
Erfahren Sie in unserem umfassenden Leitfaden, wie Sie Google News und Python für eine Reihe erweiterter Anwendungen nutzen können. Ob für Marktforschung, Stimmungsanalyse oder Krisenmanagement, diese einfach zu implementierenden Techniken können Ihnen dabei helfen, Ihre Herangehensweise an die Nachrichtenbeschaffung zu verändern.
Wir stellen detaillierte Anweisungen zur Verwendung der Google SERP API und Web-Scraping-Bibliotheken wie Beautiful Soup und Selenium für die automatisierte Informationserfassung bereit. Mit diesen Methoden können Sie fortgeschrittenere Anwendungsfälle erkunden, die über die heutigen Schlagzeilen hinausgehen. Entdecken Sie noch heute eine einfachere Möglichkeit, mit Nachrichten zu interagieren!
Google News Scraping mit API
Es gibt zwei Möglichkeiten, Nachrichten aus den Google-Suchergebnissen zu extrahieren: die Verwendung einer Python-Bibliothek für Web Scraping oder die Verwendung der Google News API. Die API-Option ist eine gute Wahl für Anfänger und alle, die sich den Aufwand mit Blockierungen, Captchas und Proxy-Rotation ersparen möchten.
Die Google News API stellt Ihnen Daten im JSON-Format zur Verfügung, die sich einfach verarbeiten und bearbeiten lassen. Sehen wir uns an, wie Sie Schlagzeilen und Beschreibungen von Google News mithilfe der Google News API durchsuchen, was Sie dazu benötigen und wie Sie die erhaltenen Daten in Excel speichern.
Melden Sie sich an und erhalten Sie einen API-Schlüssel
Um die API nutzen zu können, benötigen Sie einen API-Schlüssel. Um es zu erhalten, gehen Sie auf die Scrape-It.Cloud-Website und melden Sie sich an.
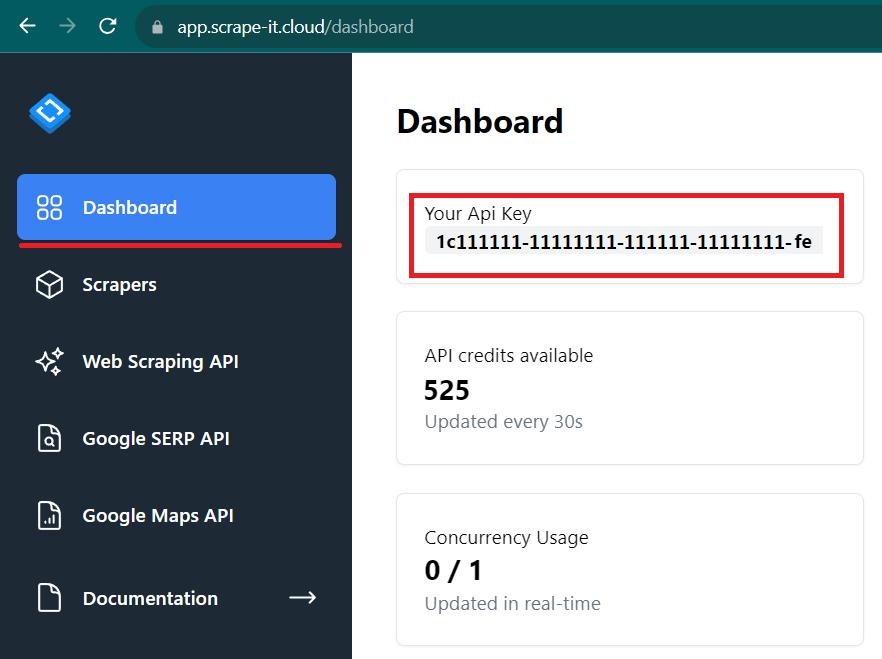
Gehen Sie in Ihrem Konto zur Registerkarte „Dashboard“ und kopieren Sie Ihren persönlichen API-Schlüssel. Wir werden es später brauchen.
Legen Sie die Parameter fest
Lassen Sie uns zunächst die erforderlichen Bibliotheken installieren. Geben Sie dazu in der Eingabeaufforderung Folgendes ein:
pip install requests
pip install pandasDie Requests-Bibliothek ist eine Anforderungsbibliothek, die es uns ermöglicht, die API anzufordern, um die erforderlichen Daten zu erhalten. Und um die Daten zu verarbeiten und anschließend als Excel-Datei zu speichern, wird die Pandas-Bibliothek benötigt.
