
Mengekstraksi data dari situs web menjadi hal yang penting dalam berbagai bidang, mulai dari pengumpulan data hingga analisis persaingan. Metode pengikisan web tradisional sering kali memerlukan pemuatan browser lengkap, yang dapat memakan banyak sumber daya dan waktu karena penyajian elemen UI seperti bilah alat dan tombol. Di sinilah alat otomatisasi browser tanpa kepala seperti Puppeteer berperan.
Di blog mendetail ini, kami akan membahas cara menggunakan Dalang untuk web scraping. Kami akan mengeksplorasi manfaatnya, pengikisan halaman tunggal dan ganda, penanganan kesalahan, klik tombol, pengiriman formulir, dan teknik utama seperti memanfaatkan header permintaan dan proxy untuk melewati deteksi. Selain itu, Anda akan mempelajari mengapa API web scraping adalah pilihan terbaik untuk scraping yang efisien dalam skala besar.
Daftar Isi
Mengapa menggunakan Dalang untuk web scraping?
Dalang adalah alat otomatisasi browser yang memungkinkan pengembang mengontrol browser secara terprogram melalui API tingkat tinggi, memanfaatkan protokol DevTools.
Kontrol peramban
Dalang memberikan kontrol canggih atas tindakan browser, memungkinkan interaksi dengan elemen seperti tombol dan formulir, pengguliran halaman, dan fitur seperti mengambil tangkapan layar atau menjalankan JavaScript khusus.
Dukungan untuk browser tanpa kepala
Secara default, Puppeteer beroperasi dalam mode tanpa kepala, artinya berjalan tanpa antarmuka grafis, sehingga meningkatkan kecepatan dan efisiensi memori. Namun, ini juga dapat dikonfigurasi untuk berjalan di jendela Chrome/Chromium penuh (“kaya kepala”). Ini menggunakan browser Chromium secara default, tetapi juga dapat dikonfigurasi untuk menggunakan Chrome atau Firefox dengan perpustakaan tidak resmi.
API yang kuat
Dalang menyediakan API tingkat tinggi untuk mengontrol dan berinteraksi secara mulus dengan halaman web melalui kode, memungkinkan interaksi elemen, manipulasi halaman web, dan navigasi lintas halaman.
Mencegat permintaan jaringan
Dalang menawarkan fitur-fitur canggih seperti mencegat dan memodifikasi permintaan jaringan. Anda dapat melihat detail setiap permintaan, seperti: B. URL, header dan body, dan menganalisis tanggapannya. Fungsionalitas ini memungkinkan ekstraksi konten dinamis dan modifikasi respons API.
keramahan pengguna
Dalang dikenal karena fleksibilitas dan kemudahan penggunaannya. Ini menyederhanakan tugas pengikisan dan otomatisasi web, membuatnya dapat diakses bahkan oleh pengembang dengan pengalaman minimal di bidang ini.
Persiapan lingkungan
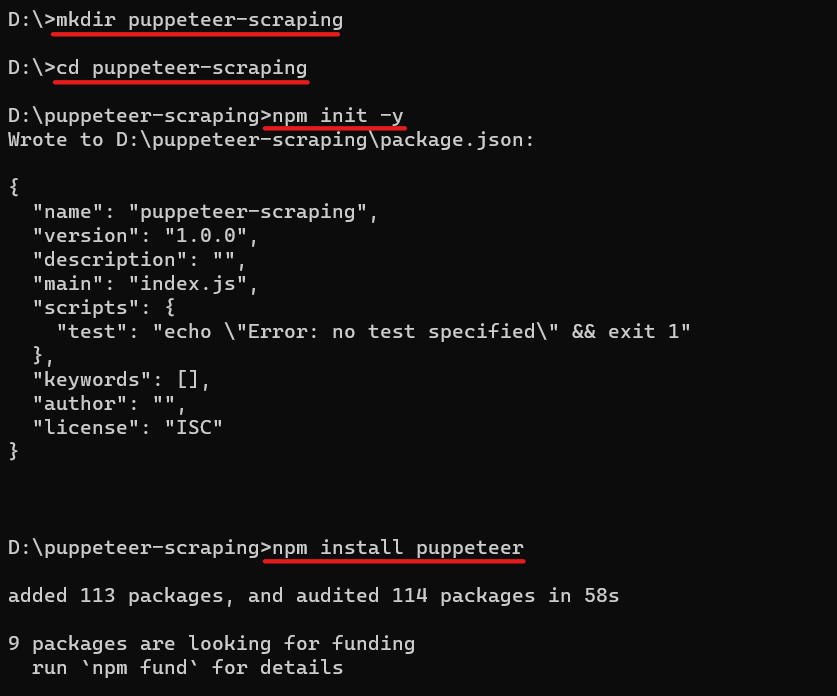
Sebelum kita mulai melakukan scraping, mari kita persiapkan lingkungan kita. Unduh dan instal Node.js dari situs resminya jika Anda belum melakukannya. Kemudian silakan buat direktori baru untuk proyek Anda, navigasikan ke sana dan inisialisasi proyek Node.js dengan menjalankannya npm init. Itu npm init -y Perintah itu menciptakannya package.json File dengan semua dependensi.
mkdir puppeteer-scraping
cd puppeteer-scraping
npm init -ySekarang Anda dapat menginstal Puppeteer menggunakan NPM (Node Package Manager). Untuk menginstal Puppeteer menggunakan NPM: Navigasikan ke direktori proyek Anda cd perintah dan jalankan perintah berikut:
npm install puppeteerPerintah ini akan mengunduh Puppeteer dan menambahkannya sebagai ketergantungan pada proyek Anda dan browser khusus yang digunakannya (Chromium).
Seperti inilah proses lengkapnya:
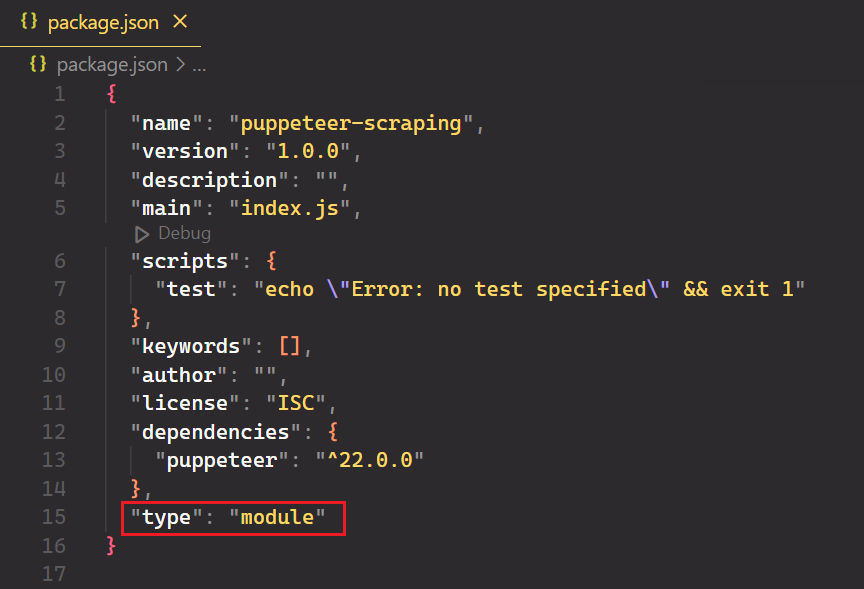
Buka proyek di editor kode favorit Anda dan buat file baru bernama index.js. Terakhir, buka package.json Tambahkan dan tambahkan file "type": "module" untuk mendukung sintaksis JavaScript modern.
