
Pada Pengikisan web ini lebih dari sekedar mengambil kode HTML. Anda juga harus memproses kodenya, dan Python menawarkan beberapa perpustakaan untuk tugas ini. Salah satu pilihan paling populer dan ramah bagi pemula adalah Beautiful Soup.
Kesederhanaan perpustakaan ini menjadikannya pilihan populer bagi pemula. Artikel ini memberikan petunjuk mendetail tentang cara menggunakannya untuk analisis halaman, serta kemungkinan tantangan dan solusinya.
Memulai dengan Sup Cantik
Sebelum memulai, pastikan Anda telah menginstal Python 3.9 atau lebih baru dan menyiapkan lingkungan pengembangan. Kami juga merekomendasikan pengaturan lingkungan virtual untuk memastikan proses pengembangan yang aman.
Jika Anda baru mengenal pemrograman Python, mengalami masalah instalasi, atau memerlukan bantuan dalam menyiapkan lingkungan virtual, lihat artikel pengantar Python kami untuk petunjuk detailnya.
Instal Sup Cantik
BeautifulSoup, juga dikenal sebagai bs4, adalah perpustakaan Python populer untuk web scraping. Ini memungkinkan Anda menganalisis halaman HTML dengan mudah dan mengekstrak berbagai elemen dari strukturnya.
Untuk menginstalnya kami menggunakan manajer paket dan, bergantung pada sistem operasi, jalankan perintah berikut di terminal atau di baris perintah:
pip install bs4Setelah menginstal, impor bs4 ke skrip Python Anda dan mulai web scraping.
Struktur dasar halaman HTML
Sebelum menganalisis data dari halaman HTML, penting untuk memahami struktur dasarnya. HTML terdiri dari tag, yang masing-masing memiliki peran tertentu. Misalnya, setiap halaman memiliki satu
, yang berisi judul halaman, gaya dan skrip, dan a , yang berisi konten yang terlihat.Untuk lebih memahami strukturnya, mari kita visualisasikan:
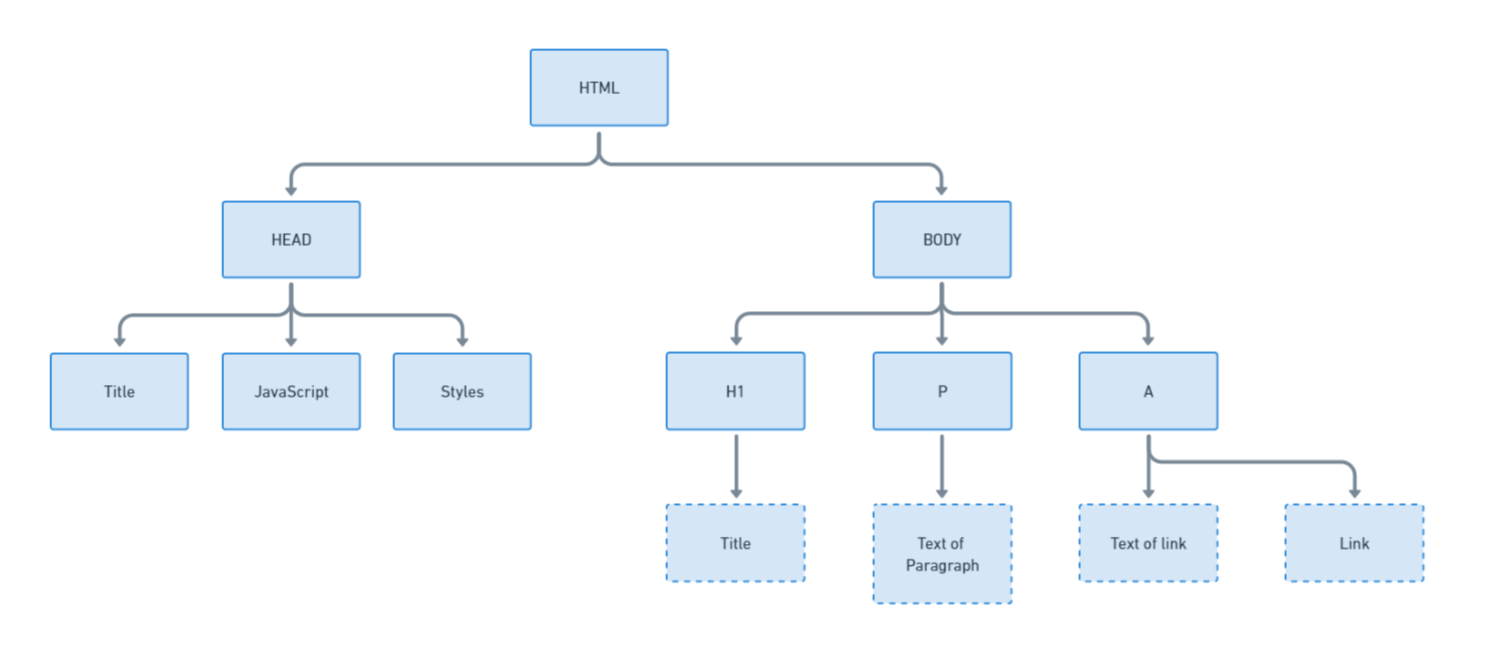
Memahami struktur membantu mengidentifikasi data yang ingin Anda ekstrak. Misalnya, tautan biasanya ada di -Tag disimpan saat teks biasa masuk
-Tag disimpan. Mari kita lihat HTML example.com, dengan beberapa gaya dihapus agar singkatnya:
<html><head>
<title>Contoh domain</title>
<meta charset="utf-8">
<meta http-equiv="Content-type" content="text/html; charset=utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<style type="text/css">
body {
background-color: #f0f0f2;
margin: 0;
padding: 0;
font-family: -apple-system, system-ui, BlinkMacSystemFont, "Segoe UI", "Open Sans", "Helvetica Neue", Helvetica, Arial, sans-serif;
}
div {
width: 600px;
margin: 5em auto;
padding: 2em;
background-color: #fdfdff;
