
Über 7,59 Millionen aktive Websites nutzen Cloudflare. Wenn Sie es nicht sagen können, ist das eine große Zahl! Und die Wahrscheinlichkeit, dass Sie auf eine durch Cloudflare geschützte Website stoßen, ist sehr hoch.
Wenn Sie versucht haben, solche Websites zu scannen, wissen Sie vielleicht bereits, wie schwierig es ist, das automatisierte Bot-Erkennungssystem von Cloudflare zu umgehen. Heute haben Sie Glück, denn Sie lernen, wie Sie mit Python Cloudflare-geschützte Websites durchsuchen.
Dazu nutzen Sie das wunderbare Open-Source-Projekt Cloudscraper. Am Ende werden Sie auch die Grenzen dieses Projekts erkennen und erfahren, warum ScraperAPI eine leistungsfähigere und zuverlässigere Alternative zu Cloudscraper ist.
Notiz: Cloudflare ändert ständig sein Bot-Erkennungssystem und zerstört Open-Source-Projekte wie Cloudscraper. Wenn Sie Ihre Zeit schätzen und große Scraping-Jobs haben, die eine Skalierung oder Intervallplanung erfordern, sollten Sie die Verwendung von ScraperAPI in Betracht ziehen. Mit diesem Tool können Sie Domänen in vielen gleichzeitigen Threads durchsuchen, ohne von den Blockern von Cloudflare blockiert zu werden.
So verwenden Sie Cloudscraper zum Scrapen von Cloudflare-geschützten Websites
Sehen wir uns an, wie Sie ein Cloudscraper-Projekt einrichten, um Glassdoor-Seiten in geringem Umfang zu scrappen.
Wenn Sie ein fortgeschrittener Web-Scraping-Benutzer sind, sollten Sie mit der anderen im Artikel beschriebenen Methode fortfahren – der Verwendung von ScraperAPI. Durch die Verwendung der API können Sie eine höhere Skalierbarkeit erreichen, Jobs planen und das Scraping von Cloudflare-geschützten Websites automatisieren.
Schritt 1. Einrichten der Voraussetzungen
Stellen Sie sicher, dass Python auf Ihrem System installiert ist. Für dieses Tutorial können Sie Python Version 3.6 oder höher verwenden. Erstellen Sie ein neues Verzeichnis, in dem der gesamte Code für dieses Projekt gespeichert wird, und erstellen Sie ein app.py Datei in:
$ mkdir web_scraper
$ cd web_scraper
$ touch app.py
Als nächstes müssen Sie installieren cloudscraper Und requests. Das geht ganz einfach über PIP:
$ pip install cloudscraper requests
Schritt 2. Erstellen einer einfachen Anfrage mithilfe von Anfragen
In diesem Tutorial werden Sie Glassdoor scrapen. So sieht die Homepage von Glassdoor aus:
Diese Website ist durch Cloudflare geschützt und kann nicht einfach durch Anfragen gelöscht werden. Sie können dies bestätigen, indem Sie ein einfaches erstellen GET Anfrage mit requests so was:
import requests
html = requests.get("https://www.glassdoor.com/")
print(html.status_code)
# 403
Wie erwartet gibt Glassdoor den Statuscode 403 Forbidden zurück und nicht die tatsächlichen Suchergebnisse. Dieser Statuscode wird vom Cloudflare Bot-Erkennungssystem zurückgegeben, das Glassdoor verwendet. Sie können die Antwort in einer lokalen Datei speichern und in Ihrem Browser öffnen, um besser zu verstehen, was vor sich geht.
Mit diesem Code können Sie die Antwort speichern:
with open("response.html", "wb") as f:
f.write(html.content)
Wenn Sie die öffnen response.html Wenn Sie die Datei in Ihrem Browser öffnen, sollten Sie etwa Folgendes sehen:
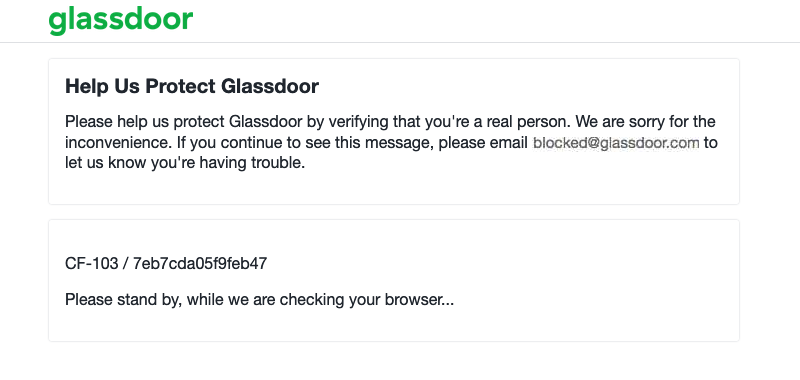
Nachdem Sie nun wissen, dass Ihre Zielwebsite durch Cloudflare geschützt wird, haben Sie irgendwelche praktikablen Möglichkeiten, dies zu umgehen?