Dasar-dasar Mengikis dengan Dalang
Sekarang lingkungan Anda sudah siap, mari kita mulai dengan web scraping dasar dengan Puppeteer. Anda dapat melakukan semua hal yang biasa Anda lakukan secara manual di browser, mulai dari mengambil tangkapan layar hingga merayapi beberapa halaman.
Memilih data yang akan dikikis
Kami akan mengekstrak data dari topik GitHub. Ini memungkinkan Anda memilih topik dan jumlah repositori yang ingin Anda ekstrak. Scraper kemudian mengembalikan informasi yang terkait dengan topik yang dipilih.
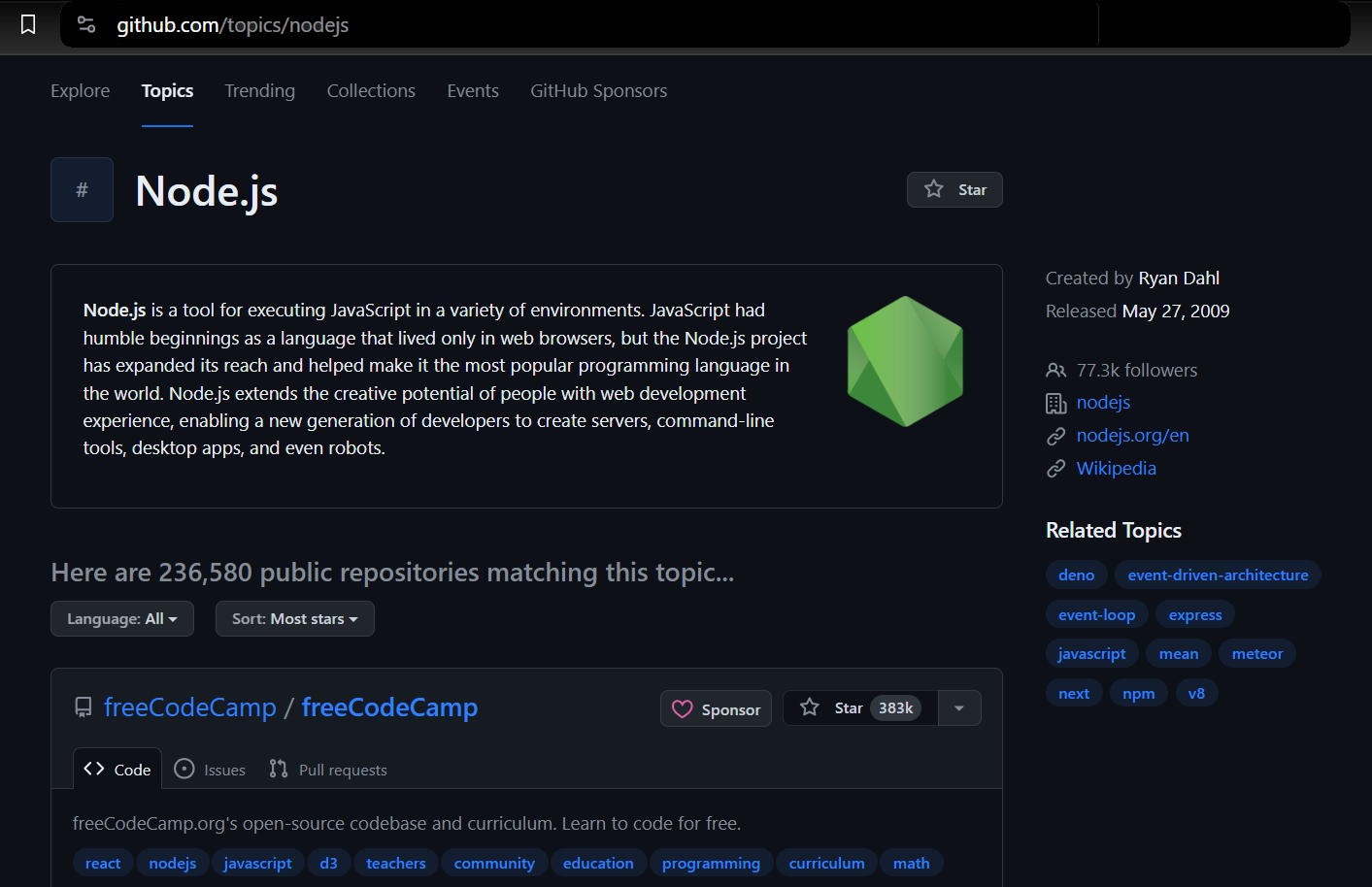
Kami menggunakan Puppeteer untuk meluncurkan browser, menavigasi ke halaman topik GitHub, dan mengekstrak informasi yang diperlukan. Ini mencakup detail seperti pemilik repositori, nama repositori, URL repositori, jumlah bintang repositori, deskripsinya, dan semua tag terkait.
Untuk memulai, Anda perlu membuka jendela browser baru menggunakan Puppeteer dan membuka URL tertentu. Dalam cuplikan kode berikut adalah puppeteer.launch() Fungsi memulai instance browser baru dan browser.newPage() membuat halaman baru dalam contoh ini. Itu page.goto() Fungsi tersebut kemudian menavigasi ke URL yang ditentukan.
import puppeteer from "puppeteer";
const browser = await puppeteer.launch({
headless: true,
defaultViewport: null
});
const page = await browser.newPage();
await page.goto('<https://github.com/topics/nodejs>');Tangkapan layar halaman web
Dalang memungkinkan Anda mengambil tangkapan layar halaman web. Fitur ini berharga untuk tinjauan visual karena memungkinkan Anda mengambil cuplikan kapan saja.
import puppeteer from "puppeteer";
const browser = await puppeteer.launch({
headless: true,
defaultViewport: null
});
const page = await browser.newPage();
await page.goto('<https://github.com/topics/nodejs>');
await page.screenshot({ path: 'Images/screenshot.png' });
await browser.close();Untuk menangkap seluruh halaman, atur fullPage properti ke true. Anda juga dapat mengubah format gambar jpg atau jpeg untuk menyimpan dalam format yang berbeda.
await page.screenshot({ path: 'Images/screenshot.jpg', fullPage: true });Menggores satu halaman
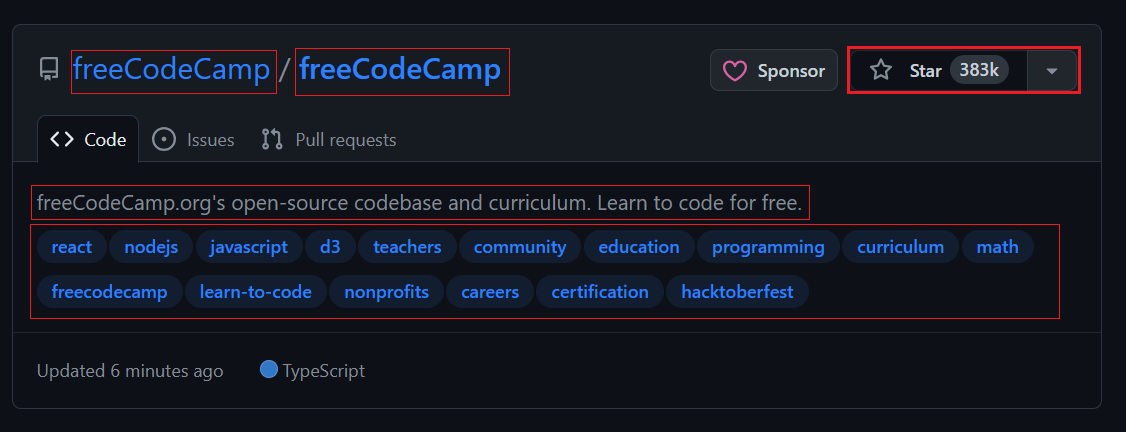
Saat Anda membuka halaman topik, Anda akan melihat 20 repositori. Setiap entri ditampilkan sebagai <article> -Elemen menampilkan informasi tentang repositori tertentu. Anda dapat memperluas setiap item untuk melihat informasi lebih rinci tentang repositori terkait.
