
Penetapan harga adalah inti dari setiap perusahaan, merek, dan produk. Strategi penetapan harga yang baik dapat membawa Anda ke puncak pasar, sementara model yang buruk dapat menjadi kejatuhan Anda. Jadi, jika Anda ingin meningkatkan peluang kesuksesan, pengurangan harga mungkin merupakan alat yang paling penting dalam gudang senjata Anda.
Dengan mengumpulkan data harga, Anda mendapatkan wawasan tentang dinamika pasar dan dapat membuat keputusan berdasarkan data untuk meningkatkan daya saing. semuanya dari data yang tersedia untuk umum di Internet.
Dengan menggunakan pengikisan harga, Anda dapat:
- Ketahui strategi penetapan harga Anda agar tetap kompetitif
- Secara otomatis menyesuaikan harga berdasarkan kondisi pasar, fluktuasi permintaan dan harga pesaing (penetapan harga dinamis).
- Identifikasi tren pasar dan beradaptasi dengan perubahan mendadak
- Identifikasi peluang penetapan harga
- Awasi pesaing Anda
Dan banyak lagi. Untuk membantu Anda memulai, kami akan memperkenalkan Anda pada beberapa alat terbaik yang dapat Anda gunakan untuk mengumpulkan informasi harga dalam skala besar, serta dua cara efektif untuk melakukannya sendiri.
Daftar Isi
3 alat pengikis harga terbaik
Ada banyak alat dan layanan yang tersedia untuk memantau data harga. Jadi, alih-alih memberi Anda ratusan solusi berbeda yang sebagian besar melakukan hal yang sama, kami telah mencantumkan tiga solusi. Jika Anda tidak yakin jalan mana yang harus diambil, pikirkan anggaran, kebutuhan data, dan keahlian Anda (milik Anda atau tim Anda) dan Anda akan segera menemukan solusi terbaik untuk Anda.
sumber: Bagaimana memilih alat pengumpulan data
1. ular piton
Python adalah bahasa pemrograman yang canggih, serbaguna, dan mudah dibaca. Ia dikenal karena kesederhanaannya dan perpustakaannya yang luas.
Karena bersifat open-source, Python bebas digunakan untuk semua jenis aplikasi (bisnis atau pribadi) dan telah membuka pintu ke komunitas luas yang selalu siap membantu.
Berkat perpustakaan seperti Permintaan, Sup Cantik, dan Panda, membaca informasi harga yang tersedia untuk umum dan memanipulasi informasi ini adalah proses yang sangat sederhana dengan pengetahuan yang cukup. Namun, yang membedakan Python dari bahasa lain (setidaknya untuk tugas ini) adalah ia telah menjadi standar dalam industri data. Tidak ada kekurangan konten pendidikan gratis, perpustakaan, dan alat untuk mengumpulkan dan menganalisis data dalam skala besar.
sumber: Panduan pengikisan web menggunakan Python dan Beautiful Soup
alternatif
Jika Anda tidak tertarik dengan Python, JavaScript (di lingkungan Node.js) adalah bahasa pemrograman hebat lainnya untuk membangun pengumpul data.
Berkat alat seperti Axios dan Cheerio, Anda dapat membuat web scraper canggih untuk situs web yang memerlukan interaksi pengguna (misalnya aplikasi satu halaman).
sumber: Cara melakukan web scrape dengan JavaScript dan Node.js
2. Saluran data
DataPipeline adalah solusi kode rendah ScraperAPI untuk membangun pengumpul data dan menjadwalkan pekerjaan scraping dengan antarmuka visual.
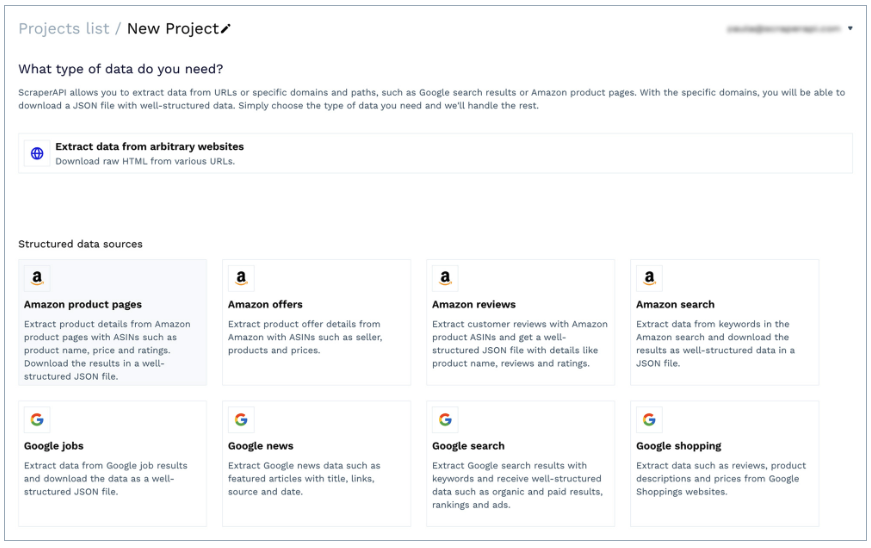
Berkat antarmukanya yang sederhana, ini dapat digunakan oleh profesional non-teknis untuk mengumpulkan data dari URL mana pun tanpa menulis satu baris kode pun. Selain itu, ia menawarkan templat khusus untuk domain seperti Amazon (halaman produk, pencarian, penawaran, dll.) dan Google Shopping. Ini memungkinkan Anda mengambil informasi produk – termasuk harga – sebagai data JSON terstruktur.
