
Pengikisan web dan perayapan adalah dua cara berbeda untuk mengumpulkan data dari situs web. Scraping adalah proses mengekstraksi data tertentu dari sebuah website, sedangkan crawling adalah proses mengunjungi semua halaman. Perayapan web digunakan untuk berbagai tujuan, seperti mengindeks situs web oleh mesin pencari atau membuat peta situs untuk pemiliknya. Anda dapat membaca perbandingan komprehensif kami untuk lebih memahami perbedaannya.
Fleksibilitas bahasa Python dan dukungan komunitasnya menjadikannya pilihan populer untuk proyek pengembangan aplikasi web, baik Anda seorang pemula atau pengembang berpengalaman. Ini menyederhanakan proses pembuatan web scraper dan crawler serta bekerja dengan data yang dikumpulkan, menjadikannya bahasa yang ideal bagi siapa saja yang ingin mengambil dan menganalisis data dari Internet.
Memahami perayap web Python
Seperti yang telah disebutkan sebelumnya, web crawling adalah proses pengumpulan data web dari seluruh halaman situs web. Saat halaman dirayapi, semua tautan di setiap situs web dicatat. Tautan yang sudah dikumpulkan kemudian dirayapi.
Jenis perayap web
Meskipun semua perayap web memiliki tujuan yang sama, mereka dapat dibagi menjadi beberapa jenis:
- Perayap tujuan umum.
- Perayap terfokus.
- Perayap tambahan.
- Perayap web dalam.
Perayap tujuan umum adalah jenis perayap web yang paling umum dan digunakan oleh mesin pencari seperti Google, Bing, dan Yahoo. Tujuan utamanya adalah mengindeks halaman web di internet dan membuatnya dapat dicari. Pada saat yang sama, perayap terfokus dirancang untuk mengindeks subkumpulan situs web atau laman web tertentu.
Perayap tambahan bertanggung jawab untuk memperbarui data yang diindeks secara rutin dengan merayapi ulang situs web untuk menemukan dan mengindeks konten baru atau yang diperbarui. Mesin pencari menggunakan perayap tambahan untuk menjaga hasil pencariannya tetap terkini.
Jenis yang terakhir adalah deep web crawler. Mereka digunakan untuk mengakses dan mengindeks konten yang biasanya tidak dapat diakses melalui mesin pencari tradisional. Anda dapat merayapi basis data, situs web yang dilindungi kata sandi, dan konten lain yang dihasilkan secara dinamis.
Cara kerja Perayap Web Python
Perayap web pada dasarnya menggunakan dua metode perayapan: yang mengutamakan kedalaman dan yang mengutamakan luas. Metode-metode ini berbeda dalam cara mereka mengikuti tautan. Kami akan membahas metode ini lebih terinci nanti. Pertama, mari kita fokus pada prinsip umum perayapan web.

Untuk memulai, perayap web memerlukan URL awal untuk memulai perayapan. Semua tautan internal ditemukan di beranda dan ditambahkan ke kumpulan tautan. Setelah semua tautan di situs web dikumpulkan, perayap web mengikuti tautan berikutnya dalam kumpulan yang belum dirayapi. Proses penangkapan kemudian diulangi untuk tautan itu. Proses ini berlanjut hingga semua link di situs telah dirayapi.
Kasus penggunaan perayapan web
Perayapan web memiliki berbagai aplikasi di berbagai industri dan bidang, termasuk pengindeksan mesin pencari, penambangan data, dan agregasi konten.
Perayap web mengindeks halaman web dan membangun basis data mesin pencari sehingga pengguna dapat mencari dan menemukan informasi secara online. Mereka juga digunakan untuk mengumpulkan konten dari berbagai situs web dan menyajikannya di satu tempat. Agregator berita, agregator blog, dan platform sindikasi konten menggunakan perayap web untuk mengumpulkan artikel dan informasi dari berbagai sumber.
Peneliti dan ilmuwan data menggunakan perayapan web untuk merayapi data web untuk tujuan analisis dan penelitian. Ini bisa berupa analisis sentimen terhadap postingan media sosial, melacak penyebaran penyakit melalui artikel berita, atau mengumpulkan informasi untuk penelitian akademis. Perayap Python dapat mengumpulkan data waktu nyata seperti harga saham, kondisi cuaca, skor olahraga, dan acara streaming langsung.