Nachdem die Bibliotheken nun installiert sind, erstellen Sie eine Datei mit der Erweiterung *.py und importieren Sie sie.
import requests
import pandas as pdLassen Sie uns nun die Parameter festlegen, die in Variablen eingegeben werden können. Es gibt nur zwei davon: einen Verweis auf den API-Endpunkt und ein Schlüsselwort.
keyword = 'new york good news'
api_url="https://api.scrape-it.cloud/scrape/google"Als letztes müssen die Header und der Text der Anfrage festgelegt werden. Der Header enthält nur einen Parameter – den API-Schlüssel. Der Anforderungstext kann jedoch viele Parameter enthalten, einschließlich Lokalisierungsparameter. Die vollständige Liste der Parameter finden Sie in unserer Dokumentation.
In diesem Beispiel verwenden wir nur die notwendigen Parameter:
headers = {'x-api-key': 'YOUR-API-KEY'}
params = {
'q': keyword,
'domain': 'google.com',
'tbm': 'nws'
}Wir haben das Schlüsselwort, die Domäne und den Typ angegeben. Die übrigen Parameter können nicht spezifiziert werden, sie können jedoch zur Feinabstimmung der Abfrage und zum Erhalten spezifischerer Ergebnisse verwendet werden.
Eine Anfrage stellen
Nachdem nun alle notwendigen Parameter angegeben sind, führen Sie die Anfrage aus:
response = requests.get(api_url, params=params, headers=headers)Die Google News API von Scrape-It.Cloud verwendet eine GET-Anfrage und stellt eine JSON-Antwort im folgenden Format bereit:
{
"requestMetadata": {
"id": "57239e2b-02a2-4bfb-878d-9c36f5c21798",
"googleUrl": "https://www.google.com/search?q=Coffee&uule=w+CAIQICIaQXVzdGluLFRleGFzLFVuaXRlZCBTdGF0ZXM%3D&gl=us&hl=en&filter=1&tbm=nws&oq=Coffee&sourceid=chrome&num=10&ie=UTF-8",
"googleHtmlFile": "https://storage.googleapis.com/scrapeit-cloud-screenshots/57239e2b-02a2-4bfb-878d-9c36f5c21798.html",
"status": "ok"
},
"pagination": {
"next": "https://www.google.com/search?q=Coffee&gl=us&hl=en&tbm=nws&ei=sim9ZPe7Noit5NoP3_efgAU&start=10&sa=N&ved=2ahUKEwj33Jes9qSAAxWIFlkFHd_7B1AQ8NMDegQIAhAW",
"current": 1,
"pages": (
{
"2": "https://www.google.com/search?q=Coffee&gl=us&hl=en&tbm=nws&ei=sim9ZPe7Noit5NoP3_efgAU&start=10&sa=N&ved=2ahUKEwj33Jes9qSAAxWIFlkFHd_7B1AQ8tMDegQIAhAE"
},
// ... More pages ...
)
},
"searchInformation": {
"totalResults": "37600000",
"timeTaken": 0.47
},
"newsResults": (
{
"position": 1,
"title": "De'Longhi's TrueBrew Coffee Maker Boasts Simplicity, but the Joe Is Just So-So",
"link": "https://www.wired.com/review/delonghi-truebrew-drip-coffee-maker/",
"source": "WIRED",
"snippet": "The expensive coffee maker with Brad Pitt as its spokesmodel is better than a capsule-based machine but not as good as competing single-cup...",
"date": "1 day ago"
},
// ... More news results ...
)
}Sie können die erhaltenen Daten auf dem Bildschirm anzeigen oder damit weiterarbeiten.
Analysieren Sie die Daten
Um die Daten weiter zu verarbeiten, müssen wir sie analysieren. Zu diesem Zweck geben wir ausdrücklich an, dass die Daten im JSON-Format gespeichert werden:
data = response.json()Jetzt können wir die Attributnamen verwenden, um bestimmte Daten abzurufen:
news = data('newsResults')Daher haben wir alle Nachrichten in die Nachrichtenvariable eingefügt.
