
Wenn Sie sich die HTML-Variable ansehen, werden Sie feststellen, dass Sie dieses Mal wie gewünscht die vollständige Suchergebnisseite erhalten haben.
Wenn wir schon dabei sind, laden wir die Antwort auch in ein BeautifulSoup-Objekt:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html.text)
Süß! Da Sie nun die vollständige Antwort in einem BeautifulSoup-Objekt haben, können Sie damit beginnen, relevante Daten daraus zu extrahieren.
Scraping von Produktattributen
Der einfachste Weg, herauszufinden, wie man die benötigten Daten extrahiert, ist die Verwendung der Entwicklertools, die in fast allen gängigen Browsern verfügbar sind.
Mit den Entwicklertools können Sie die DOM-Struktur der Seite erkunden.
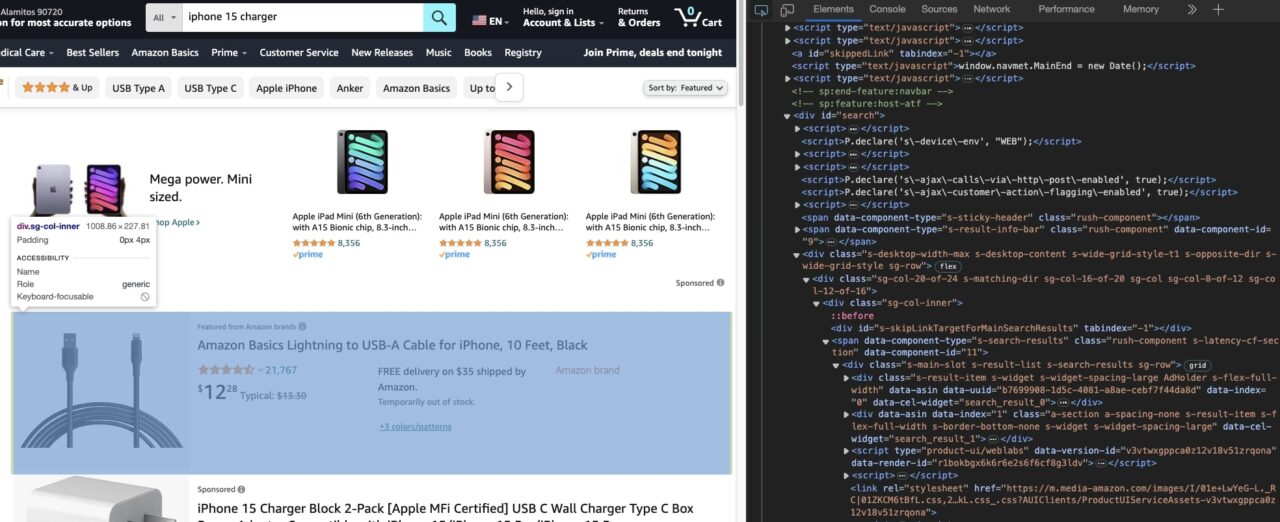
Das Hauptziel besteht darin, herauszufinden, mit welchen HTML-Tag-Attributen Sie ein HTML-Tag eindeutig ansprechen können.
Meistens werden Sie sich darauf verlassen id Und class Attribute. Dann können Sie diese Attribute an BeautifulSoup übergeben und es bitten, den Text/das Attribut zurückzugeben, das Sie aus diesem bestimmten Tag extrahieren möchten.
Extrahieren des Produktnamens
Sehen wir uns an, wie Sie den Produktnamen extrahieren können. Dadurch erhalten Sie ein gutes Verständnis des allgemeinen Prozesses.
