
Web Scraping und Web Crawling sind zwei unterschiedliche, aber verwandte Prozesse, die das Sammeln von Daten aus dem gesamten Internet ermöglichen. Bei beiden Methoden geht es darum, bestimmte Informationen durch die Navigation auf Websites zu extrahieren und Muster in HTML-Dokumenten zu identifizieren. Sie weisen jedoch grundlegende Unterschiede auf.
In diesem Artikel werden die Unterschiede zwischen diesen Ansätzen untersucht und erläutert, wann jeder für eine bestimmte Situation am besten geeignet ist. Wir werden uns auch einige Beispiele ansehen, wie Web Scraping und Crawling in realen Anwendungen implementiert werden können. Abschließend prüfen wir Tipps zur Auswahl des für Ihr Projekt oder Ihre Geschäftsanforderungen geeigneten Ansatzes.
Was ist Webcrawlen?
Beim Webcrawlen, auch Webspidering genannt, werden automatisch Inhalte von Websites abgerufen. Dabei werden Software-Bots eingesetzt, um Webseiten systematisch zu durchsuchen, deren Inhalte zu indizieren und Links zu anderen Websites zu folgen. Im Gegensatz zum Web-Scraping, bei dem es darum geht, bestimmte Daten von einer Website zu extrahieren, handelt es sich beim Web-Crawling um eine automatisierte Möglichkeit, das gesamte Internet zu erkunden, indem jede Seite besucht wird, die es findet.
Webcrawler, auch Spider, Robots oder Bots genannt, sind Computerprogramme, die eine Reihe verwandter Dokumente im Internet durchsuchen, um relevante Informationen oder Daten für bestimmte Benutzer oder Anwendungen zu finden. Ein typisches Beispiel wäre der Suchmaschinen-Spider von Google, der alle verfügbaren Seiten im Web besucht und sie nach den auf diesen Seiten gefundenen Schlüsselwörtern indiziert, sodass Suchanfragen umfassendere Ergebnisse für Benutzer liefern können, die diese Begriffe in ihren Suchanfragen verwenden.
So funktioniert Webcrawlen