Yang terbaik dari semuanya, ia memiliki penjadwal bawaan. Ini memungkinkan Anda mengatur interval tertentu untuk membuang pekerjaan dan memantau produk dan URL secara teratur hanya dengan beberapa klik.
alternatif
Jika Anda memiliki pengalaman pemrograman, Anda dapat menggunakan titik akhir data terstruktur ScraperAPI untuk mengonversi halaman produk ke JSON. Saat mengirimkan permintaan get() melalui salah satu titik akhir ini, ScraperAPI melewati semua mekanisme anti-scraping, mengambil semua elemen yang relevan dari halaman produk atau hasil pencarian, dan mengembalikan semuanya dalam pasangan kunci terstruktur (JSON).
Anda masih memiliki fleksibilitas untuk membangun solusi lengkap dari awal, namun dengan format data yang lebih mudah dimanipulasi.
3. Ketenangan pikiran
Mindrest adalah perangkat lunak pemantauan harga dan pengoptimalan harga yang lengkap. Ini dirancang untuk langsung bekerja tanpa Anda harus berkontribusi banyak.
Tentu saja, trade-off dengan menggunakan perangkat lunak jenis ini adalah penyesuaian dan harga.
Karena perangkat lunak pemantauan harga harus melayani sebanyak mungkin bisnis agar dapat memperoleh keuntungan, ini juga berarti bahwa perangkat lunak tersebut dirancang untuk mencakup sebanyak mungkin kasus penggunaan, dan mengubah bagian perangkat lunak agar sesuai dengan alur kerja Anda bisa jadi lebih menantang.
Namun, ini bisa menjadi pilihan sempurna bagi perusahaan (yang memiliki anggaran untuk membayar layanan tersebut) yang tidak ingin mengembangkan solusi sendiri atau tidak memiliki cukup staf untuk menangani proyek (misalnya analis data, untuk memproses data yang dikumpulkan). data). Data).
alternatif
Solusi serupa namun lebih murah adalah Prisync. Perangkat lunak ini dapat memantau berbagai platform (seperti toko Shopify) dan menerapkan penetapan harga dinamis berdasarkan data yang ditemukan, menjadikannya solusi yang dirancang khusus untuk bisnis skala menengah.
Kumpulkan data harga dengan DataPipeline (metode kode rendah)
Pertama, mari kita jelajahi metode kode rendah, yang cukup sederhana.
Untuk memulai, buat akun ScraperAPI gratis, navigasikan ke dasbor Anda dan klik “Buat proyek DataPipeline baru”.
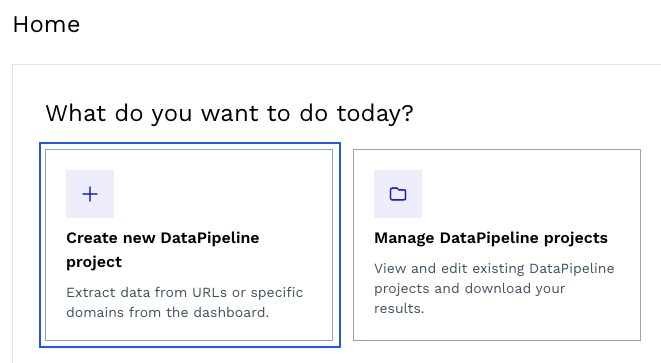
Kita dapat memilih salah satu template yang sudah jadi atau membuat proyek untuk mengumpulkan data dari URL mana pun. Untuk proyek ini, kami menggunakan template Amazon Product Pages.
