
Dalam panduan ini Anda akan mempelajari cara:
- Menyiapkan dan menginstal Selenium untuk Pengikisan web
- Lakukan tugas seperti mengambil tangkapan layar, menggulir, dan mengklik item.
- Gunakan Selenium bersama dengan BeautifulSoup untuk ekstraksi data yang lebih efisien
- Tangani pemuatan konten dinamis dan pengguliran tanpa batas
- Identifikasi dan hindari honeypot dan hambatan gesekan lainnya
- Terapkan proxy untuk menghindari pemblokiran IP dan meningkatkan kinerja scraping
- Render situs web dengan banyak JavaScript tanpa hanya mengandalkan Selenium
Sekarang mari selami web scraping Selenium dan buka potensi penuh pengumpulan data otomatis!
Persyaratan proyek
Sebelum Anda memulai web scraping Selenium, pastikan Anda memiliki hal berikut:
- Anda harus menginstal Python di komputer Anda (versi 3.10 atau lebih baru)
pip(Penginstal paket Python)- Driver web untuk browser pilihan Anda (mis. ChromeDriver untuk Google Chrome)
instalasi
Pertama, Anda perlu menginstal Selenium. Anda dapat melakukan ini dengan pip:
Selanjutnya, unduh driver web untuk browser Anda. Misalnya, unduh ChromeDriver untuk Google Chrome dan pastikan dapat diakses dari PATH sistem Anda.
Impor Selenium
Mulailah dengan mengimpor modul yang diperlukan:
-
pengemudi web: Ini adalah modul utama Selenium yang menyediakan semua implementasi WebDriver. Ini memungkinkan Anda untuk memulai instance browser dan mengontrol perilakunya secara terprogram.
from selenium import webdriver -
Dari: Itu
ByKelas menentukan mekanisme untuk menemukan elemen dalam halaman web. Ini menyediakan berbagai metode seperti ID, Nama, Nama Kelas, Pemilih CSS, XPath, dll. yang penting untuk menemukan elemen pada halaman web.from selenium.webdriver.common.by import By -
Kunci: Itu
KeysKelas menyediakan kunci khusus yang dapat dikirim ke elemen, seperti tombol Enter, tombol panah, escape, dll. Hal ini berguna untuk mensimulasikan interaksi keyboard dalam pengujian otomatis atau web scraping.from selenium.webdriver.common.keys import Keys -
WebDriverTunggu: Kelas ini adalah bagian dari modul Dukungan UI Selenium (
selenium.webdriver.support.ui) dan memungkinkan Anda menunggu hingga kondisi tertentu terjadi sebelum melanjutkan dengan kode. Ini membantu dalam menangani elemen web dinamis yang mungkin memerlukan waktu untuk dimuat.from selenium.webdriver.support.ui import WebDriverWait -
kondisi_yang diharapkan sebagai EC: Itu
expected_conditionsModul dalam Selenium menyediakan serangkaian kondisi yang telah ditentukan sebelumnyaWebDriverWaitbisa menggunakan. Kondisi ini termasuk memeriksa keberadaan elemen, visibilitas, status yang dapat diklik, dll.from selenium.webdriver.support import expected_conditions as EC
Impor ini penting untuk menyiapkan skrip otomatisasi Selenium. Mereka menyediakan akses ke kelas dan metode yang diperlukan untuk berinteraksi dengan elemen web, mendengarkan kondisi, dan secara efektif mensimulasikan tindakan pengguna di halaman web.
Menyiapkan driver web
Inisialisasi driver web untuk browser Anda dan konfigurasikan opsi jika perlu:
chrome_options = webdriver.ChromeOptions()
# Add any desired options here, for example, headless mode:
# chrome_options.add_argument("--headless")
driver = webdriver.Chrome(options=chrome_options)
Penyiapan ini memungkinkan Anda menyesuaikan perilaku browser Chrome melalui chrome_options.
Misalnya, Anda dapat menjalankan browser dalam mode tanpa kepala dengan menggunakan --headless Pilihan. Ini berarti semuanya terjadi di latar belakang dan Anda tidak melihat jendela browser muncul.
Dan sekarang mari kita mulai mengikis!