Klicken Sie mit der rechten Maustaste auf den Produktnamen und klicken Sie auf „Inspizieren“:
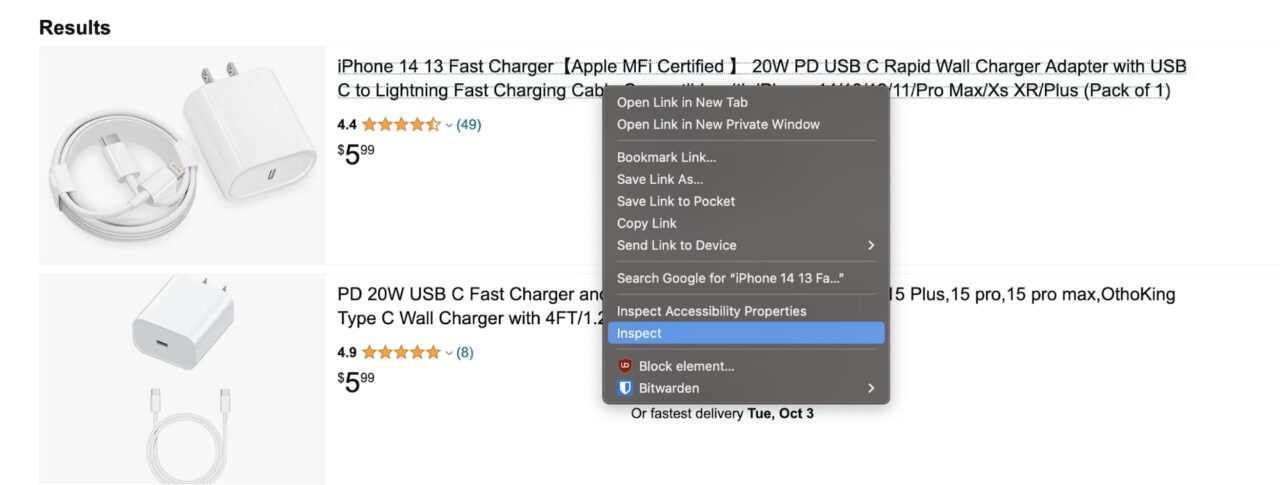
Dadurch werden die Entwicklertools geöffnet:
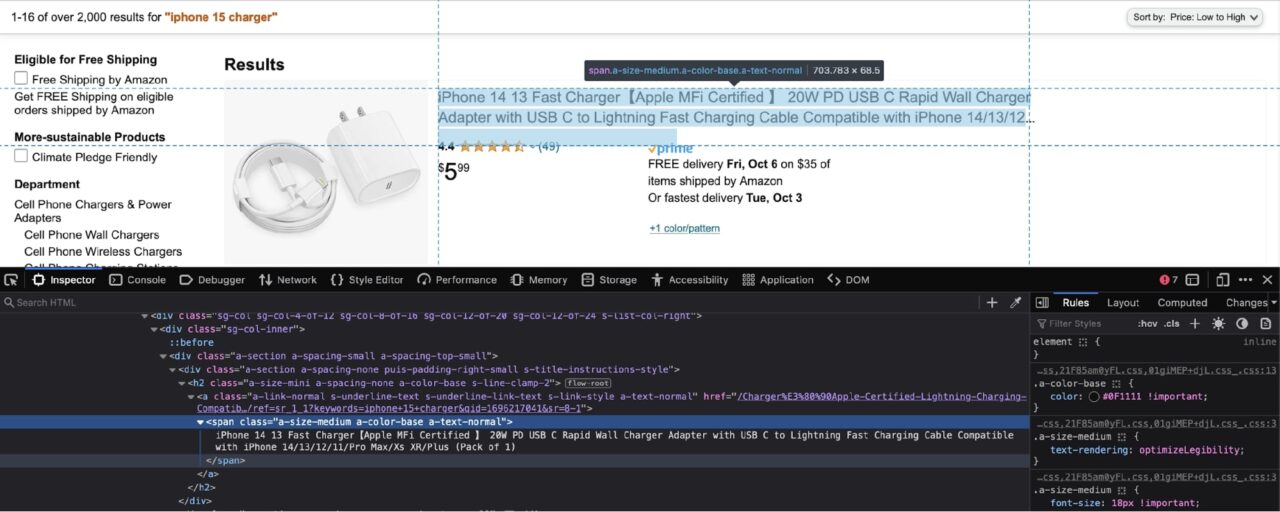
Wie Sie im obigen Screenshot sehen können, ist der Produktname in einem Span mit den folgenden Klassen verschachtelt: a-size-medium a-color-base a-text-normal.
An diesem Punkt müssen Sie eine Entscheidung treffen: Sie können BeautifulSoup entweder bitten, alles zu extrahieren spans mit diesen Klassen von der Seite, oder Sie können jedes Ergebnis extrahieren div und diese dann durchlaufen divs und extrahieren Sie Daten für jedes Produkt.