Im Kern funktioniert ein Webcrawler, indem er Anfragen über HTTP/HTTPS-Protokolle sendet, um Informationen von bestimmten URLs anzufordern und dann zurückgegebene HTML-Dateien auf Links zu anderen URLs analysiert – dieser Vorgang wiederholt sich, bis keine neuen eindeutigen Verbindungen zwischen Dokumenten gefunden werden oder wann Es erreicht entweder vom Benutzer festgelegte Grenzwerte, z. B. eine maximale Anzahl von Hops von der ursprünglichen URL entfernt (um Endlosschleifen zu vermeiden).
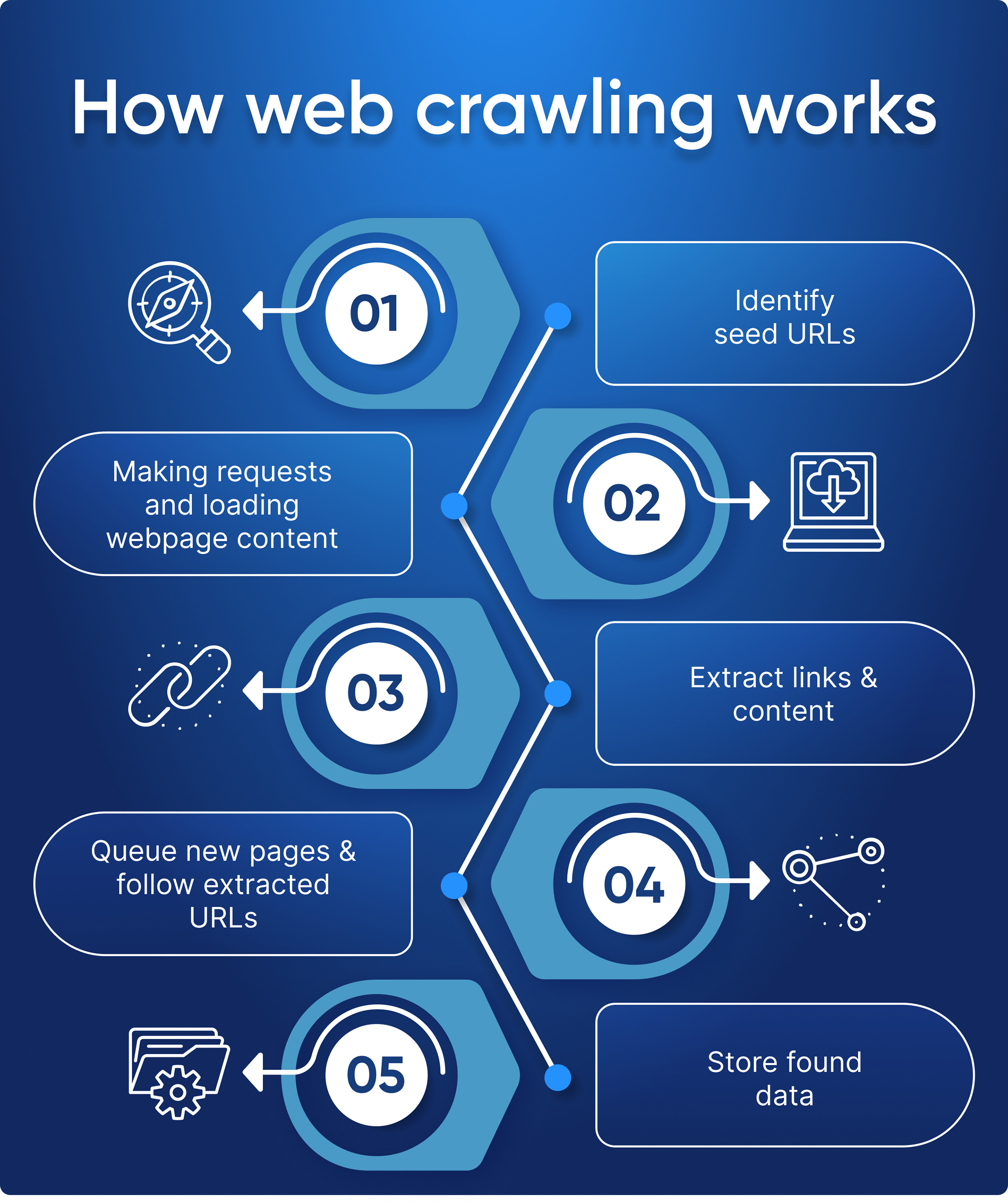
Hier sind die Schritt-für-Schritt-Prozesse, die veranschaulichen, wie ein Webcrawler funktioniert:
- Identifizieren Sie Seed-URLs: Hier beginnt ein Webcrawler mit der Suche. Seed-URLs sind die ersten Websites, die der Benutzer zum Crawlen auswählt.
- Seiten anfordern: Sobald eine Seed-Liste von URLs identifiziert wurde, sendet der Crawler HTTP-Anfragen für jede einzelne Seite, die er auf diesen Websites findet, um deren Inhalte abzurufen und weiter zu analysieren.
- Links und Inhalte extrahieren: Nachdem der Crawler ein HTML-Dokument aus einer seiner Anfragen erhalten hat, extrahiert er alle relevanten Links innerhalb dieser Seite sowie alle anderen relevanten Inhalte wie Bilder oder textbasierte Informationen (z. B. Metadaten).
- Neue Seiten in die Warteschlange stellen und extrahierten URLs folgen: Zu diesem Zeitpunkt können neu entdeckte Links entweder einer Prioritätswarteschlange hinzugefügt werden, wenn sie noch nicht gecrawlt wurden, oder verworfen werden, wenn sie bereits zuvor von einer anderen Instanz dieses Programms besucht wurden – was eine effiziente Nutzung ermöglicht Erkundung, ohne zuvor erkundete Gebiete unnötig erneut aufzusuchen! Abhängig davon, wie komplex der/die Crawling-Algorithmus(s) werden soll/sind, könnte es außerdem bestimmte Muster/Schlüsselwörter priorisieren, wenn bestimmt wird, welcher Link als nächstes verwendet werden soll, basierend auf Relevanzergebnissen während der Analysevorgänge (d. h. Techniken des maschinellen Lernens wie natürliche Sprache). wird bearbeitet).
- Gefundene Daten speichern: Wenn alle erforderlichen Ressourcen gesammelt und ordnungsgemäß in die Warteschlange gestellt wurden, erreichen wir schließlich unseren letzten Schritt, bei dem alle gesammelten Daten gespeichert und die Anweisungen befolgt werden.