Speichern Sie die gesammelten Daten
Um die gewonnenen Daten als Excel-Datei zu speichern, verwenden wir Pandas. Mit dieser Bibliothek können wir aus einer JSON-Antwort einen Datenrahmen oder einen organisierten Datensatz als Tabelle erstellen.
df = pd.DataFrame(news)Die Überschriften sind identisch mit den Attributnamen. Jetzt speichern wir einfach den Datenrahmen in einer Datei:
df.to_excel("news_result.xlsx", index=False)Das Ergebnis ist eine Tabelle wie diese:

Um den Code zuverlässiger zu machen, fügen wir try..exclusive-Blöcke hinzu und prüfen, ob eine erfolgreiche Antwort erfolgt. Resultierender Code:
import requests
import pandas as pd
keyword = 'new york good news'
api_url="https://api.scrape-it.cloud/scrape/google"
headers = {'x-api-key': 'YOUR-API-KEY'}
params = {
'q': keyword,
'domain': 'google.com',
'tbm': 'nws'
}
try:
response = requests.get(api_url, params=params, headers=headers)
if response.status_code == 200:
data = response.json()
news = data('newsResults')
df = pd.DataFrame(news)
df.to_excel("news_result.xlsx", index=False)
except Exception as e:
print('Error:', e)So haben wir die Daten erhalten, ohne HTML-Seiten verarbeiten, Proxys verwenden oder nach Möglichkeiten suchen zu müssen, Blockierungen und Captchas zu umgehen.
Scrapen Sie Google News-Ergebnisse mit Selenium
Die nächste Möglichkeit zum Scrapen von Google News ist die Verwendung von Python-Bibliotheken. In diesem Fall lohnt es sich, Headless-Browser zu verwenden, um das Verhalten eines echten Benutzers nachzuahmen und so das Risiko einer Blockierung zu verringern.
Wir werden Selenium verwenden, um Google News Scraper zu erstellen, da es mit verschiedenen Programmiersprachen funktioniert und mehrere Webtreiber unterstützt. In diesem Tutorial verwenden wir den Chrome-Webtreiber.
Installieren Sie die Bibliothek und laden Sie den Webdriver herunter
Um Selenium zu installieren, geben Sie an der Eingabeaufforderung Folgendes ein:
pip install seleniumGehen Sie dann zur Chrome-Webtreiber-Website und laden Sie die benötigte Version herunter (sie sollte mit der Version von Google Chrome übereinstimmen, die Sie installiert haben).
Recherchieren Sie die Seitenstruktur von Google News
Schauen Sie sich vor dem Schreiben des Codes die Google News-Seite an und recherchieren Sie die Teile, die wir kratzen werden. Als erstes sollten Sie sich den Link zur Google News-Seite ansehen. Lasst uns rübergehen und sehen, wie es aussieht.
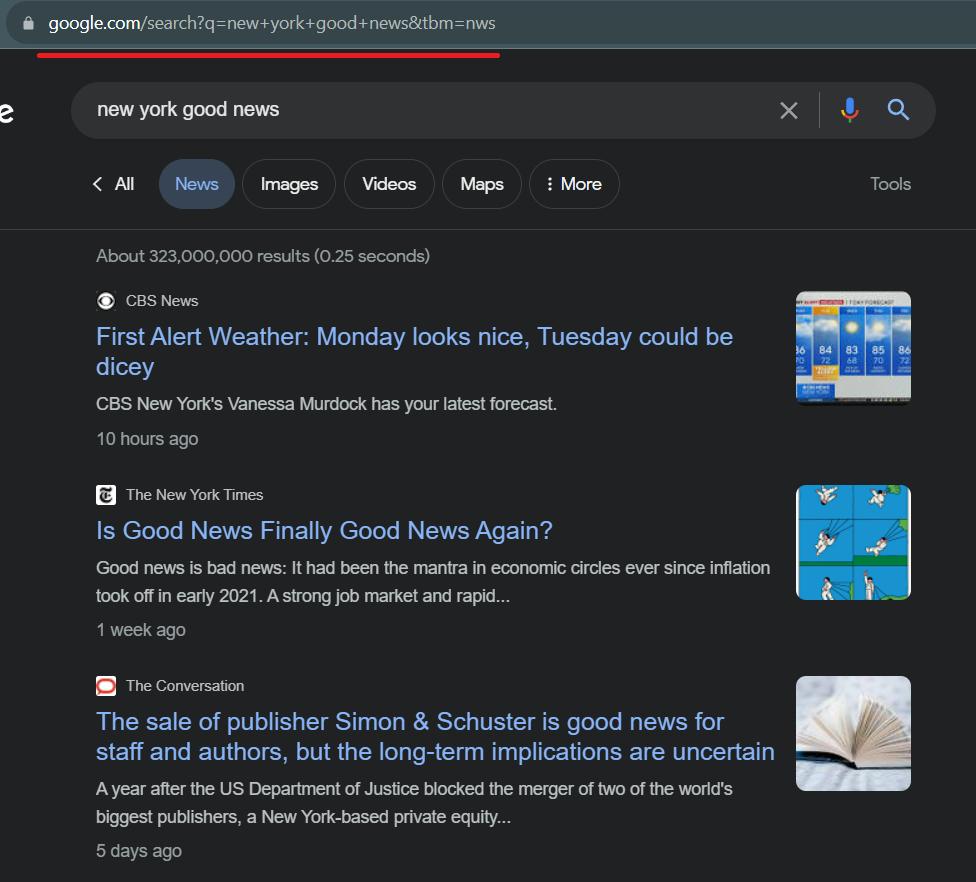
Wie wir sehen, können wir ganz einfach Scraping-Links erstellen, indem wir „new york good news“ durch eine beliebige andere Suchanfrage ersetzen.