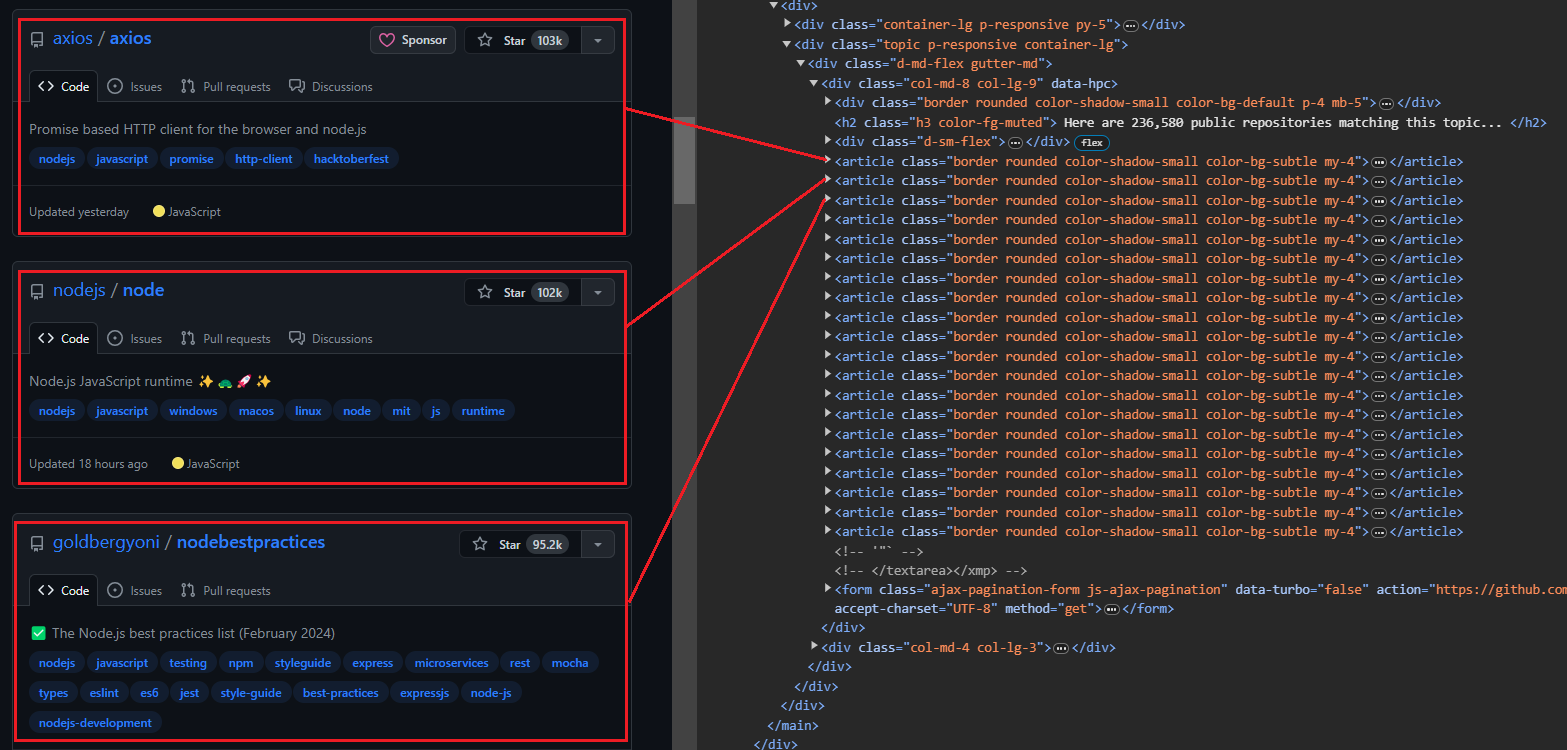
Gambar di bawah menunjukkan tampilan yang diperluas <article> Elemen yang menampilkan semua informasi tentang repositori.
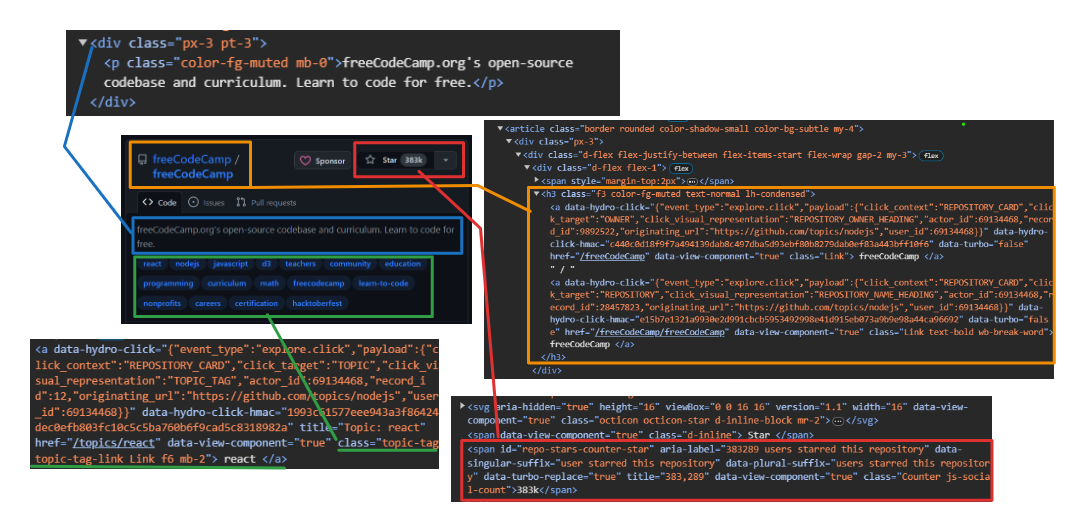
Mengekstraksi informasi pengguna dan repositori:
- Pengguna: Menggunakan
h3 > a:first-childuntuk mengatasi tag jangkar pertama secara langsung di dalam a<h3>Label. - Nama repositori: Targetkan anak kedua yang sama
<h3>Induk. Anak ini berisi nama dan URL. Gunakan itutextContentProperti untuk mengekstrak nama dangetAttribute('href')Metode untuk mengekstrak URL. - Jumlah bintang: Menggunakan
#repo-stars-counter-staruntuk memilih elemen dan mengekstrak nomor sebenarnya darinyatitleAtribut. - Deskripsi repositori: Menggunakan
div.px-3 > puntuk memilih paragraf pertama dalam adivdengan kelaspx-3. - Tag repositori: Menggunakan
a.topic-taguntuk memilih semua tag jangkar dengan kelastopic-tag.