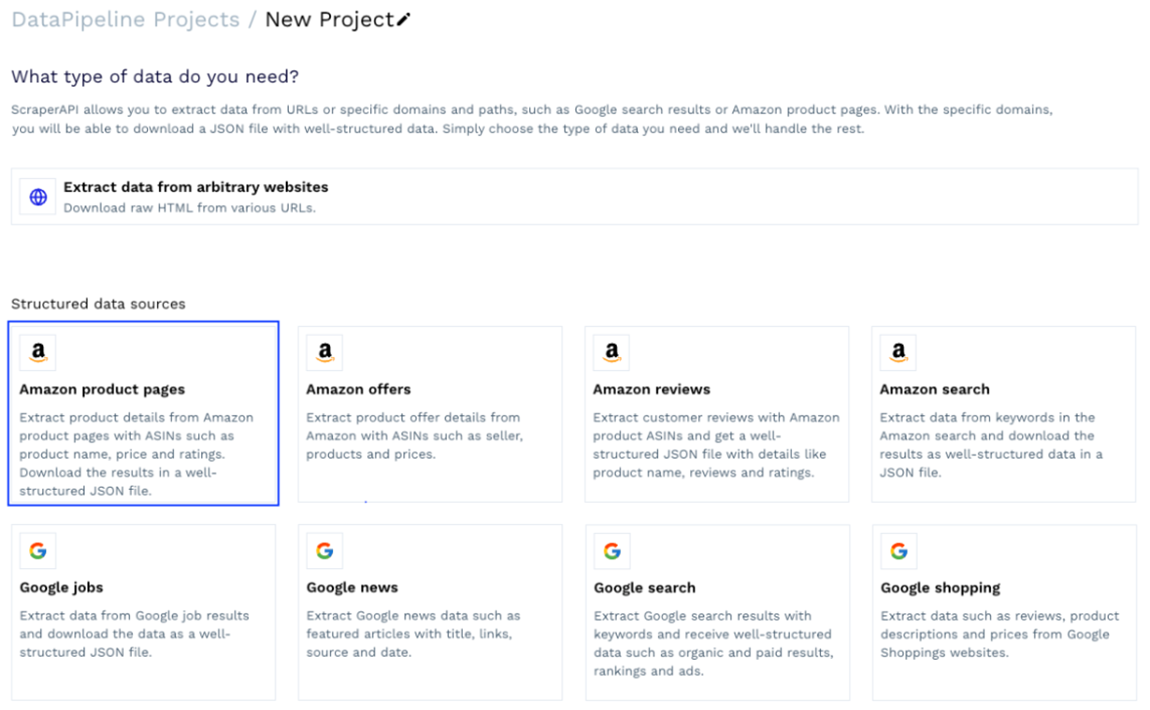
Templat ini akan menanyakan beberapa detail tentang pekerjaan pengikisan, tetapi elemen yang paling penting adalah produk ASIN - nomor unik yang diberikan Amazon untuk setiap produk yang terdaftar di platform dan biasanya dapat Anda temukan dengan mudah di URL produk /db /.
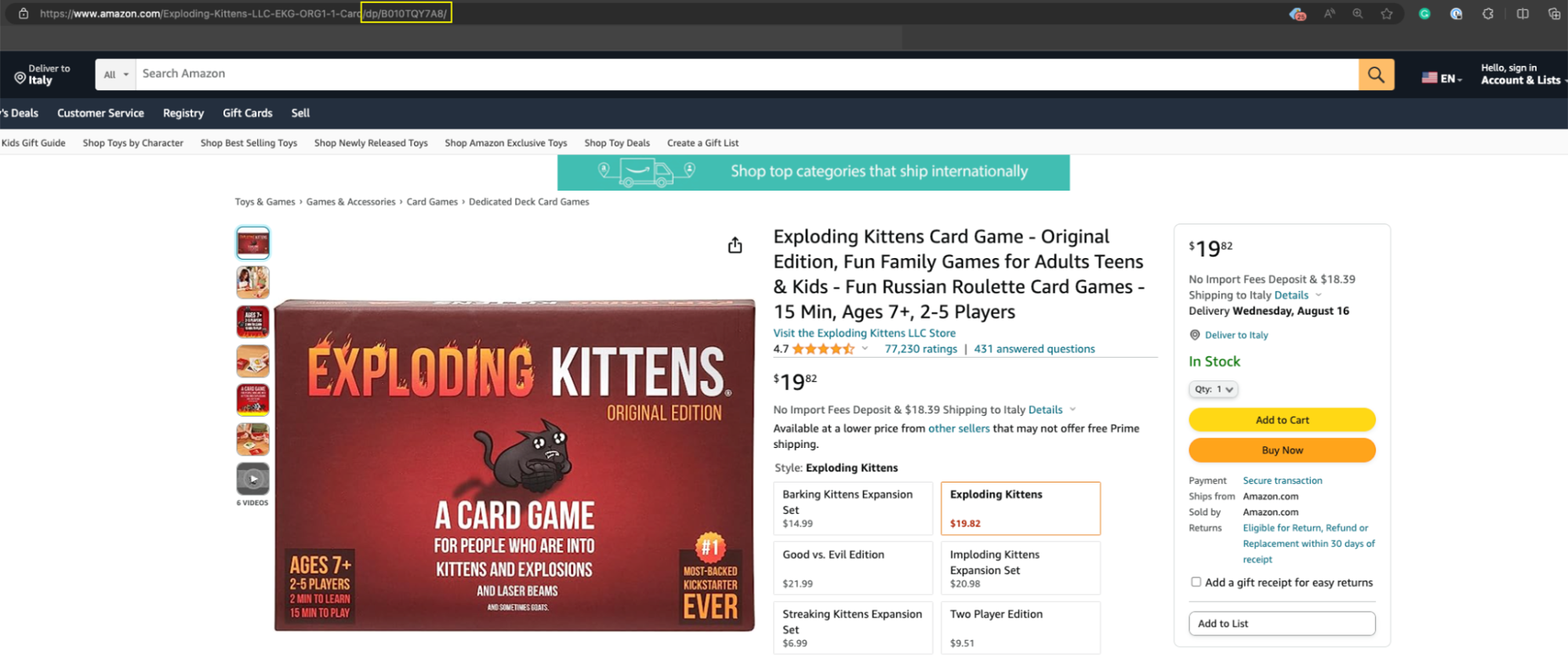
Salin dan tempel produk ASIN ke dalam bidang teks alat.