Ein Webcrawler ist wie ein begeisterter Tourist, der eine neue Stadt besucht – er beginnt mit ein paar Start-URLs (z. B. den Top-Attraktionen der Stadt) und folgt dann allen interessanten Links, die er während seiner Erkundung findet, und sammelt dabei so viele Informationen wie möglich . Irgendwann wird es, genau wie unser touristischer Freund es irgendwann tun müsste, alle Ergebnisse in einer Art Datenbank oder Datei zur späteren Verwendung speichern.
Was ist Web-Scraping?
Andererseits deutet Web Scraping darauf hin, dass der Link zur Zielwebsite bereits bekannt ist und es nicht erforderlich ist, Websites zu durchsuchen, um Links zu sammeln. Dabei handelt es sich um das Schreiben oder Verwenden von Web-Scraping-Tools, die Informationen wie Produktpreise, Bilder, Kontaktinformationen oder andere Daten zur weiteren Analyse oder Bearbeitung sammeln.
So funktioniert Web Scraping
Beim Web-Scraping-Prozess werden Anfragen an eine Zielwebsite gesendet, die Daten aus dem zurückgegebenen HTML-Code extrahiert und anschließend in nutzbare Informationen umformatiert.
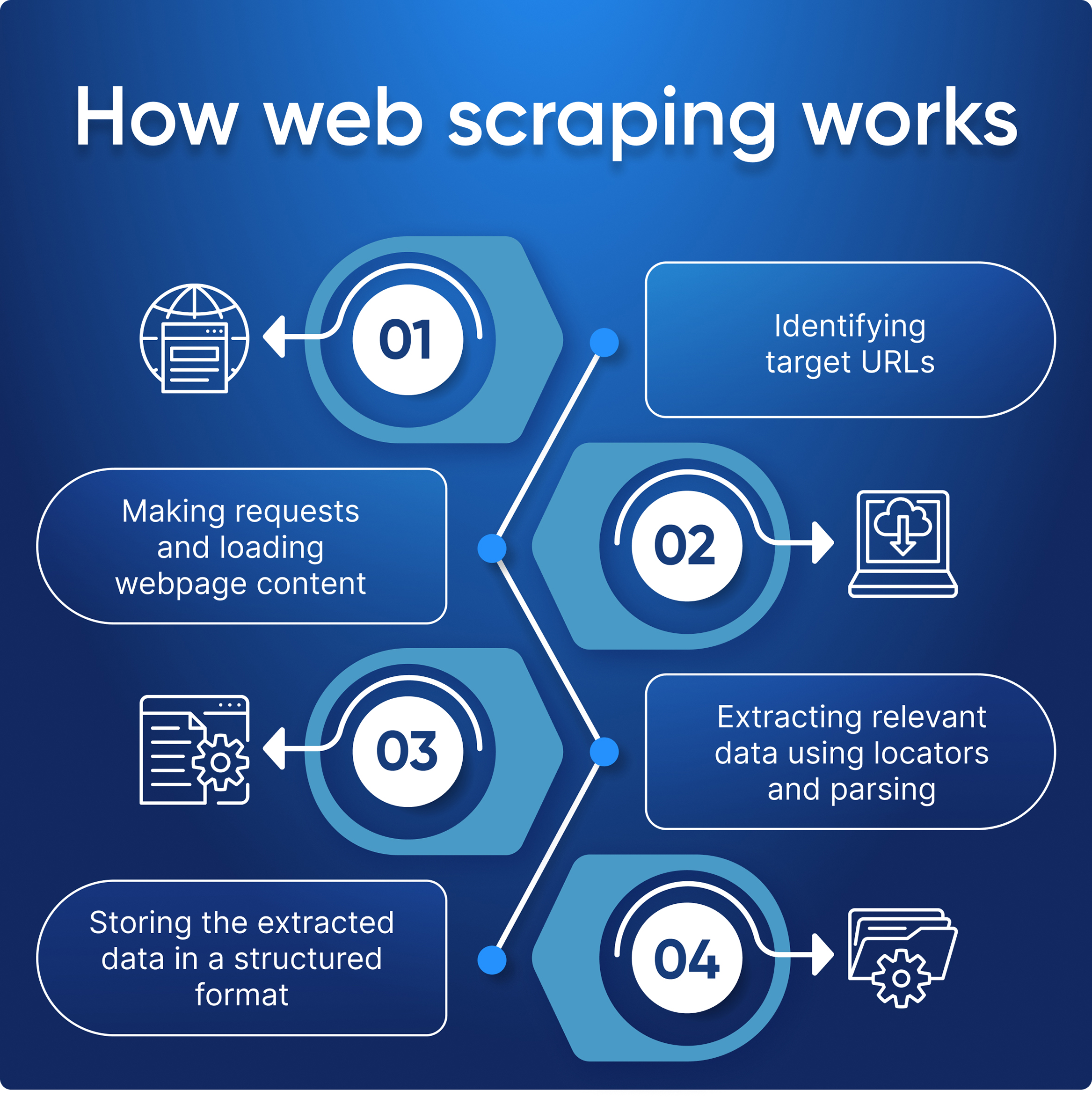
Hier sind die Schritt-für-Schritt-Prozesse, die veranschaulichen, wie Web Scraping funktioniert:
- Definieren Sie die Zielsite und ihre Struktur.
