
Go, juga dikenal sebagai Golang, adalah bahasa pemrograman sumber terbuka yang dikembangkan oleh Google. Dengan menghindari konstruksi bahasa yang rumit dan menggunakan sekumpulan kata kunci minimal serta tipe bawaan, Go sangat populer bahkan di kalangan pemula.
Selain itu, Go menyediakan dukungan bawaan untuk konkurensi melalui goroutine dan saluran. Goroutine adalah thread ringan yang memungkinkan eksekusi paralel, sementara saluran menyediakan sarana komunikasi dan sinkronisasi data yang aman antar goroutine. Hal ini mempermudah penulisan program secara bersamaan dan terukur.
Selain kesederhanaannya dan dukungan konkurensi bawaan, Go memiliki banyak perpustakaan dan alat yang memperluas kemampuannya secara signifikan. Sumber daya ini mencakup berbagai bidang termasuk Pengikisan web, dan memungkinkan pengembang mengekstrak dan memproses data secara efisien dari situs web dan sumber online.
Memulai dengan Go
Sebelum kami menjelajahi data selangkah demi selangkah dan menjelajahi berbagai perpustakaan, kami mempersiapkan dan menyiapkan lingkungan kami. Pertama, mari kita instal Git agar kita bisa mendapatkan perpustakaan Go langsung dari GitHub. Unduh dan instal versi yang diperlukan dari situs resminya. Jika Anda seorang pemula dan belum pernah menggunakan Git sebelumnya, kami sarankan untuk membiarkan pengaturan default tidak berubah.
Sekarang saatnya menginstal Go. Untuk melakukan ini, cukup kunjungi situs web resmi Go, unduh file instalasi dan ikuti instruksi selama instalasi.
Untuk memastikan bahwa Anda telah berhasil menginstal Go, Anda dapat menggunakan perintah “go version”:
C:\Scripts>versi go
buka versi go1.20.5 Windows/AMD64
