
Amazon, salah satu pasar online terbesar untuk membeli dan menjual barang, memiliki harta karun berupa informasi yang berharga bagi para peneliti, analis bisnis, dan pengusaha. Namun mengakses data di Amazon, seperti banyak situs web lainnya, dapat menjadi suatu tantangan. Ini melibatkan analisis data dan menemukan cara terbaik untuk mengekstraknya.
Pada artikel ini, kita akan mengeksplorasi berbagai metode pengumpulan data dari situs web Amazon menggunakan Python. Kita akan mulai dengan memeriksa struktur halaman produk Amazon dan menyimpulkan dengan membuat alat otomatis untuk ekstraksi data web.
Kami juga akan membahas tantangan yang mungkin Anda hadapi saat mengumpulkan data di Amazon dan memberikan tips praktis untuk mengatasinya. Kami mengeksplorasi teknik untuk menghindari pemblokiran alamat IP, menggunakan API untuk mengumpulkan data, dan memberikan contoh kode dan alat untuk membantu Anda mengumpulkan data yang Anda perlukan secara efisien.
Analisis halaman produk Amazon
Amazon adalah pasar yang besar dan terkenal. Pemrosesan data yang dihasilkan dapat memakan waktu, namun dapat dilakukan secara otomatis. Sebelum kita mulai mengembangkan scraper Amazon dengan Python, mari kita periksa struktur halaman produk.
Elemen halaman
Setiap halaman produk Amazon berisi banyak informasi, beberapa di antaranya khusus untuk kategori tertentu. Namun, kami hanya mengekstrak informasi dari elemen yang umum di semua halaman produk.
Mari kita lihat halaman produk dan identifikasi elemen yang ingin kita hapus:
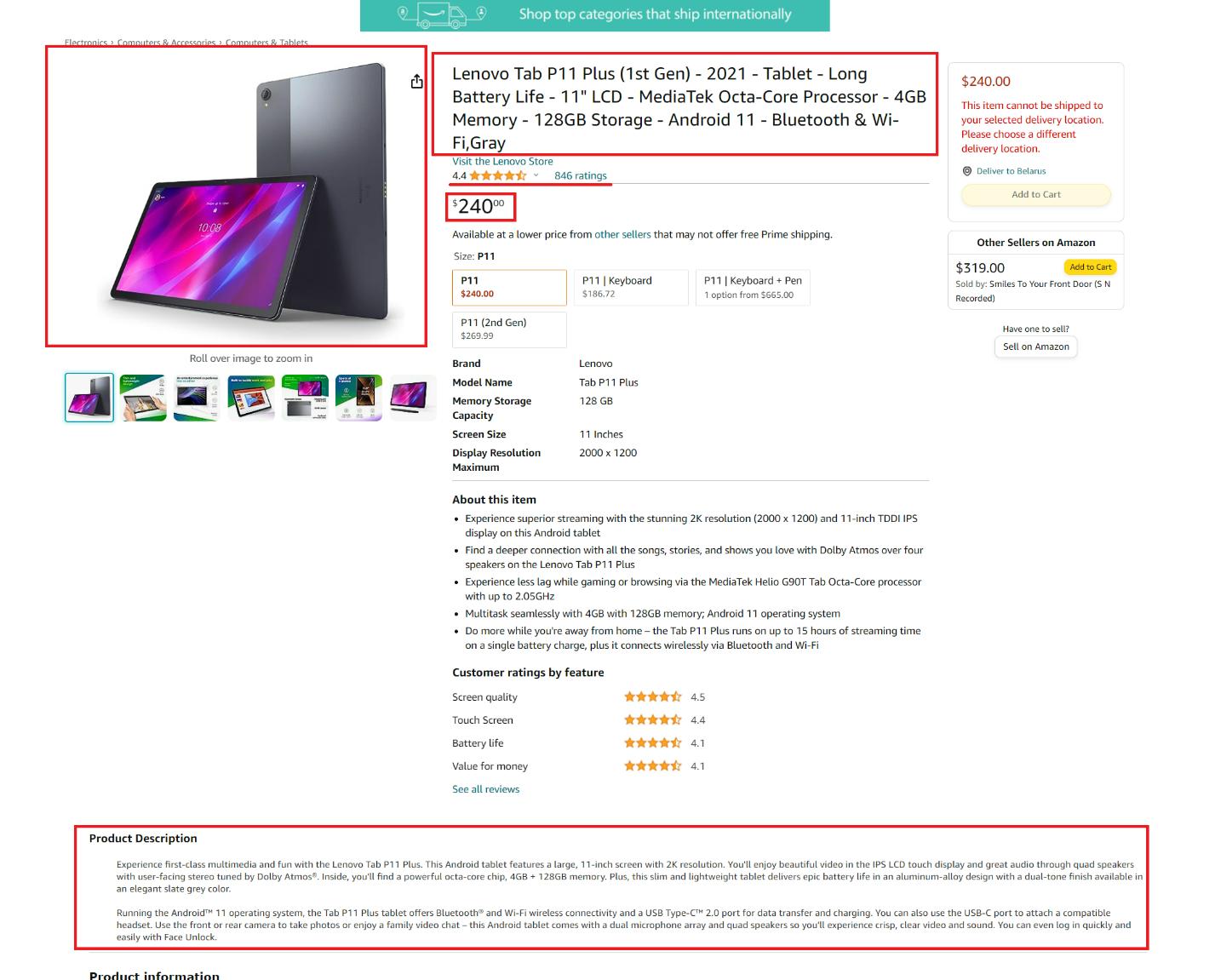
Di sini kita dapat menyoroti elemen-elemen berikut:
- Judul atau nama produk.