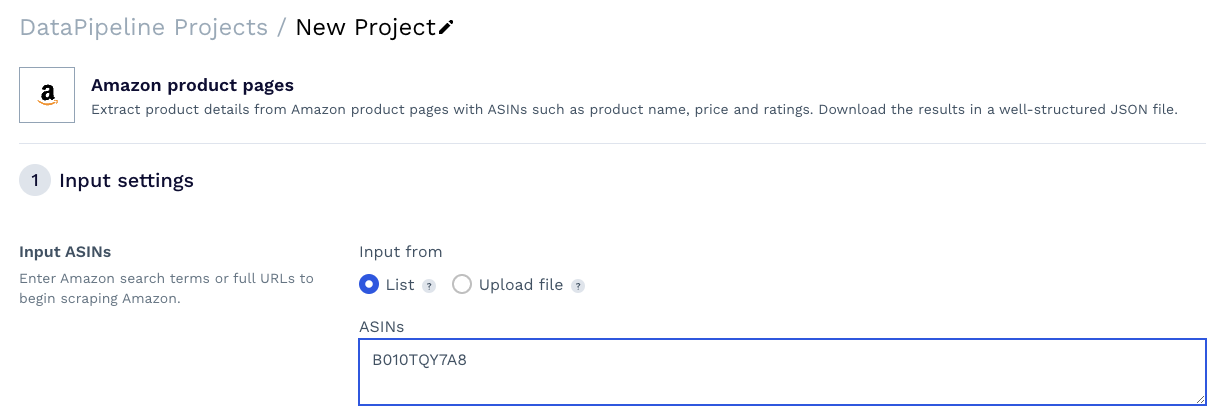
sumber: Kumpulkan ASIN produk dalam skala besar
Selanjutnya, klik menu drop-down dan cari USA. Anda dapat membiarkan TLD kosong.

Kode negara menentukan lokasi DataPipeline harus mengirimkan permintaan. TLD memberi tahu domain Amazon mana yang akan dikiriminya. Jika tidak ada TLD yang ditentukan, seperti dalam kasus kami, TLD AS digunakan secara default, yaitu amazon.com.
catatan: Ini berguna saat mengumpulkan data yang dilokalkan.
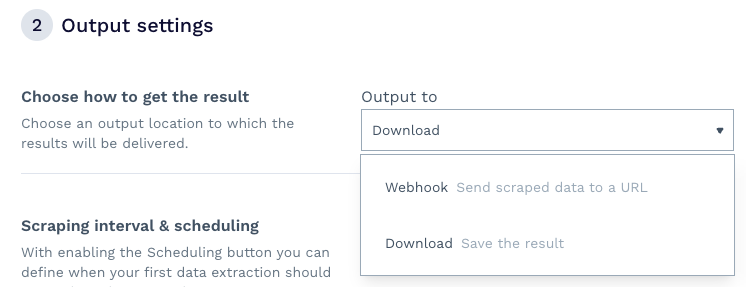
Langkah kedua dari penyiapan adalah tempat keajaiban terjadi. Pertama, Anda dapat memutuskan bagaimana Anda ingin menerima data - kami memilih untuk mengunduh file, namun Anda juga dapat menyiapkan webhook untuk menerima informasi langsung ke dalam aplikasi, gudang data, dll.
Kedua, dengan mengaktifkan penjadwalan, Anda dapat mengatur hari, waktu, dan interval di mana pekerjaan scraping akan dijalankan kembali secara otomatis, sehingga secara efektif memantau halaman produk pesaing Anda.
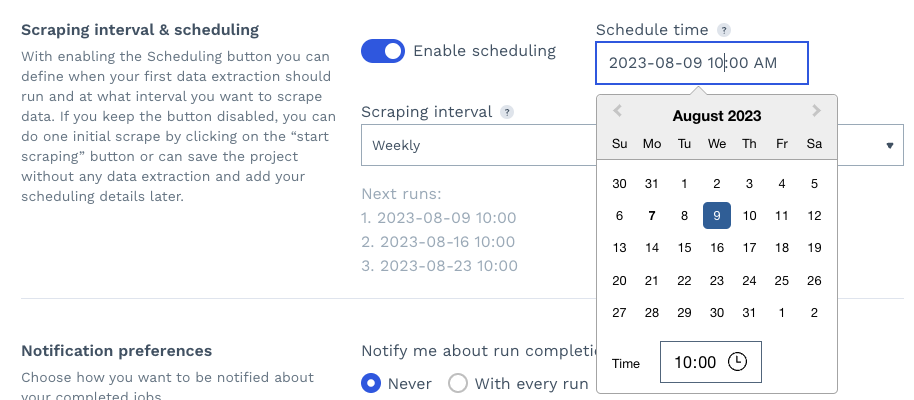
Terakhir, Anda dapat mengatur preferensi notifikasi dan mengklik “Mulai Scraping” untuk menjalankan proyek Anda.

Setelah pekerjaan selesai, Anda dapat kembali ke proyek dan mengunduh file dengan data yang siap untuk diurai.