Schritt 3. Scrapen von Glassdoor.com mit Cloudscraper
Glücklicherweise kommt hier Cloudscraper ins Spiel. Es basiert auf Anfragen und verfügt über eine intelligente Logik, um die von Cloudflare zurückgegebene Herausforderungsseite zu analysieren und die entsprechende Antwort zu senden, um das Problem erfolgreich zu umgehen. Die größte Einschränkung besteht darin, dass es nur die Cloudflare-Bot-Erkennung Version 1 und nicht Version 2 umgehen kann. Wenn Ihre Zielwebsite jedoch die Bot-Erkennung Version 1 verwendet, ist dies eine sehr vernünftige Lösung. Wir werden diese Einschränkung in einem nächsten Schritt ausführlich besprechen.
Eine weitere bemerkenswerte Tatsache ist, dass Cloudscraper standardmäßig keine vollständige Browser-Engine ausführt. Daher ist es erheblich schneller als andere ähnliche Lösungen, die auf Headless-Browsern oder Browser-Emulation basieren.
Notiz: Wenn Sie versuchen, eine Website zu crawlen, die Version 2 des Bot-Erkennungssystems von Cloudflare verwendet, können Sie etwas Zeit sparen und bis zum Ende dieses Tutorials springen und sich über ScraperAPI informieren, da dies eine mögliche Lösung für Ihren Anwendungsfall ist.
Wiederholen wir dasselbe GET Anfrage an Glassdoor.com, diesmal jedoch mit Cloudscraper. Öffnen Sie die Python REPL und geben Sie diesen Code ein:
import cloudscraper
scraper = cloudscraper.create_scraper()
html = scraper.get("https://www.glassdoor.com/")
print(html.status_code)
# 200
Süß! Cloudflare hat unsere Anfrage dieses Mal nicht blockiert. Speichern Sie den HTML-Code wie im vorherigen Schritt in einer lokalen Datei und öffnen Sie ihn in Ihrem Browser. Sie sollten die Homepage von Glassdoor sehen. Die Benutzeroberfläche ist aufgrund defekter CSS- und JS-Links etwas seltsam (da wir CSS und JSON nicht lokal gespeichert haben), aber alle Daten sind vorhanden:

Durch die Änderung einiger Codezeilen konnten Sie das Bot-Erkennungssystem von Cloudflare umgehen!
Schritt 4. Erweiterte Optionen von Cloudscraper verwenden
Cloudscraper bietet sofort eine Vielzahl konfigurierbarer Optionen. Werfen wir einen Blick auf einige davon.
4.1 Integrierte Unterstützung für Captcha-Löser
Cloudscraper bietet integrierte Unterstützung für einige Captcha-Löser von Drittanbietern, falls Sie diese benötigen. Wenn Ihre Anfragen beispielsweise eine Captcha-Seite erreichen, können Sie 2captcha einfach mit Cloudscraper als Captcha-Lösungsanbieter verbinden:
scraper = cloudscraper.create_scraper(
captcha={
'provider': '2captcha',
'api_key': 'your_2captcha_api_key'
}
)
Bisher unterstützt Cloudscraper die folgenden Captcha-Dienste standardmäßig:
4.2 Verwendung eines benutzerdefinierten Proxys
In den meisten Fällen möchten Sie den gesamten Scraping-Verkehr über einen Proxy leiten. Dadurch wird sichergestellt, dass Ihre echte IP-Adresse maskiert wird und nicht von der Zielwebsite aufgrund übermäßiger Anfragen gesperrt wird. Glücklicherweise bietet Cloudscraper Unterstützung für die Verwendung benutzerdefinierter Proxys. Dies ist ein Nebeneffekt der Tatsache, dass Cloudscraper auf dem Erstaunlichen basiert requests Bibliothek.
