
Wenn Sie an einem großen Web-Scraping-Projekt arbeiten (z. B. Scraping von Produktinformationen), sind Sie wahrscheinlich auf paginierte Seiten gestoßen. Bei E-Commerce- und Content-Websites ist es gängige Praxis, Inhalte auf mehrere Seiten aufzuteilen, um die Benutzererfahrung zu verbessern. Die Web-Scraping-Paginierung macht unsere Arbeit jedoch etwas komplexer.
In diesem Artikel erfahren Sie, wie Sie in nur wenigen Minuten und ohne Blockierung durch Anti-Scraping-Techniken einen Paginierungs-Web-Scraper erstellen.
Obwohl Sie diesem Tutorial ohne Vorkenntnisse folgen können, ist es möglicherweise eine gute Idee, zunächst unseren Leitfaden zu Scrapy für Anfänger zu lesen, um eine ausführlichere Erklärung des Frameworks zu erhalten, bevor Sie beginnen.
Lassen Sie uns ohne weitere Umschweife direkt loslegen!
Scraping einer Website mit Paginierung mit Python Scrapy
Für dieses Tutorial durchsuchen wir die Kategorie „Herrenhüte von SnowAndRock“, um alle Produktnamen, Preise und Links zu extrahieren.
Ein kleiner Haftungsausschluss: Wir schreiben diesen Artikel mit einem Mac, daher müssen Sie die Dinge ein wenig anpassen, um auf dem PC zu funktionieren. Ansonsten sollte alles beim Alten sein.
TLDR: Hier ist ein kurzer Ausschnitt zum Umgang mit der Paginierung in Scrapy mithilfe der Schaltfläche „Weiter“.:
next_page = response.css('a(rel=next)').attrib('href')
if next_page is not None:
yield response.follow(next_page, callback=self.parse)
Lesen Sie weiter, um eine ausführliche Erklärung zur Implementierung dieses Codes in Ihr Skript und zum Umgang mit Seiten zu erhalten ohne eine Schaltfläche „Weiter“.
1. Richten Sie Ihre Entwicklungsumgebung ein
Bevor wir mit dem Schreiben von Code beginnen, müssen wir unsere Umgebung für die Arbeit mit Scrapy einrichten, einer Python-Bibliothek, die für Web-Scraping entwickelt wurde. Es ermöglicht uns, Daten von Websites zu crawlen und zu extrahieren, die Rohdaten in ein strukturiertes Format zu analysieren und Elemente mithilfe von CSS- und/oder XPath-Selektoren auszuwählen.
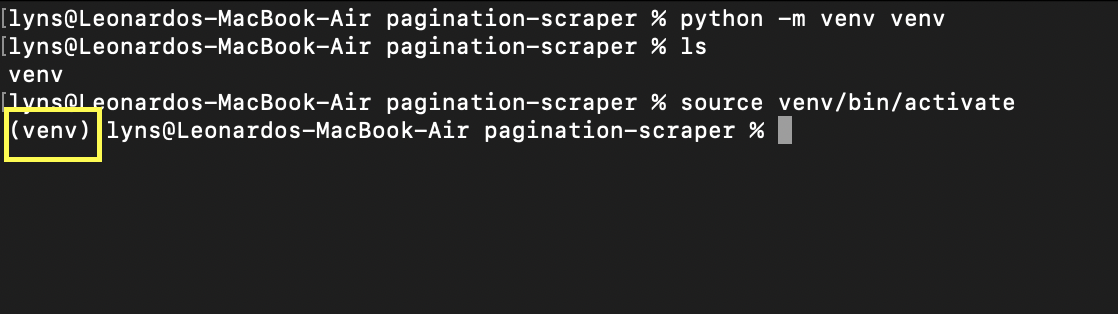
Erstellen wir zunächst ein neues Verzeichnis (wir nennen es Pagination-Scraper) und erstellen darin eine virtuelle Python-Umgebung mit dem Befehl python -m venv venv. Wobei das zweite venv der Name Ihrer Umgebung ist – Sie können es aber so nennen, wie Sie möchten.
Um es zu aktivieren, geben Sie einfach source venv/bin/activate ein. Ihre Eingabeaufforderung sollte so aussehen:
Jetzt ist die Installation von Scrapy so einfach wie die Eingabe von pip3 install scrapy – es kann einige Sekunden dauern, bis es heruntergeladen und installiert ist.