Im Allgemeinen bevorzuge ich die letztere Methode, da sie dabei hilft, Produkte zu identifizieren, die möglicherweise nicht über alle erforderlichen Daten verfügen. In diesem Tutorial wird auch dieselbe Methode vorgestellt.
Daher müssen Sie jetzt das Div identifizieren, das jedes Ergebniselement umschließt:
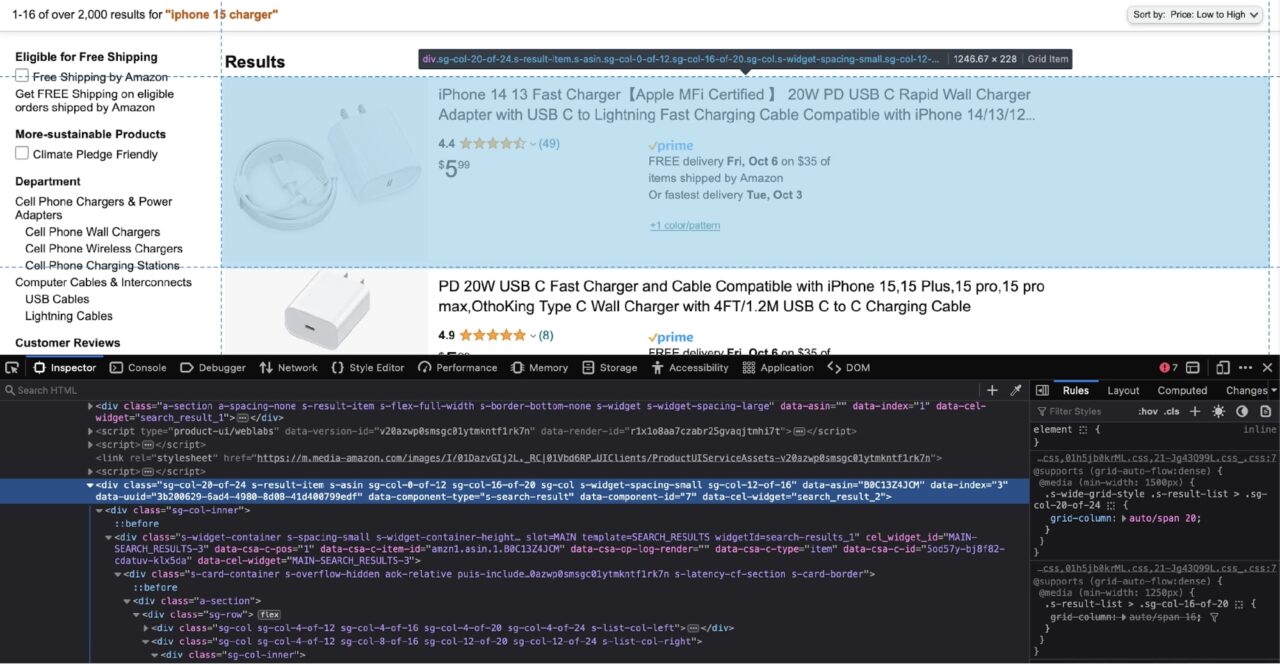
Gemäß dem Screenshot oben ist jedes Ergebnis in einem verschachtelt div Tag mit dem data-component-type Attribut von s-search-result.
Nutzen wir diese Informationen, um das gesamte Ergebnis zu extrahieren divs und durchlaufen Sie sie dann und extrahieren Sie die verschachtelten Produkttitel:
results = soup.find_all('div', attrs={'data-component-type': 's-search-result'})
for r in results:
print(r.select_one('.a-size-medium.a-color-base.a-text-normal').text)
Hier ist eine einfache Aufschlüsselung dessen, was dieser Code tut:
- Es nutzt die
find_all()Methode von BeautifulSoup - Es gibt alle passenden Elemente aus dem HTML zurück
- Es verwendet dann die
select_one()Methode zum Extrahieren des ersten Elements, das mit dem übergebenen CSS-Selektor übereinstimmt
Beachten dass wir hier vor jedem Klassennamen einen Punkt (.) anhängen. Dadurch wird BeautifulSoup mitgeteilt, dass der übergebene CSS-Selektor ein Klassenname ist. Es gibt auch kein Leerzeichen zwischen den Klassennamen. Dies ist wichtig, da es BeautifulSoup darüber informiert, dass jede Klasse aus demselben HTML-Tag stammt.