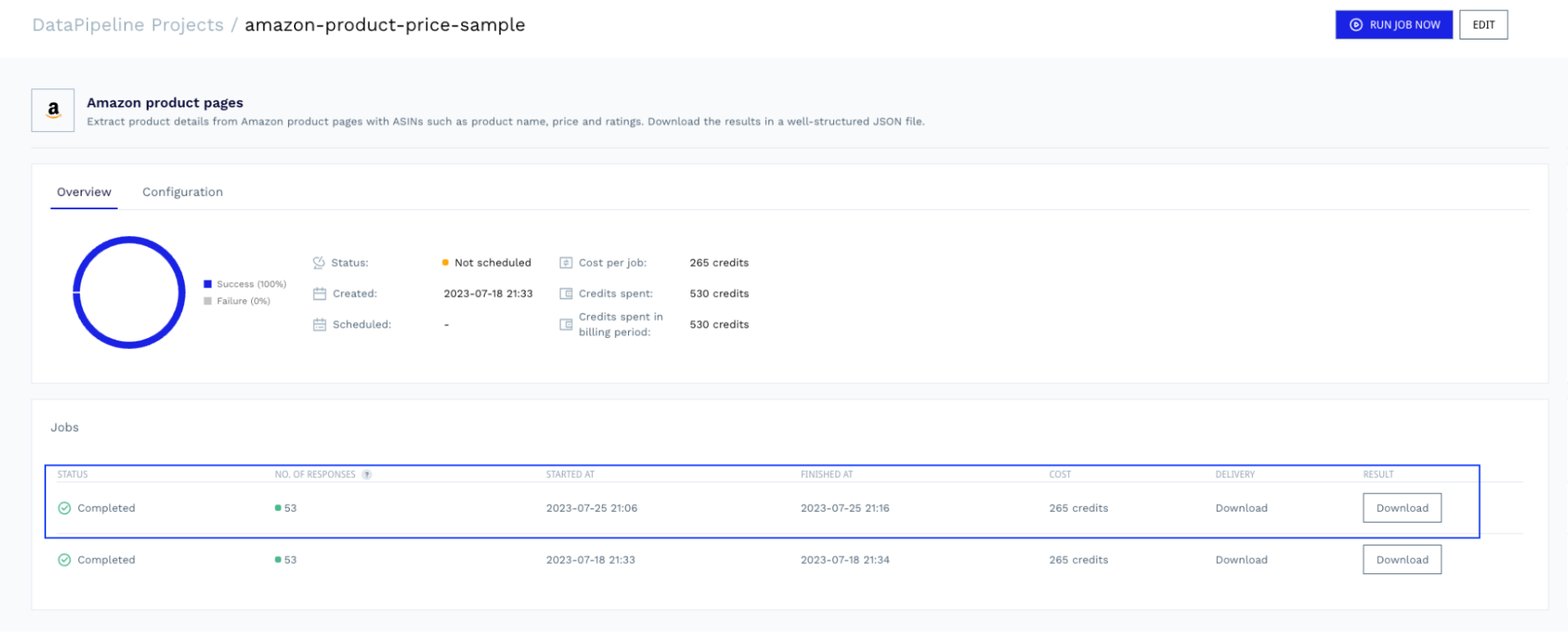
Lihat respons sampel produk Amazon lengkap yang dikembalikan DataPipeline.
Mengikis data harga dengan Python (metode teknis)
Untuk kenyamanan, kami mengumpulkan data harga dari books.toscrape.com. Lebih spesifiknya, kami mencatat nama, harga, UPC, dan ketersediaan buku pertama yang tercantum di halaman tersebut.
Menyiapkan proyek Anda
Mari buat direktori baru untuk proyek kita, buat file Python dan impor dependensi kita di atas.
import requests
from bs4 import BeautifulSoup
import pandas as pd
Selanjutnya, buat akun ScraperAPI gratis jika Anda belum melakukannya, salin kunci API Anda dari dasbor dan tambahkan variabel payload berikut ke file Anda.
payload = {
'api_key': 'YOUR_API_KEY',
'url': 'https://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html',
'country_code': 'us'
}
Dalam proyek nyata - terutama situs web yang kompleks - situs web akan dengan cepat mendeteksi skrip Anda dan memblokirnya agar tidak mengakses web, yang juga dapat mengakibatkan IP Anda masuk daftar hitam tanpa batas waktu.
Untuk menghindari risiko dan aspek web scraping yang paling menuntut secara teknis (seperti proxy yang berputar, menangani CAPTCHA dan penargetan geografis), kami menggunakan titik akhir ScraperAPI standar.
Perhatikan juga bahwa kami menambahkan URL yang ingin kami pindai (https://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html) dan lokasi proksi yang harus digunakan ScraperAPI (proksi yang berbasis di AS).
Sekarang kami dapat mengirimkan permintaan kami.
Mengirimkan permintaan Anda
Untuk mengirim permintaan melalui ScraperAPI, kami membuat get() Pertanyaan ke https://api.scraperapi.com Titik akhir, dengan payload sebagai parameternya.
response = requests.get('https://api.scraperapi.com', params=payload)
ScraperAPI menggunakan pembelajaran mesin dan analisis statistik selama bertahun-tahun untuk memilih kombinasi IP dan header yang tepat untuk melewati mekanisme anti-scraping situs web. Setelah mengakses konten, ia mengembalikan kode HTML mentah dan menyimpannya Menjawab.