Wenn Sie mit Cloudscraper einen benutzerdefinierten Proxy verwenden möchten, können Sie ein Wörterbuch definieren, das die HTTP- und HTTPS-Proxy-Endpunkte enthält, und Cloudscraper stellt sicher, dass für alle zukünftigen Anfragen das entsprechende Wörterbuch verwendet wird. Hier ist ein Code, der dies demonstriert:
import cloudscraper
proxies = {"http": "http://localhost:8080", "https": "http://localhost:8080"}
scraper = cloudscraper.create_scraper()
scraper.proxies.update(proxies)
html = scraper.get("https://www.glassdoor.com/")
print(html.status_code)
# 200
Sie können dieses benutzerdefinierte Proxy-Setup weiter verbessern, indem Sie Logik für rotierende Proxys hinzufügen. Sehen Sie sich diesen anderen Artikel auf unserer Website an, um zu erfahren, wie das geht.
4.3 Nur das Cloudflare-Token extrahieren
Wenn Sie die Cloudflare-Bot-Erkennung umgehen, antwortet Cloudflare mit einem Cookie, das bei allen Folgeanfragen an die Zielwebsite übergeben werden muss. Dieses Cookie informiert Cloudflare darüber, dass Ihr Browser die Bot-Erkennungsherausforderung bereits bestanden hat und ohne weitere Herausforderungen bestehen sollte. Cloudscraper bietet praktische Methoden zum Extrahieren dieses Cookies (oder der darin enthaltenen Token). So können Sie sie verwenden:
import cloudscraper
tokens, user_agent = cloudscraper.get_tokens("https://www.glassdoor.com/")
print(tokens)
# {
# 'cf_clearance': 'c8f913c707b818b47aa328d81cab57c349b1eee5-1426733163-3600',
# '__cfduid': 'dd8ec03dfdbcb8c2ea63e920f1335c1001426733158'
# }
cookie_value, user_agent = cloudscraper.get_cookie_string("https://www.glassdoor.com/")
print(cookie_value)
# cf_clearance=c8f913c707b818b47aa328d81cab57c349b1eee5-1426733163-3600; __cfduid=dd8ec03dfdbcb8c2ea63e920f1335c1001426733158
Dies ist sehr nützlich, da Sie mit Cloudscraper das Bot-Erkennungssystem umgehen und die resultierenden Cookies dann mit den Folgeanfragen Ihres bereits vorhandenen Web-Scraping-Codes verwenden können. Sie müssen lediglich sicherstellen, dass die Folgeanfragen von derselben IP generiert werden, die bei der Umgehung des Bot-Erkennungssystems verwendet wurde. Wenn die IPs unterschiedlich sind, blockiert Cloudflare Ihre Anfrage und fordert Sie zu einer erneuten Bestätigung auf.
Einschränkungen von Cloudscraper: Wenn das Scrapen von Cloudflare-geschützten Websites nicht möglich ist
Wir haben bereits erwähnt, dass Cloudscraper ein paar Einschränkungen hat und dass die Tatsache, dass es nicht in der Lage ist, durch Cloudflare Bot Detection v2 geschützte Websites zu scannen, ein großer Nachteil ist. Dies ist die neuere Version der Bot-Erkennung von Cloudflare und wird derzeit von zahlreichen Websites verwendet. Eine solche Website ist Author.
So sieht die Homepage des Autors aus:
Wenn Sie versuchen, mit Cloudscraper Daten von dieser Website zu extrahieren, wird die folgende Ausnahme angezeigt:
cloudscraper.exceptions.CloudflareChallengeError: Detected a Cloudflare version 2 challenge, This feature is not available in the opensource (free) version.
Auch wenn diese Ausnahme auf die Existenz einer kostenpflichtigen Version von Cloudscraper hinweist, gibt es keine. Leider bricht Cloudscraper angesichts des neuesten von Cloudflare verwendeten Bot-Erkennungsalgorithmus völlig zusammen.
Alternativen zu Cloudscraper
Wenn Sie Websites scrapen möchten, die Cloudscraper derzeit nicht scrapen kann, oder wenn Sie Skalierbarkeit und bessere Leistung erzielen möchten, sollten Sie sich nach Cloudscraper-Alternativen umsehen. Eine der besten heute verfügbaren Alternativen ist ScraperAPI.
Es kann mit der neuesten Version des von Cloudflare verwendeten Bot-Erkennungsalgorithmus umgehen und wird regelmäßig mit neuen Anti-Bot-Umgehungstechniken aktualisiert, damit Ihre Scraping-Jobs reibungslos laufen.
