
TL;DR: Menggunakan Koran3k
Pertama instal paket Newspaper3k:
Berikut beberapa cuplikan kode yang berguna saat menggunakan paket:
- Unduh HTML halaman untuk diurai
- Parsing respons HTML untuk mengekstrak titik data tertentu
- Ekstrak semua penulis halaman artikel
- Ekstrak tanggal publikasi artikel
- Ekstrak teks artikel dari HTML
- Ekstrak gambar sampul artikel
- Unduh video apa pun untuk artikel tersebut
Gunakan pemrosesan bahasa alami (NLP) untuk menganalisis artikel sebelum mengekstraksi data tambahan. Ini akan memberi Anda kata kunci dan ringkasan artikel
- Ekstrak istilah pencarian yang relevan dari artikel
- Buat ringkasan singkat dari sebuah artikel
Apakah Anda ingin mempelajari cara menggunakan semua ini dalam proyek nyata?
Lanjut membaca!
Apa itu Koran3k?
Newspaper3k adalah alat yang ampuh untuk Pengikisan web. Ini adalah perpustakaan Python yang membaca konten dari situs web yang terstruktur seperti artikel online. Ia juga memiliki fitur lain yang memungkinkan pengembang menganalisis konten HTML untuk mengekstrak data seperti penulis, judul, teks isi, tanggal publikasi, dan terkadang konten gambar atau video yang terkait dengan artikel.
Cara mengikis artikel berita dengan Newspaper3k
Untuk mengikis artikel berita menggunakan paket Newspaper3k, pertama-tama buat folder proyek dan di dalamnya ada file bernama index.py. Kemudian ikuti langkah-langkah di bawah ini.
Langkah 1: Instal paket Newspaper3k
Instal paket Newspaper3k dengan menjalankan perintah berikut:
Langkah 2: Unduh dan analisis artikel
Impor paket dan dapatkan URL dari halaman berita yang ingin Anda kikis. Pertama kita download artikelnya dengan mengklik download() metode pada item tersebut. Kemudian kita analisa artikel tersebut dengan memanggil metodenya
parse()Seperti yang ditunjukkan di bawah ini.
from newspaper import Article
url = 'https://edition.cnn.com/2023/06/10/sport/manchester-city-wins-champions-league-for-first-time-beating-inter-milan-1-0-in-tense-istanbul-final/index.html'
article = Article(url)
article.download()
article.parse()
Langkah 3: Ekstrak data yang diinginkan
Metode Parse yang dipanggil pada langkah sebelumnya mengekstrak data dari halaman HTML. Data ini meliputi:
- judul – mengekstrak judul artikel
- Penulis – mengekstrak daftar penulis atau penulis artikel dan mengembalikan hasilnya dalam array.
- Tanggal rilis – mengekstrak tanggal dan waktu artikel diterbitkan
- teks – mengekstrak konten teks artikel
- html – mengembalikan HTML penuh halaman
- gambar atas – mengembalikan gambar unggulan artikel (jika ada)