Namun, untuk memilih item dari Menjawabkita harus menganalisis ini Menjawabdan di sinilah BeautifulSoup berperan.
soup = BeautifulSoup(response.content, 'html.parser')
Ini akan menghasilkan pohon parse yang sekarang dapat kita navigasikan menggunakan pemilih CSS.
Bangun pengurai Anda
Karena kami ingin mengekspor data ini, kami membuat array kosong tempat kami memformat elemen yang diekstraksi.
Sebelum kita menulis kode, kita perlu memahami di mana letak data dalam struktur HTML. Navigasikan ke halaman dan buka DevTools untuk melihat kode HTML halaman.
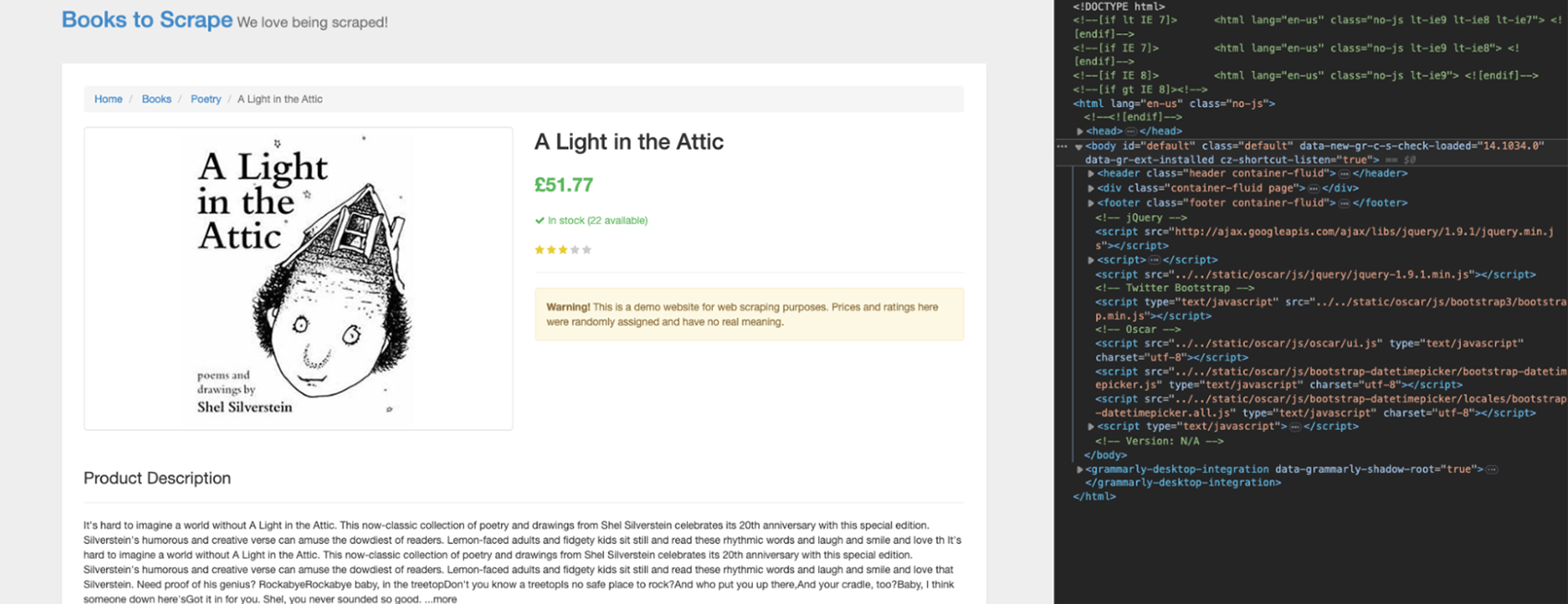
Klik pada nama buku di bagian atas menggunakan alat Inspektur.