Perayapan yang mengutamakan kedalaman vs. yang mengutamakan lebar
Perayapan kedalaman dan luas adalah dua strategi dasar yang digunakan perayap web untuk menavigasi dan mengindeks web. Mereka berbeda dalam cara mereka memprioritaskan dan merayapi situs web.
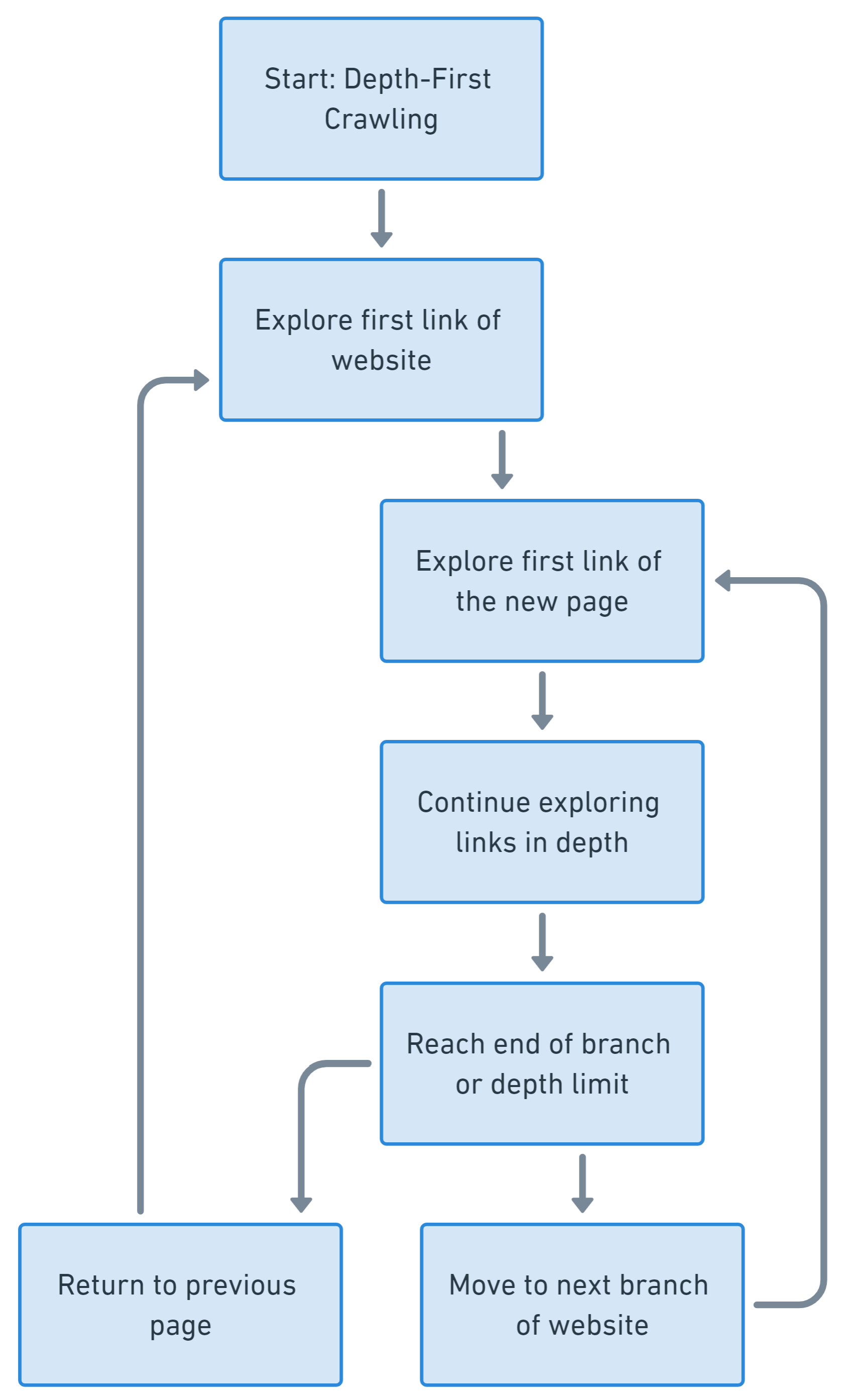
Perayapan mendalam pertama berfokus pada penjelajahan satu cabang struktur tautan situs web selengkap mungkin sebelum berpindah ke cabang lain. Ini memprioritaskan urutan jalur tautan daripada percabangan.