- Foto-foto – mengembalikan objek yang berisi URL semua gambar dalam artikel
- video – mengekstrak semua video di artikel (jika ada)
# Extract and print the desired data
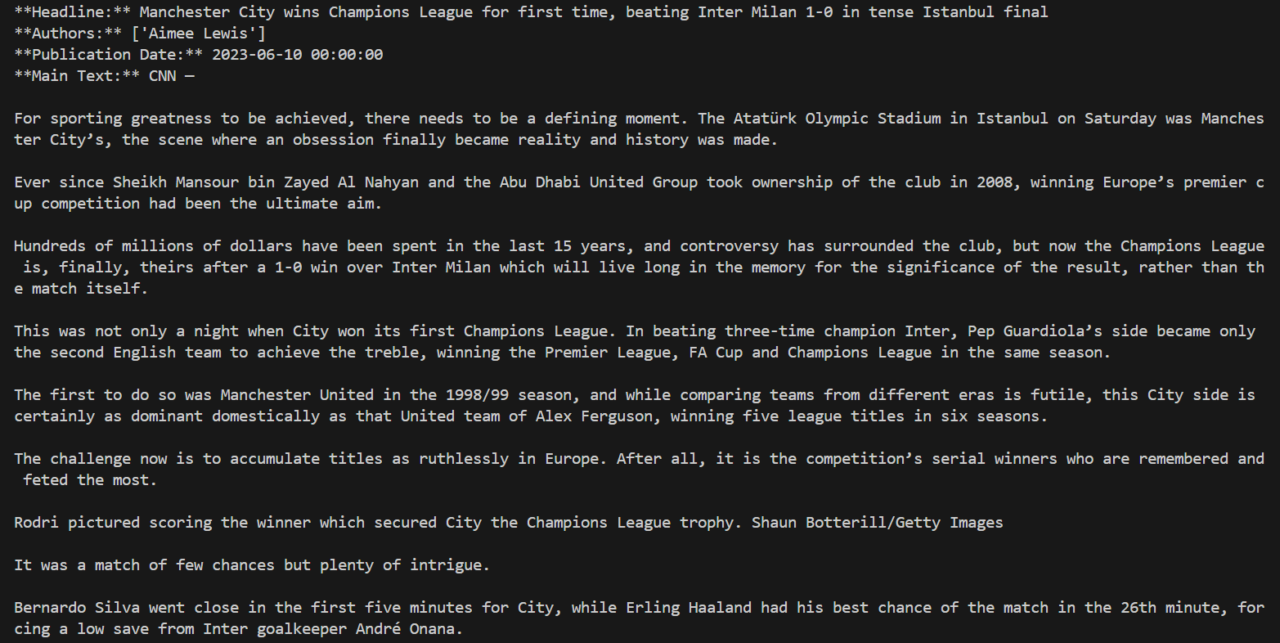
print("**Headline:**", article.title)
print("**Authors:**", article.authors)
print("**Publication Date:**", article.publish_date)
print("**Main Text:**", article.text)
Jalankan skrip dengan mengeluarkan perintah berikut.
Hasilnya akan menyerupai gambar di bawah ini.
Langkah 4: Atur bahasa artikel
Paket Newspaper3k juga memiliki fitur tertanam untuk pengenalan dan ekstraksi ucapan tanpa hambatan. Hal ini memungkinkan pengembang menentukan bahasa untuk ekstraksi data. Jika tidak ada bahasa yang ditentukan, Newspaper3k akan secara otomatis mendeteksi bahasa dan menggunakannya secara default.
Mari kita lihat cara menentukan bahasa saat mengambil data:
url = 'https://www.bbc.com/zhongwen/simp/chinese_news/2012/12/121210_hongkong_politics'
article = Article(url, language='zh') #Chinese
Pada saat penulisan, Newspaper3k mendukung bahasa berikut:
Your available languages are:
input code full name
ar Arabic
be Belarusian
bg Bulgarian
da Danish
de German
el Greek
en English
es Spanish
et Estonian
fa Persian
fi Finnish
fr French
he Hebrew
hi Hindi
hr Croatian
hu Hungarian
id Indonesian
it Italian
ja Japanese
ko Korean
mk Macedonian
nb Norwegian (Bokmål)
nl Dutch
no Norwegian
pl Polish
pt Portuguese
ro Romanian
ru Russian
sl Slovenian
sr Serbian
sv Swedish
sw Swahili
tr Turkish
uk Ukrainian
vi Vietnamese
zh Chinese
Tambahkan rotasi proxy di Newspaper3k menggunakan ScraperAPI
Banyak surat kabar dan situs artikel menggunakan teknologi anti-bot, sehingga menyulitkan paket untuk merayapi situs web dalam skala besar. Mengoptimalkan header dan menggunakan proxy untuk mengekstrak data HTML mentah dari situs web biasanya tidak dapat dihindari dalam situasi ini.
Namun, kelemahan utama Newspaper3k adalah fitur pengunduhan tidak memiliki dukungan bawaan untuk proxy. Oleh karena itu, klien HTTP seperti Permintaan Python harus digunakan untuk mengimplementasikannya dan kemudian HTML harus diurai menggunakan perpustakaan Newspaper3k.
Untuk contoh ini, kami akan menggunakan API scraping ScraperAPI sebagai solusi proksi untuk mengekstrak konten HTML dan meneruskannya ke Newspaper3k untuk dianalisis.
catatan: Untuk menggunakan metode Titik Akhir Proksi ScraperAPI, Anda harus membuat akun ScraperAPI gratis untuk mengakses kunci API di dasbor Anda - uji coba gratis Anda mencakup 5.000 kredit API, yang dalam banyak kasus akan memberi Anda hingga 5.000. Anda dapat mengikis halaman secara gratis.