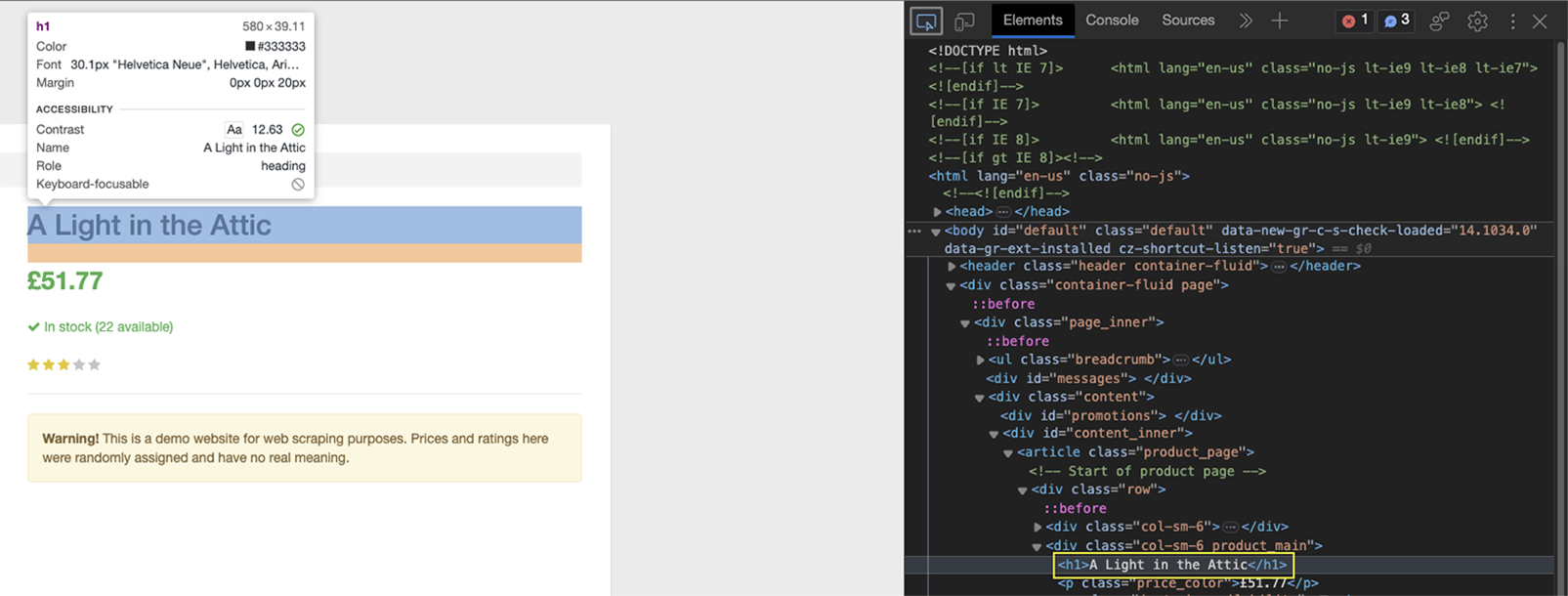
Seperti yang Anda lihat, elemen tersebut dibungkus di antara tag h1 dan merupakan satu-satunya elemen h1 di halaman.
Sebelum mengekstrak nama buku, kita membuat logika untuk menambahkan data ke array kosong (book_data.append()), dan dalam hal ini kami memformat informasinya.
book_data.append({
'Name': soup.find('h1').text,
})
Karena pohon parse disimpan di Supkita bisa menggunakan ini sekarang .find() metode di atasnya untuk membidik h1 item dan kemudian meminta mereka untuk mengembalikannya teks dalam elemen ini.
Lakukan hal yang sama untuk harganya.

Dalam hal ini harganya antara dibungkus p Tag, tetapi ada banyak di situs ini. Jadi apa yang bisa kita lakukan?
Jika dicermati, hal ini menjadi nyata p Hari punya satu price_color Kelas yang dapat kita targetkan dengan pemilih CSS yang tepat:
book_data.append({
'Name': soup.find('h1').text,
'Price': soup.find('p', class_='price_color').text,
})
Namun, dua item berikutnya berada dalam tabel, yang memerlukan strategi berbeda.
Ekstrak data produk dari tabel
Tabel (terkadang) sedikit lebih sulit untuk dicari dibandingkan elemen lainnya karena tabel terdiri dari tag tanpa atribut target tertentu seperti kelas atau ID. Sebagai gantinya, kita bisa menggunakan posisi setiap elemen dalam tabel untuk menargetkan data.

Pada gambar di atas Anda dapat melihat bahwa isi utama tabel ada di tbody Tag - hal ini terjadi pada sebagian besar tabel - dan setiap baris diwakili oleh a tr Label.
Lalu, di dalam tr Tag adalah dua tag yang berisi nama detail (th) dan nilai (td).
Dengan struktur ini kita harus bisa menargetkan UPC, misalnya dengan menemukan semua orang tr Tag pada halaman, pilih yang pertama dalam daftar dan kemudian kembalikan teks masing-masing td.