TL;DR: Dasar-dasar pengikisan Selenium
Berikut adalah lembar contekan singkat untuk membantu Anda memulai dengan web scraping Selenium. Di sini Anda akan menemukan langkah-langkah penting dan cuplikan kode untuk tugas-tugas umum, sehingga Anda dapat langsung mulai melakukan scraping dengan mudah.
Kunjungi sebuah situs
Untuk membuka situs web, gunakan itu get() Fungsi:
driver.get("https://www.google.com")
Ambil tangkapan layar
Untuk mengambil tangkapan layar halaman saat ini, gunakan ini save_screenshot() Fungsi:
driver.save_screenshot('screenshot.png')
Menggulir halaman
Untuk menggulir halaman ke bawah, gunakan execute_script() Berfungsi untuk menggulir ke bawah hingga tinggi halaman penuh:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
Klik pada sebuah elemen
Untuk mengklik elemen (misalnya tombol), gunakan find_element() berfungsi untuk menemukan elemen dan kemudian memanggil click() Fungsi pada elemen:
button = driver.find_element(By.ID, "button_id")
button.click()
Menunggu suatu barang
Untuk menunggu item terlihat:
element = WebDriverWait(driver, 10).until(
EC.visibility_of_element_located((By.ID, "element_id"))
)
Berurusan dengan pengguliran tanpa batas
Untuk menangani pengguliran tanpa batas, Anda dapat menggulir berulang kali ke bagian bawah halaman hingga konten baru berhenti dimuat:
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2) # Wait for new content to load
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height
Menggabungkan Selenium dengan BeautifulSoup
Untuk ekstraksi data yang lebih efisien, Anda dapat menggunakan BeautifulSoup bersama Selenium:
from bs4 import BeautifulSoup
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
# Now you can use BeautifulSoup to parse the HTML content like normal
Dengan mengikuti langkah-langkah ini, Anda dapat menyelesaikan sebagian besar tugas web scraping dengan Selenium.
Jika Anda ingin mempelajari lebih dalam tentang web scraping dengan Selenium, baca terus!
Cara menggunakan Selenium untuk web scraping
Langkah 1: Konfigurasikan ChromeOptions
Untuk menyesuaikan cara Selenium berinteraksi dengan browser Chrome, konfigurasikan terlebih dahulu ChromeOptions:
chrome_options = webdriver.ChromeOptions()
Ini benar chrome_options dengan webdriver.ChromeOptions()jadi kami dapat menyesuaikan perilaku Chrome saat dikontrol oleh Selenium.
Opsional: Sesuaikan ChromeOptions
Anda dapat menyesuaikan ChromeOptions lebih lanjut. Misalnya, tambahkan baris berikut untuk mengaktifkan mode tanpa kepala:
chrome_options.add_argument("--headless")
Aktifkan mode tanpa kepala (--headless) menjalankan Chrome tanpa UI yang terlihat, yang sempurna untuk tugas otomatis yang tidak mengharuskan Anda melihat browser.
Langkah 2: Inisialisasi WebDriver dengan ChromeOptions
Selanjutnya, inisialisasi Chrome WebDriver dengan yang dikonfigurasi ChromeOptions:
driver = webdriver.Chrome(options=chrome_options)
Baris ini mempersiapkan Selenium untuk mengontrol Chrome berdasarkan opsi yang ditentukan, mengatur tahapan untuk interaksi otomatis dengan halaman web.
Langkah 3: Navigasikan ke situs web
Untuk mengarahkan WebDriver ke URL yang diinginkan, gunakan get() Fungsi. Perintah ini memberitahu Selenium untuk membuka dan memuat halaman web sehingga Anda dapat berinteraksi dengan situs tersebut.
driver.get("https://google.com/")
Ketika Anda selesai dengan interaksi Anda, gunakan quit() Metode untuk menutup browser dan mengakhiri sesi WebDriver.
Secara keseluruhan, get() memuat halaman web yang ditentukan sementara quit() menutup browser dan mengakhiri sesi, memastikan penyelesaian tugas pengikisan Anda dengan bersih.
Langkah 4: Ambil tangkapan layar
Untuk mengambil tangkapan layar halaman saat ini, gunakan ini save_screenshot() Fungsi. Ini dapat berguna untuk melakukan debug atau menyimpan status halaman.
driver.save_screenshot('screenshot.png')
Ini akan mengambil tangkapan layar halaman tersebut dan memasukkannya ke dalam gambar bernama Tangkapan layar.png.