Itu querySelector memilih elemen pertama yang cocok dengan pemilih CSS tertentu dalam dokumen atau elemen querySelectorAll memilih semua elemen yang cocok dengan pemilih.
Berikut cuplikan kodenya:
repos.forEach(repo => {
const user = repo.querySelector('h3 > a:first-child').textContent.trim();
const repoLink = repo.querySelector('h3 > a:nth-child(2)');
const repoName = repoLink.textContent.trim();
const repoUrl = repoLink.getAttribute('href');
const repoStar = repo.querySelector('#repo-stars-counter-star').getAttribute('title');
const repoDescription = repo.querySelector('div.px-3 > p').textContent.trim();
const tagsElements = Array.from(repo.querySelectorAll('a.topic-tag'));
const tags = tagsElements.map(tag => tag.textContent.trim());
});Mari kita lihat keseluruhan proses mengekstraksi semua repositori dari satu halaman.
Prosesnya dimulai dengan page.evaluate Metode yang menjalankan JavaScript pada halaman. Ini berguna untuk mengekstraksi data tanpa mengunduh semua konten HTML. Kami mendefinisikan semua variabel dan penyeleksi dalam metode ini.
const repos = await page.evaluate(() => { ... });Kemudian pilih semua elemen dengan kelas border dalam article Tandai dan ubah menjadi array bernama repos. Buat juga array kosong bernama repoData untuk menyimpan informasi yang diekstraksi.
const repos = Array.from(document.querySelectorAll('article.border'));
const repoData = ();Iterasi melalui setiap elemen di repos Array untuk mengekstrak semua data yang relevan untuk setiap repositori menggunakan penyeleksi yang disediakan.
repos.forEach(repo => { ... });Terakhir, data yang diekstraksi untuk setiap repositori ditambahkan ke repoData Array, dan array dikembalikan.
repoData.push({ user, repoName, repoStar, repoDescription, tags, repoUrl });Berikut adalah kode untuk semua langkah di atas.
const extractedRepos = await page.evaluate(() => {
const repos = Array.from(document.querySelectorAll('article.border'));
const repoData = ();
repos.forEach(repo => {
const user = repo.querySelector('h3 > a:first-child').textContent.trim();
const repoLink = repo.querySelector('h3 > a:nth-child(2)');
const repoName = repoLink.textContent.trim();
const repoUrl = repoLink.getAttribute('href');
const repoStar = repo.querySelector('#repo-stars-counter-star').getAttribute('title');
const repoDescription = repo.querySelector('div.px-3 > p').textContent.trim();
const tagsElements = Array.from(repo.querySelectorAll('a.topic-tag'));
const tags = tagsElements.map(tag => tag.textContent.trim());
repoData.push({ user, repoName, repoStar, repoDescription, tags, repoUrl });
});
return repoData;
});Berikut kode lengkapnya. Dengan kode ini Anda dapat dengan mudah mengumpulkan data dari satu halaman. Jalankan saja dan nikmati hasilnya!
// Import the Puppeteer library
import puppeteer from "puppeteer";
(async () => {
// Launch a headless browser
const browser = await puppeteer.launch({ headless: true });
// Open a new page
const page = await browser.newPage();
// Navigate to the Node.js topic page on GitHub
await page.goto('<https://github.com/topics/nodejs>');
const extractedRepos = await page.evaluate(() => {
// Select all repository elements
const repos = Array.from(document.querySelectorAll('article.border'));
// Create an empty array to store extracted data
const repoData = ();
// Loop through each repository element
repos.forEach(repo => {
// Extract specific details from the repository element
const user = repo.querySelector('h3 > a:first-child').textContent.trim();
const repoLink = repo.querySelector('h3 > a:nth-child(2)');
const repoName = repoLink.textContent.trim();
const repoUrl = repoLink.getAttribute('href');
const repoStar = repo.querySelector('#repo-stars-counter-star').getAttribute('title');
const repoDescription = repo.querySelector('div.px-3 > p').textContent.trim();
const tagsElements = Array.from(repo.querySelectorAll('a.topic-tag'));
const tags = tagsElements.map(tag => tag.textContent.trim());
// Add extracted data to the main array
repoData.push({ user, repoName, repoStar, repoDescription, tags, repoUrl });
});
// Return the extracted data
return repoData;
});
console.log(`We extracted ${extractedRepos.length} repositories.\\n`);
// Print the extracted data to the console
console.dir(extractedRepos, { depth: null }); // Show all nested data
// Close the browser
await browser.close();
})();Hasilnya adalah:
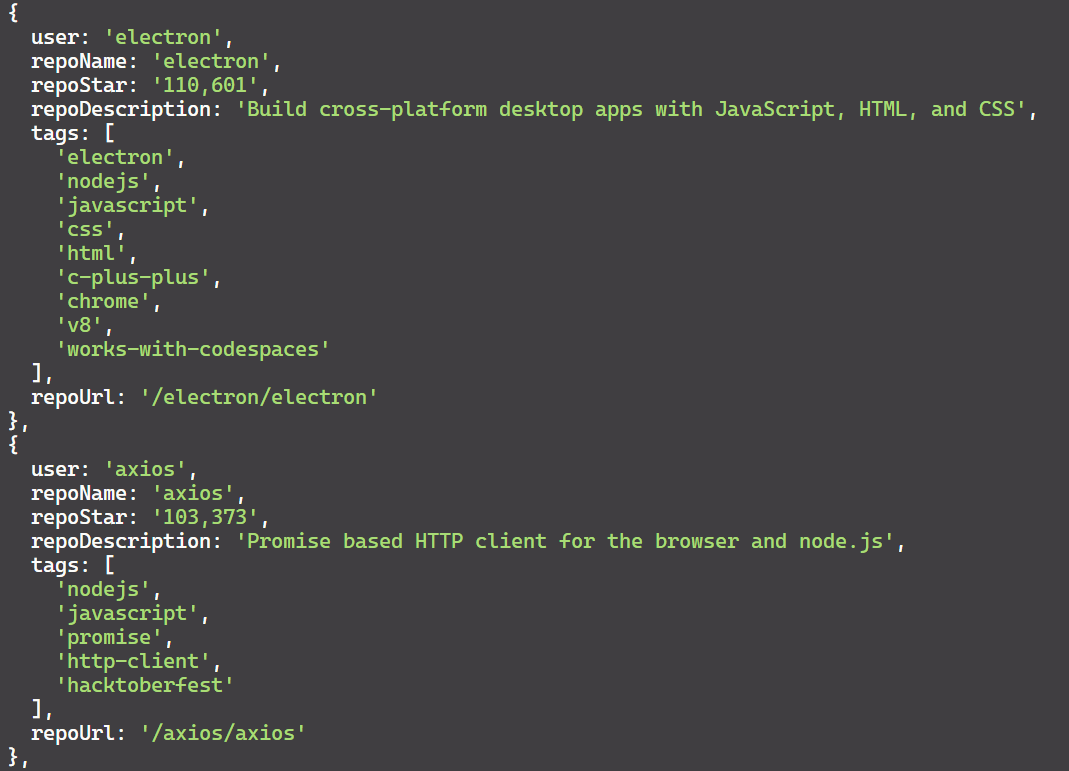
Jika Anda ingin mempelajari lebih lanjut tentang web scraping dengan Node.js selain Puppeteer, Anda mungkin menemukan panduan komprehensif kami tentang web scraping dengan Node.js bermanfaat. Artikel ini membahas pustaka dan teknik tambahan untuk meningkatkan kemampuan scraping Anda dengan Node.js.