border-radius: 0.5em;
box-shadow: 2px 3px 7px 2px rgba(0,0,0,0.02);
}
a:link, a:visited {
color: #38488f;
text-decoration: none;
}
@media (max-width: 700px) {
div {
margin: 0 auto;
width: auto;
}
}
</style>
<style>.reset-css {
border: 0;
line-height: 1.5;
margin: 0;
padding: 0;
width: auto;
height: auto;
font-size: 100%;
border-collapse: separate;
border-spacing: 0;
text-align: left;
vertical-align: middle;
}
</style></head>
<body>
<div>
<h1>Contoh domain</h1>
<p>Domain ini untuk digunakan dalam contoh ilustratif dalam dokumen. Anda dapat menggunakan domain ini dalam literatur tanpa koordinasi sebelumnya atau meminta izin.</p>
<p><a href="https://www.iana.org/domains/example">Informasi lebih lanjut...</a></p>
</div>
<div id="wt-sky-root"></div></body></html>Setiap halaman unik dan memiliki kumpulan tag HTML sendiri. Artinya tidak ada skrip terpadu untuk mengurai data dari halaman HTML. Sebaliknya, Anda perlu mengidentifikasi tag spesifik pada setiap halaman yang berisi data yang Anda inginkan.
Anda dapat menggunakan DevTools di browser Anda untuk melakukan ini. Buka DevTools dengan menekan F12 atau klik kanan pada halaman dan pilih Inspect. Kemudian navigasikan ke tab Elemen untuk melihat kode HTML.
Dapatkan kode HTML dari file atau situs web
Seperti disebutkan sebelumnya, Beautiful Soup adalah perpustakaan Python untuk mengurai dokumen HTML. Ini tidak cocok untuk web scraping atau mengirim permintaan HTTP, tetapi ini akan membantu Anda mengurai elemen HTML tertentu.
Sebelum Anda dapat menggunakan BeautifulSoup, Anda perlu mendapatkan HTML yang ingin Anda parsing. Berikut dua cara umum untuk melakukannya: dari file HTML dan halaman web. Mari kita asumsikan bahwa dalam folder yang sama dengan skrip kita, kita memiliki file index.html yang menyimpan kode HTML suatu halaman. Kemudian kita bisa menggunakan kode berikut untuk mendapatkannya:
with open('index.html', 'r') as file:
html_code = file.read()Jika Anda ingin mendapatkan data dari halaman dan bukan file HTML, Anda harus menggunakan perpustakaan tambahan yang bisa membuat permintaan. Anda dapat menggunakan perpustakaan apa pun yang Anda kenal, seperti: Misalnya “permintaan”, “urllib” atau “http.klien”. Mari pertimbangkan perpustakaan Permintaan sebagai contoh:
import requests
response = requests.get('https://example.com')
html_code = response.textSekarang variabel html_code berisi semua kode HTML halaman dan kita dapat menguraikannya menggunakan perpustakaan bs4.