Anda dapat menggunakan editor teks apa pun untuk menulis kode, tetapi lebih baik menggunakan alat khusus untuk penyederhanaan dan penyorotan sintaksis. Kami akan menggunakan Kode Visual Studio.
Setelah menyiapkan lingkungan, mari kita lihat halaman contoh dan perpustakaan Go untuk digores. Kami akan membahas cara menginstal dan membuat scraper sederhana menggunakan perpustakaan ini dan mendemonstrasikan fungsinya.
Inspeksi situs target
Sebelum menggores situs web, penting untuk menganalisis situs web target. Hal ini diperlukan untuk mengetahui secara pasti dimana letak informasi yang kita butuhkan. Kita harus mengetahui tag dan kelas mana yang mengandung elemen yang diperlukan. Misalnya kita bisa di dalam
Halaman sampel
Untuk menganalisis situs example.com, kita perlu memeriksa struktur dan kontennya. Dengan memeriksa kode HTML halaman tersebut, kita dapat mengidentifikasi tag dan kelas yang berisi informasi yang diperlukan. Untuk melakukan ini, buka halaman tersebut dan buka DevTools (tekan F12 atau klik kanan pada layar dan pilih “Inspeksi”).
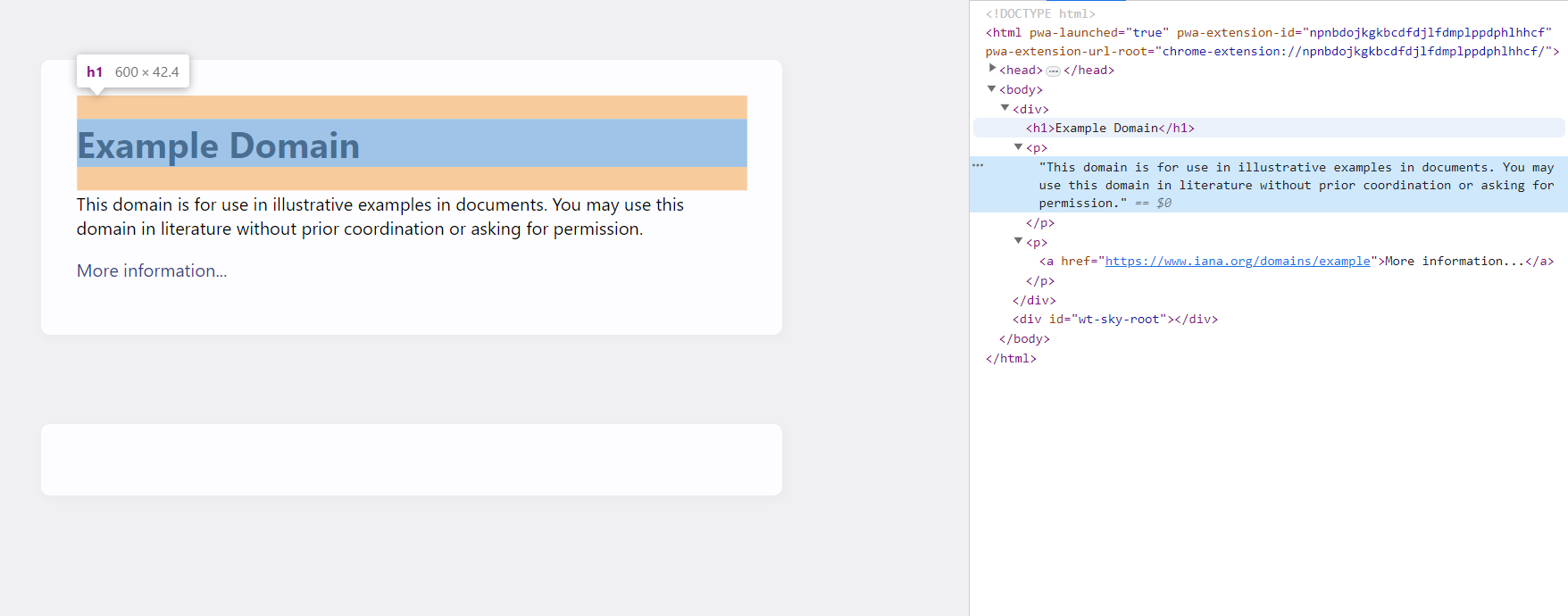
Seperti yang bisa kita lihat, judul halaman ada di tag h1 dan teks lainnya disimpan di tag p. Sekarang kita dapat menggunakan pemilih CSS atau XPATH untuk mengekstrak informasi yang kita inginkan.
Toko contoh
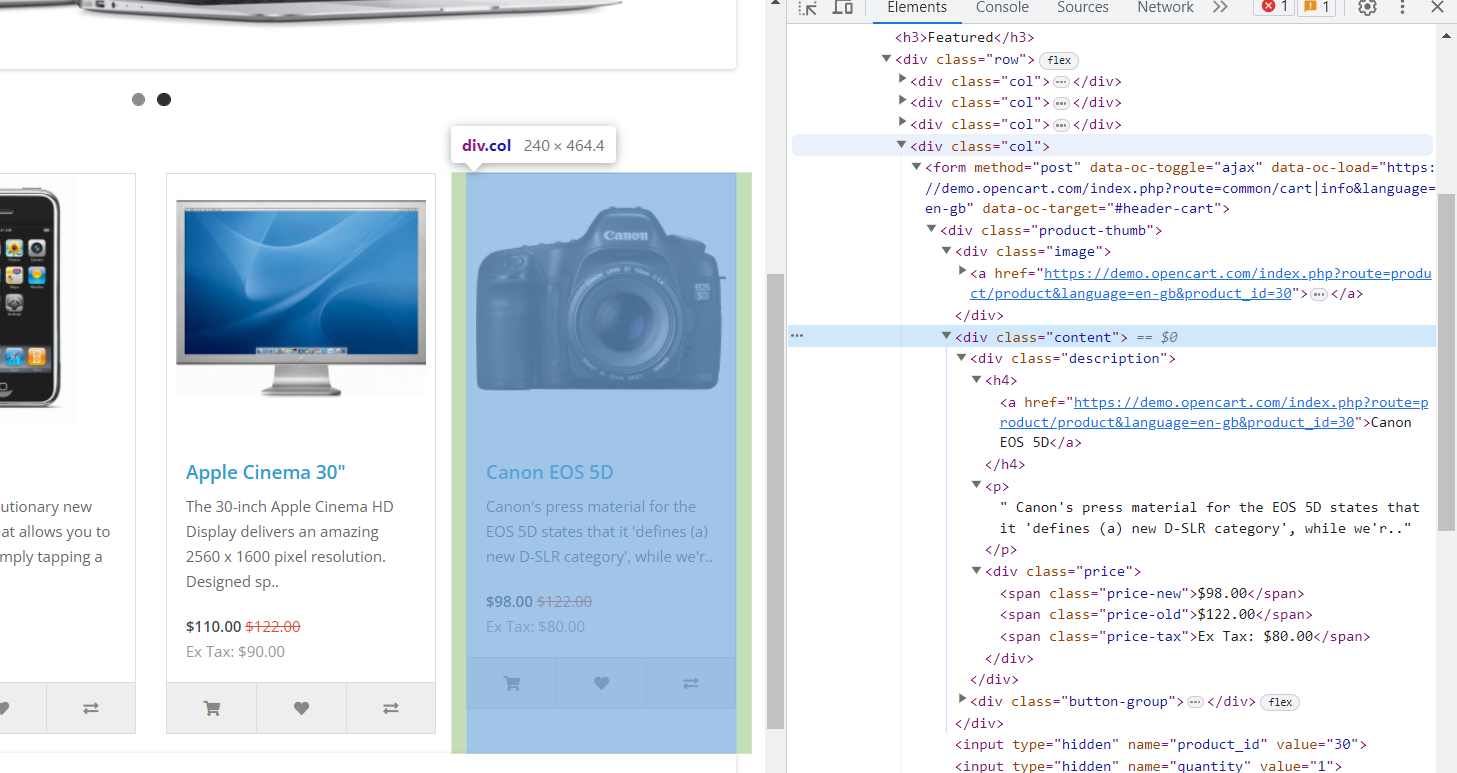
Situs web ini memiliki lebih banyak data dan struktur yang mendekati kenyataan. Setiap elemen memiliki elemen div dengan kelas "col", dan di div ini Anda akan menemukan informasi berikut:
- Gambar berada dalam tag div dengan kelas "gambar" di dalam tag "a" bersarang dengan atribut "href".