Gehen wir nun zu den Entwicklertools (F12 oder Rechtsklick auf den Bildschirm und „Inspizieren“) und schauen wir uns eines der Ergebnisse genauer an.

Alle Nachrichten haben ein div-Tag mit id=“rso“. Wir können dies und die HTML-Seitenstruktur verwenden, um die benötigten Daten zu erhalten. Um die Elemente selbst abzurufen, können wir den Selektor „div#rso > div > div > div > div > div > div“ verwenden, der die Daten in div-Tags abruft.
In einer anderen Situation würden wir die Daten von den Elementen mithilfe von Klassen abrufen. Dies könnte die Klasse „SoaBEf“ sein, die allen Elementen gemeinsam ist. Allerdings ändern sich die Klassennamen in Google News häufig und sind nicht konstant. Verlassen wir uns daher auf die Struktur und die Elemente, die sich nicht ändern werden.
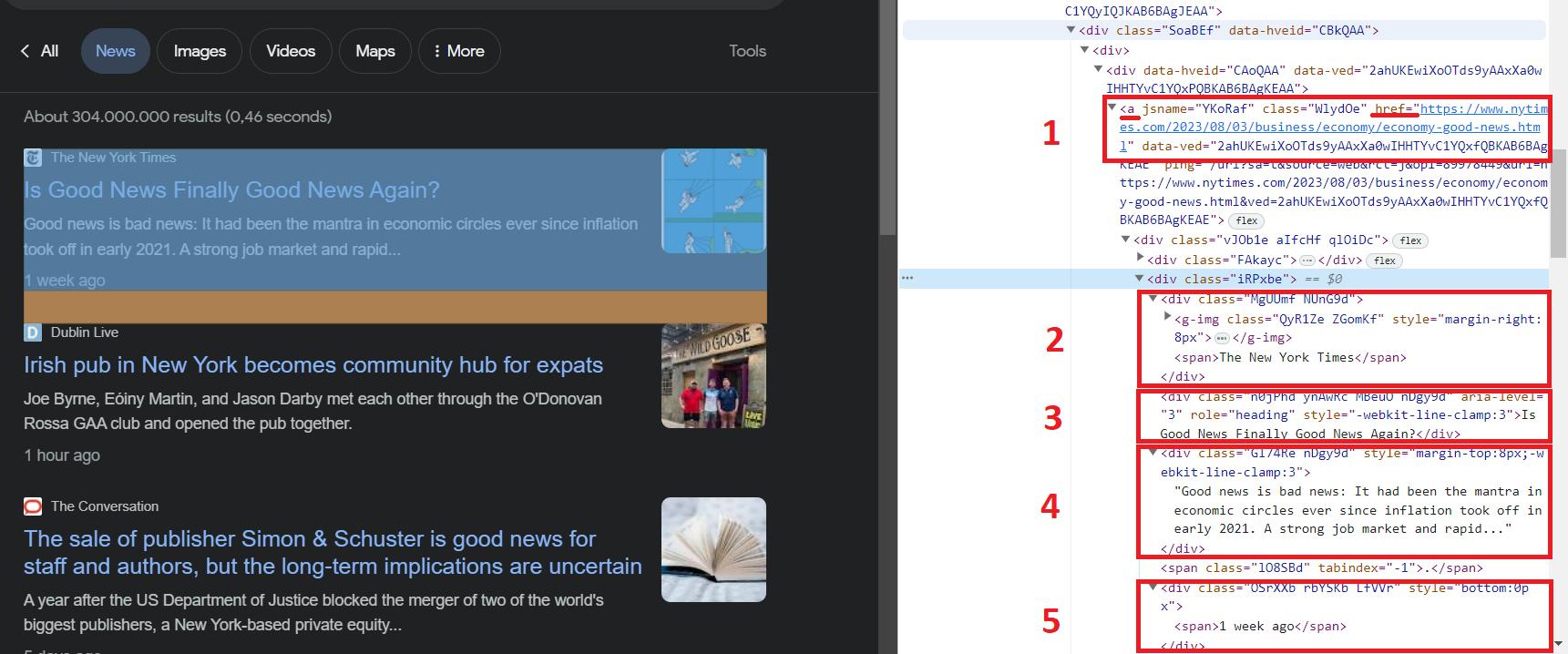
Hier können wir, wie wir sehen können, die folgenden Daten erhalten:
- Der Link zu den Neuigkeiten.