Parsing kode HTML dengan Beautiful Soup
Sekarang kita perlu membuat objek sup yang mewakili dokumen HTML yang dapat kita gunakan untuk berinteraksi. Kami mengimpor perpustakaan ke proyek kami dan membuat objek sup dengan parser yang ditentukan. Dalam kasus kami ini adalah parser HTML:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_code, 'html.parser')Setelah itu, kita dapat mengakses objek ini untuk mengekstrak data yang diperlukan.
Temukan elemen HTML
Beautiful Soup menyediakan beberapa metode untuk menemukan dan mengedit elemen dalam dokumen HTML. Di bawah ini adalah metode utama:
| metode | Keterangan |
|---|---|
| temukan(nama, attrs, rekursif, string, **kwargs) | Temukan elemen pertama yang cocok dengan parameter yang ditentukan. |
| find_all(nama, attrs, rekursif, string, batas, **kwargs) | Temukan semua elemen yang cocok dengan parameter yang ditentukan. |
| find_next(nama, attrs, string, **kwargs) | Temukan item berikutnya setelah item yang ditentukan. |
| find_all_next(nama, attrs, string, limit, **kwargs) | Temukan semua elemen sesuai dengan elemen yang ditentukan. |
| find_previous(nama, attrs, string, **kwargs) | Temukan elemen sebelumnya sebelum elemen yang ditentukan. |
| find_all_previous(nama, attrs, string, limit, **kwargs) | Menemukan semua elemen sebelum elemen yang ditentukan. |
| find_parent(nama, attrs, string, **kwargs) | Temukan induk dari elemen yang ditentukan. |
| find_all_parents(nama, attrs, string, limit, **kwargs) | Temukan semua induk dari elemen yang ditentukan. |
| find_next_sibling(nama, attrs, string, **kwargs) | Temukan saudara berikutnya dari elemen yang ditentukan. |
| find_all_next_siblings(nama, attrs, string, limit, **kwargs) | Temukan semua saudara terdekat dari elemen yang ditentukan. |
| find_previous_sibling(nama, attrs, string, **kwargs) | Temukan elemen saudara sebelumnya dari elemen yang ditentukan. |
| find_all_previous_siblings(nama, attrs, string, limit, **kwargs) | Temukan semua elemen saudara sebelumnya dari elemen yang ditentukan. |
| pilih(pemilih, rekursif=Benar, batas=Tidak Ada, **kwargs) | Temukan elemen menggunakan pemilih CSS. |
Daftar lengkap metode dapat ditemukan di dokumentasi resmi. Pada bagian ini, kita akan membahas beberapa contoh penggunaan metode tersebut untuk mencari item yang dibutuhkan berdasarkan berbagai parameter.
Dengan nama tag HTML
Beautiful Soup memudahkan untuk menemukan elemen pada halaman dengan tag HTML-nya. Misalnya, jika kita mengetahui bahwa semua tautan masuk tag disertakan, kita dapat menggunakan metode find_all() untuk menemukan semuanya -Tag ditemukan di halaman:
all_a_tags = soup.find_all('a')Ini akan menghasilkan daftar semua yang ditemukan tag dikembalikan. Kita juga dapat menggunakan find() untuk hanya mendapatkan tag HTML pertama yang cocok:
first_a_tags = soup.find('a')Penting untuk dicatat bahwa pencarian dilakukan pada seluruh kode HTML halaman, bukan hanya bagian yang ditampilkan di layar. Artinya yang pertama -hari biasanya masuk -hari dan tidak masuk -Hari berada. Penting untuk mempertimbangkan hal ini saat menguraikan.
Berdasarkan tanda pengenal
Terkadang elemen diberi pengidentifikasi unik, ID, yang secara unik mengidentifikasi objek. Hanya ada satu elemen dengan ID seperti itu pada suatu halaman, jadi pencarian berdasarkan ID cukup dapat diandalkan.
element_by_id = soup.find(id='example_id')ID ditentukan sebagai atribut tag HTML.
Berdasarkan nama kelas
Kelas adalah cara mudah lainnya untuk mendeskripsikan elemen. Mereka nyaman bagi pengembang situs web karena mereka dapat membuat kumpulan gaya unik untuk setiap kelas yang dapat ditetapkan dengan mudah. Kelas juga bagus untuk parsing.
elements_by_class = soup.find_all(class_='example_class')Terkadang pencarian berdasarkan kelas adalah cara yang paling nyaman dan bahkan satu-satunya cara untuk menemukan elemen pada halaman.