Langkah 5: Gulir halaman
Menggulir penting untuk berinteraksi dengan situs web dinamis yang memuat konten tambahan saat Anda menggulir. Selenium menawarkan itu execute_script() Kemampuan untuk mengeksekusi kode JavaScript dalam konteks browser, memungkinkan Anda mengontrol perilaku pengguliran halaman.
Gulir ke bagian bawah halaman
Untuk menggulir ke bagian bawah halaman Anda dapat menggunakan skrip berikut. Ini sangat berguna untuk memuat konten tambahan di situs web dinamis.
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
Kode JavaScript ini menggulir jendela browser setinggi teks dokumen, secara efektif memindahkannya ke bagian bawah halaman.
Gulir ke item tertentu
Jika Anda ingin menggulir ke elemen tertentu pada halaman, Anda bisa scrollIntoView() Metode. Ini berguna ketika berinteraksi dengan elemen yang tidak terlihat di area pandang saat ini.
element = driver.find_element(By.ID, "element_id")
driver.execute_script("arguments(0).scrollIntoView(true);", element)
Kode ini menemukan elemen berdasarkan ID-nya dan menggulir halaman hingga elemen tersebut ditampilkan.
Berurusan dengan pengguliran tanpa batas
Untuk halaman yang terus-menerus memuat konten saat Anda menggulir, Anda dapat menerapkan loop untuk berulang kali menggulir ke bawah hingga konten baru berhenti dimuat. Berikut ini contoh cara menangani pengguliran tak terbatas:
import time
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2) # Wait for new content to load
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height
Lingkaran ini menggulir ke bagian bawah halaman, menunggu konten baru dimuat, dan memeriksa apakah tinggi gulir bertambah. Jika tingginya tetap sama, perulangan akan keluar, artinya tidak ada konten lebih lanjut yang akan dimuat.
Pengguliran horizontal
Dalam beberapa kasus, Anda mungkin perlu menggulir secara horizontal, misalnya untuk berinteraksi dengan item dalam tabel lebar. Gunakan skrip berikut untuk menggulir secara horizontal:
driver.execute_script("window.scrollBy(1000, 0);")
Kode ini menggulir halaman 1000 piksel ke kanan. Sesuaikan nilainya tergantung pada kasus penggunaan.
Teknik pengguliran dengan Selenium ini memastikan bahwa semua konten yang diperlukan dimuat dan dapat diakses untuk interaksi atau pengikisan. Metode ini penting untuk navigasi yang efektif dan mengekstraksi data dari situs web dinamis.
Langkah 6: Berinteraksi dengan elemen
Berinteraksi dengan elemen halaman web sering kali melibatkan mengklik tombol atau link dan memasukkan teks ke dalam kolom sebelum membaca isinya.
Selenium menawarkan berbagai strategi untuk menemukan elemen pada halaman menggunakan By kelas dan itu find_element() Dan find_elements() Metode.
Berikut cara menggunakan strategi pencari lokasi ini untuk berinteraksi dengan elemen:
Elemen lokalisasi
Selenium menawarkan berbagai cara untuk menemukan elemen pada halaman web menggunakan find_element() Metode untuk satu elemen dan find_elements() Metode untuk elemen berbeda:
-
Berdasarkan tanda pengenal: Temukan elemen berdasarkan atribut ID uniknya.
driver.find_element(By.ID, "element_id") -
Yaitu: Temukan elemen berdasarkan atribut namanya.
driver.find_element(By.NAME, "element_name") -
Berdasarkan nama kelas: Temukan elemen berdasarkan nama kelas CSSnya.
driver.find_element(By.CLASS_NAME, "element_class") -
Berdasarkan nama tag: Temukan elemen berdasarkan nama tag HTML-nya.
driver.find_element(By.TAG_NAME, "element_tag") -
Menurut teks tautan: Temukan hyperlink berdasarkan teks yang terlihat persis.
driver.find_element(By.LINK_TEXT, "visible_text") -
Menurut sebagian teks tautan: Temukan hyperlink berdasarkan kecocokan sebagian dari teks yang terlihat.
driver.find_element(By.PARTIAL_LINK_TEXT, "partial_text") -
Melalui pemilih CSS: Gunakan pemilih CSS untuk menemukan elemen berdasarkan aturan CSS.
driver.find_element(By.CSS_SELECTOR, "css_selector") -
Melalui XPath: Temukan item menggunakan XPATH mereka. XPath adalah cara ampuh untuk mencari elemen menggunakan ekspresi jalur.
driver.find_element(By.XPATH, "xpath_expression")
Klik pada sebuah elemen
Untuk mengklik suatu item, temukan item tersebut menggunakan salah satu strategi di atas, lalu gunakan click() Metode.