- Ergreifen Sie Maßnahmen, um eine Blockierung zu vermeiden:
- Verbinden Sie einen Proxy.
- Verbinden Sie Captcha-Lösungsdienste.
- Richten Sie Header und User-Agent ein.
- Es empfiehlt sich, einen Headless-Browser zu verwenden.
- Scraper stellt eine Anfrage und erhält seinen HTML-Code.
- Extrahiert Daten von der Seite mithilfe von Locators und Parsing.
- Speichert Webdaten in einem praktischen Format wie JSON, Excel oder CSV.
Für das Scraping können auch mehrere Links verwendet werden, diese stammen jedoch alle von derselben Website, was bedeutet, dass alle Seiten eine ähnliche Struktur haben.
Im Gegensatz zu unserem „Touristen-Crawler“ ist ein Web-Scraper wie ein kluger Käufer. Sie wissen genau, was sie suchen und verschwenden keine Zeit damit, den gesamten Laden zu durchstöbern. Sie springen schnell von Geschäft zu Geschäft und schnappen sich alle dort verfügbaren Angebote und Rabatte, bevor sie zum nächsten weitergehen.
Hauptunterschiede zwischen Web Scraping und Web Crawling
Wie bereits erwähnt, dient das Daten-Crawling dem Sammeln von Links und das Daten-Scraping dem Sammeln von Daten. Normalerweise werden sie zusammen verwendet: Zuerst sammelt der Crawler Links, dann verarbeitet der Scraper sie und sammelt die notwendigen Daten.
Vergleichen wir Web-Crawling und Web-Scraping:
| Kategorie | Web Scraping | Web-Crawling |
|---|---|---|
| Definition | Extrahieren von Daten von Websites mithilfe von Software oder Web-Scraping-Tools, die das Surfverhalten von Menschen simulieren. | Automatisierter Prozess des Surfens im Internet, der Indizierung und Katalogisierung von Informationen sowie deren Organisation in einer Datenbank. |
| Zweck | Extrahieren Sie spezifische Daten von Webseiten zur Analyse und Verwendung | Erkunden und indizieren Sie Webseiten für Suchmaschinen und Datenanalyse |
| Datenextraktionsmethode | Ruft Daten aus der HTML-Struktur einer Website ab. | Crawlt Webseiten und folgt Hyperlinks, um neue Seiten zum Indexieren zu finden. |
| Umfang | Beschränkt auf bestimmte Websites oder Seiten. | Es kann ein breiteres Spektrum an Websites oder Seiten abdecken. |
| Gezielte Websites | Im Allgemeinen auf bestimmte Websites oder Seiten ausgerichtet. | Es kann ein breites Spektrum an Websites oder Seiten abdecken. |
| Datenanalyse | Daten können in einem leicht zu analysierenden Format extrahiert und für verschiedene Zwecke verwendet werden, beispielsweise für Preisvergleiche oder Marktforschung. | Crawler führt keine Datenanalyse durch |
| Skalierbarkeit | Sowohl im kleinen als auch im großen Maßstab durchgeführt | Meist im großen Maßstab eingesetzt |
| Prozessanforderungen | Zum Anfordern und Abrufen von Webseiten ist lediglich ein Crawler erforderlich | Erfordert sowohl einen Crawler zum Abrufen von Webseiten als auch einen Parser zum Extrahieren der relevanten Daten aus diesen Seiten |
Der Hauptunterschied zwischen Web-Crawling und Web-Scraping besteht also darin, dass beim Web-Crawling automatisch jede Seite besucht wird, die gefunden werden kann, während sich beim Web-Scraping das Extrahieren spezifischer Daten von einer Website konzentriert. Webcrawler durchsuchen das gesamte Internet, indem sie Links zwischen Seiten verfolgen, während Webscraper nur auf Informationen abzielen, die mit ihren Suchanfragen in Zusammenhang stehen.