Sobald das fertig ist, geben wir cd venv ein und erstellen ein neues Scrapy-Projekt: scrapy startproject scrapypagination.
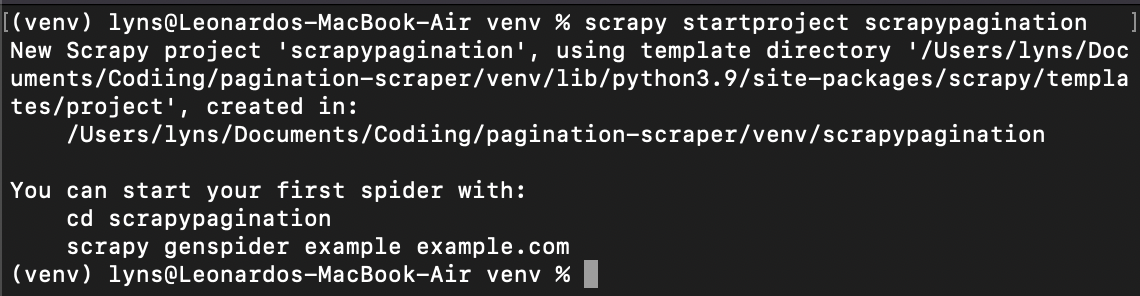
Jetzt können Sie sehen, dass Scrapy unser Projekt für uns in Gang gesetzt hat, indem es alle erforderlichen Dateien installiert hat.
2. ScraperAPI einrichten, um Verbote zu vermeiden
Der schwierigste Teil beim Umgang mit paginierten Seiten besteht nicht darin, das Skript selbst zu schreiben, sondern darin, unseren Bot nicht vom Server blockieren zu lassen.
Dazu müssen wir eine Funktion (oder einen Satz von Funktionen) erstellen, die unsere IP-Adresse nach mehreren Versuchen rotiert (was bedeutet, dass wir auch Zugriff auf einen Pool von IP-Adressen benötigen). Einige Websites verwenden außerdem fortschrittliche Techniken wie CAPTCHAs und Browser-Verhaltensprofilierung.
Um uns Zeit und Kopfschmerzen zu ersparen, verwenden wir ScraperAPI, eine API, die maschinelles Lernen, riesige Browserfarmen, Proxys von Drittanbietern und jahrelange statistische Analysen nutzt, um jeden Anti-Bot-Mechanismus automatisch zu verarbeiten, auf den unser Skript stoßen könnte.
Das Beste ist, dass die Einrichtung von ScraperAPI in unserem Projekt mit Scrapy ganz einfach ist:
import scrapy
from urllib.parse import urlencode
API_KEY = '51e43be283e4db2a5afb62660xxxxxxx'
def get_scraperapi_url(url):
payload = {'api_key': API_KEY, 'url': url}
proxy_url = 'http://api.scraperapi.com/?' + urlencode(payload)
return proxy_url
Wie Sie sehen, definieren wir die Methode get_scraperapi_url(), um uns bei der Erstellung der URL zu helfen, an die wir die Anfrage senden. Zuerst haben wir oben unsere Abhängigkeiten hinzugefügt und dann die Variable API_KEY hinzugefügt, die unseren API-Schlüssel enthält – um Ihren Schlüssel zu erhalten, melden Sie sich einfach für ein kostenloses ScraperAPI-Konto an und Sie finden ihn in Ihrem Dashboard.
Diese Methode erstellt die URL für die Anfrage für jede URL, die unser Scraper findet, und deshalb richten wir sie auf diese Weise ein, anstatt auf die direktere Art, einfach alle Parameter wie folgt direkt in die URL einzufügen:
start_urls = ('http://api.scraperapi.com?api_key={yourApiKey}&url={URL}')
3. Verstehen der URL-Struktur der Website
Die URL-Struktur ist für jede Website so ziemlich einzigartig. Entwickler neigen dazu, unterschiedliche Strukturen zu verwenden, um ihnen die Navigation zu erleichtern und in einigen Fällen das Navigationserlebnis für Suchmaschinen-Crawler wie Google und echte Benutzer zu optimieren.
Um paginierten Inhalt zu extrahieren, müssen wir verstehen, wie er funktioniert, und entsprechend planen. Es gibt keinen besseren Weg, dies zu tun, als die Seiten zu überprüfen und zu sehen, wie sich die URL selbst von einer Seite zur nächsten ändert.