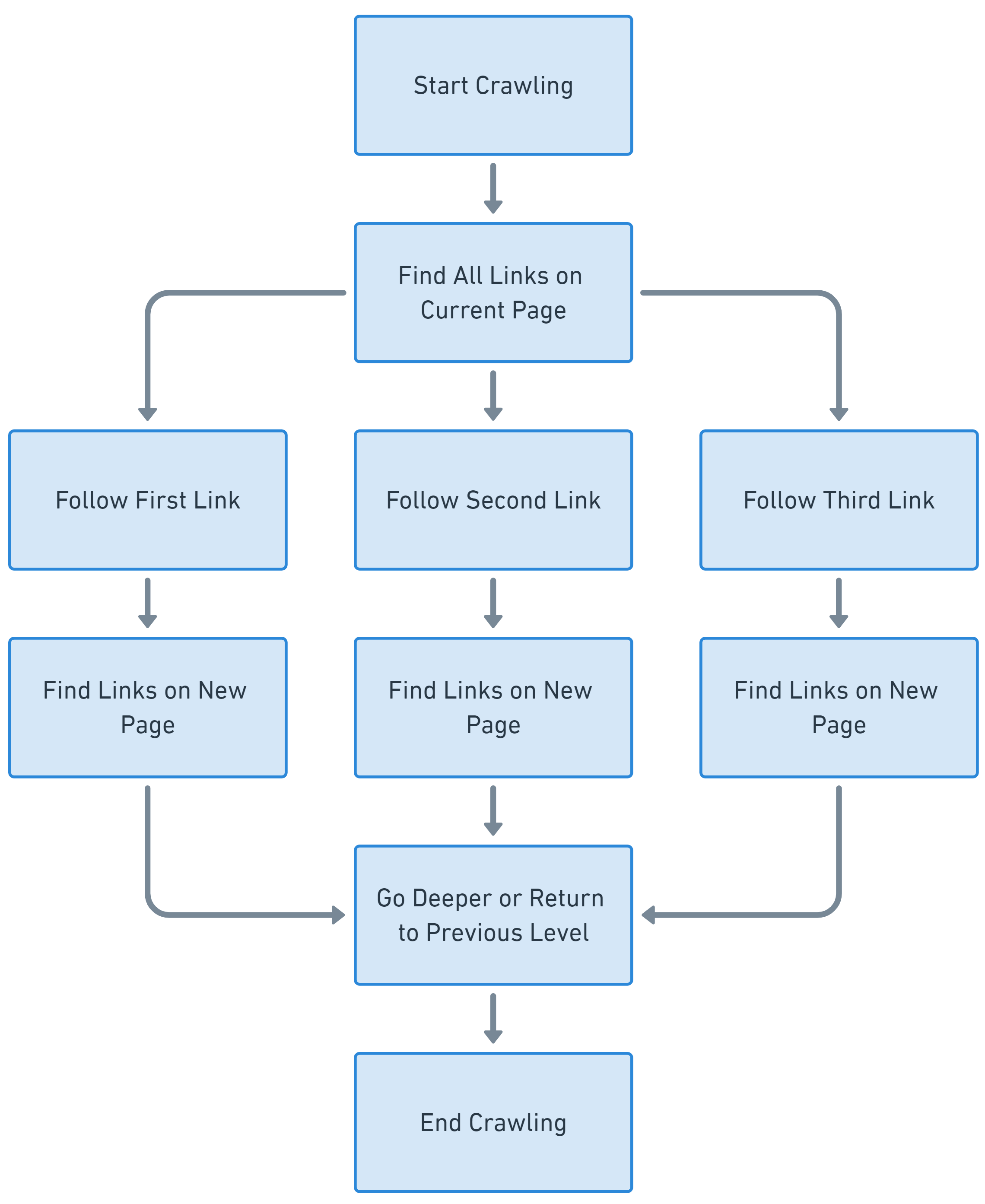
Sebaliknya, perayapan luas pertama melibatkan penjelajahan berbagai situs web dengan kedalaman yang sama sebelum masuk lebih dalam. Ini memprioritaskan lebar daripada kedalaman.
Dalam praktiknya, banyak perayap web menggunakan kombinasi strategi ini, menerapkan pendekatan hibrid yang menyeimbangkan kedalaman dan keluasan untuk mencapai hasil yang diinginkan.