Anwendungsfälle von Web-Crawling und Web-Scraping
Web-Scraping und Web-Scanning sind zwei unterschiedliche Prozesse, die gemeinsam mit erheblicher Wirkung eingesetzt werden können. Sie können jedoch je nach Aufgabenstellung auch unabhängig voneinander eingesetzt werden.
Anwendungsfälle für Web-Crawling
Web-Crawling eignet sich, wie bereits erwähnt, hervorragend für Projekte, die das Sammeln von Links erfordern, möglicherweise nicht über gezielte Ressourcen verfügen und den gesamten Seitencode ohne weitere Analyse und Verarbeitung abrufen müssen. Hier sind einige der häufigsten Anwendungsfälle:
Suchmaschinenindizierung
Suchmaschinen wie Google, Bing und Yahoo nutzen ihre Crawler-Teams, um neu aktualisierte Inhalte oder neue Seiten zu finden. Anschließend speichern die Suchenden die gefundenen Informationen in einem Index, einer riesigen Datenbank mit allen Inhalten, die ihrer Meinung nach gut genug sind, um sie den Benutzern bereitzustellen.
Verbessern Sie die Leistung Ihrer eigenen Website
Web-Crawling ist ein wertvolles Tool zur Analyse Ihrer Website und zur Verbesserung ihrer Leistung. Durch die Ausführung eines Webcrawlers können Sie defekte Links oder Bilder, doppelte Inhalte oder Meta-Tags sowie andere Probleme erkennen, die sich negativ auf die SEO-Leistung Ihrer Website auswirken könnten. Durch das Webcrawlen können Sie auch Möglichkeiten zur Optimierung der Struktur der Website als Ganzes erkennen.
Analyse der Websites von Wettbewerbern für SEO-Zwecke
Sie können Änderungen nicht nur auf Ihrer Website, sondern auch bei Ihren Mitbewerbern überwachen. So stellen Sie sicher, dass Sie stets über neue Veränderungen Ihrer Mitbewerber informiert sind und erfolgreich und schnell darauf reagieren können.
Data-Mining
Mit Webcrawlern können große Datenmengen aus verschiedenen Quellen im Internet gesammelt und analysiert werden. Dies erleichtert es Forschern, Unternehmen oder anderen interessierten Parteien, wertvolle Erkenntnisse zu einem bestimmten Thema zu gewinnen und auf der Grundlage dieser Erkenntnisse fundierte Entscheidungen zu treffen.
Defekte Links auf externen Websites finden
Neben der Überprüfung Ihrer Seiten ist es wichtig, alle Links auf externen Seiten aktuell zu halten. Während Fehler auf Ihren Seiten normalerweise im Admin-Bereich gefunden werden können, ist es viel schwieriger, defekte Links zu externen Websites zu finden. Um sie auf dem neuesten Stand zu halten, müssen Sie sie entweder manuell prüfen oder Crawler einsetzen.
Inhaltspflege
Crawler eignen sich auch hervorragend zum schnellen und effizienten Auffinden inhaltsbezogener Themen und ermöglichen es Unternehmen oder Einzelpersonen, diese anhand spezifischer Kriterien wie Schlüsselwörter oder Tags in Sammlungen zusammenzustellen.
Anwendungsfälle für Web Scraping
Andererseits eignet sich Web Scraping hervorragend, wenn Sie bereits wissen, welche spezifischen Informationen Sie aus einer Website extrahieren möchten. Einige der häufigsten Anwendungen sind:
- Preisüberwachung
- Inhaltsaggregation
- Lead-Generierung
- Wettbewerbsanalyse
- Social-Media-Analyse
- Online-Reputationsmanagement
Weitere Informationen zum Web Scraping und seinen Anwendungsfällen finden Sie in unserem Artikel, in dem einige der häufigsten Anwendungen beschrieben werden.