Wenn wir also zu https://www.snowandrock.com/c/mens/accessories/hats.html gehen und zum letzten aufgeführten Produkt scrollen, können wir sehen, dass es eine nummerierte Paginierung und eine Weiter-Schaltfläche verwendet.
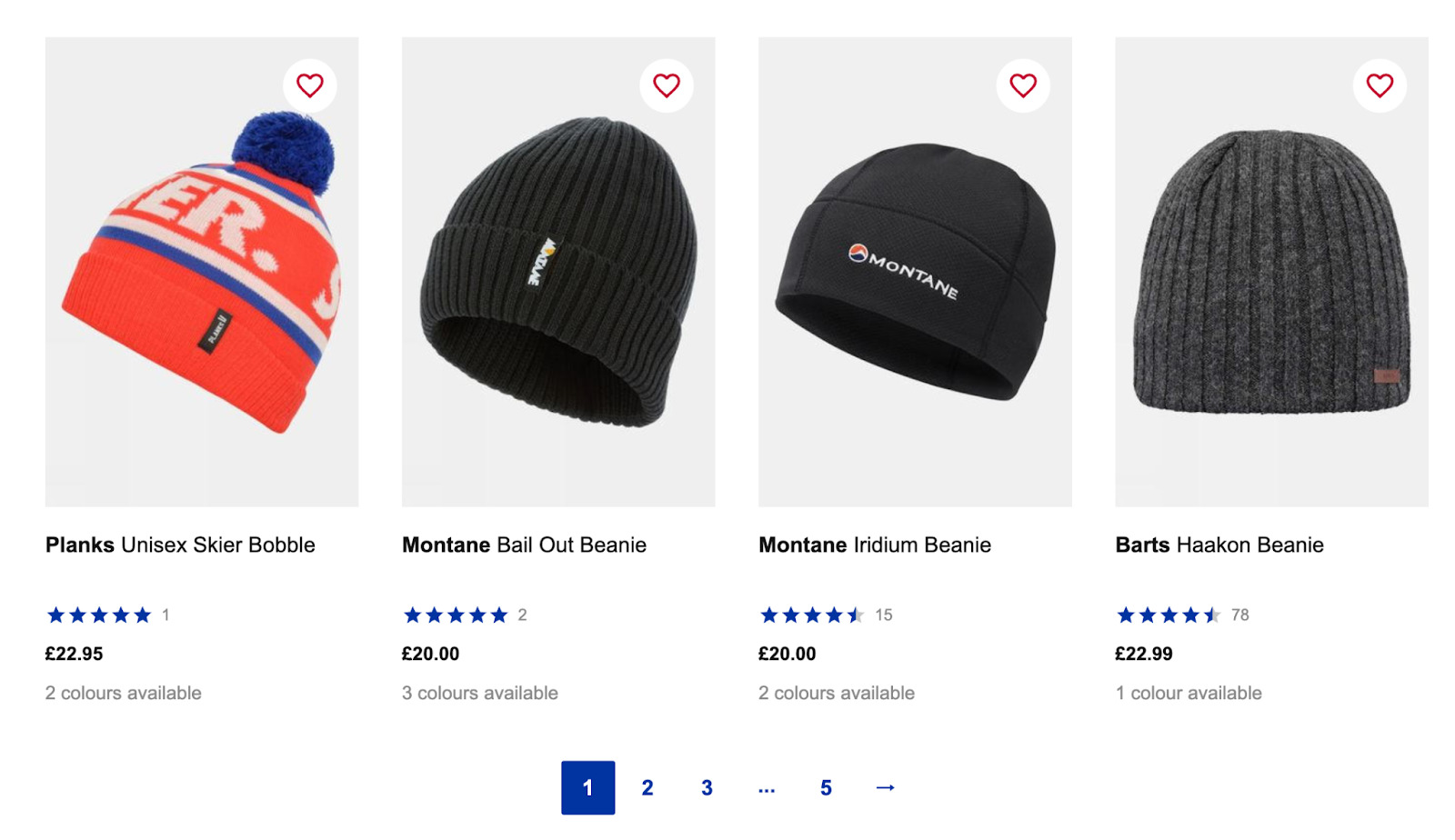
Das sind großartige Neuigkeiten, da es einfacher ist, auf jeder Seite die Schaltfläche „Weiter“ auszuwählen, als jede Seitennummer durchzugehen. Schauen wir uns dennoch an, wie sich die URL ändert, wenn man auf die zweite Seite klickt.