Menggunakan pemilih CSS
Beautiful Soup juga mendukung pencarian elemen menggunakan pemilih CSS, memberikan pendekatan yang cukup fleksibel. Misalnya, mari pertimbangkan untuk menelusuri semua item berdasarkan tag , yang terletak di dalam elemen dengan kelas “container”:
selected_elements = soup.select('.container a')Penggunaan pemilih CSS menjadikan BeautifulSoup alat yang sangat berguna. Dan jika Anda belum menggunakannya, Anda dapat mempelajari lebih lanjut tentang penyeleksi CSS dan cara menggunakannya di artikel kami yang lain.
Memilih item yang sesuai saja tidak cukup untuk mendapatkan data yang dibutuhkan. Pertama, Anda perlu menentukan apakah Anda memerlukan teks elemen atau konten atributnya. Tergantung pada ini, ekstraksi data berbeda-beda. Di bagian ini kita akan melihat kedua opsi.
Seperti disebutkan sebelumnya, teks pada halaman biasanya berada di
-Hari. Oleh karena itu, sebagai contoh, mari kita ekstrak teks dari elemen berikut:
paragraph_text = soup.find('p').textJika Anda ingin teks dari semua elemen dengan tag
Untuk mengekstrak, Anda perlu ingat bahwa metode find_all mengembalikan daftar, bukan elemen. Oleh karena itu, untuk mengekstrak konten tag, Anda perlu mengulangi semua elemen daftar dan mengekstrak teks satu per satu:
all_paragraphs = soup.find_all('p')
all_paragraph_texts = (paragraph.text for paragraph in all_paragraphs)Dengan kode ini Anda dapat mengubah isi semua elemen dengan
-Ekstrak tag pada halaman.
Kasus penggunaan umum lainnya adalah mengekstraksi tautan. Namun, link tidak disimpan di dalam tag itu sendiri, melainkan di dalam atribut tag, misalnya:
<a href="https://www.iana.org/domains/example">Informasi lebih lanjut...</a>Namun, kita dapat menentukan atribut yang isinya ingin kita kembalikan ketika mencari suatu elemen:
link_href = soup.find('a')('href')Sekarang mari kita ekstrak semua tautan di halaman:
all_links = soup.find_all('a')
all_link_hrefs = (link('href') for link in all_links)Ini memungkinkan Anda mengekstrak informasi dari tag atau atribut apa pun. Yang paling penting adalah memperhatikan apakah Anda mendapatkan suatu item atau daftar. Tergantung pada ini, pemrosesannya akan berbeda.
Teknik tingkat lanjut
Pada titik ini, kami telah membahas metode utama perpustakaan bs4, dan metode tersebut akan cukup untuk menyelesaikan sebagian besar masalah. Namun, kami juga ingin membagikan beberapa trik tambahan yang mungkin berguna saat mengerjakan proyek tertentu.
Menavigasi antar elemen
Terkadang lebih mudah untuk menemukan suatu elemen berdasarkan saudara atau orangtuanya dibandingkan dengan satu elemen saja. Misalkan Anda tidak dapat menemukan elemen yang Anda perlukan secara langsung, namun Anda dapat dengan mudah mengidentifikasi elemen saudara sebelumnya:
current_element = soup.find(id='example_id')Kemudian temukan yang berikutnya
-Elemen setelah elemen_saat ini:
next_element = current_element.find_next_sibling('p')Anda juga dapat menemukan saudara sebelumnya:
prev_element = current_element.find_previous_sibling('p')Anda dapat menggunakan metode serupa untuk menemukan orang tua dan anak.
Menangani elemen bersarang
Namun, Beautiful Soup menawarkan cara yang lebih ringkas untuk menavigasi elemen anak: notasi titik. Ini memungkinkan Anda mengakses elemen bersarang langsung dari elemen induk.
Misalnya, mari kita cari elemen div induk:
outer_div = soup.find('div')Kemudian akses elemen anak apa pun secara langsung:
inner_paragraph = outer_div.pIni akan lebih nyaman untuk bekerja dengan struktur bersarang.
Elemen penyaring
Anda dapat menggunakan BeautifulSoup untuk menemukan dan memfilter elemen saat mengekstrak data tertentu dari halaman web. Ini berguna saat mengekstraksi informasi spesifik, menghapus item yang tidak diinginkan, atau mengatur data. Misalnya, mari kita semua mencari
-Tag dan filter berdasarkan konten teks:
filtered_elements = soup.find_all('p', text="desired_text")Dengan menggunakan prinsip yang sama, Anda dapat memfilter konten tag dan elemen apa pun.