| Anwendungsfall | Web-Crawling | Web Scraping |
|---|---|---|
| Preisüberwachung | ✔️ Kann Preise von mehreren Websites erfassen und Änderungen im Laufe der Zeit verfolgen | ✔️ Kann Preise von bestimmten Webseiten extrahieren, um sie zu vergleichen und zu analysieren |
| Jobaggregation | ✔️ Kann Stellenangebote von verschiedenen Websites sammeln und zentral präsentieren | ✔️ Kann Stellenangebote von bestimmten Websites extrahieren und zentral präsentieren |
| Inhaltsaggregation | ✔️ Kann Inhalte von mehreren Websites sammeln, um ein zentrales Repository zu erstellen | ❌ Nicht geeignet, da hierfür spezifische Informationen von jeder Webseite extrahiert werden müssen |
| SEO-Optimierung | ✔️ Kann Website-Struktur und Backlinks zur Suchmaschinenoptimierung analysieren | ❌ Nicht geeignet, da Zugriff auf bestimmte Website-Daten wie Keyword-Dichte und Metadaten erforderlich ist |
| Nachrichtenüberwachung | ✔️ Kann Nachrichtenagenturen und RSS-Feeds auf Aktualisierungen überwachen | ❌ Nicht geeignet, da aus jedem Nachrichtenartikel spezifische Informationen extrahiert werden müssen |
| Aggregation von Produktbewertungen | ✔️ Kann Bewertungen von mehreren Websites sammeln und die Stimmung analysieren | ✔️ Kann Bewertungen von bestimmten Websites extrahieren und die Stimmung analysieren |
| Data Mining | ✔️ Kann große Datenmengen zur Analyse und Modellierung sammeln | ✔️ Kann spezifische Datenpunkte zur Analyse und Modellierung extrahieren |
| Defekte Links auf externen Websites finden | ✔️ Kann externe Websites crawlen, um defekte Links zu identifizieren | ❌ Nicht geeignet, da hierfür spezifische Informationen von jeder Webseite extrahiert werden müssen |
| Lead-Generierung | ✔️ Kann Kontaktinformationen von mehreren Websites sammeln | ✔️ Kann Kontaktinformationen von bestimmten Websites extrahieren |
| Wettbewerbsanalyse | ✔️ Kann Daten auf Websites von Mitbewerbern zur Analyse sammeln | ✔️ Kann spezifische Datenpunkte auf Websites von Mitbewerbern zur Analyse extrahieren |
| Online-Reputationsmanagement | ✔️ Kann Online-Erwähnungen und Bewertungen für das Reputationsmanagement überwachen | ❌ Nicht geeignet, da hierfür spezifische Informationen von jeder Webseite extrahiert werden müssen |
Herausforderungen beim Web-Crawling und Web-Scraping
Beim Web-Crawling und Web-Scraping müssen einige Herausforderungen berücksichtigt werden. Abhängig von der Größe des Projekts können diese von einfachen technischen Problemen wie langsamen Ladezeiten oder blockierten Anfragen (aufgrund von Anti-Scraping-Maßnahmen) bis hin zu komplexen rechtlichen Fragen zum Datenschutz reichen.
Crawls in robots.txt blockieren
Stellen Sie vor dem Crawlen einer Ressource sicher, dass die Site dies zulässt. Wenn in der robots.txt-Datei angegeben ist, dass die Ressource die Verwendung von Daten von beliebigen Seiten verbietet, sollten Sie höflich sein und die Bedingungen einhalten.
IP-Blockierung
Denken Sie beim Crawlen daran, dass eine Person nicht jede Millisekunde auf Links klicken kann. Internetressourcen halten solche Aktionen für verdächtig und blockieren möglicherweise die IP, von der aus solche Aktionen ausgeführt werden. Daher ist es sinnvoll, zwischen den Anfragen zumindest eine kurze Verzögerung einzuhalten und Proxys zu verwenden, die Ihre echte IP verbergen. Sie können jedoch auch nicht unbegrenzt denselben Proxy verwenden. Daher müssen Sie beim Crawlen, genau wie beim Scraping, mehrere Proxys (Proxy-Pool) verwenden und diese ständig wechseln.
Um ein erfolgreiches Crawlen zu gewährleisten, sollten Sie auch die Einstellungen Ihres Bots überprüfen. Geben Sie Header und Benutzeragenten manuell an, da dies der Site hilft, zu erkennen, dass ein echter Benutzer mit der Site interagiert. Die gute Idee besteht darin, echte Benutzeragenten und Header zu verwenden, beispielsweise die Header Ihres Browsers.