# Example: Clicking a button by ID
button = driver.find_element(By.ID, "button_id")
button.click()
# Example: Clicking a link by Link Text
link = driver.find_element(By.LINK_TEXT, "Click Here")
link.click()
Ketik di kolom teks
Untuk memasukkan teks ke dalam bidang, cari elemen dan gunakan send_keys() Metode.
# Example: Typing into a textbox by Name
textbox = driver.find_element(By.NAME, "username")
textbox.send_keys("your_username")
# Example: Typing into a textbox by XPath
textbox = driver.find_element(By.XPATH, "//input(@name='username')")
textbox.send_keys("your_username")
Mengambil teks dari suatu elemen
Temukan konten teks elemen dan gunakan text Atribut untuk mendapatkan konten teks.
# Example: Retrieving text by Class Name
element = driver.find_element(By.CLASS_NAME, "content")
print(element.text)
# Example: Retrieving text by Tag Name
element = driver.find_element(By.TAG_NAME, "p")
print(element.text)
Ambil nilai atribut
Setelah menemukan item, gunakan get_attribute() Metode untuk mendapatkan nilai atribut, seperti B. URL, dari tag jangkar.
# Example: Getting the href attribute from a link by Tag Name
link = driver.find_element(By.TAG_NAME, "a")
print(link.get_attribute("href"))
# Example: Getting src attribute from an image by CSS Selector
img = driver.find_element(By.CSS_SELECTOR, "img")
print(img.get_attribute("src"))
Anda dapat berinteraksi secara efektif dengan berbagai elemen di halaman web dengan menggunakan strategi pencari lokasi Selenium ini. By Kelas. Baik Anda perlu mengeklik tombol, memasukkan teks ke dalam formulir, mengambil teks, atau mengambil nilai atribut, metode ini akan membantu Anda mengotomatiskan tugas pengikisan web secara efisien.
Langkah 7: Identifikasi honeypot
Honeypots adalah elemen yang sengaja disembunyikan dari pengguna normal namun terlihat oleh bot. Mereka dirancang untuk mendeteksi dan memblokir aktivitas otomatis seperti web scraping. Selenium memungkinkan Anda mendeteksi elemen-elemen ini secara efektif dan menghindari interaksi dengannya.
Anda dapat menggunakan pemilih CSS untuk mengidentifikasi elemen yang tersembunyi dengan gaya seperti ini display: none; atau visibility: hidden;. Selenium find_elements metode dengan By.CSS_SELECTOR berguna untuk tujuan ini:
elements = driver.find_elements(By.CSS_SELECTOR, '(style*="display:none"), (style*="visibility:hidden")')
for element in elements:
if not element.is_displayed():
continue # Skip interacting with honeypot elements
Di sini kami memeriksa apakah elemen tersebut tidak ditampilkan di halaman web is_displayed() Metode. Hal ini memastikan bahwa interaksi hanya terjadi dengan elemen yang dimaksudkan untuk interaksi pengguna, sehingga menghindari potensi honeypots.
Bentuk umum dari honeypot adalah elemen tombol yang disamarkan. Tombol-tombol ini secara visual tersembunyi dari pengguna, namun ada dalam struktur HTML halaman:
Dalam skenario ini tombolnya sengaja disembunyikan. Bot otomatis yang diprogram untuk mengklik semua tombol di halaman dapat berinteraksi dengan tombol tersembunyi ini dan memicu tindakan keamanan di situs web. Namun, pengguna yang sah tidak akan pernah menemukan atau berinteraksi dengan elemen tersembunyi tersebut.