Teknik pengikisan tingkat lanjut
Kami telah berhasil menghapus satu halaman. Sekarang mari beralih ke pengikisan tingkat lanjut dengan Dalang. Anda dapat mengklik tombol, mengisi formulir, meng-crawl beberapa halaman, dan memutar header dan proxy untuk membuat scraping Anda lebih andal.
Klik tombol dan tunggu tindakan
Anda dapat memuat repositori tambahan dengan mengklik tombol “Muat Lebih Banyak…” di bagian bawah halaman. Berikut adalah tindakan yang memberitahu Puppeteer untuk memuat lebih banyak repositori:
- Tunggu hingga tombol “Muat lebih banyak…” muncul.
- Klik tombol “Muat Lebih Banyak…”.
- Tunggu hingga repositori baru dimuat sebelum melanjutkan.
Mengklik tombol dengan Dalang sangatlah mudah! Mulailah pencarian Anda "text/" diikuti dengan teks yang Anda cari. Dalang kemudian menemukan elemen yang berisi teks tersebut dan mengkliknya.
const buttonSelector = "text/Load more";
await page.waitForSelector(buttonSelector);
await page.click(buttonSelector);Merangkak beberapa halaman
Untuk merayapi beberapa halaman, Anda perlu mengklik tombol Muat Lebih Banyak berulang kali hingga Anda mencapai akhir. Namun, kita dapat menulis kode untuk mengotomatiskan proses ini dan mencari sejumlah repositori yang diinginkan. Misalnya, bayangkan ada 10.000 repositori nodejs dan Anda hanya ingin mengekstrak data untuk 1.000 repositori tersebut.
Berikut cara skrip meng-crawl beberapa halaman:
- Buka halaman topik nodejs di GitHub.
- Buat set kosong untuk menyimpan entri data repositori unik.
- Tunggu untuk itu
article.borderItem yang akan dimuat menunjukkan keberadaan repositori. - Gunakan dalang
evaluateBerfungsi untuk mengekstrak data dari repositori mana pun. - Gunakan perbandingan string JSON untuk memeriksa apakah data yang diekstraksi sudah ada di kumpulan. Jika unik, tambahkan ke set.
- Ketika ukuran yang ditetapkan mencapai jumlah repositori yang diinginkan (dalam hal ini 30), hentikan iterasi.
- Jika tidak, coba temukan tombol Muat Lebih Banyak dan klik tombol tersebut untuk menavigasi ke halaman repositori berikutnya.
Ini kodenya:
import puppeteer from "puppeteer";
import { exit } from "process";
async function scrapeData(numRepos) {
try {
// Launch headless browser with default viewport
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
// Navigate to nodejs
await page.goto("<https://github.com/topics/nodejs>");
// Use a Set to store unique entries efficiently
let uniqueRepos = new Set();
// Flag to track if there are more repos to load
let hasMoreRepos = true;
while (hasMoreRepos && uniqueRepos.size < numRepos) {
try {
// Extract data from repositories
const extractedData = await page.evaluate(() => {
const repos = document.querySelectorAll("article.border");
const repoData = ();
repos.forEach((repo) => {
const userLink = repo.querySelector("h3 > a:first-child");
const repoLink = repo.querySelector("h3 > a:last-child");
const user = userLink.textContent.trim();
const repoName = repoLink.textContent.trim();
const repoStar = repo.querySelector("#repo-stars-counter-star").title;
const repoDescription = repo.querySelector("div.px-3 > p")?.textContent.trim() || "";
const tags = Array.from(repo.querySelectorAll("a.topic-tag")).map((tag) => tag.textContent.trim());
const repoUrl = repoLink.href;
repoData.push({ user, repoName, repoStar, repoDescription, tags, repoUrl });
});
return repoData;
});
extractedData.forEach((entry) => uniqueRepos.add(JSON.stringify(entry)));
// Check if enough repos have been scraped
if (uniqueRepos.size >= numRepos) {
uniqueRepos = Array.from(uniqueRepos).slice(0, numRepos);
hasMoreRepos = false;
break;
}
// Click "Load more" button if available
const buttonSelector = "text/Load more";
const button = await page.waitForSelector(buttonSelector, { timeout: 5000 });
if (button) {
await button.click();
} else {
console.log("No more repos found. All data scraped.");
hasMoreRepos = false;
}
} catch (error) {
console.error("Error while extracting data:", error);
exit(1);
}
}
// Convert unique entries to an array and format JSON content
const uniqueList = Array.from(uniqueRepos).map((entry) => JSON.parse(entry));
console.dir(uniqueList, { depth: null });
await browser.close();
} catch (error) {
console.error("Error during scraping process:", error);
exit(1);
}
}
scrapeData(30);Mengisi formulir dan mensimulasikan interaksi pengguna
Kami akan menggunakan dua fitur Dalang penting: type untuk memasukkan kueri dan press Untuk mengirimkan formulir, tekan Enter.
import puppeteer from "puppeteer";
(async () => {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
await page.goto('<https://youtube.com/>');
const input = await page.$('input(id="search")');
await input.type('nasa');
await page.keyboard.press('Enter');
await page.waitForSelector('ytd-video-renderer');
await page.screenshot({ path: 'youtube_search_image.png' });
await browser.close();
})();Dalam kode di atas:
- Diperlukan
page.$('input(id="search")')untuk menemukan item bilah pencarian. - Tekan tombol "Enter".
page.keyboard.press('Enter'). - Menunggu elemen ada di kelas
ytd-video-rendereryang menandakan hasil pencarian telah dimuat. - Akhirnya saya mengambil tangkapan layar.
Gambar keluarannya adalah:
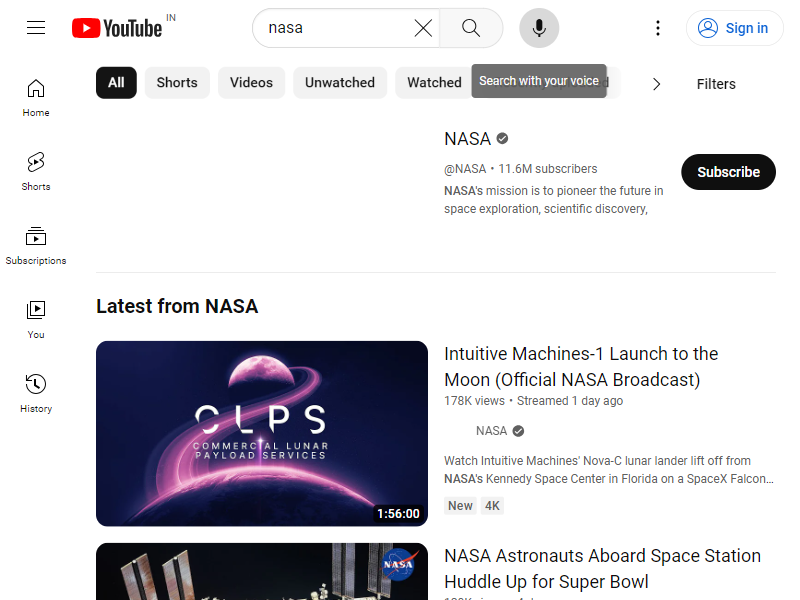
Untuk mensimulasikan interaksi pengguna, kami mengklik tab Shorts menggunakan Puppeteer. mouse.click(x, y) Metode yang memungkinkan mengklik koordinat layar tertentu.