- Harga produk.
- Deskripsi umum produk.
- Tautan ke gambar produk.
- Ulasan produk.
- Jumlah ulasan untuk produk.
Elemen-elemen ini umum untuk semua kategori produk dan dapat diekstraksi menggunakan scraper. Jika halaman berisi elemen khusus kategori tambahan, nanti Anda dapat menambahkan kode untuk mengekstraknya sendiri.
Dapatkan halaman HTML
Sebelum kita melanjutkan memproses halaman dan mengambil data tertentu, mari kita tulis kueri sederhana untuk mengambil seluruh halaman dan menampilkan data tersebut. Untuk melakukan ini, buat file baru dengan *.py Perluas dan impor perpustakaan Permintaan:
import requestsUntuk memudahkan kita nantinya, mari kita letakkan link ke halaman tersebut dalam sebuah variabel:
url="https://www.amazon.com/Lenovo-Tab-P11-Plus-1st/dp/B09B17DVYR/ref=sr_1_2?qid=1695021332&rnid=16225007011&s=computers-intl-ship&sr=1-2&th=1"Sekarang kita perlu mengatur header untuk permintaan kita. Ini tidak diperlukan untuk mengirimkan permintaan itu sendiri, tetapi Amazon tidak akan memberi Anda konten halaman jika Anda tidak menyediakannya. Karena Amazon tidak mau berbagi data dengan bot dan program, Anda perlu memanusiakan skrip Anda untuk mendapatkan datanya. Salah satu cara untuk melakukan ini adalah dengan menggunakan header:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36'
}Sekarang kita dapat menjalankan query dan mencetak data jika berhasil atau mencetak kesalahan jika gagal:
response = requests.get(url, headers=headers)
if response.status_code == 200:
print (response.text)
else:
print(str(response.status_code)+' - Error loading the page')Metode sederhana ini memungkinkan Anda mengumpulkan data dari hampir semua situs web. Meskipun metode ini membuat skrip lebih manusiawi, metode ini mungkin kurang dapat diandalkan. Untuk benar-benar meniru tindakan manusia, Anda memerlukan browser dan perpustakaan tanpa kepala seperti Pyppeteer atau Selenium.
Namun, karena ini mungkin sulit bagi pemula, kami tidak akan membahasnya di sini. Sebagai gantinya, kami akan membahas bagaimana Anda dapat menghindari semua kerumitan dengan menggunakan API web scraping nanti di artikel ini.
Mengikis detail produk Amazon menggunakan pustaka Python
Sekarang setelah kita memiliki konten halaman, kita dapat menganalisisnya dan mendapatkan elemen spesifik yang telah kita diskusikan sebelumnya. Untuk ini kita memerlukan perpustakaan BeautifulSoup, jadi kita mengimpornya dan kemudian mengurai seluruh halaman untuk mengekstrak elemen halaman tertentu menggunakan pemilih CSS-nya.
import requests
from bs4 import BeautifulSoup
url="https://www.amazon.com/Lenovo-Tab-P11-Plus-1st/dp/B09B17DVYR/ref=sr_1_2?qid=1695021332&rnid=16225007011&s=computers-intl-ship&sr=1-2&th=1"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# Extract data here
else:
print(str(response.status_code)+' - Error loading the page')Sekarang mari kita lihat setiap elemen yang kita perlukan dan tambahkan ekstraksinya ke kode kita.
Nama Produk
Pertama, dapatkan judul produk. Untuk melakukan ini, buka halaman produk dan buka DevTools (F12 atau klik kanan pada layar dan pilih “Inspeksi”). Kemudian pilih nama produk pada halaman tersebut dan lihat bagian kode mana yang menjelaskannya.