- Nama produk ada dalam tag “h4”. Ini juga berisi tautan ke halaman produk dalam tag “a” bersarang dengan atribut “href”.
- Deskripsi produk ada dalam tag “p”.
- Harga ada dalam tag div dengan kelas “harga”. Itu juga memiliki tag bersarang:
- Harga asli di tag "rentang" dengan kelas "harga lama".
- Harga diskon tersebut dalam rentang tag dengan harga kelas-baru.
- Informasi pajak ada dalam tag rentang dengan pajak harga kelas.
Sekarang kita mengetahui struktur kedua situs web yang akan kita jelajahi, kita dapat memilih perpustakaannya.
Perpustakaan Go Web Scraping Terbaik
Go memiliki komunitas pengembang yang berkembang dan aktif. Ia memiliki ekosistem perpustakaan dan kerangka kerja yang kuat yang mencakup berbagai aplikasi termasuk pengembangan web, jaringan, database, dan web scraping. Namun hari ini kita akan fokus pada tiga perpustakaan Go yang populer untuk scraping:
- permintaan;
- kolik;
- Pholkus.
Bergantung pada pustaka yang Anda pilih, Anda dapat menggunakan fungsi permintaan sederhana atau fitur lanjutan seperti rendering halaman dinamis, ekstraksi ekspresi reguler, dan pengikisan terdistribusi.
Untuk membuat web scraping Golang lebih mudah bagi pemula dan memberi mereka contoh serbaguna, selain tiga perpustakaan yang terdaftar, kami juga mendemonstrasikan penggunaan API web scraping kami. Ini memungkinkan Anda mengekstrak data secara otomatis, mengelola penggunaan proxy, memecahkan masalah rendering JavaScript, dan melewati captcha dan blokir.
Dapatkan data dengan API Scrape-It.Cloud
API scraping web Scrape-It.Cloud dengan proxy yang berputar menawarkan beberapa keuntungan besar. Ini membuat pengambilan data dari situs web menjadi lebih mudah karena Anda tidak perlu khawatir tentang proxy. API ini mudah digunakan dan bekerja dengan berbagai bahasa pemrograman seperti Golang, Python atau NodeJS.
Itu dapat menangani situs web yang menggunakan JavaScript, memungkinkan Anda mengekstrak konten dinamis. Fungsi untuk proxy yang berputar membantu Anda tetap anonim dan menghindari pemblokiran. Layanan ini dapat menangani tugas pengikisan kecil dan besar. Paket harga fleksibel; Anda bahkan dapat mencobanya secara gratis. Secara keseluruhan, ini adalah solusi ekstraksi data situs web yang sederhana dan nyaman.
Bersiaplah untuk mengikis
Kami akan menggunakan perpustakaan net/http untuk membuat permintaan HTTP ke API Scrapi-It.Cloud. Ini adalah perpustakaan permintaan yang membantu kami membuat permintaan ke situs web. Untuk menginstal perpustakaan Net/http Anda tidak perlu melakukan sesuatu yang khusus. Ini adalah paket terintegrasi dalam bahasa pemrograman Go. Saat Anda menginstal Go di sistem Anda, pustaka Net/http secara otomatis disertakan. Anda dapat menggunakannya di program Go Anda tanpa langkah instalasi tambahan.
Kami juga memerlukan kunci API, yang akan Anda terima setelah mendaftar ke Scrape-It.Cloud, serta beberapa kredit gratis untuk menggunakan API.
Gunakan contoh
Pertama, mari kita ambil datanya misalnya example.com. Deklarasikan perpustakaan terlebih dahulu:
package main
import (
"encoding/json"
"fmt"
"io/ioutil"
"net/http"
"strings"
)Kami akan menulis semua kode di fungsi utama, jadi mari kita deklarasikan:
func main() { }Sekarang dalam fungsi ini kita perlu mengakses API Scrape-It.Cloud dengan parameter yang diperlukan, mendapatkan respons JSON dengan data dan menampilkan informasi yang diperlukan di layar.