Wenn Sie mit CSS-Selektoren noch nicht vertraut sind, sollten Sie unseren Spickzettel zu CSS-Selektoren lesen. Wir gehen die Grundlagen von CSS-Selektoren durch und stellen Ihnen ein benutzerfreundliches Framework zur Verfügung, um den Prozess zu beschleunigen.
Extrahieren des Produktpreises
Nachdem Sie nun den Produktnamen extrahiert haben, ist das Extrahieren des Produktpreises ziemlich einfach.
Befolgen Sie die gleichen Schritte aus dem letzten Abschnitt und verwenden Sie die Entwicklertools, um den Preis zu überprüfen:
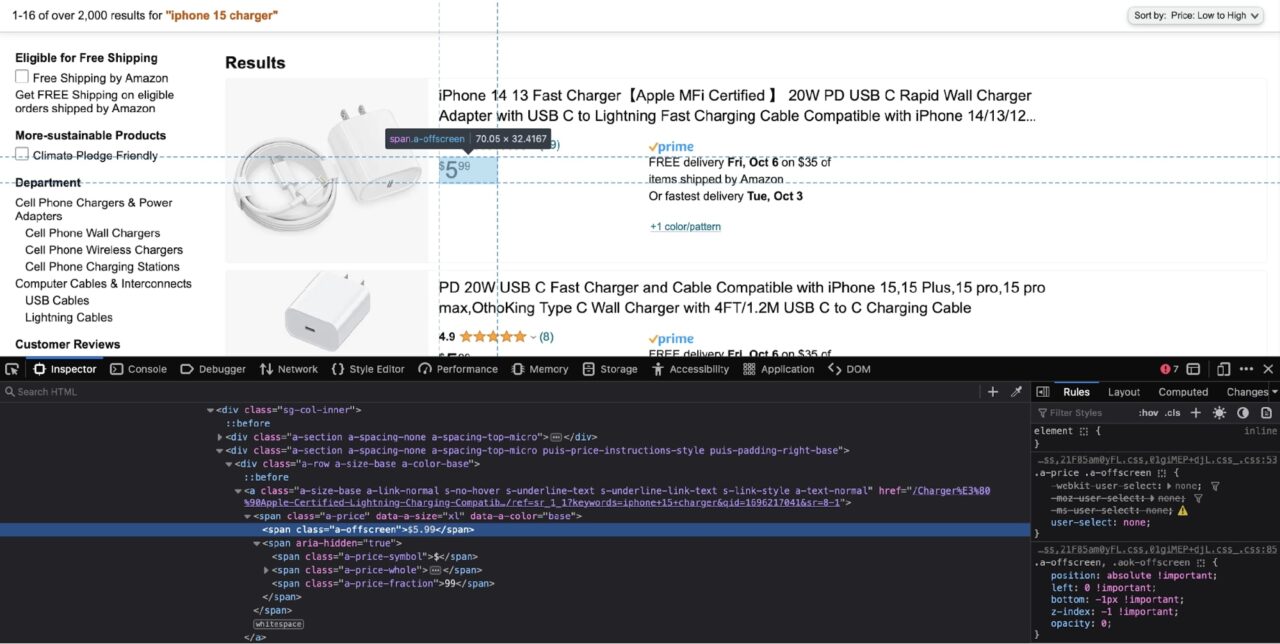
Der Preis kann aus der Spanne mit der Klasse extrahiert werden a-offscreen. Das span ist selbst in einem anderen verschachtelt span mit einer Klasse von a-price. Mit diesem Wissen können Sie einen CSS-Selektor erstellen:
for r in results:
# -- truc --
print(r.select_one('.a-price .a-offscreen').text)
Da Sie dieses Mal auf verschachtelte Bereiche abzielen möchten, müssen Sie zwischen den Klassennamen ein Leerzeichen einfügen.
Extrahieren des Produktbildes
Versuchen Sie, die Schritte aus den beiden vorherigen Abschnitten zu befolgen, um selbst den entsprechenden Code zu erstellen. Hier ist ein Screenshot des Bildes, das im Fenster „Entwicklertools“ überprüft wird:

Der img Tag hat eine Klasse von s-image. Sie können dies gezielt angehen img Markieren und extrahieren Sie die src Attribut (die Bild-URL) mit diesem Code:
for r in results:
# -- truc --
print(r.select_one('.s-image').attrs('src'))
Notiz: Extrapunkte, wenn Sie es alleine machen!