import requests
from urllib.parse import urlencode
from newspaper import Article
url = 'https://edition.cnn.com/2023/06/10/sport/manchester-city-wins-champions-league-for-first-time-beating-inter-milan-1-0-in-tense-istanbul-final/index.html'
article = Article(url)
## Download HTML using ScraperAPI Proxy
payload = {'api_key': ‘API-KEY', 'url': url}
response = requests.get('https://api.scraperapi.com', params=urlencode(payload))
## Insert HTML into the Newspaper3k article object and parse the article
article.download(input_html=response.text)
article.parse()
print("Headline: ", article.title)
print("Authors: ", article.authors)
print("Publication Date: ", article.publish_date)
Kombinasi ini memungkinkan Anda menskalakan scraper ke jutaan halaman tanpa harus mengkhawatirkan CAPTCHA, batas kecepatan, dan potensi tantangan lainnya.
Cara menggunakan metode NLP Newspaper3k
Newspaper3k juga menawarkan fitur Natural Language Processing (NLP). Hal ini memungkinkan pengembang menganalisis konten sebelum mengekstraknya. Itu
nlp() Cara ini memungkinkan Anda mendapatkan ringkasan dan kata kunci dalam artikel.
Metode NLP sama rumitnya dengan metode parse. Oleh karena itu, penting untuk hanya menggunakannya bila diperlukan. Di bawah ini adalah demo cara mengimplementasikan metode NLP.
from newspaper import Article
url = 'https://edition.cnn.com/2023/06/10/sport/manchester-city-wins-champions-league-for-first-time-beating-inter-milan-1-0-in-tense-istanbul-final/index.html'
article = Article(url)
article.download()
article.parse()
article.nlp()
# Extract and print the desired data
print("**Text Summary:**", article.summary)
print("**Keywords: **", article.keywords)
Hasilnya akan menyerupai gambar di bawah ini.

Kiat pemecahan masalah untuk metode NLP Newspaper3k
Kesalahan ini dapat terjadi ketika metode nlp() diimplementasikan untuk pertama kalinya.

Kesalahan ini dapat diperbaiki dengan menambahkan kode berikut di bagian atas skrip:
import nltk
nltk.download('punkt')
Kemudian jalankan kembali skrip tersebut. Skrip ini mengunduh paket dot yang diperlukan untuk menjalankan fungsi NLP. Kedua baris kode tersebut kemudian dapat dihapus tanpa mempengaruhi eksekusi skrip.
Menggunakan fitur pengunduhan artikel multi-utas Newspaper3k
Fitur ini memungkinkan pengembang mengekstrak berita dari beberapa sumber berita sekaligus. Mengirim spam ke satu sumber pesan dengan beberapa thread atau beberapa permintaan I/O asinkron secara bersamaan akan mengakibatkan pembatasan kecepatan. Oleh karena itu, Newspaper3k menyediakan 1-2 thread untuk setiap sumber berita yang disediakan.
Untuk mengimplementasikan fitur multi-threading pada fungsi download artikel, gunakan kode berikut:
import newspaper
from newspaper import news_pool
ted = newspaper.build('https://ted.com')
cnbc = newspaper.build('https://cnbc.com')
fox_news = newspaper.build('https://foxnews.com/')
papers = (ted, cnbc, fox_news)
news_pool.set(papers, threads_per_source=2) # (3*2) = 6 threads total
news_pool.join()
# At this point, you can safely assume that download() has been
# called on every single article for all three sources.
print(cnbc.size())
Itu join() Metode ini memanggil fungsi pengunduhan artikel apa pun dari sumber mana pun. Oleh karena itu, setiap sumber mengembalikan sebuah array dan data di setiap array dapat diakses seperti yang ditunjukkan di bawah ini.
for article in cnbc.articles:
print(article.title)
Terus belajar
Dalam artikel ini kita mempelajari hal berikut:
- Gunakan paket Newspaper3k untuk mengikis situs surat kabar dan artikel
-
Integrasikan Newspaper3k dengan ScraperAPI untuk menskalakan infrastruktur Anda dalam hitungan detik
-
Gunakan metode nlp() untuk mengekstrak istilah pencarian yang relevan dan membuat ringkasan untuk setiap artikel
Paket ini menawarkan beberapa fitur lainnya termasuk hot Dan
popular_url Metode paket koran. Metode ini mengembalikan istilah yang sedang tren atau sumber berita paling populer. Untuk informasi lebih lanjut tentang paket ini, lihat dokumentasi resmi.
Jika Anda ingin mempelajari lebih lanjut tentang scraping dengan Python, lihat beberapa sumber berikut:
Sampai jumpa lagi, selamat menggores!