- Der Name der Ressource, in der die Neuigkeiten veröffentlicht werden.
- Die Schlagzeile der Nachrichten.
- Eine Beschreibung der Neuigkeiten.
- Wie lange ist es her, dass die Nachricht veröffentlicht wurde?
Nachdem wir nun wissen, welche Daten wir benötigen, können wir mit dem Scraping fortfahren.
Bibliothek importieren und Parameter festlegen
Erstellen Sie eine neue Datei mit der Erweiterung *.py und beschädigen Sie die erforderlichen Selenium-Bibliotheksmodule:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import ServiceLegen wir nun den Pfad zur zuvor heruntergeladenen Web-Treiberdatei und den Link zur Google-News-Seite fest, die gescrapt werden soll.
chromedriver_path="C://chromedriver.exe"
url="https://www.google.com/search?q=new+york+good+news&tbm=nws"Wir müssen auch die Parameter des auszuführenden Webtreibers angeben.
service = Service(chromedriver_path)
driver = webdriver.Chrome(service=service)Damit ist die Vorbereitung abgeschlossen und Sie können mit der Datenerfassung fortfahren.
Gehen Sie zu Google News und Scrape Data
Wir müssen lediglich die Abfrage ausführen und die Daten sammeln. Führen Sie dazu webdriver aus:
driver.get(url)Wenn Sie das Skript jetzt ausführen, wird ein Google Chrome-Fenster geöffnet, das zur Suchabfrage navigiert.
Lassen Sie uns nun den Inhalt der Seite analysieren, auf der wir uns befinden. Zu diesem Zweck haben wir die Webseite zuvor untersucht und ihre Struktur untersucht. Jetzt nutzen wir es und erhalten alle Neuigkeiten auf der Seite:
news_results = driver.find_elements(By.CSS_SELECTOR, 'div#rso > div > div > div > div')Dann gehen wir jedes Element einzeln um:
for news_div in news_results:Sammeln wir zunächst die Links und zeigen sie auf dem Bildschirm an:
news_link = news_div.find_element(By.TAG_NAME, 'a').get_attribute('href')
print("Link:", news_link)Dann erhalten wir die restlichen Elemente:
divs_inside_news = news_div.find_elements(By.CSS_SELECTOR, 'a > div > div > div')
news_item = ()
for new in divs_inside_news:
news_item.append(new.text)Lassen Sie uns nun diese Werte auf dem Bildschirm anzeigen:
print("Domain:", news_item(1))
print("Title:", news_item(2))
print("Description:", news_item(3))
print("Date:", news_item(4))Machen Sie eine Trennlinie zwischen den verschiedenen Nachrichten, damit sie optisch deutlich erkennbar ist:
print("-"*50+"\n\n"+"-"*50)Und schließlich schließen Sie den Webtreiber.