Persyaratan untuk merayapi situs web
Perayapan web memerlukan perpustakaan unik untuk meminta berbagai tautan dan mengekstrak data dari halaman. Perpustakaan scraping yang kami pertimbangkan sebelumnya cocok untuk tujuan ini. Namun, yang paling umum untuk tujuan ini adalah:
- Pertanyaan dengan BeautifulSoup. Ini adalah pilihan yang bagus untuk melakukan scraping meskipun Anda seorang pemula. Namun, perpustakaan ini memiliki beberapa keterbatasan karena hanya memungkinkan Anda membuat kueri sederhana dan menganalisis data. Dalam hal ini, kita juga memerlukan pustaka urllib untuk bekerja dengan berbagai bagian tautan.
- Selenium. Memungkinkan Anda menggunakan browser tanpa kepala, meningkatkan kemungkinan menghindari pemblokiran saat merayapi halaman. Menggunakan perpustakaan ini memungkinkan Anda meniru perilaku pengguna sebenarnya, yang berarti penggunaannya mengurangi risiko pemblokiran dan menyelesaikan semua masalah pada opsi pertama.
- Tdk lengkap. Ini bukan perpustakaan, tetapi keseluruhan kerangka kerja untuk scraping. Ia memiliki sejumlah fitur yang dirancang khusus untuk menyelesaikan tugas ini. Namun, dibandingkan dengan perpustakaan lain, tampaknya cukup sulit untuk digunakan.
Dalam artikel ini, kita akan melihat ketiga opsi untuk membantu Anda menemukan solusi yang paling sesuai dengan kebutuhan dan tugas Anda. Pertama, pastikan Anda menginstal Python 3 dan editor teks, sebaiknya dengan penyorotan sintaksis (sebaiknya gunakan Sublime atau Visual Studio Code). Meskipun Anda tidak memerlukan IDE lengkap untuk bekerja dengan Python, mereka dapat membuat pengkodean lebih mudah. Sekarang mari kita instal perpustakaan yang diperlukan:
pip install beautifulsoup4
pip install urllib
pip install selenium
pip install scrapyPustaka persyaratan sudah diinstal sebelumnya dan Anda memerlukan driver web untuk menggunakan Selenium. Untuk petunjuk cara menginstal semua komponen Selenium, termasuk driver web, lihat artikel kami sebelumnya.
Perayapan web dengan Permintaan dan BeautifulSoup
Untuk membuat contoh ini lebih bermanfaat dan mudah dipahami, mari kita tetapkan tujuan. Misalnya kita ingin membuat web crawler yang akan kita gunakan untuk membuat peta situs. Buat file dengan ekstensi .py yang ingin Anda kerjakan. Hal pertama yang perlu kita lakukan adalah mengimpor semua modul dan perpustakaan yang akan kita gunakan dalam skrip.
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoinTentukan URL awal untuk memulai proses perayapan web, kumpulan untuk menyimpan URL yang dikunjungi untuk menghindari duplikat URL, dan daftar untuk menyimpan URL yang dikumpulkan.
start_url="https://example.com"
visited_urls = set()
sitemap = ()Cara termudah untuk mengulangi semua tautan adalah dengan membuat fungsi terpisah yang kita panggil untuk setiap tautan yang kita temukan.
def crawl(url):Pertama, periksa apakah URL telah dikunjungi sebelumnya untuk menghindari duplikat:
if url in visited_urls:
returnJika link belum diproses, proseslah. Namun, untuk menghindari kesalahan dan gangguan yang tidak terduga, sertakan pemrosesan dalam blok coba/kecuali.
try:
# Here will be URL process
except Exception as e:
print(f'Error crawling URL: {url}')
print(e)Selanjutnya kita beralih ke blok try. Ikuti tautannya dan lihat apakah kode status 200 dikembalikan. Ini berarti situs tersebut mengembalikan respons yang berhasil. Jika situs web mengembalikan kode status yang berbeda, kami akan melewati tautan ini.
response = requests.get(url)
if response.status_code == 200:Jika kode status berhasil, analisis halaman web dengan BeautifulSoup dan ekstrak semua link.
soup = BeautifulSoup(response.text, 'html.parser')
links = soup.find_all('a')Ekstrak semua URL dari peta situs dan simpan dalam daftar. Kemudian proses secara rekursif setiap URL yang ditemukan.