Das haben wir herausgefunden:
- Seite 1: https://www.snowandrock.com/c/mens/accessories/hats.html?page=0&size=48
- Seite 2: https://www.snowandrock.com/c/mens/accessories/hats.html?page=1&size=48
- Seite 3: https://www.snowandrock.com/c/mens/accessories/hats.html?page=2&size=48
Beachten Sie, dass sich die URL der ersten Seite ändert, wenn Sie über die Navigation zur Seite zurückkehren und zu page=0 wechselt. Obwohl wir die Schaltfläche „Weiter“ verwenden, um durch die Seitennummerierung dieser Website zu navigieren, ist dies nicht in jedem Fall so einfach.
Wenn wir diese Struktur verstehen, können wir eine Funktion erstellen, um den Seitenparameter in der URL zu ändern und um 1 zu erhöhen, sodass wir ohne eine Schaltfläche „Weiter“ zur nächsten Seite wechseln können.
Notiz: Nicht alle Seiten folgen derselben Struktur. Überprüfen Sie daher immer, welche Parameter sich wie ändern.
Da wir nun die ursprüngliche URL für die Anfrage kennen, können wir einen benutzerdefinierten Spider erstellen.
4. Senden der ersten Anfrage mit der Methode Start_Requests()
Für die erste Anfrage erstellen wir eine Spider-Klasse und geben ihr den Namen Pagi:
class PaginationScraper(scrapy.Spider):
name = "pagi"
Dann definieren wir die Methode start_requests():
def start_requests(self):
start_urls = ('https://www.snowandrock.com/c/mens/accessories/hats.html')
for url in start_urls:
yield scrapy.Request(url=get_scraperapi_url(url), callback=self.parse)
Nachdem wir nun unser Skript ausgeführt haben, sendet es jede neu gefundene URL an diese Methode, wo die neue URL mit dem Ergebnis zusammengeführt wird get_scraperapi_url() Methode, Senden der Anfrage über die ScraperAPI-Server und Sicherstellen unseres Projekts.
5. Aufbau unseres Parsers
Nachdem wir unsere Selektoren mit Scrapy Shell getestet haben, sind dies die Selektoren, die wir entwickelt haben:
def parse(self, response):
for hats in response.css('div.as-t-product-grid__item'):
yield {
'name': hats.css('.as-a-text.as-m-product-tile__name::text').get(),
'price': hats.css('.as-a-price__value--sell strong::text').get(),
'link': hats.css('a').attrib('href'),
}
Wenn Sie mit Scrapy Shell oder Scrapy im Allgemeinen nicht vertraut sind, ist es möglicherweise eine gute Idee, sich unser vollständiges Scrapy-Tutorial anzusehen, in dem wir alle Grundlagen behandeln, die Sie wissen müssen.
Wir wählen jedoch grundsätzlich alle Divs aus, die die gewünschten Informationen enthalten (response.css('div.as-t-product-grid__item') und dann den Namen, den Preis und den Produktlink extrahieren.
6. Machen Sie eine Scrapy-Bewegung durch die Paginierung
Großartig! Wir haben die Informationen, die wir benötigen, von der ersten Seite an, was nun? Nun, wir müssen unseren Parser anweisen, die neue URL irgendwie zu finden und an die zu senden start_requests() Methode, die wir zuvor definiert haben. Mit anderen Worten: Wir müssen eine ID oder Klasse finden, mit der wir den Link in die Schaltfläche „Weiter“ einfügen können.
Technisch gesehen könnten wir die Klasse gebrauchen ‘.as-a-btn.as-a-btn--pagination as-m-pagination__item’ aber zum Glück gibt es ein besseres Ziel: rel=next. Es wird nicht mit anderen Selektoren verwechselt und die Auswahl eines Attributs mit Scrapy ist einfach.
next_page = response.css('a(rel=next)').attrib('href')
if next_page is not None:
yield response.follow(next_page, callback=self.parse)
Jetzt wird zwischen den Seiten iteriert, bis keine Seiten mehr in der Paginierung vorhanden sind – wir müssen also keinen weiteren Stoppmechanismus festlegen.