const puppeteer = require("puppeteer");
(async () => {
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
await page.goto("<https://youtube.com/>");
// Wait for the search input element with ID "search"
await page.waitForSelector('input(id="search")');
// Type "nasa channel" into the search input
await page.type('input(id="search")', "nasa channel");
// Press Enter to submit the search
await page.keyboard.press("Enter");
// Wait for the channel title element with ID "channel-title"
await page.waitForSelector('#channel-title');
// Click the mouse at coordinates (200, 80)
await page.mouse.click(200, 80);
// Wait for a video renderer element
await page.waitForSelector('ytd-video-renderer');
// Take a screenshot
await page.screenshot({ path: "shorts.png" });
// Close the browser
await browser.close();
})();Tab “Celana Pendek” berhasil diklik.
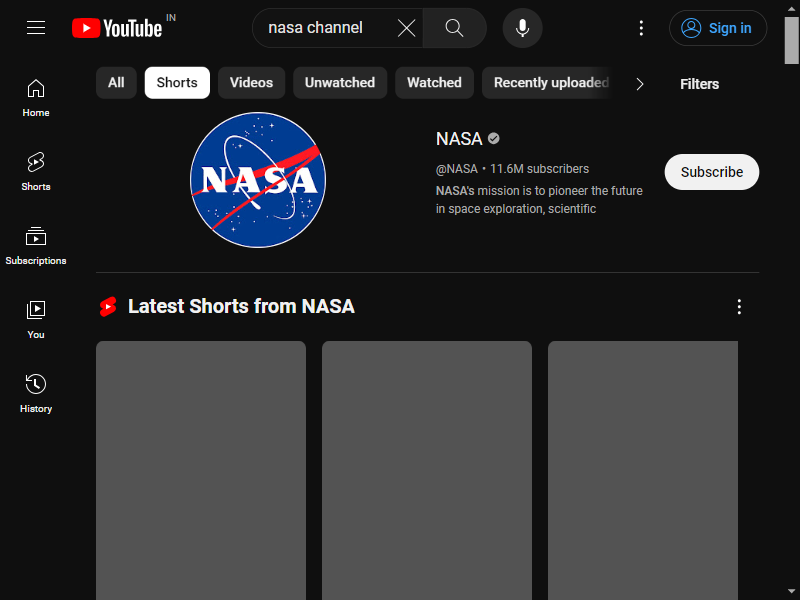
Dalang menawarkan berbagai metode interaksi tikus, seperti: mouse.drop(), mouse.reset(), mouse.drag()Dan mouse.move(). Pelajari lebih lanjut tentang metode ini di sini.
Header permintaan sangat penting untuk cara server memproses dan merespons permintaan Anda. Di Puppeteer, cara paling umum untuk menyetel header khusus untuk semua permintaan adalah setExtraHTTPHeaders() Metode.
Pertama, atur header yang ingin Anda gunakan.
const requestHeaders = {
'referer': 'www.google.com',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'en-US,en;q=0.9',
'cache-control': 'max-age=0',
'accept-encoding': 'gzip, deflate, br',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
};Header ini berisi informasi tentang browser, format konten pilihan, pengaturan bahasa, dan yang terpenting agen pengguna. Informasi ini membantu server memberikan respon yang paling tepat kepada pengguna. Secara default, Dalang menyiarkan HeadlessChrome sebagai agen pengguna.
Berikut kode lengkapnya:
import puppeteer from 'puppeteer';
const requestHeaders = {
'referer': 'www.google.com',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'en-US,en;q=0.9',
'cache-control': 'max-age=0',
'accept-encoding': 'gzip, deflate, br',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
};
(async () => {
const browser = await puppeteer.launch({
headless: true,
});
const page = await browser.newPage();
// Set extra HTTP headers
await page.setExtraHTTPHeaders({ ...requestHeaders });
await page.goto('<https://httpbin.io/headers>');
const content = await page.evaluate(() => document.body.textContent);
console.log(content);
await browser.close()
})();Output dari Puppeteer mengonfirmasi bahwa header permintaan berhasil diubah. Log konsol menunjukkan bahwa header “Agen-Pengguna” telah diperbarui dan parameter relevan lainnya juga diperbarui.
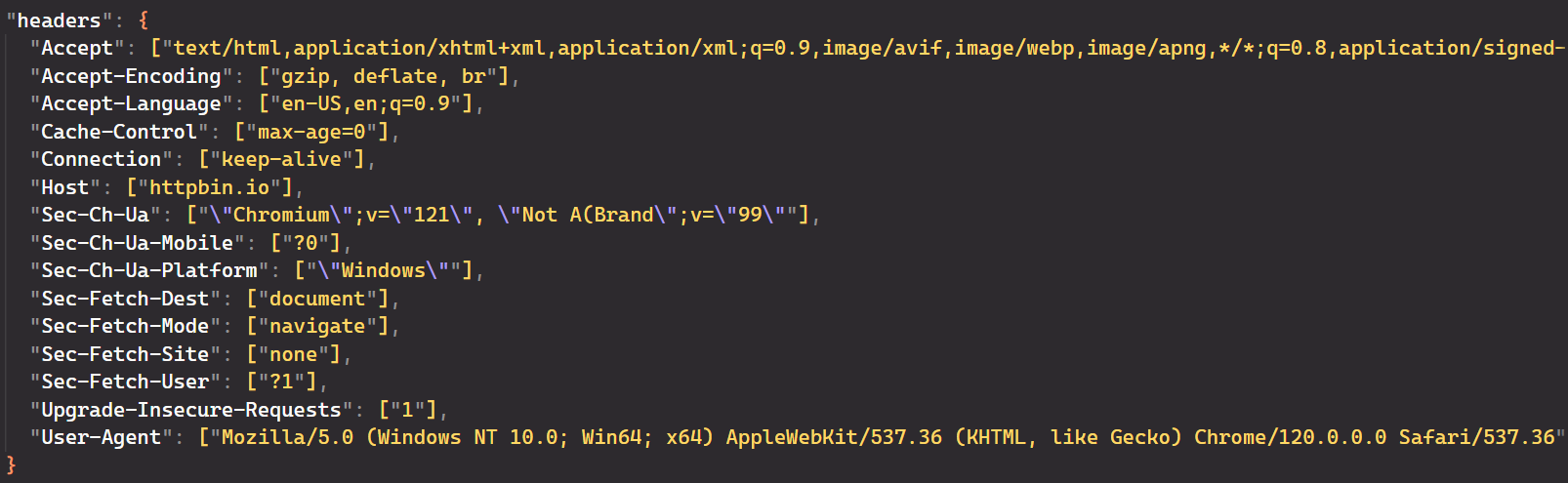
Menggunakan proxy untuk mengikis anonimitas
Mengikis data dari situs web terkadang merupakan tantangan. Situs web mungkin membatasi akses berdasarkan lokasi Anda atau memblokir alamat IP Anda. Di sinilah proxy berperan. Proxy membantu melewati batasan ini dengan menyembunyikan alamat IP dan lokasi asli Anda.