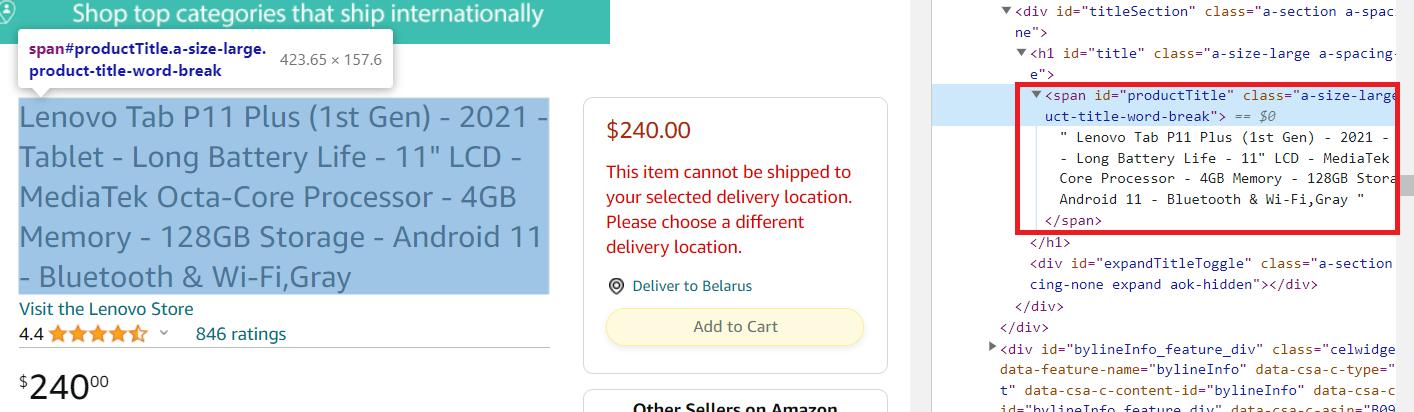
Seperti yang bisa kita lihat, elemen ini ada di dalam span Tandai dengan pengenal unik productTitle. Jadi kita bisa mengekstraknya menggunakan kode berikut:
title_element = soup.find('span', id='productTitle')
title = title_element.get_text()Namun, halaman tersebut mungkin kembali dengan kesalahan. Dalam hal ini, jika item tidak ditemukan, kita akan mendapatkan kesalahan dan skrip kita akan berhenti bekerja. Mari kita modifikasi sedikit baris kedua untuk memberikan nilai tergantung pada keberadaannya:
title = title_element.get_text(strip=True) if title_element else 'Title not found'Sekarang Anda dapat melihat data yang diekstraksi di layar:
print(f'Title: {title}')Sekarang mari kita beralih ke elemen berikutnya.
Gambar produk
Kami akan menghapus tautan gambar dari pratinjau. Tidak akan ada gambar beresolusi tinggi, tetapi perpustakaan kami bagus untuk pemula dan tidak cocok untuk mengekstrak informasi dari tag meta.
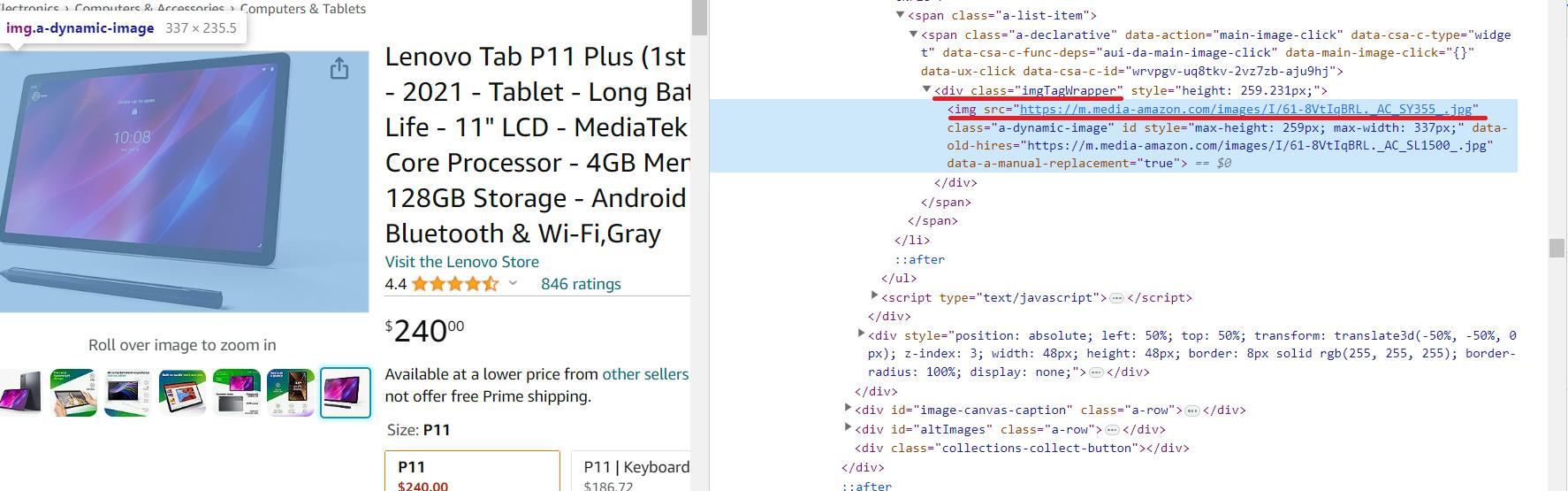
Tautan ke gambar produk resolusi tinggi ada di dalamnya img hari div elemen dengan id=imgTagWrapperId. Berbeda dengan elemen lainnya, tautan ke gambar produk tidak disimpan sebagai teks dalam tag, tetapi sebagai atribut dari tag. Oleh karena itu, kode untuk scraping akan sedikit berbeda.
image_element = soup.find('div', id='imgTagWrapperId')
if image_element:
image_url = image_element.find('img')('src')
else:
image_url="Image link not found"Dan kemudian tampilkan data di layar:
print(f'Image link: {image_url}')Walaupun untuk mendapatkan gambarnya sedikit berbeda, namun caranya juga cukup mudah.