for link in links:
href = link.get('href')
if href:
full_url = urljoin(url, href)
sitemap.append(full_url)
crawl(full_url) Pada akhirnya, setelah blok coba/kecuali, tandai URL saat ini sebagai diproses.
visited_urls.add(url)Kami sekarang telah menyelesaikan definisi fungsi. Namun, kita masih perlu memintanya. Kami tidak dapat memanggilnya sebelum mendefinisikannya karena Python adalah bahasa pemrograman yang ditafsirkan, artinya ia menjalankan kode baris demi baris dan tidak mengkompilasinya sebelum dieksekusi. Jadi mari kita panggil fungsi tautan awal yang kita nyatakan di awal.
crawl(start_url)Ini menyelesaikan proses perayapan. Dengan tautan yang telah Anda kumpulkan, kini Anda dapat melakukan semua yang Anda perlukan. Misalnya, simpan peta situs yang dihasilkan ke file teks dan tampilkan pesan di layar bahwa peta situs berhasil dibuat.
with open('sitemap.txt', 'w') as file:
for url in sitemap:
file.write(url + '\n')
print('Sitemap created and saved to sitemap.txt')Sekarang ketika Anda menjalankan skrip, file sitemap.txt akan dihasilkan yang berisi semua URL situs web. Peta situs ini dapat berguna untuk optimasi mesin pencari (SEO) dan organisasi situs web.
Perayapan web dengan Scrapy
Scrapy adalah kerangka kerja Python perayapan dan pengikisan web sumber terbuka. Ia menawarkan alat yang kuat dan fleksibel untuk mengekstraksi data dari situs web. Ini memungkinkan Anda menentukan laba-laba khusus untuk menavigasi situs web, mengekstrak data, dan menyimpannya dalam berbagai format.
Scrapy juga menangani pembatasan permintaan, perayapan serentak, dan fitur-fitur canggih lainnya. Kami telah membahas cara menginstal dan menggunakan Scrapy di postingan sebelumnya, jadi kami tidak akan mengulanginya di sini. Mari buat crawler untuk membuat peta situs menggunakan Scrapy. Gunakan perintah ini untuk membuat proyek baru:
scrapy startproject my_sitemapDalam proyek Scrapy Anda, buatlah laba-laba yang menentukan bagaimana situs Anda harus dirayapi dan tautan dikumpulkan. Di laba-laba Anda, Anda dapat menentukan URL awal dan bagaimana tautan harus diikuti:
import scrapy
class SitemapSpider(scrapy.Spider):
name="sitemap"
allowed_domains = ('example.com')
start_urls = ('https://example.com')
def parse(self, response):
for href in response.css('a::attr(href)'):
url = response.urljoin(href.extract())
yield {
'url': url
}Untuk menjalankan laba-laba, gunakan perintah berikut:
scrapy crawl sitemap -o sitemap.jsonHasilnya, Anda akan mendapatkan file keluaran bernama sitemap.json, yang berisi peta situs.
Gunakan Selenium untuk merayapi situs web dinamis
Untuk menggunakan Selenium untuk merayapi semua tautan di situs web dan mengumpulkannya untuk pembuatan peta situs, Anda dapat membuat fungsi rekursif yang menavigasi situs web, mengumpulkan tautan, dan mengikutinya, seperti pada contoh pertama. Pertama impor perpustakaan dan konfigurasikan browser tanpa kepala:
from selenium import webdriver
DRIVER_PATH = 'C:\chromedriver.exe' #or any other path of webdriver
options = webdriver.ChromeOptions()
options.add_argument("user-agent=Mozilla/5.0 (X11; CrOS x86_64 8172.45.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.64 Safari/537.36")
driver = webdriver.Chrome(executable_path=DRIVER_PATH, options=options)Sekarang tentukan URL awal dan buat kumpulan untuk menyimpan URL yang dikunjungi untuk menghindari perayapan halaman yang sama dua kali.
start_url="https://example.com"
visited_urls = set()Mari buat fungsi pemrosesan URL yang melakukan traversal tautan rekursif menggunakan Selenium.
def collect_links(url):
if url in visited_urls:
return
visited_urls.add(url)
driver.get(url)
links = (a.get_attribute('href') for a in driver.find_elements_by_tag_name('a'))
for link in links:
if link and link.startswith('https://example.com'):
collect_links(link)Sekarang yang harus Anda lakukan adalah memanggil fungsi tersebut untuk memulai proses pengumpulan tautan.
collect_links(start_url)Untuk menyelesaikan eksekusi skrip, tutup browser:
driver.quit()Selenium adalah alat yang sempurna untuk menyalin situs web dinamis, tetapi mungkin memerlukan lebih banyak kode dan sumber daya dibandingkan perayap web tradisional. Kemampuannya untuk berinteraksi dengan halaman web dan menjalankan JavaScript menjadikannya pilihan pertama untuk menyalin konten yang mengandalkan pembaruan waktu nyata dan interaksi pengguna.