Pertama, dapatkan proxy Anda dari daftar proxy gratis. Kemudian konfigurasikan Puppeteer untuk memulai Chrome --proxy-server Kemungkinan:
import puppeteer from "puppeteer";
async function scrapeIp() {
const proxyServerUrl="<http://20.210.113.32:80>";
const browser = await puppeteer.launch({
args: (`--proxy-server=${proxyServerUrl}`)
});
const page = await browser.newPage();
await page.goto('<https://httpbin.org/ip>');
const bodyElement = await page.waitForSelector('body');
const ipText = await bodyElement.getProperty('textContent');
const ipAddress = await ipText.jsonValue();
console.log(ipAddress);
await browser.close();
}
scrapeIp();Outputnya adalah:
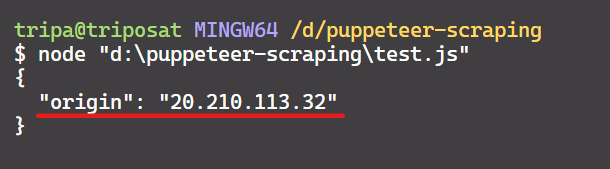
Kita berhasil! Alamat IP cocok dengan yang ada di situs web dan mengonfirmasi bahwa Dalang menggunakan proxy yang ditentukan.
Waspadai banned oleh implementasi kode di atas. Mengirimkan semua permintaan berulang kali melalui proxy yang sama dapat mengingatkan situs web dan memicu larangan.
Untungnya, opsi lain membantu kami mengelola proxy. Beberapa dari mereka adalah:
- Proksi berputar: Terlalu banyak permintaan cepat dapat menandai skrip Anda sebagai ancaman dan mengakibatkan IP Anda diblokir. Proksi yang berputar mencegah hal ini dengan menggunakan kumpulan IP dan secara otomatis beralih setelah setiap permintaan.
- proxy-halaman-dalang: Pustaka ini memperluas Puppeteer dan memungkinkan Anda mengatur proxy per halaman atau bahkan per permintaan, memberikan kontrol terperinci.
- dalang-ekstra-plugin-proxy: Plugin Puppeteer-extra ini menyediakan dukungan proxy yang dirancang khusus untuk menghindari batasan kecepatan dalam web scraping sekaligus memberikan anonimitas dan fleksibilitas untuk tugas otomatisasi.
Catatan: Proxy gratis tidak disarankan karena tidak dapat diandalkan. Secara khusus, umurnya yang pendek membuat mereka tidak cocok untuk skenario dunia nyata.
Penanganan kesalahan
Banyak kesalahan yang dapat terjadi saat menggores situs web. Ada berbagai strategi untuk mengatasi tantangan ini. Pendekatan yang umum adalah dengan menggunakan try/catch Blok untuk menangani kesalahan dengan elegan Navigasi halaman gagal. Ini akan mencegah kode Anda mogok dan memungkinkan Anda melanjutkan eksekusi.
Selain itu, Anda juga bisa menggunakan dalang waitForSelector Metode memperkenalkan penundaan. Hal ini memastikan bahwa elemen tertentu dimuat sebelum berinteraksi dengannya.
Berikut kode lengkap dengan penanganan errornya:
import puppeteer from "puppeteer";
import { exit } from "process";
async function scrapeData(numRepos) {
try {
// Launch headless browser with default viewport
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
// Navigate to Node.js topic page
await page.goto("<https://github.com/topics/nodejs>");
// Use a Set to store unique entries efficiently
let uniqueRepos = new Set();
// Flag to track if there are more repos to load
let hasMoreRepos = true;
while (hasMoreRepos && uniqueRepos.size < numRepos) {
try {
// Extract data from repositories
const extractedData = await page.evaluate(() => {
const repos = document.querySelectorAll("article.border");
const repoData = ();
repos.forEach((repo) => {
const userLink = repo.querySelector("h3 > a:first-child");
const repoLink = repo.querySelector("h3 > a:last-child");
const user = userLink.textContent.trim();
const repoName = repoLink.textContent.trim();
const repoStar = repo.querySelector("#repo-stars-counter-star").title;
const repoDescription = repo.querySelector("div.px-3 > p")?.textContent.trim() || "";
const tags = Array.from(repo.querySelectorAll("a.topic-tag")).map((tag) => tag.textContent.trim());
const repoUrl = repoLink.href;
repoData.push({ user, repoName, repoStar, repoDescription, tags, repoUrl });
});
return repoData;
});
extractedData.forEach((entry) => uniqueRepos.add(JSON.stringify(entry)));
// Check if enough repos have been scraped
if (uniqueRepos.size >= numRepos) {
uniqueRepos = Array.from(uniqueRepos).slice(0, numRepos);
hasMoreRepos = false;
break;
}
// Click "Load more" button if available
const buttonSelector = "text/Load more";
const button = await page.waitForSelector(buttonSelector, { timeout: 5000 });
if (button) {
await button.click();
} else {
console.log("No more repos found. All data scraped.");
hasMoreRepos = false;
}
} catch (error) {
console.error("Error while extracting data:", error);
exit(1);
}
}
// Convert unique entries to an array and format JSON content
const uniqueList = Array.from(uniqueRepos).map((entry) => JSON.parse(entry));
console.dir(uniqueList, { depth: null });
await browser.close();
} catch (error) {
console.error("Error during scraping process:", error);
exit(1);
}
}
scrapeData(50);Simpan data yang tergores ke file
Mengesankan! Kami telah berhasil menghapus data. Mari simpan ke file JSON alih-alih mencetaknya ke konsol. JSON adalah format terstruktur yang memungkinkan Anda menyimpan dan mengatur data kompleks dengan jelas dan konsisten.
Kami mengimpornya fs Modul dan penggunaan fs.writeFile() untuk menulis data ke file. Namun sebelum kita melakukan ini, mari kita konversi objek JavaScript uniqueList menjadi string JSON JSON.stringify().