Vollständiger Scraper-Code
Sie haben alle Kleinigkeiten, um den kompletten Scraper-Code zusammenzustellen.
Hier ist eine leicht modifizierte Version des Scrapers, der alle Produktergebnisse ganz am Ende in eine Liste einfügt:
import requests
from bs4 import BeautifulSoup
url = "https://www.amazon.com/s?k=iphone+15+charger&s=price-asc-rank"
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36',
'Accept-Language': 'en-US, en;q=0.5'
}
html = requests.get(url, headers=headers)
soup = BeautifulSoup(html.text)
results = soup.find_all('div', attrs={'data-component-type': 's-search-result'})
result_list = ()
for r in results:
result_dict = {
"title": r.select_one('.a-size-medium.a-color-base.a-text-normal').text,
"price": r.select_one('.a-price .a-offscreen').text,
"image": r.select_one('.s-image').attrs('src')
}
result_list.append(result_dict)
Sie können diese Ergebnisliste problemlos für verschiedene APIs verwenden oder diese Informationen zur weiteren Analyse in einer Tabelle speichern.
Verwenden des Endpunkts für strukturierte Daten
Dieses Tutorial konzentrierte sich nicht zu sehr auf die Fallstricke beim Scraping von Amazon im großen Maßstab.
Amazon ist dafür berüchtigt, Scraper zu verbieten und das Scrapen von Daten von seinen Websites zu erschweren.
Sie haben dies bereits zu Beginn des Tutorials gesehen, als eine Anfrage ohne die richtigen Header von Amazon blockiert wurde.
Glücklicherweise gibt es eine einfache Lösung für dieses Problem. Anstatt eine Anfrage direkt an Amazon zu senden, können Sie die Anfrage an den Endpunkt für strukturierte Daten von ScraperAPI senden, und ScraperAPI antwortet mit den gescrapten Daten in schön formatiertem JSON.

Dies ist eine sehr leistungsstarke Funktion von ScraperAPI, da Sie sich keine Sorgen machen müssen, von Amazon blockiert zu werden oder Ihren Scraper über die ständigen Änderungen der Anti-Bot-Techniken von Amazon auf dem Laufenden zu halten.
Das Beste daran ist, dass ScraperAPI 5.000 kostenlose API-Credits für 7 Tage als Testversion bereitstellt und anschließend einen großzügigen kostenlosen Plan mit wiederkehrenden 1.000 API-Credits bereitstellt, um Sie am Laufen zu halten. Dies reicht aus, um Daten für den allgemeinen Gebrauch zu extrahieren.
Sie können schnell loslegen, indem Sie zur ScraperAPI-Dashboard-Seite gehen und sich für ein neues Konto anmelden:
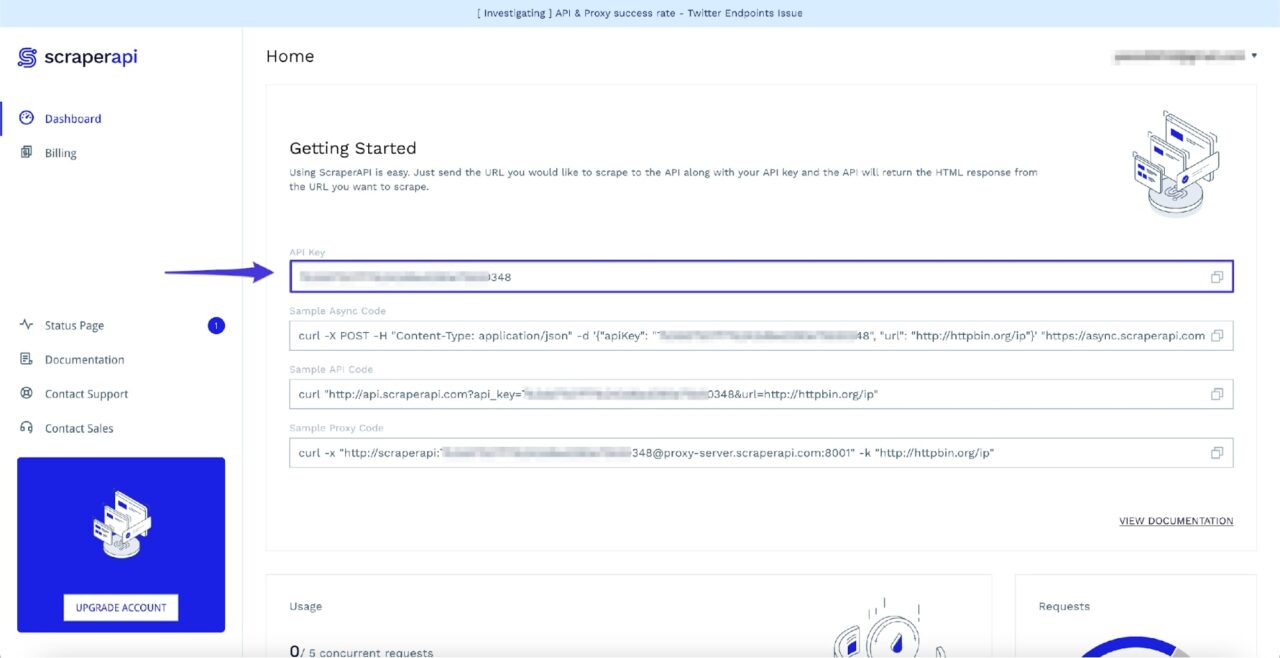
Nach der Anmeldung sehen Sie Ihren API-Schlüssel:
Jetzt können Sie mit dem folgenden Code über den Structured Data-Endpunkt auf die Suchergebnisse von Amazon zugreifen:
import requests
payload = {
'api_key': 'API_KEY,
'query': 'iphone 15 charger',
's': 'price-asc-rank'
}
response = requests.get('https://api.scraperapi.com/structured/amazon/search', params=payload)
print(response.json())
Notiz: Vergessen Sie nicht, den Ersatz auszutauschen API_KEY im obigen Code mit Ihrem eigenen ScraperAPI-API-Schlüssel.
Wie Sie vielleicht bereits bemerkt haben, können Sie die meisten Abfrageparameter übergeben, die Amazon als Teil der Nutzlast akzeptiert. Dies bedeutet, dass alle folgenden Sortierwerte für die gültig sind s Geben Sie die Nutzlast ein:
- Preis: Hoch nach niedrig =
price-desc-rank - Preis: Niedrig bis hoch =
price-asc-rank - Hervorgehoben =
rerelevanceblender - Durchschn. Kundenbewertung =
review-rank - Neuzugänge =
date-desc-rank
Wenn Sie dasselbe wollen result_list Um die Daten aus dem letzten Abschnitt abzurufen, können Sie am Ende den folgenden Code hinzufügen:
result_list = ()
for r in response.json()('results'):
result_dict = {
"title": r('name')
"price": r('price_string'),
"image": r('image')
}
result_list.append(result_dict)
Weitere Informationen zu diesem Endpunkt finden Sie in den ScraperAPI-Dokumenten.
Zusammenfassung
Dieses Tutorial war ein kurzer Überblick über die Vorgehensweise beim Scrapen von Daten von Amazon.
- Es hat Ihnen eine einfache Umgehungsmethode für das von Amazon verwendete Bot-Erkennungssystem beigebracht.
- Es zeigte Ihnen, wie Sie die verschiedenen von BeautifulSoup bereitgestellten Methoden verwenden, um die erforderlichen Daten aus dem HTML-Dokument zu extrahieren.
- Zuletzt haben Sie etwas über den von ScraperAPI angebotenen Endpunkt für strukturierte Daten erfahren und erfahren, wie er eine ganze Reihe von Problemen löst.
Wenn Sie bereit sind, Ihre Datensammlung von ein paar Seiten auf Tausende oder sogar Millionen Seiten auszuweiten, ist unser Businessplan ein guter Ausgangspunkt.
Benötigen Sie mehr als 10 Millionen API-Credits? Kontaktieren Sie den Vertrieb für einen individuellen Plan, der alle Premium-Funktionen, Premium-Support und einen Account Manager umfasst.
Bis zum nächsten Mal, viel Spaß beim Schaben!