Selenium memungkinkan Anda menghindari jebakan ini secara efektif dengan memeriksa visibilitas elemen sebelum berinteraksi dengannya. Seperti yang telah disebutkan, is_displayed() Metode mengonfirmasi apakah suatu item terlihat oleh pengguna. Inilah cara Anda menerapkan tindakan keamanan ini di skrip Selenium Anda:
from selenium import webdriver
# Set your WebDriver options
chrome_options = webdriver.ChromeOptions()
# Initialize the WebDriver
driver = webdriver.Chrome(options=chrome_options)
# Navigate to a sample website
driver.get("https://example.com")
# Locate the hidden button element
button_element = driver.find_element_by_id("fakeButton")
# Check if the element is displayed
if button_element.is_displayed():
# Element is visible; proceed with interaction
button_element.click()
else:
# Element is likely a honeypot, skip interaction
print("Detected a honeypot element, skipping interaction")
# Close the WebDriver session
driver.quit()
Inilah yang harus Anda ingat saat mengidentifikasi dan menghindari honeypots:
- Selalu gunakan
is_displayed()untuk memeriksa apakah suatu elemen terlihat sebelum berinteraksi dengannya, untuk membedakan antara elemen UI sebenarnya dan jebakan tersembunyi seperti honeypots - Saat mengotomatiskan interaksi (seperti klik atau pengiriman formulir), pastikan skrip Anda menghindari interaksi yang tidak disengaja dengan elemen tersembunyi atau tidak terlihat.
- Saat mengambil data, ikuti aturan situs dan pedoman hukum untuk bertindak etis dan menghindari tindakan keamanan situs.
Dengan memasukkan praktik ini ke dalam skrip Selenium Anda, Anda akan meningkatkan keandalan dan kepatuhan etisnya, melindungi upaya otomatisasi Anda sekaligus menghormati tujuan penggunaan sumber daya web.
Langkah 8: Tunggu hingga elemen dimuat
Situs web dinamis sering kali memuat konten secara asinkron, yang berarti elemen pada laman mungkin tidak muncul hingga laman pertama kali dimuat.
Untuk menghindari kesalahan dalam proses web scraping Anda, penting untuk menunggu hingga elemen ini muncul sebelum berinteraksi dengannya. Selenium WebDriverWait Dan expected_conditions Izinkan kami menunggu hingga kondisi tertentu terpenuhi sebelum melanjutkan.
Dalam contoh ini, saya akan menunjukkan cara menunggu bilah pencarian di beranda Amazon dimuat, melakukan pencarian, dan kemudian mengekstrak ASIN produk Amazon di hasil pencarian.
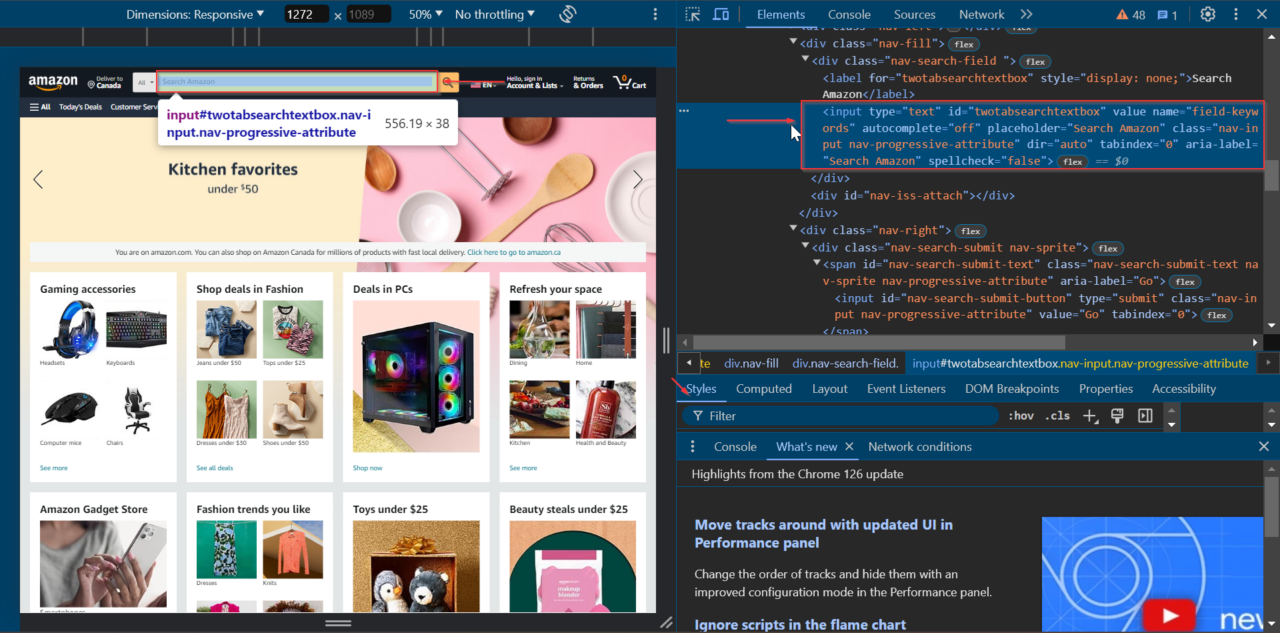
Pertama, kita mencari elemen bilah pencarian di halaman beranda. Arahkan ke Amazon, klik kanan bilah pencarian dan pilih "Periksa" untuk membuka alat pengembang.