Deskripsi Produk
Deskripsi produk adalah informasi penting dan berguna. Kategori produk yang berbeda mungkin memiliki deskripsi dan fitur tambahan, namun ini bersifat sementara, dinamis dan bervariasi dari satu kategori ke kategori lainnya. Oleh karena itu, kami hanya menerima gambaran umum produk yang ada di semua halaman produk.
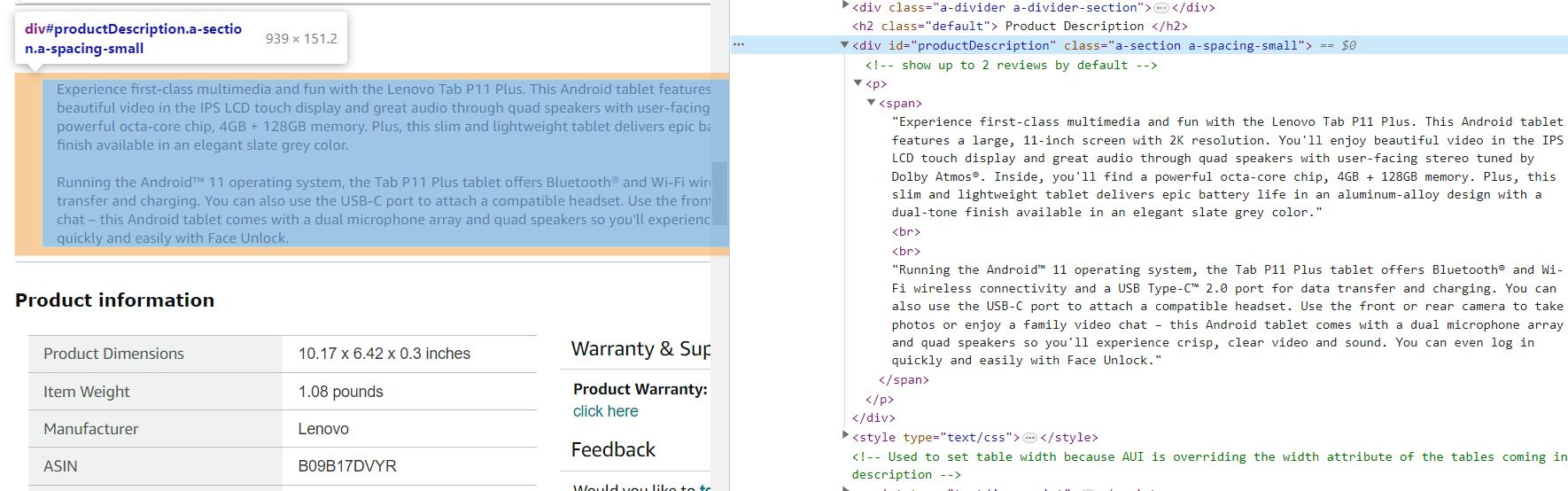
Seperti yang bisa kita lihat, deskripsi produk ada di div Elemen dengan pengidentifikasi unik productDescription:
description_element = soup.find('div', id='productDescription')
description = description_element.get_text() if description_element else 'Description not found'Menampilkan informasi di layar sama:
print(f'Description: {description}')Pada beberapa halaman, deskripsi mungkin memiliki tag yang berbeda atau mungkin tidak dikirimkan sama sekali karena ditampilkan secara dinamis setelah seluruh halaman dimuat. Ini juga harus diperhitungkan saat mengikis.
Harga produk
Beberapa item di Amazon mungkin memiliki beberapa harga dan label serta nilainya mungkin berbeda berdasarkan kategori. Namun, harga umum produk ditampilkan secara default di semua halaman. Jadi itulah yang akan kita hapus.
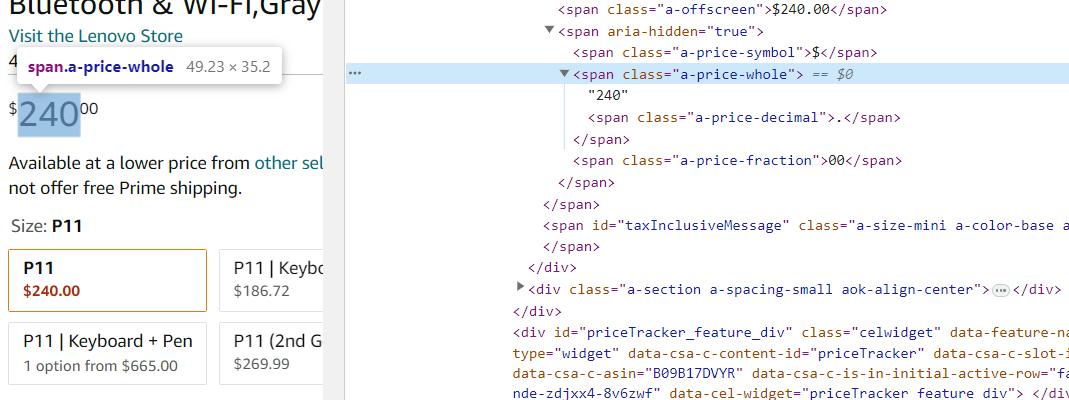
Harga produk ada di span Elemen dengan kelas a-price-whole. Mari kita dapatkan data ini menggunakan BeautifulSoup:
price_element = soup.find('span', class_='a-price-whole')
price = price_element.get_text(strip=True) if price_element else 'Price not found'Untuk keluaran gunakan cetak:
print(f'Price: {price}')Dengan pendekatan ini, Anda menangkap harga sebenarnya dari halaman produk dan menerima data dalam bentuk angka tanpa menentukan mata uang. Jika Anda perlu mengekstrak harga beserta spesifikasi mata uang, gunakan pemilih lain yang lebih umum.