Mari kita nyatakan jenis permintaan dan atur parameternya (isi permintaan):
url := "https://api.scrape-it.cloud/scrape"
method := "POST"
payload := strings.NewReader(`{
"extract_rules": {
"Title": "h1",
"Description": "p"
},
"wait": 0,
"screenshot": true,
"block_resources": false,
"url": "https://example.com/"
}`)
client := &http.Client{}
req, err := http.NewRequest(method, url, payload)
if err != nil {
fmt.Println(err)
return
}
Selain isi permintaan, kami juga mendeklarasikan header permintaan.
req.Header.Add("x-api-key", "YOUR-API-KEY")
req.Header.Add("Content-Type", "application/json")Selanjutnya kita bisa membuat request dan mendapatkan datanya:
res, err := client.Do(req)
if err != nil {
fmt.Println(err)
return
}
defer res.Body.Close()Sekarang kita tinggal mengolah datanya sehingga kita hanya mengekstrak elemen yang ada di (“scrapingResult”) (“extractedData”) (“Judul”) dan (“scrapingResult”) (“extractedData”) (“Deskripsi” ) ) kondisi. dari kode JSON yang kami terima. Untuk memastikan kami menargetkan atribut yang benar, Anda dapat melihat respons JSON di layar atau melihat contoh respons di dokumentasi API kami.
body, err := ioutil.ReadAll(res.Body)
if err != nil {
fmt.Println(err)
return
}
var response map(string)interface{}
err = json.Unmarshal(body, &response)
if err != nil {
fmt.Println(err)
return
}
if response("status") != "ok" {
fmt.Println("Error: Request failed")
return
}
scrapingResult := response("scrapingResult").(map(string)interface{})
extractedData := scrapingResult("extractedData").(map(string)interface{})
Sekarang yang harus kita lakukan adalah menampilkan variabel-variabel ini di layar:
fmt.Println("Title:", extractedData("Title"))
fmt.Println("Description:", extractedData("Description"))Mari kumpulkan data dari situs web kedua untuk memastikan pendekatan ini mudah. Untuk ini kita tidak perlu melakukan perubahan signifikan pada kode kita. Kita perlu mengganti isi permintaan dan menambahkan variabel untuk mengambil data. Kami tidak menampilkan bagian kode yang tetap tidak berubah, tetapi pada akhirnya kami memberikan kode lengkap untuk menggores situs web produk.
Jadi mari kita ubah isi permintaan:
payload := strings.NewReader(`{
"extract_rules": {
"Title":"h4",
"Link":"h4 > a @href",
"Description":"p",
"Old":"span.price-old",
"New":"span.price-new",
"Tax":"span.price-tax",
"Image":".image > a @href"
},
"wait": 0,
"screenshot": true,
"block_resources": false,
"url": "https://demo.opencart.com/"
}`)
Pada akhirnya tambahkan output data baru:
fmt.Println("Titles:", extractedData("Title"))
fmt.Println("Links:", extractedData("Link"))
fmt.Println("Descriptions:", extractedData("Description"))
fmt.Println("Old Prices:", extractedData("Old"))
fmt.Println("New Prices:", extractedData("New"))
fmt.Println("Taxes:", extractedData("Tax"))
fmt.Println("Images:", extractedData("Image"))Ini semua adalah perubahan skrip yang dilakukan. Mari kita jalankan dan dapatkan semua data yang kita butuhkan.
D:\scripts>go run scraper.go
Titles: (MacBook iPhone Apple Cinema 30" Canon EOS 5D)
Links: (https://demo.opencart.com/index.php?route=product/product&language=en-gb&product_id=43 https://demo.opencart.com/index.php?route=product/product&language=en-gb&product_id=40 https://demo.opencart.com/index.php?route=product/product&language=en-gb&product_id=42 https://demo.opencart.com/index.php?route=product/product&language=en-gb&product_id=30)
Descriptions: (Your shopping cart is empty!
Intel Core 2 Duo processor
Powered by an Intel Core 2 Duo processor at speeds up to 2.1..
iPhone is a revolutionary new mobile phone that allows you to make a call by simply tapping a nam..
The 30-inch Apple Cinema HD Display delivers an amazing 2560 x 1600 pixel resolution. Designed sp..