Das Beste daran ist, dass ScraperAPI 5.000 kostenlose API-Credits für 7 Tage als Testversion bereitstellt und anschließend einen großzügigen kostenlosen Plan mit wiederkehrenden 1.000 API-Credits bereitstellt, um Sie am Laufen zu halten.
Sie können schnell loslegen, indem Sie zur ScraperAPI-Dashboard-Seite gehen und sich für ein neues Konto anmelden:
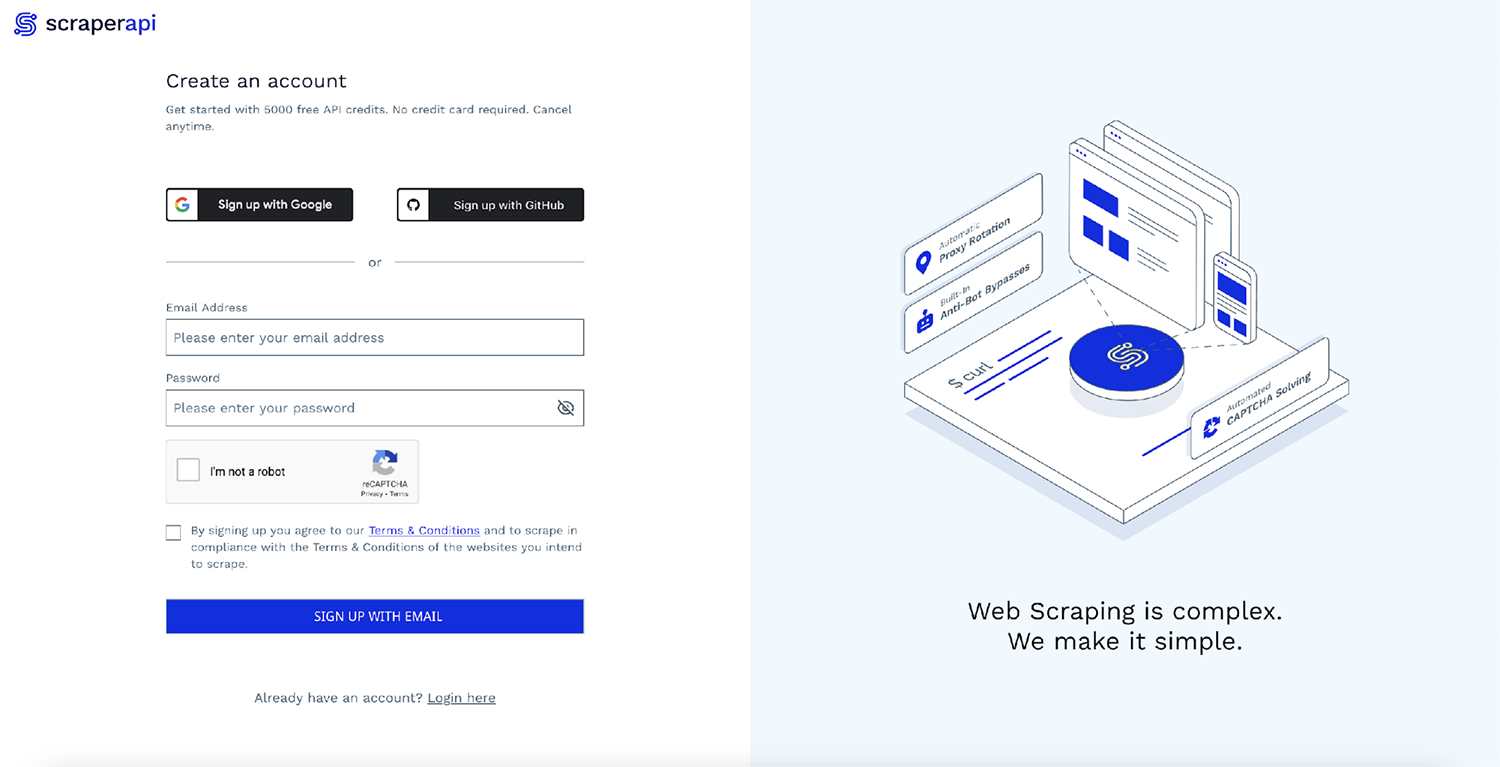
Nach der Anmeldung sehen Sie Ihren API-Schlüssel und einige Beispielcodes:
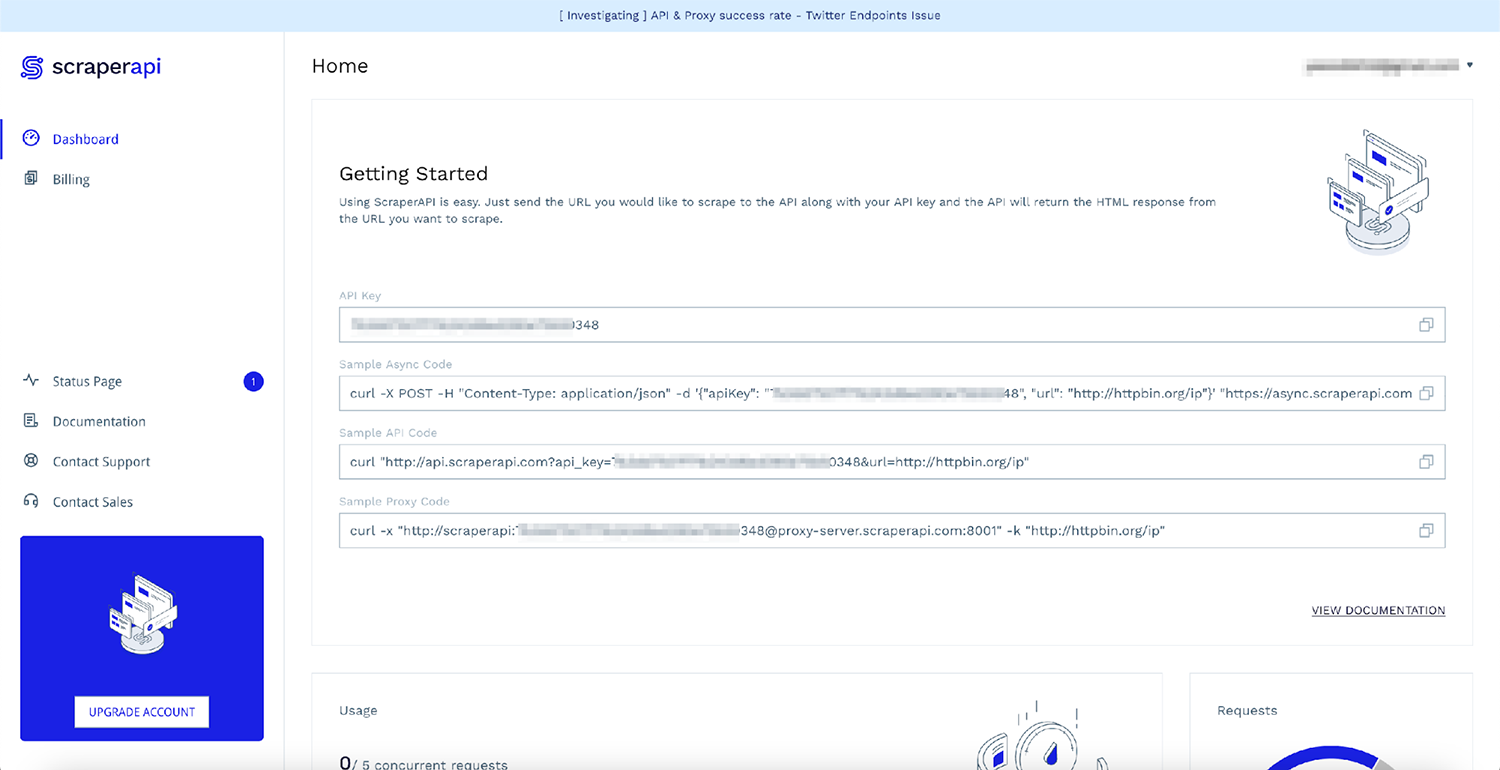
Der schnellste Weg, ScraperAPI zu verwenden, ohne Ihren vorhandenen Code zu ändern, besteht darin, ScraperAPI als Proxy für Anfragen zu verwenden. So können Sie das tun:
import requests
proxies = {
"http": "http://scraperapi:[email protected]:8001"
}
r = requests.get('https://author.today/', proxies=proxies, verify=False)
print(r.text)
Notiz: Vergessen Sie nicht, APIKEY durch Ihren persönlichen API-Schlüssel aus dem Dashboard zu ersetzen.
Das ist es! Mit nur wenigen Codezeilen müssen Sie nicht mehr über das Bot-Erkennungssystem von Cloudflare nachdenken. ScraperAPI stellt sicher, dass es nicht blockierte Proxys und fortschrittliche Techniken verwendet, um das bestehende Bot-Erkennungssystem zu umgehen. Jetzt können Sie mehr Zeit damit verbringen, sich auf Ihre Kerngeschäftslogik zu konzentrieren.