Ulasan dan peringkat
Kami akan melihat rating dan review bersama-sama karena saling terkait satu sama lain. Namun, karena keduanya merupakan elemen yang berbeda, kami akan mengekstraknya menggunakan penyeleksi yang berbeda.
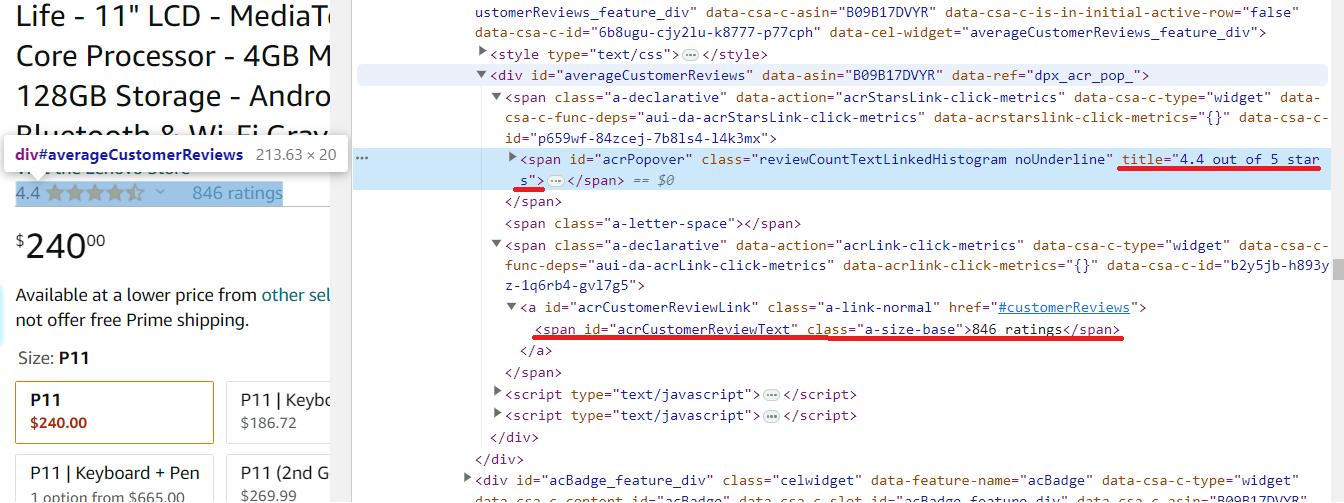
Review produk sudah masuk span Elemen dengan kelas reviewCountTextLinkedHistogramdan nilainya tersedia melalui title Atribut. Anda dapat menemukan jumlah ulasan produk di span Elemen dengan pengidentifikasi unik acrCustomerReviewText.
# Extract the product rating
rating_element = soup.find('span', class_='reviewCountTextLinkedHistogram')
rating = rating_element('title') if rating_element else 'Rating not found'
# Extract the number of reviews
reviews_element = soup.find('span', id='acrCustomerReviewText')
reviews = reviews_element.get_text(strip=True) if reviews_element else 'Number of reviews not found'Dan kemudian tampilkan data ini di layar:
print(f'Rating: {rating}')
print(f'Number of reviews: {reviews}')Sekarang kita telah mengumpulkan semua data yang diperlukan, mari tambahkan simpanan ke file CSV dan lihat skrip yang dihasilkan.
Kode lengkap dengan penyimpanan data
Agar dapat bekerja secara bebas dengan file CSV, kami memerlukannya csv Perpustakaan. Impor ke dalam skrip ::
import csvSekarang gunakan untuk menyimpan semua data yang dikumpulkan setelah eksekusi:
with open('product_data.csv', mode="w", newline="") as csv_file:
writer = csv.writer(csv_file)
writer.writerow(('Title', 'Price', 'Description', 'Image Link', 'Rating', 'Number of Reviews'))
writer.writerow((title, price, description, image_url, rating, reviews))
print('Data has been saved to product_data.csv')Setelah menjalankan skrip, kami mendapatkan informasi bukan di baris perintah tetapi di file product_data.csv. Misalnya, metode ini lebih nyaman jika Anda memiliki banyak halaman produk dan ingin mendapatkan semua data ringkasan dalam satu file.