Canon's press material for the EOS 5D states that it 'defines (a) new D-SLR category', while we'r.. Powered By OpenCart Your Store © 2023)
Old Prices: ($122.00 $122.00)
New Prices: ($602.00 $123.20 $110.00 $98.00)
Taxes: (Ex Tax: $500.00 Ex Tax: $101.00 Ex Tax: $90.00 Ex Tax: $80.00)
Images: (https://demo.opencart.com/index.php?route=product/product&language=en-gb&product_id=43 https://demo.opencart.com/index.php?route=product/product&language=en-gb&product_id=40 https://demo.opencart.com/index.php?route=product/product&language=en-gb&product_id=42 https://demo.opencart.com/index.php?route=product/product&language=en-gb&product_id=30)Kode lengkap:
package main
import (
"encoding/json"
"fmt"
"io/ioutil"
"net/http"
"strings"
)
func main() {
url := "https://api.scrape-it.cloud/scrape"
method := "POST"
payload := strings.NewReader(`{
"extract_rules": {
"Title":"h4",
"Link":"h4 > a @href",
"Description":"p",
"Old":"span.price-old",
"New":"span.price-new",
"Tax":"span.price-tax",
"Image":".image > a @href"
},
"wait": 0,
"screenshot": true,
"block_resources": false,
"url": "https://demo.opencart.com/"
}`)
client := &http.Client{}
req, err := http.NewRequest(method, url, payload)
if err != nil {
fmt.Println(err)
return
}
req.Header.Add("x-api-key", "1cb2a4a1-a569-423e-835e-07c3b1308bfe")
req.Header.Add("Content-Type", "application/json")
res, err := client.Do(req)
if err != nil {
fmt.Println(err)
return
}
defer res.Body.Close()
body, err := ioutil.ReadAll(res.Body)
if err != nil {
fmt.Println(err)
return
}
var response map(string)interface{}
err = json.Unmarshal(body, &response)
if err != nil {
fmt.Println(err)
return
}
if response("status") != "ok" {
fmt.Println("Error: Request failed")
return
}
scrapingResult := response("scrapingResult").(map(string)interface{})
extractedData := scrapingResult("extractedData").(map(string)interface{})
fmt.Println("Titles:", extractedData("Title"))
fmt.Println("Links:", extractedData("Link"))
fmt.Println("Descriptions:", extractedData("Description"))
fmt.Println("Old Prices:", extractedData("Old"))
fmt.Println("New Prices:", extractedData("New"))
fmt.Println("Taxes:", extractedData("Tax"))
fmt.Println("Images:", extractedData("Image"))
}Seperti yang Anda lihat, ini cukup sederhana dan bahkan pemula pun dapat memodifikasi contoh ini untuk keperluan mereka sendiri.
Penguraian mudah dengan GoQuery
Goquery adalah perpustakaan Go populer yang menyediakan cara mudah untuk mengurai dokumen HTML atau XML dan mengekstrak data menggunakan pemilih CSS. Hal ini didasarkan pada jQuery, perpustakaan JavaScript yang banyak digunakan untuk mengedit dan mencari dokumen HTML.
Instal perpustakaan GoQuery
Untuk menggunakan perpustakaan GoQuery, kita perlu menginstalnya terlebih dahulu. Anda dapat melakukan ini dengan menggunakan perintah berikut di Terminal:
go get github.com/PuerkitoBio/goqueryDan sekarang Anda dapat menggunakannya dalam proyek Anda.
Gunakan contoh
Seperti pada contoh sebelumnya, mari kita mulai dengan menyertakan perpustakaan yang diperlukan dan mendeklarasikan fungsi utama:
package main
import (
"fmt"
"log"
"net/http"
"github.com/PuerkitoBio/goquery"
)
func main() { }Mari kita membuat permintaan dan menyimpan data yang kita peroleh dalam sebuah variabel. Penting juga untuk tidak melupakan pemeriksaan kesalahan.
url := "https://example.com"
resp, err := http.Get(url)
if err != nil {
log.Fatal(err)
}
defer resp.Body.Close()
doc, err := goquery.NewDocumentFromReader(resp.Body)
if err != nil {
log.Fatal(err)
}Sekarang mari kita cari data yang diinginkan menggunakan pemilih CSS menggunakan fungsi bawaan perpustakaan GoQuery.
doc.Find("h1").Each(func(_ int, s *goquery.Selection) {
fmt.Println(s.Text())
})Hasilnya, kami mendapatkan judul halaman.
D:\scripts>go run scraper.go
Example DomainKode lengkap:
package main
import (
"fmt"
"log"
"net/http"
"github.com/PuerkitoBio/goquery"
)
func main() {
url := "https://example.com"
resp, err := http.Get(url)
if err != nil {
log.Fatal(err)
}
defer resp.Body.Close()
doc, err := goquery.NewDocumentFromReader(resp.Body)
if err != nil {
log.Fatal(err)
}
doc.Find("h1").Each(func(_ int, s *goquery.Selection) {
fmt.Println(s.Text())
})
}Kita telah membahas pengikisan situs web example.com menggunakan API dan pustaka, namun karena contoh tersebut terlalu sederhana, kami tidak akan membahasnya lagi. Mari kita menulis scraper untuk website yang menjual produk.