Wenn Sie mitgemacht haben, sollte Ihre Datei so aussehen:
import scrapy
from urllib.parse import urlencode
API_KEY = '51e43be283e4db2a5afb62660xxxxxx'
def get_scraperapi_url(url):
payload = {'api_key': API_KEY, 'url': url}
proxy_url = 'http://api.scraperapi.com/?' + urlencode(payload)
return proxy_url
class PaginationScraper(scrapy.Spider):
name = "pagi"
def start_requests(self):
start_urls = ('https://www.snowandrock.com/c/mens/accessories/hats.html')
for url in start_urls:
yield scrapy.Request(url=get_scraperapi_url(url), callback=self.parse)
def parse(self, response):
for hats in response.css('div.as-t-product-grid__item'):
yield {
'name': hats.css('.as-a-text.as-m-product-tile__name::text').get(),
'price': hats.css('.as-a-price__value--sell strong::text').get(),
'link': hats.css('a').attrib('href'),
}
next_page = response.css('a(rel=next)').attrib('href')
if next_page is not None:
yield response.follow(next_page, callback=self.parse)
Es ist jetzt betriebsbereit!
Umgang mit Paginierung ohne Weiter-Schaltfläche
Bisher haben wir gesehen, wie man einen Web-Scraper erstellt, der mithilfe des Links in der Schaltfläche „Weiter“ durch die Paginierung geht – denken Sie daran, dass Scrapy nicht wirklich mit der Seite interagieren kann, sodass es nicht funktioniert, wenn die Schaltfläche der Reihe nach angeklickt werden muss damit mehr Inhalte angezeigt werden.
Was passiert jedoch, wenn es keine Option ist? Mit anderen Worten: Wie können wir durch eine Paginierung navigieren, ohne dass wir uns auf eine Schaltfläche „Weiter“ verlassen können?
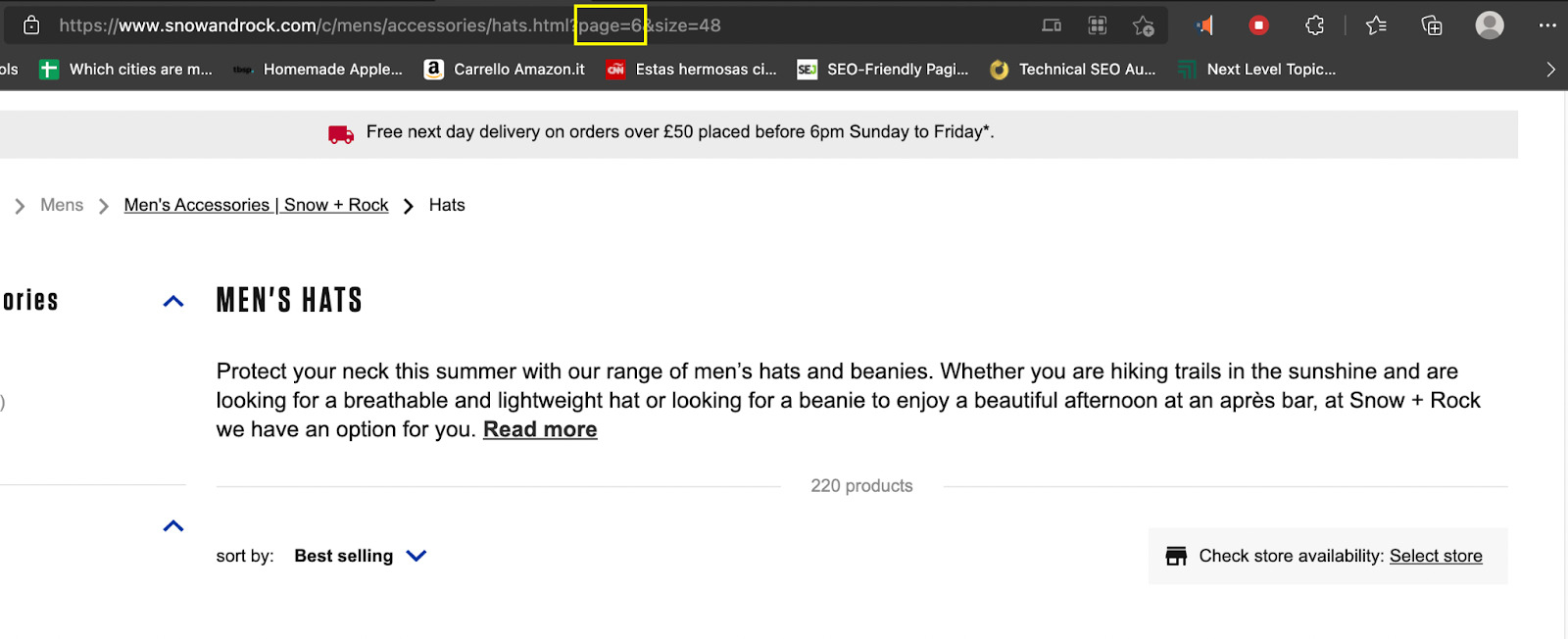
Hier ist es hilfreich, die URL-Struktur der Website zu verstehen:
- Seite 1: https://www.snowandrock.com/c/mens/accessories/hats.html?page=0&size=48
- Seite 2: https://www.snowandrock.com/c/mens/accessories/hats.html?page=1&size=48
- Seite 3: https://www.snowandrock.com/c/mens/accessories/hats.html?page=2&size=48
Das Einzige, was sich zwischen den URLs ändert, ist der Seitenparameter, der sich für jede nächste Seite um 1 erhöht. Was bedeutet das für unser Drehbuch? Nun, zunächst müssen wir die Art und Weise ändern, wie wir die ursprüngliche Anfrage senden, indem wir eine neue Variable hinzufügen:
class PaginationScraper(scrapy.Spider):
name = "pagi"
page_number = 1
start_urls = ('http://api.scraperapi.com?api_key=51e43be283e4db2a5afb62660xxxxxxx&url=https://www.snowandrock.com/c/mens/accessories/hats.html?page=0&size=48')