Mari kita uji ini di konsol browser:
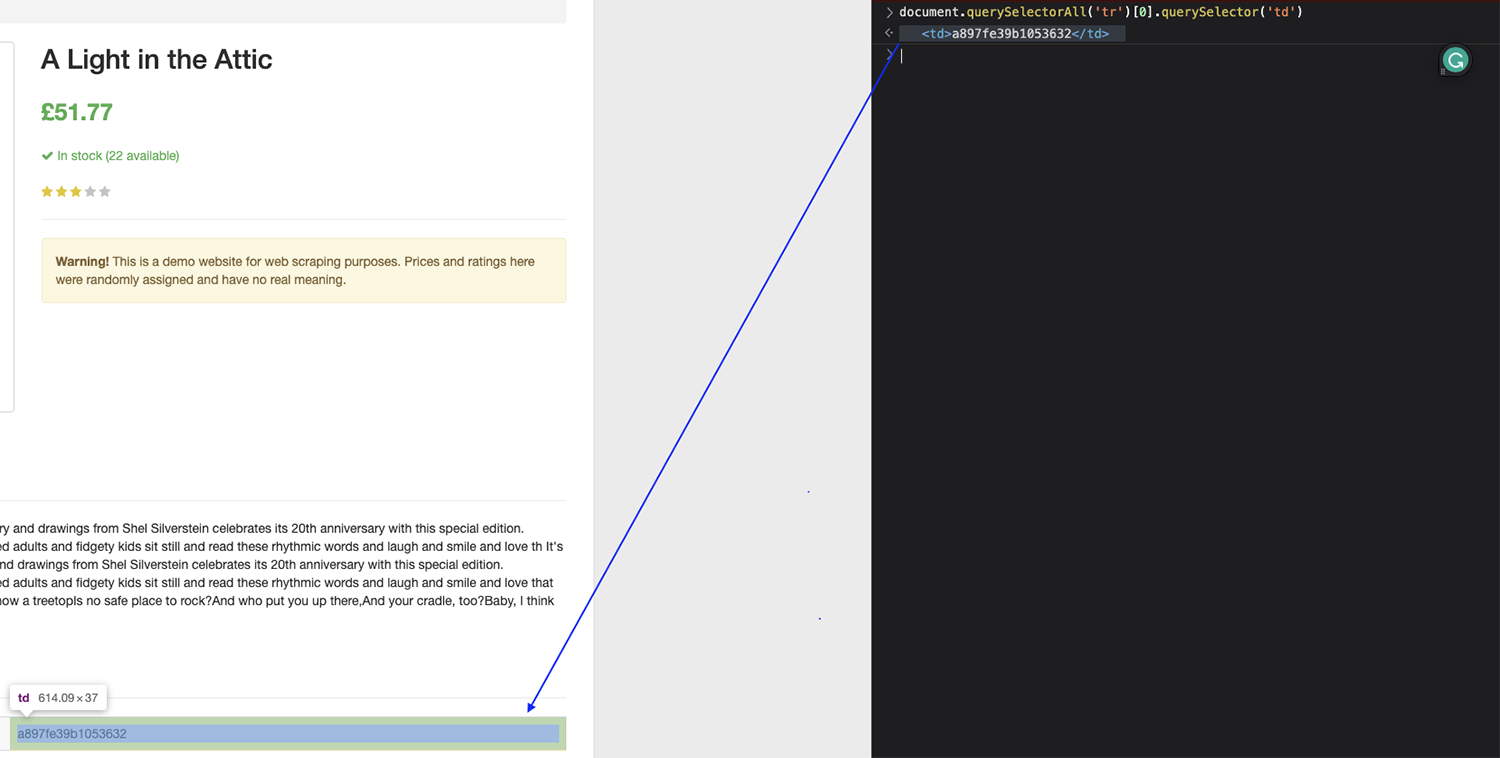
catatan: Ingatlah bahwa indeks mulai menghitung dari nol (0). Jadi jika Anda ingin menangkap elemen pertama, Anda perlu menargetkan elemen nol.
Ini bekerja dengan sempurna!
Sekarang kita dapat menggunakan logika yang sama dalam kode kita untuk mengekstrak UPC.
book_data.append({
'Name': soup.find('h1').text,
'Price': soup.find('p', class_='price_color').text,
'UPC': soup.find_all('tr')(0).find('td').text,
})
Untuk ketersediaan, cukup ubah angkanya menjadi 5 untuk menargetkan baris keenam dalam tabel dan sekarang parser kita sudah selesai.
book_data.append({
'Name': soup.find('h1').text,
'Price': soup.find('p', class_='price_color').text,
'UPC': soup.find_all('tr')(0).find('td').text,
'Availability': soup.find_all('tr')(5).find('td').text,
})
Ekspor data yang diekstraksi ke file CSV
Bagian ini sangat mudah karena Anda sudah melakukan kerja keras. Dengan menambahkan data ke book_data, kami membuat kamus yang dapat kami ekspor menggunakan Pandas seperti ini:
df = pd.DataFrame(book_data)
df.to_csv('product_data.csv', index=False)
Ini menggunakan nama yang ditentukan di atas (Nama, Harga, UPC, dan Ketersediaan) sebagai header dan kemudian menambahkan nilainya.

Ringkasan
Selamat, Anda baru saja membuat pelacak harga pertama Anda!
Tentu saja, Anda dapat menskalakan skrip ini untuk mengumpulkan data dari 1.000 buku di Books to Scrape jika Anda mau, atau membuat daftar Amazon ASIN dan menggunakan DataPipeline untuk mengumpulkan data harga hingga 10.000 produk per proyek.
Setelah mengumpulkan data yang diinginkan, Anda dapat menganalisisnya untuk menarik kesimpulan bermakna yang dapat membantu Anda menetapkan harga produk, memahami pasar secara keseluruhan, dan menemukan peluang penetapan harga yang menarik.
Membuat data harga historis adalah cara terbaik untuk menemukan peluang harga bernilai tinggi (misalnya, waktu ketika pesaing lebih mahal), mengidentifikasi perubahan pasar sehingga Anda dapat beradaptasi dengan cepat, mengidentifikasi penurunan penjualan karena tren harga yang lebih rendah, dan banyak lagi.
Gabungkan data ini dengan detail produk dan ulasan produk untuk mendapatkan hasil maksimal dari upaya Anda.
Berikut adalah dua sumber daya untuk Anda mulai:
Jangan ragu untuk menggunakan skrip hari ini untuk memulai proyek lain atau gunakan DataPipeline untuk menjadwalkan pekerjaan scraping dengan lebih efisien.
Sampai jumpa lagi, selamat menggores!