Deklarasi perpustakaan, seperti kebanyakan skrip, tetap tidak berubah. Yang perlu kita lakukan hanyalah mengganti link ke halaman dan penyeleksi untuk mendapatkan data yang diperlukan. Pertama, mari kita ubah link ke halaman tersebut:
url := "https://demo.opencart.com/" Kita perlu memeriksa setiap produk dan mengekstrak tag yang diperlukan dari masing-masing produk. Untuk kenyamanan, kami menyimpan data dalam variabel dan menampilkannya di layar.
doc.Find("div.col").Each(func(_ int, s *goquery.Selection) {
image := s.Find(".image a").AttrOr("href", "")
productName := s.Find("h4 a").Text()
productLink := s.Find("h4 a").AttrOr("href", "")
description := s.Find("p").Text()
oldPrice := s.Find(".price-old").Text()
newPrice := s.Find(".price-new").Text()
tax := s.Find(".price-tax").Text()
fmt.Println("Image:", image)
fmt.Println("Product Name:", productName)
fmt.Println("Product Link:", productLink)
fmt.Println("Description:", description)
fmt.Println("Old Price:", oldPrice)
fmt.Println("New Price:", newPrice)
fmt.Println("Tax:", tax)
fmt.Println()
})Skrip menampilkan semua produk dan meninggalkan baris kosong di antara produk tersebut untuk kenyamanan. Berikut adalah contoh output dari salah satu elemen:
Image: https://demo.opencart.com/index.php?route=product/product&language=en-gb&product_id=30
Product Name: Canon EOS 5D
Product Link: https://demo.opencart.com/index.php?route=product/product&language=en-gb&product_id=30
Description:
Canon's press material for the EOS 5D states that it 'defines (a) new D-SLR category', while we'r..
Old Price: $122.00
New Price: $98.00
Tax: Ex Tax: $80.00Seperti yang Anda lihat, membuat skrip scraping di Go menggunakan perpustakaan GoQuery adalah tugas yang relatif sederhana.
Namun, perpustakaan GoQuery memiliki beberapa kekurangan yang mungkin memerlukan penggunaan perpustakaan lain yang lebih fungsional. Salah satu kelemahannya adalah GoQuery hanya mendukung sejumlah pemilih CSS yang terbatas, yang dapat membatasi pilihan Anda saat mengekstraksi data dari dokumen HTML.
Selain itu, GoQuery hanya berfungsi dengan kode HTML statis. Jika laman landas Anda menggunakan JavaScript dinamis untuk membuat atau mengubah konten, GoQuery tidak dapat memproses konten tersebut karena tidak memiliki mesin JavaScript bawaan.
Jadi ayo pergi ke perpustakaan terdekat.
Mengikis data dinamis dengan Colly
Pustaka Colly adalah alat populer lainnya untuk menyalin halaman web dalam bahasa Go. Ini mendukung berbagai fitur seperti menavigasi halaman, mengekstraksi data, menangani kesalahan, bekerja dengan formulir, dan banyak lagi.
Selain itu, Colly mengizinkan permintaan situs web dieksekusi secara asinkron. Ini berarti Anda dapat memindai dan memproses beberapa halaman sekaligus, meningkatkan kinerja dan mengurangi waktu pengikisan.
Selain itu, perpustakaan Colly secara efektif mengelola JavaScript pada halaman dengan kemampuan browser tanpa kepala. Ini juga menyediakan metode yang mudah digunakan untuk navigasi halaman, mengikuti tautan, pengiriman formulir, dan berbagai interaksi situs web lainnya.
Instal perpustakaan Colly
Dulu, Colly menggunakan PhantomJS untuk menangani JavaScript di halaman web. Namun, mulai versi 2.0, Colly beralih menggunakan perpustakaan Go standar untuk menangani JavaScript.
Untuk menggunakan Colly kita hanya perlu menginstal perpustakaan Colly:
go get -u github.com/gocolly/colly/v2Sekarang kita bisa menulis scraper menggunakan Colly.
Gunakan contoh
Seperti yang disebutkan, kami tidak lagi menggunakan example.com. Jadi mari kita mulai langsung dengan mengambil halaman produk dari toko online percobaan. Pertama, mari kita deklarasikan perpustakaan, tentukan alamat situs web dan buat kolektor yang akan digunakan untuk navigasi dan pengumpulan data dari situs web.
package main
import (
"fmt"
"log"
"github.com/gocolly/colly/v2"
)
func main() {
url := "https://demo.opencart.com/"
c := colly.NewCollector()
}
Selanjutnya, kita mendefinisikan event handler untuk berbagai elemen pada halaman menggunakan metode OnHTML. Dalam penangan ini kita menentukan data mana yang perlu kita ekstrak dari elemen HTML terkait.