driver.quit()Wenn wir nun dieses Skript ausführen, erhalten wir die Daten in der Form:
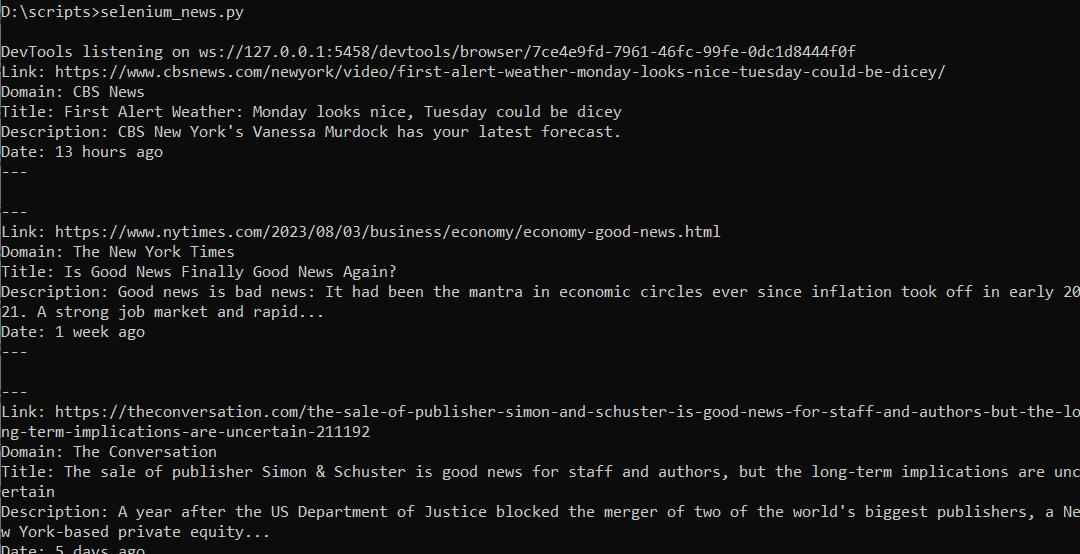
Vollständiger Code:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
chromedriver_path="C://chromedriver.exe"
service = Service(chromedriver_path)
driver = webdriver.Chrome(service=service)
url="https://www.google.com/search?q=new+york+good+news&tbm=nws"
driver.get(url)
news_results = driver.find_elements(By.CSS_SELECTOR, 'div#rso > div >div>div>div')
for news_div in news_results:
news_item = ()
try:
news_link = news_div.find_element(By.TAG_NAME, 'a').get_attribute('href')
print("Link:", news_link)
divs_inside_news = news_div.find_elements(By.CSS_SELECTOR, 'a>div>div>div')
for new in divs_inside_news:
news_item.append(new.text)
print("Domain:", news_item(1))
print("Title:", news_item(2))
print("Description:", news_item(3))
print("Date:", news_item(4))
print("-"*50+"\n\n"+"-"*50)
except Exception as e:
print("No Elems")
driver.quit()Wenn Sie die Daten im Excel-Format speichern möchten, können Sie sie Zeile für Zeile eingeben oder, wie in der vorherigen Option, einen Datenrahmen erstellen und alles auf einmal speichern.
Fazit und Erkenntnisse
In diesem Artikel werden zwei Möglichkeiten zum Scrapen von Google News-Daten mit Python besprochen: die Verwendung der Google News API und die Anwendung von Web-Scraping-Methoden mithilfe der Selenium-Bibliothek. Die Google News API bietet einen einfachen Ansatz und stellt Daten im JSON-Format bereit, die schnell verarbeitet und analysiert werden können. Durch den Erhalt des API-Schlüssels und das Festlegen der Parameter können Sie schnell Nachrichteninformationen entsprechend Ihren Anforderungen abrufen.
Für diejenigen, die mehr Kontrolle und Flexibilität benötigen, kann Web Scraping mit Selenium eine Alternative sein. Indem Selenium das Verhalten und die Interaktion des Benutzers mit einer Webseite nachahmt, können Sie bestimmte Datenelemente extrahieren. Diese Methode eignet sich, wenn komplexere Interaktionen mit einer Webseite erforderlich sind, beispielsweise das Ausfüllen von Feldern.
Der Artikel beschrieb einen schrittweisen Prozess für beide Methoden und stellte Codebeispiele bereit, die zeigen, wie jede Methode zum Abrufen von Google News-Daten verwendet wird. Wenn Sie den Anweisungen und Codeausschnitten folgen, erhalten Sie eine klare Vorstellung davon, wie Sie Nachrichtendaten von Google News für maschinelles Lernen oder Ihre Analyse- und Forschungsanforderungen sammeln.