Meskipun sebagian besar konten tekstual masuk
tag, ada kalanya Anda perlu mengekstrak semua teks pada halaman apa pun tag penampungnya. Untuk melakukan ini, Anda dapat menggunakan metode get_text() pada seluruh objek BeautifulSoup:
all_text = soup.get_text()Kode ini mengembalikan semua teks di halaman mana pun, apa pun struktur tagnya.
Jadikan pemformatan HTML cantik
Meskipun tugas ini jarang terjadi, mungkin ada saatnya Anda memerlukan cara untuk membuat kode HTML Anda cantik. Anda dapat melakukannya menggunakan metode berikut:
pretty_html = soup.prettify()Ini akan menambahkan lekukan dan jeda baris yang diperlukan ke kode HTML Anda.
Mengatasi tantangan
Beberapa kesulitan mungkin muncul saat memproses kode HTML dengan perpustakaan BeautifulSoup. Pada bagian ini Anda akan mempelajari cara mengatasinya.
Kode HTML hilang atau rusak
Situs web mungkin berisi HTML yang tidak lengkap atau salah. BeautifulSoup dirancang untuk menangani HTML "kotor" tersebut dan akan melakukan yang terbaik untuk menafsirkannya dan menyediakan akses ke data. Misalnya, HTML tidak lengkap berikut ini diuraikan dengan benar:
tidak lengkap_html="<p>Ini adalah paragraf" sup = BeautifulSoup(incomplete_html, 'html.parser')Seperti yang ditunjukkan oleh latihan, BeautifulSoup mengatasi masalah seperti itu dengan cukup baik.
Kondisi kesalahan
Seperti kode lainnya, BeautifulSoup dapat menyebabkan kesalahan saat memproses data. Misalnya, jika Anda mencoba menemukan elemen yang tidak ada, BeautifulSoup mengembalikan Tidak Ada. Pemrosesan lebih lanjut dari elemen ini menghasilkan pengecualian. Untuk menghindari hal ini, gunakan blok coba/eksklusif atau pemeriksaan bersyarat untuk menangani data yang hilang.
Konten dinamis
Beautiful Soup hanya mem-parsing HTML dan tidak mengambilnya. Anda memerlukan alat terpisah untuk mengambil kode HTML dan memproses halaman web dinamis. Anda kemudian dapat menggunakan BeautifulSoup atau alat pilihan Anda untuk mengekstrak item yang diperlukan.
Alat populer untuk menangani halaman dinamis adalah Selenium dan Pyppeteer. Anda dapat menggunakannya untuk mendapatkan kode HTML:
from selenium import webdriver
from bs4 import BeautifulSoup
driver = webdriver.Chrome()
driver.get('https://example.com')
dynamic_content = driver.page_source
soup = BeautifulSoup(dynamic_content, 'html.parser')Namun, karena alat ini memiliki metode penguraiannya sendiri, penggunaan BeautifulSoup mungkin tidak diperlukan.
Diploma
Beautiful Soup adalah salah satu perpustakaan web scraping yang paling populer dan mudah digunakan. Mudah dipelajari, bahkan bagi pengguna yang tidak memiliki teknologi web atau pengetahuan pemrograman yang luas. Ia menawarkan berbagai metode untuk mencari, menavigasi dan mengekstraksi data dari HTML. Fitur pemfilteran dan navigasinya yang fleksibel cocok untuk berbagai skenario web scraping.
Namun, seperti alat lainnya, alat ini memiliki beberapa keterbatasan. Ini tidak mendukung permintaan asinkron, yang dapat menjadi kerugian saat bekerja dengan data atau konten dinamis dalam jumlah besar. Selain itu, ini tidak menjalankan JavaScript, sehingga alat lain seperti Selenium mungkin diperlukan untuk situs web yang menghasilkan konten menggunakan JavaScript.
Seperti disebutkan dalam artikel, perpustakaan ini dirancang untuk parsing dan tidak mengeksekusi permintaan HTTP secara independen. Oleh karena itu, mengunduh halaman web memerlukan perpustakaan tambahan seperti Permintaan.
Secara keseluruhan, BS4 adalah alat yang ampuh dan praktis untuk web scraping. Namun, seperti teknologi apa pun, ia memiliki kekuatan dan keterbatasannya sendiri. Pilihan penggunaan bergantung pada persyaratan spesifik tugas dan preferensi pengembang.