Kode lengkap:
import requests
from bs4 import BeautifulSoup
import csv
url="https://www.amazon.com/Lenovo-Tab-P11-Plus-1st/dp/B09B17DVYR/ref=sr_1_2?qid=1695021332&rnid=16225007011&s=computers-intl-ship&sr=1-2&th=1"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
title_element = soup.find('span', id='productTitle')
title = title_element.get_text(strip=True) if title_element else 'Title not found'
price_element = soup.find('span', class_='a-price-whole')
price = price_element.get_text(strip=True) if price_element else 'Price not found'
description_element = soup.find('div', id='productDescription')
description = description_element.get_text() if description_element else 'Description not found'
image_element = soup.find('div', id='imgTagWrapperId')
if image_element:
image_url = image_element.find('img')('src')
else:
image_url="Image link not found"
rating_element = soup.find('span', class_='reviewCountTextLinkedHistogram')
rating = rating_element('title') if rating_element else 'Rating not found'
reviews_element = soup.find('span', id='acrCustomerReviewText')
reviews = reviews_element.get_text(strip=True) if reviews_element else 'Number of reviews not found'
with open('product_data.csv', mode="w", newline="") as csv_file:
writer = csv.writer(csv_file)
writer.writerow(('Title', 'Price', 'Description', 'Image Link', 'Rating', 'Number of Reviews'))
writer.writerow((title, price, description, image_url, rating, reviews))
print('Data has been saved to product_data.csv')
else:
print(str(response.status_code)+' - Error loading the page')Anda dapat menyempurnakannya untuk mendapatkan lebih banyak data atau menggunakannya apa adanya.
Membuat perayap tautan produk
Pada contoh sebelumnya, kita melihat opsi skrip untuk mengekstrak informasi dari halaman produk. Kami menyediakan link halaman produk secara manual, namun kami dapat menangkapnya secara otomatis. Untuk melakukan ini, kami membuka halaman kategori dan melihat di mana tautan ke produk disimpan untuk membuat perayap kecil untuk mengumpulkan tautan ini.
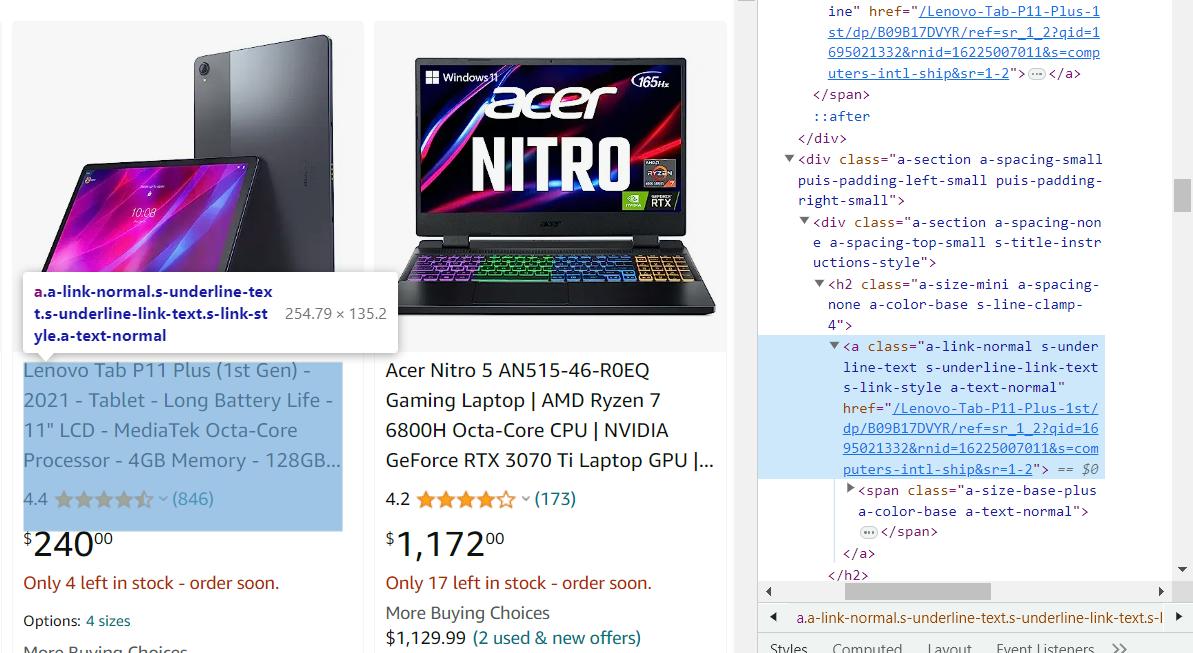
Mengikis tautan tidak berbeda dengan mengeksekusi data dari halaman produk, jadi kami akan segera memberi Anda kode yang dihasilkan:
import requests
from bs4 import BeautifulSoup
url="https://www.amazon.com/s?bbn=16225007011&rh=n%3A16225007011%2Cn%3A13896617011&dc&qid=1695021317&rnid=16225007011&ref=lp_16225007011_nr_n_2"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
product_links = soup.find_all('a', class_='a-link-normal s-underline-text s-underline-link-text s-link-style a-text-normal')
for link in product_links:
product_url="https://www.amazon.com" + link('href')
print(product_url)
else:
print(response.status_code)Jika Anda ingin laba-laba web Anda mengumpulkan tautan dan informasi produk secara otomatis alih-alih hanya menampilkan tautan di layar, Anda dapat menggunakan skrip yang telah kita lihat sebelumnya.