In diesem Fall verwenden wir auch die direkte cURL-Struktur von ScraperAPI, da wir nur einen Parameter ändern – was bedeutet, dass keine Notwendigkeit besteht, eine völlig neue URL zu erstellen. Auf diese Weise wird die Anfrage bei jeder Änderung weiterhin über die Server von ScraperAPI gesendet.
Als nächstes müssen wir unsere Bedingung am Ende ändern, um sie an die neue Logik anzupassen:
next_page = 'http://api.scraperapi.com?api_key=51e43be283e4db2a5afb62660xxxxxxx&url=https://www.snowandrock.com/c/mens/accessories/hats.html?page=' + str(PaginationScraper.page_number) + '&size=48'
if PaginationScraper.page_number
Was hier passiert, ist, dass wir über die auf die Variable page_number zugreifen PaginationScraper() Methode zum Ersetzen des Werts des Seitenparameters innerhalb der URL.
Anschließend wird geprüft, ob der Wert von page_number kleiner als 6 ist – da nach Seite 5 keine Ergebnisse mehr vorliegen.
Solange die Bedingung erfüllt ist, erhöht sich die page_number Wert um 1 und senden Sie die URL zum Parsen und Scrapen usw., bis der page_number ist 6 oder mehr.
Hier ist die Vollständiger Code zum Scrapen paginierter Seiten ohne Weiter-Schaltfläche:
import scrapy
class PaginationScraper(scrapy.Spider):
name = "pagi"
page_number = 1
start_urls = ('http://api.scraperapi.com?api_key=51e43be283e4db2a5afb62660xxxxxxx&url=https://www.snowandrock.com/c/mens/accessories/hats.html?page=0&size=48')
def parse(self, response):
for hats in response.css('div.as-t-product-grid__item'):
yield {
'name': hats.css('.as-a-text.as-m-product-tile__name::text').get(),
'price': hats.css('.as-a-price__value--sell strong::text').get(),
'link': 'https://www.snowandrock.com/' + hats.css('a').attrib('href')
}
next_page = 'http://api.scraperapi.com?api_key=51e43be283e4db2a5afb62660fc6ee44&url=https://www.snowandrock.com/c/mens/accessories/hats.html?page=' + str(PaginationScraper.page_number) + '&size=48'
if PaginationScraper.page_number
Zusammenfassung
Egal, ob Sie Immobiliendaten zusammenstellen oder E-Commerce-Plattformen wie Etsy durchsuchen, der Umgang mit Paginierung kommt häufig vor und Sie müssen bereit sein, kreativ zu werden.
Alternative Daten sind für fast jede Branche auf der Welt zu einem Muss geworden, und die Fähigkeit, komplexe und effiziente Scraper zu erstellen, wird Ihnen einen enormen Wettbewerbsvorteil verschaffen.
Egal, ob Sie ein freiberuflicher Entwickler oder ein Geschäftsinhaber sind, der bereit ist, in Web Scraping zu investieren, ScraperAPI verfügt über alle Tools, die Sie zum mühelosen Sammeln von Daten benötigen, indem alle Hindernisse automatisch für Sie behoben werden.
Bis zum nächsten Mal, viel Spaß beim Schaben!