CAPTCHAs
Versuchen Sie, Captchas zu vermeiden, indem Sie alle oben genannten Richtlinien befolgen. Und falls sich Captchas nicht vermeiden lassen, können Sie CAPTCHA-Lösungsdienste nutzen.
Spinnenfalle
Einige Ressourcen hinterlassen Crawlerfallen, sogenannte Honeypots. Hierbei handelt es sich um zusätzliche versteckte Links im Code, die für normale Benutzer im Browser nicht sichtbar sind. Und wenn ein Crawler diesem Link folgt, erkennt die Ressource, dass es sich um einen Bot handelt und blockiert ihn.
Überkriechen
Manchmal kann es vorkommen, dass Bots in einer Endlosschleife stecken bleiben, wenn sie nicht richtig programmiert sind oder zu stark crawlen und die Zielwebsite mit übermäßig vielen Anfragen überfordern – und so Ressourcen von anderen Benutzern wegnehmen, die zu diesem Zeitpunkt möglicherweise versuchen, darauf zuzugreifen.
Best Practices für Web-Crawling und Web-Scraping
Beim Crawlen und Scrapen sind einige Regeln zu beachten, die das Crawlen sowohl für Sie als auch für die Websites erleichtern.
Höflich sein
Wenn Sie die Option haben, crawlen Sie Seiten, die die Ressource in robots.txt zugelassen hat, und begrenzen Sie die Häufigkeit von Anfragen. Andernfalls kann eine starke Auslastung einer Ressource dazu führen, dass diese extrem langsam auf alle Benutzer reagiert oder sogar ausfällt.
Kriechen Sie zu Zeiten mit geringer Nutzung
Sie sollten auch dann kriechen, wenn die Ressourcenbelastung geringer ist, beispielsweise nachts. Auf diese Weise erhalten Sie die benötigten Daten und verursachen gleichzeitig den geringsten Schaden für die Ressource.
Verwenden Sie Caching-Strategien
Implementieren Sie Caching-Strategien, um die Anzahl der auf jeder Seite gestellten Anfragen zu reduzieren und zuvor gecrawlte Daten als zukünftige Referenzpunkte zu speichern, wenn Sie entscheiden, welche Inhalte als nächstes gescrapt werden müssen.
Fazit und Erkenntnisse
Web Scraping und Web Crawling sind wichtige Tools zum Sammeln von Daten aus dem Web. Web Scraping wird zum Extrahieren von Daten von Websites verwendet und kann manuell oder durch automatisierte Skripte durchgeführt werden. Beim Webcrawlen werden Bots eingesetzt, um Websites zu erkunden, Informationen zu sammeln und Inhalte für Suchmaschinen zu indizieren.
Sehen wir uns einige Tipps zur Auswahl des Ansatzes an, der zu Ihrem Projekt oder Ihren Geschäftsanforderungen passt:
- Definieren Sie den Zweck: Der erste Schritt besteht darin, zu verstehen, warum Sie Daten durch Web Scraping oder Crawling sammeln möchten. Dies wird Ihnen bei der Auswahl der richtigen Methode helfen, die Ihren Geschäftsanforderungen entspricht.
- Identifizieren Sie die Daten: Sie sollten die Art der benötigten Daten und ihren Speicherort identifizieren. Auf diese Weise können Sie feststellen, ob Web Scraping oder Crawling die beste Methode zum Datenabruf ist.
- Datenkomplexität analysieren: Es ist wichtig, die Komplexität der Daten zu bewerten, die Sie sammeln möchten. Wenn es sich um einen komplexen Datensatz handelt, ist das Webcrawlen möglicherweise besser geeignet, da dadurch mehr Daten in kürzerer Zeit effizient erfasst werden können.
- Berücksichtigen Sie die Häufigkeit der Datenaktualisierung: Wenn die von Ihnen benötigten Daten häufig aktualisiert werden, ist das Webcrawlen möglicherweise die bessere Option, da es automatisiert werden kann, um die Daten auf dem neuesten Stand zu halten.
Beide Methoden sind für die Datenextraktion aus dem Internet unerlässlich, es hängt jedoch von Ihren Anforderungen ab, welche Technik für Sie am besten geeignet ist.