Tantangan Amazon Scraping: Masalah dan Solusi
Pengikisan web bisa menjadi tugas yang menantang karena beberapa alasan. Membuat scraper itu sendiri bisa menjadi tugas yang menantang, namun menghindari pemblokiran selama scraping dan mengikuti perubahan yang telah dilakukan pengembang pada situs scraping bahkan lebih sulit lagi. Jika Anda tidak terus-menerus mendukung dan meningkatkan scraper Amazon Anda, efektivitasnya akan cepat hilang. Jadi, mari kita lihat cara menghindari masalah pengikisan data yang paling umum.
Pertama, Ketentuan Layanan Amazon secara khusus melarang web scraping, yaitu ekstraksi data dari situs web Amazon menggunakan alat atau robot otomatis. Artinya, akses otomatis apa pun ke situs web Amazon dilarang, termasuk mengekstraksi informasi produk, harga, ulasan, peringkat, dan data relevan lainnya dari daftar produk Amazon.
Langkah-langkah teknis
Amazon memiliki sejumlah tindakan untuk mendeteksi dan mencegah pengikisan, seperti: Contohnya termasuk membatasi permintaan, melarang alamat IP, dan menggunakan sidik jari browser untuk mengidentifikasi bot. Aktivitas online yang mencurigakan dapat menyebabkan potensi pemblokiran. Namun, Amazon biasanya memverifikasi identitas pengguna dengan menghadirkan tantangan CAPTCHA sebelum menerapkan pembatasan untuk memastikan perbedaan antara manusia dan bot.
Kami telah membicarakan hal ini dan cara menghindari penyumbatan. Namun, jika Anda ingin menghindari membaca artikel lain, berikut solusi cepatnya: gunakan API web scraping untuk mengumpulkan detail produk. Ini adalah cara terbaik untuk melewati CAPTCHA dan mencegah pemblokiran.
Perubahan struktur situs web yang sering terjadi
Amazon terus-menerus mengubah situs webnya, menambahkan hal-hal baru dan mengubah tampilannya. Hal ini dapat menyebabkan scraper yang dibuat untuk mengumpulkan data dari situs web ini berhenti berfungsi. Untuk menghindari masalah ini, perlu dilakukan pemantauan perubahan pada situs. Hal ini dapat dilakukan secara manual, dengan menelusuri situs web, atau menggunakan alat pemantauan perubahan.
Selain itu, jika Anda mengantisipasi bahwa suatu bagian mungkin terlihat berbeda atau mungkin akan segera berubah, Anda dapat menggunakan try..exclusive untuk mencegah kerusakan seluruh kode. Dengan cara ini, meskipun strukturnya berubah, Anda tetap mendapatkan data yang Anda butuhkan, meskipun dalam skala yang sedikit lebih kecil.
Pilihan lainnya adalah menggunakan alat yang ada untuk mengikis data produk Amazon. Misalnya, Anda dapat menggunakan scraper tanpa kode kami. Dalam hal ini, Anda tidak perlu khawatir tentang struktur halaman atau apa pun - Anda cukup mendapatkan data yang Anda butuhkan.
Pengumpulan data Amazon menggunakan Web Scraping API
Seperti yang telah disebutkan, kita dapat menggunakan API web scraping untuk menyelesaikan tugas yang ada. Ini menangani pemrosesan pertanyaan Anda untuk Anda. Ini berarti Anda tidak perlu khawatir alamat IP Anda diblokir dan Anda tidak perlu menggunakan server proxy untuk melewati CAPTCHA. Selain itu, API scraping web kami memungkinkan Anda mengumpulkan data dengan cepat menggunakan pemilih CSS dan aturan ekstraksi.
Dapatkan kunci API
Untuk memulai, Anda memerlukan kunci API. Anda dapat menemukannya di akun Anda setelah mendaftar dengan Scrape-It.Cloud. Selain itu, Anda akan menerima 1.000 kredit gratis saat mendaftar untuk menguji fitur kami.