c.OnHTML("div.col", func(e *colly.HTMLElement) {
image := e.ChildAttr("div.image a", "href")
productName := e.ChildText("h4 a")
productLink := e.ChildAttr("h4 a", "href")
description := e.ChildText("p")
oldPrice := e.ChildText(".price-old")
newPrice := e.ChildText(".price-new")
tax := e.ChildText(".price-tax")
fmt.Println("Image:", image)
fmt.Println("Product Name:", productName)
fmt.Println("Product Link:", productLink)
fmt.Println("Description:", description)
fmt.Println("Old Price:", oldPrice)
fmt.Println("New Price:", newPrice)
fmt.Println("Tax:", tax)
fmt.Println()
})
Setelah menentukan penangannya, kami menggunakan fungsi panggilan balik untuk membiarkan kolektor menavigasi ke URL. Pada titik ini, kolektor mengunjungi halaman tersebut, memicu penangan yang relevan, dan mengekstrak data.
err := c.Visit(url)
if err != nil {
log.Fatal(err)
}Ini memberi kita hasil yang sama seperti menggunakan perpustakaan GoQuery, tetapi dengan kecepatan dan fungsionalitas yang lebih tinggi. Namun, Colly adalah perpustakaan yang kuat dan oleh karena itu sedikit lebih kompleks daripada perpustakaan sederhana seperti GoQuery, yang lebih cocok untuk mengurai situs web sederhana.
Pengikisan fungsional dengan Pholcus Framework
Kerangka kerja Pholcus (juga dikenal sebagai “Pholcus WebCrawler”) adalah kerangka web scraping serbaguna yang dibuat menggunakan bahasa pemrograman Go. Tujuannya adalah untuk menyederhanakan pembuatan dan pengelolaan web scraper.
Pholcus menawarkan seperangkat alat lengkap untuk mengekstraksi data dari halaman web. Ini mendukung teknik seperti ekspresi reguler, XPath dan pemilih CSS. Selain itu, kerangka kerja ini menawarkan kemampuan untuk menggunakan server proxy yang dapat membantu menghapus situs web dengan batasan IP atau memastikan anonimitas.
Instal Kerangka Pholcus
Untuk menginstal Pholcus dan dependensinya, Anda dapat menggunakan perintah berikut di Command Prompt:
go get -u github.com/henrylee2cn/pholcusSetelah terinstal, Anda dapat mengimpor perpustakaan dan menggunakannya dalam skrip Anda.
Gunakan contoh
Penggunaan framework ini sangat mirip dengan penggunaan perpustakaan Colly. Jadi jika Anda pernah melihat contoh sebelumnya, Anda tidak akan kesulitan menulis scraper atau crawler Go serupa menggunakan Pholcus.
Pertama, kita mengimpor perpustakaan yang diperlukan dan membuat fungsi utama:
package main
import (
"fmt"
"github.com/henrylee2cn/pholcus/app"
"github.com/henrylee2cn/pholcus/logs"
)
func main() { }Sekarang mari kita atur parameter untuk tugas tersebut, seperti URL dasar yang akan di-scrap:
task := app.NewTask()
task.SetBaseUrls("https://demo.opencart.com/")Selanjutnya, kita membuat kolektor dan menentukan penangan untuk elemen HTML yang ingin kita ekstrak. Di setiap penangan kami mengambil data spesifik yang kami perlukan:
collector := app.NewCollector()
collector.OnHTML("div.col", func(element *app.HTMLElement) {
image := element.ChildAttr(".image a", "href")
productName := element.ChildText("h4 a")
productLink := element.ChildAttr("h4 a", "href")
description := element.ChildText("p")
oldPrice := element.ChildText(".price-old")
newPrice := element.ChildText(".price-new")
tax := element.ChildText(".price-tax")
fmt.Println("Image:", image)
fmt.Println("Product Name:", productName)
fmt.Println("Product Link:", productLink)
fmt.Println("Description:", description)
fmt.Println("Old Price:", oldPrice)
fmt.Println("New Price:", newPrice)
fmt.Println("Tax:", tax)
fmt.Println()
})Setelah tugas dan kolektor disiapkan, kami memulai eksekusi tugas menggunakan fungsi app.Run(task). Tugas ini memicu permintaan ke URL tertentu dan memproses respons yang diterima sesuai dengan penangan yang ditentukan.
task.Collector(collector)
if err := app.Run(task); err != nil {
logs.Log.Error(err)
}
Dengan cara ini kami mendapatkan data yang sama tetapi menggunakan alat baru. Sayangnya, menggunakan kerangka kerja ini bisa jadi sangat menantang bagi pemula karena kerangka ini berisi lebih sedikit contoh, dokumentasi yang kurang mendetail, dan komunitas yang jauh lebih kecil dibandingkan GoQuery atau Colly.