Kita dapat melihat bahwa elemen bilah pencarian memiliki ID twotabsearchtextbox.
Mari kita mulai dengan menyiapkan Selenium WebDriver dan menavigasi ke beranda Amazon.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
# Set up the web driver
chrome_options = webdriver.ChromeOptions()
# Uncomment the line below to run Chrome in headless mode
# chrome_options.add_argument("--headless")
driver = webdriver.Chrome(options=chrome_options)
# Open Amazon's homepage
driver.get("https://amazon.com/")
Penggunaan selanjutnya WebDriverWait tunggu hingga item bilah pencarian ada sebelum berinteraksi dengannya. Hal ini memastikan bahwa elemen terisi penuh dan siap untuk berinteraksi.
# Wait for the search bar to be present
search_bar = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "twotabsearchtextbox"))
)
Kemudian masukkan istilah pencarian Anda di bilah pencarian. Untuk melakukan ini, gunakan ini send_keys() dan kirimkan formulir dengan submit() Metode. Dalam contoh ini kami mencari headphones.
# Perform a search for "headphones"
search_bar.send_keys("headphones")
# Submit the search form (press Enter)
search_bar.submit()
Rencanakan untuk menunggu sebentar time.sleep() Metode untuk memastikan halaman hasil pencarian memiliki cukup waktu untuk dimuat.
# Wait for the search results to load
time.sleep(10)
Setelah hasil pencarian dimuat, kami mengekstrak ASIN produk di hasil pencarian. Kami menggunakan BeautifulSoup untuk menganalisis sumber halaman dan mengekstrak data.
from bs4 import BeautifulSoup
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
products = ()
# Extract product ASINs
productsHTML = soup.select('div(data-asin)')
for product in productsHTML:
if product.attrs.get('data-asin'):
products.append(product.attrs('data-asin'))
print(products)
Terakhir, tutup browser dan akhiri sesi WebDriver.
# Quit the WebDriver
driver.quit()
Jika digabungkan, kode lengkapnya terlihat seperti ini:
import time
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# Set up the web driver
chrome_options = webdriver.ChromeOptions()
# Uncomment the line below to run Chrome in headless mode
# chrome_options.add_argument("--headless")
driver = webdriver.Chrome(options=chrome_options)
# Open Amazon's homepage
driver.get("https://amazon.com/")
# Wait for the search bar to be present
search_bar = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "twotabsearchtextbox"))
)
# Perform a search for "headphones"
search_bar.send_keys("headphones")
# Submit the search form (press Enter)
search_bar.submit()
# Wait for the search results to load
time.sleep(10)
# Extract product ASINs
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
products = ()
productsHTML = soup.select('div(data-asin)')
for product in productsHTML:
if product.attrs.get('data-asin'):
products.append(product.attrs('data-asin'))
print(products)
# Quit the WebDriver
driver.quit()
Sekarang Anda dapat menggunakannya secara efektif WebDriverWait untuk memproses elemen dinamis dan memastikan elemen tersebut dimuat sebelum berinteraksi dengannya. Pendekatan ini membuat skrip web scraping Anda lebih andal dan efektif.