const uniqueList = Array.from(uniqueRepos).map((entry) => JSON.parse(entry));
const jsonContent = JSON.stringify(uniqueList, null, 2);
await fs.writeFile("github_repos.json", jsonContent);Berikut kode lengkapnya:
import puppeteer from "puppeteer";
import fs from "fs";
import { exit } from "process";
async function scrapeData(numRepos) {
try {
// Launch headless browser with default viewport
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
// Navigate to Node.js topic page
await page.goto("<https://github.com/topics/nodejs>");
// Use a Set to store unique entries efficiently
let uniqueRepos = new Set();
// Flag to track if there are more repos to load
let hasMoreRepos = true;
while (hasMoreRepos && uniqueRepos.size < numRepos) {
try {
// Extract data from repositories
const extractedData = await page.evaluate(() => {
const repos = document.querySelectorAll("article.border");
const repoData = ();
repos.forEach((repo) => {
const userLink = repo.querySelector("h3 > a:first-child");
const repoLink = repo.querySelector("h3 > a:last-child");
const user = userLink.textContent.trim();
const repoName = repoLink.textContent.trim();
const repoStar = repo.querySelector("#repo-stars-counter-star").title;
const repoDescription = repo.querySelector("div.px-3 > p")?.textContent.trim() || "";
const tags = Array.from(repo.querySelectorAll("a.topic-tag")).map((tag) => tag.textContent.trim());
const repoUrl = repoLink.href;
repoData.push({ user, repoName, repoStar, repoDescription, tags, repoUrl });
});
return repoData;
});
extractedData.forEach((entry) => uniqueRepos.add(JSON.stringify(entry)));
// Check if enough repos have been scraped
if (uniqueRepos.size >= numRepos) {
uniqueRepos = Array.from(uniqueRepos).slice(0, numRepos);
hasMoreRepos = false;
break;
}
// Click "Load more" button if available
const buttonSelector = "text/Load more";
const button = await page.waitForSelector(buttonSelector, { timeout: 5000 });
if (button) {
await button.click();
} else {
console.log("No more repos found. All data scraped.");
hasMoreRepos = false;
}
} catch (error) {
console.error("Error while extracting data:", error);
exit(1);
}
}
// Convert unique entries to an array and format JSON content
const uniqueList = Array.from(uniqueRepos).map((entry) => JSON.parse(entry));
const jsonContent = JSON.stringify(uniqueList, null, 2);
await fs.writeFile("github_repos.json", jsonContent);
console.log(`${uniqueList.length} unique repositories scraped and saved to 'github_repos.json'.`);
await browser.close();
} catch (error) {
console.error("Error during scraping process:", error);
exit(1);
}
}
scrapeData(50);berkas JSON:
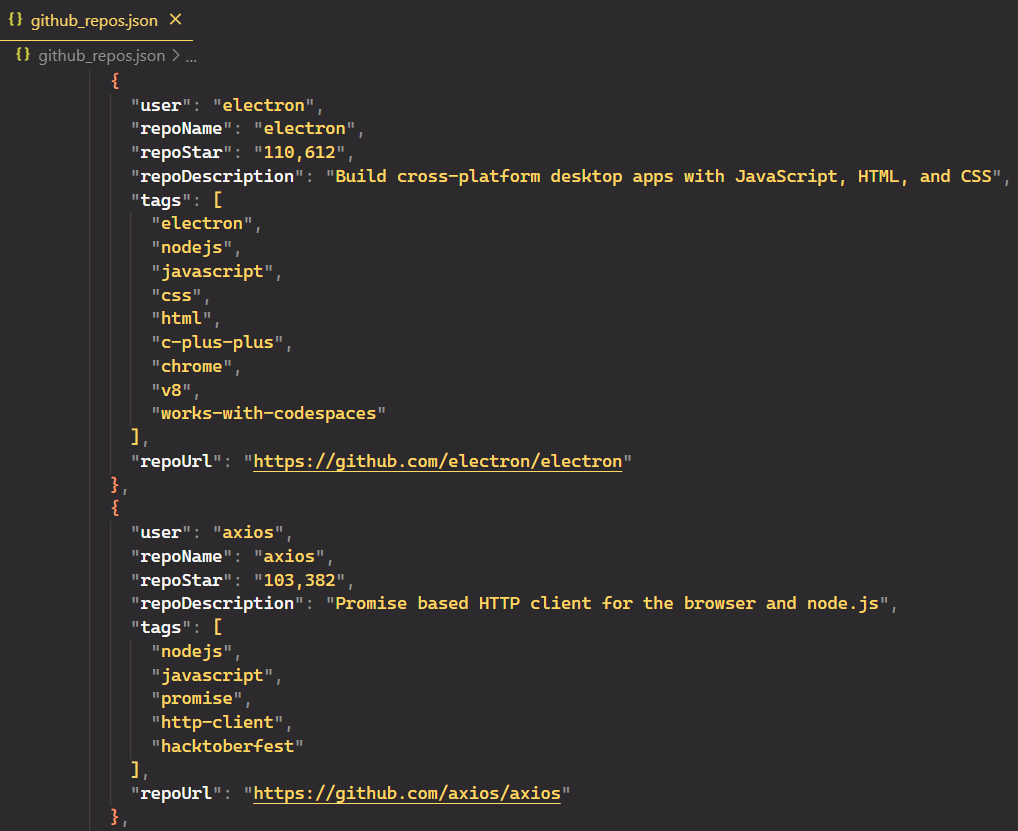
Alternatif untuk dalang
Dalang populer karena komunikasi browser langsungnya melalui protokol DevTools dan kemudahan penggunaannya. Namun, terdapat keterbatasan, termasuk terbatasnya dukungan browser dan ketergantungan pada satu bahasa. Keterbatasan ini mungkin mengarahkan pengembang untuk mencari opsi lain.
Berikut adalah beberapa alternatif paling populer untuk Dalang:
Selenium: Ini adalah alat otomatisasi browser populer yang bekerja dengan banyak browser (Chrome, Firefox, Safari, dll.) dan memungkinkan Anda menggunakan berbagai bahasa pemrograman (Python, Java, JavaScript, dll.). Namun, dibandingkan dengan Puppeteer, Selenium bisa lebih lambat dan mengonsumsi lebih banyak sumber daya, terutama untuk tugas scraping yang besar.
Dramawan: Pustaka sumber terbuka ini menyediakan dukungan browser yang lebih luas seperti browser Chrome, Firefox, Edge, dan WebKit. Keuntungan utamanya adalah dukungan lintas-browser, yang memungkinkan Anda menguji aplikasi web di beberapa browser secara bersamaan. Ini juga mendukung berbagai bahasa pemrograman, sehingga fleksibel untuk pengembang yang berbeda.
Mengikis-it.Cloud NodeJS SDK: Berbeda dengan alat sebelumnya, Scrape-It.Cloud adalah layanan web scraping berbasis cloud yang menghilangkan kebutuhan untuk mengelola infrastruktur Anda sendiri. Ini menangani kompleksitas otomatisasi browser dan menangani hal-hal seperti mengelola proxy, menangani tindakan anti-bot, dan merender JavaScript. Hal ini memungkinkan Anda fokus menulis kode untuk mengekstrak data yang Anda perlukan tanpa mengkhawatirkan infrastruktur yang mendasarinya.
Memilih alat pengikis yang tepat bergantung pada proyek Anda. Dalang memang hebat, tetapi opsi lain mungkin lebih cocok untuk Anda. Cobalah untuk melihat mana yang berhasil.
Diploma
Dalang menawarkan perangkat yang kuat dan serbaguna untuk tugas pengikisan web. Dengan memanfaatkan fitur-fiturnya, Anda dapat mengekstrak data berharga dari situs web secara efisien, mengotomatiskan interaksi browser yang berulang, dan menyederhanakan berbagai alur kerja.
Dalam panduan ini, kami fokus pada halaman topik GitHub, tempat Anda dapat memilih topik (misalnya NodeJS) dan menentukan jumlah repositori yang akan dikikis. Kami membahas cara menangani kesalahan pengikisan, menghindari deteksi, dan mendiskusikan manfaat API pengikisan web untuk ekstraksi data yang lebih mudah dan efisien.
Saat Anda memperoleh pengalaman, jelajahi teknik-teknik canggih seperti rotasi proxy dan plugin browser untuk meningkatkan keterampilan scraping Anda dan menavigasi struktur situs web yang kompleks. Dengan dedikasi dan eksplorasi, Dalang dapat membantu Anda mendapatkan wawasan berharga dari internet yang luas.