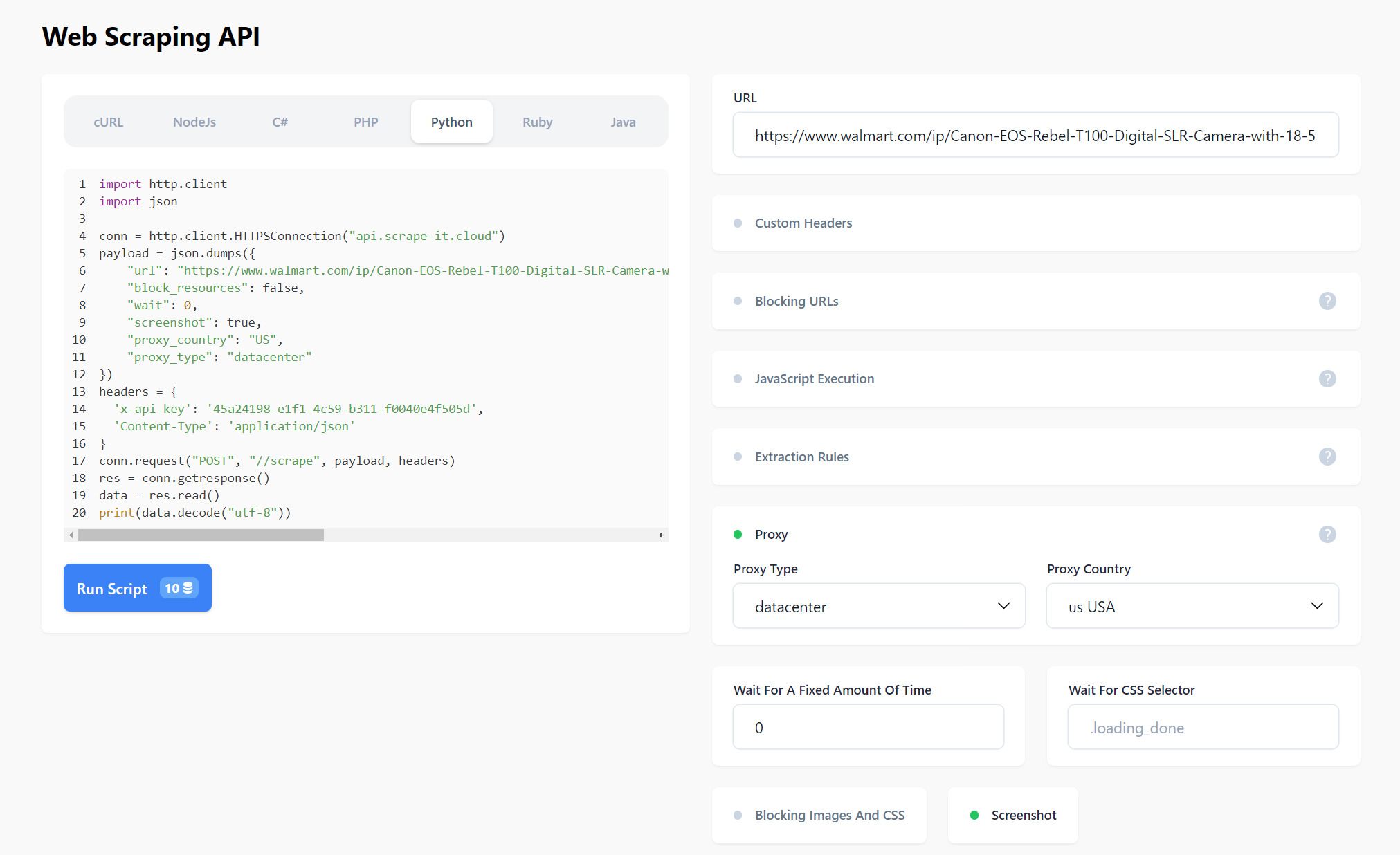
Sie können die Anfrage visuell stellen und dann den Code in einer der unterstützten Programmiersprachen erhalten.
Fazit und Erkenntnisse
Das Auffinden und Scrapen von Daten für den E-Commerce ist eine zeitaufwändige Aufgabe, insbesondere wenn sie manuell durchgeführt wird. Es ist auch schwer zu wissen, ob es genaue, objektive Daten sind, die Ihnen helfen, die richtigen Geschäftsentscheidungen zu treffen.
Ohne hochwertige Daten ist es schwierig, die Marketingstrategien zu entwickeln und umzusetzen, die Ihr Unternehmen benötigt, um zu wachsen, erfolgreich zu sein und die Bedürfnisse der Kunden zu erfüllen. Es kann sich auch auf Ihren Ruf auswirken, da Sie möglicherweise als unzuverlässig wahrgenommen werden, wenn Ihre Kunden oder Partner feststellen, dass Ihre Daten unzuverlässig sind.
Das Scraping von Walmart-Produktdaten mit Python ist eine großartige Möglichkeit, schnell große Mengen wertvoller Informationen über die auf der Website verfügbaren Produkte zu sammeln. Durch die Verwendung leistungsstarker Bibliotheken wie Beautiful Soup und Selenium zusammen mit XPath-Abfragen oder Regexes können Entwickler ganz einfach bestimmte Informationen von jeder gewünschten Webseite extrahieren und sie in strukturierte Datensätze umwandeln, die sie in ihren Anwendungen oder Analyseprojekten verwenden können. Und wenn Sie die Web-Scraping-API zur Automatisierung des Datenerfassungsprozesses verwenden, müssen Sie sich keine Gedanken über Blockierung, Captcha, Proxying, die Verwendung von Headern und vieles mehr machen.