Penyimpanan dan pemrosesan data
Untuk melengkapi contoh ini, mari kita periksa cara menyimpan data yang diambil dalam file CSV. Kami akan menggunakan skrip yang kami tulis sebagai contoh penggunaan perpustakaan Colly sebagai titik awal. Namun, karena kami tidak perlu menampilkan data yang diambil di layar, kami menghapus perintah keluaran. Sebagai gantinya, kami menambahkan variabel ke mana kami menulis data kami baris demi baris untuk kemudian ditulis ke file.
package main
import (
"encoding/csv"
"fmt"
"log"
"os"
"github.com/gocolly/colly/v2"
)
func main() {
url := "https://demo.opencart.com/"
c := colly.NewCollector()
var data ()()string
c.OnHTML("div.col", func(e *colly.HTMLElement) {
image := e.ChildAttr("div.image a", "href")
productName := e.ChildText("h4 a")
productLink := e.ChildAttr("h4 a", "href")
description := e.ChildText("p")
oldPrice := e.ChildText(".price-old")
newPrice := e.ChildText(".price-new")
tax := e.ChildText(".price-tax")
data = append(data, ()string{image, productName, productLink, description, oldPrice, newPrice, tax})
})
err := c.Visit(url)
if err != nil {
log.Fatal(err)
}
Buat file CSV dan setel pemisah ke “;”. Kami juga menentukan nama kolom dan menyimpan data dari variabel ke file.
file, err := os.Create("data.csv")
if err != nil {
log.Fatal(err)
}
defer file.Close()
writer := csv.NewWriter(file)
writer.Comma=";"
defer writer.Flush()
header := ()string{"Image", "Product Name", "Product Link", "Description", "Old Price", "New Price", "Tax"}
err = writer.Write(header)
if err != nil {
log.Fatal(err)
}
err = writer.WriteAll(data)
if err != nil {
log.Fatal(err)
}
Setelah skrip dijalankan, kita akan mendapatkan file CSV yang akan disimpan di folder yang sama dengan skrip. File ini berisi semua data yang dikumpulkan:

Biasanya pada fase ini selain menyimpan, kita juga mengolah data untuk menghilangkan sel-sel kosong, data yang salah, atau simbol yang tidak diperlukan. Ini disebut pemrosesan dan pembersihan data. Biasanya, kualitas data keluaran serta keakuratan dan keberhasilan analisis berdasarkan data tersebut bergantung pada hal ini.
Hal ini sangat penting bagi mereka yang bekerja dengan data dalam jumlah besar atau melakukan analisis untuk membuat keputusan penting. Data yang bersih dan akurat memungkinkan hasil yang lebih andal dan keputusan yang lebih tepat.
Praktik dan tip terbaik
Mengikuti aturan khusus saat web scraping penting untuk membuatnya lebih mudah dan aman. Sebaiknya juga menggunakan sumber daya pada waktu yang paling tidak sibuk untuk menghindari kelebihan beban, karena sumber daya tersebut mungkin tidak mampu menangani lalu lintas padat dan bisa gagal.
Gunakan fungsi Go secara efektif
Gunakan nama bermakna yang secara akurat menggambarkan tujuan variabel, fungsi, dan tipe. Hal ini meningkatkan keterbacaan kode dan memudahkan orang lain memahami kode Anda.
Selain itu, gunakan goroutine dan saluran untuk mencapai konkurensi. Gunakan mereka untuk menulis program yang efisien dan paralel.
Atur kode Anda ke dalam paket yang dapat digunakan kembali untuk meningkatkan modularitas kode dan memfasilitasi penggunaan kembali.
Gunakan perpustakaan yang terdokumentasi dengan baik
Secara umum, semakin baik dokumentasinya, semakin besar komunitas pengguna perpustakaan tersebut. Ini berarti Anda selalu dapat menemukan kasus penggunaan untuk fitur yang Anda perlukan dan dukungan dari pengguna sebenarnya ketika Anda menghadapi masalah yang tidak dapat Anda selesaikan sendiri.
Ikuti aturan untuk pengikisan yang efisien
Jika Anda tidak mengikuti aturan tertentu, masalah mungkin timbul, seperti: B. bahwa IP Anda diblokir oleh sumber daya atau captcha perlu diselesaikan. Oleh karena itu, penting untuk mengikuti beberapa aturan. Misalnya, berikan interval kecil antar permintaan, gunakan agen pengguna, hindari pengambilan data dalam jumlah besar, dan pertimbangkan untuk menggunakan proxy.
Namun, di sisi lain, semua masalah ini dapat diselesaikan dengan menggunakan API web scraping, seperti Google SERP API untuk menggores hasil pencarian Google, yang mengatasi tantangan melewati blok dalam scraping.
Kesimpulan dan temuan
Golang adalah bahasa pemrograman yang kuat dan ramah bagi pemula yang dikembangkan oleh Google. Kesederhanaannya, dukungan konkurensi bawaan, dan koleksi perpustakaan yang luas menjadikannya pilihan yang sangat baik untuk tugas web scraping.
Dengan bantuan perpustakaan populer seperti Goquery, Colly, Pholcus dan Scrape-It.Cloud API serta tutorial kami, pengembang dapat dengan mudah mengekstrak dan memproses data dari situs web. Baik Anda seorang pemula atau pengembang berpengalaman, Go menawarkan lingkungan yang mulus dan efisien untuk proyek web scraping.