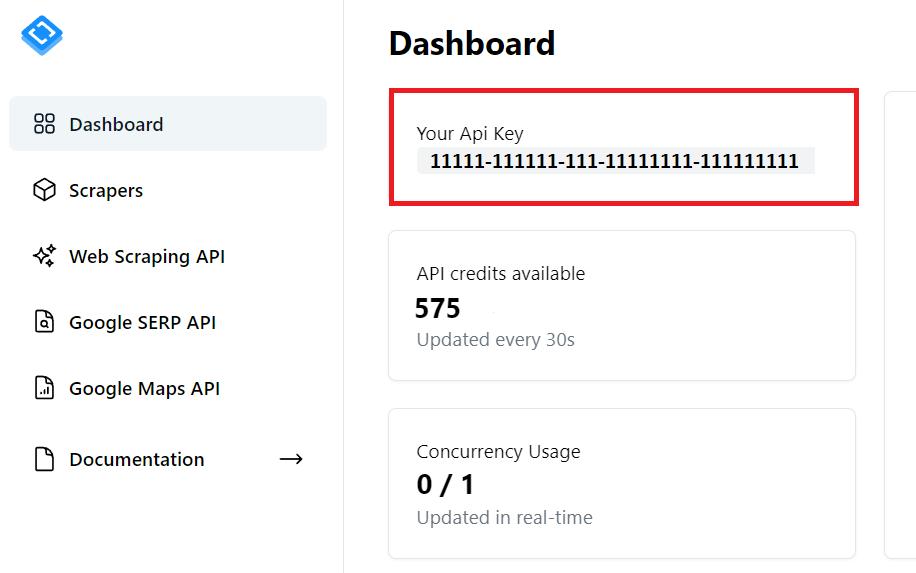
Anda akan memerlukan kunci API ini dalam kode selanjutnya.
Sekarang kita mendapatkan data yang sama seperti contoh sebelumnya tetapi menggunakan web scraping API. Kami juga menyimpan semua data yang kami terima dalam file Excel. Impor semua perpustakaan yang akan kita gunakan:
import requests
import json
import pandas as pdKita memerlukan perpustakaan Permintaan untuk membuat permintaan ke API. Lalu kita menggunakannya JSON Library untuk memproses respon dari API yang berformat JSON. Dan pada akhirnya kami menggunakan perpustakaan Pandas untuk membuat bingkai data dan menyimpan data dalam file Excel.
Sekarang mari kita atur variabel dan parameter yang akan kita gunakan di seluruh skrip:
url="https://www.amazon.com/s?bbn=16225007011&rh=n%3A16225007011%2Cn%3A13896617011&dc&qid=1695021317&rnid=16225007011&ref=lp_16225007011_nr_n_2"
api_url="https://api.scrape-it.cloud/scrape"
api_key = 'PUT-YOUR-API-KEY'
headers = {
'x-api-key': api_key,
'Content-Type': 'application/json'
}Di sini Anda harus memberikan tautan ke halaman produk dan kunci API pribadi Anda. Kemudian bentuk isi kueri untuk mengambil semua link di halaman:
payload = json.dumps({
"url": url,
"js_rendering": True,
"block_ads": True,
"extract_rules": {
'links': 'a.a-link-normal.s-underline-text.s-underline-link-text.s-link-style.a-text-normal @href'
},
"proxy_type": "datacenter",
"proxy_country": "US"
})Di sini kami telah menentukan pemilih CSS dalam aturan ekstraksi untuk segera mendapatkan data yang diperlukan. Sekarang kami menjalankan permintaan dan mengurai respons dalam format JSON untuk mendapatkan daftar tautan:
response = requests.request("POST", api_url, headers=headers, data=payload)
if response.status_code == 200:
data = response.json()
product_links = data('scrapingResult')('extractedData')('links')Tetapkan aturan ekstraksi yang mendapatkan data yang kita butuhkan:
extract_rules = {
"title": "span#productTitle",
"price": "span.a-price-whole",
"description": "div#productDescription",
"image": "div#imgTagWrapperId img",
"rating": "span.reviewCountTextLinkedHistogram",
"reviews": "span#acrCustomerReviewText"
}Menambahkan for Ulangi untuk menelusuri semua tautan dan membuat permintaan untuk mendapatkan data dari masing-masing tautan:
for product_link in product_links:
url = str("https://www.amazon.com/")+str(product_link)
print(url)
payload = json.dumps({
"extract_rules": extract_rules,
"wait": 0,
"block_resources": False,
"url": url
})
response = requests.post(api_url, headers=headers, data=payload)Sekarang yang harus Anda lakukan adalah menyimpan data ke file. Untuk ini kami menggunakan perpustakaan Pandas, yang membuat header itu sendiri dan memungkinkan kami menyimpan data yang diperlukan dengan mudah:
if response.status_code == 200:
data = response.json()
data = data('scrapingResult')('extractedData')
df = pd.DataFrame(data)
df.to_excel("scraped_data.xlsx", index=False)
else:
print(f'Error: {response.status_code} - Error loading the page for {product_link}')Meskipun kami sekarang memiliki file data yang berisi semua produk yang dapat kami peroleh dengan menggabungkan contoh-contoh sebelumnya, saat menggunakan API kami tidak perlu khawatir tentang masalah seperti pemblokiran atau perolehan konten dinamis.
Diploma
Pada artikel ini, kami membahas berbagai cara untuk mengumpulkan data dari halaman Amazon. Kami juga telah membahas masalah yang akan Anda hadapi saat menggunakan scraper dan metode untuk mengatasi masalah tersebut.
Anda dapat menggunakan API web scraping untuk menghindari masalah seperti pemblokiran IP dan penanganan konten dinamis. Jika Anda tidak ingin menghadapi kerumitan apa pun, Anda dapat menggunakan scraper Amazon tanpa kode kami yang sudah jadi, yang akan memberi Anda detail produk Amazon dalam format yang nyaman.