Menghindari tindakan anti-bot
Pencakar dan perayap web sering kali dihadapkan pada tindakan anti-bot yang diterapkan oleh situs web untuk mencegah akses otomatis. Langkah-langkah ini diambil untuk melindungi situs web dari penyalahgunaan atau pencurian data. Operator perayap perlu mengetahui perlindungan bot ini dan cara melewatinya.
Mengidentifikasi dan menangani mekanisme anti-bot
Situs web dapat memblokir permintaan jika tampak mencurigakan. Untuk menghindarinya, Anda bisa menggunakan beberapa tips yang dapat membantu Anda. Misalnya, Anda dapat menggunakan agen pengguna yang meniru browser pada umumnya. Yang terbaik adalah menggunakan agen pengguna nyata.
Salah satu tindakan anti-bot yang paling umum adalah memblokir permintaan dari alamat IP tertentu. Untuk menghindari hal ini, gunakan server proxy atau siapkan kumpulan proxy Anda sendiri. Untuk menghindari terpicunya mekanisme pembatasan tarif, kendalikan jumlah permintaan selama periode waktu tertentu dengan memanfaatkan penundaan antar permintaan.
Situs web dapat menggunakan penanda sesi untuk melacak interaksi pengguna. Untuk menghindari deteksi, tiru perilaku pengguna dan kelola sesi. Anda juga dapat menggunakan browser tanpa kepala untuk meniru interaksi pengguna sebenarnya. Pilihan lain untuk situs web adalah menggunakan cookie untuk melacak sesi pengguna. Agar sesi tetap hidup, gunakan cookie di kode perayapan web Anda.
CAPTCHA dan cara melewatinya
CAPTCHA adalah tes respons tantangan yang digunakan dalam ilmu komputer untuk menentukan apakah penggunanya adalah manusia. Mereka dirancang agar mudah dipecahkan oleh manusia, tetapi sulit bagi bot.
Ada berbagai cara untuk melewati CAPTCHA. Salah satu opsinya adalah menggunakan layanan pemecah CAPTCHA pihak ketiga. Layanan ini menggunakan berbagai metode untuk menyelesaikan CAPTCHA, termasuk pengenalan gambar dan pembelajaran mesin.
Cara lain untuk melewati CAPTCHA adalah dengan menyelesaikan CAPTCHA secara manual. Hal ini seringkali tidak mungkin dilakukan saat mengikis area yang luas, namun dalam beberapa kasus hal ini pasti dapat dilakukan.
Situs web biasanya hanya menampilkan CAPTCHA ketika perilaku pengguna mencurigakan. Dengan mengikuti rekomendasi di bagian sebelumnya, Anda dapat mengurangi kemungkinan terkena CAPTCHA.
Diploma
Perayapan web adalah alat penting untuk mengumpulkan data dari Internet, dan Python menyediakan lingkungan yang kuat untuk penerapannya. Memahami prinsip, jenis, dan metode perayapan web akan membantu Anda memanfaatkan potensinya di berbagai bidang, mulai dari SEO hingga penelitian dan analisis.
Penting untuk memahami web crawler, dasar dari web scraping. Perayap web diklasifikasikan menjadi beberapa jenis seperti: B. Perayap tujuan umum, perayap khusus, perayap tambahan, dan perayap dalam. Setiap jenis melakukan tugas tertentu, mulai dari mengindeks seluruh Internet hingga mengakses konten yang biasanya tidak terlihat di mesin pencari standar.
Ada banyak perpustakaan dan alat yang tersedia untuk perayapan web, termasuk Permintaan dengan BeautifulSoup, Selenium, dan Scrapy. Alat-alat ini memungkinkan pengembang mengekstrak data dari situs web secara efisien. Pilihan alat tergantung pada kebutuhan spesifik proyek.
